Spark---创建DataFrame的方式
1、读取json格式的文件创建DataFrame
注意:
1、可以两种方式读取json格式的文件。
2、df.show()默认显示前20行数据。
3、DataFrame原生API可以操作DataFrame。
4、注册成临时表时,表中的列默认按ascii顺序显示列。
df.createTempView("mytable")
df.createOrReplaceTempView("mytable")
df.createGlobalTempView("mytable")
df.createOrReplaceGlobalTempView("mytable")
Session.sql("select * from global_temp.mytable").show()5、DataFrame是一个Row类型的RDD,df.rdd()/df.javaRdd()。
java
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("jsonfile");
SparkContext sc = new SparkContext(conf);//创建sqlContext
SQLContext sqlContext = new SQLContext(sc);/*** DataFrame的底层是一个一个的RDD RDD的泛型是Row类型。* 以下两种方式都可以读取json格式的文件*/
DataFrame df = sqlContext.read().format("json").load("sparksql/json");
// DataFrame df2 = sqlContext.read().json("sparksql/json.txt");
// df2.show();/*** DataFrame转换成RDD*/
RDD<Row> rdd = df.rdd();
/*** 显示 DataFrame中的内容,默认显示前20行。如果现实多行要指定多少行show(行数)* 注意:当有多个列时,显示的列先后顺序是按列的ascii码先后显示。*/
// df.show();
/*** 树形的形式显示schema信息*/
df.printSchema();
/*** dataFram自带的API 操作DataFrame*///select name from table// df.select("name").show();//select name age+10 as addage from tabledf.select(df.col("name"),df.col("age").plus(10).alias("addage")).show();//select name ,age from table where age>19df.select(df.col("name"),df.col("age")).where(df.col("age").gt(19)).show();//select count(*) from table group by agedf.groupBy(df.col("age")).count().show();/*** 将DataFrame注册成临时的一张表,这张表临时注册到内存中,是逻辑上的表,不会雾化到磁盘*/df.registerTempTable("jtable");DataFrame sql = sqlContext.sql("select age,count(1) from jtable group by age");DataFrame sql2 = sqlContext.sql("select * from jtable");sc.stop();scala:
1.val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
2.// val frame: DataFrame = session.read.json("./data/json")
3.val frame = session.read.format("json").load("./data/json")
4.frame.show(100)
5.frame.printSchema()
6.
7./**
8.* DataFrame API 操作
9.*/
10.//select name ,age from table
11.frame.select("name","age").show(100)
12.
13.//select name,age + 10 as addage from table
14.frame.select(frame.col("name"),frame.col("age").plus(10).as("addage")).show(100)
15.
16.//select name,age from table where age >= 19
17.frame.select("name","age").where(frame.col("age").>=(19)).show(100)
18.frame.filter("age>=19").show(100)
19.
20.//select name ,age from table order by name asc ,age desc
21.import session.implicits._
22.frame.sort($"name".asc,frame.col("age").desc).show(100)
23.
24.//select name ,age from table where age is not null
25.frame.filter("age is not null").show()
26.
27./**
28.* 创建临时表
29.*/
30.frame.createTempView("mytable")
31.session.sql("select name ,age from mytable where age >= 19").show()
32.frame.createOrReplaceTempView("mytable")
33.frame.createGlobalTempView("mytable")
34.frame.createOrReplaceGlobalTempView("mytable")
35.
36./**
37.* dataFrame 转换成RDD
38.*/
39.val rdd: RDD[Row] = frame.rdd
40.rdd.foreach(row=>{
41. val name = row.getAs[String]("name")
42. val age = row.getAs[Long]("age")
43. println(s"name is $name ,age is $age")
44.})2、通过json格式的RDD创建DataFrame
java:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("jsonRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> nameRDD = sc.parallelize(Arrays.asList("{\"name\":\"zhangsan\",\"age\":\"18\"}","{\"name\":\"lisi\",\"age\":\"19\"}","{\"name\":\"wangwu\",\"age\":\"20\"}"
));
JavaRDD<String> scoreRDD = sc.parallelize(Arrays.asList(
"{\"name\":\"zhangsan\",\"score\":\"100\"}",
"{\"name\":\"lisi\",\"score\":\"200\"}",
"{\"name\":\"wangwu\",\"score\":\"300\"}"
));DataFrame namedf = sqlContext.read().json(nameRDD);
DataFrame scoredf = sqlContext.read().json(scoreRDD);
namedf.registerTempTable("name");
scoredf.registerTempTable("score");DataFrame result = sqlContext.sql("select name.name,name.age,score.score from name,score where name.name = score.name");
result.show();sc.stop();scala:
1.val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
2.val jsonList = List[String](
3. "{'name':'zhangsan','age':'18'}",
4. "{'name':'lisi','age':'19'}",
5. "{'name':'wangwu','age':'20'}",
6. "{'name':'maliu','age':'21'}",
7. "{'name':'tainqi','age':'22'}"
8.)
9.
10.import session.implicits._
11.val jsds: Dataset[String] = jsonList.toDS()
12.val df = session.read.json(jsds)
13.df.show()
14.
15./**
16.* Spark 1.6
17.*/
18.val jsRDD: RDD[String] = session.sparkContext.parallelize(jsonList)
19.val frame: DataFrame = session.read.json(jsRDD)
20.frame.show()
3、非json格式的RDD创建DataFrame
1)、通过反射的方式将非json格式的RDD转换成DataFrame(不建议使用)
- 自定义类要可序列化
- 自定义类的访问级别是Public
- RDD转成DataFrame后会根据映射将字段按Assci码排序
- 将DataFrame转换成RDD时获取字段两种方式,一种是df.getInt(0)下标获取(不推荐使用),另一种是df.getAs(“列名”)获取(推荐使用)
/**
* 注意:
* 1.自定义类必须是可序列化的
* 2.自定义类访问级别必须是Public
* 3.RDD转成DataFrame会把自定义类中字段的名称按assci码排序
*/
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("RDD");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lineRDD = sc.textFile("sparksql/person.txt");
JavaRDD<Person> personRDD = lineRDD.map(new Function<String, Person>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Person call(String s) throws Exception {Person p = new Person();p.setId(s.split(",")[0]);p.setName(s.split(",")[1]);p.setAge(Integer.valueOf(s.split(",")[2]));return p;}
});
/**
* 传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame
* 在底层通过反射的方式获得Person的所有field,结合RDD本身,就生成了DataFrame
*/
DataFrame df = sqlContext.createDataFrame(personRDD, Person.class);
df.show();
df.registerTempTable("person");
sqlContext.sql("select name from person where id = 2").show();/**
* 将DataFrame转成JavaRDD
* 注意:
* 1.可以使用row.getInt(0),row.getString(1)...通过下标获取返回Row类型的数据,但是要注意列顺序问题---不常用
* 2.可以使用row.getAs("列名")来获取对应的列值。
*
*/
JavaRDD<Row> javaRDD = df.javaRDD();
JavaRDD<Person> map = javaRDD.map(new Function<Row, Person>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Person call(Row row) throws Exception {Person p = new Person();//p.setId(row.getString(1));//p.setName(row.getString(2));//p.setAge(row.getInt(0));p.setId((String)row.getAs("id"));p.setName((String)row.getAs("name"));p.setAge((Integer)row.getAs("age"));return p;}
});
map.foreach(new VoidFunction<Person>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic void call(Person t) throws Exception {System.out.println(t);}
});sc.stop();scala:
1.case class MyPerson(id:Int,name:String,age:Int,score:Double)
2.
3.object Test {
4. def main(args: Array[String]): Unit = {
5. val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
6. val peopleInfo: RDD[String] = session.sparkContext.textFile("./data/people.txt")
7. val personRDD : RDD[MyPerson] = peopleInfo.map(info =>{
8.MyPerson(info.split(",")(0).toInt,info.split(",")(1),info.split(",")(2).toInt,info.split(",")(3).toDouble)
9. })
10. import session.implicits._
11. val ds = personRDD.toDS()
12. ds.createTempView("mytable")
13. session.sql("select * from mytable ").show()
14. }
15.}2)、动态创建Schema将非json格式的RDD转换成DataFrame
java:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("rddStruct");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lineRDD = sc.textFile("./sparksql/person.txt");
/*** 转换成Row类型的RDD*/
JavaRDD<Row> rowRDD = lineRDD.map(new Function<String, Row>() {/*** */private static final long serialVersionUID = 1L;@Overridepublic Row call(String s) throws Exception {return RowFactory.create(String.valueOf(s.split(",")[0]),String.valueOf(s.split(",")[1]),Integer.valueOf(s.split(",")[2]));}
});
/*** 动态构建DataFrame中的元数据,一般来说这里的字段可以来源自字符串,也可以来源于外部数据库*/
List<StructField> asList =Arrays.asList(DataTypes.createStructField("id", DataTypes.StringType, true),DataTypes.createStructField("name", DataTypes.StringType, true),DataTypes.createStructField("age", DataTypes.IntegerType, true)
);StructType schema = DataTypes.createStructType(asList);
DataFrame df = sqlContext.createDataFrame(rowRDD, schema);df.show();
sc.stop();scala:
1.val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
2.val peopleInfo: RDD[String] = session.sparkContext.textFile("./data/people.txt")
3.
4.val rowRDD: RDD[Row] = peopleInfo.map(info => {
5. val id = info.split(",")(0).toInt
6. val name = info.split(",")(1)
7. val age = info.split(",")(2).toInt
8. val score = info.split(",")(3).toDouble
9. Row(id, name, age, score)
10.})
11.val structType: StructType = StructType(Array[StructField](
12. StructField("id", IntegerType),
13. StructField("name", StringType),
14. StructField("age", IntegerType),
15. StructField("score", DoubleType)
16.))
17.val frame: DataFrame = session.createDataFrame(rowRDD,structType)
18.frame.createTempView("mytable")
19.session.sql("select * from mytable ").show()4、读取parquet文件创建DataFrame
注意:
- 可以将DataFrame存储成parquet文件。保存成parquet文件的方式有两种
df.write().mode(SaveMode.Overwrite)format("parquet").save("./sparksql/parquet");
df.write().mode(SaveMode.Overwrite).parquet("./sparksql/parquet");- SaveMode指定文件保存时的模式。
Overwrite:覆盖
Append:追加
ErrorIfExists:如果存在就报错
Ignore:如果存在就忽略
java:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("parquet");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> jsonRDD = sc.textFile("sparksql/json");
DataFrame df = sqlContext.read().json(jsonRDD);
/*** 将DataFrame保存成parquet文件,SaveMode指定存储文件时的保存模式* 保存成parquet文件有以下两种方式:*/
df.write().mode(SaveMode.Overwrite).format("parquet").save("./sparksql/parquet");
df.write().mode(SaveMode.Overwrite).parquet("./sparksql/parquet");
df.show();
/*** 加载parquet文件成DataFrame * 加载parquet文件有以下两种方式: */DataFrame load = sqlContext.read().format("parquet").load("./sparksql/parquet");
load = sqlContext.read().parquet("./sparksql/parquet");
load.show();sc.stop();scala:
1.val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
2.val frame: DataFrame = session.read.json("./data/json")
3.frame.show()
4.frame.write.mode(SaveMode.Overwrite).parquet("./data/parquet")
5.
6.val df: DataFrame = session.read.format("parquet").load("./data/parquet")
7.df.createTempView("mytable")
8.session.sql("select count(*) from mytable ").show()5、读取JDBC中的数据创建DataFrame(MySql为例)
两种方式创建DataFrame
java:
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("mysql");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
/*** 第一种方式读取MySql数据库表,加载为DataFrame*/
Map<String, String> options = new HashMap<String,String>();
options.put("url", "jdbc:mysql://192.168.179.4:3306/spark");
options.put("driver", "com.mysql.jdbc.Driver");
options.put("user", "root");
options.put("password", "123456");
options.put("dbtable", "person");
DataFrame person = sqlContext.read().format("jdbc").options(options).load();
person.show();
person.registerTempTable("person");
/*** 第二种方式读取MySql数据表加载为DataFrame*/
DataFrameReader reader = sqlContext.read().format("jdbc");
reader.option("url", "jdbc:mysql://192.168.179.4:3306/spark");
reader.option("driver", "com.mysql.jdbc.Driver");
reader.option("user", "root");
reader.option("password", "123456");
reader.option("dbtable", "score");
DataFrame score = reader.load();
score.show();
score.registerTempTable("score");DataFrame result =
sqlContext.sql("select person.id,person.name,score.score from person,score where person.name = score.name");
result.show();
/*** 将DataFrame结果保存到Mysql中*/
Properties properties = new Properties();
properties.setProperty("user", "root");
properties.setProperty("password", "123456");
result.write().mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.179.4:3306/spark", "result", properties);sc.stop();scala:
1.val session = SparkSession.builder().appName("jsonData").master("local").getOrCreate()
2.
3.val prop = new Properties()
4.prop.setProperty("user","root")
5.prop.setProperty("password","123456")
6./**
7.* 第一种方式
8.*/
9.val df1 = session.read.jdbc("jdbc:mysql://192.168.179.14:3306/spark","person",prop)
10.df1.show()
11.df1.createTempView("person")
12.
13./**
14.* 第二种方式
15.*/
16.val map = Map[String,String](
17. "url" -> "jdbc:mysql://192.168.179.14:3306/spark",
18. "driver " -> "com.mysql.jdbc.Driver",
19. "user" -> "root",
20. "password" -> "123456",
21. "dbtable" -> "score"
22.)
23.val df2 = session.read.format("jdbc").options(map).load()
24.df2.show()
25.
26./**
27.* 第三种方式
28.*/
29.val df3 = session.read.format("jdbc")
30. .option("url", "jdbc:mysql://192.168.179.14:3306/spark")
31. .option("driver", "com.mysql.jdbc.Driver")
32. .option("user", "root")
33. .option("password", "123456")
34. .option("dbtable", "score")
35. .load()
36.df3.show()
37.df3.createTempView("score")
38.
39.val result = session.sql("select person.id,person.name,person.age,score.score from person ,score where person.id = score.id")
40.
41.result.show()
42.//将结果保存到mysql中
43.result.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.179.14:3306/spark","result",prop)
44.相关文章:

Spark---创建DataFrame的方式
1、读取json格式的文件创建DataFrame 注意: 1、可以两种方式读取json格式的文件。 2、df.show()默认显示前20行数据。 3、DataFrame原生API可以操作DataFrame。 4、注册成临时表时,表中的列默认按ascii顺序显示列。 df.createTempView("mytab…...

瑜伽学习零基础入门,各种瑜伽教学方法全集
一、教程描述 练习瑜伽的好处多多,能够保证平衡健康的身体基础,提升气质、塑造形体、陶冶情操,等等。本套教程是瑜伽的组合教程,共由33套视频教程组合而成,包含了塑身纤体,速效瘦身,四季养生&a…...

pycharm编译报错处理
1.c生成工具下载 https://visualstudio.microsoft.com/visual-cpp-build-tools/ 在这里插入图片描述 pip install pycocotools...
)
“华为杯”研究生数学建模竞赛2019年-【华为杯】E题:基于多变量的全球气候与极端天气模型的构建与应用(附python代码实现)
目录 摘 要: 一.问题重述 1.1 问题背景 1.2 问题提出 二.模型假设及符号设定...
)
冒泡排序(适合编程新手的体质)
冒泡排序:简单而高效的排序技巧 欢迎来到我们今天的博客,我们将一起探索计算机科学中最基本但同时也非常重要的概念之一:冒泡排序。无论你是编程新手还是有一些编程经验的读者,这篇博客都将帮助你更好地理解冒泡排序的原理和应用…...

pdfjs,pdf懒加载
PDF.js是一个使用JavaScript实现的PDF阅读器,它可以在Web浏览器中显示PDF文档。PDF.js支持懒加载,也就是说,它可以在用户滚动页面时才加载PDF文档的某些部分,从而减少初始加载时间和内存占用。 注意点:如果要运行在多留…...
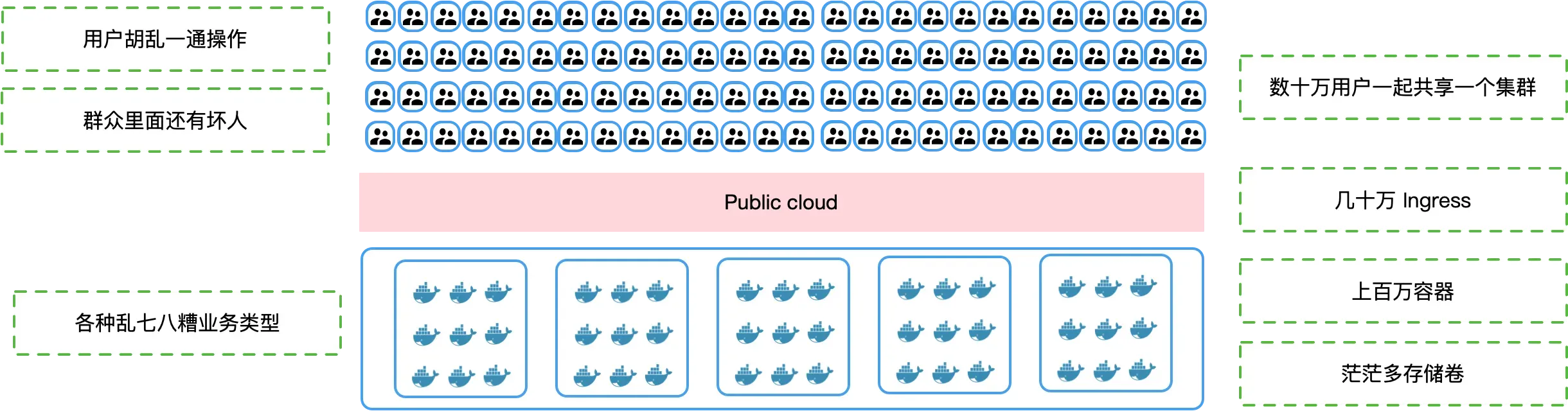
K8s 多租户方案的挑战与价值
在当今企业环境中,随着业务的快速增长和多样化,服务器和云资源的管理会越来越让人头疼。K8s 虽然很强大,但在处理多个部门或团队的业务部署需求时,如果缺乏有效的多租户支持,在效率和资源管理方面都会不尽如人意。 本…...
单链表相关经典算法OJ题:移除链表元素
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 题目:移除链表元素 解法一: 解法一的代码实现: 解法二: 解法二代码的实现: 总结 前言 世上有两种耀眼的…...

【JUC】十九、volatile与内存屏障
文章目录 1、volatile的两大特性2、volatile的四大内存屏障3、分类4、happens-before之volatile变量重排规则5、读写屏障插入策略 1、volatile的两大特性 被volatile修饰的变量有两大特点: 可见性有序性 关于volatile的可见性,也即volatile的内存语义…...
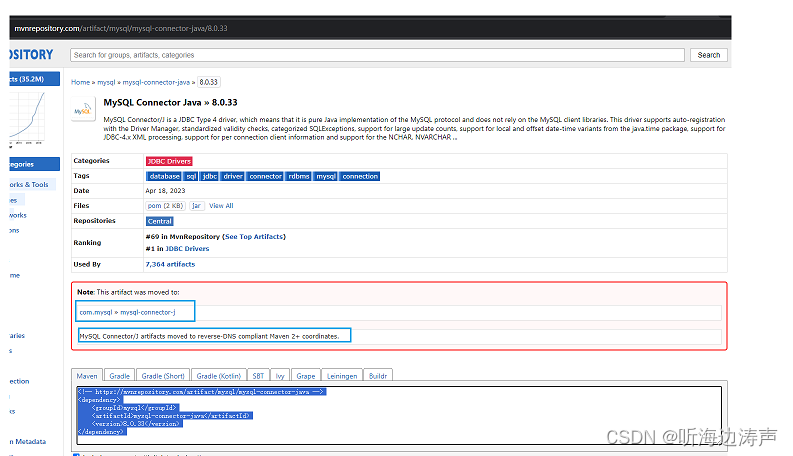
下载MySQL JDBC驱动的方法
说明 java代码通过JDBC访问MySQL数据库,需要MySQL JDBC驱动。 例如,下面这段代码,因为找不到JDBC驱动,所以执行会报异常: package com.thb;public class JDBCDemo {public static void main(String[] args) throws …...
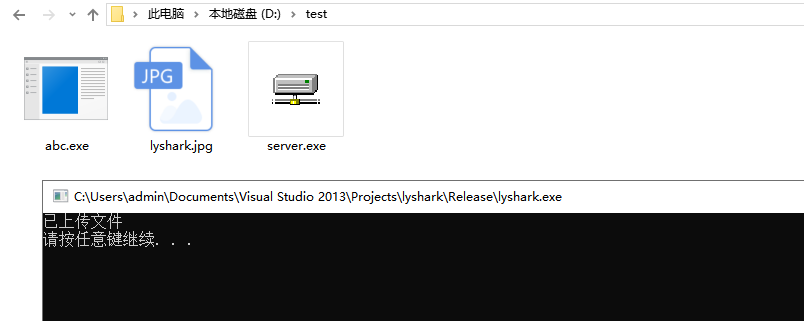
C/C++ 实现FTP文件上传下载
FTP(文件传输协议)是一种用于在网络上传输文件的标准协议。它属于因特网标准化的协议族之一,为文件的上传、下载和文件管理提供了一种标准化的方法,在Windows系统中操作FTP上传下载可以使用WinINet库,WinINetÿ…...

第十三章 python之爬虫
Python基础、函数、模块、面向对象、网络和并发编程、数据库和缓存、 前端、django、Flask、tornado、api、git、爬虫、算法和数据结构、Linux、设计题、客观题、其他 第十三章 爬虫 1. 写出在网络爬取过程中, 遇到防爬问题的解决办法。 在网络爬取过程中,可能会遇…...

scrum 敏捷开发
scrum 敏捷开发 Scrum 是一种敏捷软件开发方法,旨在通过迭代、增量和协作的方式提高团队的效率和产品质量。下面是关于 Scrum 的一些重要概念和实践: 1. Scrum 团队角色 Scrum 团队通常由以下角色组成: 产品负责人(Product Ow…...

亚信科技AntDB数据库完成中国信通院数据库迁移工具专项测试
近日,在中国信通院“可信数据库”数据库迁移工具专项测试中,湖南亚信安慧科技有限公司(简称:亚信安慧科技)数据库数据同步平台V2.1产品依据《数据库迁移工具能力要求》、结合亚信科技AntDB分布式关系型数据库产品&…...

深度学习(一):Pytorch之YOLOv8目标检测
1.YOLOv8 2.模型详解 2.1模型结构设计 和YOLOv5对比: 主要的模块: ConvSPPFBottleneckConcatUpsampleC2f Backbone ----->Neck------>head Backdone 1.第一个卷积层的 kernel 从 6x6 变成了 3x3 2. 所有的 C3 模块换成 C2f,可以发现…...
EasyExcel如何读取全部Sheet页数据方法
一、需求描述 Excel表格里面大约有20个sheet页,每个sheet页65535条数据,需要读取全部数据,并导入至数据库。 找了好多种方式,EasyExcel比较符合,下面看代码。 二、实现方式 采用EasyExcel框架的doReadAll()方法 1、…...
GDPU 数据结构 天码行空12
文章目录 数据结构实验十二 图的遍历及应用一、【实验目的】二、【实验内容】三、实验源代码🍻 CPP🍻 C 数据结构实验十二 图的遍历及应用 一、【实验目的】 1、 理解图的存储结构与基本操作; 2、熟悉图的深度度优先遍历和广度优先遍历算法…...

什么是 Proxy?
目录 Proxy 的作用 1. 流量过滤 2. 记录日志 3. 加快访问速度 4. 隐藏 IP 地址 Proxy 的分类 1. 按协议分类 - HTTP 代理:只支持 HTTP 协议的代理服务器,它可以缓存 HTTP 请求和响应并过滤 HTTP 流量。 - FTP 代理:只支持 FTP 协议的…...

Vue系列:Vue Element UI中,使用按钮实现视频的播放、停止、停止后继续播放、播放完成后重新播放功能
最近在工作中有个政务大屏用到了视频播放; 技术栈是Vue2、Element UI; 要实现的功能是:使用按钮实现视频的播放、停止、停止后继续播放、播放完成后重新播放功能 具体可以按照以下步骤进行操作: 引入插件: 在Vue组件…...

.Net 8 Blazor下 Auto交互渲染模式试用
一、环境 C:\Users\zhuji>dotnet --version 8.0.100C:\Users\zhuji>dotnet --list-sdks 5.0.403 [C:\Program Files\dotnet\sdk] 6.0.404 [C:\Program Files\dotnet\sdk] 8.0.100 [C:\Program Files\dotnet\sdk] Microsoft Visual Studio Enterprise 2022 (64 位) - Cu…...

量子优化新突破:虚时间演化高效求解QUBO问题
1. 量子优化新范式:模拟虚时间演化解决QUBO问题在金融投资组合优化、物流路径规划和机器学习特征选择等领域,二次无约束二进制优化(QUBO)问题无处不在。这类NP难问题随着规模扩大,求解难度呈指数级增长,传统…...

AssetStudio Unity资源提取终极指南:精准解析SerializedFile与AssetBundle
1. 为什么AssetStudio是Unity资源提取的“第一把刀”——不是因为它最强,而是因为它最准你有没有遇到过这样的场景:刚下载一个热门Unity手游的APK,兴致勃勃地解包,结果在assets/bin/Data/Managed/目录下看到一堆Assembly-CSharp.d…...

探索OneMore:解锁OneNote高效笔记的完整指南
探索OneMore:解锁OneNote高效笔记的完整指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款专为OneNote设计的强大插件,通过160…...
)
Spring Boot项目实战:手把手教你集成银联B2B无卡支付(SM2国密证书版)
Spring Boot实战:银联B2B无卡支付集成全流程解析(SM2国密证书版) 在企业级应用开发中,支付功能是不可或缺的核心模块。银联B2B无卡支付作为国内企业间交易的重要渠道,其安全性和稳定性备受开发者关注。本文将带你从零开…...

2026头部GEO服务商哪家实力强?服务质量效果深度测评,合作优选榜单
随着生成式AI全面接管大众信息检索与商业决策场景,GEO生成式引擎优化已然成为企业品牌智能化布局的核心刚需。相较于传统SEO的页面排名逻辑,GEO主打适配大模型语义推理、信源采信、答案生成规则,帮助品牌成为AI问答中的核心推荐信源。当下多数…...

昇腾CANN amct:模型压缩工具的量化和部署实践
amct(Ascend Model Compression Toolkit)是 CANN 内置的模型压缩工具,不是 AtomGit 上的独立开源仓库——它在 CANN AOE 调优引擎里作为一个子模块运行。amct 做三件事:量化(INT8/FP16)、剪枝(结…...

MakeMeAHanzi完整指南:如何免费获取9000+汉字笔画动画数据
MakeMeAHanzi完整指南:如何免费获取9000汉字笔画动画数据 【免费下载链接】makemeahanzi Free, open-source Chinese character data 项目地址: https://gitcode.com/gh_mirrors/ma/makemeahanzi MakeMeAHanzi是一个免费开源的汉字数据项目,为开发…...

dumpsys netstats detail 输出解释netd的app的网络流量统计
dumpsys netstats detail 输出解释 重启后,数据会清零,从新统计 UID tag stats: Pending bytes: 27977 History since boot: ident[{type9, ratTypeCOMBINED, meteredtrue, defaultNetworktrue, oemManagedOEM_NONE, subId-1}] uid1000 setDEFAULT tag0x…...

stm32f4 + Helix + Max98357播放mp3文件
stm32f4的SDIO + FataFs读取SD卡文件在前面的文章中已经实现,下面的配置和修改基于之前的配置实现 配置I2S 模式设置 参数设置 DMA配置 勾选 SPI2 global interrupt 以上都配置完Helix 解码出来的 PCM 数据就发给 MAX98357了 Helix解码库移植...

DeepSeek OCR:文档智能处理的成本革命与工程落地
1. 这不是又一个OCR工具,而是一次成本结构的重写DeepSeek OCR这个名字刚出来时,我第一反应是:又一个堆参数的模型?点开官网文档扫了一眼,发现它连“支持PDF”这种基础描述都懒得写——因为PDF只是输入格式里最不值一提…...