NoSQL 数据建模错误会降低性能
数据建模错误是破坏性能的最简单方法之一。当您使用 NoSQL 时,特别容易搞砸,(讽刺的是)NoSQL 往往用于对性能最敏感的工作负载。NoSQL 数据建模最初可能看起来非常简单:只需对数据进行建模以适应应用程序的访问模式。但实际上,说起来容易做起来难。
修复数据建模并不有趣,但它通常是一种不可避免的罪恶。如果您的数据建模从根本上来说效率低下,那么一旦扩展到某个临界点(根据您的特定工作负载和部署而变化),您的性能就会受到影响。即使您在最强大的基础设施上采用最快的数据库,除非您的数据建模正确,否则您将无法充分发挥其潜力。
本文探讨了破坏 NoSQL 数据库性能的三种最常见方法,以及有关如何避免或解决这些问题的提示。
不处理大分区
当团队扩展其分布式数据库时,通常会出现大型分区。大型分区是指变得太大以至于开始在集群副本中引入性能问题的分区。
我们经常听到的问题之一(至少每月一次)是“什么构成了大分区?” 这得看情况。需要考虑的一些事项:
-
延迟预期:分区越大,检索所需的时间就越长。考虑页面大小以及完全扫描分区所需的客户端-服务器往返次数。
-
平均有效负载大小:较大的有效负载通常会导致较高的延迟。它们需要更多的服务器端处理时间来进行序列化和反序列化,并且还会产生更高的网络数据传输开销。
-
工作负载需求:某些工作负载自然需要比其他工作负载更大的负载。例如,我曾与一家 Web3 区块链公司合作,该公司将多个交易存储为单个密钥下的 BLOB,并且每个密钥的大小很容易超过 1 MB。
-
如何从这些分区中读取:例如,时间序列用例通常具有时间戳集群组件。在这种情况下,从特定时间窗口读取将检索到的数据比扫描整个分区要少得多。
下表说明了大分区在不同负载大小(例如 1、2 和 4 KB)下的影响。
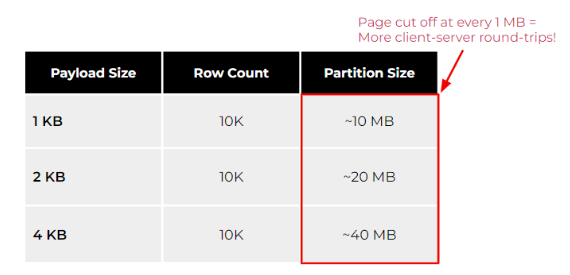
正如您所看到的,在相同的行数下,您的有效负载越高,您的分区就越大。但是,如果您的用例经常需要扫描整个分区,那么请注意数据库有限制以防止无限制的内存消耗。例如,ScyllaDB 每 1MB 就切断页面,以防止系统可能耗尽内存。其他数据库(甚至是关系数据库)也有类似的保护机制,以防止无限的错误查询导致数据库资源匮乏。要使用 ScyllaDB 检索 4KB 的负载大小和 10K 行,您需要检索至少 40 个页面才能使用单个查询扫描分区。乍一看这似乎没什么大不了的。但是,随着时间的推移进行扩展,它可能会影响整体客户端尾部延迟。
另一个考虑因素:对于 ScyllaDB 和 Cassandra 等数据库,写入数据库的数据存储在提交日志中和称为“memtable”的内存数据结构下。

提交日志是一种预写日志,除非服务器崩溃或服务中断,否则永远不会真正读取它。由于内存表存在于内存中,因此它最终会变满。为了释放内存空间,数据库将内存表刷新到磁盘。该过程会产生 SSTable(排序字符串表),这就是数据持久化的方式。
这一切与大分区有什么关系?嗯,SSTables 有特定的组件,需要在数据库启动时保存在内存中。这可确保读取始终高效,并最大限度地减少查找数据时存储磁盘 I/O 的浪费。当您拥有非常大的分区时(例如,我们最近有一个用户在 ScyllaDB 中拥有 2.5 TB 的分区),这些 SSTable 组件会带来沉重的内存压力,从而缩小数据库的缓存空间并进一步限制延迟。
如何通过数据建模解决大型分区问题?基本上,是时候重新考虑你的主键了。主键决定数据如何在集群中分布,从而提高性能和资源利用率。一个好的分区键应该具有高基数和大致均匀的分布。例如,用户名、用户 ID 或传感器 ID 等高基数属性可能是一个很好的分区键。像“州”这样的州将是一个糟糕的选择,因为加利福尼亚州和德克萨斯州等州可能比怀俄明州和佛蒙特州等人口较少的州拥有更多的数据。
或者考虑这个例子。下表可用于具有多个传感器的分布式空气质量监测系统:
CREATE TABLE air_quality_data (sensor_id text,time timestamp,co_ppm int,PRIMARY KEY (sensor_id, time));
由于时间 是我们表的聚类键,因此很容易想象每个传感器的分区可能会变得非常大,特别是如果每几毫秒收集一次数据。这张看似无辜的桌子最终可能会变得无法使用。在此示例中,仅需要大约 50 天。
标准解决方案是修改数据模型以减少每个分区键的集群键数量。在这种情况下,我们来看看更新后的`air_quality_data`表:
CREATE TABLE air_quality_data (sensor_id text,date text,time timestamp,co_ppm int,PRIMARY KEY ((sensor_id, date), time));
更改后,一个分区保存一天收集的值,这使得它不太可能溢出。这种技术称为分桶,因为它允许我们控制分区中存储的数据量。
热点介绍
热点可能是大分区的副作用。如果您有一个大分区(存储大部分数据集),那么您的应用程序访问模式很可能会比其他分区更频繁地访问该分区。既然如此,它也成为热点。
只要有问题的数据访问模式导致集群中的数据访问方式不平衡,就会出现热点。罪魁祸首之一是应用程序未能对客户端施加任何限制,并允许租户潜在地向给定的密钥发送垃圾邮件。例如,考虑一下消息应用程序中的机器人经常在频道中发送垃圾邮件。不稳定的客户端配置也可能以重试风暴的形式引入热点。也就是说,客户端尝试查询特定数据,在数据库超时之前超时,并在数据库仍在处理前一个查询时重试查询。
监控仪表板应该可以让您轻松找到集群中的热点。例如,此仪表板显示分片 20 因读取而不堪重负。

再举一个例子,下图显示了三个利用率较高的分片,这与为相关键空间配置的三个分片的复制因子相关。

在这里,由于垃圾邮件,分片七引入了更高的负载。
如何解决热点问题?首先,在受影响的节点之一上使用供应商实用程序来对采样期间最常点击的键进行采样。您还可以使用跟踪(例如概率跟踪)来分析哪些查询正在命中哪些分片,然后从那里采取行动。
如果您发现热点,请考虑:
-
检查您的应用程序访问模式。您可能会发现需要更改数据建模,例如前面提到的分桶技术。如果需要排序,可以使用单调递增组件,例如 Snowflake。或者,也许最好应用并发限制器并限制潜在的不良行为者。
-
指定每个分区的速率限制,之后数据库将拒绝命中同一分区的任何查询。
-
确保客户端超时 高于服务器端超时,以防止客户端在服务器有机会处理查询之前重试查询(“重试风暴”)。
滥用集合
团队并不总是使用集合,但当他们使用集合时,他们经常会错误地使用它们。集合用于存储/反规范化相对少量的数据。它们本质上存储在单个单元中,这会使序列化/反序列化变得极其昂贵。
使用集合时,您可以定义相关字段是冻结还是非冻结。冻结集合只能作为一个整体来写;您不能从中添加或删除元素。可以附加非冻结集合,而这正是人们最常误用的集合类型。更糟糕的是,您甚至可以拥有嵌套集合,例如一个地图包含另一个地图,其中包含一个列表,等等。
例如,误用的集合会比大分区更快地引入性能问题。如果您关心性能,集合根本不能太大。例如,如果我们创建一个简单的键:值表,其中键是` sensor_id`,值是随时间记录的样本集合,那么一旦开始提取数据,我们的性能将不是最佳的。
CREATE TABLE IF NOT EXISTS {table} (sensor_id uuid PRIMARY KEY,events map<timestamp, FROZEN<map<text, int>>>,)
以下监视快照显示了当您尝试一次将多个项目追加到集合时会发生什么情况。
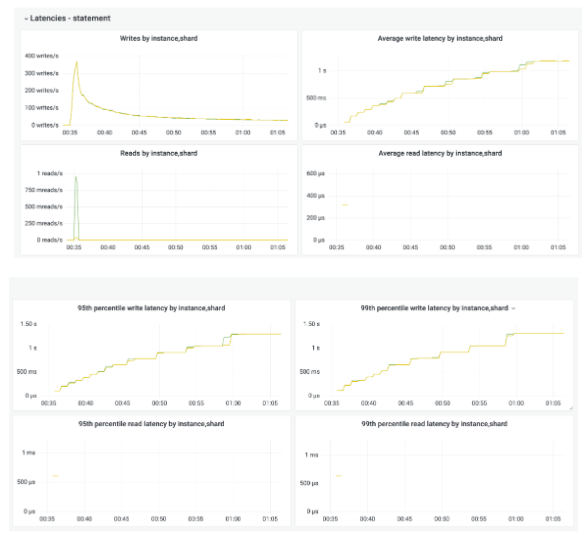
您可以看到,虽然吞吐量下降,但 p99 延迟却增加。为什么会出现这种情况?
-
集合单元作为排序向量存储在内存中。
-
添加元素需要合并两个集合(旧的和新的)。
-
添加元素的成本与整个集合的大小成正比。
-
树(而不是向量)会提高性能,但是......
-
树会降低小集合的效率!
返回同一示例,解决方案是将时间戳移动到聚类键并将映射转换为 FROZEN 集合(因为您不再需要向其中附加数据)。这些非常简单的更改将极大地提高用例的性能。
CREATE TABLE IF NOT EXISTS {table} (sensor_id uuid,record_time timestamp,events FROZEN<map<text, int>>,PRIMARY KEY(sensor_id, record_time))
作者:Felipe Mendes
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。
相关文章:
NoSQL 数据建模错误会降低性能
数据建模错误是破坏性能的最简单方法之一。当您使用 NoSQL 时,特别容易搞砸,(讽刺的是)NoSQL 往往用于对性能最敏感的工作负载。NoSQL 数据建模最初可能看起来非常简单:只需对数据进行建模以适应应用程序的访问模式。但…...
在Android上搭建一个NDK项目
首先New Project,选择Native C,点击Next。 填入项目名称和包名,点击Next。 这里我们选择Cmake默认的C版本。 创建好的项目目录,里面比我们正常的Android项目多了一个cpp目录 打开MainActivity。里面定义了一个jni方法stringFromJN…...
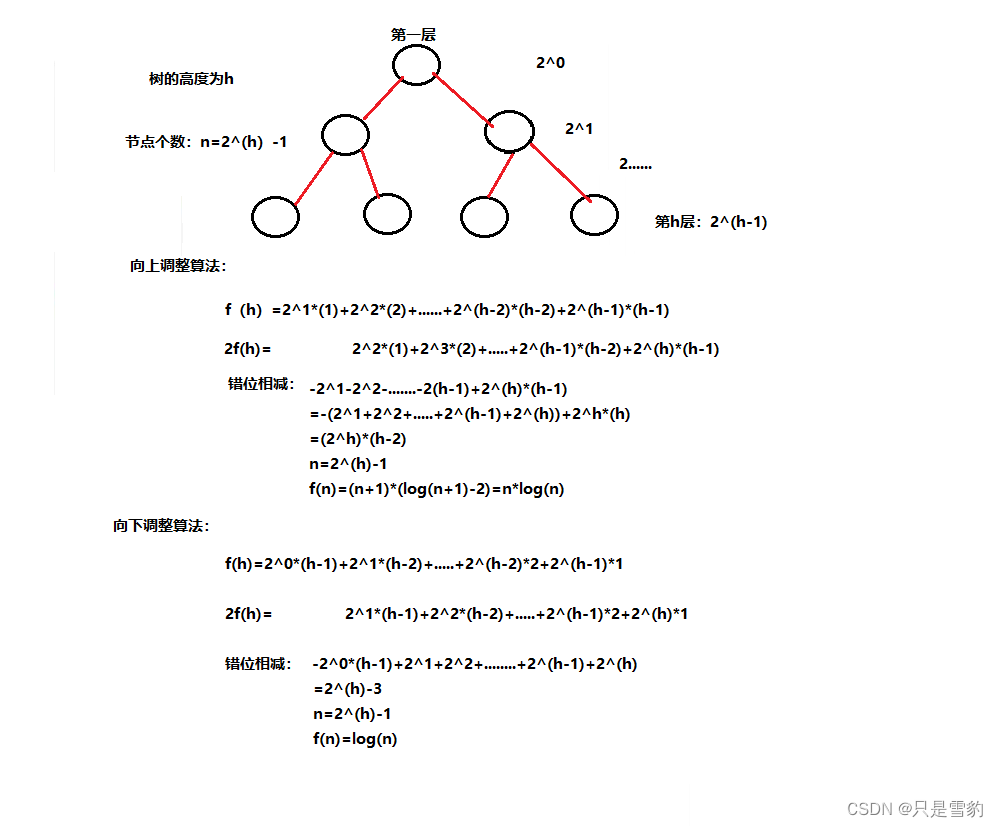
TOP-K问题和向上调整算法和向下调整算法的时间复杂度问题的分析
TOP-K问题 TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大 比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等 对于Top-K问题,能想到的最简单直接的方式就是排序,但是…...

3、服务器性能剖析
性能优化简介 **我们将性能定义为完成某件任务所需要的时间度量,换句话说,性能即响应时间,这是一个非常重要的原则。**我们通过任务和时间而不是资源来测量性能。数据库服务器的目的是执行sql语句,所以他关注的任务是查询或者语句…...

xxl-job 分布式任务调度框架
文章目录 分布式任务调度XXL-Job 简介XXL-Job 环境搭建XXL-Job (源码说明)配置部署调度中心docker安装 Bean模式任务(方法形式)-入门案例任务详解任务详解-执行器任务详解-基础配置任务详解-调度配置任务详解-基础配置任务详解-阻塞处理策略任务详解-路由策略 路由策略路由策略…...

软件使用-stm32入门
这节主要是介绍大家使用两个软件。这两个软件也是比较常用的,里面也有很多有意思的功能,可以给大家介绍一下。 1. FlyMcu 软件 这个软件可以通过串口给 STM32 下载程序,如果你没有 STLINK,就可以用这个软件通过串口下载程序。 …...
使用MAT分析内存泄漏(mac)
前言 今天主要简单分享下Eclipse的Memory Analyzer在mac下的使用。 一、Mat(简称)干什么的? 就是分析java内存泄漏的工具。 二、使用步骤 1.下载 mac版的现在也分芯片,别下错了。我这里是M2芯片的,下载的Arch64的。 …...
【Vue】Linux 运行 npm run serve 报错 vue-cli-service: Permission denied
问题描述 在Linux系统上运行npm run serve命令时,控制台报错: sudo npm run serve project50.1.0 serve vue-cli-service serve sh: 1: vue-cli-service: Permission denied错误截图如下: 原因分析 该错误是由于vue-cli-service文件权限不…...
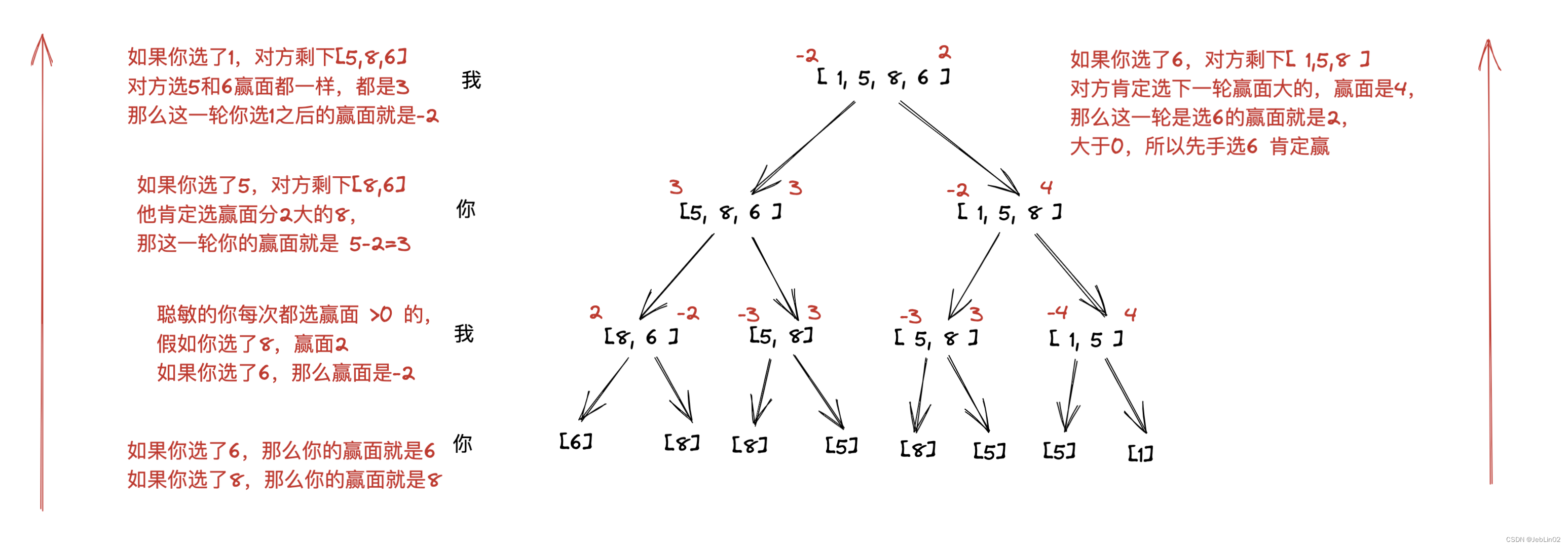
LeetCode的几道题
一、捡石头 292 思路就是: 谁面对4块石头的时候,谁就输(因为每次就是1-3块石头,如果剩下4块石头,你怎么拿,我都能把剩下的拿走,所以你就要想尽办法让对面面对4块石头的倍数, 比如有…...

NLP/Natural Language Processing
一、NLP是什么 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,也就是人们常说的「自然语言处理」,就是研究如何让计算机读懂人类语言,即将人的自然语言转换为计算机可以阅读的指令。它研…...
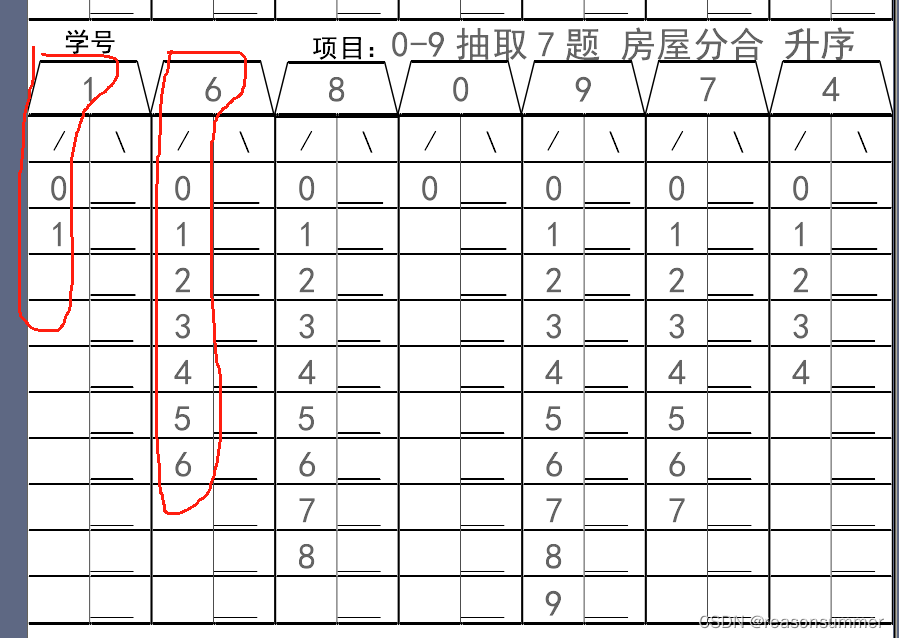
【教学类-06-12】20231202 0-9数字分合-房屋样式(一)-下右空-升序-抽7题
作品展示-屋顶分合(0-9之间随机抽取7个不重复分合) 背景需求: 大班幼儿学分合题,通常区角里会设计一个“房屋分合”的样式 根据这种房屋样式,设计0-9内的升序分合题模板 素材准备 WORD样式 代码展示: 2-9…...
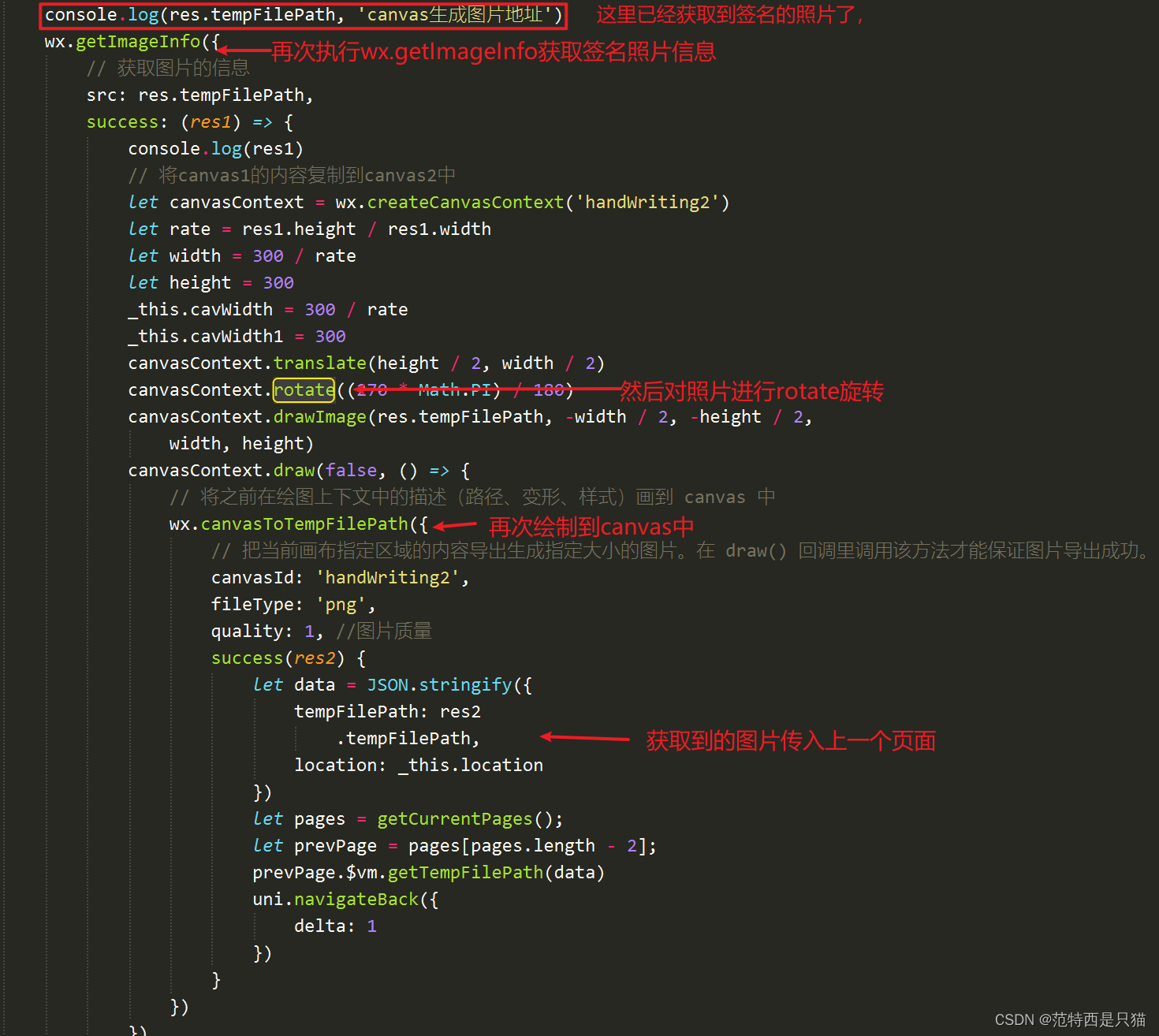
uni-app 微信小程序 电子签名及签名图片翻转显示功能
文章目录 1. 需求背景2. 开始撸2.1 点击 重写 进入签名页面(上图一)2.2 书写签名,点击确认返回,及图片翻转显示(上图二,三) 3. 图片进行翻转,返回翻转后的图片 1. 需求背景 接的一个…...

MySQL 8.0关键字和保留字
官网地址: https://dev.mysql.com/doc/refman/8.0/en/keywords.html 可以粘贴出去自己排版整理 {accessible} {account} {action} {active} {add} {admin} {after} {against} {aggregate} {algorithm} {all} {alter} {always} {analyse} {analyze} …...

PyLMKit(3):基于角色扮演的应用案例
角色扮演应用案例RolePlay 0.项目信息 日期: 2023-12-2作者:小知课题: 通过设置角色模板并结合在线搜索、记忆和知识库功能,实现典型的对话应用功能。这个功能是大模型应用的基础功能,在后续其它RAG等功能中都会用到这个功能。功…...

JAVA全栈开发 集合详解(day14+day15汇总)
一、数组 数组是一个容器,可以存入相同类型的多个数据元素。 数组局限性: 长度固定:(添加–扩容, 删除-缩容) 类型是一致的 对象数组 : int[] arr new int[5]; … Student[] arr …...
Linux Spug自动化运维平台本地部署与公网远程访问
文章目录 前言1. Docker安装Spug2 . 本地访问测试3. Linux 安装cpolar4. 配置Spug公网访问地址5. 公网远程访问Spug管理界面6. 固定Spug公网地址 前言 Spug 面向中小型企业设计的轻量级无 Agent 的自动化运维平台,整合了主机管理、主机批量执行、主机在线终端、文件…...

zookeeper集群和kafka集群
(一)kafka 1、kafka3.0之前依赖于zookeeper 2、kafka3.0之后不依赖zookeeper,元数据由kafka节点自己管理 (二)zookeeper 1、zookeeper是一个开源的、分布式的架构,提供协调服务(Apache项目&…...
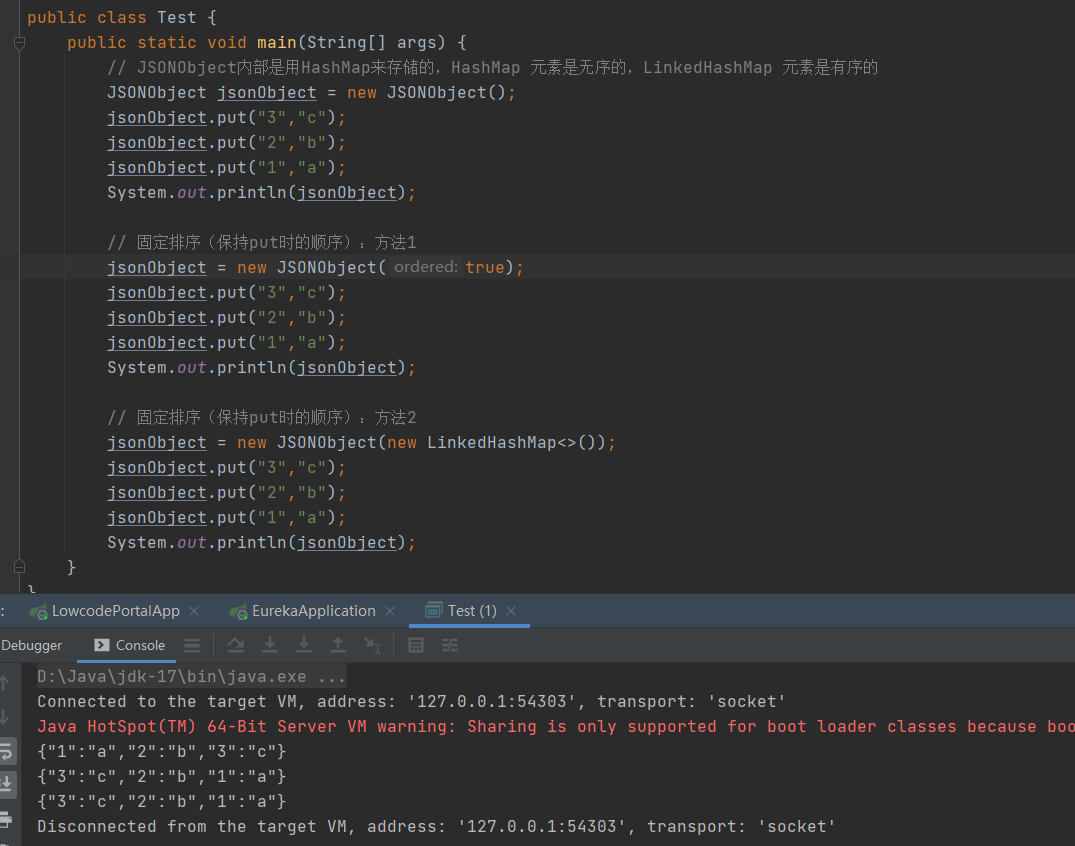
Java——》JSONObjet 数据顺序
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

【个人记录】NGINX反向代理grpc服务
最开始使用proxy_pass去代理了grpc服务,结果请求时候报错提示: rpc error: code Unavailable desc connection error: desc "error reading server preface: http2: frame too large"后来才知道代理grpc服务需要使用grpc_pass,…...

【小白推荐】安装OpenCV4.8 系统 Ubuntu 22.04LST Linux.
先看一下目录,知道大致的流程! 文章目录 安装OpenCV安装依赖下载源码配置与构建安装 测试编写CMakeListx.txt编写测试代码 安装OpenCV 安装依赖 sudo apt update && sudo apt upgrade sudo apt install cmake ninja-build build-essential lib…...

2026 年,DD4 内存条平台为何仍备受关注?
在内存技术飞速发展的今天,DDR5内存条逐渐成为了市场的主流。然而,令人意外的是,DDR4内存条平台在2026年仍然备受关注。究竟是什么原因让DDR4内存条在新时代依然占据一席之地呢?本文将从多个角度为您深入剖析。一、性价比之选对于…...

通用物体识别-ResNet18镜像5分钟快速部署:零基础搭建AI图像分类服务
通用物体识别-ResNet18镜像5分钟快速部署:零基础搭建AI图像分类服务 1. 引言:为什么选择ResNet-18进行物体识别? 在当今AI技术快速发展的时代,图像分类已经成为许多应用的基础功能。但对于初学者和中小型企业来说,部…...

量化交易开发实战指南:从入门到部署
量化交易开发实战指南:从入门到部署 【免费下载链接】StockSharp Algorithmic trading and quantitative trading open source platform to develop trading robots (stock markets, forex, crypto, bitcoins, and options). 项目地址: https://gitcode.com/gh_mi…...

Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流
Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

新手零代码入门:用快马ai一键生成vmware虚拟机图文安装教程
新手零代码入门:用快马AI一键生成VMware虚拟机图文安装教程 最近在学网络安全和Linux系统,第一步就是要搭建虚拟机环境。作为完全没接触过虚拟化技术的小白,我原本以为安装VMware会很复杂,结果发现用InsCode(快马)平台的AI功能&a…...

CA6140车床杠杆831009钻M6孔夹具设计全套带图
CA6140车床作为机械加工领域的经典设备,其杠杆零件(编号831009)的加工精度直接影响整机性能。针对该零件M6螺纹孔的加工需求,专用夹具的设计需兼顾定位稳定性、操作便捷性与加工经济性。通过分析零件结构可知,杠杆两端…...

AI辅助开发新范式:让快马AI成为你的智能代码库与协作者
最近在整理自己的代码库时,发现一个痛点:随着项目积累,很多实用的代码片段散落在各处,虽然写了注释,但时间久了还是很难快速找到需要的部分。于是萌生了一个想法——开发一个AI辅助的代码片段管理工具。这个工具不仅能…...

DVWA SQL 注入:两种查表字段 Payload 结果差异详解
一、问题引入在 DVWA Medium 级别 SQL 注入实验中,我们通过 Burp Suite 抓包改包,对users表字段进行查询时,会遇到两种看似不同的执行结果:图 1:逐行展示users表的每一个字段名图 2:一行展示user表的所有字…...

3步解决视频转PPT难题:智能幻灯片提取工具全攻略
3步解决视频转PPT难题:智能幻灯片提取工具全攻略 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字化学习与办公场景中,从视频中提取PPT内容一直是效率瓶…...

《数字图像处理》实战:从傅里叶到小波,解锁图像变换的时空密码
1. 图像变换的时空密码:从傅里叶到小波 当你用手机拍摄一张照片时,是否想过这张看似简单的图片背后隐藏着怎样的数学奥秘?图像处理领域的变换技术就像是一把钥匙,能够解开图像中隐藏的时空密码。在众多变换方法中,傅里…...