Zookeeper下载和安装
Zookeeper
1.下载
官方下载地址:https://zookeeper.apache.org/
版本:apache-zookeeper-3.7.1-bin.tar.gz
2. 安装
2.1 本地安装
2.1.1 安装JDK
见:Hadoop集群搭建
2.1.2 上传安装包
使用远程工具拷贝安装包到Linux指定路径
/opt/software
2.1.3 解压到指定目录
将安装包解压到/opt/module中
[li@hadoop102 software]$ tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
2.1.4 修改安装包名称
[li@hadoop102 module]$ mv apache-zookeeper-3.7.1 zookeeper-3.7.1
2.1.5 配置修改
(1)将/opt/module/zookeeper-3.7.1/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
[li@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开 zoo.cfg 文件,修改 dataDir 路径:
[li@hadoop102 zookeeper-3.7.1]$ vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.7.1/zkData
配置参数解读:
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2)initLimit = 10:LF初始通信时限。Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
3)syncLimit = 5:LF同步通信时限
4)dataDir:保存Zookeeper中的数据 注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
5)clientPort = 2181:客户端连接端口,通常不做修改。
(3)在/opt/module/zookeeper-3.7.1/这个目录上创建 zkData 文件夹
[li@hadoop102 zookeeper-3.7.1]$ mkdir zkData
2.1.6 操作Zookeeper
(1)启动 Zookeeper
[li@hadoop102 zookeeper-3.7.1]$ bin/zkServer.sh start
(2)查看进程是否启动
[li@hadoop102 zookeeper-3.7.1]$ jps
4020 Jps
4001 QuorumPeerMain
(3)查看状态
[li@hadoop102 zookeeper-3.7.1]$ bin/zkServer.sh stutas
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.7.1/bin/../conf/zoo.cfg
Usage: /opt/module/zookeeper-3.7.1/bin/zkServer.sh [--config <conf-dir>] {start|start-foreground|stop|version|restart|status|print-cmd}
(4)启动客户端
[li@hadoop102 zookeeper-3.7.1]$ bin/zkCli.sh
(5)退出客户端:
[zk: localhost:2181(CONNECTING) 3] quit
(6)停止 Zookeeper
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.7.1/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
2.2 集群操作
2.2.1 集群安装
(1)集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上都部署 Zookeeper。
(2)解压安装
- 在 hadoop102 解压 Zookeeper 安装包到/opt/module/目录下
[li@hadoop102 software]$ tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
- 修改 apache-zookeeper-3.7.1-bin 名称为 zookeeper-3.7.1
[li@hadoop102 software]$ mv apache-zookeeper-3.7.1-bin/ zookeeper-3.7.1
(3)配置服务器编号
- 在/opt/module/zookeeper-3.7.1/这个目录下创建 zkData
[li@hadoop102 software]$ mkdir zkDate
- 在/opt/module/zookeeper-3.7.1/zkData 目录下创建一个 myid 的文件
[li@hadoop102 software]$ vim myid
在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
2
- 拷贝配置好的 zookeeper 到其他机器上
[li@hadoop102 software]$ xsync zookeeper-3.7.1
并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
(4)配置zoo.cfg文件
- 重命名/opt/module/zookeeper-3.7.1/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[li@hadoop102 software]$ mv zoo_sample.cfg zoo.cfg
- 打开zoo.cfg文件
[li@hadoop102 software]$ vim zoo.cfg
# 增加如下配置
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
配置参数解读:
server.A=B:C:D
- A 是一个数字,表示这个是第几号服务器; 集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据 就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比 较从而判断到底是哪个 server;
- B 是这个服务器的地址;
- C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
- D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
- 同步 zoo.cfg 配置文件
[li@hadoop102 conf]$ xsync zoo.cfg
2.2.2 集群操作
(1)分别启动Zookeeper
[li@hadoop102 zookeeper-3.7.1]$ bin/zkServer.sh start
[li@hadoop103 zookeeper-3.7.1]$ bin/zkServer.sh start
[li@hadoop104 zookeeper-3.7.1]$ bin/zkServer.sh start
(2) 查看状态
[li@hadoop102 zookeeper-3.7.1]$ bin/zkServer.sh status
[li@hadoop103 zookeeper-3.7.1]$ bin/zkServer.sh status
[li@hadoop104 zookeeper-3.7.1]$ bin/zkServer.sh status
2.2.3 集群启动停止脚本
(1)在 hadoop102 的/home/li/bin 目录下创建脚本
[li@hadoop102 bin]$ vim zk.sh
脚本中编写如下内容:
#!/bin/bashcase $1 in
"start")for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh start"done
;;
"stop")for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh stop"done
;;
"status")for i in hadoop102 hadoop103 hadoop104doecho ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh status"done
;;
esac
(2)增加脚本执行权限
[li@hadoop102 bin]$ chmod u+x zk.sh
(3)Zookeeper 集群启动脚本
[li@hadoop102 bin]$ zk.sh start
(4)Zookeeper 集群停止脚本
[li@hadoop102 bin]$ zk.sh stop
2.3.4 添加环境变量
在my_env.sh中配置Zookeeper环境变量,添加如下内容:
export ZK_HOME=/opt/module/zookeeper-3.7.1
export PATH=$PATH:$ZK_HOME/bin
2.3.5 分发文件
将更改过的文件同步到hadoop103,hadoop104中
[li@hadoop102 profile.d]$ xsync my_env.sh
相关文章:

Zookeeper下载和安装
Zookeeper 1.下载 官方下载地址:https://zookeeper.apache.org/ 版本:apache-zookeeper-3.7.1-bin.tar.gz 2. 安装 2.1 本地安装 2.1.1 安装JDK 见:Hadoop集群搭建 2.1.2 上传安装包 使用远程工具拷贝安装包到Linux指定路径 /opt/s…...

Biomod2 (上):物种分布模型预备知识总结
Biomod11.栅格数据处理1.1 读取一个栅格图片1.2 计算数据间的相关系数1.3 生成多波段的栅格图像1.4 修改变量名称1.4.1 计算多个变量之间的相关性2. 矢量数据处理2.1 提取矢量数据2.2 数据掩膜2.2 栅格计算2.3 拓展插件的使用3. 图表绘制3.1 遥感影像绘制3.2 柱状图分析图绘制3…...
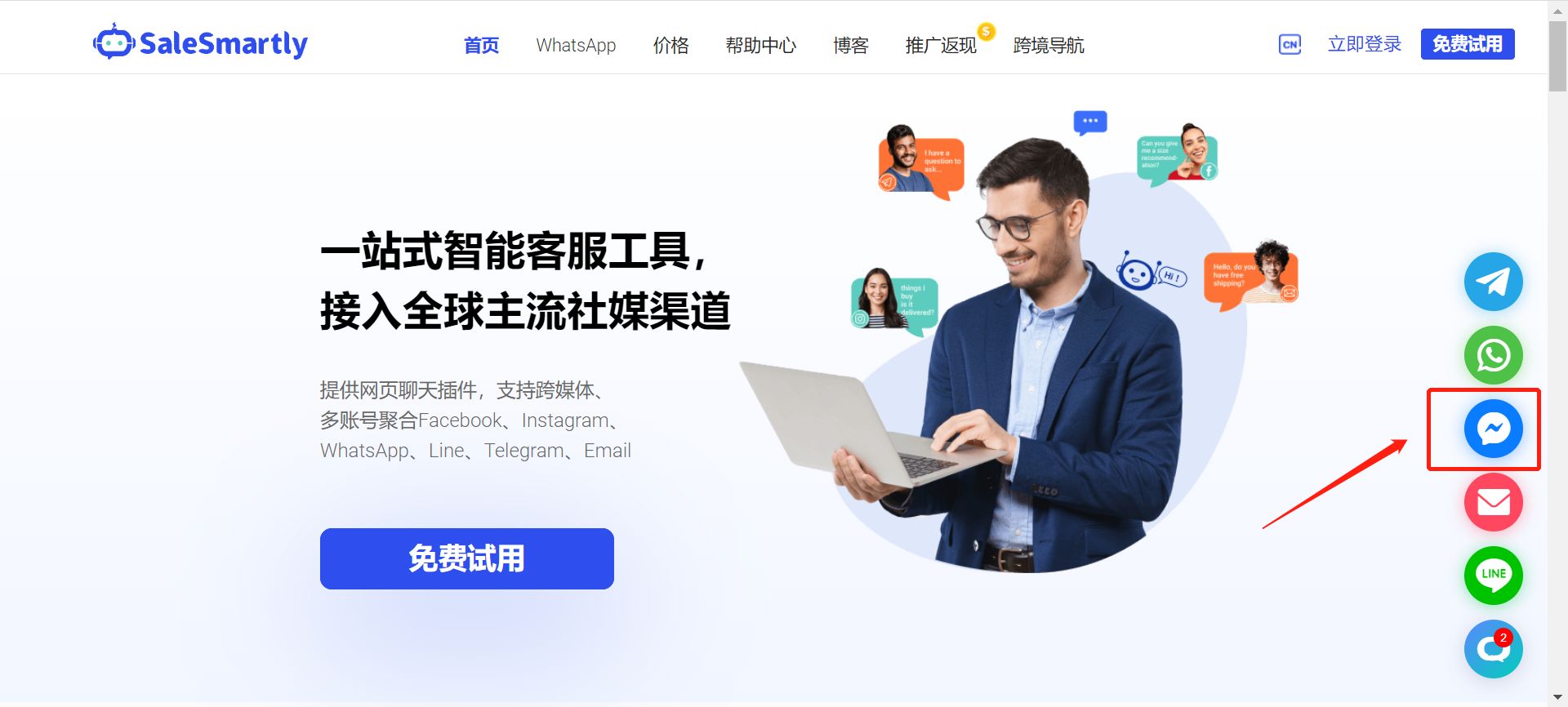
操作指南:如何高效使用Facebook Messenger销售(二)
上一篇文章我们介绍了使用Facebook Messenger作为销售渠道的定义、好处及注意事项,本节我们将详细介绍怎么将Facebook Messenger销售与SaleSmartly(ss客服)结合,实现一站式管理多主页配图来源:SaleSmartly(…...

计算机三级|网络技术|中小型网络系统总体规划与设计方案|IP地址规划技术|2|3
p3 p4一、中小型网络系统总体规划与设计方案网络关键的设备选型路由器技术指标性能指标综述吞吐量背板能力丢包率时延抖动突发处理能力路由表容量服务质量网管能力可靠性和可用性1 吞吐量指路由器的包转发能力,涉及两个内容:端口吞吐量和整机吞吐量&…...
为什么一定要做集成测试?
集成测试,我们都不陌生,几乎我们产品每天都在进行。但是我们真的有好好思考:为什么一定要做集成测试吗?只是为了简单的将“积木”搭起来就行,还是有什么其他的深意? 深意可能不一定会有,但是意…...

前端:CSS
CSS基本语法规则:选择器若干属性声明 style标签:可以放到代码的任意位置处,head/body中都可以 三种写CSS的方式: 1、内部样式:使用style标签,直接把CSS写到html文件中。此时的style标签可以放到任何位置…...
)
CMMI—组织级过程定义(OPD)
大家好,我是Doker 多克!一、目的组织级过程定义(Organizational Process Definition, OPD)的目的在于建立并维护一套可用的组织级过程资产、工作环境标准以及团队规则与指南二、简介组织级过程资产使得整个组织具有一致…...
)
华为OD机试真题Python实现【猜字谜】真题+解题思路+代码(20222023)
猜字谜 题目 小王设计了一个简单的猜字谜游戏,游戏的谜面是一个错误的单词,比如nesw,玩家需要猜出谜底库中正确的单词。 猜中的要求如下: 对于某个谜面和谜底单词,满足下面任一条件都表示猜中: 变换顺序以后一样的,比如通过变换w和e的顺序,nwes跟news是可以完全对应的…...
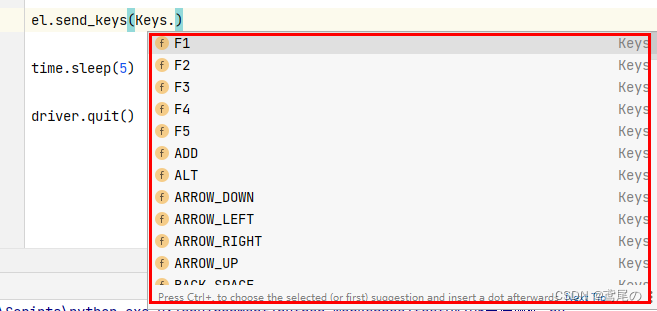
软测入门(三)Selenium(Web自动化测试基础)
Selenium(Web端自动测试) Selenium是一个用于Web应用程序测试的工具:中文是硒 开源跨平台:linux、windows、mac核心:可以在多个浏览器上进行自动化测试多语言 Selenium WebDriver控制原理 Selenium Client Library…...

备战蓝桥杯——sort函数
备战蓝桥杯——sort函数排列字母lambda匿名函数排列字母 链接: 排列字母 不用多说,很简单的签到题,我们先来了解一下sort函数的用法 list.sort(cmpNone, keyNone, reverseFalse) cmp:进行比较的方法(可以自定义排序的方法,通常…...
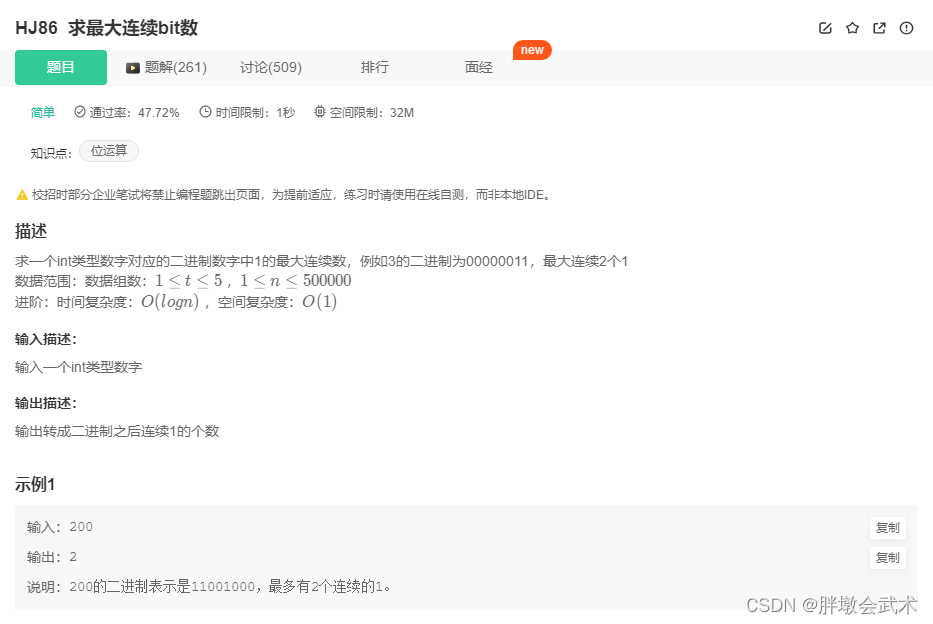
华为机试题:HJ86 求最大连续bit数(python)
文章目录(1)题目描述(2)Python3实现(3)知识点详解1、input():获取控制台(任意形式)的输入。输出均为字符串类型。1.1、input() 与 list(input()) 的区别、及其相互转换方…...

机器学习复习--logistic回归简单的介绍和代码调用
最近需要复习一下机器学习相关知识,记录一下 一、简介 线性回归:h(x)wTxbh(x)w^T x bh(x)wTxb logistic回归就是在线性模型的基础上加上一个sigmoid函数ggg,即h(x)g(wTxb)h(x)g(w^T xb)h(x)g(wTxb)。。。g(z)1/(1e−z)g(z)1/(1e^{-z})g(z)…...
uniapp小程序接入腾讯地图sdk
新建一个项目。配置uniapp配置文件设置小程序的appid注意:匿名用户可能存在地理定位失效。查uniapp官网官网->apiuni.getLocation(OBJECT) 获取当前的地理位置、速度。属性:success匿名函数返回值:uni.getLocation({type: gcj02,success: …...

总结JavaScript中的条件判断与比较运算
一、条件判断 JavaScript 中有三种方法可以用来进行条件判断: 1、使用 if-else 语句。这种方法用于在特定条件为 true 时执行一段代码,否则执行另一段代码。例如: let a 5; if (a > 10) {console.log("a is greater than 10"…...

算法练习-排序(一)
算法练习-排序(一) 文章目录算法练习-排序(一)1 排序算法1.1 冒泡排序1.1.1代码1.2插入排序1.2.1代码1.3 选择排序1.3.1代码1.4归并排序1.4.1代码1.5 快速排序1.5.1 思路1.5.2 代码2 题目2.1 特殊排序2.1.1 题目2.1.2 题解2.2 数组中的第k个最大元素2.2.1 题目2.2.2 题解2.3 对…...

CentOS7.6快速安装Docker
快速安装 官网安装参考手册:https://docs.docker.com/install/linux/docker-ce/centos/ 确定你是CentOS7及以上版本,yum是在线安装! [rootVM-4-5-centos ~]# cat /etc/redhat-releaseCentOS Linux release 7.6.1810 (Core)接下来您只管自上向下执行命令即可&#x…...
CentOS 7安装N卡驱动和CUDA和cuDNN
前言系统一开始是CentOS 7.6,安装依赖时yum给的内核文件的版本号和uname -r的结果不一样,这时不能直接装依赖,装上后后面装驱动时会报错找不到内核头文件(最开始我直接装依赖了,以为高版本兼容低版本,然后装驱动时报错…...

Java开发 - 分页查询初体验
前言在上一篇,我们对es进行了深入讲解,相信看过的小伙伴已经能基本掌握es的使用方法,我们知道,es主要针对的是搜索条件,在这方面es具有无可比拟的优势,但我们也会注意到,有时候搜索条件过于宽泛…...
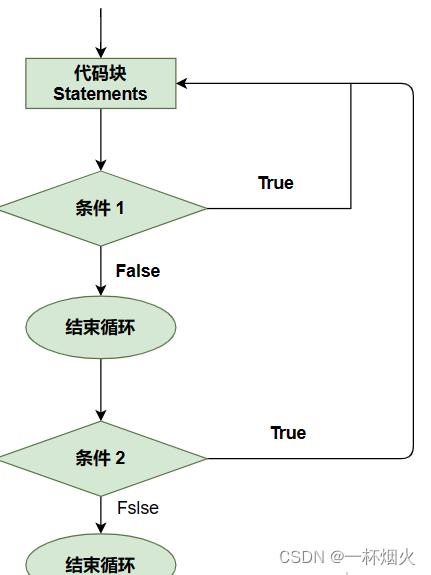
C语言循环语句do while和嵌套循环语句讲解
C do…while 循环 不像 for 和 while 循环,它们是在循环头部测试循环条件。在 C 语言中,do…while 循环是在循环的尾部检查它的条件。 do…while 循环与 while 循环类似,但是 do…while 循环会确保至少执行一次循环。 语法 C 语言中 do…w…...
【7】:拼接图像)
【计算机视觉】OpenCV 4高级编程与项目实战(Python版)【7】:拼接图像
我们已经知道,图像是通过数组描述的,那么拼接图像其实就是拼接数组。NumPy提供了2个拼接数组的函数,分别是hstack函数和vstack函数,这两个拼接函数可以将两个数组水平和垂直拼接在一起,也就相当于将两幅图像水平和垂直拼接在一起,本节将详细讲解如何使用这两个函数水平拼…...
)
GalaxyView和Halcon抢相机?手把手教你解决USB3.0大恒相机驱动冲突(附优先级切换技巧)
多视觉软件共存环境下的USB3.0相机驱动冲突深度解析与实战解决方案 在工业视觉和自动化检测领域,工程师常常需要同时使用多种视觉软件来完成不同的任务。Halcon以其强大的算法库著称,而GalaxyView则在相机控制和图像采集方面表现出色。但当这些软件共存于…...

ARM Cortex-R中断处理与ECC机制详解
1. ARM Cortex-R中断处理机制深度解析在嵌入式实时系统中,中断处理机制的设计直接影响系统的响应速度和可靠性。ARM Cortex-R系列处理器作为面向实时控制应用的处理器架构,其中断处理系统经过精心设计,能够满足工业控制、汽车电子等领域的严苛…...

嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定?
嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定? 在复杂的嵌入式系统中,信号链的完整性往往决定了整个产品的可靠性。想象一下,当你精心设计的传感器数据经过长距离传输后,最终到达MCU时却出现了严…...

基于GitHub Actions的跨平台应用自动化发布流水线实战指南
1. 项目概述:一个开源应用发布管道的诞生在软件开发的日常里,发布环节常常是那个“说起来简单,做起来一团糟”的部分。尤其是在团队协作中,从代码提交到最终用户能下载到安装包,中间要经历构建、测试、签名、打包、上传…...

如何深度定制MPC-HC实现专业级影音播放:终极实战配置指南
如何深度定制MPC-HC实现专业级影音播放:终极实战配置指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc 想要将MPC-HC从普通播放器升级为专业…...
)
用C++和Eigen库手把手实现UR3机械臂逆解(附完整代码与避坑指南)
从理论到实践:基于Eigen库的UR3机械臂逆运动学完整实现指南 在工业自动化和机器人研究领域,六轴协作机械臂因其灵活性和广泛的应用场景而备受关注。UR3作为Universal Robots旗下的紧凑型协作机械臂,凭借其轻量化设计和用户友好特性࿰…...

【技术解析】VadCLIP:如何让视觉语言模型“看懂”视频异常?
1. VadCLIP是什么?为什么视频异常检测需要它? 想象一下你正在监控室盯着几十块屏幕,突然有个画面闪过一个可疑行为——可能是打架、偷窃或者交通事故。传统监控系统要么依赖人工盯屏(容易疲劳漏检),要么使用…...

TypeScript + Next.js + Tailwind CSS 现代Web开发最佳实践模板解析
1. 项目概述:一个现代Web开发的“瑞士军刀”如果你最近在考虑启动一个Next.js项目,并且希望它从一开始就具备现代化的技术栈、清晰的代码结构和高效的开发体验,那么你很可能已经听说过或者正在寻找一个合适的“启动器”。theodorusclarence/t…...

ZYNQ AXI DMA Scatter/Gather模式实战:从PL到PS的高效数据流构建与FreeRTOS任务调度
1. 理解AXI DMA Scatter/Gather模式的核心价值 在ZYNQ平台上构建高效数据流系统时,AXI DMA的Scatter/Gather模式(简称SG模式)绝对是硬件加速的利器。我第一次接触这个功能时,发现它完美解决了传统DMA传输中的两大痛点:…...
)
Shell 相关基础入门,在 Ubuntu 与 CentOS Shell 中的语法差异总结(bash、dash、sh)
新建的test.sh文件,vim进去,每行开头都默认有一个~符号,是什么意思,而且在里面鼠标也失效了? 你问的这两个问题,恰好是初学者刚接触 vim 编辑器时最常遇到的两个困惑。它们完全正常,不是系统出错…...