[数据结构]HashSet与LinkedHashSet的底层原理学习心得
我们区分list和set集合的标准是三个:有无顺序,可否重复,有无索引。 list的答案是:有顺序,可重复,有索引。这也就是ArrayList和LinkedList的共性 set的答案是:顺序内部再区分,不可以重复,无索引 我们接下来可以通过顺序的标准在set集合中进行再区分: 1.HashSet无顺序 2.LinkedHashSet有顺序 3.TreeSet可排序
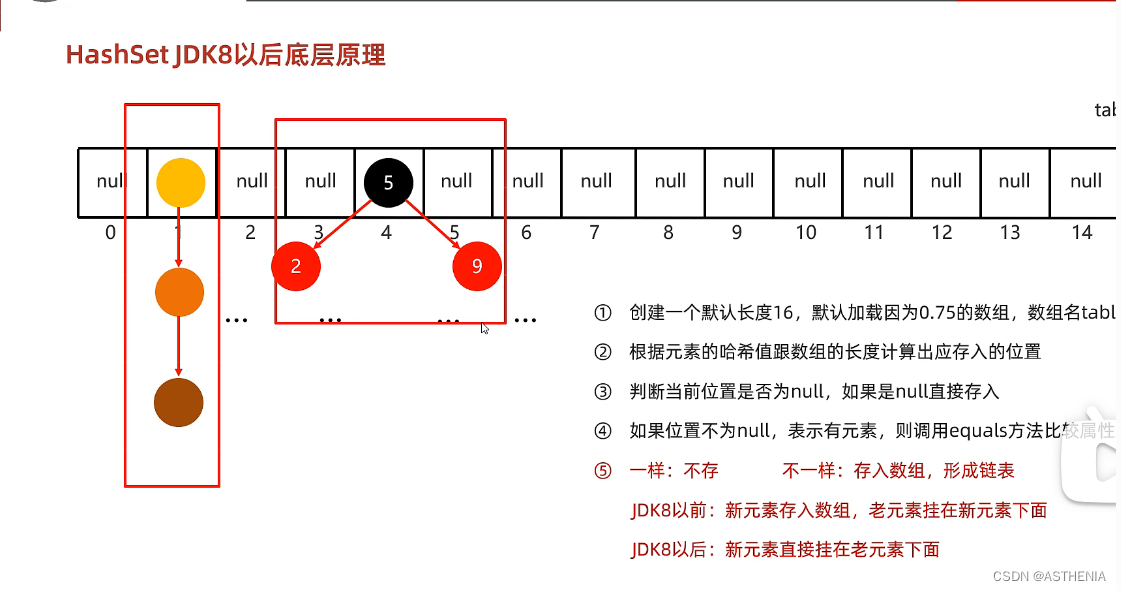
Hashset的底层是哈希表->一种对于增删改查数据性能较好的数据结构 分析哈希表的构成: Before JDK8:数组+链表 After JDK8:数组+链表+红黑树 哈希值:哈希表的灵魂所在->对象的整数表现形式 我们可以使用Object类中的hashcode方法来计算某个对象,运算结果是int类型的整数 问题来了:我们会拿对象的什么来进行计算?答案是:地址值 举个简单的例子: 现在有一个对象的地址值是0x0011 我通过这个地址值算出来一个哈希值:6794651616 然后我们在哈希表内添加元素的时候,注意,是在有索引的哈希表内添加元素的时候 这里我们避免一个认识误区:Hashset是没有索引的,但是构成Hashset的底层数据结构-哈希表是有索引的 我们将添加的元素在哈希表上的索引index的公式给出: int index=(数组长度-1)&哈希值; 这里又证明了先前我们提出的哈希表底层原理:数组+链表+红黑树(JDK8以前) 那么此时我们会有一个问题:在Object类下的hashcode和复写后的hashcode产生的哈希值是一样的么? 答案是不一样的-> 如果没有重写hashcode方法:不同对象计算出的哈希值是不同的 如果已经重写hashcode方法:不同的对象只要属性值相同,计算出的哈希值是一样的 这句话有点晦涩难懂,我们举个例子: 我需要构建一个学生信息管理系统,需要添加两个学生的名字进去 两个"小明" 如果我使用了object的hashcode 那么计算出的哈希值两次是不一样的 于是两个小明会被分配到不同的空间 但是如果我使用了重写后的hashcode 那么计算出的哈希值两次都是一样的 小明都会被储存到同一块区域当中去 但是注意:在小部分的情况下 不同的属性值或者不同的属性值计算机出的哈希值是一样的 这样的情况就是:哈希碰撞。因为int的范围是-21E到+21E 但是我现在创建50E个对象 一点有8E对象的哈希值是一样的 这样就会发生哈希碰撞 但是这样的极端概率是不高的
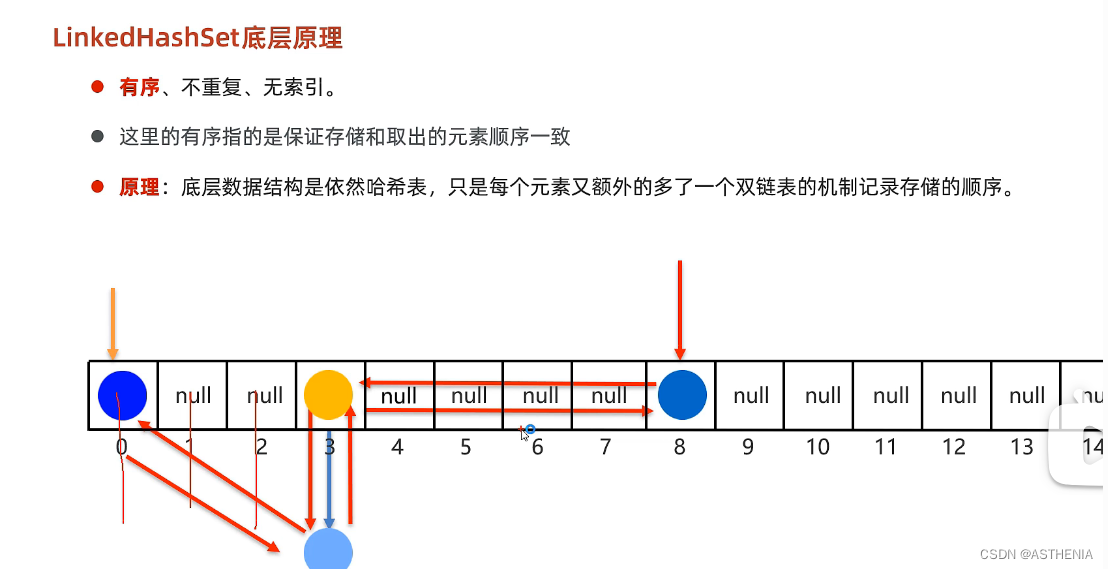
1.首先创建一个默认长度为16 默认加载因子是0.75的数组 数组名叫table 2.根据元素的哈希值跟数组的长度进行计算 计算出当前元素应存入的位置 公式: int index= (数组元素-1)&哈希值; 注意&是按位与 3.判断当前这个index对应的位置是否是Null 如果是null直接存入 4.如果当前位置不是Null 就说明已经有元素了 调用equals方法来比较属性值 例子:比如我要在Index为4的位置存入一个新的数据 但是4位置已经有数据了 5.如果属性值是一样:不存属性值不一样:存入数组,形成链表(JDK8以前 新的元素存入数组 老的元素挂在新元素下面)(JDK8以后 新元素挂在老元素下面)加载因子是什么:数组的扩容时机:16x0.75=12元素满时添加6.红黑树的出现:我们先前谈到了在哈希表的相同位置添加元素会触发equals方法然后新的数据会挂载在哈希表的下面,其中红黑树就是一种jdk8以后产生的新挂载方法JDK8满足条件:a.链表长度超过8 b.数组长度>=647.集合中储存的是自定义对象,必须要重写hashcode和equals方法前者的目的是为了属性值取代地址值,后者的目的是用属性值去进行比较我们构造链表和树的目的就是为了减少哈希碰撞Hashset为什么没有索引 Hash表上挂着许多的链表和红黑树 无法准确的表示具体的索引 因为一个index上可以挂着红黑树和链表 你如何确定二者的索引呢?学习问答题:Q1:Hashset的集合的底层数据结构是什么样的答案:HashTable(散列表)在JDK8以前 HashTable由数组和链表构成的 在JDK8以后由数组 链表 红黑树构成一个HashTable的所谓索引也就是Hashbucket(哈希桶),每一个哈希桶上可以挂载链表和红黑树Q2:Hashset添加元素的过程是如何的答案:如果哈希值对应的Hashbucket为Null 直接添加 else 再调用equals进行判断 一样就不存 不一样就存Q3 Hashset为什么取和存的顺序不一样答案:我遍历一个hashset其实是从hashtable的序号为0的hashbucket开始的 但是我存入一个元素到hashbucket是根据hashcode算出来的读取和存入执行的过程是不一样的Q4:HashSet为什么没有索引:答案:使用到了链表和红黑树挂在hashbucket上面 过于复杂无法用索引表示Q5:HashSet是用什么机制去保证去重复的?答案:重写后的equals方法———————————————————————————————————————————— LinkedHashSet底层原理 有序,不重复,无索引 底层数据结构:哈希表+链表
import java.util.*;public class Main{public static void main(String[] args){/*我们区分list和set集合的标准是三个:有无顺序,可否重复,有无索引。list的答案是:有顺序,可重复,有索引。这也就是ArrayList和LinkedList的共性set的答案是:顺序内部再区分,不可以重复,无索引我们接下来可以通过顺序的标准在set集合中进行再区分:1.HashSet无顺序2.LinkedHashSet有顺序3.TreeSet可排序*/Set<String> Hash = new HashSet<>();Set<String> LinkedHash = new LinkedHashSet<>();Set<String> TreeSet = new TreeSet<>();Hash.add("张三");Hash.add("李四");Hash.add("王五");//1.ForEach+lambda表达式遍历Hash.forEach(s->System.out.println(s));//2.加强for循环遍历for(String s:Hash){System.out.println(s);}//3.迭代器遍历Iterator<String> it = Hash.iterator();while(it.hasNext()){System.out.println(it.next());}//现在我们开始系统学习set,第一课:Hashset/*Hashset的底层是哈希表->一种对于增删改查数据性能较好的数据结构分析哈希表的构成:Before JDK8:数组+链表After JDK8:数组+链表+红黑树哈希值:哈希表的灵魂所在->对象的整数表现形式我们可以使用Object类中的hashcode方法来计算某个对象,运算结果是int类型的整数问题来了:我们会拿对象的什么来进行计算?答案是:地址值举个简单的例子:现在有一个对象的地址值是0x0011 我通过这个地址值算出来一个哈希值:6794651616然后我们在哈希表内添加元素的时候,注意,是在有索引的哈希表内添加元素的时候这里我们避免一个认识误区:Hashset是没有索引的,但是构成Hashset的底层数据结构-哈希表是有索引的我们将添加的元素在哈希表上的索引index的公式给出:int index=(数组长度-1)&哈希值; 这里又证明了先前我们提出的哈希表底层原理:数组+链表+红黑树(JDK8以前)那么此时我们会有一个问题:在Object类下的hashcode和复写后的hashcode产生的哈希值是一样的么?答案是不一样的->如果没有重写hashcode方法:不同对象计算出的哈希值是不同的如果已经重写hashcode方法:不同的对象只要属性值相同,计算出的哈希值是一样的这句话有点晦涩难懂,我们举个例子:我需要构建一个学生信息管理系统,需要添加两个学生的名字进去 两个"小明"如果我使用了object的hashcode 那么计算出的哈希值两次是不一样的 于是两个小明会被分配到不同的空间但是如果我使用了重写后的hashcode 那么计算出的哈希值两次都是一样的 小明都会被储存到同一块区域当中去但是注意:在小部分的情况下 不同的属性值或者不同的属性值计算机出的哈希值是一样的这样的情况就是:哈希碰撞。因为int的范围是-21E到+21E 但是我现在创建50E个对象一点有8E对象的哈希值是一样的 这样就会发生哈希碰撞 但是这样的极端概率是不高的*///1.创建一个对象Student s1=new Student("小明",23);Student s2=new Student("小明",23);//2.如果没有重写hashcode s1和s2返回的哈希值是不一样的System.out.println(s1.hashCode());System.out.println(s2.hashCode());//你会发现在Student重写hashcode后的返回哈希值是一样的//这里的重写我们用alt+insert的便捷键来进行重写//哈希碰撞的特例:System.out.println("abc".hashCode());System.out.println("acD".hashCode());//Hashcode在JDK8以前的底层原理/*1.首先创建一个默认长度为16 默认加载因子是0.75的数组 数组名叫table2.根据元素的哈希值跟数组的长度进行计算 计算出当前元素应存入的位置公式: int index= (数组元素-1)&哈希值; 注意&是按位与3.判断当前这个index对应的位置是否是Null 如果是null直接存入4.如果当前位置不是Null 就说明已经有元素了 调用equals方法来比较属性值例子:比如我要在Index为4的位置存入一个新的数据 但是4位置已经有数据了5.如果属性值是一样:不存属性值不一样:存入数组,形成链表(JDK8以前 新的元素存入数组 老的元素挂在新元素下面)(JDK8以后 新元素挂在老元素下面)加载因子是什么:数组的扩容时机:16x0.75=12元素满时添加6.红黑树的出现:我们先前谈到了在哈希表的相同位置添加元素会触发equals方法然后新的数据会挂载在哈希表的下面,其中红黑树就是一种jdk8以后产生的新挂载方法JDK8满足条件:a.链表长度超过8 b.数组长度>=647.集合中储存的是自定义对象,必须要重写hashcode和equals方法前者的目的是为了属性值取代地址值,后者的目的是用属性值去进行比较我们构造链表和树的目的就是为了减少哈希碰撞Hashset为什么没有索引 Hash表上挂着许多的链表和红黑树 无法准确的表示具体的索引 因为一个index上可以挂着红黑树和链表 你如何确定二者的索引呢?学习问答题:Q1:Hashset的集合的底层数据结构是什么样的答案:HashTable(散列表)在JDK8以前 HashTable由数组和链表构成的 在JDK8以后由数组 链表 红黑树构成一个HashTable的所谓索引也就是Hashbucket(哈希桶),每一个哈希桶上可以挂载链表和红黑树Q2:Hashset添加元素的过程是如何的答案:如果哈希值对应的Hashbucket为Null 直接添加 else 再调用equals进行判断 一样就不存 不一样就存Q3 Hashset为什么取和存的顺序不一样答案:我遍历一个hashset其实是从hashtable的序号为0的hashbucket开始的 但是我存入一个元素到hashbucket是根据hashcode算出来的读取和存入执行的过程是不一样的Q4:HashSet为什么没有索引:答案:使用到了链表和红黑树挂在hashbucket上面 过于复杂无法用索引表示Q5:HashSet是用什么机制去保证去重复的?答案:重写后的equals方法————————————————————————————————————————————LinkedHashSet底层原理有序,不重复,无索引底层数据结构:哈希表+链表*/}
} 1.首先创建一个默认长度为16 默认加载因子是0.75的数组 数组名叫table2.根据元素的哈希值跟数组的长度进行计算 计算出当前元素应存入的位置公式: int index= (数组元素-1)&哈希值; 注意&是按位与3.判断当前这个index对应的位置是否是Null 如果是null直接存入4.如果当前位置不是Null 就说明已经有元素了 调用equals方法来比较属性值例子:比如我要在Index为4的位置存入一个新的数据 但是4位置已经有数据了5.如果属性值是一样:不存属性值不一样:存入数组,形成链表(JDK8以前 新的元素存入数组 老的元素挂在新元素下面)(JDK8以后 新元素挂在老元素下面)加载因子是什么:数组的扩容时机:16x0.75=12元素满时添加6.红黑树的出现:我们先前谈到了在哈希表的相同位置添加元素会触发equals方法然后新的数据会挂载在哈希表的下面,其中红黑树就是一种jdk8以后产生的新挂载方法JDK8满足条件:a.链表长度超过8 b.数组长度>=647.集合中储存的是自定义对象,必须要重写hashcode和equals方法前者的目的是为了属性值取代地址值,后者的目的是用属性值去进行比较我们构造链表和树的目的就是为了减少哈希碰撞Hashset为什么没有索引 Hash表上挂着许多的链表和红黑树 无法准确的表示具体的索引 因为一个index上可以挂着红黑树和链表 你如何确定二者的索引呢?学习问答题:Q1:Hashset的集合的底层数据结构是什么样的答案:HashTable(散列表)在JDK8以前 HashTable由数组和链表构成的 在JDK8以后由数组 链表 红黑树构成一个HashTable的所谓索引也就是Hashbucket(哈希桶),每一个哈希桶上可以挂载链表和红黑树Q2:Hashset添加元素的过程是如何的答案:如果哈希值对应的Hashbucket为Null 直接添加 else 再调用equals进行判断 一样就不存 不一样就存Q3 Hashset为什么取和存的顺序不一样答案:我遍历一个hashset其实是从hashtable的序号为0的hashbucket开始的 但是我存入一个元素到hashbucket是根据hashcode算出来的读取和存入执行的过程是不一样的Q4:HashSet为什么没有索引:答案:使用到了链表和红黑树挂在hashbucket上面 过于复杂无法用索引表示Q5:HashSet是用什么机制去保证去重复的?答案:重写后的equals方法————————————————————————————————————————————LinkedHashSet底层原理有序,不重复,无索引底层数据结构:哈希表+链表import java.util.Objects;public class Student
{private String name;private int age;public Student() {}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}public Student(String name, int age) {this.name = name;this.age = age;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}public String toString() {return "Student{name = " + name + ", age = " + age + "}";}
}
@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}相关文章:
[数据结构]HashSet与LinkedHashSet的底层原理学习心得
我们区分list和set集合的标准是三个:有无顺序,可否重复,有无索引。 list的答案是:有顺序,可重复,有索引。这也就是ArrayList和LinkedList的共性 set的答案是:顺序内部再区分,不可以重复…...

使用unity开发Pico程序,场景中锯齿问题
1、问题 使用unity【非HDR】开发Pico程序,场景中锯齿问题,设置了unity的抗锯齿和渲染方式,及悬挂抗锯齿的脚本,都不能很好的解决项目中图片、文字的锯齿问题,通过摸索找到了妥善的方法 1、修改项目中图片的 GenerateMIpMaps 为勾…...

Spring | Spring的基本应用
目录: 1.什么是Spring?2.Spring框架的优点3.Spring的体系结构 (重点★★★) :3.1 Core Container (核心容器) ★★★Beans模块 (★★★) : BeanFactoryCore核心模块 (★★★) : IOCContext上下文模块 (★★★) : ApplicationContextContext-support模块 (★★★)SpE…...
)
项目开发维护技术文档(梳理总结中)
目录 项目名称——惠誉灵境 一、项目背景 二、架构设计 1.技术栈 2.架构图 3.代码结构 三、模块划分 1.平台首页 2.登录模块 3.系统模块 (1)系统首页 (2)组织架构 (3)权限管控 ①角色管理 (4&am…...
【接口测试】Apifox实用技巧干货分享
前言 不知道有多少人和我有着这样相似的经历:从写程序只要不报错就不测试😊,到写了程序若是有bug就debug甚至写单元测试,然后到了真实开发场景,大哥和你说,你负责的功能模块的所有接口写完要测试一遍无误在…...
_消息平台的搭建)
车联网架构设计(一)_消息平台的搭建
车联网是物联网的一个主要应用方向,车辆通过连接车联网平台,实时进行消息的交互,平台可以提供车辆远程控制,故障检测,车路协同等各方面的功能。 我在车联网行业从事了很长时间的技术工作,参与了整个车联网…...

(蓝桥杯)1125 第 4 场算法双周赛题解+AC代码(c++/java)
题目一:验题人的生日【算法赛】 验题人的生日【算法赛】 - 蓝桥云课 (lanqiao.cn) 思路: 1.又是偶数,又是质数,那么只有2喽 AC_Code:C #include <iostream> using namespace std; int main() {cout<<2;return 0; …...
也可Adobe Animate
Animate CC 由原Adobe Flash Professional CC 更名得来,2015年12月2日:Adobe 宣布Flash Professional更名为Animate CC,在支持Flash SWF文件的基础上,加入了对HTML5的支持。并在2016年1月份发布新版本的时候,正式更名为…...
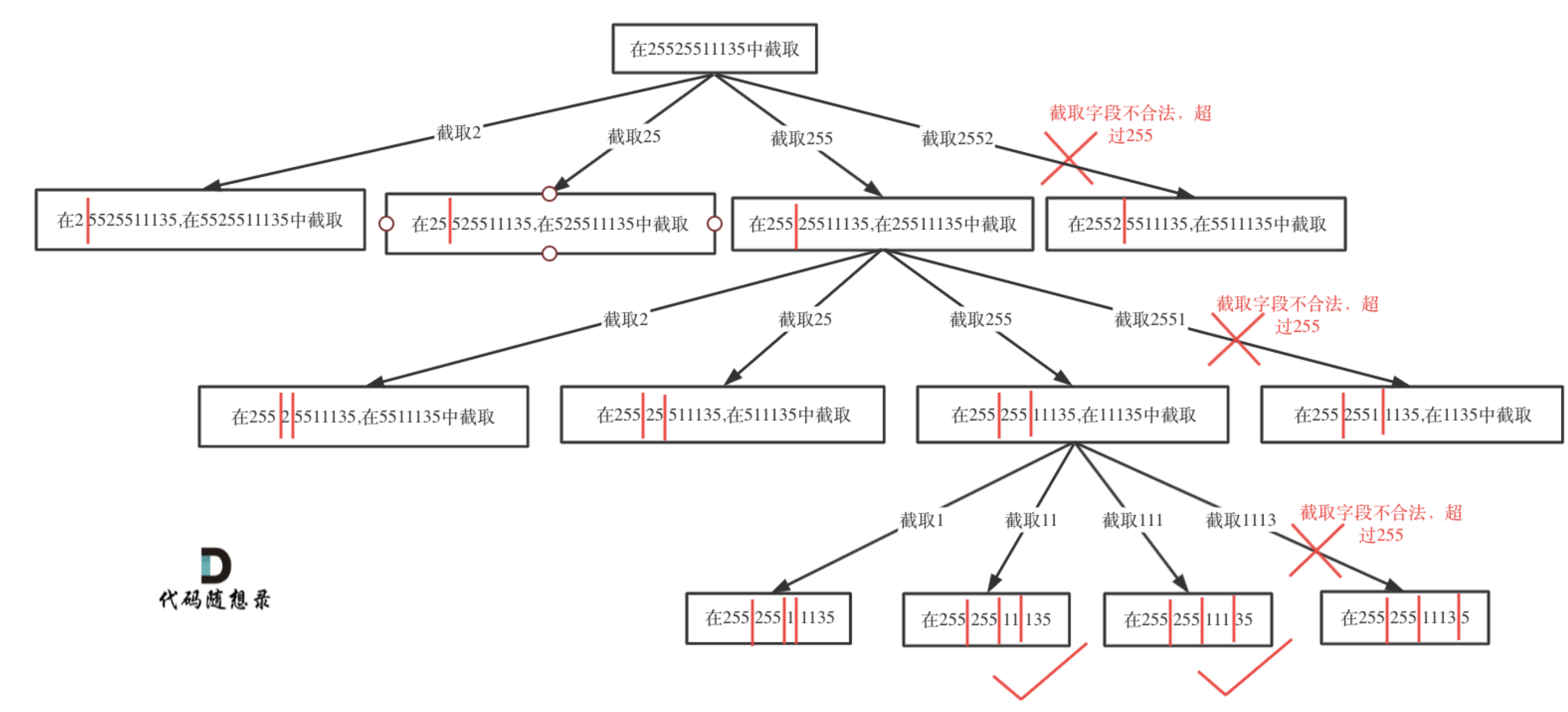
【面试HOT200】回溯篇
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于【CodeTopHot300】进行的,每个知识点的修正和深入主要参…...

JVM——内存溢出和内存泄漏
目录 1. 内存溢出和内存泄漏内存泄漏的常见场景解决内存溢出的思路1.发现问题 – Top命令2.发现问题 – VisualVM3.发现问题 – Arthas4.发现问题 – Prometheus Grafana5.发现问题 – 堆内存状况的对比
《凤凰项目》读书笔记
文章目录 一、书名和作者二、书籍概览2.1 主要论点和结构2.2 目标读者和应用场景 三、核心观点与主题3.1 DevOps的核心原则与文化变革3.2 持续交付与自动化3.3 变更管理与风险控制3.4 关键绩效指标与持续改进 四、亮点与启发4.1 最有影响的观点4.2 对个人专业发展的启示 五、批…...

熬夜会秃头——beta冲刺Day4
这个作业属于哪个课程2301-计算机学院-软件工程社区-CSDN社区云这个作业要求在哪里团队作业—beta冲刺事后诸葛亮-CSDN社区这个作业的目标记录beta冲刺Day4团队名称熬夜会秃头团队置顶集合随笔链接熬夜会秃头——Beta冲刺置顶随笔-CSDN社区 一、团队成员会议总结 1、成员工作进…...

HTML5+CSS3+Vue小实例:浪漫的心形文字动画特效
实例:浪漫的心形文字动画特效 技术栈:HTML+CSS+Vue 效果: 源码: 【HTML】 <!DOCTYPE html> <html><head><meta http-equiv="content-type" content="text/html; charset=utf-8"><meta name="viewport" conte…...

数据结构-基数排序
基数排序 基本思想 基数排序其实就是依靠多位关键字进行排序,现在我们有一个数据为101,那么“101”就是一个三位 关键字,分别为:“百位->1”、“十位->0”、“个位->1”。 此时我们就可以按照三位关键字进行排序&…...
基于ASP.NET MVC技术的图书管理系统的设计与实现
基于ASP.NET MVC技术的图书管理系统的设计与实现 摘要:图书管理系统是一套高新科学技术和图书知识信息以及传统历史文化完美结合的体现。它改变了传统图书收藏的静态书本式图书服务特征,实现了多媒体存取、远程网络传输、智能化检索、跨库无缝链接、创造…...
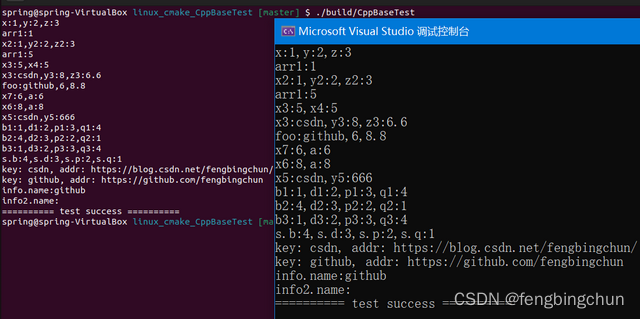
C++17中的结构化绑定
C17中的结构化绑定(structured binding):将指定名称绑定到初始化程序的子对象或元素。简而言之,它们使我们能够从元组或结构中声明多个变量。与引用一样,结构化绑定是现有对象的别名;与引用不同,结构化绑定不必是引用类型(referen…...
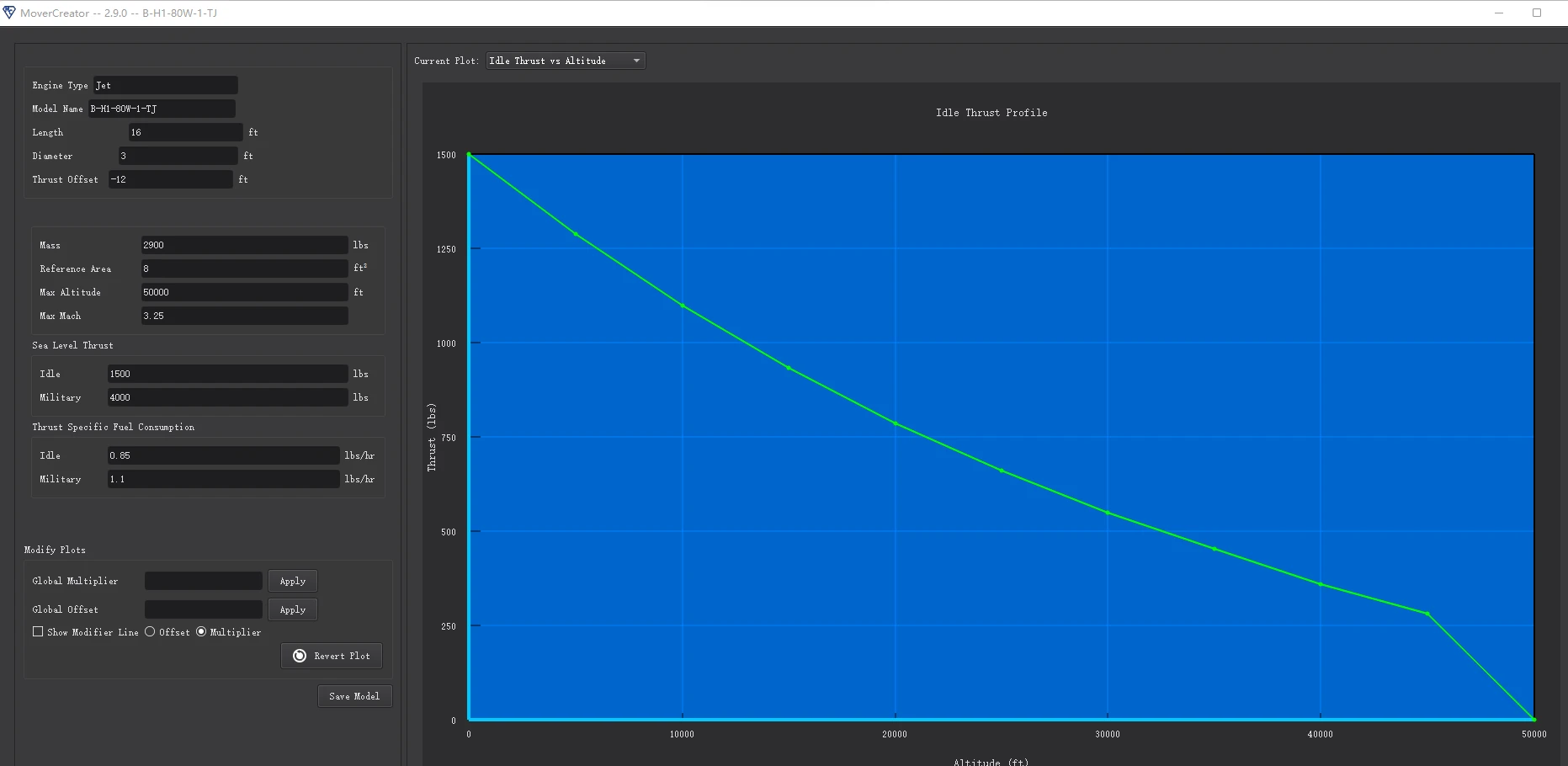
Mover Creator 用户界面
1 “开始”对话框 首次打开 Mover Creator 时,出现的第一个页面是“开始”对话框,如下所示。从这里开始,用户可以选择开始设计飞机、武器或发动机。在上述每种情况下,用户都可以创建新模型或编辑现有模型。 1.1 新建模型 如果用…...

『Nginx安全访问控制』利用Nginx实现账号密码认证登录的最佳实践
📣读完这篇文章里你能收获到 如何创建用户账号和密码文件,并生成加密密码配置Nginx的认证模块,实现基于账号密码的登录验证 文章目录 一、创建账号密码文件1. 安装htpasswd工具1.1 CentOS1.2 Ubuntu 二、配置Nginx三、重启Nginx 在Web应用程…...

MongoDB导入导出命令
(1)mongoexport命令 例如: mongoexport --db testdb --collection person --out person.json mongoexport --db testdb --collection person --fields name,age --out person.json mongoexport --db testdb --collection person --query {&qu…...
软件工程期末复习(1)
学习资料 软件工程知识点总结_嘤桃子的博客-CSDN博客 软件工程学习笔记_软件工程导论第六版张海藩pdf-CSDN博客 【软件工程】软件工程期末试卷习题课讲解!!_哔哩哔哩_bilibili 【拯救者】软件工程速成(期末考研复试软考)均适用. 支持4K_哔哩哔哩_bil…...

Need is all you need:AI接手Coding后,程序员最值钱的能力只剩这一项?
闻乐 发自 凹非寺量子位 | 公众号 QbitAIAI Coding的玩法,又变了。如果你留意就会发现,Cursor、Windsurf、Claude Code这些顶流玩家,现在基本都不爱吹“代码生成有多快”了。话锋一转,全在讲“我能帮你完成多少任务”。这个微妙的…...

瑞为技术获IPO备案:年营收4.4亿 亏损6815万
雷递网 雷建平 5月15日厦门瑞为信息技术股份有限公司(简称“瑞为技术”)日前获IPO备案,拿到了上市钥匙。与瑞为技术一同拿到上市备案的公司还有上海仙工智能科技股份有限公司、江西齐云山食品股份有限公司、广东鼎泰高科技术股份有限公司。年…...

Linux矢量设计挑战:Wine环境下的Adobe Illustrator CC安装与配置技术方案
Linux矢量设计挑战:Wine环境下的Adobe Illustrator CC安装与配置技术方案 【免费下载链接】illustratorCClinux Illustrator CC v17 installer for Gnu/Linux 项目地址: https://gitcode.com/gh_mirrors/il/illustratorCClinux 对于Linux用户而言,…...

合宙BluePill开发板:9.9元ARM Cortex-M核心板硬件解析与实战指南
1. 项目概述:一块“炸场”的开发板意味着什么最近在嵌入式开发圈子里,一块名为“合宙BluePill”的新品开发板以9.9元包邮的价格开售,瞬间点燃了众多开发者、电子爱好者和学生群体的热情。这个价格,别说是一块功能完整的开发板&…...

tchMaterial-parser:基于智能解析引擎的教育资源去中心化获取方案
tchMaterial-parser:基于智能解析引擎的教育资源去中心化获取方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。…...

Spectator:云原生可观测性数据采集库的设计与实战
1. 项目概述:从“观众”到“洞察者”的转变在分布式系统和微服务架构成为主流的今天,我们每天面对的不再是单一的、庞大的单体应用,而是由数十甚至上百个服务节点组成的复杂网络。每个服务都在持续地产生日志、指标和追踪数据,这些…...

终极MifareOneTool使用指南:如何零基础玩转MIFARE经典卡的Windows图形化神器
终极MifareOneTool使用指南:如何零基础玩转MIFARE经典卡的Windows图形化神器 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool …...

怎样高效搭建AI多智能体交易系统:3步快速部署完整方案
怎样高效搭建AI多智能体交易系统:3步快速部署完整方案 【免费下载链接】TradingAgents-AI.github.io TradingAgents: Multi-Agents LLM Financial Trading Framework 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-AI.github.io 想要让AI…...

在Ubuntu上快速搭建LVGL模拟器开发环境
1. 为什么选择Ubuntu搭建LVGL模拟器 LVGL作为当下最流行的嵌入式图形库之一,以其高度可裁剪性和低资源占用的特性赢得了广大开发者的青睐。在实际开发中,我们经常需要先在PC端完成界面原型设计,再移植到嵌入式设备。Ubuntu作为Linux发行版中的…...

从PyQt5迁移到PyQt6:一个真实项目的踩坑与平滑升级实战记录
从PyQt5迁移到PyQt6:一个真实项目的踩坑与平滑升级实战记录 在Python GUI开发领域,PyQt一直是许多开发者的首选工具包。当PyQt6发布时,我们团队面临一个关键决策:是否要将正在开发中的数据分析平台从PyQt5迁移到新版本。这个决策不…...