Cypher中的聚合
- 深解Cypher中的聚合
- 值或计数的聚合要么从查询返回,要么用作多步查询下一部分的输入。
- 查看数据模型
- CALL db.schema.visualization()
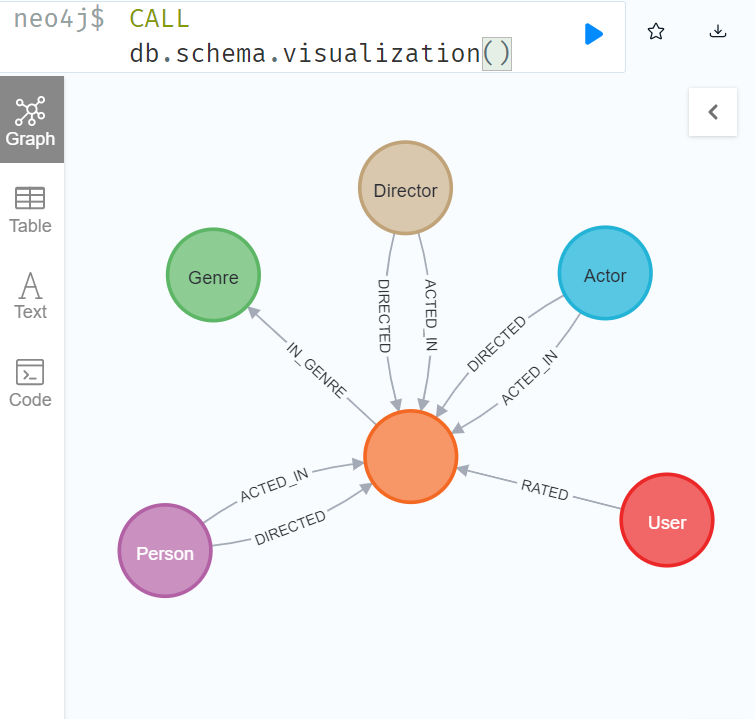
- CALL db.schema.visualization()
- 查看图中节点的属性类型
- CALL db.schema.notetypeproperties()
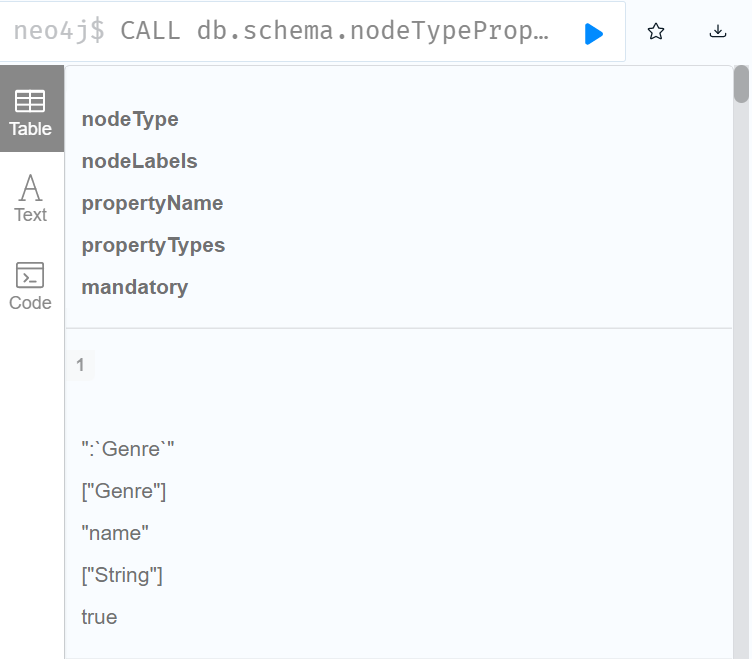
- CALL db.schema.notetypeproperties()
- 查看图中关系的属性类型
- CALL db.schema.reltypeproperties()
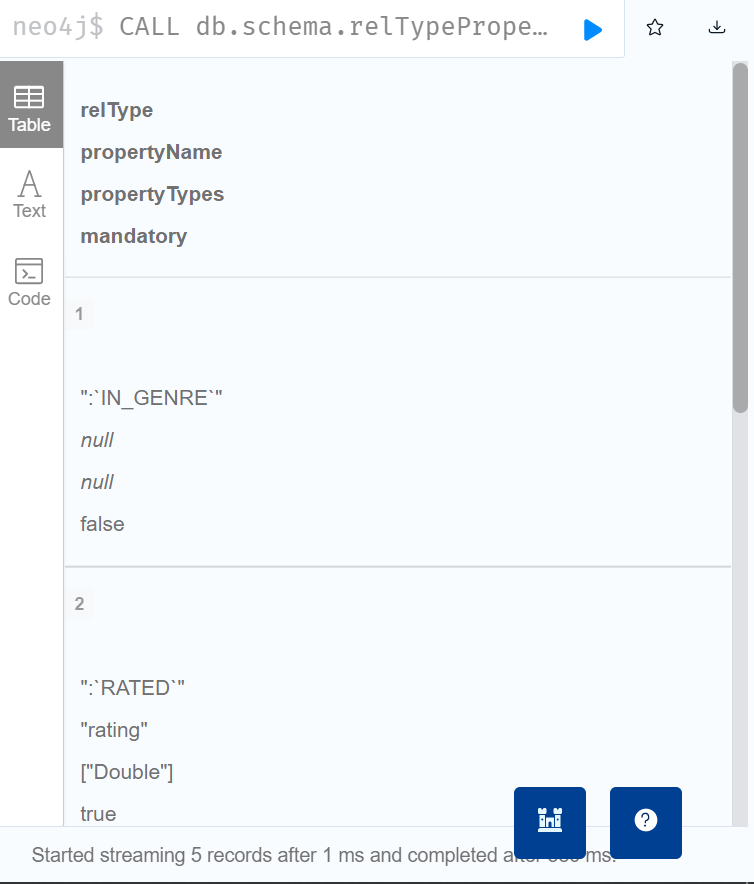
- CALL db.schema.reltypeproperties()
- Cypher中的聚合
- 列表
- 列表是包含元素的数组。列表中的元素不必都是同一类型。
- 使用 [ ]
- MATCH (m:Movie) RETURN [m.title, m.released, date().year - date(m.released).year + 1 ]
- 使用 collect()
- MATCH (a:Actor)--(m:Movie) WITH a,collect(m.title) AS Movies RETURN a.name AS Actor,Movies LIMIT 10
- 工作原理
- 返回一个元素列表。可以 collect() 在查询期间随时使用创建列表。在查询期间创建列表时,会发生聚合。
- 在聚合期间,图形引擎通常根据行中的某个值对数据进行分组。(非聚合值是分组键)
- Examples
- 多个MATCH
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 优化
- PROFILE MATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) WITH m, collect (d.name) AS Directors MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(a.name) AS Actors, Directors
- 类似传统SQL将每部分添加查询条件得到最终结果
- 优化
- PROFIL EMATCH (m:Movie {title:'Jupiter Ascending'}) MATCH (d:Person)-[:DIRECTED]->(m) MATCH (a:Person)-[:ACTED_IN]->(m) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 单个MATCH
- PROFILE MATCH (d:Person)-[:DIRECTED]->(m:Movie {title:'Jupiter Ascending'})<-[:ACTED_IN]-(a:Person) RETURN m.title AS Title, collect(DISTINCT a.name) AS Actors,collect(DISTINCT d.name) AS Directors
- 多个MATCH
- 收集节点
- MATCH (m:Movie) UNWIND m.languages AS language WITH language, collect(m) AS movies MERGE (l:Language {name:language}) WITH l, movies UNWIND movies AS m WITH l,mMERGE (l)<-[:SPEAKS]-(m)
- 以作为 language 分组键,收集节点
- 使用 nodes() 返回路径中的节点列表。
- MATCH path = (p:Person {name: 'Elvis Presley'})-[*4]-(a:Actor) WITH nodes(path) AS n UNWIND n AS x WITH x WHERE x:Movie RETURN DISTINCT x.title
- 收集关系
- MATCH (u:User {name: "Misty Williams"})-[x]->() WITH collect(x) AS ratings UNWIND ratings AS r WITH r WHERE r.rating <= 1 RETURN r.rating AS Rating, endNode(r).title AS Title
- 使用 endNode() 返回关系末尾的节点。
- 与子查询
- PROFILE MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m, collect(p.name) AS Actors WHERE size(Actors) <= 3 RETURN m.title AS Movie, Actors
- 查询重写
- PROFILE CALL { MATCH (m:Movie)<-[:ACTED_IN]-(p:Person) WITH m , collect(p.name) as Actors WHERE size(Actors)<= 3 RETURN m.title as Movie, Actors } RETURN Movie, Actors
- 使用 count()
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person) RETURN a.name AS ActorName,d.name AS DirectorName,count(*) AS NumMovies, collect(m.title) AS Movies ORDER BY NumMovies DESC
- 在属性值上使用
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 此查询看到 born 的计数与其它不同,说明节点中无 born 属性
- MATCH (p:Person) RETURN count(p) , count(p.born),count(p.name)
- 作为过滤查询的子句
- MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WITH a, count(*) AS NumMovies, collect(m.title) AS Movies WHERE NumMovies = 2 RETURN a.name AS Actor,Movies
- 计算节点数
- MATCH (p:Person {name: 'Elvis Presley'})-[]-(m:Movie)-[]-(a:Actor) RETURN count(*), count(m), count (a)
- 可以在查询处理期间对属性、节点、关系、路径或行进行计数。
- 使用模式理解
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 原
- PROFILE MATCH(m:Movie) WHERE m.year = 2015 OPTIONAL MATCH (a:Person)-[:ACTED_IN]-(m) WITH m, collect(DISTINCT a.name) AS Actors OPTIONAL MATCH (m)-[:DIRECTED]-(d:Person) RETURN m.title AS Movie, Actors, collect (DISTINCT d.name) AS Directors
- 模式
- PROFILE MATCH (m:Movie) WHERE m.year = 2015 RETURN m.title AS Movie,[(dir:Person)-[:DIRECTED]->(m) | dir.name] AS Directors,[(actor:Person)-[:ACTED_IN]->(m) | actor.name] AS Actors
- 原
- 模式理解条件的过滤
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title ]AS Movies
- 返回的列表添加更多属性(相当于Oracle中的合并列)
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 AND a.born.year >= 1980 RETURN a.name AS Actor, a.born AS Born,collect(DISTINCT m.title) AS Movies ORDER BY Actor
- MATCH (a:Actor) WHERE a.born.year >= 1980 WITH a, [(a)-[:ACTED_IN]->(m:Movie) WHERE 2000 <= m.year <= 2005 | m.title] AS Movies WHERE size(Movies) > 0 RETURN a.name as Actor, a.born as Born, Movies
- MATCH (a:Person {name: 'Tom Hanks'}) RETURN [(a)--(b:Movie) WHERE b.title CONTAINS "Toy" | b.title + ": " + b.year] AS Movies
- 相当于不重复属性的collect(),注:模式理解下的属性可能为0,所有用size()定义
- 模式理解的行为类似于使用 OPTIONAL MATCH,并且对于这个特定的查询,经过的时间减少了。
- 列表
相关文章:
Cypher中的聚合
深解Cypher中的聚合 值或计数的聚合要么从查询返回,要么用作多步查询下一部分的输入。查看数据模型 CALL db.schema.visualization() 查看图中节点的属性类型 CALL db.schema.notetypeproperties() 查看图中关系的属性类型 CALL db.schema.reltypeproperties() C…...

图注意网络GAT理解及Pytorch代码实现【PyGAT代码详细注释】
文章目录GAT代码实现【PyGAT】GraphAttentionLayer【一个图注意力层实现】用上面实现的单层网络测试加入Multi-head机制的GAT对数据集Cora的处理csr_matrix()处理稀疏矩阵encode_onehot()对label编号build graph邻接矩阵构造GAT的推广GAT 题:Graph Attention Netwo…...

项目成本管理中的常见误区及解决方案
做过项目的人都明白,项目实施时间一般很长,在实施期间总有很多项目结果不尽人意的问题。要使一个项目取得成功,就要结合很多因素一起才能作用,其中做好项目成本的管理就是最重要的步骤之一,下面列出了常见的项目成本管…...

墨天轮2022年度数据库获奖名单
2022年,国家相继从高位部署、省级试点布局、地市重点深入三个维度,颁布了多项中国数据库行业发展的利好政策。但是我们也能清晰地看到,中国数据库行业发展之路道阻且长,而道路上的“拦路虎”之一则是生态。中国数据库的发展需要多…...
仓储调度|库存管理系统
技术:Java、JSP等摘要:随着电子商务技术和网络技术的快速发展,现代物流技术也在不断进步。物流技术是指与物流要素活动有关的所有专业技术的总称,包括各种操作方法、管理技能等,物流业采用某些现代信息技术方面的成功经…...

Canvas入门-01
导读: 读完全文需要2min。通过这篇文章,你可以了解到以下内容: Canvas标签基本属性如何使用Canvas画矩形、圆形、线条、曲线、笑脸😊 如果你曾经了解过Canvas,可以对照目录回忆一下能否回答上来 毕竟带着问题学习最有效…...

运算符优先级
醋坛酸味罐,位落跳福豆 醋:初等运算符: () [] -> . 坛:单目运算符: - ~ – * & ! sizeof 右结合 酸:算术运算符: - * / % 味:位移运算符:>> << …...
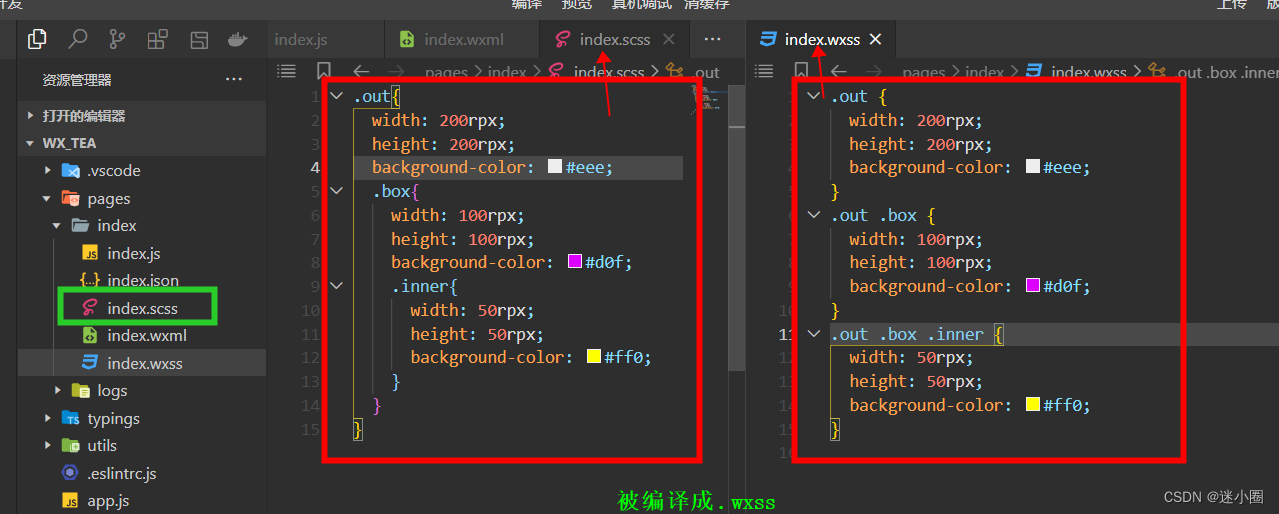
微信小程序使用scss编译wxss文件的配置步骤
文章目录1、在 vscode 中搜索 easysass 插件并安装2、在微信开发工具中导入安装的easysass插件3、修改 spook.easysass-0.0.6/package.json 文件中的配置4、重启开发者工具,就可用使用了微信小程序开发者工具集成了 vscode 编辑器,可以使用 vscode 中众多…...

一步一步教你如何使用 Visual Studio Code 编译一段 C# 代码
以下是一步一步教你如何使用 Visual Studio Code 编写使用 C# 语言输出当前日期和时间的代码: 1、下载并安装 .NET SDK。您可以从 Microsoft 官网下载并安装它。 2、打开 Visual Studio Code,并安装 C# 扩展。您可以在 Visual Studio Code 中通过扩展菜…...

vue-cli中的环境变量注意点
在客户端侧代码中使用环境变量只有以 VUE_APP_ 开头的变量会被 webpack.DefinePlugin 静态嵌入到客户端侧的包中。你可以在应用的代码中这样访问它们:console.log(process.env.VUE_APP_SECRET)在构建过程中,process.env.VUE_APP_SECRET 将会被相应的值所…...

2.3数据类型
文章目录1. 命名规则2.字符3.数字4.日期5.图片1. 命名规则 字段名必须以字母开头,尽量不要使用拼音长度不能超过30个字符(不同数据库,不同版本会有不同)不能使用SQL的保留字,如where,order,group只能使用如下字符a-z、…...
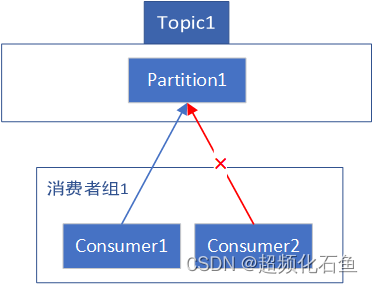
Kafka基本概念
什么是Kafka Kafka是一个消息系统。它可以集中收集生产者的消息,并由消费者按需获取。在Kafka中,也将消息称为日志(log)。 一个系统,若仅有一类或者少量的消息,可直接进行发送和接收。 随着业务量日益复杂,消息的种类…...

使用QueryBuilders、NativeSearchQuery实现复杂查询
使用QueryBuilders、NativeSearchQuery实现复杂查询 本文继续前面文章《ElasticSearch系列(二)springboot中集成使用ElasticSearch的Demo》,在前文中,我们介绍了使用springdata做一些简单查询,但是要实现一些高级的组…...

taobao.open.account.update( Open Account数据更新 )
¥开放平台免费API不需用户授权 Open Account数据更新 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 响应参数 点击获取key和secret 请求示例 TaobaoClient client new DefaultTaobaoClient(url, appkey, sec…...
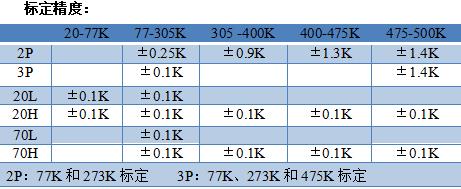
PT100铂电阻温度传感器
PT100温度传感器又叫做铂热电阻。 热电阻是中低温区﹡常用的一种温度检测器。它的主要特点是测量精度高,性能稳定。其中铂热电阻的测量精确度是﹡高的,它不仅广泛应用于工业测温,而且被制成标准的基准仪。金属热…...

蓝桥杯-本质上升序列
没有白走的路,每一步都算数🎈🎈🎈 题目描述: 小蓝特别喜欢单调递增的事物 在一个字符串中如果取出若干个字符,按照在原来字符串中的顺序排列在一起,组成的新的字符串如果是单调递增的…...

synchronized锁重入验证
文章目录synchronized锁重入验证1. 可重入锁2. synchronized锁重入2.1 本类同步方法内部调用本类其它同步方法2.2 子类同步方法内部调用父类的同步方法2.3 A类的同步方法内部调用B类的同步方法3. synchronized修饰方法写法synchronized锁重入验证 1. 可重入锁 可重入锁&#…...

超简单的计数排序!!
假设给定混乱数据为:3,0,1,3,6,5,4,2,1,9。 下面我们将通过使用计数排序的思想来完成对上面数据的排序。(先不谈负数) 计数排序 该排序的思路和它的名字一样…...

发现新大陆——原来软件开发根本不需要会编码(看我10分钟应用上线)
目录 一、前言 二、官网基础功能及搭建 三、体验过程 01、连接数据源 02、设计表单 03、流程设计 04、图表呈现 05、组织架构设置 五、效率评价 六、小结 一、前言 众所周知,每家公司在发展过程中都需要构建大量的内部系统, 如运营使用的用户…...

【Leedcode】栈和队列必备的面试题(第二期)
【Leedcode】栈和队列必备的面试题(第二期) 文章目录【Leedcode】栈和队列必备的面试题(第二期)一、题目(用两个队列实现栈)二、思路图解1.定义两个队列2.初始化两个队列3.往两个队列中放入数据4.两个队列出…...

别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器
别再手动写滤波器了!用Simulink DSP工具箱5分钟搞定一个可调带宽IIR滤波器 信号处理工程师的日常工作中,滤波器设计是个绕不开的话题。无论是音频处理、通信系统还是生物医学信号分析,我们总需要根据不同的应用场景调整滤波器参数。传统方法中…...

HLS技术解析:从原理到FPGA开发实战
1. HLS技术概述与评估背景高等级综合(High-Level Synthesis, HLS)技术正在重塑FPGA开发范式。作为从业十年的硬件加速工程师,我见证了这项技术从实验室走向工业界的全过程。传统RTL开发需要手动编写每一行寄存器传输级代码,而HLS允许开发者用C等高级语言…...
)
别再为导入报错发愁了!手把手教你用Parasolid格式把SolidWorks模型完美导入Adams(附常见错误排查)
从SolidWorks到Adams的模型导入实战指南:避坑技巧与深度解析 在工程仿真领域,SolidWorks和Adams的组合堪称黄金搭档——前者负责精确建模,后者专精多体动力学分析。但这对"黄金组合"的第一次握手往往让工程师们抓狂:模型…...
)
第七届先进金属材料国际研讨会(AMM 2026)
第七届先进金属材料国际研讨会(AMM 2026) The 7th Intl Conference on Advanced Metallic Materials(AMM 2026) 2026年8月7-9日 中国昆明 📅 重要信息 会议官网:https://www.academicx.org/AMM/2026/ 会议时间:2026年8月7-9日 会议地点…...

毫米波雷达3D重建技术:挑战与RFconstruct系统创新
1. 毫米波雷达3D重建技术概述在自动驾驶感知系统中,毫米波雷达因其独特的物理特性正扮演着越来越关键的角色。与激光雷达和摄像头相比,工作在76-81GHz频段的毫米波雷达具有穿透雾霾、雨雪的能力,且不受光照条件影响,这使其成为全天…...

基于DS18B20与WipperSnapper的无代码物联网温度监测方案
1. 项目概述:当经典传感器遇上无代码物联网 在物联网和智能硬件的世界里,温度监测是一个永恒的基础需求。无论是想监控家里的温室环境、记录鱼缸水温,还是追踪服务器机柜的热量变化,你都需要一个可靠、精确且易于集成的温度传感器…...
)
2026山东大学软件学院项目实训(六)
一、基本信息组号:69组员:李重昊负责模块:AI 工作流 —— 图片收集节点二、任务概述在 LangGraph4j 工作流中完成图片收集节点开发,根据用户自然语言需求自动规划并收集网站所需图片,为后续提示词增强与代码生成提供素…...

tmphw16tc47
AgentMDT协作:多学科会诊前的信息整理能不能先交给 AI MDT 会诊前,技术系统最容易被抱怨的不是“模型不够聪明”,而是病历、检验、用药、既往记录分散在不同系统里,人工整理耗时且容易遗漏。本文只讨论技术架构和工程流程示例&am…...

多变量分数阶系统的频域分析与设计【附程序】
✨ 长期致力于多变量系统、频率域、分数阶PID控制、鲁棒控制、参数拟合、参数优化、工具箱、框图法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基…...

图记忆架构:用知识图谱增强AI智能体的长期记忆与推理能力
1. 项目概述:当记忆成为可编程的图最近在探索如何让AI应用真正“记住”复杂的上下文时,我遇到了一个非常有意思的项目:openclaw-memory-graphiti。这个名字听起来有点拗口,但拆解一下就能明白它的野心——“OpenClaw”可能是一个开…...