Elasticsearch:评估 RAG - 指标之旅
作者:Quentin Herreros,Thomas Veasey,Thanos Papaoikonomou

2020年,Meta发表了一篇题为 “知识密集型NLP任务的检索增强生成” 的论文。 本文介绍了一种通过利用外部数据库将语言模型 (LLM) 知识扩展到初始训练数据之外的方法。 从那时起,这种方法引起了研究人员的极大关注,并且由于其巨大的好处仍然是一个突出且备受讨论的话题。 这些优点包括易于更新知识数据库、使较小的模型能够在特定任务上匹配较大模型的性能、允许生成泛化到训练数据之外的领域、减少幻觉的发生等等。
所有这些实验和发现总是围绕着测量模型在给定任务上的性能。 不幸的是,鉴于其固有的开放性和宽容性,评估生成文本的质量提出了重大挑战。 在 “搜索” 场景中,存在一个 “理想” 文档排名,它允许直接比较来衡量与该理想排名的吻合程度。 然而,当涉及到在回答问题或总结内容方面评估生成文本的质量时,任务变得相当复杂。
在本博客中,我们的主要重点将是 RAG(检索增强生成)问答任务,更具体地说是闭域 QA。 我们将深入研究该领域常用的一些各种指标。 我们将深入探讨这些指标并解释 Elastic 为有效监控模型性能而做出的决策。
N-gram 指标
在这一系列指标中,其想法是检查生成的文本与 “真实情况” 的相似程度。 基于这个想法有很多变体,我们只讨论其中的几个。
- BLEU 分数:双语评估研究,称为 BLEU,是一种用于评估机器生成的段落与一个或多个参考段落进行比较的质量的指标。 它通过分析共享 n-grams(n 个连续单词的序列)的存在来量化相似性。 BLEU 分数的分配范围为 0 到 1,分数越高表示生成的文本与参考文本之间的对齐程度越接近(见下文)。

- ROUGE 分数:面向召回的 Gisting 评估通常用于评估机器生成摘要的有效性。 它通过计算共享单词或短语来评估生成的段落与参考段落的相似程度。 ROUGE 与 BLEU 的评分不同,它计算召回率,而 BLEU 计算精度。 这意味着 ROUGE 主要关注确定生成的段落中包含多少来自参考段落的信息。 这一特性使得 ROUGE 成为与摘要相关的任务的流行选择。
- METEOR 分数:显式排序翻译评估指标是机器生成领域广泛使用的指标。 METEOR 与前面提到的指标不同,它结合了精确率和召回率的调和平均值。 此外,在评估单词匹配时,它还会考虑同义词、词干和词序(通过碎片惩罚)。 与 BLEU 相比,这些属性有助于 METEOR 与人类判断实现更强的相关性。
虽然这些指标可以作为快速、直接评估 LLMs 的宝贵工具,但它们具有某些局限性,使其不太理想。 首先,他们在评估段落的流畅性、连贯性和整体意义方面存在不足。 他们对词序也相对不敏感。 此外,尽管 METEOR 试图通过同义词和词干来解决这个问题,但这些评估工具缺乏语义知识,使得它们对语义变化视而不见。 这个问题在有效评估长文本时尤其严重,因为将文本仅仅视为一组段落过于简单化。 此外,对 “模板答案” 的依赖使得它们在大规模评估中使用起来昂贵,并且引入了对模板中使用的确切措辞的偏见。 最后,对于特定任务,研究表明 BLEU 和 ROUGE 分数与人类判断之间的相关性实际上相当低。 出于这些原因,研究人员试图寻找改进的指标。
内在指标
困惑度(通常缩写为 PPL)是评估语言模型 (LLM) 的最常见指标之一。 计算困惑度需要访问模型生成的每个单词的概率分布。 它衡量模型预测单词序列的信心程度。 困惑度越高,模型预测观察到的序列的信心就越低。 正式地,它的定义如下:
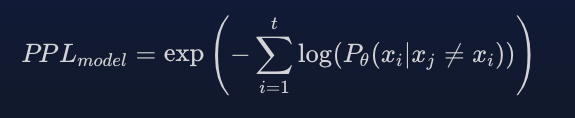
这里 是根据模型以句子中其他标记 (!= i) 为条件的
个标记的对数预测概率。 为了说明这一点,下面的示例说明了如何计算词汇量只有三个单词的模型的困惑度。

困惑度的一个显着好处是它的计算速度,因为它仅依赖于输出概率并且不涉及外部模型。 此外,它往往与模型的质量具有很强的相关性(尽管这种相关性可能会根据所使用的测试数据集而有所不同)。
尽管如此,困惑度也伴随着某些可能带来挑战的限制。 首先,它依赖于模型的信息密度,因此很难比较词汇量大小或上下文长度不同的两个模型。 比较数据集之间的分数也是不可能的,因为某些评估数据本质上可能比其他数据具有更高的复杂度。 此外,它可能对词汇差异过于敏感,可能会惩罚以不同方式表达相同答案的模型,即使两个版本都有效。 最后,困惑度不太适合评估模型处理语言歧义、创造力或幻觉的能力。 特别是在歧义性方面,序列的其余部分很难确定的单词会增加困惑,但它们并不是生成或理解不良的指标。 它可能会惩罚一个比能力较差的模型更好地理解模糊性的模型。 由于这些缺点,NLP 社区探索了更先进的外在指标来解决这些问题。
基于模型的指标
内在和 N-gram 指标有一个显着的缺点,因为它们不利用语义理解来评估生成内容的准确性。 因此,它们可能不会像我们想要的那样与人类的判断紧密一致。 基于模型的指标已成为解决此问题的更有前景的解决方案。
- BERTScore:为了从语义的角度理解句子的真正含义,BERTScore 使用著名的基于 Transformer 的模型 BERT。 它会查看我们想要评估的句子和参考句子,然后通过利用两个句子中标记的上下文嵌入来比较它们的相似程度。 最终分数计算为最接近标记对的余弦相似度的加权组合。
- BLEURT:基本概念与 BERTScore 非常相似,因为它依赖于基于 Transformer 的模型来评估参考文本和候选文本之间的相似性。 然而,BLEURT 的训练包含两个关键的增强功能。 首先,它使用预训练步骤,使用基于维基百科内容进行随机更改的数据集来模拟生成的输出可变性。 此外,它还使用了一个微调步骤,其中结合了人类评分来改进其性能。
- BARTScore:这个想法是将评估生成文本的问题转化为文本生成问题。 使用基于 BART 的经过专门训练的序列到序列模型,能够使用给定另一个输入文本 x 的一个生成文本 y 的加权对数概率来获得分数。 BARTScore 支持从不同角度(忠实度、精确度、召回率等)评估生成的文本,这使其功能强大。

BERTcore 和 BLEURT 本质上可以被视为 n-gram 召回,但使用上下文表示。 另一方面,BARTScore 更接近于目标和生成文本之间的困惑度测量,使用评估模型而不是模型本身。 虽然这些基于模型的指标提供了强大的评估功能,但它们比 BLEU 或 PPL 慢,因为它们涉及外部模型。 在许多世代背景下,BLEU 与人类判断之间的相关性相对较低,这意味着这种权衡是合理的。 基于简单相似性的指标在选择 LLMs 时仍然很受欢迎(如 Hugging Face 排行榜所示)。 这种方法可能可以作为一个合理的代理,但考虑到当前最先进的 LLMs 的能力,它还不够。
Elastic 的选择:UniEval
UniEval 将所有评估维度统一到布尔问答框架中,允许单个模型从各个角度评估生成的文本。 例如,如果其中一个评估维度是相关性,那么人们会直接询问模型“这是这个问题的相关答案吗?”。给定一组由评估维度确定的任务,训练一个模型,该模型能够 根据这些维度评估生成的文本。UniEval 采用 T5 作为基础模型,采用两步训练过程。第一步称为 “中间多任务学习”,利用查询和上下文来处理统一为布尔 QA 任务的多个任务 来自预先存在的相关数据集。随后,第二步需要顺序训练,其中模型逐个维度地学习如何评估生成文本的不同方面。预训练的 UniEval 模型面向摘要,但我们认为 RAG 问答可以被视为一项积极的总结任务,它避免了参数记忆以获得准确的响应。它已经在以下维度进行了训练:
- 连贯性,衡量所有句子的凝聚力的形成。
- 一致性,评估答案与上下文之间的事实一致性。
- 流利度,评估单个句子的质量。
- 相关性,衡量答案与事实真相之间的事实一致性。

虽然 UniEval 非常强大,但截至我们撰写本文时,它目前还不具备 “最先进” 评估模型的称号。 似乎基于 GPT 的评估器(例如 G-Eval)可能比 UniEval 表现出与人类判断更强的相关性(仅在基于 GPT-4 的评估器的情况下)。 然而,必须考虑显着的成本差异。 UniEval 是一个包含 8 亿个参数的模型,而 GPT-4 估计拥有 1.76 万亿个参数。 我们坚信,G-Eval-4 的微小优势并不能因为成本的大幅增加而得到证明。
实际使用情况
我们刚刚开始探索 UniEval,并且打算在未来将其合并到许多涉及文本生成的令人兴奋的项目中。 然而,有了这个评估模型,我们决定通过解决三个具体问题来测试其功能。
我们可以轻松地使用 UniEval 来比较 LLMs 的质量吗?
当你有评估指标时,这可能是你首先想到的考虑因素。 它是预测 LLMs 质量的有效工具吗? 我们对 Mistral-7b-Instruct 和 Falcon-7b-Instruct 进行了基准测试,以评估这两个模型在流畅性、一致性、连贯性和相关性方面的区别程度。 对于此基准测试,我们使用了来自 18 个数据集的 200 个查询,确保了多样化的上下文(包括 BioASQ、BoolQ、CoQA、CosmosQA、HAGRID、HotpotQA、MSMARCO、MultiSpanQA、NarrativeQA、NewsQA、NQ、PopQA、QuAC、SearchQA、SleepQA、 SQuAD、ToolQA、TriviaQA、TruthfulQA)。 给予 Mistral/Falcon 的提示包括查询和包含回答查询所需信息的上下文。

在这个特定的例子中,很明显,Mistral 在所有评估维度上都优于 Falcon,因此决策非常简单。 然而,在其他情况下可能更具挑战性,特别是在相关性和一致性之间做出决定时,这两者对于 RAG 问答都至关重要。
“一致性得分”与模型产生的幻觉数量相关吗?
实验很简单。 我们从 SQuAD 2.0 数据集中收集了大约 100 个查询。 接下来,我们使用 UniEval 评估模型(在本例中具体为 Mistral-7B-Instruct-v0.1,但它可以是任何模型)。 接下来,我们手动检查并注释生成的表现出幻觉的文本。 之后,我们创建一条校准曲线来检查 “一致性分数” 是否可以作为幻觉概率的可靠预测因子。 简单来说,我们正在调查 “一致性分数” 和幻觉数量是否相关。

据观察,一致性被证明是幻觉概率的可靠指标,尽管它并非完美无缺。 我们遇到过幻觉很微妙且难以识别的情况。 此外,我们测试的模型偶尔会提供正确的答案,这些答案并非来自提示的上下文,而是来自其参数记忆。 就一致性指标而言,这类似于幻觉,尽管答案是准确的。 这就是为什么平均而言,我们检测到的幻觉数量多于实际数量。 值得注意的是,在某些实验中,我们故意加入误导性提示,从而误导了生成过程和我们对其的评估。 这证明 UniEval 并不是灵丹妙药。
解码策略如何影响评估维度?
在本实验中,我们想要比较 Falcon-7b-Instruct 中解码信息的不同方式。 我们在 18 个数据集上尝试了多种方法,每个数据集使用 5 个查询(总共 90 个查询):
- 贪婪解码,我们选择最有可能的标记。
- 波束解码,涉及维护多个可能的路径并选择总体概率最高的路径(使用 5 个波束)。
- TopK 解码,我们选择顶部候选者,在它们之间重新分配概率,然后对令牌进行采样(顶部 k 值为 4)。
- 核解码,与 TopK 类似,但基于概率质量阈值(阈值=0.95,max_topk=50)具有可变数量的候选者。
- 对比解码,对排名靠前的候选者进行惩罚,以鼓励选择过程中的多样性(penalty_alpha=0.6,topk=4)。
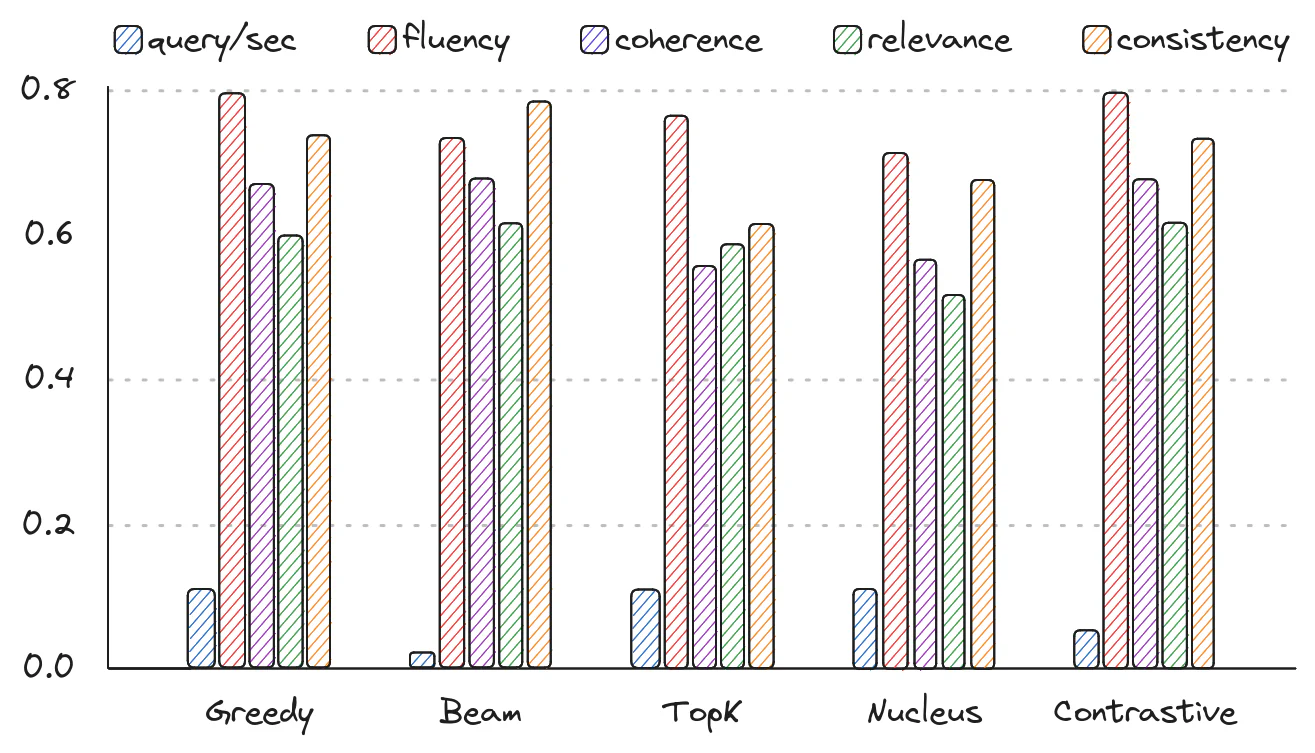
根据早期的研究,最有效的方法是对比解码。 值得注意的是,贪婪解码在这种情况下表现得相当好,尽管它被认为是一种有些受限的策略。 这可能归因于对简短答案(最多 64 个新标记)的关注,或者 UniEval 没有准确评估 “多样性” 方面的可能性。
结论
在这篇博客中,我们旨在深入了解评估 LLMs 所涉及的挑战,特别是在使用 RAG 回答问题的背景下。 该领域仍处于早期阶段,有大量关于该主题的论文发表。 虽然 UniEval 不是万能的解决方案,但我们发现它是一种引人注目的方法,可以更准确地评估我们的 RAG 管道的性能。 这标志着 Elastic 正在进行的研究工作迈出了第一步。 一如既往,我们的目标是增强搜索体验,我们相信 UniEval 等解决方案或类似方法将有助于为我们的用户开发有价值的工具。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:https://www.elastic.co/search-labs/blog/articles/evaluating-rag-metrics
相关文章:
Elasticsearch:评估 RAG - 指标之旅
作者:Quentin Herreros,Thomas Veasey,Thanos Papaoikonomou 2020年,Meta发表了一篇题为 “知识密集型NLP任务的检索增强生成” 的论文。 本文介绍了一种通过利用外部数据库将语言模型 (LLM) 知识扩展到初始训练数据之外的方法。 …...

【2023.12.4练习】数据库知识点复习测试
概论 数据表:用于存储现实中数据的联系。 储存信息联系。 字段:又称列,如姓名、年龄、编号等。 记录:又称元组,为数据表中的一行,代表了一个实体的信息。 数据库(DB)࿱…...
【wvp】测试记录
ffmpeg 这是个莫名其妙的报错,通过排查,应该是zlm哪个进程引起的 会议室的性能 网络IO也就20M...
【若依框架实现上传文件组件】
若依框架中只有个人中心有上传图片组件,但是这个组件不适用于el-dialog中的el-form表单页面 于是通过elementui重新写了一个上传组件,如图是实现效果 vue代码 <el-dialog :title"title" v-model"find" width"600px"…...

玩转大数据5:构建可扩展的大数据架构
1. 引言 随着数字化时代的到来,大数据已经成为企业、组织和个人关注的焦点。大数据架构作为大数据应用的核心组成部分,对于企业的数字化转型和信息化建设至关重要。我们将探讨大数据架构的基本要素和原则,以及Java在大数据架构中的角色&…...

【华为数据之道学习笔记】非数字原生企业的特点
非数字原生企业的数字化转型挑战 软件和数据平台为核心的数字世界入口,便捷地获取和存储了大量的数据,并开始尝试通过机器学习等人工智能技术分析这些数据,以便更好地理解用户需求,增强数字化创新能力。部分数字原生企业引领着云计…...

Kubernetes学习笔记-Part.01 Kubernets与docker
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第一章 Kubernets与docker Docker是一种轻量级的容器…...

k8s学习
文章目录 前言一、k8s部署方式二、学习k8s的方式今天主要配置k8s环境的方式今天遇到的是一个在k8s进行初始化的方式,但是发现k8s不能正常初始化总是出现错误,或者在错误中有问题的方式,在网上查询挺多资料需要重新启动kub文件,删除…...

测试:JMeter和LoadRunner比较
比较 JMeter和LoadRunner是两款常用的软件性能测试工具,它们在功能和性能上有一定的相似性和差异。下面从几个方面对它们进行比较: 1. 架构和原理: JMeter和LoadRunner的架构和原理基本相同,都是通过中间代理监控和收集并发客户…...
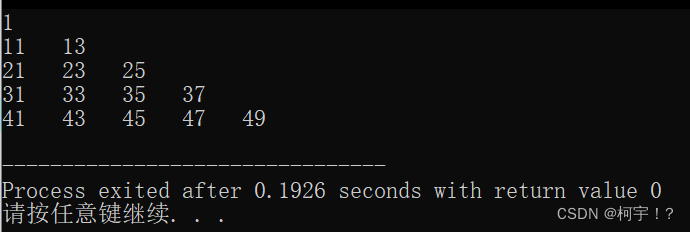
(C语言)通过循环按行顺序为一个矩阵赋予1,3,5,7,9,等奇数,然后输出矩阵左下角的值。
#include<stdio.h> int main() {int a[5][5];int n 1;for(int i 0;i < 5;i ){for(int j 0;j < 5;j ){a[i][j] n;n 2;}}for(int i 0;i < 5;i ){for(int j 0;j < i;j )printf("%-5d",a[i][j]);printf("\n");}return 0; } 运行截图…...
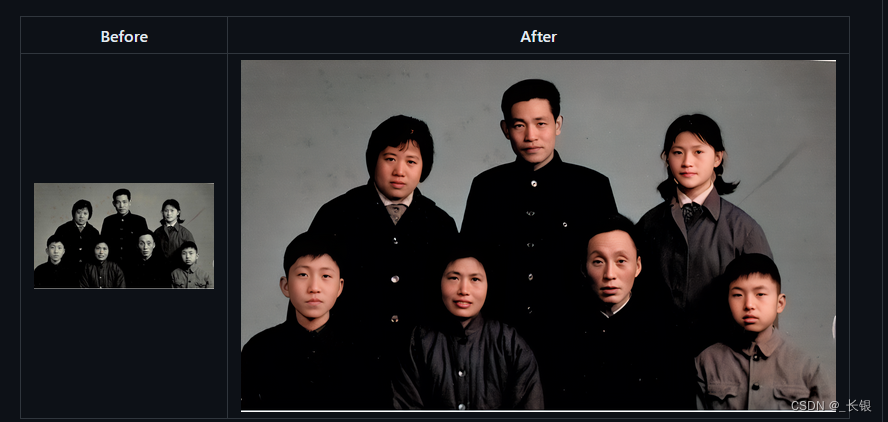
GitHub项目推荐-Deoldify
有小伙伴推荐了一个老照片上色的GitHub项目,看了简介,还不错,推荐给大家。 项目地址 GitHub - SpenserCai/sd-webui-deoldify: DeOldify for Stable Diffusion WebUI:This is an extension for StableDiffusions AUTOMATIC1111 w…...

微前端qiankun示例 Umi3.5
主应用配置(基座) 安装包 npm i umijs/plugin-qiankun -D 配置 qiankun 开启 {"private": true,"scripts": {"start": "umi dev","build": "umi build","postinstall": "…...
熬夜会秃头——beta冲刺Day7
这个作业属于哪个课程2301-计算机学院-软件工程社区-CSDN社区云这个作业要求在哪里团队作业—beta冲刺事后诸葛亮-CSDN社区这个作业的目标记录beta冲刺Day7团队名称熬夜会秃头团队置顶集合随笔链接熬夜会秃头——Beta冲刺置顶随笔-CSDN社区 一、团队成员会议总结 1、成员工作…...
IntelliJ IDEA设置中文界面
1.下载中文插件 2. 点击重启IDE 3.问题就解决啦!...
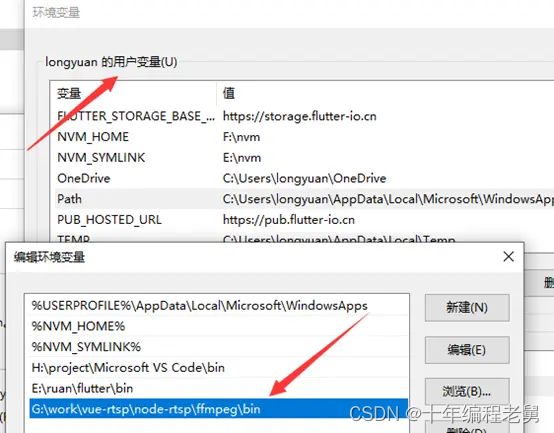
RTSP流媒体播放器
rtsp主要还是运用ffmpeg来搭建node后端转发到前端,前端再播放这样的思路。 这里讲的到是用两种方式,一种是ffmpeg设置成全局来实现,一种是ffmpeg放在本地目录用相对路径来引用的方式。 ffmpeg下载地址:http://www.ffmpeg.org/do…...

使用正则表达式时-可能会导致性能下降的情况
目录 前言 正则表达式引擎 NFA自动机的回溯 解决方案 前言 正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机&a…...
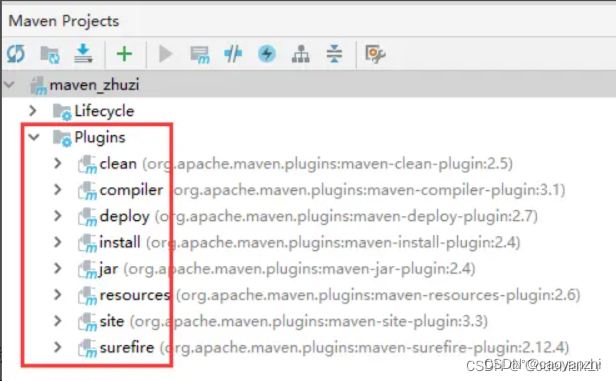
Maven生命周期
Maven生命周期 通过IDEA工具的辅助,能很轻易看见Maven的九种生命周期命令,如下: 双击其中任何一个,都会执行相应的Maven构建动作,为啥IDEA能实现这个功能呢?道理很简单,因为IDEA封装了Maven提供…...

深度学习(五):pytorch迁移学习之resnet50
1.迁移学习 迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。 迁移学习的核心思想是将源领域的知识迁…...

面试官:说说synchronized与ReentrantLock的区别
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...
数据结构学习笔记——广义表
目录 一、广义表的定义二、广义表的表头和表尾三、广义表的深度和长度四、广义表与二叉树(一)广义表表示二叉树(二)广义表表示二叉树的代码实现 一、广义表的定义 广义表是线性表的进一步推广,是由n(n≥0&…...

3PEAK思瑞浦 LM324A-SR SOP14 运算放大器
特性 供电电压:3V至36V 低供电电流:每通道100A 输入共模电压范围包含地线: 可作为比较器工作 轨到轨输出 带宽:0.9MHz 斜率:0.5V/us 优异的EMI抑制性能:1GHz时71dB 偏移电压:最大3mV 偏移电压温度漂移:7V/C 工作温度范围:-40C至125C...

避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南
避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南 在芯片设计领域,可测试性设计(DFT)是确保产品质量的关键环节。而作为DFT的重要组成部分,存储器内建自测试(MBIST)的实现质量直接影响着…...

别再手动拼接数据了!用ONNXRuntime和TensorRT实现多Batch推理的Python/C++实战对比
多Batch推理实战:ONNXRuntime与TensorRT的高效对决 在计算机视觉项目的实际部署中,我们常常会遇到这样的场景:摄像头持续采集图像,或者需要同时处理来自多个传感器的数据。如果每次只处理单张图片,就像用吸管喝一大桶…...

IS6201A多相PWM控制器:从架构解析到PCB布局的电源设计实战
1. 项目概述:为什么我们需要关注IS6201A?在电源设计领域,尤其是面对高性能计算、数据中心服务器、高端显卡以及工业自动化设备时,工程师们常常面临一个核心挑战:如何为那些“电老虎”级别的核心芯片(比如CP…...

AI Agent的协作竞争机制:多智能体博弈与协调
AI Agent的协作竞争机制:多智能体博弈与协调 本文面向中级AI算法工程师、软件架构师与AI产品经理,深度解析多智能体系统的核心原理、博弈机制、协调算法与落地实践,帮助读者掌握下一代AI系统的设计方法论。 一、核心概念与问题背景 1.1 核心概念定义 我们首先明确全文的核…...

算法和数学模型转换在FPGA中实现问题
1.关于指数运算在FPGA中实现问题 比如,高斯函数,在FPGA直接实现指数函数会极大的消耗资源,并且延迟比较大; 这种一般的使用办法,就是使用LUT查找表来替换; 或者使用分段线性逼近法则; 或者使用泰…...

不用Remix在线版!在VSCode里用Hardhat写合约,搭配Ganache和MetaMask本地测试全流程
在VSCode中构建专业级以太坊开发环境:HardhatGanacheMetaMask全流程指南 对于追求高效开发的以太坊工程师而言,脱离浏览器限制、建立本地化开发工作流已成为专业化的标志。本文将带你用VSCodeHardhat打造企业级智能合约开发环境,结合Ganache私…...

影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案
影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案 一、问题场景:数据集里混入模糊图,模型效果怎么调都上不去 在图像识别、OCR、人脸识别、商品图审核、视频抽帧数据清洗中,经…...

ARMv8.3指针认证技术原理与安全实践
1. AArch64指针认证技术深度解析指针认证(Pointer Authentication)是ARMv8.3-A引入的关键安全特性,通过在指针的高位比特中嵌入加密签名(Pointer Authentication Code, PAC)来验证指针的完整性。这项技术能有效防御ROP…...

树莓派Web IDE:零配置云端编程环境与Python硬件模拟实践
1. 项目概述:一个“开箱即用”的编程环境革命最近,树莓派基金会悄无声息地扔下了一颗“重磅炸弹”——他们正式推出了一个网页端的代码编辑器。这个消息在创客圈和教育圈里,可能比发布一款新硬件还要让人兴奋。为什么?因为它直接戳…...