【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作
【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作
- 前言
- Lambda函数式编程
- Stream流对集合数据操作
- (一)创建Stream流
- (二)中间操作之filter
- (三)中间操作之map
- (四)中间操作之distinct
- (五)中间操作之sorted
- (六)中间操作之limit
- (七)中间操作之skip
- (八)中间操作之flatMap
- (九)终结操作之forEach
- (十)终结操作之count
- (十一)终结操作之max&min
- (十二)终结操作之collect
- (十三)终结操作之anyMatch&allMatch&noneMatch
- (十四)终结操作之findAny
- (十五)终结操作之findFirst
- (十六)终结操作之reduce
- (十七)并行流
- Optional包装类
- 函数式接口
- 最后
前言
以下知识总结,是笔者在b站上学完了相关课程视频,总结而来。有意者可直接通过点击下面链接
【Lambda表达式&Stream流-函数式编程-java8函数式编程(Lambda表达式,Optional,Stream流)从入门到精通-最通俗易懂】 访问三更草堂课程进行视频学习。
Lambda函数式编程
Lambda表达式是Java 8中引入的一个重要特性,它可以用更简洁的方式来表示匿名函数或闭包,使得代码更加简洁和易读。Lambda表达式可以被视为一个匿名函数,它可以作为参数传递给方法或存储在变量中,并且可以在需要时被调用。
Lambda表达式的语法如下:
(parameter1,parameter2) -> expression
// 或
parameter -> expression
// 或
parameter -> { statements; }
// 或
(parameter1,parameter2) -> { statements; }
其中,参数列表(parameter1,parameter2)是一个逗号分隔的参数列表,箭头符号"->"将参数列表和Lambda表达式的主体部分分隔开来。Lambda表达式的主体可以是一个表达式或者一段代码块。
用建立线程的程序可以举例,如下:
public static void main(String[] args) {// 新线程的建立 匿名内部类的方法new Thread(new Runnable() {public void run() {System.out.println("LambdaDemo01新线程运行");}}).start();//优化 lambda方式new Thread(() -> { System.out.println("LambdaDemo01新线程优化运行"); }).start();//继续优化new Thread(() -> System.out.println("LambdaDemo01新线程继续优化运行")).start();}
Stream流对集合数据操作
在Java中,Stream是用来处理集合数据的工具,它引入自Java 8,并提供了一种更加便利和高效的方式来对集合进行操作。Stream提供了一系列的操作方法,可以对集合进行过滤、映射、排序、聚合等操作,同时还支持并行处理,可以充分利用多核处理器的性能。
注意事项
- 惰性求值 (如果没有终结操作,中间操作是不会得到执行的)
- 流是一次性的(一旦一个流对象经过一个终结操作后。这个流就不能再被使用)
- 不会影响原数据(我们在流中可以多数据做很多处理。但是正常情况下是不会影响原来集合中的元素的。这往往也是我们期望的
先准备一个集合数据,方便接下来在程序举例中用到。
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode//用于后期的distinct去重使用
public class Author{//idprivate Long id;//姓名private String name;//年龄private Integer age;//简介private String intro;//作品private List<Book> books;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode//用于后期的distinct去重使用
public class Book {//idprivate Long id;//书名private String name;//分类private String category;//评分private Integer score;//简介private String intro;
}
private static List<Author> getAuthors(){//数据初始化Author author1 = new Author(1L,"蒙多",33,"一个从菜刀中明悟哲理的祖安人",null);Author author2 = new Author(2L,"亚拉索",15,"狂风也追逐不上他的思考速度",null);Author author3 = new Author(3L,"易",14,"是这个世界在限制他的思维",null);Author author4 = new Author(3L,"易",14,"是这个世界在限制他的思维",null);//书籍列表List<Book> books1 = new ArrayList<>();List<Book> books2 = new ArrayList<>();List<Book> books3 = new ArrayList<>();books1.add(new Book(1L,"刀的两侧是光明与黑暗","哲学,爱情",88,"用一把刀划分了爱恨"));books1.add(new Book(2L,"一个人不能死在同一把刀下","个人成长,爱情",99,"讲述如何从失败中明悟真理"));books2.add(new Book(3L,"那风吹不到的地方","哲学",85,"带你用思维去领略世界的尽头"));books2.add(new Book(3L,"那风吹不到的地方","哲学",85,"带你用思维去领略世界的尽头"));books2.add(new Book(4L,"吹或不吹","爱情,个人传记",56,"一个哲学家的恋爱观注定很难把他所在的时代理解"));books3.add(new Book(5L,"你的剑就是我的剑","爱情",56,"无法想象一个武者能对他的伴侣这么的宽容"));books3.add(new Book(6L,"风与剑","个人传记",100,"两个哲学家灵魂和肉体的碰撞会激起怎么样的火花呢?"));books3.add(new Book(6L,"风与剑","个人传记",100,"两个哲学家灵魂和肉体的碰撞会激起怎么样的火花呢?"));author1.setBooks(books1);author2.setBooks(books2);author3.setBooks(books3);author4.setBooks(books3);List<Author> authorlist = new ArrayList<>(Arrays.asList(author1,author2,author3,author4));return authorlist;}
(一)创建Stream流
可以通过多种方式来创建Stream流。以下是一些常见的创建Stream流的方式:
private static void test02(){// 创建流Integer[] arr = {1, 2, 3, 4, 5};Stream<Integer> stream = Arrays.stream(arr); //Stream.of(arr)stream.distinct().filter(integer -> integer>2).forEach(integer -> System. out.println(integer));//双列集合创建流Map<String,Integer> map = new HashMap<>();map.put("蜡笔小新",19);map.put("黑子",17);map.put("日向翔阳",16);Stream<Map.Entry<String, Integer>> streamDD = map.entrySet().stream();streamDD.filter(entry -> entry.getValue() == 19).forEach(entry -> System.out.println(entry));}
Stream流对集合操作是一种链式编程的方式,以创建获取Stream流为开始操作,这里可以通过中间操作和终结操作进行分类分点总结。
(二)中间操作之filter
filter起到的是过滤的作用,通过判断数据是否满足要求来进行过滤。程序举例如下:
private static void test03(){List<Author> authors = getAuthors();//打印所有姓名长度大于1的作家的姓名authors.stream().distinct().filter(author -> author.getName().length()>1).forEach(author -> System.out.println(author.getName()));//testAnd 打印所有姓名长度大于1且年龄大于14的作家的姓名authors.stream().distinct().filter(((Predicate<Author>) author -> author.getName().length() > 1).and(author -> author.getAge()>14)).forEach(author -> System.out.println(author.getName()));//testOr 打印所有姓名长度大于1或年龄大于14的作家的姓名authors.stream().distinct().filter(((Predicate<Author>) author -> author.getName().length() > 1).or(author -> author.getAge()>14)).forEach(author -> System.out.println(author.getName()));//testNegate 打印作家中年龄不大于I7的作家authors.stream().distinct().filter(((Predicate<Author>) author -> author.getAge() > 17).negate()).forEach(author -> System.out.println(author.getName()));}
(三)中间操作之map
map的作用是更改流中的元素,程序举例如下:
private static void test04(){List<Author> authors = getAuthors();//打印所有作家的姓名//用foreach 直接输出authors.stream().forEach(author -> System.out.println(author.getName()));//用map 可以更改流里的元素 再进行输出authors.stream().map(author -> author.getName()).forEach(name -> System.out.println(name));//一些情况根据更改元素的类型可以提高效率authors.stream().mapToInt(author -> author.getAge()).forEach(age -> System.out.println(age));}
(四)中间操作之distinct
distinct起到的作用是对数据进行去重,distinct方法是依赖Obiect的equals方法来判断是否是相同对象的。所以需要注意重写数据的equals方法。
private static void test05(){List<Author> authors = getAuthors();//打印所有作家的姓名,并且要求其中不能有重复元素。authors.stream().map(author -> author.getName()).distinct().forEach(name -> System.out.println(name));}
(五)中间操作之sorted
sorted起到的是排序的作用,程序举例如下:
private static void test06(){List<Author> authors = getAuthors();//对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素authors.stream().distinct().sorted((author1,author2) -> author2.getAge() - author1.getAge()) //如果调用空参的sorted0方法, 需要流中的元素是实现了Comparable.forEach(author -> System.out.println(author.getAge()));//Comparator优化(升序可用,降序的话需要同上写法)authors.stream().distinct().sorted(Comparator.comparingInt(Author::getAge)) //如果调用空参的sorted0方法, 需要流中的元素是实现了Comparable.forEach(author -> System.out.println(author.getAge()));}
(六)中间操作之limit
limit可以设置流的最大长度,超出的部分将被抛弃。程序举例如下:
private static void test07(){List<Author> authors = getAuthors();//对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素,然后打印其中年龄最大的两个作家的姓名。authors.stream().distinct().sorted((author1,author2) -> author2.getAge() - author1.getAge()) //如果调用空参的sorted方法, 需要流中的元素是实现了Comparable.limit(2).forEach(author -> System.out.println(author.getName()));}
(七)中间操作之skip
skip可以跳过流中的前n个元素,返回剩下的元素。程序举例如下:
private static void test08(){List<Author> authors = getAuthors();//打印除了年龄最大的作家外的其他作家,要求不能有重复元素,并且按照年龄降序排序。authors.stream().distinct().sorted((author1,author2) -> author2.getAge() - author1.getAge()) //如果调用空参的sorted0方法, 需要流中的元素是实现了Comparable.skip(1).forEach(author -> System.out.println(author.getName()));}
(八)中间操作之flatMap
map只能把一个对象转换成另一个对象来作为流中的元素。而flatMap可以把一个对象转换成多个对象作为流中的元素,类似于展开操作的作用。程序举例如下:
private static void test09(){List<Author> authors = getAuthors();//打印所有书籍的名字。要求对重复的元素进行去重.authors.stream().flatMap(author -> author.getBooks().stream()).map(book -> book.getName()).distinct().forEach(name -> System.out.println(name));}
(九)终结操作之forEach
forEach对流中的元素进行遍历操作,我们通过传入的参数去指定对遍历到的元素进行什么具体操作。程序举例如下:
private static void test10(){List<Author> authors = getAuthors();//输出所有作家的名字authors.stream().map(Author::getName).distinct().forEach(name -> System.out.println(name));}
(十)终结操作之count
count可以用来获取当前流中元素的个数。程序举例如下:
private static void test11(){List<Author> authors = getAuthors();//打印这些作家的所出书籍的数目,注意删除重复元素long count = authors.stream().flatMap(author -> author.getBooks().stream()).distinct().count();System.out.println(count);}
(十一)终结操作之max&min
max&min可以用来获取流中的最值。程序举例如下:
private static void test12(){List<Author> authors = getAuthors();//分别获取这些作家的所出书籍的最高分和最低分并打印。long max = authors.stream().flatMap(author -> author.getBooks().stream()).max(Comparator.comparingInt(Book::getScore)).get().getScore();System.out.println(max);long min = authors.stream().flatMap(author -> author.getBooks().stream()).min(Comparator.comparingInt(Book::getScore)).get().getScore();System.out.println(min);}
(十二)终结操作之collect
collect可以把当前流转换成一个集合。程序举例如下
private static void test13(){List<Author> authors = getAuthors();//获取一个存放所有作者名字的List集合List<String> authorNameList = authors.stream().map(Author::getName).distinct().collect(Collectors.toList());//获取一个所有书名的Set集合。Set<Book> bookNameSet = authors.stream().flatMap(author -> author.getBooks().stream()).collect(Collectors.toSet());//获取一个map集合,map的key为作者名,value为List<Book>Map<String, List<Book>> authorBookMap = authors.stream().distinct().collect(Collectors.toMap(Author::getName, Author::getBooks));}
(十三)终结操作之anyMatch&allMatch&noneMatch
anyMatch可以用来判断是否有任意符合匹配条件的元素,结果为boolean类型。如果都符合结果为true,否则结果为false。
allMatch可以用来判断是否都符合匹配条件,结果为boolean类型。如果都符合结果为true,否则结果为false。
noneMatch可以判断流中的元素是否都不符合匹配条件。如果都不符合结果为true,否则结果为false。
程序举例如下:
private static void test16(){List<Author> authors = getAuthors();//判断是否有年龄在29以上的作家boolean isExitSomeKindAuthor = authors.stream().anyMatch(author -> author.getAge() > 29);List<Author> authors = getAuthors();//判断是否所有的作家都是成年人boolean isAllAdult = authors.stream().allMatch(author -> author.getAge()>=18);List<Author> authors = getAuthors();//判断作家是否都没有超过100岁的。boolean isAllLowerHundrenAge = authors.stream().noneMatch(author -> author.getAge()>=100);}
(十四)终结操作之findAny
findAny获取流中的任意一个元素。程序举例如下:
private static void test17(){List<Author> authors = getAuthors();//获取任意一个大于18的作家,如果存在就输出他的名字authors.stream().filter(author -> author.getAge() < 18).findAny().ifPresent(author -> System.out.println(author.getName())); //ifPresent 如果存在}
(十五)终结操作之findFirst
获取流中的第一个元素。程序举例如下:
private static void test18(){List<Author> authors = getAuthors();//获取一个年龄最小的作家,并输出他的姓名String name = authors.stream().sorted(Comparator.comparingInt(Author::getAge)).findFirst().get().getName();System.out.println(name);}
(十六)终结操作之reduce
reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值,它会按照我们的计算方式依次拿流中的元素和在初始化值的基础上进行计算,计算结果再和后面的元素计算。
reduce原理示意:
T result = identity;
for (T element : this stream)result = accumulator .apply(result,element)
return result;
使用时程序举例如下:
private static void test19(){List<Author> authors = getAuthors();//使用reduce求所有作者年龄的和Integer sum = authors.stream().distinct().map(author -> author.getAge()).reduce(0,(result, element) -> Math.addExact(result,element));System.out.println(sum);//使用reduce求所有作者中年龄的最大值Integer max = authors.stream().distinct().map(author -> author.getAge()).reduce(Integer.MIN_VALUE,(result, element) -> Math.max(result,element));System.out.println(max);//使用reduce求所有作者中年龄的最小值Integer min = authors.stream().distinct().map(author -> author.getAge()).reduce(Integer.MAX_VALUE,(result, element) -> Math.min(result,element));System.out.println(min);}
(十七)并行流
当流中有大量元素时,我们可以使用并行流去提高操作的效率。其实并行流就是把任务分配给多个线程去完成。如果我们自己去用代码实现的话其实会非常的复杂,并且要求你对并发编程有足够的理解和认识。而如果我们使用Stream的话,我们只需要修改一个方法的调用就可以使用并行流来帮我们实现,从而提高效率。
程序示例如下:
parallel方法可以把串行流转换成并行流 也可以通过parallelStream直接获取并行流对象
private static void test20() {Stream<Integer> stream = Stream.of(1,2,3,4, 5,6,7,8,9,10);Integer sum = stream.parallel().peek(num -> System.out.println(num+Thread.currentThread().getName())) //通常用于调试和日志记录,可以在peek()中输出元素的信息,或者对元素进行一些检查操作。.filter(num -> num > 5).reduce((result, ele) -> result + ele).get() ;System.out.println(sum);Integer sum1 = Arrays.asList(1,2,3,4, 5,6,7,8,9,10).parallelStream().peek(num -> System.out.println(num+Thread.currentThread().getName())) //通常用于调试和日志记录,可以在peek()中输出元素的信息,或者对元素进行一些检查操作。.filter(num -> num > 5).reduce((result, ele) -> result + ele).get();System.out.println(sum1);}
Optional包装类
Optional类似于包装类,可以把我们的具体数据封装Optional对象内部。然后我们去使用Optional中封装好的方法操作封装进去的数据就可以非常优雅的避免空指针异常。
Stream中的一些操作可能会返回Optional类型的结果,比如findFirst()、findAny()等操作,这些操作可能会返回一个包含结果的Optional对象,或者一个空的Optional对象。另外,Stream也提供了一些操作可以将Optional对象转换为Stream,比如Stream.ofNullable()方法可以将一个Optional对象转换为包含该对象的Stream。因此,Optional和Stream在处理可能为空的值时可以相互配合使用。
以下是Optional的一些使用示例:
public class OptionalDemo {public static void main(String[] args) {test04();}/** 创建对象* 我们一般使用Optional的静态方法ofNullable来把数据封装成一个Optional对象。无论传入的参数是否为nul都不会出现问题。*/private static void test01() {Optional<Author> authorOptional = getAuthorOptional();authorOptional.ifPresent(author -> System.out.println(author.getName()));}private static Optional<Author> getAuthorOptional(){Author author = new Author(1L,"蒙多",33,"一个从菜刀中明悟哲理的祖安人",null);// Optional.of(T) 无法排除空指针报错情况,或者return author ==nul1?Optional.empty() :Optional.of(author)return Optional.ofNullable(author);}/** 获取值* 可以使用get方法获取,但是不推荐。因为当Optional内部的数据为空的时候会出现异堂,* orElseGet 获取数据并且设置数据为空时的默认值。* orElseThrow 获取数据,如果数据不为空就能获取到该数据。如果为空则根据你传入的参数来创建异常抛出。*/private static void test02() {Optional<Author> authorOptional = getAuthorOptional();String name = authorOptional.orElseGet(() -> new Author()).getName();System.out.println(name);String name1 = authorOptional.orElseThrow(() -> new RuntimeException("数据为null")).getName();System.out.println(name1);}/** 过滤* 我们可以使用filter方法对数据进行过滤。* 如果原本是有数据的,但是不符合判断,也会变成一个无数据的Optional对象。**/private static void test03() {Optional<Author> authorOptional = getAuthorOptional();String name = authorOptional.filter(author -> author.getAge() > 100).orElseGet(() -> new Author()).getName();System.out.println(name);}/** 判断* 我们可以使用isPresent方法进行是否存在数据的判断。如果为空返回值为false,如果不为空,返回值为true。但是这种方式并不能体现* Optional的好处,更推荐使用ifPresent方法。*/private static void test04() {Optional<Author> authorOptional = getAuthorOptional();// isPresentif (authorOptional.isPresent()){System.out.println(authorOptional.get().getName());}// ifPresentauthorOptional.ifPresent(author -> System.out.println(author.getName()));}/** 数据转换* Optional还提供了map可以让我们的对数据进行转换,并且转换得到的数据也还是被Optiona包装好的,保证了我们的使用安全* 例如我们想获取作家的书籍集合。*/private static void test05() {Optional<Author> authorOptional = getAuthorOptional();Optional<List<Book>> booksOptional = authorOptional.map(author -> author.getBooks());booksOptional.ifPresent(books -> books.stream().forEach(book -> System.out.println(book.getName())));}
}函数式接口
只有一个抽象方法的接口我们称之为函数接口。JDK的函数式接口都上了@Functionallnterface 注解进行标识。但是无论是否加上该注解只要接口中只有一个抽象方法,都是函数式接口。
只要是函数式接口就可以使用函数式编程方法,函数式编程方法的目的就是为了专注于业务,而无需花费精力在名称上。
函数式接口示例如下:
@FunctionalInterface
public interface FunctionalInterfaceExample1<T> {void accept(T t);
}
@FunctionalInterface
public interface FunctionalInterfaceExample2<R,T> {R accept(T t);
}
最后
上述知识总结来自于b站up主三更草堂高质的课程视频,链接如下:
【Lambda表达式&Stream流-函数式编程-java8函数式编程(Lambda表达式,Optional,Stream流)从入门到精通-最通俗易懂】
相关文章:

【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作
【Java】Java8重要特性——Lambda函数式编程以及Stream流对集合数据的操作 前言Lambda函数式编程Stream流对集合数据操作(一)创建Stream流(二)中间操作之filter(三)中间操作之map(四)…...

大话数据结构-查找-散列表查找(哈希表)
注:本文同步发布于稀土掘金。 8 散列表查找(哈希表) 8.1 定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。查找时,根据这个确定的对应关系找到给…...

持续集成交付CICD:Sonarqube自动更新项目质量配置
目录 一、实验 1.Sonarqube手动自定义质量规则并指定项目 2.Sonarqube自动更新项目质量配置 一、实验 1.Sonarqube手动自定义质量规则并指定项目 (1)自定义质量规则 ①新配置 ②更多激活规则③根据需求激活相应规则④已新增配置 ⑤ 查看 &#x…...

Linux设置Docker自动创建Nginx容器脚本
文章目录 前言一、本地新建脚本二、复制本地脚本到服务器三、执行服务器脚本总结如有启发,可点赞收藏哟~ 前言 一、本地新建脚本 在本地新建nginx-generator.sh脚本文件,并保存以下内容 主要动态定义两个变量(容器名称/服务器本地文件名、端…...
技术博客:Vue中各种混淆用法汇总
技术博客:Vue中各种混淆用法汇总 摘要 本文主要介绍了在Vue中使用的一些常见混淆用法,包括new Vue()、export default {}、createApp()、Vue.component、Vue3注册全局组件、Vue.use()等,以及如何使用混淆器对代码进行加固,保护应…...

【python】Python生成GIF动图,多张图片转动态图,pillow
pip install pillow 示例代码: from PIL import Image, ImageSequence# 图片文件名列表 image_files [car.png, detected_map.png, base64_image_out.png]# 打开图片 images [Image.open(filename) for filename in image_files]# 设置输出 GIF 文件名 output_g…...

python/matlab图像去雾/去雨综述
图像去雾和去雨是计算机视觉领域的两个重要任务,旨在提高图像质量和可视化效果。本文将综述图像去雾和去雨的算法、理论以及相关项目代码示例。 一、图像去雾算法 基于暗通道先验的方法: 这是广泛应用于图像去雾的经典算法之一。该方法基于一个观察&…...
Docker+jenkins+gitlab实现持续集成
1.安装环境 服务器ip虚拟机版本192.168.5.132centos7.6192.168.5.152centos7.6 2. 安装docker 安装必要的一些系统工具 yum install -y yum-utils device-mapper-persistent-data lvm2添加软件源信息,要确保centos7能上外网 yum-config-manager --add-repo http:…...

Web前端JS如何获取 Video/Audio 视音频声道(左右声道|多声道)、视音频轨道、音频流数据
写在前面: 根据Web项目开发需求,需要在H5页面中,通过点击视频列表页中的任意视频进入视频详情页,然后根据视频的链接地址,主要是 .mp4 文件格式,在进行播放时实时的显示该视频的音频轨道情况,并…...
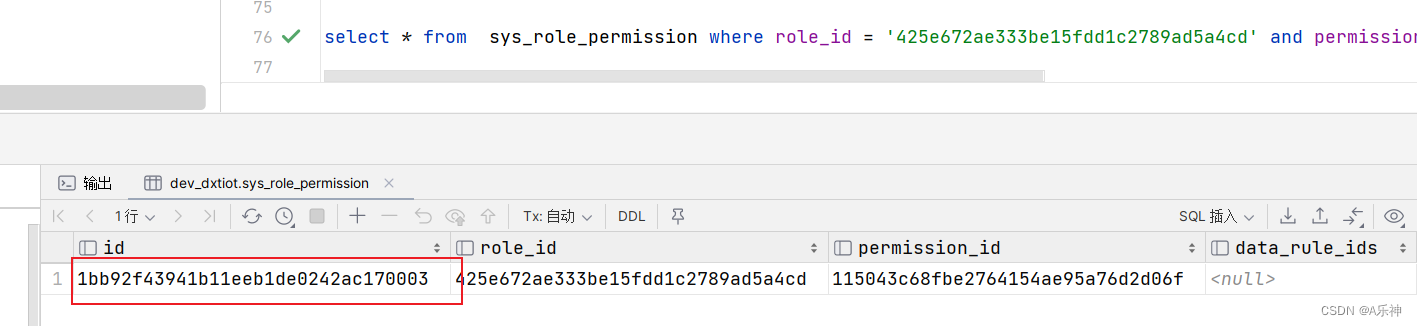
MySQL生成UUID并去除-
uuid()函数 uuid() 函数可以使mysql生成uuid,但是uuid中存在-,如下图: 去除uuid的- 默认生成的uuid含有-,我们可以使用replace函数替换掉-,SQL如下 select replace(uuid(),"-","") as uuid;Insert语句中使用UUID 如果…...

包与字符串
包是分类管理的需要,建立包用:package,包中类的引用import 学习使用javaAPI中的字符串类String,学会其成员方法的使用 (必看)eclipse包的分层等级结构设置 因为eclipse的包的结构默认是平行等级的,所以要手…...
【Gradle】mac环境安装Gradle及配置
官网安装说明:Gradle | Installation 由于Gradle运行依赖jvm,所以事先需要安装jdk,并确认你的jdk版本和gradle版本要求的对应关系,这个官网上有说明,但是我试了一下不太准确,供参考,链接如下&a…...

使用C语言操作kafka ---- librdkafka
1 安装librdkafka git clone https://github.com/edenhill/librdkafka.git cd librdkafka git checkout v1.7.0 ./configure make sudo make install sudo ldconfig 在librdkafka的examples目录下会有示例程序。比如consumer的启动需要下列参数 ./consumer <broker> &…...
误用STM32串口发送标志位 “USART_FLAG_TXE” “USART_FLAG_TC”造成的BUG
当你使用串口发送数据时是否出现过这样的情况: 1.发送时第一个字节丢失。 2.发送时出现莫名的字节丢失。 3.各种情况字节丢失。 1.先了解一下串口发送的流程图(手动描绘): 可以假想USART_FLAG_TXE是用于检测"弹仓"&…...

指针(三)
函数指针 定义:整型指针是指向整形的指针,数组指针式指向数组的指针,其实函数指针就是指向函数的指针。 函数指针基础: ()优先级要高于*;一个变量除去了变量名,便是它的变量类型;一个指针变量…...

labelimg遇到的标签修改问题:修改一张图像的标签时,保存后导致classes.txt改变
问题描述:修改一张图像的标签时候, classes.txt 会同步更新,导致重新生成了 classes.txt 但是这个 classes.txt 只有你现在写的那个类别名,以前的没有了。 解决:设置一个 predefined_classes.txt,内容和模…...

Spring Cloud Gateway使用和配置
Spring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway作为Spring Cloud生态系中的网关ÿ…...

RT-Thread 时钟管理
时钟管理 时钟是非常重要的概念,和朋友出去游玩需要约定时间,完成任务也需要花费时间,生活离不开时间。 操作系统也一样,需要通过时间来规范其任务的执行,操作系统中最小的时间单位是时钟节拍(OS Tick&…...
User: zhangflink is not allowed to impersonate zhangflink
使用hive2连接进行添加数据是报错: [08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: zhangflink is not allowed to impersonate zhangflink 有些文章说需要修…...

深入理解Sentinel系列-1.初识Sentinel
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理、分布式技术原理🔥如果感觉博主的文章还不错的话ÿ…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...

用Ruby实现RISC-V模拟器:从指令集架构到交互式教学工具
1. 项目概述:一个为Ruby语言量身打造的RISC-V模拟器如果你是一名Ruby开发者,或者对RISC-V这个新兴的指令集架构充满好奇,那么你很可能已经听说过RuriOSS/rurima这个名字。简单来说,这是一个用Ruby语言实现的RISC-V指令集模拟器。但…...

TPU材料3D打印iPad Pro保护框:从设计到成品的完整实践指南
1. 项目概述:为什么选择TPU为iPad Pro打造专属保护框?作为一名折腾过几十公斤耗材的3D打印老玩家,我始终认为,这项技术最迷人的地方不在于复刻网上的模型,而在于为手头的心爱之物量身定制解决方案。就拿我手边的这台iP…...

Java源码详解:深入Java并发之AtomicBoolean全景式解析——无锁布尔标志的精妙实现与云原生演进
概述 在高并发编程中,一个看似简单的布尔标志位(如 shutdown、initialized)也可能成为线程安全的隐患。传统的 volatile boolean 虽能保证可见性,却无法保证 “读-改-写” 操作的原子性。为解决这一问题,Java并发包&a…...

DIY LED眼妆:从电路原理到穿戴制作的完整指南
1. 项目概述:打造你的专属发光眼妆想为下一次Cosplay活动或万圣节派对增添一抹赛博朋克般的未来感吗?厌倦了千篇一律的商店货,渴望一件真正独一无二、能让你在人群中脱颖而出的发光装饰?这个DIY LED眼妆项目,正是为你准…...

3D打印LED发光史莱姆:零焊接电子制作与创意材料科学实践
1. 项目概述:当电子制作遇上创意手工几年前,我在一个社区创客空间带孩子们做活动,发现一个挺有意思的现象:一讲到电路、LED、电阻,不少孩子眼神就开始飘忽;但一旦拿出会发光的、可以随意揉捏的“史莱姆”泥…...

大疆M4系列+YOLOV8识别算法 如何训练无人机罂粟识别检测数据集 让非法种植无处可藏:无人机+AI罂粟识别数据集发布,覆盖花期_果期多阶段检测 无人机俯拍+AI识别罂粟
无人机俯拍AI识别罂粟,准确率超95%!,助力禁毒攻坚》 《科技禁毒再升级!YOLO实测mAP 83.9%》 《让非法种植无处可藏:无人机AI罂粟识别数据集发布,覆盖花期/果期多阶段检测 智慧巡检 {专业级AI巡查无人机…...

陕西省ICPC省赛总结
个人反思 我个人感觉还是练的少,学的不够系统。具体反应到题上,表现在看到题没有思路,并且也不知道这道题用到什么算法思想,导致拿的书和本子几乎用不上。其次是思考不够深入,我的队友都能进行深入的思考,但…...

Harness 中的请求标识染色:端到端追踪
1. 标题选项(核心关键词:Harness、请求标识染色、端到端追踪、可观测性、CI/CD) 「Harness 可观测性实战:请求标识染色实现全链路端到端追踪」 「从0到1搞定Harness请求染色:让微服务调用链路+变更链路无所遁形」 「告别排查黑洞:Harness请求标识染色的端到端追踪落地指南…...

C++中的封装、继承、多态理解
封装(encapsulation):就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成”类”,其中数据和函数都是类的成员。封装的目的是增强安全性和简化编程&…...