数据结构奇妙旅程之顺序表和链表
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱
ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客
本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如需转载还请通知˶⍤⃝˶
个人主页:xiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客
系列专栏:xiaoxie的JAVA系列专栏——CSDN博客●'ᴗ'σσணღ*
我的目标:"团团等我💪( ◡̀_◡́ ҂)"( ⸝⸝⸝›ᴥ‹⸝⸝⸝ )欢迎各位→点赞👍 + 收藏⭐️ + 留言📝+关注(互三必回)!
目录
编辑一.顺序表
1.底层实现
2.构造方法
3.常用方法
4.Arrays的遍历方法
编辑5.实战演示
 一.顺序表
一.顺序表
1.底层实现
首先我们要清楚,数据结构是一门逻辑十分清晰的学科,所以我们需要清楚的认识到每个结构的底层是什么,这样才能更好的掌握这个结构。
2.构造方法
public class Text {public static void main(String[] args) {//无参List<Integer> list = new ArrayList<>();//指定顺序表初始容量List<Integer> list1 = new ArrayList<>(20);list1.add(1);list1.add(11);//ArrayList(Collection<? extends E> c) 利用其他 Collection 构建 ArrayListList<Integer> list2 = new ArrayList<>(list1);}
}
3.常用方法
ArrayList是一个普通的类,实现了List接口,所以它实现了许多接口内的方法,博主现在为大家列举出一些常用的方法
List<Integer> list = new ArrayList<>();//尾插入元素list.add(1);list.add(12);list.add(11);//指定位置插入参数为 位置 和 元素list.add(2,3);//顺序表长度list.size();//删除指定位置元素list.remove(2);//是否包含某个元素list.contains(4);//截取部分 listlist.subList(0,1);//获取下标 index 位置元素list.get(2);//将下标 index 位置元素设置为 elementlist.set(3,9);//返回第一个 o 所在下标list.indexOf(8);//返回最后一个 o 的下标list.lastIndexOf(8);
4.Arrays的遍历方法
1.直接输出
List<Integer> list = new ArrayList<>();//尾插入元素list.add(1);list.add(12);list.add(11);System.out.println(list);
2.for循环和for-each
List<Integer> list = new ArrayList<>();//尾插入元素list.add(1);list.add(12);list.add(11);System.out.println("for循环遍历");for (int i = 0; i < list.size(); i++) {System.out.print(list.get(i)+" ");}System.out.println();System.out.println("for-each循环遍历");for (Integer x:list) {System.out.print(x+" ");}
3.使用迭代器
List<Integer> list = new ArrayList<>();//尾插入元素list.add(1);list.add(12);list.add(11);System.out.println("迭代器正序输出");Iterator<Integer>it = list.iterator();while (it.hasNext()) {System.out.print(it.next()+" ");}System.out.println();System.out.println("迭代器逆序输出");ListIterator <Integer> it1 = list.listIterator(list.size());while (it1.hasPrevious()) {System.out.print(it1.previous()+" ");}} 5.实战演示
5.实战演示
杨辉三角 力扣的118题,难度不大,感兴趣的朋友可以去尝试一下
解答代码如下
/*11 1 1 2 11 3 3 11 4 6 4 1 由图可知每一行的第一个为1,最后一个也为一中间部分等于上一行的前一个加上上一行同一列的一个,并且最后一个也为一。
*/
class Solution {public List<List<Integer>> generate(int numRows) {List<Integer> list = new ArrayList<>();List<List<Integer>> ans = new ArrayList<>();list.add(1);//第一行ans.add(list);for(int i = 1;i < numRows;i++) {List<Integer> temp = new ArrayList<>();temp.add(1);//每一行的第一个都为一List<Integer> row =ans.get(i-1);//上一行for(int j = 1; j <i;j++) {int x = row.get(j)+row.get(j-1);//中间部分为上一行的前一个加上上一行同一列的一个temp.add(x);}temp.add(1);//一行的最后一个元素也为1ans.add(temp);}return ans;}
}以上是博主解答这题的思路和代码,时间复杂度为O(n^2)如果你有更好的方法或者是不懂的地方都可以私聊博主,大家一起交流进步
二.链表
1.底层实现
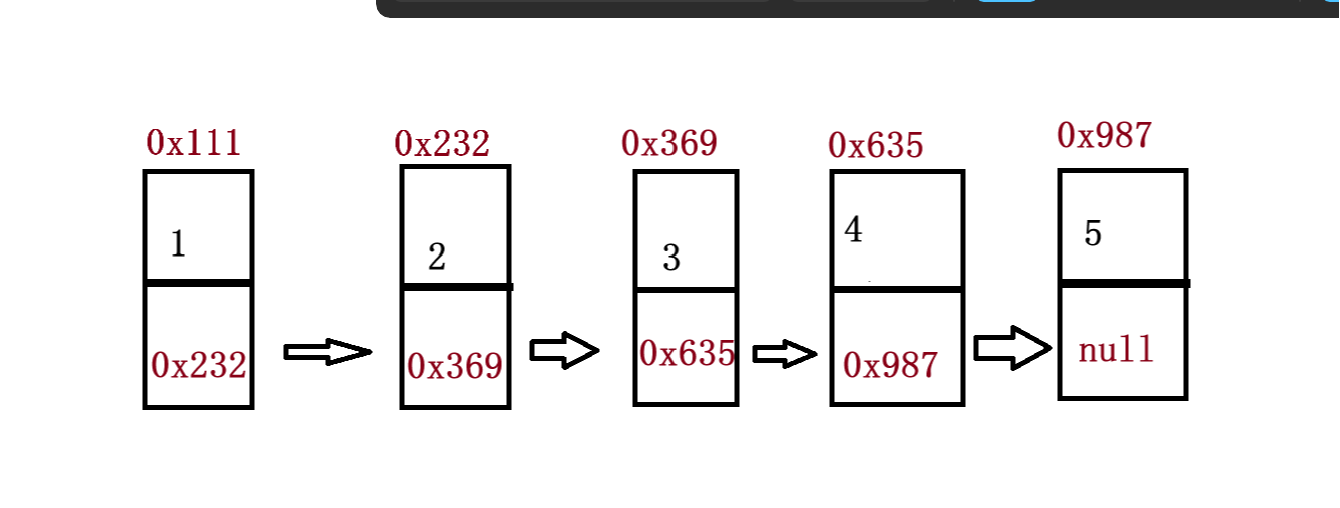
当然链表的结构不仅仅是这一种其他还有1. 单向或者双向 2. 带头或者不带头 3. 循环或者非循环
2.无头单向非循环链表
无头单向非循环链表是一种数据结构,其特点是没有头节点、只有一个指向第一个节点的指针,而且最后一个节点的指针为空(NULL),形成一个单向链表的尾部。这意味着如果需要查找第一个节点,必须从指向第一个节点的指针开始遍历链表。此外,非循环链表是一个单向链表,从第一个节点开始一直到最后一个节点,而最后一个节点指向空(NULL),这样就可以避免链表中的死循环问题。
3.无头双向非循环链表
无头双向非循环链表是一种数据结构,它由多个节点组成,每个节点有两个指针,一个指向前一个节点,一个指向后一个节点。和单向链表不同的是,双向链表可以向前和向后遍历,而且插入和删除节点的操作比较方便。
无头表示链表没有头节点,也就是第一个节点就是链表的起始节点。非循环表示链表没有环,也就是最后一个节点的指针指向 NULL。
在无头双向非循环链表中,我们可以从任意一个节点开始遍历,也可以逆序遍历整个链表。双向链表比单向链表多了一个指针,所以它在一些场景下比单向链表更加方便,比如需要频繁地插入和删除节点时。但是,它也需要更多的内存空间来存储指针。
4.顺序表和链表之间的区别
顺序表和链表是两种数据结构,它们的主要区别在于存储方式和操作效率不同:
-
存储方式不同:顺序表使用一组连续的存储单元存储数据,而链表则使用指针将一组零散的存储单元串联起来。
-
随机访问效率不同:顺序表通过下标可以直接访问任意位置的元素,时间复杂度为O(1),但插入和删除操作需要移动数据,时间复杂度为O(n)。而链表不能通过下标直接访问元素,插入和删除操作只需要修改指针,时间复杂度为O(1),但是随机访问需要遍历整个链表,时间复杂度为O(n)。
-
空间利用率不同:顺序表预先分配存储空间大小固定,当存储空间不够时需要重新分配内存,可能浪费内存。而链表通过动态分配内存,只在需要时才分配所需的存储空间,空间利用率较高。
总之,应根据实际需求选择合适的数据结构,如果需要频繁随机访问,可以选择顺序表;如果需要频繁插入和删除,可以选择链表。
5.链表面试题
1.给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 NULL 链接
public class Solution {// 定义一个方法detectCycle,输入参数为链表头节点head,返回值类型为ListNode(链表节点)public ListNode detectCycle(ListNode head) {// 如果链表为空或只有一个元素,则没有环,直接返回nullif(head == null || head.next == null) {return null;}// 初始化两个指针fast和slow,都指向链表头节点ListNode fast = head;ListNode slow = head;// 使用快慢指针进行遍历while(fast != null && fast.next != null) {// 慢指针每次前进一步slow = slow.next;// 快指针每次前进两步fast = fast.next.next;// 如果快慢指针相遇,则说明存在环if(slow == fast) {break;}}// 如果快指针遍历到链表末尾,说明不存在环,返回nullif(fast == null || fast.next == null) {return null;}// 重新设置快指针fast到链表头节点,慢指针slow保持在相遇点fast = head;// 当快慢指针再次相遇时,相遇点即为环的起点while(slow != fast) {slow = slow.next;fast = fast.next;}// 返回环的起点return fast;}
}2.链表的回文结构链接
public class PalindromeList {// 定义一个方法chkPalindrome,输入参数为链表头节点head,返回值类型为布尔值(true表示是回文链表,false表示不是)public boolean chkPalindrome(ListNode head) {// 如果链表为空,则直接返回true(空链表是回文链表)if(head == null ) {return true;}// 使用快慢指针找到链表的中间结点ListNode fast = head;ListNode slow = head;while(fast != null && fast.next != null) {fast = fast.next.next; // 快指针每次前进一步slow = slow.next; // 慢指针每次前进一步}// 翻转链表后半部分ListNode cur = slow.next;while(cur != null) {ListNode curnext = cur.next;cur.next = slow;slow = cur;cur = curnext;}// 判断翻转后的链表与原链表前半部分是否相等while(head != slow) {if(head.val != slow.val) { // 如果两个节点的值不相等,则说明不是回文链表return false;}if(head.next != slow) { // 奇数情况下,已经比较完所有节点,可以提前结束循环return true;}head = head.next; // 头节点向后移动一位slow = slow.next; // 反转后的尾节点向前移动一位}// 遍历结束后没有发现不相等的节点,说明是回文链表return true;}
}3.将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。链接
public class Partition {// 定义一个方法partition,输入参数为链表头节点head和整数x,返回值类型为ListNode(链表节点)public ListNode partition(ListNode head, int x) {// 如果链表为空,则直接返回nullif(head == null) {return null;}// 初始化两个指针de和dx,用于记录小于x的元素链表的尾节点和当前节点ListNode de = null;ListNode dx = null;// 初始化两个指针pe和px,用于记录大于等于x的元素链表的尾节点和当前节点ListNode pe = null;ListNode px = null;// 初始化一个指针cur,指向链表的头节点ListNode cur = head;// 遍历链表中的每个节点while(cur != null) {// 如果当前节点的值小于xif(cur.val < x) {// 如果小于x的元素链表尚未创建,则将当前节点设置为头节点和尾节点if(de == null) {de = cur;dx = cur;}else { // 否则将当前节点添加到小于x的元素链表的末尾dx.next = cur;dx = dx.next;}}else { // 如果当前节点的值大于等于x// 如果大于等于x的元素链表尚未创建,则将当前节点设置为头节点和尾节点if(pe == null) {pe = cur;px = cur;}else { // 否则将当前节点添加到大于等于x的元素链表的末尾px.next = cur;px = px.next;}}// 指针cur向后移动一位cur = cur.next;}// 如果不存在小于x的元素,则直接返回大于等于x的元素链表if(dx == null) {return pe;}// 将大于等于x的元素链表接到小于x的元素链表的末尾dx.next = pe;// 如果存在大于等于x的元素,则将其尾节点的next指针置为nullif(pe != null) {px.next = null;}// 返回小于x的元素链表的头节点return de;}
}三.结语
数据结构一门逻辑十分严谨的一门学科,而顺序表和链表都是十分基础的结构,也是后续学习的基础,所以应该要多花时间去搞清楚它的底层,好了本文到这里就结束了,感谢您的阅读,祝您一天愉快
相关文章:
数据结构奇妙旅程之顺序表和链表
꒰˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN …...
vitepress的使用
创建项目并启动项目 // 1.创建项目,直接在空项目下安装vitepress(npm/yarn等都可以,这个可以看官网,官网给了好几种安装方式) yarn add -D vitepress // 2.初始化配置项目(npm/官网也给了多种包管理工具的安装方式) npx vitepress init // 初始化命令执行完会遇到以下几个问题…...

Discuz论坛自动采集发布软件
随着网络时代的不断发展,Discuz论坛作为一个具有广泛用户基础的开源论坛系统,其采集全网文章的技术也日益受到关注。在这篇文章中,我们将专心分享通过输入关键词实现Discuz论坛的全网文章采集,同时探讨采集过程中伪原创的发布方法…...

B树在数据库的应用
B树(B-tree)是一种自平衡的树状数据结构,广泛应用于数据库和文件系统等领域,其设计的目标是提供一种高效的插入、删除和查找操作。B树的设计是为了在磁盘等存储介质上存储和操作大量的数据。 主要特点包括: 平衡性&a…...

Android 源码编译
一,虚拟机安装 1.1 进入https://cn.ubuntu.com/download中文官网下载iso镜像 1.2 这里我们下载Ubuntu 18.04 LTS 1.3虚拟VM机安装ubuntu系统,注意编译源码需要至少16G运行内存和400G磁盘空间,尽量设大点 二 配置编译环境 2.1 下载andr…...

信而泰 SSL测试方法介绍
[本文介绍在ALPS平台上进行SSL测试的内容和方法] 什么是SSL SSL全称是Secure Sockets Layer,指安全套接字协议,为基于TCP的应用层协议提供安全连接;SSL介于TCP/IP协议栈的第四层和第五层之间,广泛用于电子商务、网上银行等。 SSL…...
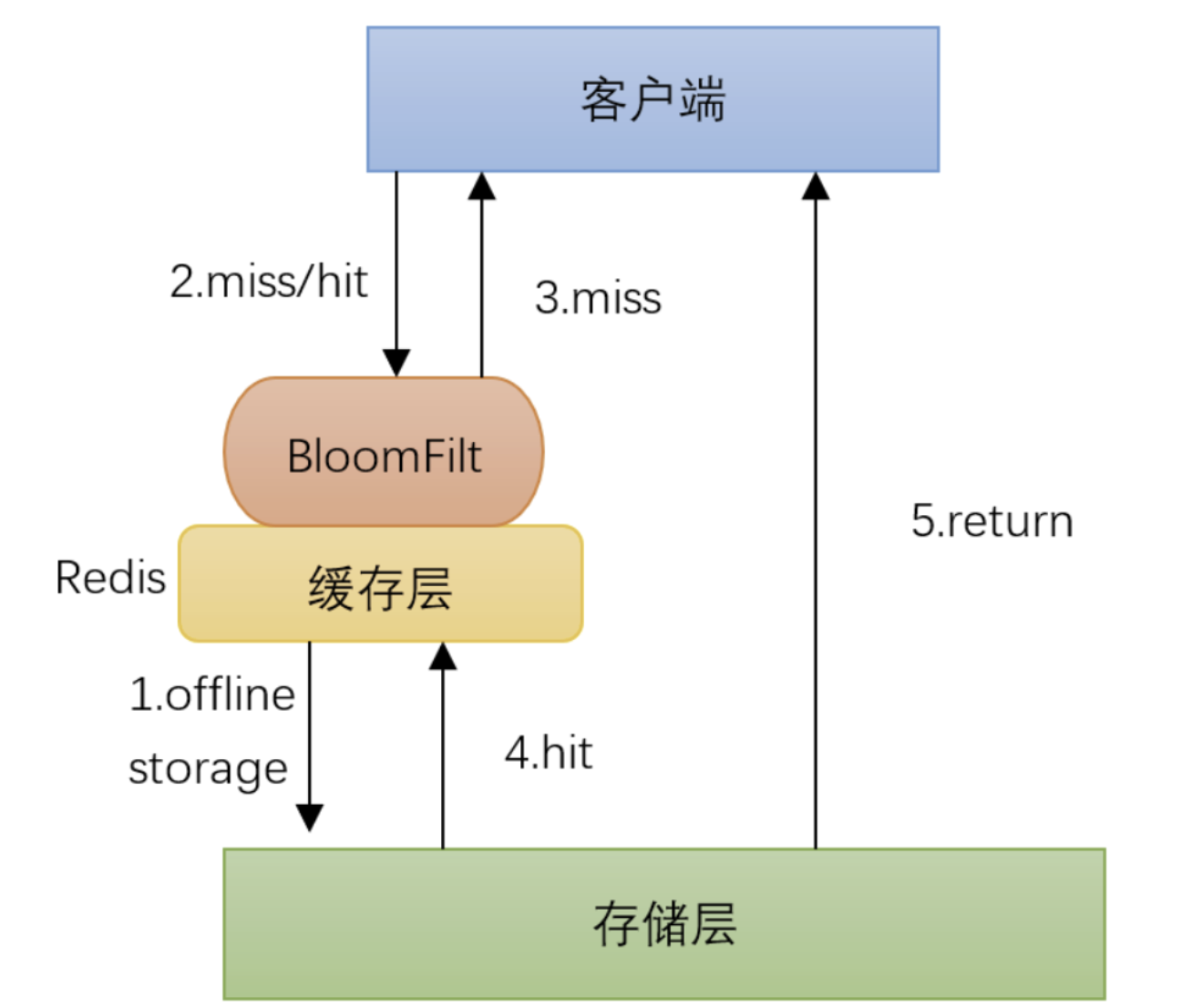
Redis--15--缓存穿透 击穿 雪崩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 缓存穿透 击穿 雪崩运行速度:1 缓存穿透问题描述:如何解决: 2 缓存击穿问题描述:如何解决: 3 缓存雪崩说明:解决方案: 缓存穿透 击穿 雪崩 问题描述: 由于海量的用…...
excel表格在线编辑(开源版)
文章目录 前言一、Luckysheetvue3vite 例子如有启发,可点赞收藏哟~ 前言 本文记录好用的开源在线表格 具体如图显示 另外记录下更名后的univer~,如下图(有兴趣可自行详细了解) univer 在线思维导图 一、Luckysheet 参考git…...

17.字符串处理函数——字符串比较函数
文章目录 前言一、题目描述 二、解题 程序运行代码 总结 前言 本系列为字符串处理函数编程题,点滴成长,一起逆袭。 一、题目描述 二、解题 程序运行代码 #include<stdio.h> #include<string.h> int main() {char *str1 "hello wo…...

【面试HOT200】二叉树——深度优先搜索篇
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于【CodeTopHot200】进行的,每个知识点的修正和深入主要参…...

价值投资选股的方法
价值投资法是一种长期投资策略,其核心思想是寻找被市场低估的股票,即股票的市场价格低于其内在价值。这种策略认为,投资者应该关注公司的基本面,如盈利能力、成长潜力、财务状况等,而不是短期的市场波动。以下是价值投…...

java中如何将mysql里面的数据取出来然后通过stream流的方式进行数据处理代码实例?
在 Java 中使用 Stream 流的方式从 MySQL 数据库中取出数据并进行处理,你可以通过 JDBC(Java Database Connectivity)来实现。下面是一个简单的代码示例: import java.sql.*; import java.util.stream.Stream; public class MySQ…...

C++服务器 支持http、tcp protobuf、websocket,linux开源框架 零依赖轻松编译部署 Reactor
开源地址: https://github.com/crust-hub/tubekit/tree/main Github:https://github.com/gaowanlu 诚招有兴趣的小伙伴加入开发维护 Tubekit The C TCP server framework based on the Reactor model continues to implement POSIX thread pool, Epoll, non blocking IO, obj…...

1688API接口系列,1688开放平台接口使用方案(商品详情数据+搜索商品列表+商家订单类)
1688商品详情接口是指1688平台提供的API接口,用于获取商品详情信息。通过该接口,您可以获取到商品的详细信息,包括商品标题、价格、库存、描述、图片等。 要使用1688商品详情接口,您需要先申请1688的API权限,并获取ac…...
CentOS服务器网页版Rstudio-server及R包批量安装最佳实践
CentOS服务器安装网页版Rstudio-server及R包批量安装 以下为CentOS 7/8的Rstudio-server安装、配置和R包安装操作 1. 软件包安装 Centos 7安装 # 下载安装包,大小115.14 MB wget -c https://download2.rstudio.org/server/centos7/x86_64/rstudio-server-rhel-…...

centos7内核升级(k8s基础篇)
1.查看系统内核版本信息 uname -r 2.升级内核 2.1更新yum源仓库 yum -y update更新完成后,启用 ELRepo 仓库并安装ELRepo仓库的yum源 ELRepo 仓库是基于社区的用于企业级 Linux 仓库,提供对 RedHat Enterprise (RHEL) 和 其他基于 RHEL的 Linux 发行…...

数据结构与算法设计分析——NP完全理论
目录 一、P类问题与NP类问题的定义二、常见的NP类问题(一)旅行商问题(TSP)(二)哈密尔顿回路问题(三)判断回路问题(四)图的着色问题(五)…...
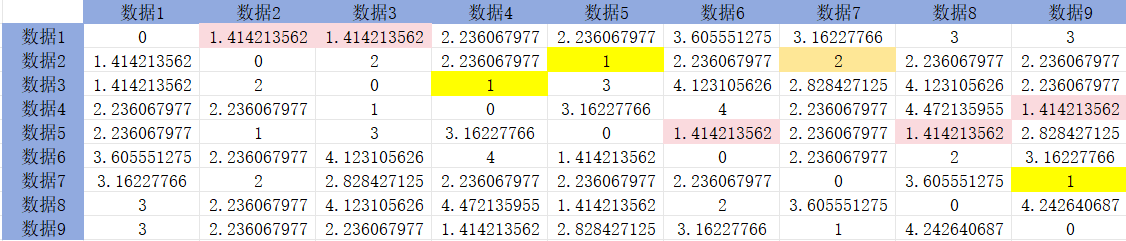
AGNES层次聚类
已知数据集D中有9个数据点,分别是(1,2),(2,3),(2,1), (3,1),(2,4),(3,5),(4,3),(1,5),(4,2)。要求: (1)采用层次聚类的聚集算法进行聚类,k2。 (2)距离计算采用欧几里得距离。 (3)簇之间的距离采用单链接方…...
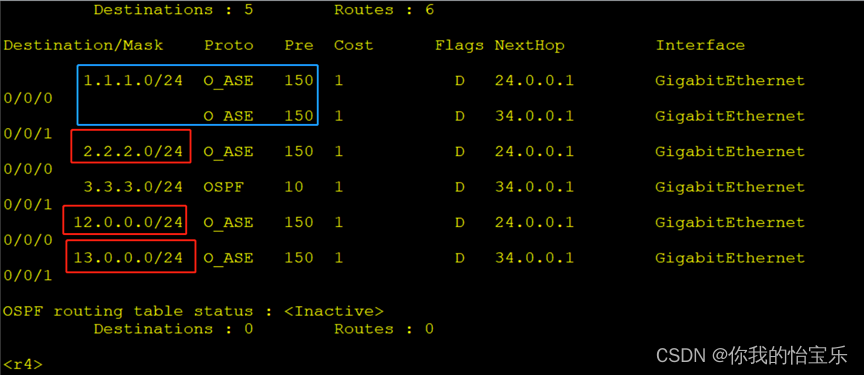
HCIP —— 双点重发布 + 路由策略 实验
目录 实验拓扑: 实验要求: 实验配置: 1.配置IP地址 2.配置动态路由协议 —— RIP 、 OSPF R1 RIP R4 OSPF R2 配置RIP、OSPF 双向重发布 R3配置RIP、OSPF 双向重发布 3.查询路由表学习情况 4.使用路由策略控制选路 R2 R3 5.检…...

Python标准库:datetime模块【侯小啾python领航班系列(二十五)】
Python标准库:datetime模块【侯小啾python领航班系列(二十五)】 大家好,我是博主侯小啾, 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ…...

localForage性能监控终极指南:实时追踪存储操作的关键指标
localForage性能监控终极指南:实时追踪存储操作的关键指标 【免费下载链接】localForage 💾 Offline storage, improved. Wraps IndexedDB, WebSQL, or localStorage using a simple but powerful API. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...

四通道32孔生物源性检测仪 肉源性检测仪器
四通道32孔生物源性检测仪搭载四通道48孔高通量检测架构,本少、效率低的短板,大幅提升肉类质检筛查效率。多通道独立运行互不干扰,可一次性完成大批量肉类样本同步检测设备检测精度优异,可精准识别各类常见动物源性成分࿰…...

ONLYOFFICE集成踩坑实录:90%的“内容丢失”和“版本已更新”都因为document.key用错了
在集成OnlyOffice DocumentServer的过程中,很多开发者都会遇到两个非常典型的问题: 多人协同编辑后,再次打开文档发现内容缺失重新打开文档时提示“文档版本已更新” 很多人会认为: 是 ONLYOFFICE 不稳定是缓存机制异常是协同编…...

紧急预警:Midjourney即将关闭--style raw参数入口!最后48小时掌握赛博朋克硬核写实风格迁移技巧
更多请点击: https://intelliparadigm.com 第一章:紧急预警:Midjourney即将关闭--style raw参数入口!最后48小时掌握赛博朋克硬核写实风格迁移技巧 立即行动:锁定--style raw的最后窗口期 Midjourney v6.9 已悄然启动…...

Codex 小步迭代详解与操作指南
1. 文档目标 这份文档的目标,是帮助你从“一步到位思维”切换到“小步迭代思维”。 读完之后,你应该能够: 理解为什么 Codex 更适合小步迭代,而不是一次性大改掌握一套稳定的小步迭代操作流程知道每一步应该让 Codex 做多大范围的…...

观察智能体项目使用 Taotoken 后的月度 token 消耗与成本趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察智能体项目使用 Taotoken 后的月度 token 消耗与成本趋势 对于一个持续运行的智能体项目而言,清晰的成本洞察是项目…...

2026 汽车运动权威盘点:历史悠久、级别最高的标杆赛事解读
在汽车产业飞速发展的今天,汽车运动早已超越单纯的竞技比拼,成为彰显工业实力、传递汽车文化、连接产业与消费者的重要桥梁。2026 年,全球汽车运动市场持续升温,国际顶级赛事与国内标杆赛事同频共振、百花齐放。而那些历史悠久、级…...

3步完成NCM转MP3:网易云音乐格式转换终极指南
3步完成NCM转MP3:网易云音乐格式转换终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐下载的NCM格式文件无法在其他设备播放而烦恼?这款开源NCMDump工具为你提供完美的解决方案&a…...

如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析
如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析 【免费下载链接】Node.js-Design-Patterns-Third-Edition Node.js Design Patterns Third Edition, published by Packt 项目地址: https://gitcode.com/gh_mirrors/no/Node.js-Design-Pa…...

自建个人知识管理系统Memex:从数据捕获到知识图谱的实践
1. 项目概述:一个私人数字记忆库的诞生几年前,我开始意识到一个严重的问题:我的数字生活正在变得支离破碎。一篇在浏览器里偶然看到的深度文章,一个在社交媒体上转瞬即逝的灵感火花,一段在播客里听到的精彩论述&#x…...