kafka的详细安装部署
introduce
Kafka是一个分布式流处理平台,主要用于处理高吞吐量的实时数据流。Kafka最初由LinkedIn公司开发,现在由Apache Software Foundation维护和开发。
Kafka的核心是一个分布式发布-订阅消息系统,它可以处理大量的消息流,并将它们传递给多个消费者。Kafka的消息被组织成多个主题(Topic),每个主题可以有多个分区(Partition),每个分区可以有多个副本(Replica)。生产者(Producer)将消息发布到主题中,消费者(Consumer)从主题中订阅消息并处理它们。
Kafka的设计目标是高吞吐量、低延迟、高可靠性和可扩展性。它使用了一些优秀的技术来实现这些目标,如零拷贝技术、批量处理、压缩、异步IO等。Kafka还提供了许多额外的功能,如流处理、连接器(Connectors)和管理工具。
Kafka已经被广泛应用于许多领域,如日志收集、事件处理、实时分析、监控等。它是一个高性能、可靠、可扩展的分布式流处理平台,可以帮助企业更好地处理和管理海量数据。
server
| software | hostname | ip | version | configuration |
| zookeeper/kafka | kafka1 | 192.168.58.158 | centos7 | 2G |
| zookeeper/kafka | kafka2 | 192.168.58.159 | centos7 | 2G |
| zookeeper/kafka | kafka3 | 192.168.58.160 | centos7 | 2G |
software version:jdk-8u121-linux-x64.tar.gz、kafka_2.11-2.0.0.tgz
示例节点:192.168.58.158
1.安装配置jdk8
(1)Kafka、Zookeeper(简称:ZK)运行依赖jdk8 (三台均安装)
[root@kafka1 ~]# tar zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
[root@kafka1 ~]# mv /usr/local/jdk1.8.0_211 /usr/local/java
[root@kafka1 ~]# echo '
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' > /etc/profile.d/java.sh
[root@kafka1 ~]# source /etc/profile.d/java.sh2.安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。(三台服务器均安装)
(1)安装
[root@kafka1 ~]# tar zxvf kafka_2.11-2.0.0.tgz -C /usr/local/
(2)配置
[root@kafka1 ~]# echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.58.158:2888:3888
server.2=192.168.58.159:2888:3888
server.3=192.168.58.160:2888:3888
'> /usr/local/kafka_2.11-2.0.0/config/zookeeper.properties
配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
创建目录
创建data、log目录
[root@kafka1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@kafka2 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
[root@kafka3 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
创建myid文件(此处的myid文件需与相应的IP地址对应,否则可能会出现拒绝连接的错误)
# 创建myid文件
[root@kafka1 ~]# echo 1 > /opt/data/zookeeper/data/myid
[root@kafka1 ~]# echo 2 > /opt/data/zookeeper/data/myid
[root@kafka1 ~]# echo 3 > /opt/data/zookeeper/data/myid
3.配置Kafka
(1)配置
kafka1 192.168.58.158 1
kafka2 192.168.58.159 2
kafka3 192.168.58.160 3
[root@kafka1 ~]# cat /usr/local/kafka_2.11-2.0.0/config/server.properties
broker.id=1 # 这里的id要与IP对应
listeners=PLAINTEXT://192.168.58.158:9092 #本机IP地址
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.58.158:2181,192.168.58.159:2181,192.168.58.160:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0配置项含义:
broker.id 每个server需要单独配置broker id,如果不配置系统会自动配置。
listeners 监听地址,格式PLAINTEXT://IP:端口。
num.network.threads 接收和发送网络信息的线程数。
num.io.threads 服务器用于处理请求的线程数,其中可能包括磁盘I/O。
socket.send.buffer.bytes 套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes 套接字服务器将接受的请求的最大大小(防止OOM)
log.dirs 日志文件目录。
num.partitions partition数量。
num.recovery.threads.per.data.dir 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1。
offsets.topic.replication.factor 偏移量话题的复制因子(设置更高保证可用),为了保证有效的复制,偏移话题的复制因子是可配置的,在偏移话题的第一次请求的时候可用的broker的数量至少为复制因子的大小,否则要么话题创建失败,要么复制因子取可用broker的数量和配置复制因子的最小值。
log.retention.hours 日志文件删除之前保留的时间(单位小时),默认168
log.segment.bytes 单个日志文件的大小,默认1073741824
log.retention.check.interval.ms 检查日志段以查看是否可以根据保留策略删除它们的时间间隔。
zookeeper.connect ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间。创建log目录
[root@kafka1 ~]# mkdir -p /opt/data/kafka/logs
[root@kafka2 ~]# mkdir -p /opt/data/kafka/logs
[root@kafka3 ~]# mkdir -p /opt/data/kafka/logs4、其他kafka节点配置
只需把配置好的安装包直接分发到其他节点,然后修改ZK的myid,Kafka的broker.id和listeners就可以了。
5、启动、验证ZK集群
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &(2)验证
查看ZK配置(三台均可查看)
# 下载nmap
[root@kafka1 ~]# yum install nmap
[root@kafka1 ~]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=20
syncLimit=10
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0查看ZK状态(三台均可查看)
[root@kafka1 ~]# echo stat |nc 127.0.0.1 2181
Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
Clients:/127.0.0.1:51876[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: follower
Node count: 4查看端口
[root@kafka1 ~]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 15002 root 98u IPv4 43385 0t0 TCP *:eforward (LISTEN)6、启动、验证Kafka
(1)启动
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/kafka-server-start.sh config/server.properties &(2)验证
在192.168.58.158上创建topic
[root@kafka1 ~]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
Created topic "testtopic".查询192.168.58.158上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 192.168.58.158:2181 --list
testtopic查询192.168.58.159上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 192.168.58.159:2181 --list
testtopic查询192.168.58.160上的topic
[root@kafka1 ~]# bin/kafka-topics.sh --zookeeper 192.168.58.160:2181 --list
testtopic模拟消息生产和消费 发送消息到192.168.58.158
[root@kafka1 kafka_2.11-2.0.0]# bin/kafka-console-producer.sh --broker-list 192.168.58.158:9092 --topic testtopic
>世界,你好
>好好爱自己哦
>^C
[root@elk kafka_2.11-2.0.0]# 从192.168.58.159接受消息
[root@kafka2 kafka_2.11-2.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.58.158:9092 --topic testtopic --from-beginning
世界,你好
好好爱自己哦
^C
Processed a total of 2 messages
[root@ksfks2 kafka_2.11-2.0.0]# 完毕!
相关文章:

kafka的详细安装部署
introduce Kafka是一个分布式流处理平台,主要用于处理高吞吐量的实时数据流。Kafka最初由LinkedIn公司开发,现在由Apache Software Foundation维护和开发。 Kafka的核心是一个分布式发布-订阅消息系统,它可以处理大量的消息流,并…...

【数据分享】2015-2023年我国区县逐月二手房房价数据(Excel/Shp格式)
房价是一个城市发展程度的重要体现,一个城市的房价越高通常代表这个城市越发达,对于人口的吸引力越大!因此,房价数据是我们在各项城市研究中都非常常用的数据!之前我们分享过2015-2023年我国地级市逐月房价数据&#x…...
)
PTA 7-226 sdut-C语言实验-矩阵输出(数组移位)
输入N个整数,输出由这些整数组成的n行矩阵。 输入格式: 第一行输入一个正整数N(N<20),表示后面要输入的整数个数。 下面依次输入N个整数。 输出格式: 以输入的整数为基础,输出有规律的N行数据。 输入样例: 在…...

Android 各平台推送通知栏点击处理方案
示例代码如下: RongPushClient.setPushEventListener( new PushEventListener() { Override public boolean preNotificationMessageArrived( Context context, PushType pushType, PushNotificationMessage notificationMessage) { //透传通知时,调用。…...

什么是网络安全 ?
网络安全已成为我们生活的数字时代最重要的话题之一。随着连接设备数量的增加、互联网的普及和在线数据的指数级增长,网络攻击的风险呈指数级增长。 但网络安全是什么意思? 简而言之,网络安全是一组旨在保护网络、设备和数据免受网络攻击、…...
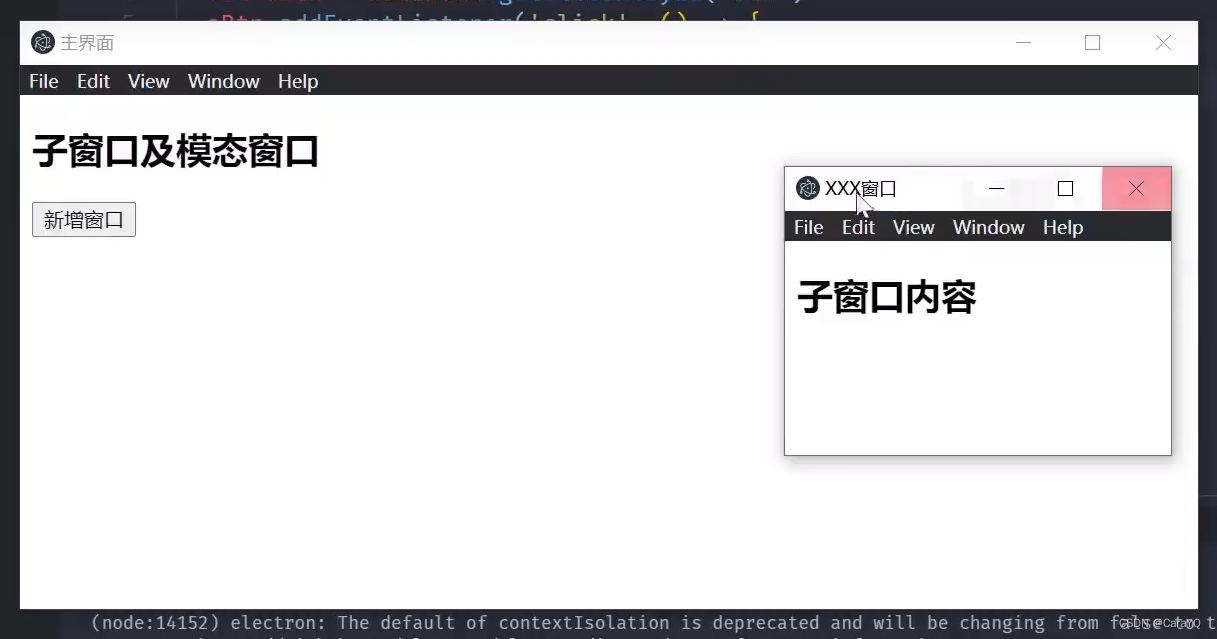
【前端】-【electron】
文章目录 介绍electron工作流程环境搭建 electron生命周期(app的生命周期)窗口尺寸窗口标题自定义窗口的实现阻止窗口关闭父子及模态窗口自定义菜单 介绍 electron技术架构:chromium、node.js、native.apis electron工作流程 桌面应用就是…...

Python中的类(Class)和对象(Object)
目录 一、引言 二、类(Class) 1、类的定义 2、类的实例化 三、对象(Object) 1、对象的属性 2、对象的方法 四、类和对象的继承和多态性 1、继承 2、多态性 五、类与对象的封装性 1、封装的概念 2、Python中的封装实现…...

dp-拦截导弹2
所有代码均来自于acwing中的算法基础课和算法提高课 Description 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统。但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度, 但是以后每一发炮弹都不能高于前一发的高度。…...
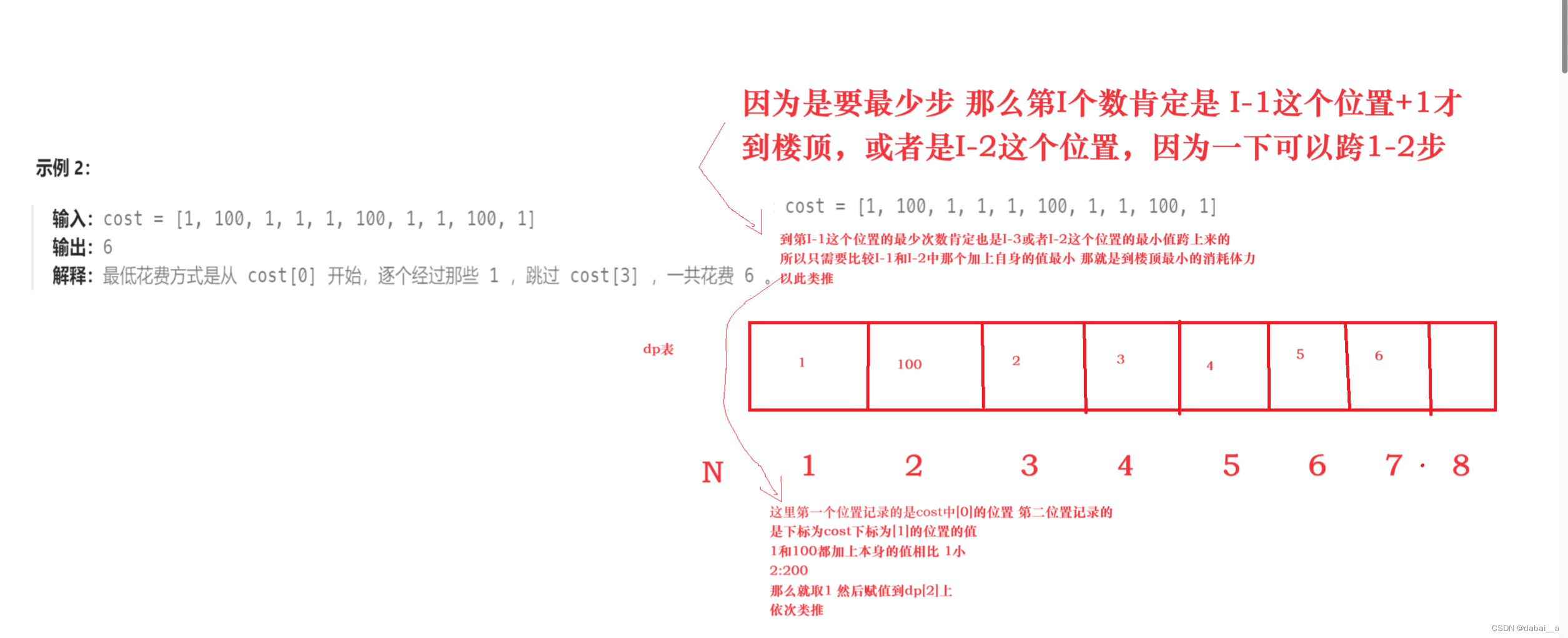
初识动态规划算法(题目加解析)
文章目录 什么是动态规划正文力扣题第 N 个泰波那契数三步问题使用最小花费爬楼梯 总结 什么是动态规划 线性动态规划:是可以用一个dp表来存储内容,并且找到规律存储,按照规律存储。让第i个位置的值等于题目要求的答案 >dp表:dp表就是用一…...
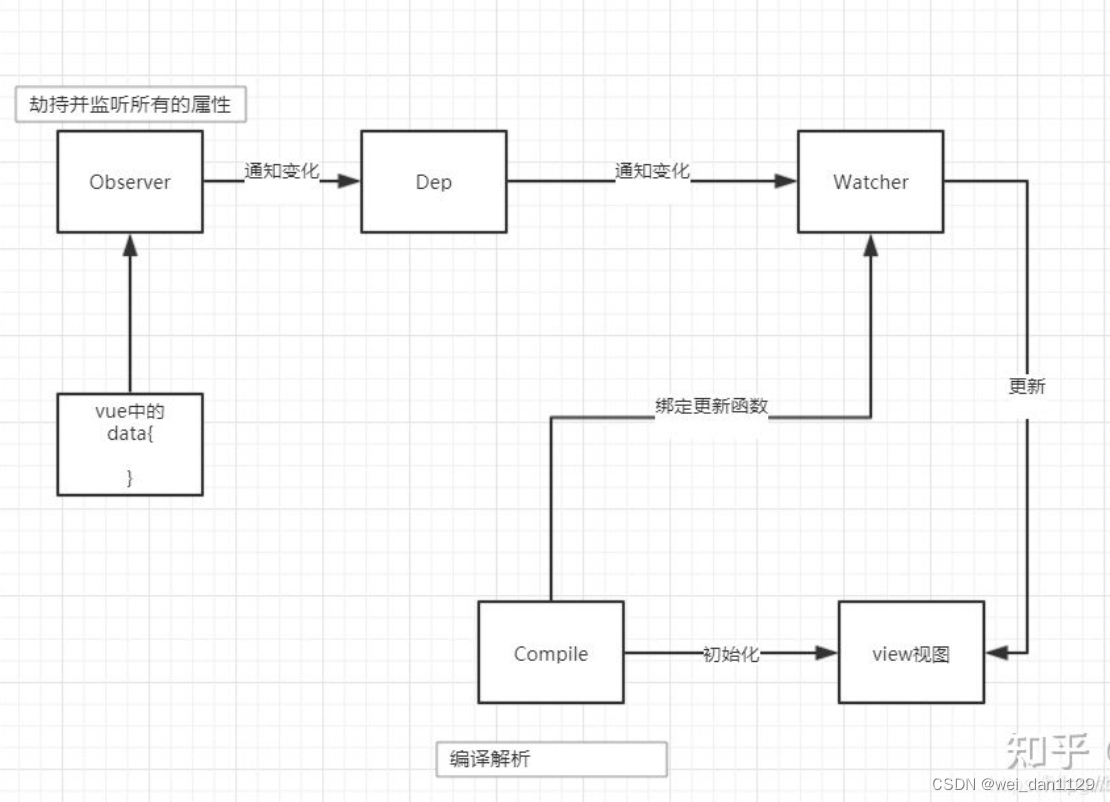
Vue2.0与Vue3.0的区别
一、Vue2和Vue3的数据双向绑定原理发生了改变 Vue2的双向数据绑定是利用ES5的一个API,Object.definePropert()对数据进行劫持 结合 发布 订阅模式的方式来实现的。通过Object.defineProperty来劫持数据的setter,getter,在数据变动时发布消息…...

探索人工智能领域——每日20个名词详解【day6】
目录 前言 正文 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Filotimo__✍️原创,首发于CSDN📚。 📣如需转载,请事先与我联系以…...
C++初阶 | [七] string类(上)
摘要:标准库中的string类的常用函数 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP(面向对象)的思想&#…...
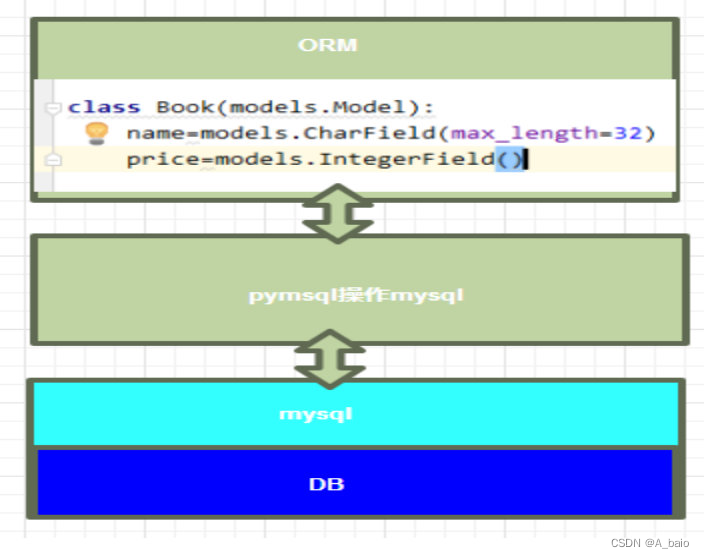
Django总结
文章目录 一、Web应用Web应用程序的优点Web应用程序的缺点应用程序有两种模式C/S、B/S C/S 客户端/服务端局域网连接其他电脑的MySQL数据库1.先用其他电脑再cmd命令行ping本机ip2.开放MySQL的访问 B/S 浏览器/服务端基于socket编写一个Web应用 二、Http协议1.http协议是什么2.h…...

【qml入门系列教程】:qml QtObject用法介绍
作者:令狐掌门 技术交流QQ群:675120140 博客地址:https://mingshiqiang.blog.csdn.net/ 文章目录 QtObject 是 Qt/QML 中的一个基础类型,通常用作创建一个没有 UI 的(不渲染任何东西的)纯逻辑对象。可以使用它来组织代码、存储状态或者作为属性和方法的容器。 以下是如何…...
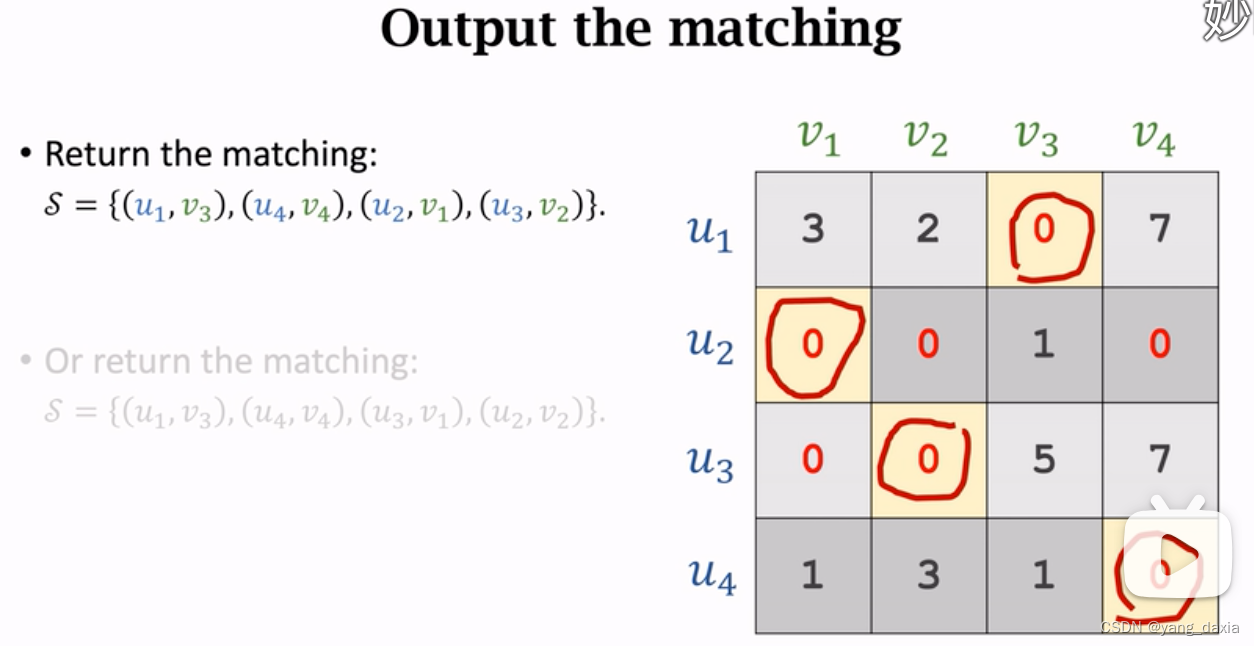
2分图匹配算法
定义 节点u直接无边,v之间无边,边只存在uv之间。判断方法:BFS染色法,全部染色后,相邻边不同色 无权二部图中的最大匹配 最大匹配即每一个都匹配上min(u, v)。贪心算法可能导致&…...
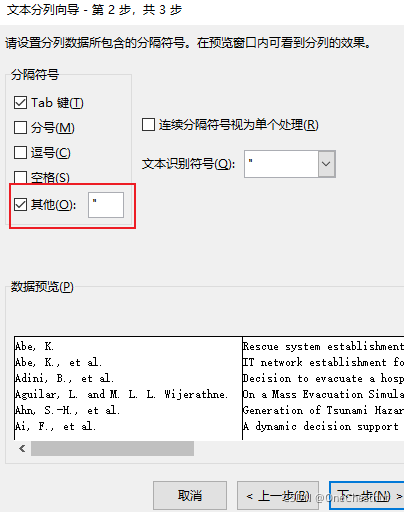
[EndNote学习笔记] 导出库中文献的作者、标题、年份到Excel
菜单栏Edit中,选择 Output Styles 在默认的 Annotated上进行修改,在Bibliography栏下的Templates中修改想要导出的格式 其中,每个粗体标题表示,针对不同的文献类型,设置相应的导出格式。一般为Journal Article&…...
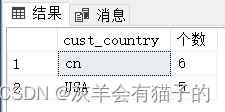
SQL Sever 基础知识 - 数据查询
SQL Sever 基础知识 - 一、查询数据 一、查询数据第1节 基本 SQL Server 语句SELECT第2节 SELECT语句示例2.1 SELECT - 检索表示例的某些列2.2 SELECT - 检索表的所有列2.3 SELECT - 对结果集进行筛选2.4 SELECT - 对结果集进行排序2.5 SELECT - 对结果集进行分组2.5 SELECT - …...

Vue入门——v-on标签
文章目录 规则v-on 一、案例总结 规则 v-on 作用:为html标签绑定事件语法: v-on:事件名:“函数名”简写为 事件名“函数名” 注意:函数需要定义在methods选项内部 一、案例 我们给案件绑定一个单击事件 <!DOCTYPE…...
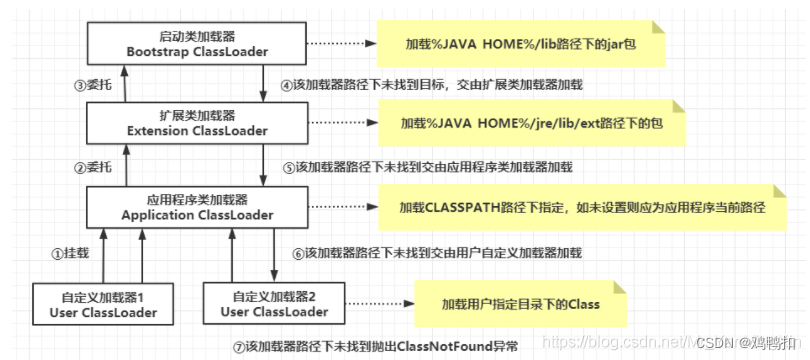
JVM:双亲委派(未完结)
类加载 定义 一个java文件从编写代码到最终运行,必须要经历编译和类加载的过程,如下图(图源自b站视频up主“跟着Mic学架构”)。 编译就是把.java文件变成.class文件。类加载就是把.class文件加载到JVM内存中,得到一…...

Leetcode 2661. 找出叠涂元素
Leetcode 2661. 找出叠涂元素题目 给你一个下标从 0 开始的整数数组 arr 和一个 m x n 的整数 矩阵 mat 。arr 和 mat 都包含范围 [1,m * n] 内的 所有 整数。从下标 0 开始遍历 arr 中的每个下标 i ,并将包含整数 arr[i] 的 mat 单元格涂色。请你找出 a…...

基于AI智能体群组的网站自动化测试:原理、配置与实战
1. 项目概述:用AI智能体群组自动化测试你的网站 最近在折腾一个本地开发的项目,前端页面越做越复杂,每次手动点点点测试UI、检查链接、看看响应式布局,实在是费时费力。直到我发现了 browser-use/vibetest-use 这个项目&#x…...

当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身
当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身 围绕“为什么 MiniMax 大模型无法识别马嘉祺是谁”的一次能力拆解:真正暴露的,往往是知识覆盖、检索策略与风控边界的耦合问题 直接回答 先给结论。 如果 Mi…...

LeetCode 比特位计数题解
LeetCode 比特位计数题解 题目描述 给定一个非负整数 num,返回一个数组 answer,其中 answer[i] 表示 i 的二进制表示中 1 的个数。 示例: 输入:num 2输出:[0,1,1] 输入:num 5输出:[0,1,1…...

跨平台光标同步工具:技术原理、实现与多屏开发效率优化
1. 项目概述:一个为开发者量身定制的光标同步工具 如果你和我一样,经常需要在多台显示器、多个IDE窗口,甚至是远程桌面和本地环境之间来回切换,那么你一定对“找光标”这件事深恶痛绝。尤其是在进行代码对比、调试或者多屏幕协作时…...

离线式SMPS输入整流器设计与优化指南
1. 离线式SMPS输入整流器设计基础开关电源(SMPS)的输入整流环节如同电力系统的"第一道闸门",其设计质量直接影响后续DC-DC转换环节的稳定性。在离线式设计中,整流器需要将85-265VAC的宽范围交流输入转换为高压直流,这个看似简单的过…...

番茄小说下载器:打造个人专属离线小说图书馆的完整指南
番茄小说下载器:打造个人专属离线小说图书馆的完整指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在通勤路上突然想读小说,却因为网络信号不佳而无法加…...

【STM32F407 DSP实战】矩阵运算基础:从初始化到加减法与求逆的嵌入式实现
1. 为什么要在STM32F407上实现矩阵运算 在嵌入式开发中,矩阵运算可以说是无处不在。从简单的PID控制到复杂的图像处理算法,都离不开矩阵这个基础数据结构。就拿我最近做的一个四轴飞行器项目来说,姿态解算部分就需要频繁地进行矩阵乘法、求逆…...

3步完成PlayCover多语言界面配置:从零到精通的全栈指南
3步完成PlayCover多语言界面配置:从零到精通的全栈指南 【免费下载链接】PlayCover Community fork of PlayCover 项目地址: https://gitcode.com/gh_mirrors/pl/PlayCover PlayCover作为iOS应用兼容性工具,其多语言界面支持让全球用户都能获得本…...

GPU加速向量搜索实战:cuVS核心原理与CAGRA算法应用
1. 从CPU到GPU:向量搜索的范式转移与cuVS的诞生如果你最近在折腾大模型应用、推荐系统或者任何需要处理海量高维数据的项目,那么“向量搜索”这个词对你来说一定不陌生。简单来说,它就是把文本、图片、音频这些非结构化数据,通过模…...

ARM架构CNTP_CVAL寄存器详解与定时器编程实践
1. ARM架构中的CNTP_CVAL寄存器解析 在ARMv8/v9架构中,定时器系统是处理器关键的时间管理组件,而CNTP_CVAL(Counter-timer Physical Timer CompareValue Register)作为EL1物理定时器的比较值寄存器,在实时任务调度、中…...