【数据中台】开源项目(5)-Amoro
介绍
Amoro架构
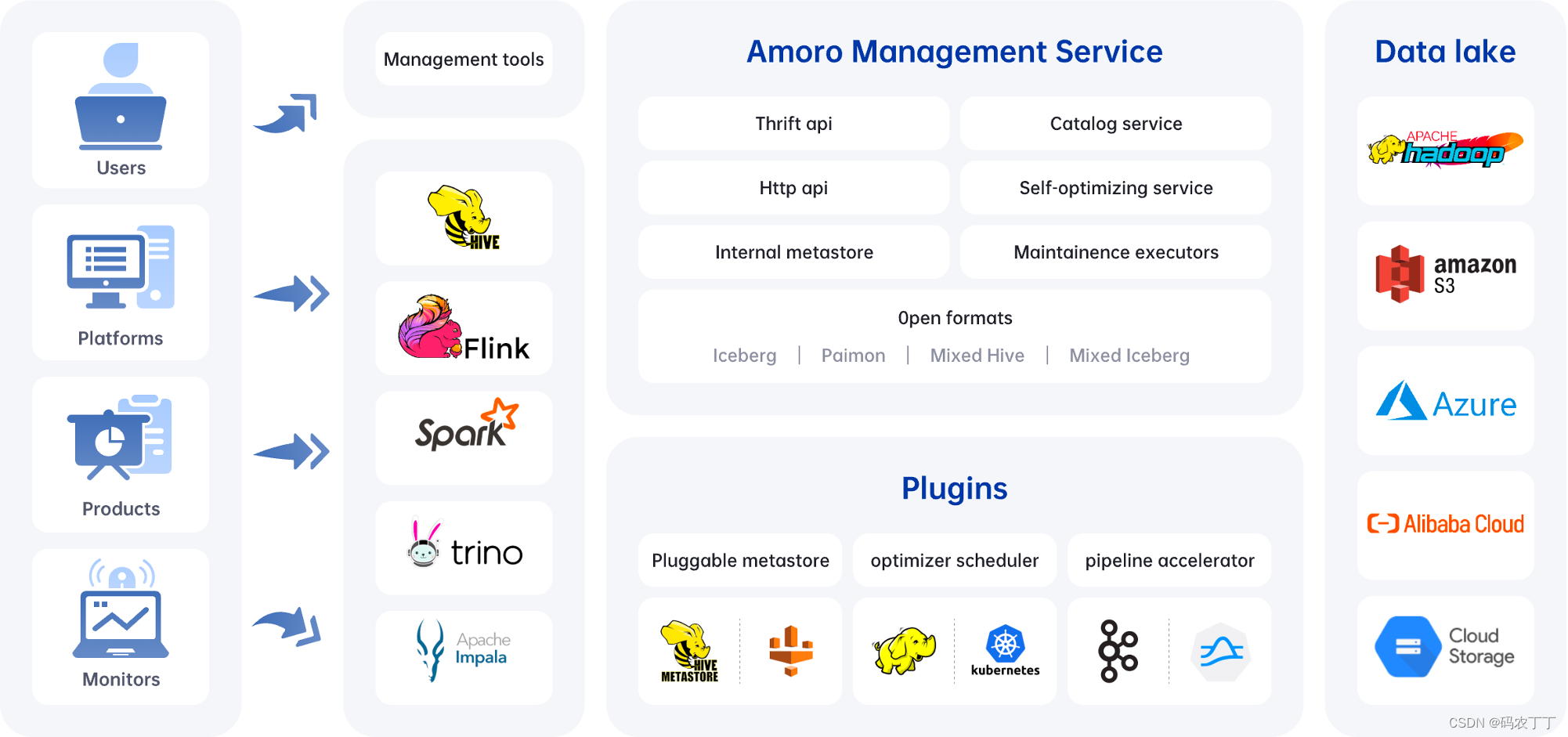
- AMS: Amoro Management Service provides Lakehouse management features, like self-optimizing, data expiration, etc. It also provides a unified catalog service for all computing engines, which can also be combined with existing metadata services.
- Plugins: Amoro provides a wide selection of external plugins to meet different scenarios.
- Optimizers: The self-optimizing execution engine plugin asynchronously performs merging, sorting, deduplication, layout optimization, and other operations on all type table format tables.
- Terminal: SQL command-line tools, provide various implementations like local Spark and Kyuubi.
- LogStore: Provide millisecond to second level SLAs for real-time data processing based on message queues like Kafka and Pulsar.
支持的格式
- Iceberg format: means using the native table format of the Apache Iceberg, which has all the features and characteristics of Iceberg.
- Mixed-Iceberg format: built on top of Iceberg format, which can accelerate data processing using LogStore and provides more efficient query performance and streaming read capability in CDC scenarios.
- Mixed-Hive format: has the same features as the Mixed-Iceberg tables but is compatible with a Hive table. Support upgrading Hive tables to Mixed-Hive tables, and allow Hive’s native read and write methods after upgrading.
支持的引擎
Iceberg format
Paimon format
Mixed format
| Processing Engine | Version | Batch Read | Batch Write | Batch Overwrite | Streaming Read | Streaming Write | Create Table | Alter Table |
| Flink | 1.15.x, 1.16.x and 1.17.x | ✔ | ✔ | ✖ | ✔ | ✔ | ✔ | ✖ |
| Spark | 3.1, 3.2, 3.3 | ✔ | ✔ | ✔ | ✖ | ✖ | ✔ | ✔ |
| Hive | 2.x, 3.x | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
| Trino | 406 | ✔ | ✖ | ✔ | ✖ | ✖ | ✖ | ✔ |
应用场景
Self-managed streaming Lakehouse
Stream-and-batch-fused data pipeline
Cloud-native Lakehouse
相关文章:
【数据中台】开源项目(5)-Amoro
介绍 Amoro is a Lakehouse management system built on open data lake formats. Working with compute engines including Flink, Spark, and Trino, Amoro brings pluggable and self-managed features for Lakehouse to provide out-of-the-box data warehouse experience,…...

_WorldSpaceLightPos0的含义 UNITY SHADER
_WorldSpaceLightPos0 为当前平行光的方向,方向是从光源到照射的方向。 因此,如果要算法线和平行光之间的夹角, 则需要首先将归一化的_WorldSpaceLightPos0去负数。这样才能继续去计算。 也就是: fixed3 reflectdirnormalize…...
iOS不越狱自动挂机
自动挂机在电脑上或者安卓手机上都相对容易,而在不越狱的iOS设备上还是有点难度的。 此方法不是我原创,详情见: 【苹果党福音,ios也能用的挂机脚本】 https://www.bilibili.com/video/BV1sv4y1P7TL/?share_sourcecopy_web&v…...

智能优化算法应用:基于鼠群算法无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于鼠群算法无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于鼠群算法无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.鼠群算法4.实验参数设定5.算法结果6.参考文献7.MATLAB…...
FL Studio中如何录音的技巧,让你的声音更加出众哦!
Hey小伙伴们!今天我要和大家分享一下在FL Studio中如何录音的技巧,让你的声音更加出众哦! 编曲软件FL Studio 即“Fruity Loops Studio ”,也就是众所熟知的水果软件, 全能音乐制作环境或数字音频工作站࿰…...

前端React基础面试题
1,说说react里面bind函数与箭头函数 bind 由于在类中,采用的是严格模式,所以事件回调的时候会丢失this指向,指向的undefined,需要使用bind来给函数绑定上当前实例的this指向。 箭头函数的this指向上下文,所以永久能拿到当前组件实例的。this指向我们可以完美的使用箭头…...

【1day】致远A6系统任意文件下载漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...

朝花夕拾华山平台流水账
2022年8月25日,我加入了诚迈科技(南京),加入了华山平台。 跟我一起入职平台的还有三个小伙伴:小帅、小阳、小甘。 小帅能力很强,前后端都会,入职各种考试工具人。 小阳毕业没多久,一…...

云原生周刊:K8s 的 YAML 技巧 | 2023.12.4
开源项目推荐 Helmfile Helmfile 是用于部署 Helm Chart 的声明性规范。其功能有: 保留图表值文件的目录并维护版本控制中的更改。将 CI/CD 应用于配置更改。定期同步以避免环境偏差。 Docketeer 一款 Docker 和 Kubernetes 开发人员工具,用于管理容…...

Leetcode.2477 到达首都的最少油耗
题目链接 Leetcode.2477 到达首都的最少油耗 rating : 2012 题目描述 给你一棵 n n n 个节点的树(一个无向、连通、无环图),每个节点表示一个城市,编号从 0 0 0 到 n − 1 n - 1 n−1 ,且恰好有 n − 1 n - 1 n−…...
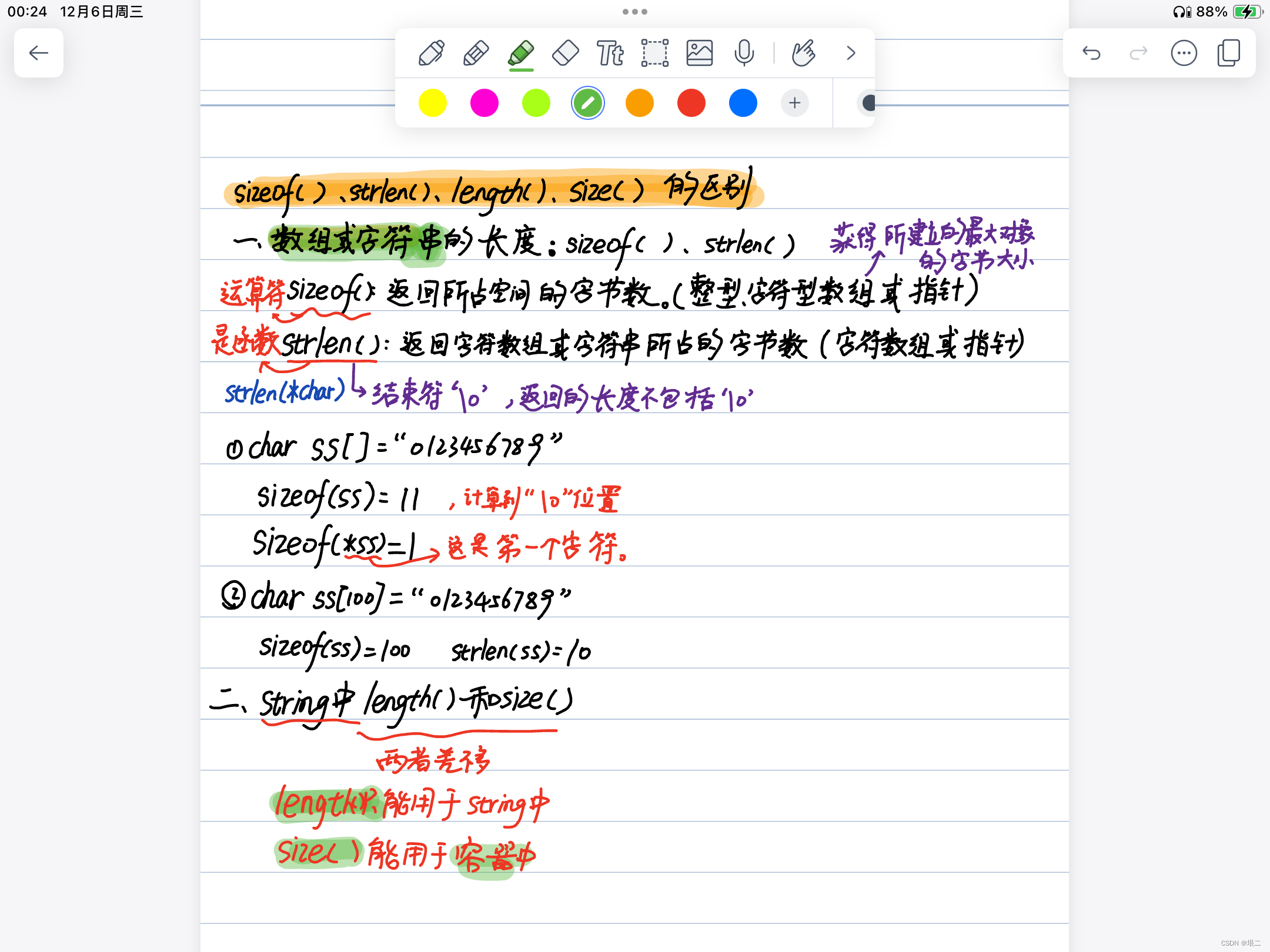
sizeof()、strlen()、length()、size()的区别(笔记)
上面的笔记有点简陋,可以看一下下面这个博主的: c/c中sizeof()、strlen()、length()、size()详解和区别_csize,sizeof,length_xuechanba的博客-CSDN博客...
)
Redis击穿(热点key失效)
Redis击穿是指在高并发情况下,一个键在缓存中过期失效时,同时有大量请求访问该键,导致所有请求都落到数据库上,对数据库造成压力。这种情况下,数据库可能无法及时处理这些请求,导致性能下降甚至崩溃。 为了…...

分类预测 | Matlab实现OOA-CNN-SVM鱼鹰算法优化卷积支持向量机分类预测
分类预测 | Matlab实现OOA-CNN-SVM鱼鹰算法优化卷积支持向量机分类预测 目录 分类预测 | Matlab实现OOA-CNN-SVM鱼鹰算法优化卷积支持向量机分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现OOA-CNN-SVM鱼鹰算法优化卷积支持向量机分类预测࿰…...
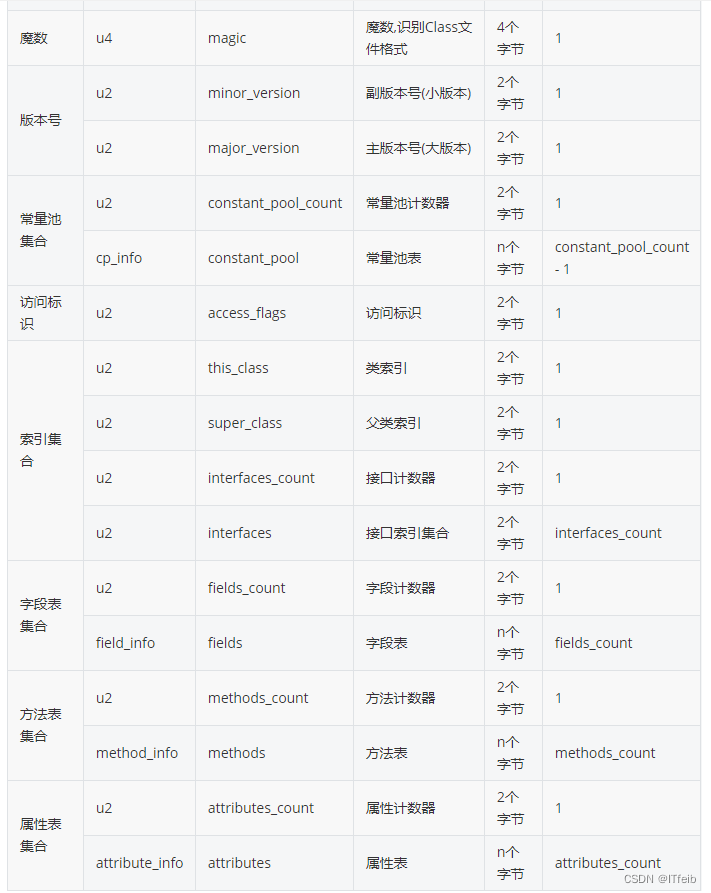
class文件结构
文章目录 1. 常量池集合2. 访问标志3. 字段表集合4. 方法表集合5. 属性表集合 成员变量(非静态)的赋值过程:1. 默认初始化 2. 显示初始化/代码块中初始化 3. 构造器中初始化 4. 有了对象后对象。属性或者对象。方法的方式对成员变量进行赋值 …...

多重背包问题 一句话说清楚“二进制拆分“
目录 区别: 一句话说清楚: 板子: 区别: 得先懂完全背包问题完全背包问题 非零基础-CSDN博客 都是让背包内价值最大。 完全背包问题每种物品可以取无数次。而多重背包问题每件取的次数有限。 都可以用的最挫的方法就是0~k件去…...

nodejs微信小程序+python+PHP本科生优秀作业交流网站的设计与实现-计算机毕业设计推荐
通过软件的需求分析已经获得了系统的基本功能需求,根据需求,将本科生优秀作业交流网站功能模块主要分为管理员模块。管理员添加系统首页、个人中心、用户管理、作业分类管理、作业分享管理、论坛交流、投诉举报、系统管理等操作。 随着信息化社会的形成…...

使用git出现的问题
保证 首先保证自己的git已经下载 其次保证自己的gitee账号已经安装并且已经生成ssh公钥 保证自己要push的代码在要上传的文件夹内并且配置文件等都在父文件夹(也就是文件没有套着文件) 问题 1 $ git push origin master gitgitee.com: Permission de…...
)
rk3568 适配PCIE(二)
rk3568 适配pcie3.0 PCIe(Peripheral Component Interconnect Express)是一种用于连接计算机主板和其他设备的高速串行总线接口。PCIe 2.0和PCIe 3.0是两个不同版本的PCIe规范,它们在以下几个方面有所不同: 带宽:PCIe 2.0的理论带宽为每条通道5 Gbps,而PCIe 3.0的理论带…...

Java基础 进制
在Java中,可以使用不同的进制表示整数常量和字面量。 十进制(Decimal):默认为十进制,不需要添加前缀。例如:int num 10;二进制(Binary):以0b或0B作为前缀表示二进制。例…...

springboot中@Builder注解的详细用法实例,跟数据库结合。
在Spring Boot中,Builder注解是Lombok库提供的一个注解,用于生成带有Builder模式支持的构造器方法。通过Builder注解,可以简化对象的创建过程,特别适用于需要设置多个属性的情况。 下面是一个使用Builder注解的示例: …...

OpenClaw-RUH:基于深度学习的机器人灵巧抓取框架解析与实践
1. 项目概述:当AI遇上“机械爪”最近在AI和机器人交叉的圈子里,一个名为“OpenClaw-RUH”的项目引起了我的注意。乍一看这个标题,你可能会觉得它又是一个开源的机械臂控制项目。但当我深入其代码仓库和社区讨论后,发现它的野心远不…...

如何三步轻松下载B站高清视频:BilibiliDown完整使用指南
如何三步轻松下载B站高清视频:BilibiliDown完整使用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...

突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试
突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今复杂的软件生态中,跨…...

3种实战方法深度解析:如何高效使用TrollInstallerX安装TrollStore越狱工具
3种实战方法深度解析:如何高效使用TrollInstallerX安装TrollStore越狱工具 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14…...

基于BMapGL与MapVGL,实战城市人流热力图可视化
1. 从零开始搭建热力图开发环境 第一次接触百度地图GL版开发时,我也被各种配置搞得晕头转向。现在把完整的环境搭建流程梳理出来,帮你避开我踩过的那些坑。BMapGL作为百度地图的WebGL版本,相比传统API渲染效率提升明显,特别适合数…...

河南AI设计课程指南:机构推荐与避坑秘籍
一、AI 设计热潮下的河南求学路在数字化时代的浪潮中,AI 设计正以前所未有的速度席卷各个行业,成为了创新与效率的新代名词。从广告设计、影视制作到电商运营、交互设计,AI 设计不仅能够大幅提升设计效率,还能通过数据分析和算法模…...

Allegro中Route Keepout、Design Outline和Cutout到底怎么用?一张图讲清PCB布局中的‘禁区’设置
Allegro中三大边界工具实战指南:Route Keepout、Design Outline与Cutout的精准运用 在PCB设计领域,边界定义如同城市规划中的红线,既决定了板卡的物理形态,又影响着电气性能的发挥。Cadence Allegro作为行业标准工具,提…...

苹果防线全线血崩,Mythos5天攻破最强硬件,全球20亿台设备危了
太震撼了,苹果花5年数十亿美元造出最强硬件安全防线MIE,三个黑客加一个AI,5天就把它打穿了!20亿台苹果设备的安全逻辑正在被改写,人类安全系统正迎来「奥本海默时刻」 。 就在刚刚,苹果这座「永不陷落的堡…...
)
DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试实战手册:5步完成生产级对话模型验收(附测试用例模板) DeepSeek Chat 作为开源大语言模型对话接口,其生产就绪性需通过结构化、可…...

3D设计工作流的终极桥梁:如何用stltostp高效解决STL到STEP格式转换难题
3D设计工作流的终极桥梁:如何用stltostp高效解决STL到STEP格式转换难题 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 当你在3D打印与CAD设计之间切换时,是否经常遇到这…...