Redis RDB
基于内存的 Redis, 数据都是存储在内存中的。 那么如果重启的话, 数据就会丢失。 为了解决这个问题, Redis 提供了 2 种数据持久化的方案: RDB 和 AOF。
RDB 是 Redis 默认的持久化方案。当满足一定条件的时候, 会把当前内存中的数据写入磁盘, 生成一个快照文件 dump.rdb。Redis 重启会通过加载 dump.rdb 文件恢复数据。
1 触发 RDB 的方式
1.1 RDB 文件相关的配置
dir ./ # RDB 文件路径, 默认在启动目录下
dbfilename dump.rdb # REB 文件名称
rdbcompression yes # 开启 LZF 压缩, 这样可以节省存储空间, 但是会消耗一些 CPU 的计算时间, 默认开启
rdbchecksum yes # 使用 CRC64 算法来进行数据校验, 但是这样会增加大约 10% 的性能消耗, 默认开启stop-writes-on-bgsave-error yes # 在 RDB 持久化操作失败时, Redis 则会停止接受更新操作, 让用户知道异常的出现, 否则无感知的话, 会造成大的存储问题, 默认开启
以上是 RDB 开启的默认一些配置, 在这些配置的基础下, 有 2 种方式可以触发 RDB 的进行, 也就是数据持久化的触发。
1.2 通过配置规则触发
在 redis.conf 的 SNAPSHOTING 配置中, 定义了触发把数据保存到磁盘的触发频率 (如果不需要 RDB 默认方案, 注释掉 save 或配置成空字符串 “” 即可)。
save 900 1 # 900 秒内至少有一个 key 被修改 (包括添加)
save 300 10 # 300 秒内至少有 10 个 key 被修改
save 60 100 # 60 秒内至少有 100 个 key 被修改
上面的配置是不冲突的, 只要满足任意一个都会触发。
1.3 通过命令触发
Redis 提供了 2 条命令 save 和 bgsave 可以用来手动触发数据保存。
save: 在生成快照的时候会阻塞当前 Redis 服务器, Redis 不能处理其他命令。如果内存中的数据比较多, 会造成 Redis 长时间阻塞。 生产中不建议使用这个命令。
bgsave: Redis 进程通过 fork 函数, 创建出一个子进程 (copy-on-write)。 RDB 持久化过程由子进程负责, 完成后自动结束。它不会记录 fork 之后的命令, 阻塞只发生在 fork 阶段, 一般时间很短。
Redis 提供了 lastsave 命令, 用来查看最近一次生成快照的时间。
当然通过 shutdown 命令关闭 Redis, 也会触发 RDB 持久化的发生, 以确保服务器正常关闭和后面启动数据能正常准确地重新加载。
2 RDB 文件的优势和劣势
优势
- RDB 是一个非常紧凑 (compact) 的文件, 它保存了 Redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复
- 生成 RDB 文件的时候, Redis 进程会 fork 一个子进程来处理所有的保存工作, 主进程不需要进行任何磁盘 IO 操作
- RDB 在恢复大数据集时的速度比 AOF 恢复速度快
劣势
- RDB 方式数据没办法做到实时持久化或秒级持久化。因为 bgsave 每次运行都要执行 fork 函数, 创建子进程, 频繁执行成本高
- 在一定间隔时间做一次备份, 所以如果 Redis 意外 down 掉的话, 就会丢失最后一次快照之后的修改 (数据丢失)
如果数据相对来说比较重要, 希望将损失降到最小, 则可以使用 AOF 方式进行持久化。
3 RDB 持久化的过程
- 配置的规则条件达到或者收到了 bgsave / save 命令, 持久化开始
- 主进程通过 fork 函数, 创建出一个子进程
- 父进程进行一些统计状态和指标的保存, 然后可以进行处理其他的命令
- fork 出的子进程, 创建出一个临时文件, 将数据库中的数据写入到临时文件中
- 整个数据库的数据都写入完成了, 通过 rename 函数将临时文件命名为配置的 RDB 文件名 (如果重命名的文件已经存在, 会先被删除, 再进行重命名)
- 子进程在 RDB 文件持久完成后, 把持久化中的一些信息通知给父级, 然后退出子进程, 整个持久化就完成了
到此, RDB 的理论知识就没了, 下面是从源码进行分析。
注: 下面的分析都是以 Redis 5.x 版本进行分析的, 跨大版本可能会有一些不一样。
4 RDB 文件结构
要了解 RDB 的过程, 其中有一个绕不开的点: RDB 文件的结构。

如图是 RDB 的逻辑文件结构 (当前这个图片中显示的结构和真正的 RDB 文件有些差距的, 但是差距不大), 整个文件的内容如下:
- REDIS, 文件开头的前 5 个字符的内容固定为 REDIS, 占用 5 个字节, 标识这是一个 Redis 可以处理的文件
- RDB_VERSION, 标识当前的 RDB 文件的版本号, 占用 4 个字节
- AUX_FIELD_KEY_VALUE_PAIRS, 这个属性不是简单的属性, 可以看成是 8 个 key-value 公共组成的一个属性值
- 3.1. key 为 redis-ver, value 为当前 Redis 的版本, 比如 5.0.0 版本
- 3.2. key 为 redis-bit, value 为当前 Redis 的位数, 64 位 / 32 位
- 3.3. key 为 ctime, value 为 RDB 创建时的时间戳
- 3.4. key 为 used-mem, value 为 dump 时 Redis 占的内存, 单位字节
- 3.5. key 为 repl-steam-db, 和主从复制相关, 在 server.master 客户端中选择的数据库, 这个不一定有, 只有在当前的 RDB 文件是用作主从复制时才有值, 数据持久化时, 没有这个属性
- 3.6. key 为 repl-id, 和主从复制相关, 当前实例 replication ID, 这个不一定有, 只有当前的 RDB 文件是用作主从复制时, 不是数据持久化时, 才有
- 3.7. key 为 repl-offset, 和主从复制相关, 当前实例复制的偏移量, 这个不一定有, 只有当前的 RDB 文件是用作主从复制时, 不是数据持久化时, 才有
- 3.8. key 为 aof-preamble, value 为是否开启了 aof/rdb 的混合使用
- DB_NUM, 当前后面的数据是存储在哪个数据库的, Redis 中有 16 个数据库
- DB_DIC_SIZE, 当前数据库键值对散列表的大小。Redis 的每个数据库是一个散列表, 这个字段指明当前数据库散列表的大小。这样在加载时可以直接将散列表扩展到指定大小, 提升加载速度
- EXPIRE_DIC_SIZE, 当前数据库过期时间散列表的大小。Redis 数据的过期时间也是保存为一个散列表, 该字段指明当前数据库过期时间散列表的大小
- KEY_VALUE_PAIRS, 这个部分就是 Redis 中真正存储的数据了
我们知道 Redis 中有 16 个数据库, 所以在多个数据库都有数据的情况下, 第四, 五, 六, 七这 4 个部分可能有多套的。 - 固定为 EOF, 一个常量, 文件结束标志
- CHECK_NUM, 8 字节的校验码, 用来确保文件的正确性
这 9 个部分就是 RDB 文件的内容了。
从上图中, 我们还可以知道, RDB 文件中的 KEY_VALUE_PAIRS 中, 实际存储了多个 KEY_VALUE_PAIR。 这些键值对就是我们存储在 Redis 里面的数据。
而我们存储在 Redis 里面的键值对除了单纯的 key-value 外, 还包含了其他的信息, 比如过期时间, 过期策略等。
所以代表真正数据的 KEY_VALUE_PAIR 可以划分出 5 部分
- EXPIRE_TIME, 当前这个键值对过期时间, 占 8 个字节, 如果 key 没有过期时间, 这一项可以没有
- LRU 或 LFU, 当前这个键值对过期的方式, 同样是可选项, 如果 key 没有过期配置, 这一项也可以没有
- VALUE_TYPE, 当前这个键值对的值的存储类型, 比如是字符串, 整数, 列表等, 取值看下面
- KEY, 键值对的 KEY 值
- VALUE, 键值对的 VALUE 值
VALUE_TYPE 就是存储 VALUE 的类型, 具体的取值如下
#define RDB_TYPE_STRING 0
#define RDB_TYPE_LIST 1
#define RDB_TYPE_SET 2
#define RDB_TYPE_ZSET 3
#define RDB_TYPE_HASH 4
#define RDB_TYPE_ZSET_2 5
#define RDB_TYPE_MODULE 6
#define RDB_TYPE_MODULE_2 7
#define RDB_TYPE_HASH_ZIPMAP 9
#define RDB_TYPE_LIST_ZIPLIST 10
#define RDB_TYPE_SET_INTSET 11
#define RDB_TYPE_ZSET_ZIPLIST 12
#define RDB_TYPE_HASH_ZIPLIST 13
#define RDB_TYPE_LIST_QUICKLIST 14
#define RDB_TYPE_STREAM_LISTPACKS 15
这几个就是数据类型的定义
5 数据以什么格式存入二进制文件
在进入到 Redis 是如何写数据到 RDB 文件前, 我们先看一个例子吧。
将设现在我有一个备忘录, 里面有内容如下
123 4567 8900 (手机号码)
021-3000 9000 (座机号码)
123456789012345678 (18 位的身份证)
60606060606060606 (银行卡号, 17位, 银行卡实际的长度不定, 但是长度在 15-19 位之间)
现在需要将他们写入到一个文件中, 并且期望
- 尽可能的省空间
- 后面还能正常的读取出来
现在最直接的省空间的, 当然直接将他们拼接在一起, 最终就是这样了: 123 4567 8900021-3000 12345678901234567860606060606060606
但是后面的如何正确的读取呢? 我们先对备忘录里面的内容做个分类
- 普通的手机号码, 固定长度 13 位
- 座机号码, 固定长度 11 位
- 身份证号, 固定长度为 18 位
- 中国银行卡号, 长度不定, 但是长度在 15-19 位之间
概括为
- 内容的长度是固定的, 比如手机号 13 位, 身份证 18 位
- 内容长度是不固定的, 比如银行卡号
那么我们是否可以指定一个规则, 写入文件时, 备忘录的每一个内容前面都会加入一个数字, 每个数字都代表了一种内容格式
- 数字 1 表示后面的内容是手机号码, 长度固定为 13 位
- 数字 2 表示后面的内容是座机号, 长度固定为 11 位
- 数字 3 表示后面的内容为身份证号, 长度为 18 位
- 数字 4 表示后面的内容是特殊内容, 长度不确定
通过这个规则, 我们的内容变成 1123 4567 89002021-3000 90003123456789012345678460606060606060606
读取时, 我们都是先读取第一位, 确定后面的内容是什么, 得到需要读取多少位。
比如先读取到 1, 根据规则 1, 表示后面的内容为手机号, 需要一次性读取 13 位内容, 其他同理。
但是当读取到 4, 我们卡住了, 根据规则 4, 代表后面是特殊内容, 那需要读取多长的内容?
这时我们在指定一套表示整数的规则
数字 1 表示后面的内容的长度为 15
数字 2 表示后面的内容的长度为 16
数字 3 表示后面的内容的长度为 17
数字 4 表示后面的内容的长度为 18
数字 5 表示后面的内容的长度为 19
修改上面内容格式的规则, 将数字 4 修改为如下
- 数字 4 表示后面的内容是特殊内容, 同时后面会紧跟一个一位数的整数, 表示后面的内容的长度
最终通过修改后的规则, 我们的内容变成 1123 4567 89002021-3000 900031234567890123456784460606060606060606
这时按照规则读取到数字 4, 知道后面的内容为特殊内容, 需要在往后读取 1 位, 得到特殊内容的长度, 这时读取到 4, 根据整数规则, 得到长度为 17。
上面就是 Redis 以二进制存储数据到文件的大体思路, 只是他设计得更巧妙一下, 没那么粗暴。
总体就是确定内容的长度, 而在确定内容的长度, 有 2 种方式
- 内容的长度是定长的, 我们就给他制定特有的内容类型, 这个内容类型本身就代表了后面内容的长度
- 内容的长度是不定长的, 就通过自定义的一套整数规则, 在内容前面加上一个符合整数规则的数字, 表示内容的长度
5.1 自定义的整数的规则
备注: 下面二进制之间每 8 位就手动空了一个空格, 只是为了方便理解, 真正写入文件时, 中间是不会有空格的
在实际中, Reids 会将数据以二进制的形式写入到文件中, 格式可能如下
00010000 11000011 11011010 01010101 .....
在开始介绍 Redis 自定义的整数规则前, 先看一个 Redis 将数据写入文件的伪代码
public static void rdbSaveContentString(char[] content, long contentLength) {// 1. 数据的长度在 11 个字节以内 (int 最大值, 21 亿, 10 位数)if (contentLength < 11) {// 尝试转为 int 写入if (tryWriteIntegerContent(content, contentLength)) {return;}}// 2. 开启了 LZF 压缩算法, 同时数据长度大于 20 个字节if (server.rdb_compression && contentLength > 20) {saveLzfStringObject(content, contentLength);return;}// 3. 兜底writeContentLen(contentLength);writeContent(content, contentLength);
}
逻辑整理如下
- 输入的数据长度在 11 个字节内, 同时可以转为 int 时, 以整数 int的形式写入 rdb 文件
- 开启了 LZF 压缩功能, 同时数据长度在 20 个字节以上, 以LZF 压缩字符串的形式写入 rdb 文件
- 数据不能转为整数, 同时长度在 20 个字节内, 数据的长度在 11 到 20 个字节内或者没有开启 LZF 压缩功能, 以长度 + 数据的形式写入 rdb 文件
可以看到 Redis 对写入到 RDB 文件的数据有 3 中模式。
模式一
写入 RDB 文件的数据可以转为一个整数, 同时大小在 int 的取值范围内, 会以 **整数 int (这里可以看作是数据类型 + 内容模式)**的形式存储这个整数
长度的表示: 11|XXXXXX
1 11|000000 (十进制: 192), 表示后面的内容类型为 byte, 是一个长度为 1 个字节的整数
2 11|000001 (十进制: 193), 表示后面的内容类型为 short, 是一个长度为 2 个字节的整数
3 11|000010 (十进制: 194), 表示后面的内容类型为 int, 是一个长度为 4 个字节的整数
4 11|000011 (十进制: 195), 表示后面为 FASTLZ 压缩算法压缩的字符串, 后面分析
举个例子, 我们现在如果要向 RDB 文件写入内容: 10
- 内容 10 在程序中可以转为 1 个 byte 类型的 10 (00001010),
- byte 类型的数据, 只需要 1 个字节, 可以用 Redis 定义的整数规则 11|000000 表示其数据的长度, 最终写入到 RDB 文件就是 11000000 00001010
同理写入一个 257 (00000001 00000001), 需要用 2 个字节, 也就是 short 类型。可以用 11|000001 表示其数据的长度, 最终写入到 RDB 文件的就是 11000001 00000001 00000001
这个模式就是我们备忘录里面的 直接数据类型, 这个数据类型就直接表示后面数据长度的模式。
模式二
条件
- 数据不能转为整数, 同时长度在 20 个字节内, 比如 ’abc‘
- 数据的长度在 11 到 20 个字节之间 (也就是即使能转为整数, 但是整数大于 int 最大值, 也是按照这种方式处理), 比如 ‘abcdefghijkl’ 或 ‘2147483648’ (int 最大值 + 1)
- 没有开启 LZF 压缩功能
以长度 + 数据的形式存储数据
长度的表示有 4 种模式
- 00|XXXXXX => 1 个字节, 前 2 位固定为 00, 后面 6 位表示具体的数字, 最大值为 63, 也就是表示后面的数据长度为 64 个字节
- 01|XXXXXX XXXXXXXX => 2 个字节, 前 2 位固定为 01, 后面 14 位表示具体的数字, 最大值为 16383
- 10|000000 [32 bit integer] => 5 个字节, 前 8 位固定为 10000000, 后面 32 位表示具体的数字, int 的最大值
- 10|000001 [64 bit integer] => 9 个字节, 前 8 为固定为 10000001, 后面 64 位表示具体的数字, long 的最大值
举个例子, 我们现在如果要向 RDB 文件写入内容: a (a 不能转为整数, 所以跳过了模式一)
- a 本身只需要一个字节存储就行了, 也就是表示长度的规则, 可以选 00|000001, a 本身的二进制为 01100001 (ASCII 码, 二进制),
那么最终写入到 RDB 文件的数据就是 00000001 01100001
同理写入 65 个 ‘a’, 需要 65 个字节, 表示长度的规则为 01000000 01000001 (00|XXXXXX 模式不够了), 后面接着 65 个 a 的二进制。
这个模式就是我们备忘录里面的 内容类型 + 数据长度的模式 (内容长度, 看每个字节的前 2 位确定的)。
模式三
当 Redis 开启了 LZF 压缩功能时, 如果写入的数据的长度大于 20 个字节了, 会对存储的数据进行压缩后再存储,
存储的格式为: 11|000011 + 压缩后的长度 + 原始的数据长度 + 压缩后的数据, 模式一中的特殊模式。
看起来有点绕吧,做个总结, Redis 为了能将内容准确地存储下来, 定义了一套整数规则
- 11|XXXXXX => 表示整数编码
1.1 如果后面的 XXXXXX 6 位的值为 0, 表示后面的内容长度为 1 个字节, 也就是一个 byte 整数
1.2 如果后面的 XXXXXX 6 位的值为 1, 表示后面的内容长度为 2 个字节, 同时是一个 short 整数
1.3 如果后面的 XXXXXX 6 位的值为 2, 表示后面的内容长度为 4 个字节, 同时是一个 int 整数
1.4 如果后面的 XXXXXX 6 位的值为 3, 表示后面为 FASTLZ 压缩算法压缩的字符串, 特殊处理, 内容的格式为 11|000011 压缩后的长度 (长度用上面的规则进行表示) + 原始的数据长度 (同理) + 压缩后的数据*
- 00|XXXXXX => 1 个字节, 前 2 位固定为 00, 后面 6 位表示具体的数字, 最大值为 63, 表示后面紧接的内容长度
- 01|XXXXXX XXXXXXXX => 2 个字节, 前 2 位固定为 01, 后面 14 位表示具体的数字, 表示后面紧接的内容长度
- 10|000000 [32 bit integer] => 5 个字节, 前 8 位固定为 10000000, 后面 32 位表示具体的数字, 表示后面紧接的内容长度
- 10|000001 [64 bit integer] => 9 个字节, 前 8 为固定为 10000001, 后面 64 位表示具体的数字, 表示后面紧接的内容长度
在使用时, 可以直接根据第一个字节的前 2 位, 得到后面数据的解析方式。
5.2 操作码
在分析上面的 RDB 文件的逻辑结构中, 可以发现有一些属性, 在某些情况下是没有的, 这会造成什么问题呢?
顺着二进制文件一直读下去, 虽然数据解析出来了, 但是我们不知道这个数据是什么。
比如存储具体数据的 KEY_VALUE_PAIRS 中, 过期时间 EXPIRE_TIME 是可以没有的。
这时如果顺着二进制文件, 假设这时读取到了 6, 这个数字, 那么他是 KEY_VALUE_PAIRS 中的过期时间 EXPIRE_TIME, 还是键值对的数据类型 VALUE_TYPE (没有过期时间, 也就没有过期策略, 下一位就是键值值类型)。
为了应对这种不一定存在的情况, Redis 定义了一套 操作码, 通过操作码表示后面的数据是什么, 让解析出来的数据能真正赋值到对应的属性。
操作码:
| 变量名 | 取值 | 操作码后面数据的含义 |
|---|---|---|
| RDB_OPCODE_MODULE_AUX | 247 | module 相关辅助字段 |
| RDB_OPCODE_IDLE | 248 | lru 空闲时间 |
| RDB_OPCODE_FREQ | 249 | lfu 频率 |
| RDB_OPCODE_AUX | 250 | 辅助字段类型 |
| RDB_OPCODE_RESIZEDB | 251 | resized, 和 DB_DIC_SIZE 和 EXPIRE_DIC_SIZE 的散列表个数有个相关 |
| RDB_OPCODE_EXPIRETIME_MS | 252 | 毫秒级别过期时间 |
| RDB_OPCODE_EXPIRETIME | 253 | 秒级别过期时间 |
| RDB_OPCODE_SELECTDB | 254 | 数据库序号, 也就是 DB_NUM 项 |
| RDB_OPCODE_EOF | 255 | 结束标志, 即 EOF 项 |
5.3 例子
上面聊了 RDB 文件的逻辑结构, 自定义的整数规则和操作码, 这里就举一个例子, 结合起来理解一下 (括号内为说明, 对应的内容自行转为二进制)
如果这时如果直接打开了一个 RDB 文件, 对应的内容如下
01010010 01000101 01000100 01001001 01010011 (前 5 个字节, 固定为 REDIS 字符串的二进制)
00000000 00000000 00000000 00001001 (固定 4 个字节的 RDB 版本, Redis 5.0 版本中默认为 9)
11111010 (250, 操作码, 表示后面辅助字段)
00001001 (9, 整数规则: 00|XXXXXX, 表示后面辅助字段 key 的长度) redis-ver (这里没有转为二进制) 00000110 (6, 整数规则: 00|XXXXXX 表示后面辅助字段 value 的长度) 5.0.10(这里没有转为二进制)
11111010 (250, 操作码, 表示后面辅助字段)
00001010 (10, 整数规则: 00|XXXXXX, 辅助字段 key 的长度) redis-bits (这里没有转为二进制) 01000000 01000000 (64, 整数规则: 01|XXXXXX XXXXXXXX, redis-bits 后面的内容直接用整数表示即可)
11111010 (250, 操作码, 表示后面辅助字段)
00000101 (5, 整数规则: 00|XXXXXX) ctime (这里没有转为二进制) 11000010 (4, 整数规则: 11|XXXXXX) 00101111 11001001 10111100 01011111 (时间戳, 单位秒, 小端存储, 实际值: 1606207791)
其他的 AUX_FIELD_KEY_VALUE_PAIRS 键值对
11111001 (254, 操作码, 数据库序号项) 00000000 (0 号数据库, 因为 Redis 的数据库最多 16 个, 所以直接读取后面一个字节就行, 不需要自定义的整数规则)
11111011 (251, 操作码, RESIZED 项) 00000001 (1, 整数规则: 00|XXXXXX, 当前数据库键值对散列表只有 1 个) 00000010 (2, 整数规则: 00|XXXXXX, 当前数据库过期时间散列表有 2 个)
11111100 (252, 操作码, 毫秒级别过期时间项, 这一项不一定都有, 如果 key 没有过期配置, 这一项就没有的) 11101101 00001110 10111010 00111000 01110110 000000001 00000000 00000000 (固定的 8 个字节, 时间戳, 实际值: 1607269486317, 同样小端存储)
11111000 (248, 操作码, 过期策略, 这里也可能为 249) 00101111 11001001 10111100 01011111 00000000 00000000 00000000 00000000 (固定 8 个字节, 存储的是过期的时间, 单位秒, 如果配置是 lfu, 即 249, 则这个为 1 个字节, 表示引用次数, 取值为 0 - 255)
00000000 (0, 上面 RDB 文件结构中有说明, 存储到里面数据类型的取值, 这里 0, 表示为字符串) 00000010 (2, 整数规则: 00|XXXXXX, 后面 key 的长度) k1 00000010 (2, 整数规则: 00|XXXXXX, 后面 value 的长度) v1
11111111 (255, 操作码, 结束项)
000000001 00000000 00000000 00000000 00000000 00000000 00000000 (1, 固定 8 个字节, 文件的校验码)
上面的 KEY_VALUE_PAIRS 举的例子为 String 类型, 所以比较简单。
而实际中, Redis 在 KEY_VALUE_PAIR 还会根据不同的值类型, 内部会做一下优化。
不同的数据类型, 会有不同的编码进行数据的组织, 而有些编号会在前面先保存一个当前编码数据的节点数, 然后在保存数据。
比如 quicklist, 组织的方式如下: quicklist 中的节点数 | ziplist1 | ziplist2 | ziplist3, 多了一个节点数的字段。
有这种行为的有: dict, qicklist, skiplist 等
到此就是 RDB 文件的内容, 很绕。
6 代码实现
在日常的使用中, RDB 一般都是通过配置文件, 配置规则触发的, 那么以这个为入口开始分析。
6.1 配置规则封装对象
save 900 1 # 900 秒内至少有一个 key 被修改 (包括添加)
save 300 10 # 300 秒内至少有 10 个 key 被修改
save 60 100 # 60 秒内至少有 100 个 key 被修改
一般上面就是配置 RDB 的自动触发规则了, 每一条规则在代码中会被封装为如下一个对象
struct saveparam {// 秒数time_t seconds;// 修改的次数int changes;
};
6.2 RDB 相关的配置的存储
RDB 相关的配置的话, 比如是否启用, 是否使用压缩等, 都保存在 redisServer 这个结构体中
struct redisServer {.../** 上次保存后对数据库 key 的修改次数 */long long dirty; /** 用于在 BGSAVE 失败时, 恢复 dirty */long long dirty_before_bgsave; /** 保存 RDB 的子进程 ID */pid_t rdb_child_pid; /** 保存规则数组 */struct saveparam *saveparams; /** RDB 文件名, 默认为 dump.rdb */char *rdb_filename;/** 是否启用 LZF 压缩算法对 RDB 文件压缩, 默认 yes */int rdb_compression; /** 是否启用 RDB 文件校验, 默认 yes */int rdb_checksum; /** 上一次 save 成功的时间 */time_t lastsave; /** 上一次尝试 bgsave 的时间 */time_t lastbgsave_try; /** 上次 RDB save 使用的时间 */time_t rdb_save_time_last; /** 当前 RDB 开始 save 的时间 */time_t rdb_save_time_start; /** 激活的子进程当前执行的 RDB 类型 (Redis 主从复制也是有依赖 RDB 的), 当前的执行 RDB 是要写入磁盘, 还是写入 socket, 发送给从节点 */int rdb_child_type;/** 上次 bgsave 的执行结果 C_OK / C_ERR */int lastbgsave_status; /** 是否允许写入, 如果不能 BGSAVE, 则不允许写入 */int stop_writes_on_bgsave_err;/** 无磁盘同步, 通过管道向父级写数据 */int rdb_pipe_write_result_to_parent;/** 无磁盘同步, 通过管道从从节点读数据 */int rdb_pipe_read_result_from_child; ...}
6.3 功能的触发
要触发 RDB 的话, 可以通过 save 和 bgsave 2 个命令和配置的规则达到了。
虽然是不同的方式, 但是在底层最终还是走到了相同的方法, 所以这里以配置规则的方式进行讲解。
配置规则的触发同样是基于定时器的, 也就是 serverCron 这个 Redis 的定时函数。
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {// 前面代码省略// 判断后台是否正在进行 RDB 或者 AOF 操作或者还有子进程阻塞在父级if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 || ldbPendingChildren()) {// 代码省略} else {// 如果没有后台 RDB/AOF 在进行中, 进行检查是否需要立即开启 RDB/AOF// 遍历我们的触发规则列表for (j = 0; j < server.saveparamslen; j++) {// 配置规则struct saveparam *sp = server.saveparams+j;// 当前 Redis 中修改过的 key 的数量 > 规则配置的 key 修改数量值 并且 当前的时间 - 上次保存的时间 > 规则配置的时间频率 (配置的条件达到了)// 当前的时间 - 上次 bgsave 的时间 > 5 秒 或者 上次的 bgsave 为成功状态 (内部的判断条件)if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds && (server.unixtime - server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) {//记录日志serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);// rdbSaveIndo 用来存储从节点的信息// Redis 中主从节点的数据同步也有通过 RDB 的// 把数据保存为一个 RDB 文件, 发送给从节点, 我们这里研究的是主节点自身数据的保存, 所以这里把这里的逻辑省略rdbSaveInfo rsi, *rsiptr;rsiptr = rdbPopulateSaveInfo(&rsi);// 开始 RDB 数据保存rdbSaveBackground(server.rdb_filename,rsiptr);break;}// AOF 判断if (server.aof_state == AOF_ON && ... ) {// 代码省略}}}
}上面就是配置规则的触发了, 条件达到后, 最终会执行 rdbSaveBackground 函数。
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {pid_t childpid;long long start;// 再次判断是否有子线程在 RDB/ AOF if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR;// 保存当前的 dirty 到 dirty_before_bgsaveserver.dirty_before_bgsave = server.dirty;// 更新为当前的时间server.lastbgsave_try = time(NULL); // 打开一个父子通道, 用于将 RDB/AOF 保存过程中的信息从子进程移动到父级openChildInfoPipe();// 当前的时间start = ustime();// fork 一个子进程, 如果返回值是 0, 表示为子进程, 大于 0 表示为父进程, -1 则表示 fork 失败// fork 成功后, 子进程也会从这里继续执行// 这个 fork 操作, 可以理解为克隆, 从父类克隆了一个完全一样的子类, 克隆后子类持有和父类一样的数据if ((childpid = fork()) == 0) {// 子进程逻辑// 释放掉一些子进程不需要的资源closeClildUnusedResourceAfterFork();// 设置一个执行过程的标题redisSetProcTitle("redis-rdb-bgsave");// 调用 rdbSave 真正的执行 RDB 备份retval = rdbSave(filename,rsi);// 执行成功if (retval == C_OK) {// 计算当前进程使用了多少额外的内存size_t private_dirty = zmalloc_get_private_dirty(-1);if (private_dirty) {serverLog(LL_NOTICE, "RDB: %zu MB of memory used by copy-on-write", private_dirty/(1024*1024));}server.child_info_data.cow_size = private_dirty;// 将子进程的信息发送给父进程, 也就是拷贝到 server.child_info_pipe[2] 中sendChildInfo(CHILD_INFO_TYPE_RDB);}// 退出子进程exitFromChild((retval == C_OK) ? 0 : 1);} else {// 父进程逻辑// 父进程 fork 出子进程后, 就能继续执行自身的任务了// fork 消耗的时间server.stat_fork_time = ustime()-start;// 计算 fork 频率, 单位 GB/secondserver.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024);// 尝试添加延迟事件// 当后面的时间大于 server.latency_monitor_threshold, 会向 server.latency_events 添加一个延迟事件, 用于后面的延迟分析latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000);// fork 失败if (childpid == -1) {// 关闭父子通道closeChildInfoPipe();// 更新 上一次 bgsave_status 为失败状态server.lastbgsave_status = C_ERR;serverLog(LL_WARNING,"Can't save in background: fork: %s", strerror(errno));// 返回错误码return C_ERR;}serverLog(LL_NOTICE,"Background saving started by pid %d",childpid);// RDB 开始的时间server.rdb_save_time_start = time(NULL);// 子进程的进程 IDserver.rdb_child_pid = childpid;// RDB 类型为写入磁盘类型server.rdb_child_type = RDB_CHILD_TYPE_DISK;// 更新全局的 dict.dict_can_resize 进行字典扩容的控制, 控制存储数据的 dict 扩容updateDictResizePolicy();return C_OK;}}/*** 更新 dict 的扩容行为*/
void updateDictResizePolicy(void) {// 当前的没有 rdb 子进程 和 aof 子进程if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)// 更新 dict.c 中的 dict_can_resize 为 1, 表示全部的 dict 可以进行扩容dictEnableResize();else// 更新 dict.c 中的 dict_can_resize 为 0, 表示全部的 dict 不可以进行扩容, 但是这个配置在 dict 中的数据达到某个条件后, 还是能进行扩容的dictDisableResize();
}上面就是 rdbSaveBackgroud 方法的逻辑了, 其最重要的一点就是 fork 出一个子进程, 执行最终的 RDB 文件的保存, 也就是 rdbSave 函数。
补充一点, 通过 bgsave 命令, 最终会走到上面的 rdbSaveBackground 函数, 而直接的 save 命令则是直接走到了 rdbSave 函数。
// 真正的 RDB 文件保存
int rdbSave(char *filename, rdbSaveInfo *rsi) {char tmpfile[256];/** 错误消息的当前工作目录路径 */char cwd[MAXPATHLEN]; FILE *fp;rio rdb;int error = 0;snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());// 创建打开一个临时文件fp = fopen(tmpfile,"w");// 打开临时文件失败if (!fp) {char *cwdp = getcwd(cwd, MAXPATHLEN);serverLog(LL_WARNING, "Failed opening the RDB file %s (in server root dir %s) for saving: %s", filename, cwdp ? cwdp : "unknown", strerror(errno));return C_ERR;}// 初始化一个 rio 对象, 该对象是一个文件对象 IOrioInitWithFile(&rdb,fp);// 配置判断, 通过分批将数据 fsync 到硬盘, 用来缓冲 ioif (server.rdb_save_incremental_fsync)rioSetAutoSync(&rdb,REDIS_AUTOSYNC_BYTES);// RDB_SAVE_NONE = 0 // 向文件流里面写入内容if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) {errno = error;goto werr;} // 将缓冲区中的数据写入到文件流中if (fflush(fp) == EOF) goto werr;// 执行多一次 fsync, 确保数据都写入到文件中if (fsync(fileno(fp)) == -1) goto werr; // 关闭文件if (fclose(fp) == EOF) goto werr;// 原子性改变 rdb 文件的名字, 如果存在同名的文件会删除if (rename(tmpfile,filename) == -1) {// 改变名字失败, 则获得当前目录路径, 发送日志信息, 删除临时文件char *cwdp = getcwd(cwd,MAXPATHLEN);serverLog(LL_WARNING, "Error moving temp DB file %s on the final destination %s (in server root dir %s): %s", tmpfile, filename, cwdp ? cwdp : "unknown", strerror(errno));unlink(tmpfile);return C_ERR;} serverLog(LL_NOTICE,"DB saved on disk");// 更新 RDB 的结构server.dirty = 0;server.lastsave = time(NULL);server.lastbgsave_status = C_OK;return C_OK;werr:serverLog(LL_WARNING,"Write error saving DB on disk: %s", strerror(errno));fclose(fp);unlink(tmpfile);return C_ERR;
}// 向文件流里面写入内容
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) {dictIterator *di = NULL;dictEntry *de;char magic[10];int j;uint64_t cksum;size_t processed = 0;// 开启了 RDB 文件校验码功能if (server.rdb_checksum)rdb->update_cksum = rioGenericUpdateChecksum;// RDB_VERSION = 9// magic = REDIS0009snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION);// 写入 REDIS0009if (rdbWriteRaw(rdb,magic,9) == -1) goto werr;// 写入辅助字段 redis-ver, redis-bits, ctime, used-mem, 如果入参的 rsi 不为空, 再写入 repl-stream-db repl-id repl-offset, 最后写入 aof-preambleif (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr;// 写入 module 相关的信息, 新版本增加的, 暂时跳过, 操作码为上面的 247if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_BEFORE_RDB) == -1) goto werr; // 遍历数据库数量for (j = 0; j < server.dbnum; j++) {redisDb *db = server.db+j;dict *d = db->dict;if (dictSize(d) == 0) continue;// 迭代器di = dictGetSafeIterator(d);// 写入 254 操作码, 也就是数据库编号if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr;// 写入数据库编号if (rdbSaveLen(rdb,j) == -1) goto werr;uint64_t db_size, expires_size;// 数据库数据数量db_size = dictSize(db->dict);// 数据库过期数量expires_size = dictSize(db->expires);// 写入 251 操作码, 也就是 resized 相关的内容if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr;if (rdbSaveLen(rdb,db_size) == -1) goto werr;if (rdbSaveLen(rdb,expires_size) == -1) goto werr;// 遍历数据while((de = dictNext(di)) != NULL) {// keysds keystr = dictGetKey(de);// valuerobj key, *o = dictGetVal(de);long long expire;// 把一个 sds 解析为 robjinitStaticStringObject(key,keystr);// 过期时间expire = getExpire(db,&key);// 写入 KeyValuePair if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr;// RDB_SAVE_AOF_PREAMBLE = 1, AOF_READ_DIFF_INTERVAL_BYTES = 1024*10// 通过 rdbSaveBackground() 方法到这里的 flags = RDB_SAVE_NONE = 0, 所以下面的不会执行到if (flags & RDB_SAVE_AOF_PREAMBLE && rdb->processed_bytes > processed+AOF_READ_DIFF_INTERVAL_BYTES) {processed = rdb->processed_bytes;aofReadDiffFromParent();}}// 释放迭代器dictReleaseIterator(di);di = NULL;}// rsi 从节点信息, 正常的 RDB, rsi 为 null// Redis lua 预置脚本: Redis 提供了先将 lua 脚本保存到数据库中, 同时返回一个 SHA1 的字符串, 然后客户端调用这个 SHA1 字符串就能调用到对应的 lua 脚本if (rsi && dictSize(server.lua_scripts)) {// 主从配置, 才会进入到这里, 正常的 RDB 保存不会di = dictGetIterator(server.lua_scripts);while((de = dictNext(di)) != NULL) {robj *body = dictGetVal(de);// 写入 aux 配置, // 先写入 250 操作符, // 再 aux 属性, key 为 lua, Value 为 server.lua_scripts 的 lua 脚本if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1)goto werr;}dictReleaseIterator(di);di = NULL; }// 操作码 247// 同时将 module 的配置写入if (rdbSaveModulesAux(rdb, REDISMODULE_AUX_AFTER_RDB) == -1) goto werr;// EOF 结束操作码 写入if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr;cksum = rdb->cksum;// 校验码获取memrev64ifbe(&cksum);// 写入校验码if (rioWrite(rdb,&cksum,8) == 0) goto werr; // 写入错误
werr:// 保存错误码if (error) *error = errno; // 如果没有释放迭代器, 则释放if (di) dictReleaseIterator(di); return C_ERR;
}
上面就是整个 RDB 文件保存的过程了。至于 RDB 文件的读取, 则可以通过 rdbLoad 函数, 这里就不展开了。
从中可以看出
- 父进程 fork 出子进程后, 子进程里面的数据和父进程是一样的
- 后面在子进程将自身的数据写入到文件中, 父进程修改的数据,子进程是无感知的
- 基于第二步, 在子进程开始 RDB 和 RDB 结束的这段时间, Redis 宕机或者重启, 父级处理成功的部分数据会丢失
- 同时 RDB 不是实时触发的, 只有在某个时间段 key 变更了多少次 (配置文件配置的), 才会触发 RDB, 在没有触发的这段时间, Redis 宕机或者重启, 这部分的数据也会丢失
自此整个 Redis RDB 过程就结束了。
触发执行的整个过程很简单, 整段逻辑读下去基本没有什么烧脑的
唯一有的绕的就是数据写入时, 各种数据如何写入到文件中, 但是理解了上面的文件结构,整数规则和操作码基本可以猜测到里面的逻辑了
7 参考
Redis源码剖析和注释 (十七) — RDB持久化机制
相关文章:
Redis RDB
基于内存的 Redis, 数据都是存储在内存中的。 那么如果重启的话, 数据就会丢失。 为了解决这个问题, Redis 提供了 2 种数据持久化的方案: RDB 和 AOF。 RDB 是 Redis 默认的持久化方案。当满足一定条件的时候, 会把当前内存中的数据写入磁盘, 生成一个快照文件 dump.rdb。Redi…...

Elasticsearch一些函数查询
1. 根据价格分组统计数量,每组区间为2000, filter_pathaggregations 设置查询结果只展示函数结果 也有date_histogram函数根据日期分组等等 GET order/_search?filter_pathaggregations {"aggs": {"hist_price": {"histogr…...

竞赛选题 : 题目:基于深度学习的水果识别 设计 开题 技术
1 前言 Hi,大家好,这里是丹成学长,今天做一个 基于深度学习的水果识别demo 这是一个较为新颖的竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/pos…...
Linux expect命令详解
在Linux系统中,expect 是一款非常有用的工具,它允许用户自动化与需要用户输入进行交互的程序。本文将深入探讨expect命令的基本语法、使用方法以及一些最佳实践。 什么是Expect命令? expect 是一个用于自动化交互式进程的工具。它的主要功能…...

ubuntu18编译Android8的Failed to contact Jack server问题
环境 ubuntu18.04 Android8.1.0 步骤 安装环境 apt install git-core apt install gnupg apt install flex apt install bison apt install gperf apt install build-essential apt install curl apt install libc6-dev apt install libssl-dev apt install libncurses5-dev:…...

FindSecBugs支持的检测规则
很多SAST集成了FindSecBugs这个开源工具,其好处是直接对Class文件进行检测,也就是直接检测二进制问题,可以直接检测war、jar,还是非常方便的。虽然误报率较高,但是这些检测出来的安全漏洞很多是安全从业人员耳熟能详的…...
【WPF.NET开发】WPF.NET桌面应用开发概述
本文内容 为何从 .NET Framework 升级使用 WPF 进行编程标记和代码隐藏输入和命令控件布局数据绑定图形和动画文本和版式自定义 WPF 应用 Windows Presentation Foundation (WPF) 是一个与分辨率无关的 UI 框架,使用基于矢量的呈现引擎,构建用于利用现…...
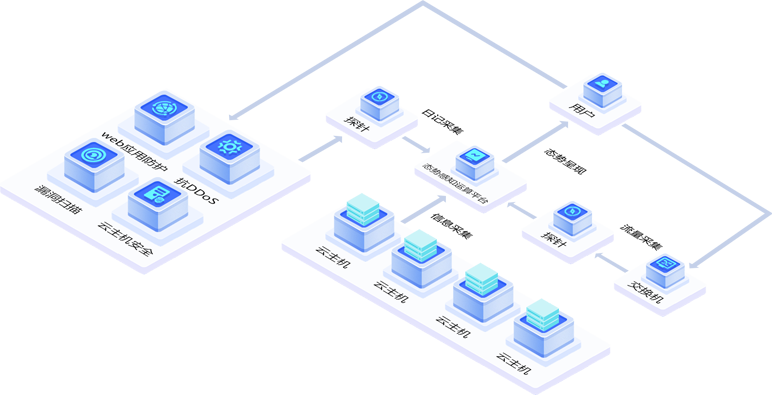
态势感知是什么
在当今高度信息化的时代,信息安全风险已经成为企业、政府和个人的重要关注点。为了有效应对这些风险,态势感知成为了一种日益重要的能力。态势感知是一种基于环境的、动态、整体地洞悉安全风险的能力,是以安全大数据为基础,从全局…...

Spring MVC常用的注解, Controller注解的作用,RequestMapping注解的作用 @ResponseBody注解的作用
文章目录 Spring MVC常用的注解和注解的相关作用Controller注解的作用RequestMapping注解的作用ResponseBody注解的作用PathVariable和RequestParam的区别 Spring MVC常用的注解和注解的相关作用 RequestMapping:用于处理请求 url 映射的注解,可用于类或…...

「Verilog学习笔记」自动贩售机1
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 自动贩售机中可能存在的几种金额:0,0.5,1,1.5,2,2.5,3。然后直接将其作为状态机的几种状…...

【大模型】更强的 ChatGLM3-6B 来了,开源可商用
【大模型】更强的 ChatGLM3-6B 来了,开源可商用 简介ChatGLM3-6B 环境配置环境搭建安装依赖 代码及模型权重拉取拉取 ChatGLM3-6B拉取 ChatGLM3-6B 模型权重及代码 终端测试网页测试安装 gradio加载模型并启动服务 参考 简介 ChatGLM3-6B ChatGLM3-6B 是 ChatGLM …...

Maxscript到Python转换工具教程
Maxscript到Python转换器教程 Maxscript到Python转换器采用MAXScript程序,将其解析为语法树,然后从语法树中生成等效的Python代码。通过提供python的自动翻译,帮助python程序员理解maxscript示例。 【项目状况】 将正确解析最正确的maxcript…...

Spark_日期参数解析参数-spark.sql.legacy.timeParserPolicy
在Apache Spark中,spark.sql.legacy.timeParserPolicy是一个配置选项,它控制着时间和日期解析策略。此选项主要影响如何解析日期和时间字符串。 在Spark 3.0之前的版本中,日期和时间解析使用java.text.SimpleDateFormat,它在解析…...
C语言之结构体
一.前言引入. 我们知道在C语言中有内置类型,如:整型,浮点型等。但是只有这些内置类 型还是不够的,假设我想描述学⽣,描述⼀本书,这时单⼀的内置类型是不⾏的。描述⼀个学⽣需要名字、年龄、学号、⾝⾼、体…...
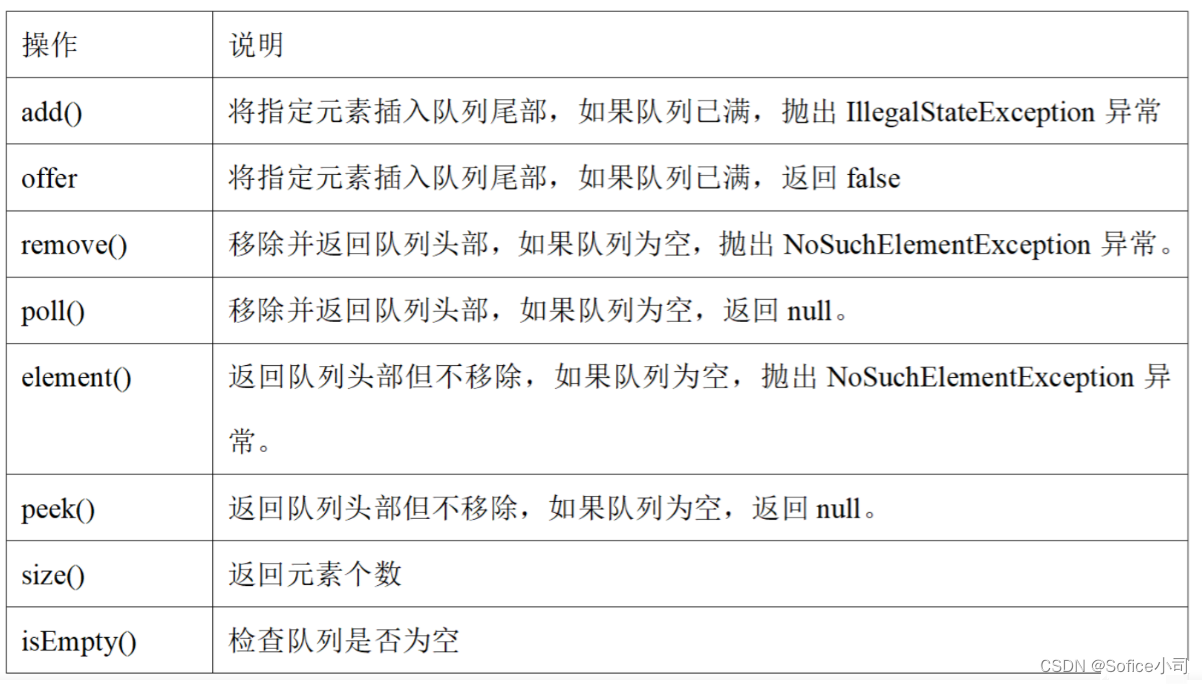
【蓝桥杯软件赛 零基础备赛20周】第5周——高精度大数运算与队列
文章目录 1. 数组的应用–高精度大数运算1.1 Java和Python计算大数1.2 C/C高精度计算大数1.2.1 高精度加法1.2.2 高精度减法 2. 队列2.1 手写队列2.1.1 C/C手写队列2.1.2 Java手写队列2.1.3 Python手写队列 2.2 C STL队列queue2.3 Java队列Queue2.4 Python队列Queue和deque2.5 …...
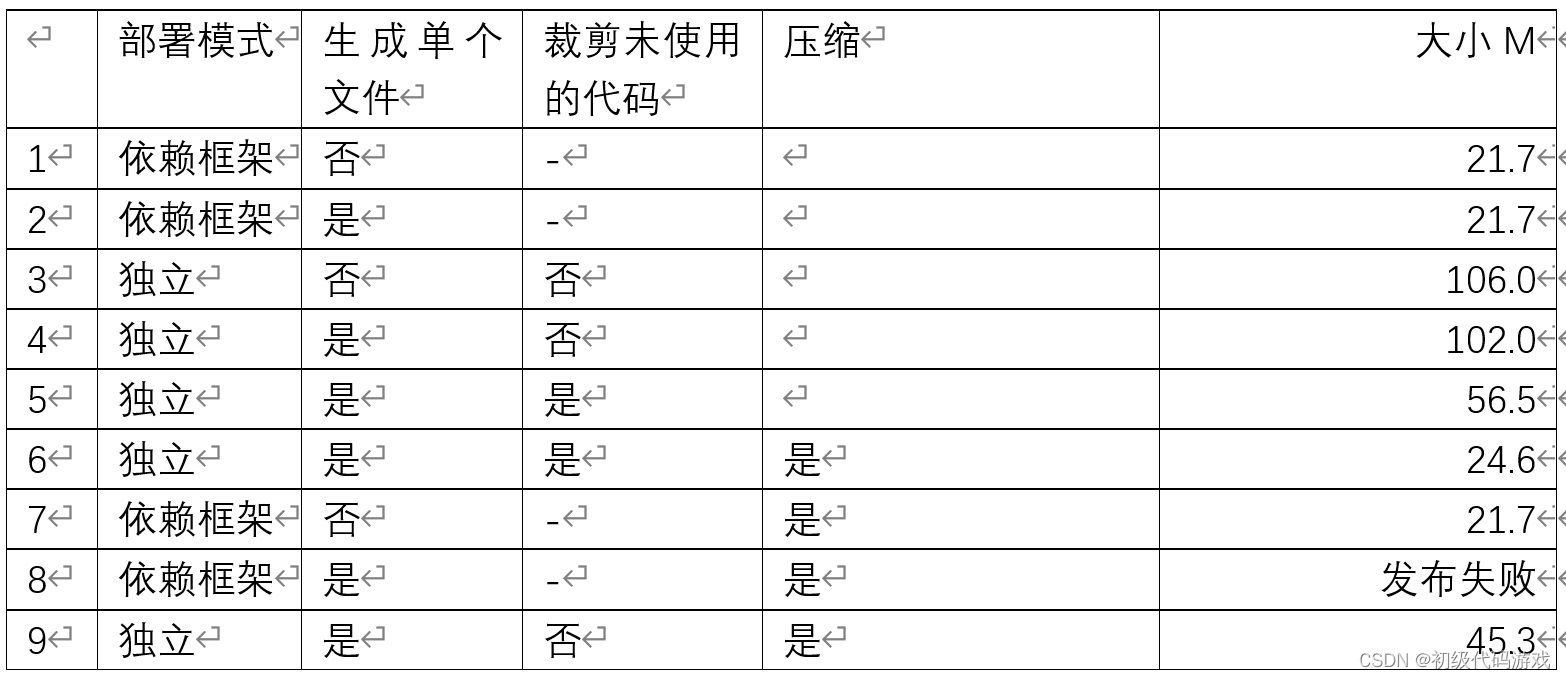
C#:程序发布的大小控制
.net不讨喜有个大原因就是.net平台本身太大了,不同版本没有兼容性,程序依赖哪个版本用户就要安装哪个版本,除非你恰好用的是操作系统默认安装的版本——问题是不同版本操作系统默认安装的不一样。 所以打包程序就很头疼,不打包平台…...
、rsplit()、splitlines()的区别)
Python中的split()、rsplit()、splitlines()的区别
split、rsplit、splitlines的区别 1、split()2、rsplit()3、splitlines() Python提供了三种字符串分割的方法:split()、rsplit()和splitlines();本文主要通过案例介绍这三种字符串分割函数的区别 1、split() split()主要用于从左向右匹配分割符进行分割…...

上位机开发框架:QT与winform/wpf对比
QT QT 是一个跨平台的 C 应用程序框架,它提供了丰富的 UI 组件和功能强大的网络通信、数据库操作等模块。QT 的优势在于其良好的跨平台性能,可以方便地部署在 Windows、Linux、macOS 等不同操作系统上。此外,QT 还具有强大的 UI 设计能力&am…...

Halcon tiff 点云读取以及平面矫正
一、读取tiff 图 dev_close_window () dev_open_window (0, 0, 512, 512, black, WindowHandle)xResolution:0.0025 yResolution:0.0025 zResolution:0.001 read_image (IntputImage, C:/Users/alber/Desktop/2023-08-15_16-38-24-982_/Sta5_002.tif) zoom_image_factor (Intpu…...
详解Spring中基于注解的Aop编程以及Spring对于JDK和CGLIB代理方式的切换
😉😉 学习交流群: ✅✅1:这是孙哥suns给大家的福利! ✨✨2:我们免费分享Netty、Dubbo、k8s、Mybatis、Spring...应用和源码级别的视频资料 🥭🥭3:QQ群:583783…...

AI编程助手用量追踪器:设计原理与本地化部署实践
1. 项目概述:一个专为编码代理设计的用量追踪器最近在折腾AI编程助手,发现一个挺实际的问题:当你把像Cursor、Claude Code、GitHub Copilot这类“编码代理”引入团队或者个人深度工作流后,怎么知道它们到底“吃”了多少资源&#…...

LoRA模型合并实战指南:多技能融合与vLLM部署
1. 项目概述:LoRA模型合并的“瑞士军刀”最近在折腾大语言模型微调的朋友,估计对LoRA(Low-Rank Adaptation)这个词都不陌生。它就像给预训练好的大模型“打补丁”,用极小的参数量(通常只有原模型的0.1%到1%…...

OpenAI GPT Image 2文字准确率95%,企业视觉硬核生产力4大核心升级与商业落地路径
GPT Image 2的4大核心升级能力1. 文字渲染准确率接近95%,多语言直出即用过去用AI生图,最头疼的就是文字。写个中文标题,十次有八次是乱码,英文稍微长一点也会出错。而GPT Image 2的文字渲染准确率做到了接近95%,支持中…...

基于MCP协议构建Naver搜索服务器,为AI智能体赋能实时信息获取
1. 项目概述:一个连接AI与实时信息的桥梁最近在折腾AI应用开发,特别是围绕OpenAI的Assistant API和Claude的Tool Use功能时,我一直在思考一个问题:如何让这些强大的AI模型摆脱其知识库的“时间枷锁”,获取到最新、最实…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

pgwatch2监控指标详解:从基础性能到高级洞察
pgwatch2监控指标详解:从基础性能到高级洞察 【免费下载链接】pgwatch2 PostgreSQL metrics monitor/dashboard 项目地址: https://gitcode.com/gh_mirrors/pg/pgwatch2 pgwatch2是一款功能强大的PostgreSQL metrics monitor/dashboard工具,它能够…...

GO Feature Flag通知系统详解:Slack、Webhook实时告警
GO Feature Flag通知系统详解:Slack、Webhook实时告警 【免费下载链接】go-feature-flag GO Feature Flag is a simple, complete and lightweight self-hosted cloud native feature flag solution 100% Open Source. 🎛️ 项目地址: https://gitcode…...

Hash-Buster未来展望:AI驱动的智能哈希破解技术
Hash-Buster未来展望:AI驱动的智能哈希破解技术 【免费下载链接】Hash-Buster Crack hashes in seconds. 项目地址: https://gitcode.com/gh_mirrors/ha/Hash-Buster Hash-Buster作为一款高效的哈希破解工具,目前已支持MD5、SHA1、SHA256等多种哈…...

策略即代码:从理念到实践,构建自动化合规与安全防线
1. 项目概述与核心价值 最近在整理团队内部的开发规范时,发现了一个非常有意思的仓库: vectimus/policies 。乍一看这个名字,你可能会觉得这只是一个存放公司政策文档的普通地方,但如果你深入进去,会发现它远不止于此…...

如何选择Mac Mouse Fix安装方式:终极指南让您的Mac鼠标体验完美升级
如何选择Mac Mouse Fix安装方式:终极指南让您的Mac鼠标体验完美升级 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是…...