基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(二)——数据清洗、转换
2 数据清洗、转换
此实验使用S3作为数据源
ETL:
E extract 输入
T transform 转换
L load 输出
大纲
- 2 数据清洗、转换
- 2.1 架构图
- 2.2 数据清洗
- 2.3 编辑脚本
- 2.3.1 连接数据源(s3)
- 2.3.2. 数据结构转换
- 2.3.2 数据结构拆分、定义
- 2.3.3 清洗后的数据写入新s3
- 2.3.4 运行作业
- 2.4 数据分区
- 2.4.1 编辑脚本
- 2.4.2 运行脚本
- 2.5 总结
2.1 架构图
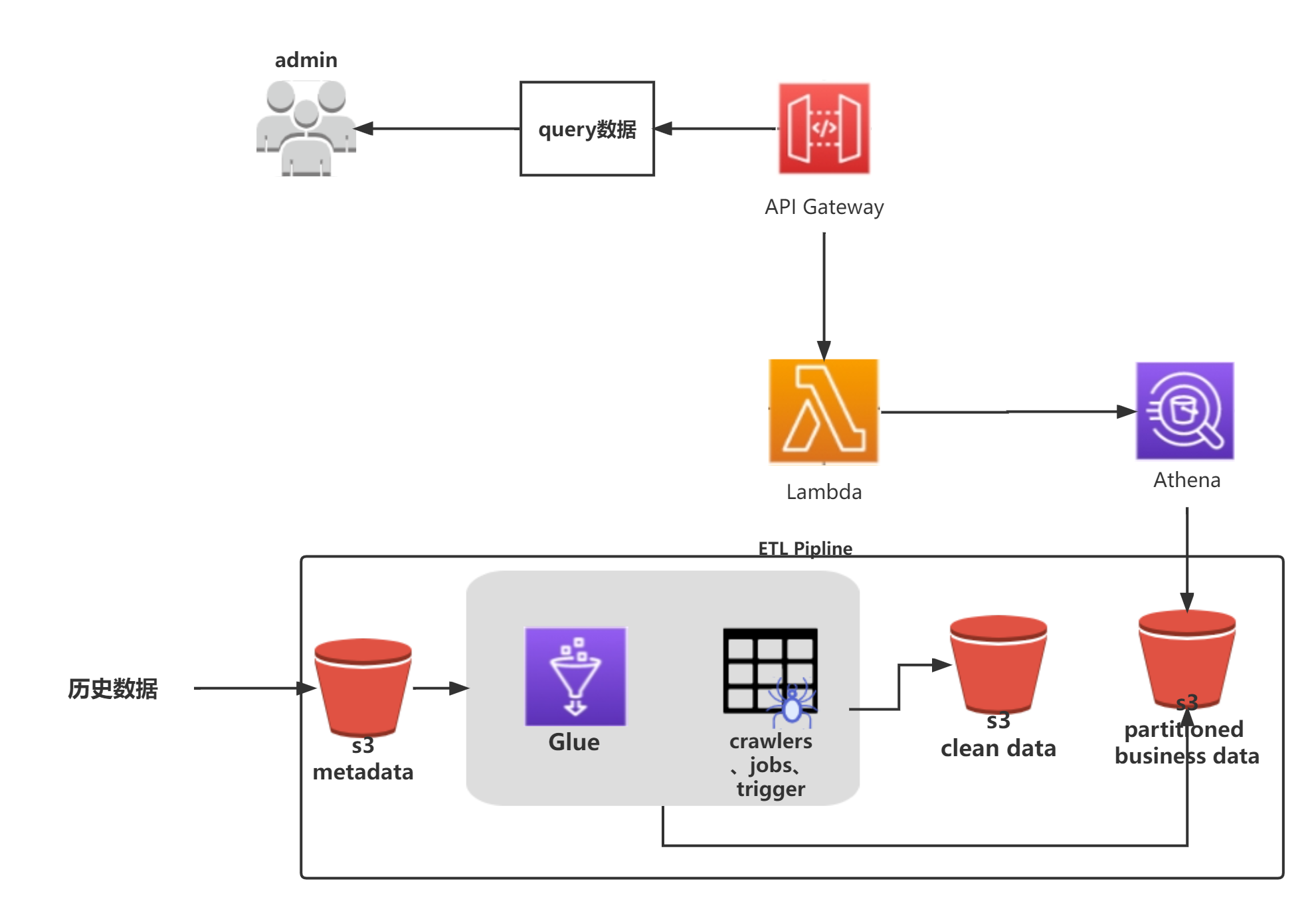
2.2 数据清洗
此步会将S3中的原始数据清洗成我们想要的自定义结构的数据。之后,我们可通过APIGateway+Lambda+Athena来实现一个无服务器的数据分析服务。
| 步骤 | 图例 |
|---|---|
| 1、入口 |  |
| 2、创建Job(s3作为数据源,则Type选择Spark,若为Kinesis等,选择Stream Spark) | 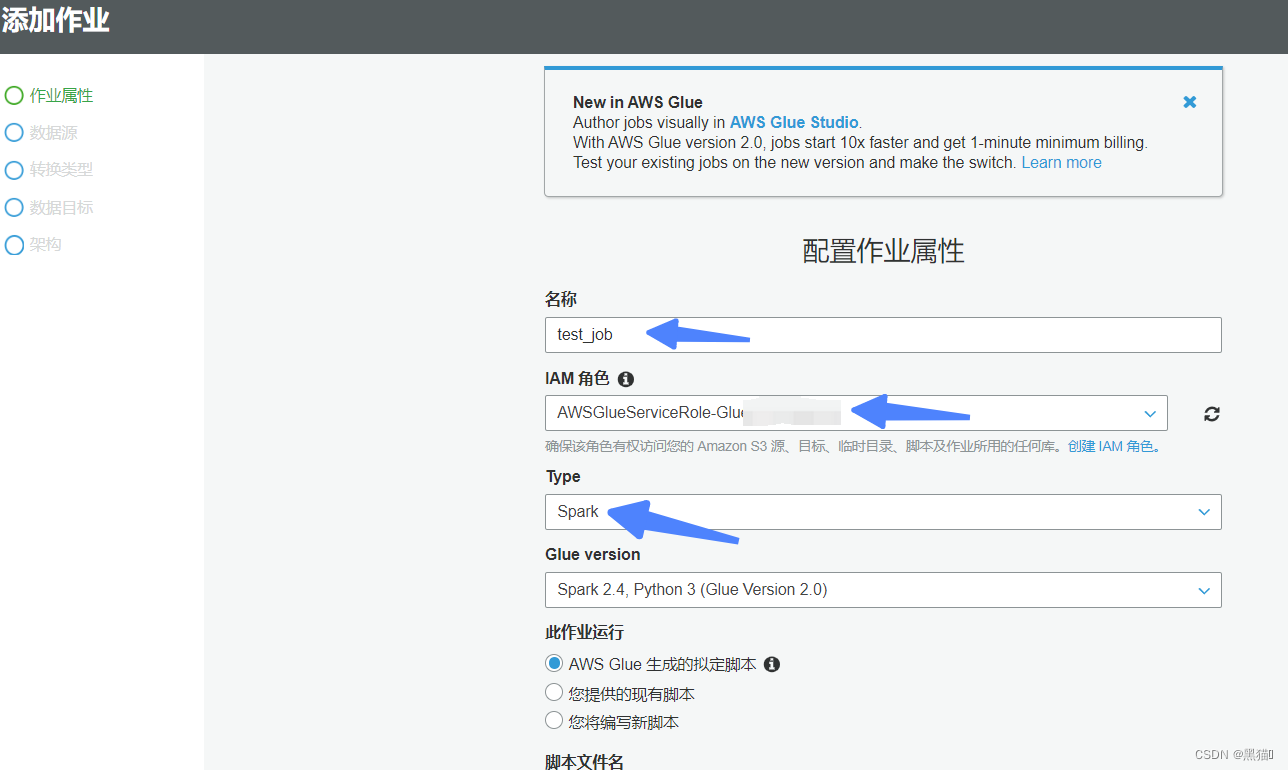 |
| 3、IAM角色需要有s3与Glue的权限 |  |
| 4、选择s3脚本位置,若已经完成脚本的编写工作,则可以选择第二项或第三项,若无则Glue会提供默认脚本 | 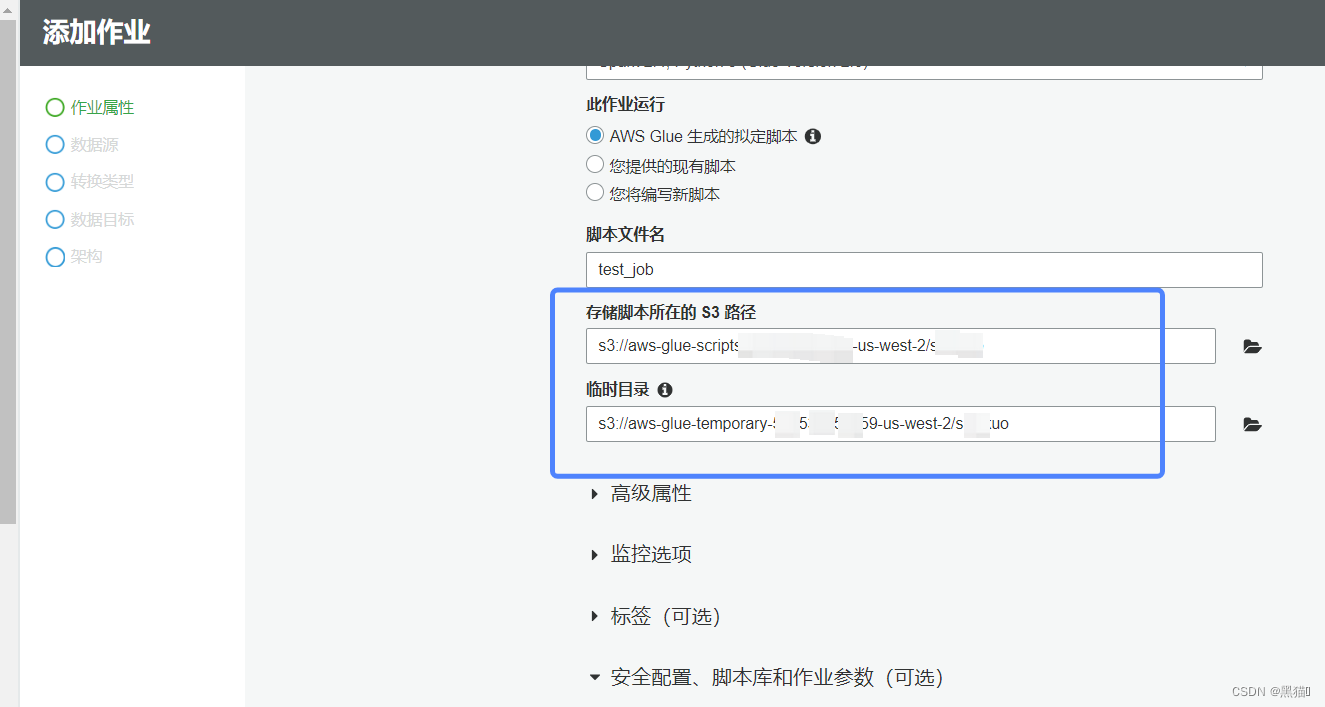 |
| 5、安全配置参数 | 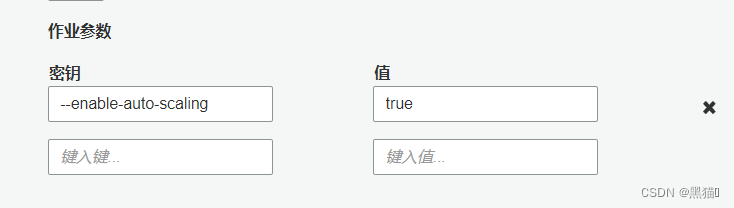 建议:添加参数–enable-auto-scaling为true。每次在我们执行Job任务时,会根据运行 ETL 任务的数据处理单元(DPU)的个数来分配动态IP,在我们子网的动态IP数低于DPU数时,Job将会执行失败。此参数将会动态分配IP。 建议:添加参数–enable-auto-scaling为true。每次在我们执行Job任务时,会根据运行 ETL 任务的数据处理单元(DPU)的个数来分配动态IP,在我们子网的动态IP数低于DPU数时,Job将会执行失败。此参数将会动态分配IP。 |
| 6、数据源() | 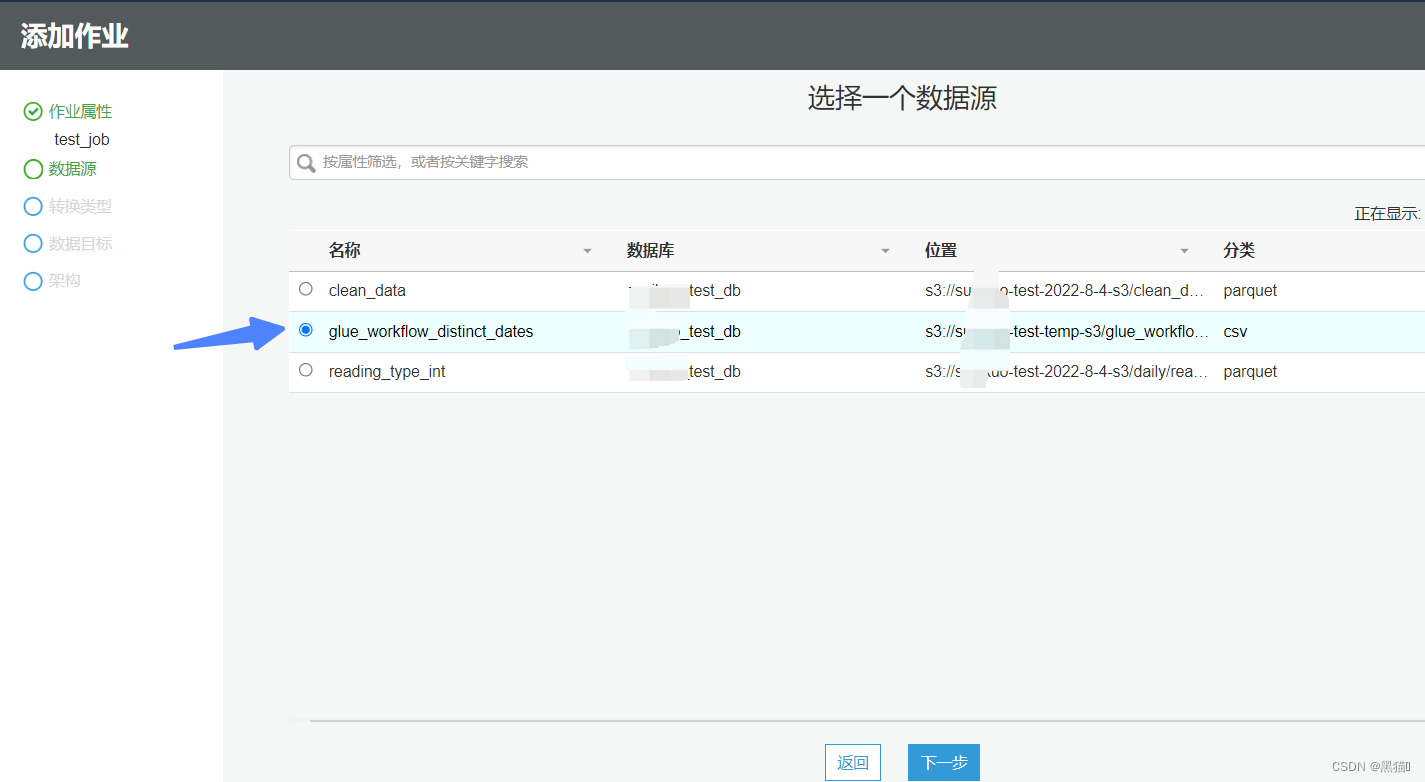 |
| 7、数据目标(我们会将清洗后的数据存储到新的s3桶) | 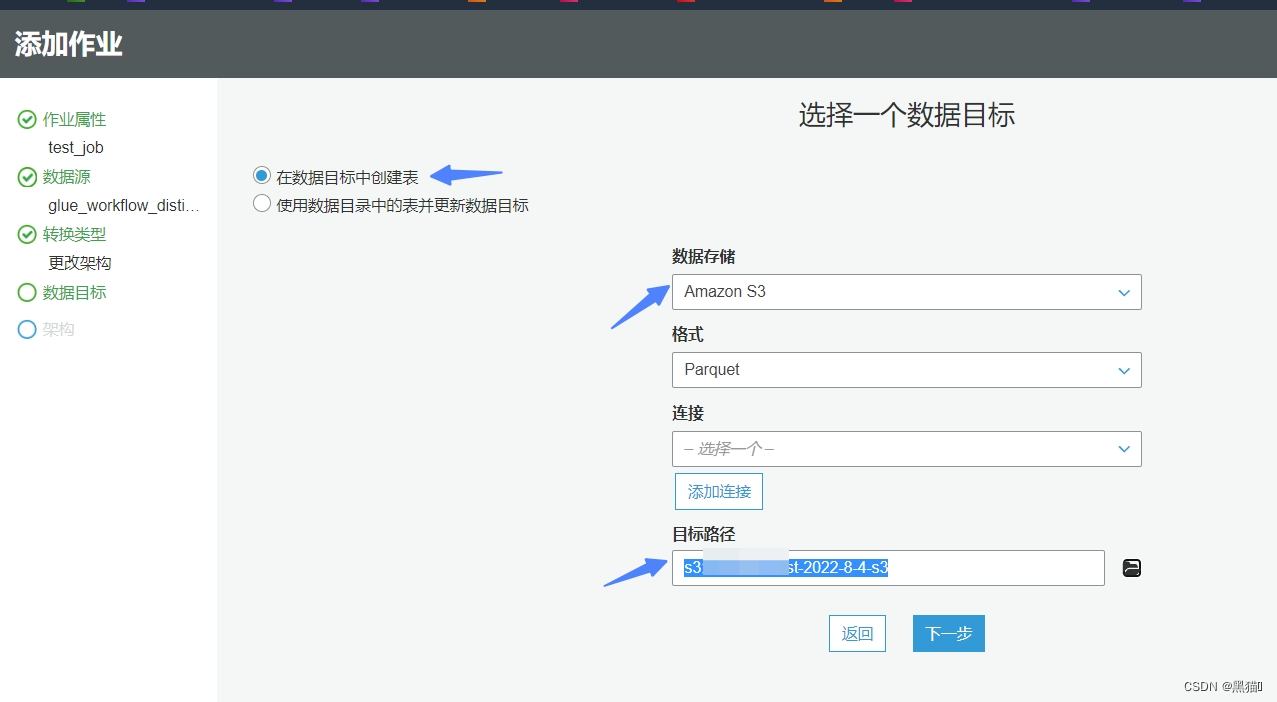 |
| 8、设计架构(在本案例中,我们会自定义脚本。所以不再在此处设计架构)(此处设计后,脚本会自动生成相关代码) | 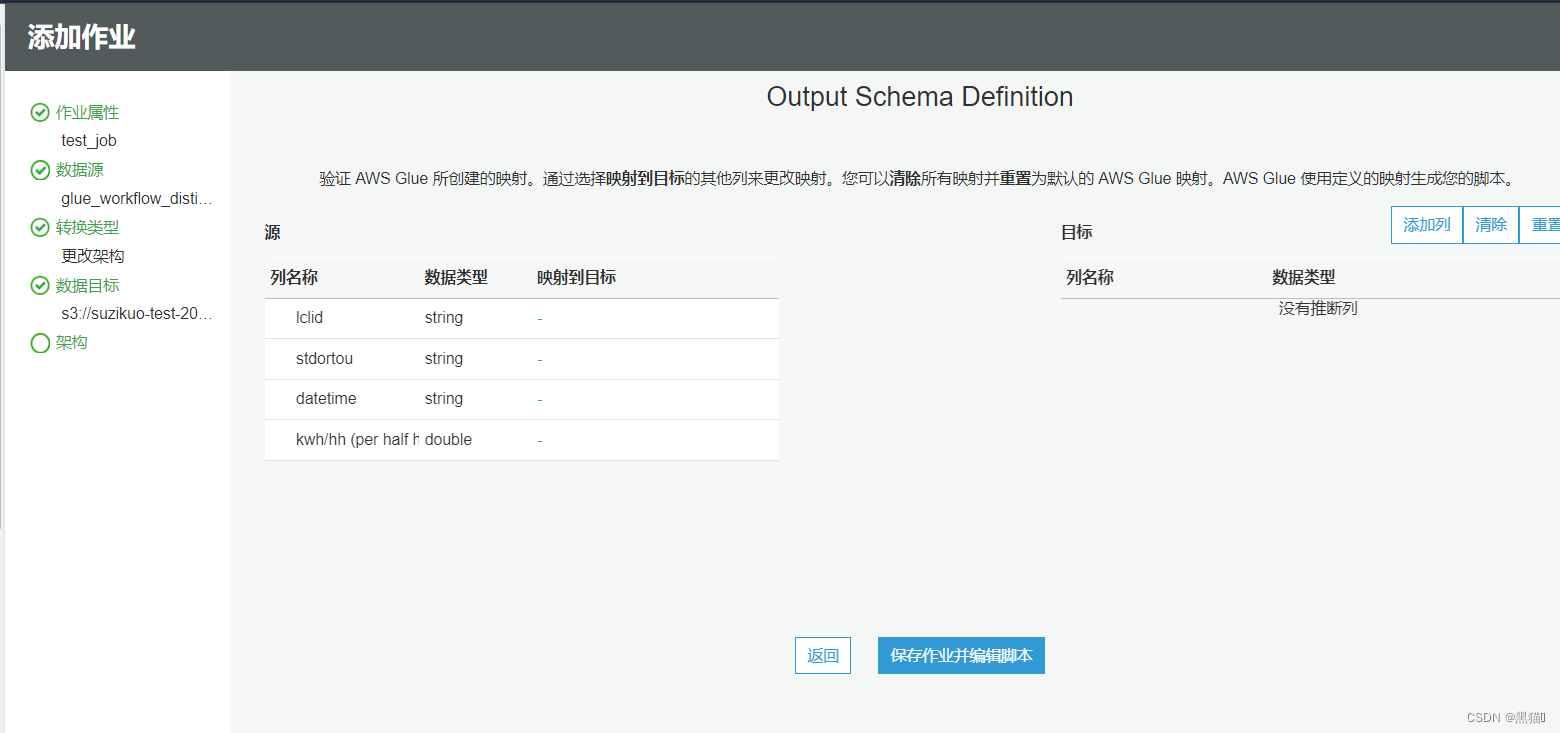 |
| 9、保存 |  |
2.3 编辑脚本
脚本中的args参数的键值需要从Job的安全配置参数中定义
2.3.1 连接数据源(s3)
#数据源
datasource = glueContext.create_dynamic_frame.from_catalog(database = args['db_name'], table_name = tableName, transformation_ctx = "datasource")
2.3.2. 数据结构转换
mapped_readings = ApplyMapping.apply(frame = datasource, mappings = [("lclid", "string", "meter_id", "string"), \("datetime", "string", "reading_time", "string"), \("KWH/hh (per half hour)", "double", "reading_value", "double")], \transformation_ctx = "mapped_readings")
2.3.2 数据结构拆分、定义
mapped_readings_df = DynamicFrame.toDF(mapped_readings)mapped_readings_df = mapped_readings_df.withColumn("obis_code", lit(""))
mapped_readings_df = mapped_readings_df.withColumn("reading_type", lit("INT"))reading_time = to_timestamp(col("reading_time"), "yyyy-MM-dd HH:mm:ss")
mapped_readings_df = mapped_readings_df \.withColumn("week_of_year", weekofyear(reading_time)) \.withColumn("date_str", regexp_replace(col("reading_time").substr(1,10), "-", "")) \.withColumn("day_of_month", dayofmonth(reading_time)) \.withColumn("month", month(reading_time)) \.withColumn("year", year(reading_time)) \.withColumn("hour", hour(reading_time)) \.withColumn("minute", minute(reading_time)) \.withColumn("reading_date_time", reading_time) \.drop("reading_time")
2.3.3 清洗后的数据写入新s3
# write data to S3
filteredMeterReads = DynamicFrame.fromDF(mapped_readings_df, glueContext, "filteredMeterReads")s3_clean_path = "s3://" + args['clean_data_bucket']glueContext.write_dynamic_frame.from_options(frame = filteredMeterReads,connection_type = "s3",connection_options = {"path": s3_clean_path},format = "parquet",transformation_ctx = "s3CleanDatasink")
2.3.4 运行作业
执行成功后,状态将变为"SUCCESS",失败将会给出失败信息,可在CloudWatch 中查看详情
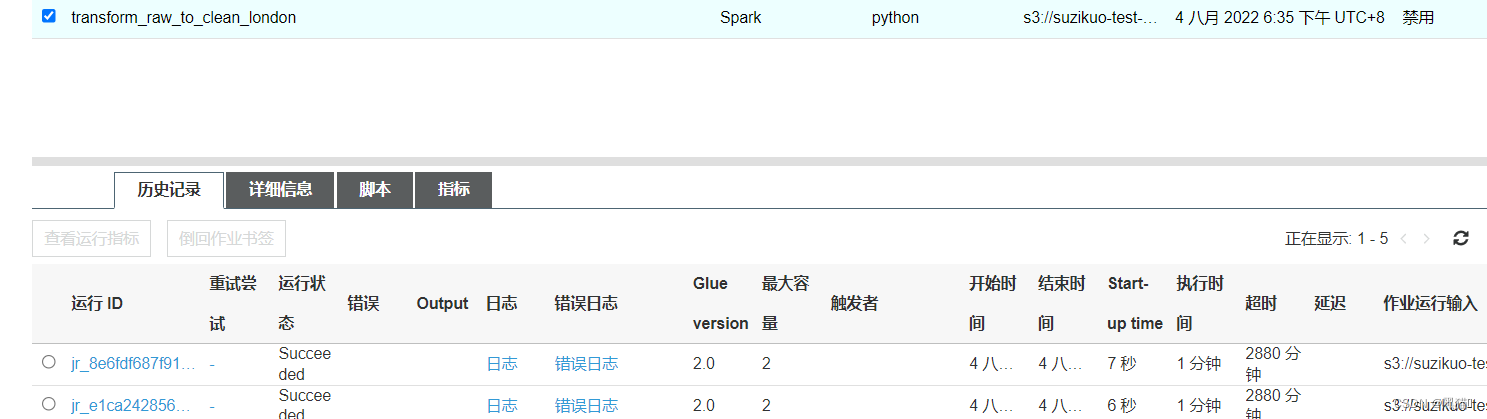
清洗后的数据保存到了s3
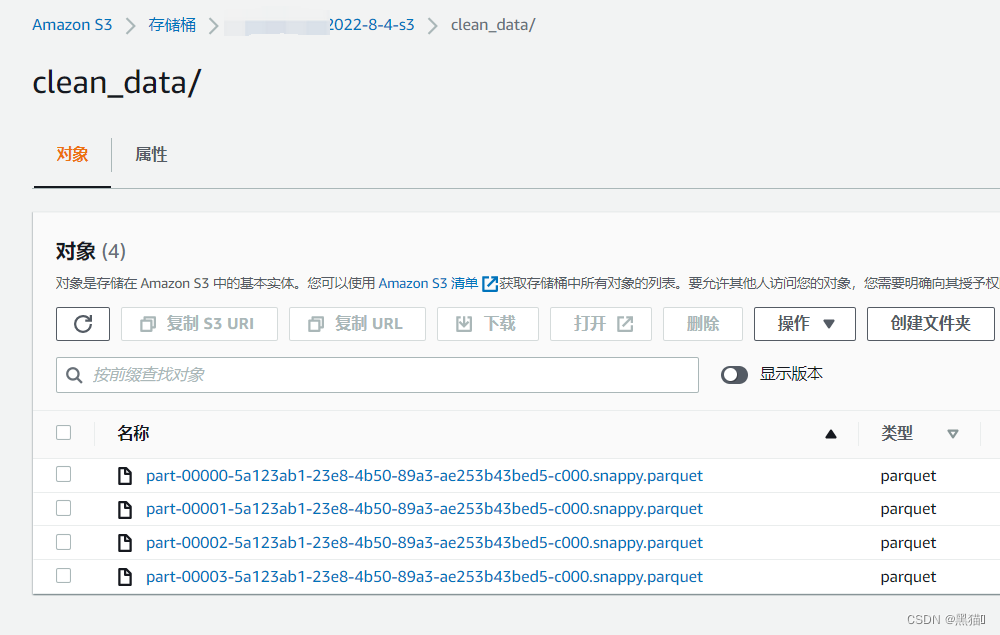
数据清洗完毕后,可通过上一篇中的爬网程序步骤,将清洗后的数据的结构创建表到数据目录中,
此时我们可以使用Athena对清洗后的数据进行分析。
2.4 数据分区
接下来我们对数据进行分区处理(此处只提供了按天分区)
重新进行数据清洗中的创建Job操作后,重写脚本
2.4.1 编辑脚本
连接数据源。表为上一步最后重新爬取生成的新表。
cleanedMeterDataSource = glueContext.create_dynamic_frame.from_catalog(database = args['db_name'], table_name = tableName, transformation_ctx = "cleanedMeterDataSource")
根据type与data_str分区
business_zone_bucket_path_daily = "s3://{}/daily".format(args['business_zone_bucket'])businessZone = glueContext.write_dynamic_frame.from_options(frame = cleanedMeterDataSource, \connection_type = "s3", \connection_options = {"path": business_zone_bucket_path_daily, "partitionKeys": ["reading_type", "date_str"]},\format = "parquet", \transformation_ctx = "businessZone")
2.4.2 运行脚本
分区后的数据结果:
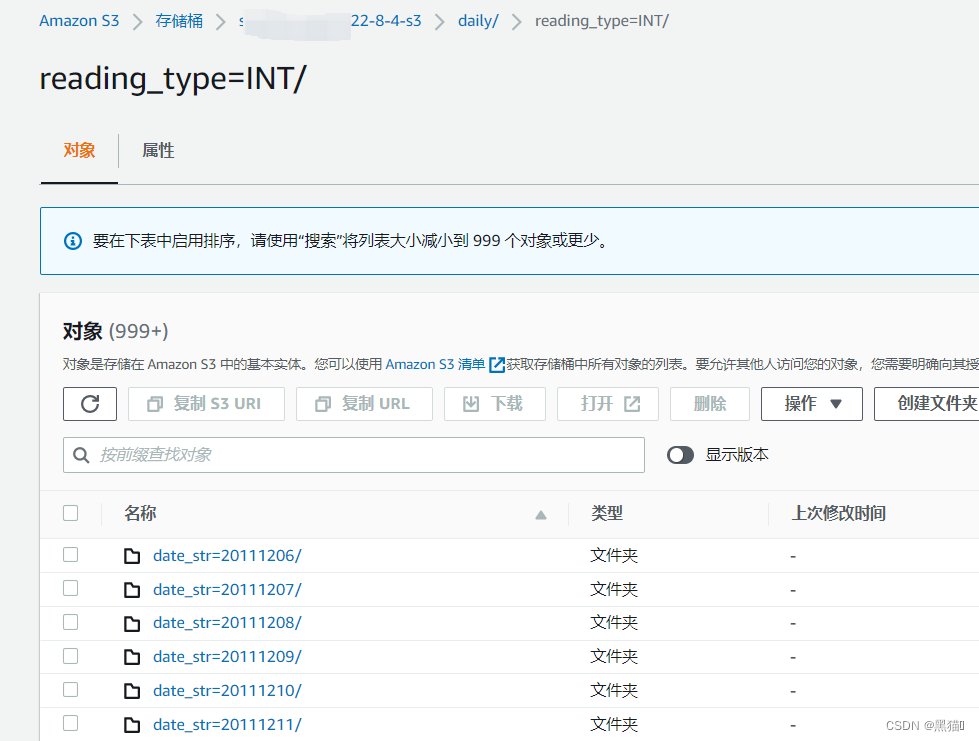
再次创建、运行爬网程序,将会在数据目录中生成新的分区表。
2.5 总结
到这一步,我们已经使用Glue ETL对s3桶中的数据进行了清洗、分区操作。在进行上篇中的Athena操作后,我们已经可以通过Athena直接查询到清洗、分区后的数据集了。
接下来,我们会通过使用APIGateway+Lambda+Athena来构建一个无服务器的数据查询分析服务。
相关文章:
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(二)——数据清洗、转换
2 数据清洗、转换 此实验使用S3作为数据源 ETL: E extract 输入 T transform 转换 L load 输出 大纲 2 数据清洗、转换2.1 架构图2.2 数据清洗2.3 编辑脚本2.3.1 连接数据源(s3)2.3.2. 数据结构转换2.3.2 数据结构拆分…...
vuepress-----6、时间更新
# 6、时间更新 基于Git提交时间修改文字时间格式 moment # 最后更新时间 # 时间格式修改 下载库文件 yarn add momentconst moment require(moment); moment.locale(zh-cn)module.exports {themeConfig: {lastUpdated: 更新时间,},plugins: [[vuepress/last-updated,{trans…...

C++ ini配置文件的简单读取使用
ini文件就是简单的section 下面有对应的键值对 std::map<std::string, std::map<std::string, std::string>>MyIni::readIniFile() {std::ifstream file(filename);if (!file.is_open()) {std::cerr << "Error: Unable to open file " << …...

【稳定检索|投稿优惠】2024年经济管理与安全科学国际学术会议(EMSSIC 2024)
2024年经济管理与安全科学国际学术会议(EMSSIC 2024) 2024 International Conference on Economic Management and Security Sciences(EMSSIC 2024) 一、【会议简介】 2024年经济管理与安全科学国际学术会议(EMSSIC 2024),将于繁华的上海城召开。这次会议的主题是“…...

什么是网站?
这篇文章是我学习网站开发,阶段性总结出来的。可以帮助你 通俗易懂 地更加深刻理解网站的这个玩意。 一,网站和网页的区别? 网站是由一个个网页组成。我们在浏览器上面看到的每一个页面就是网页,这些 相关的 网页组成一个网站。…...

pg_stat_replication.state 含义
在PostgreSQL中,pg_stat_replication视图提供了有关连接到主服务器的流式复制进程(备用服务器)的信息。该视图中的一个列是state,它指示复制进程的当前状态。 state列可以具有各种值: startup: This WAL sender 刚开始运行 catc…...
JavaWeb(六)
一、Maven的常用命令 maven的常用命令有:compile(编译)、clean(清理)、test(测试)、package(打包)、install(安装)。 1.1、compile(编译) compile(编译)的作用有如下两点: 1、从阿里云下载编译需要的jar包,在本地仓库也能看到下载好的插件(远程仓库配置的是阿里…...

GPIO的使用--时钟使能含义--代码封装
目录 一、时钟使能的含义 1.为什么要时钟使能? 2.什么是时钟使能? 3.GPIO的使能信号? 二、代码封装 1.封装前完整代码 2.封装结构 封装后代码 led.c led.h key.c key.h main.c 一、时钟使能的含义 1.为什么要时钟使能?…...

最小化安装 Neokylin7.0 用于搭建 Hadoop 集群
文章目录 环境搭建背景虚拟机创建和环境配置安装过程注意事项虚拟机设置软件选择KOUMP系统分区网络和主机名打开以太网,并记录信息配置 IPv4修改主机名 创建用户 hadoop完全分布式搭建-CSDN博客 环境搭建背景 为什么不从hadoop100或者hadoop101开始,而是…...

苍穹外卖面试题-中
8. 如何理解分组校验 很多情况下,我们会将校验规则写到实体类中的属性上,而这个实体类有可能作为不同功能方法的参数使用,而不同的功能对象参数对象中属性的要求是不一样的。比如我们在新增和修改一个用户对象时,都会接收User对象…...
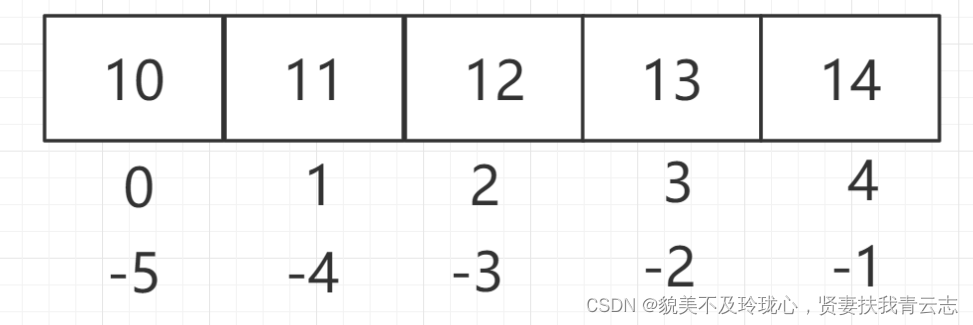
Python 重要数据类型
目录 列表 序列操作 列表内置方法 列表推到式 字典 声明字典 字典基本操作 列表内置方法 字典进阶使用 字典生成式 附录 列表 在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的…...

03、pytest初体验
官方实例 # content of test_sample.py def func(x):return x 1def test_ansewer():assert func(3) 5步骤解释 [100%]指的是所有测试用例的总体进度,完成后,pytest显示一个失败报告,因为func(3)没有返回5 注意:你可以使用ass…...
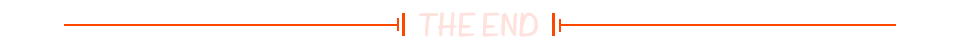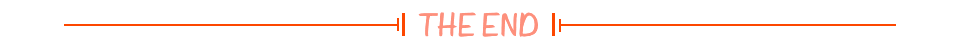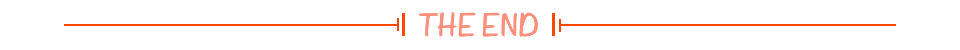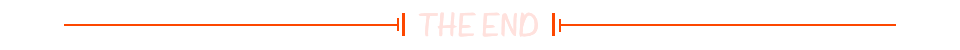
智能指针及强相关知识经验总结 --- 移动语义、引用计数、循环引用、move()、自定义删除器等
目录 前言 一、shared_ptr 1. 基本用法和构造方法 2. 引用计数机制 3. weak_ptr 解决循环引用 二、unique_ptr 1. 基本用法和构造方法 2. 独占性 3. 所有权转移 1)unique_ptr :: release() 2)移动语义 和 move() 三、 对比 shared_ptr 和 un…...
Gson 自动生成适配器插件
在json解析方面 我们常见有下面几方面困扰 1. moshi code-gen能自动生成适配器,序列化效率比gson快,但是自定义程度不如gson,能java kotlin共存 且解决了默认值的问题 2.gson api 强大自由,但是 第一次gson的反射缓存比较慢,而且生成对象都是反射,除非主动注册com.google.gson…...
React创建项目
React创建项目 提前安装好nodejs再进行下面的操作,通过node -v验证是否安装 1.设置源地址 npm config set registry https://registry.npmmirror.com/2.确认源地址 npm config get registry返回如下 https://registry.npmmirror.com/3.输入命令 npx create-re…...
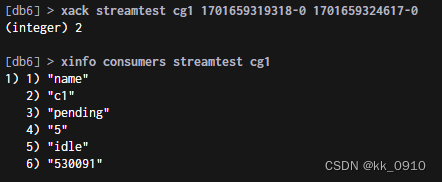
Redis5新特性-stream
Stream队列 Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的 支持多播的可持久化的消息队列,作者声明 Redis Stream 地借鉴了 Kafka 的设计。 生产者 xadd 追加消息 xdel 删除消息,这里的删除仅仅是设置了标志位&am…...
删除PPT文件的备注内容
解决方案的工作经常汇报以及经常做ppt的回报工作,但是删除备注很痛苦。 在网上或者拿历史的ppt文件修改后,需要删除ppt备注内容以及删除ppt个人文件信息的办法: 现象:很多备注信息,需要删除 解决办法一、 文件--信息-…...
2023年亚太杯APMCM数学建模大赛B题玻璃温室小气候调控
2023年亚太杯APMCM数学建模大赛 B题 玻璃温室小气候调控 原题再现 温室作物的产量受各种气候因素的影响,包括温度、湿度和风速[1]。其中,适宜的温度和风速对植物生长至关重要[2]。为了调节玻璃温室内的温度、风速等气候因素,在温室设计中常…...

Oracle 查询语句限制只选择最前面几行,和最后面几行的实现方式。
查询最前面几行 在Oracle中,可以使用 ROWNUM 关键字来限制查询结果的行数。要选择前10条记录,可以使用以下查询语句: SELECT * FROM your_table WHERE ROWNUM < 10;实际查询时将your_table替换为要查询的表名。以上查询将返回表中的前10…...
.NET Core6.0 MVC+layui+SqlSugar 简单增删改查
HTML部分: {ViewData["Title"] "用户列表"; } <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>用户列表</title><meta name"renderer" content"webkit"><meta …...
)
紧急预警:Midjourney即将下架Nihonga相关风格标签?(内部消息+已存档的5类不可再生提示词组合,仅限今日开放获取)
更多请点击: https://intelliparadigm.com 第一章:Nihonga风格在Midjourney中的历史定位与美学内核 Nihonga(日本画)作为明治维新后确立的现代民族绘画体系,以天然矿物颜料、金箔银箔、胶质媒介及传统和纸为物质基础&…...

告别答辩PPT焦虑:百考通AI如何智能化解你的毕业展示难题
当你终于为论文画上最后一个句号,准备迎接毕业的曙光时,答辩PPT的制作却往往成为压垮学生的最后一根稻草。面对这份看似简单却暗藏玄机的任务,百考通AI为你提供智能解决方案。 深夜,当你的论文最后一个字终于落定,一种…...

HarnessGate:专为AI Agent设计的纯消息网关,实现多平台无缝桥接
1. 项目概述:一个纯粹的AI Agent消息网关如果你正在构建一个需要对接多个聊天平台(比如Telegram、Discord、Slack)的AI助手或客服机器人,你很可能已经踩过这样的坑:市面上主流的机器人框架,比如Botpress、L…...

书匠策AI课程论文一键生成?我替你们踩了一遍,真香预警!
各位论文困难户们,先别划走! 今天不聊别的,就聊一个让我这个老博主都直呼"离谱"的东西——书匠策AI的课程论文功能。我知道你们一看到AI写论文就条件反射觉得是割韭菜,但这次,我是真的被圈粉了。 先说结论…...

告别龟速下载!实测对比Axel、Aria2、mwget三大神器,教你选对多线程工具
三大命令行下载神器深度横评:Axel、Aria2与mwget的性能对决 当你在终端里反复输入wget或curl命令,盯着缓慢增长的进度条时,是否想过还有更高效的解决方案?本文将带你深入探索Axel、Aria2和mwget这三款命令行下载加速工具ÿ…...

基于物理信息神经网络与降阶模型的文物数字孪生保护框架
1. 项目概述:当文化遗产保护遇上科学计算与人工智能最近几年,我一直在关注一个交叉领域:如何用前沿的计算科学和人工智能技术,去解决那些看似传统、实则充满挑战的文物保护难题。这次分享的“基于SciML与数字孪生的文化遗产保护框…...

3分钟快速上手:开源AIOps告警管理平台keep终极实战指南
3分钟快速上手:开源AIOps告警管理平台keep终极实战指南 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep 你是否曾经被海量的监控告警淹没,在Prometheus、Gr…...

OpenClaw 接入微信 / 企业微信完整教程
本文介绍如何通过 OpenClaw 框架,将个人微信和企业微信接入 AI Agent,实现「AI 自动回复」的功能。适用于树莓派、Mac/Windows 电脑、NAS 或云服务器等各类设备。 一、环境准备 1.1 安装 OpenClaw OpenClaw 是核心运行环境,负责加载插件、管…...

2026年十大RPA自动化工具盘点:从国际巨头到国产新秀
一、RPA技术的前世今生说起RPA(机器人流程自动化),很多人以为这是近几年才冒出来的新概念。其实不然,自动化的基因早在百年前就埋下了种子。1913年,福特汽车搞出了世界上第一条流水线,那是工业自动化的起点…...

在多模型AI客服场景下利用Taotoken实现成本与效果的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI客服场景下利用Taotoken实现成本与效果的平衡 应用场景类,设想一个在线客服系统需要集成对话AI的场景&#…...