pandas 基础操作3
数据删减
虽然我们可以通过数据选择方法从一个完整的数据集中拿到我们需要的数据,但有的时候直接删除不需要的数据更加简单直接。Pandas 中,以 .drop 开头的方法都与数据删减有关。
DataFrame.drop 可以直接去掉数据集中指定的列和行。一般在使用时,我们指定 labels 标签参数,然后再通过 axis 指定按列或按行删除即可。当然,你也可以通过索引参数删除数据,具体查看官方文档。
axis=0或axis='index':删除行。这是默认设置。axis=1或axis='columns':删除列。
df.drop(labels=['Median Age', 'Total Males'], axis=1)
DataFrame.drop_duplicates 则通常用于数据去重,即剔除数据集中的重复值。使用方法非常简单,默认情况下,它会根据所有列删除重复的行。也可以使用 subset 指定要删除的特定列上的重复项,要删除重复项并保留最后一次出现,请使用 keep=‘last’。
一个删除列的例子
在 Pandas 中,删除 DataFrame 的列通常通过指定列的名称来完成。你不需要直接写列数(索引),而是使用列的名称。例如,如果你的 DataFrame 是这样的:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
现在假设你想删除列 'B',你可以这样做:
df = df.drop('B', axis=1)
这里 'B' 是列的名称,axis=1 指定了你想删除的是列,而不是行(行是 axis=0)。这种方法避免了直接使用列的数值索引,使代码更加清晰易懂。
[DataFrame.drop_duplicates] 则通常用于数据去重,即剔除数据集中的重复值。使用方法非常简单,默认情况下,它会根据所有列删除重复的行。也可以使用 subset 指定要删除的特定列上的重复项,要删除重复项并保留最后一次出现,请使用 keep=‘last’。
除此之外,另一个用于数据删减的方法 [DataFrame.dropna] 也十分常用,其主要的用途是删除缺少值,即数据集中空缺的数据列或行。
数据填充
既然提到了数据删减,反之则可能会遇到数据填充的情况。而对于一个给定的数据集而言,我们一般不会乱填数据,而更多的是对缺失值进行填充。
在真实的生产环境中,我们需要处理的数据文件往往没有想象中的那么美好。其中,很大几率会遇到的情况就是缺失值。缺失值主要是指数据丢失的现象,也就是数据集中的某一块数据不存在。除此之外、存在但明显不正确的数据也被归为缺失值一类。例如,在一个时间序列数据集中,某一段数据突然发生了时间流错乱,那么这一小块数据就是毫无意义的,可以被归为缺失值。
检测缺失值
Pandas 为了更方便地检测缺失值,将不同类型数据的缺失均采用 NaN 标记。这里的 NaN 代表 Not a Number,它仅仅是作为一个标记。例外是,在时间序列里,时间戳的丢失采用 NaT 标记。
Pandas 中用于检测缺失值主要用到两个方法,分别是:isna() 和 notna(),故名思意就是「是缺失值」和「不是缺失值」。默认会返回布尔值用于判断。
接下来,我们人为生成一组包含缺失值的示例数据。
df = pd.DataFrame(np.random.rand(9, 5), columns=list('ABCDE'))
# 插入 T 列,并打上时间戳
df.insert(value=pd.Timestamp('2017-10-1'), loc=0, column='Time')
# 将 1, 3, 5 列的 2,4,6,8 行置为缺失值
df.iloc[[1, 3, 5, 7], [0, 2, 4]] = np.nan
# 将 2, 4, 6 列的 3,5,7,9 行置为缺失值
df.iloc[[2, 4, 6, 8], [1, 3, 5]] = np.nan
df
| Time | A | B | C | D | E | |
|---|---|---|---|---|---|---|
| 0 | 2017-10-01 | 0.604915 | 0.205769 | 0.265589 | 0.133621 | 0.348693 |
| 1 | NaT | 0.731832 | NaN | 0.110929 | NaN | 0.430827 |
| 2 | 2017-10-01 | NaN | 0.243280 | NaN | 0.927472 | NaN |
| 3 | NaT | 0.514475 | NaN | 0.616544 | NaN | 0.314332 |
| 4 | 2017-10-01 | NaN | 0.951334 | NaN | 0.620587 | NaN |
| 5 | NaT | 0.279080 | NaN | 0.298142 | NaN | 0.527567 |
| 6 | 2017-10-01 | NaN | 0.345831 | NaN | 0.023264 | NaN |
| 7 | NaT | 0.522263 | NaN | 0.757472 | NaN | 0.072000 |
| 8 | 2017-10-01 | NaN | 0.928859 | NaN | 0.718561 | NaN |
首先,我们可以用相同的标量值替换 NaN,比如用 0。
df.fillna(0)
除了直接填充值,我们还可以通过参数,将缺失值前面或者后面的值填充给相应的缺失值。例如使用缺失值前面的值进行填充:
df.fillna(method='pad') #使用缺失值前面的数填补
df.fillna(method='bfill') #使用缺失值后面的数填补
上面的例子中,我们的缺失值是间隔存在的。那么,如果存在连续的缺失值是怎样的情况呢?试一试。首先,我们将数据集的第 2,4 ,6 列的第 3,5 行也置为缺失值。
df.iloc[[3, 5], [1, 3, 5]] = np.nan
df
| Time | A | B | C | D | E | |
|---|---|---|---|---|---|---|
| 0 | 2017-10-01 | 0.604915 | 0.205769 | 0.265589 | 0.133621 | 0.348693 |
| 1 | NaT | 0.731832 | NaN | 0.110929 | NaN | 0.430827 |
| 2 | 2017-10-01 | NaN | 0.243280 | NaN | 0.927472 | NaN |
| 3 | NaT | NaN | NaN | NaN | NaN | NaN |
| 4 | 2017-10-01 | NaN | 0.951334 | NaN | 0.620587 | NaN |
| 5 | NaT | NaN | NaN | NaN | NaN | NaN |
| 6 | 2017-10-01 | NaN | 0.345831 | NaN | 0.023264 | NaN |
| 7 | NaT | 0.522263 | NaN | 0.757472 | NaN | 0.072000 |
| 8 | 2017-10-01 | NaN | 0.928859 | NaN | 0.718561 | NaN |
下面的操作是基于上面的表格来的,不互相影响
可以看到,连续缺失值也是按照前序数值进行填充的,并且完全填充。这里,我们可以通过 limit= 参数设置连续填充的限制数量。
填充一项
df.fillna(method='pad', limit=1) # 最多填充一项
| Time | A | B | C | D | E | |
|---|---|---|---|---|---|---|
| 0 | 2017-10-01 | 0.604915 | 0.205769 | 0.265589 | 0.133621 | 0.348693 |
| 1 | 2017-10-01 | 0.731832 | 0.205769 | 0.110929 | 0.133621 | 0.430827 |
| 2 | 2017-10-01 | 0.731832 | 0.243280 | 0.110929 | 0.927472 | 0.430827 |
| 3 | 2017-10-01 | NaN | 0.243280 | NaN | 0.927472 | NaN |
| 4 | 2017-10-01 | NaN | 0.951334 | NaN | 0.620587 | NaN |
| 5 | 2017-10-01 | NaN | 0.951334 | NaN | 0.620587 | NaN |
| 6 | 2017-10-01 | NaN | 0.345831 | NaN | 0.023264 | NaN |
| 7 | 2017-10-01 | 0.522263 | 0.345831 | 0.757472 | 0.023264 | 0.072000 |
| 8 | 2017-10-01 | 0.522263 | 0.928859 | 0.757472 | 0.718561 | 0.072000 |
正向填充多项:
df.fillna(method='pad')
| Time | A | B | C | D | E | |
|---|---|---|---|---|---|---|
| 0 | 2017-10-01 | 0.604915 | 0.205769 | 0.265589 | 0.133621 | 0.348693 |
| 1 | 2017-10-01 | 0.731832 | 0.205769 | 0.110929 | 0.133621 | 0.430827 |
| 2 | 2017-10-01 | 0.731832 | 0.243280 | 0.110929 | 0.927472 | 0.430827 |
| 3 | 2017-10-01 | 0.731832 | 0.243280 | 0.110929 | 0.927472 | 0.430827 |
| 4 | 2017-10-01 | 0.731832 | 0.951334 | 0.110929 | 0.620587 | 0.430827 |
| 5 | 2017-10-01 | 0.731832 | 0.951334 | 0.110929 | 0.620587 | 0.430827 |
| 6 | 2017-10-01 | 0.731832 | 0.345831 | 0.110929 | 0.023264 | 0.430827 |
| 7 | 2017-10-01 | 0.522263 | 0.345831 | 0.757472 | 0.023264 | 0.072000 |
| 8 | 2017-10-01 | 0.522263 | 0.928859 | 0.757472 | 0.718561 | 0.072000 |
除了上面的填充方式,还可以通过 Pandas 自带的求平均值方法等来填充特定列或行。举个例子:
df.fillna(df.mean()['C':'E'])
相关文章:

pandas 基础操作3
数据删减 虽然我们可以通过数据选择方法从一个完整的数据集中拿到我们需要的数据,但有的时候直接删除不需要的数据更加简单直接。Pandas 中,以 .drop 开头的方法都与数据删减有关。 DataFrame.drop 可以直接去掉数据集中指定的列和行。一般在使用时&am…...
开发知识点-Maven包管理工具
Maven包管理工具 SpringBootSpringSecuritydubbo图书电商后台实战-环境设置(JDK8, STS, Maven, Spring IO, Springboot)点餐小程序Java版本的选择和maven仓库的配置视频管理系统&&使用maven-tomcat7插件运行web工程SpringTool suite——maven项目…...

104. 二叉树的最大深度
104. 二叉树的最大深度 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNode right…...

JAVA毕业设计113—基于Java+Springboot+Vue的体育馆预约系统(源代码+数据库+12000字论文)
基于JavaSpringbootVue的体育馆预约系统(源代码数据库12000字论文)113 一、系统介绍 本项目前后端分离,本系统分为管理员、用户两种角色 用户角色包含以下功能: 注册、登录、场地(查看/预订/收藏/退订)、在线论坛、公告查看、我的预订管理、我的收藏…...
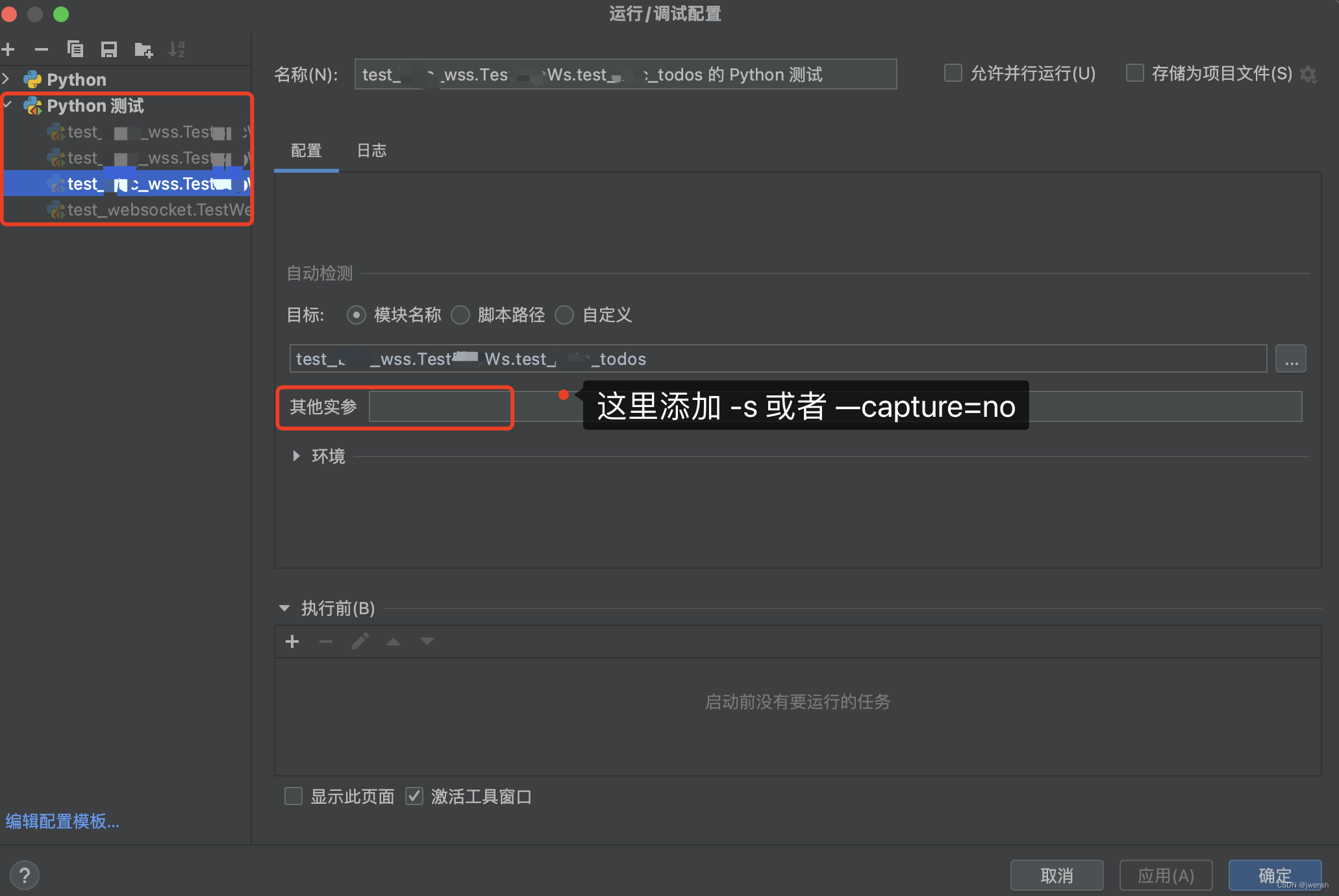
【自动化测试】pytest 用例执行中print日志实时输出
author: jwensh date: 20231130 pycharm 中 pytest 用例执行中 print 日志 standout 实时命令行输出 使用场景 在进行 websocket 接口进行测试的时候,希望有一个 case 是一直执行并接受接口返回的数据 def on_message(ws, message):message json.loads(message)…...

【深度学习】KMeans中自动K值的确认方法
1 前言 聚类常用于数据探索或挖掘前期,在没有做先验经验的背景下做的探索性分析,也适用于样本量较大情况下的数据预处理等方面工作。例如针对企业整体用户特征,在未得到相关知识或经验之前先根据数据本身特点进行用户分群,然后再…...

github问题解决(持续更新中)
1、ssh: connect to host github.com port 22: Connection refused 从.ssh文件夹中新建文件名为config,内容为: Host github.com Hostname ssh.github.com Port 4432、解决 git 多用户提交切换问题 使用系统命令ssh创建rsa公私秘钥 C:\Users\fyp01&g…...
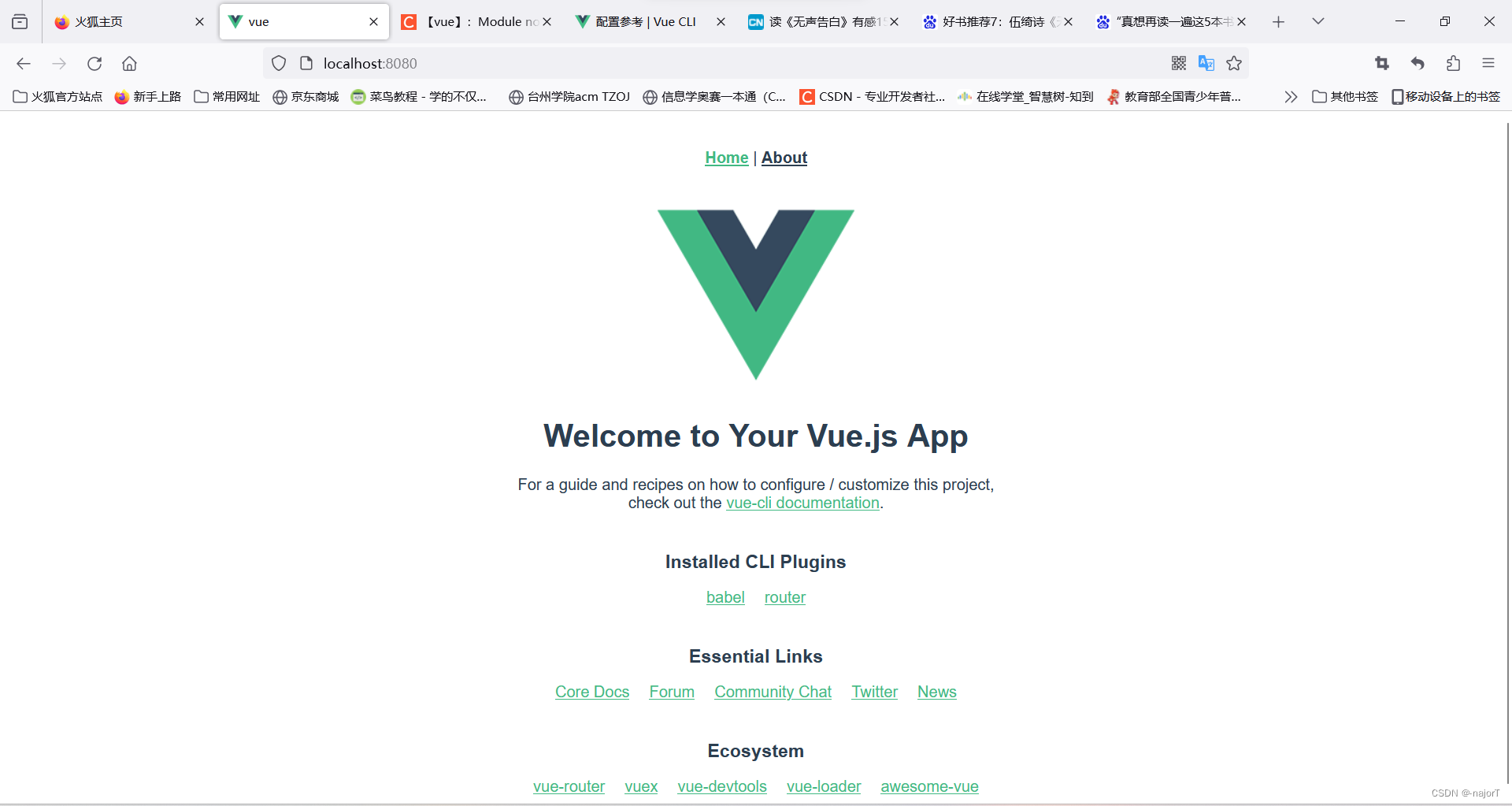
如何创建一个vue工程
1.打开vue安装网址:安装 | Vue CLI (vuejs.org) 2.创建一个项目文件夹 3.复制地址 4.打开cmd,进入这个地址 5.复制粘贴vue网页的安装命令 npm install -g vue/cli 6.创建vue工程 vue create vue这里可以通过上下键来进行选择。选最后一个选项按回车。 …...
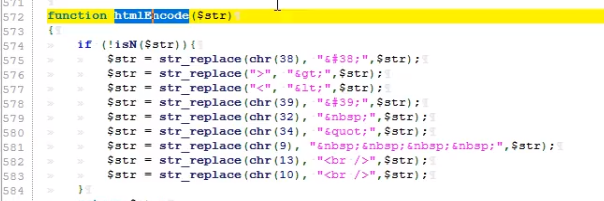
50 代码审计-PHP无框架项目SQL注入挖掘技巧
目录 演示案例:简易SQL注入代码段分析挖掘思路QQ业务图标点亮系统挖掘-数据库监控追踪74CMS人才招聘系统挖掘-2次注入应用功能(自带转义)苹果CMS影视建站系统挖掘-数据库监控追踪(自带过滤) 技巧分析:总结: demo段指的是代码段,先…...

基于Spring、SpringMVC、MyBatis的企业博客网站
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring、SpringMVC、MyBatis的企业博…...
spring日志输出到elasticsearch
1.maven <!--日志elasticsearch--><dependency><groupId>com.agido</groupId><artifactId>logback-elasticsearch-appender</artifactId><version>3.0.8</version></dependency><dependency><groupId>net.l…...

谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通
本心、输入输出、结果 文章目录 谷歌 Gemini 模型发布计划推迟:无法可靠处理部分非英语沟通前言由谷歌 CEO 桑达尔・皮查伊做出决策从一开始,Gemini 的目标就是多模态、高效集成工具、API花有重开日,人无再少年实践是检验真理的唯一标准 谷歌…...

Ubuntu显卡及内核更新问题
显卡安装(2023.12.04) # 查看显卡型号 lspci | grep -i nvidia # 卸载原nvidia 显卡驱动 sudo apt-get --purge remove nvidia*# 禁用nouveau(nouveau是ubuntu自带显卡驱动) sudo gedit /etc/modprobe.d/blacklist.conf # 新增2行…...

SpringBoot错误处理机制解析
SpringBoot错误处理----源码解析 文章目录 1、默认机制2、使用ExceptionHandler标识一个方法,处理用Controller标注的该类发生的指定错误1).局部错误处理部分源码2).测试 3、 创建一个全局错误处理类集中处理错误,使用Controller…...
牛客剑指offer刷题模拟篇
文章目录 顺时针打印矩阵题目思路代码实现 扑克牌顺子题目思路代码实现 把字符串转换成整数题目思路代码实现 表示数值的字符串题目思路代码实现 顺时针打印矩阵 题目 描述 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如…...

Locust单机多核压测,以及主从节点的数据通信处理!
一、背景 这还是2个月前做的一次接口性能测试,关于locust脚本的单机多核运行,以及主从节点之间的数据通信。 先简单交代下背景,在APP上线之前,需要对登录接口进行性能测试。经过评估,我还是优先选择了locust来进行脚…...

ERROR: [pool www] please specify user and group other than root
根据提供的日志信息,PHP-FPM 服务未能启动的原因是配置文件中的一个错误。错误消息明确指出了问题所在: [29-Nov-2023 14:28:26] ERROR: [pool www] please specify user and group other than root [29-Nov-2023 14:28:26] ERROR: FPM initialization …...

京东商品详情接口在电商行业中的重要性及实时数据获取实现
一、引言 随着电子商务的快速发展,商品信息的准确性和实时性对于电商行业的运营至关重要。京东作为中国最大的电商平台之一,其商品详情接口在电商行业中扮演着重要的角色。本文将深入探讨京东商品详情接口的重要性,并介绍如何通过API实现实时…...

WT2003H MP3语音芯片方案:强大、灵活且易于集成的音频解决方案
在当今的数字化时代,音频技术的普遍性已不容忽视。从简单的音乐播放,到复杂的语音交互,音频技术的身影无处不在。在这个背景下,WT2003H MP3语音芯片方案应运而生,它提供了一种强大、灵活且易于集成的音频解决方案。 1…...

机器学习深度学学习分类模型中常用的评价指标总结记录与代码实现说明
在机器学习深度学习算法模型大开发过程中,免不了要对算法模型进行对应的评测分析,这里主要是总结记录分类任务中经常使用到的一些评价指标,并针对性地给出对应的代码实现,方便读者直接移植到自己的项目中。 【混淆矩阵】 混淆矩阵…...

淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟
淘金币自动化脚本:3分钟完成淘宝全任务,每天节省20分钟 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojin…...

别再只用BigGantt了!这个免费JIRA甘特图插件Gantt Suite,配置简单速度快
轻量高效的JIRA甘特图解决方案:Gantt Suite全面评测与迁移指南 在项目管理领域,甘特图作为可视化排期的黄金标准已有百年历史。然而当这一经典工具遇上现代敏捷开发平台JIRA时,许多团队却陷入了两难境地——要么忍受BigGantt等老牌插件的臃肿…...

ICC II里做CTS,除了点‘clock_opt’,这些隐藏选项你真的都配好了吗?
ICC II时钟树综合实战:CTS隐藏选项配置全解析与QoR调优指南 在超大规模集成电路设计中,时钟树综合(CTS)的质量直接影响芯片性能、功耗和面积三大关键指标。当项目进展到后期阶段,工程师常会遇到这样的困境:…...

北京AGG聚砂吸声板哪家性价比高
在选择AGG聚砂吸声板时,“性价比”往往不只是看价格,而是综合考量声学性能、施工服务、材料稳定性和后期维护的平衡。北京市场上的供应商不少,但真正能长期稳定输出成熟产品的,需要从几个实际角度去判断。首先,要优先看…...

告别答辩PPT焦虑:百考通AI如何智能化解你的毕业展示难题
当你终于为论文画上最后一个句号,准备迎接毕业的曙光时,答辩PPT的制作却往往成为压垮学生的最后一根稻草。面对这份看似简单却暗藏玄机的任务,百考通AI为你提供智能解决方案。 深夜,当你的论文最后一个字终于落定,一种…...

练了半年演讲口才,汇报时还是结巴,说说我的真实感受
小林坐在会议室的角落,手心微微出汗。轮到他汇报季度项目进展时,他深吸一口气站起来——结果,开场白磕磕绊绊,PPT翻到第三页才找回节奏。散会后他苦笑着跟同事说:“演讲口才课我上了半年了,怎么还是这副德行…...

游戏平台硬件开发:定制化与长期稳定的挑战
1. 游戏平台硬件开发的特殊挑战在游戏平台开发领域,硬件选型往往面临着一个两难选择:是采用现成的通用组件(Off The Shelf Components),还是投入高昂成本进行完全定制化开发?过去十年间,我参与过…...

终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略
终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略 【免费下载链接】sqlc Generate type-safe code from SQL 项目地址: https://gitcode.com/gh_mirrors/sq/sqlc sqlc是一个强大的工具,能够从SQL生成类型安全的代码,帮…...

从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的
从“意大利面”到整洁代码:我是如何用SonarQube重构遗留项目的 接手一个结构混乱的遗留项目,就像面对一盘煮过头的意大利面——各种逻辑纠缠不清,随便动一处就可能引发连锁反应。去年我遇到这样一个Java项目:12万行代码࿰…...

大模型上手指南:从跑通到解剖,一步步深入核心机制!
本文提供了一套从零开始、由浅入深的实践路径,指导读者如何系统性地分析和学习大模型。首先通过配置环境、加载本地模型并成功进行推理,让读者直观感受模型运行。接着,结合运行结果回顾 Transformer、Tokenization 等核心概念,并探…...