深入理解mysql的explain命令
1 基础
全网最全 | MySQL EXPLAIN 完全解读
1.1 MySQL中EXPLAIN命令提供的字段包括:
- id:查询的标识符。
- select_type:查询的类型(如SIMPLE, PRIMARY, SUBQUERY等)。
- table:查询的是哪个表。
- partitions:查询中涉及的分区。
- type:join类型(如ALL, index, range等)。
- possible_keys:可能用于此查询的索引。
- key:实际使用的索引。
- key_len:使用的索引的长度。
- ref:哪些列或常量被用于查找索引列上的值。
- rows:估计要检查的行数。
- filtered:按表条件过滤的行百分比。
- Extra:关于查询执行的额外信息。
2 关于id字段的疑惑
2.1 id越大越先执行吗?(不完全对)
记住,id字段更多地表示查询中的逻辑顺序,而不一定完全代表物理执行顺序。在涉及复杂查询,尤其是嵌套子查询和UNION的情况下,理解id字段对于分析查询性能至关重要。
在MySQL的EXPLAIN命令中,id字段表示查询中各个SELECT子句的执行顺序或层级。理解id字段有时可能会有些复杂,但以下是一些基本的规则和示例:
-
相同的
id:具有相同id值的行表示它们是同一层级的查询部分,通常是因为JOIN操作或UNION。 -
递增的
id:通常,id值较小的SELECT会先执行,id值较大的后执行。但在涉及子查询的情况下,子查询(较大的id)实际上会先执行,因为它们的结果通常需要被外层查询(较小的id)所使用。 -
子查询:子查询的
id通常大于主查询的id。子查询先执行,因为外层查询依赖它们的结果。 -
UNION:在UNION中,第一个SELECT的id最小,随后的SELECT``id逐渐增大。
示例
-
简单的JOIN查询:
EXPLAIN SELECT * FROM table1 JOIN table2 ON table1.id = table2.id;这里可能会看到两行输出,每行的
id都是1,表示这是一个单一层级的查询。 -
包含子查询:
EXPLAIN SELECT * FROM (SELECT * FROM table1) AS subquery JOIN table2 ON subquery.id = table2.id;这里可能会看到两行输出,子查询
SELECT * FROM table1的id可能是2,而外层的JOIN查询的id可能是1。尽管id值较大,子查询实际上会先执行。 -
UNION查询:EXPLAIN SELECT * FROM table1 UNION SELECT * FROM table2;在这种情况下,第一个
SELECT的id可能是1,第二个SELECT的id可能是2。
3 关于select_type字段的疑惑
3.1 select_type有哪些字段值
在MySQL的EXPLAIN命令输出中,select_type字段用于描述SELECT语句的类型。以下是select_type可能的值及其含义:
-
SIMPLE:简单的SELECT,不涉及子查询或UNION。
-
PRIMARY:查询中最外层的SELECT。
-
SUBQUERY:SELECT中的子查询。
-
DEPENDENT SUBQUERY:子查询中的SELECT,其结果依赖于外部查询。
-
UNION:UNION操作中的第二个或后续的SELECT。
-
DEPENDENT UNION:UNION中的第二个或后续的SELECT,其结果依赖于外部查询。
-
UNION RESULT:UNION查询的结果。
-
DERIVED:派生表的SELECT,例如,出现在FROM子句中的子查询。
这些不同的select_type值有助于理解复杂查询的执行过程和性能表现。
3.2 针对select_type的字段值,你能各给一个例子吗
当然,以下是select_type字段的各种值及其相应的SQL查询示例:
-
SIMPLE:
SELECT * FROM table1 WHERE column1 = 'value';这是一个没有子查询或UNION的简单查询。
-
PRIMARY:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 FROM table2);这里,最外层的
SELECT是PRIMARY。 -
SUBQUERY:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 FROM table2);这里,
(SELECT column1 FROM table2)是一个SUBQUERY。 -
DEPENDENT SUBQUERY:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 FROM table2 WHERE table2.column2 = table1.column2);子查询依赖于外部查询的结果。
-
UNION:
SELECT * FROM table1 UNION SELECT * FROM table2;第二个
SELECT(和任何后续的SELECT)被视为UNION。 -
DEPENDENT UNION:
这种情况较为复杂,通常涉及到外部查询影响UNION部分的子查询。 -
UNION RESULT:
SELECT * FROM (SELECT * FROM table1 UNION SELECT * FROM table2) AS union_result;这里,UNION的结果被作为派生表处理。
-
DERIVED:
SELECT * FROM (SELECT * FROM table1) AS derived_table;这里,内部的
SELECT是一个派生表查询。
这些例子展示了不同select_type值在实际查询中的应用。理解这些类型有助于分析和优化复杂的SQL查询。
4 索引type字段
4.1 explain的type字段有哪些?
在MySQL的EXPLAIN命令输出中,type字段是一个非常重要的指标,它显示了MySQL决定使用哪种方式来访问表。以下是type字段可能的值,按性能从好到坏排序:
- system:表只有一行数据(等同于系统表),是const类型的一个特例。
- const:表示通过索引一次就找到了,适用于主键或唯一索引的等值查询,const 查询速度非常快,因为最多只返回一行数据。
- eq_ref:一对一关系,唯一索引扫描,用于主键或唯一索引的关联查询。
- ref:非唯一索引扫描,返回匹配某个单个值的所有行。
- fulltext:全文索引。
- ref_or_null:类似ref,但是MySQL会额外搜索包含NULL值的行。
- index_merge:表示使用了索引合并优化。
- unique_subquery:在IN子句中用到的唯一索引查询,该类型和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引。
- index_subquery:在IN子句中用到的非唯一索引查询,和unique_subquery类似,只是子查询使用的是非唯一索引。
- range:只检索给定范围的行,使用一个索引来选择行。范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有BETWEEN子句或WHERE子句里有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
- index:全索引扫描。
- all: 查询条件没有索引,需要全表扫描
index:全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
- 如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
- 按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index
- ALL:全表扫描,性能最差。
4.2 以下是针对MySQL EXPLAIN中type字段的每个值的SQL查询示例:
当然,以下是针对MySQL EXPLAIN中type字段的每个值的SQL查询示例:
- system:
-- 假设table1只有一行数据 SELECT * FROM table1; - const:
-- 假设id为主键 SELECT * FROM table WHERE id = 1; - eq_ref:
-- 假设table2的id是table1的外键 SELECT * FROM table1 JOIN table2 ON table1.id = table2.id; - ref:
-- 假设column是非唯一索引 SELECT * FROM table WHERE column = 'value'; - fulltext:
-- 假设对column列有全文索引 SELECT * FROM table WHERE MATCH(column) AGAINST('text'); - ref_or_null:
-- 假设column是非唯一索引,且可能包含NULL SELECT * FROM table WHERE column = 'value' OR column IS NULL; - index_merge:
-- 假设对column1和column2有单独的索引 SELECT * FROM table WHERE column1 = 'value1' OR column2 = 'value2'; - unique_subquery:
-- 假设id为唯一索引 SELECT * FROM table WHERE id IN (SELECT id FROM table2 WHERE column = 'value'); - index_subquery:
-- 假设column为非唯一索引 SELECT * FROM table WHERE column IN (SELECT column FROM table2 WHERE column2 = 'value'); - range:
-- 假设对column有索引 SELECT * FROM table WHERE column BETWEEN 'value1' AND 'value2'; - index:
-- 假设对column有索引 SELECT column FROM table; - ALL:
-- 无索引的全表扫描 SELECT * FROM table;
这些示例演示了如何在不同情况下生成特定的type值,帮助理解EXPLAIN输出中的这些类型。
4.3 如何理解这里的index,
index:全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
- 如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
- 按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
当然,这里是两个触发index查询类型的MySQL示例:
-
使用覆盖索引的查询:
- 假设
user表有一个覆盖索引idx_name_age,包含name和age列。 - 查询只涉及到这两列,因此MySQL可以只扫描索引而不是整个表:
SELECT name, age FROM user USE INDEX (idx_name_age); - 这个查询中,
EXPLAIN的结果可能会在Extra列显示Using index。
- 假设
-
按索引顺序的全表扫描:
- 假设
user表有一个索引idx_age在age列上。 - 这个查询虽然使用了
age索引,但需要返回表中的其他未索引列,导致全表扫描:SELECT name, age FROM user ORDER BY age; - 在这种情况下,
EXPLAIN的Extra列不会显示Using index,因为它需要访问表中未被索引的数据。
- 假设
在第一个例子中,查询可以完全通过索引来满足,而在第二个例子中,虽然查询利用了索引的顺序,但仍然需要访问表中的额外数据。这两种情况都会触发index类型的查询,但由于不同的使用方式,它们在性能上可能有所差异。
5 一些其他的结果列
5.1 possible_keys中有哪些值
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
5.1.1 key
表示MySQL实际选择的索引
5.1.2 key_len
索引使用的字节数。由于存储格式,当字段允许为NULL时,key_len比不允许为空时大1字节。
key_len计算公式: https://www.cnblogs.com/gomysql/p/4004244.html

5.1.3 ref
表示将哪个字段或常量和key列所使用的字段进行比较。
如果ref是一个函数,则使用的值是函数的结果。要想查看是哪个函数,可在EXPLAIN语句之后紧跟一个SHOW WARNING语句。
5.1.4 rows
MySQL估算会扫描的行数,数值越小越好。
5.1.5 filtered
表示符合查询条件的数据百分比,最大100。用rows × filtered可获得和下一张表连接的行数。例如rows = 1000,filtered = 50%,则和下一张表连接的行数是500。
TIPS
在MySQL 5.7之前,想要显示此字段需使用explain extended命令;
MySQL.5.7及更高版本,explain默认就会展示filtered
6 extra列
6.1 比较关键的几个信息字段
在MySQL的EXPLAIN命令输出中,Extra列提供了关于查询执行的附加信息,这些信息有助于理解MySQL是如何处理查询的。以下是一些关键的Extra字段及其含义的详细介绍:
-
Using index:这表示查询仅通过索引来获取所需的数据,而无需额外读取表中的数据行。这通常发生在覆盖索引的情况下,即查询的所有字段都包含在索引中。
-
Using where:这表示MySQL服务器在从存储引擎接收到数据行后,使用了额外的
WHERE条件来进一步过滤结果。 -
Using index condition:这种情况下,查询的某些列可能未被完全覆盖在索引中。MySQL会首先使用索引来过滤数据,然后使用
WHERE子句中的其余条件进一步筛选这些已过滤的数据行。 -
Using temporary:这表示MySQL为了处理查询,需要创建临时表。这种情况常见于需要对结果进行排序或分组的查询,如使用
DISTINCT、GROUP BY或某些JOIN操作。 -
Using filesort:MySQL使用了外部排序方法来对结果进行排序,而不是直接通过索引排序。当数据量较小时,排序可能在内存中完成,但较大数据量可能需要磁盘排序。出现这种情况时,通常考虑使用索引来优化排序操作。
-
Select tables optimized away:这通常发生在使用聚合函数(如
MAX()或MIN())查询索引列时。MySQL优化器能够直接从索引中获取所需的最大或最小值,而无需实际扫描表中的行。
这些Extra字段值提供了查询优化和性能调整的重要线索。通过理解这些值的含义,可以更好地分析查询效率,并在必要时进行相应的优化。
6.2 分别给我举一个例子
当然,这里是MySQL EXPLAIN命令中Extra列关键字段的示例:
-
Using index:
-- 假设在name字段上有索引 EXPLAIN SELECT name FROM users WHERE name = 'Alice'; -- 这个查询可能显示Using index,因为它只涉及到索引字段 -
Using where:
EXPLAIN SELECT * FROM users WHERE age > 25 AND name = 'Alice';-- 假设在name字段上有索引,但没有在age字段上。这里,MySQL会使用索引找到所有名为'Alice'的行,然后在返回的结果上应用`age > 25`的条件。 -
Using index condition:(索引下推技术)
-- 假设在(name,age)字段上有联合索引, EXPLAIN SELECT name, age FROM users WHERE name LIKE 'A%' AND age > 18; -- 这个查询可能显示Using index condition -
Using temporary:
-- 假设name字段没有索引 EXPLAIN SELECT DISTINCT name FROM users; -- 这个查询可能显示Using temporary,因为需要创建临时表来处理DISTINCT -
Using filesort:
-- 假设name字段没有索引 EXPLAIN SELECT * FROM users ORDER BY name; -- 这个查询可能显示Using filesort,因为需要对结果进行排序 -
Select tables optimized away:
-- 假设id字段是主键 EXPLAIN SELECT MIN(id) FROM users; -- 这个查询可能显示Select tables optimized away,因为可以直接从索引中获得最小值
这些示例展示了不同Extra字段值的典型应用场景。通过这些示例,您可以更好地理解EXPLAIN输出中这些值的含义及其对查询优化的指导意义。
6.3 对于index级别以上的是不是都会导致extra的using index?
在MySQL中,EXPLAIN命令的type字段描述了表的访问类型,而Extra字段则提供了关于查询执行的额外信息。type字段中index级别以上的访问类型并不总是导致Extra字段显示Using index。Using index在Extra字段中出现的具体情况取决于查询是否满足某些特定条件:
-
Using index出现在
Extra字段中的条件是:- 查询操作仅涉及索引中的列,即是所谓的“覆盖索引”。即使查询类型是
index(全索引扫描),但如果查询的列不完全在索引中,Using index就不会出现。
- 查询操作仅涉及索引中的列,即是所谓的“覆盖索引”。即使查询类型是
-
对于
type字段中不同级别的类型,Using index的出现情况如下:- const、eq_ref:这些类型通常表示索引被有效利用,但是否使用
Using index取决于查询的列是否完全由索引覆盖。 - ref、fulltext、ref_or_null、index_merge、unique_subquery、index_subquery、range:这些类型中的
Using index出现也同样依赖于查询是否为覆盖索引的情况。 - index:尽管表示全索引扫描,但
Using index仅当查询列完全由索引覆盖时才会出现。 - ALL:此类型通常表示全表扫描,不会出现
Using index,因为它不依赖于索引来检索数据。
- const、eq_ref:这些类型通常表示索引被有效利用,但是否使用
因此,并非type字段中的index级别以上的访问类型都会导致Extra字段出现Using index。是否出现Using index取决于查询是否能够仅通过索引来获取所需数据,而不需要访问表的数据行。
相关文章:
深入理解mysql的explain命令
1 基础 全网最全 | MySQL EXPLAIN 完全解读 1.1 MySQL中EXPLAIN命令提供的字段包括: id:查询的标识符。select_type:查询的类型(如SIMPLE, PRIMARY, SUBQUERY等)。table:查询的是哪个表。partitions&…...
相交链表(LeetCode 160)
文章目录 1.问题描述2.难度等级3.热门指数4.解题思路方法一:暴力法方法二:哈希表方法三:双栈方法四:双指针:记录链表长度方法五:双指针:互换遍历 5.实现示例参考文献 1.问题描述 给两个单链表的…...
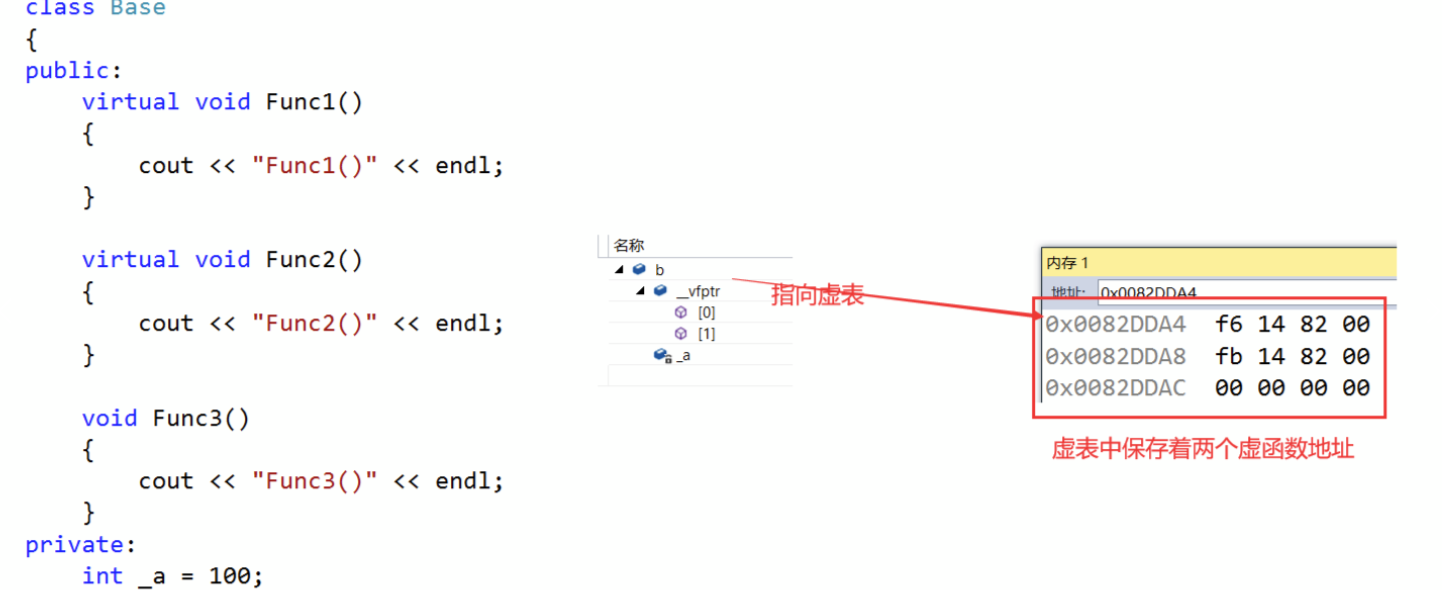
C++多态(详解)
一、多态的概念 1.1、多态的概念 多态:多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。 举个例子:比如买票这个行为,当普通人买票时,是全价买票;学生买票时&am…...
06、基于内容的过滤算法Tensorflow实现
06、基于内容的过滤算法Tensorflow实现 开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。全部工程可从最上方链接下载。 05、基于梯度下降的协同过滤算法中已经介绍了协同过滤算法的基本实现方法,但是这种方法仅…...
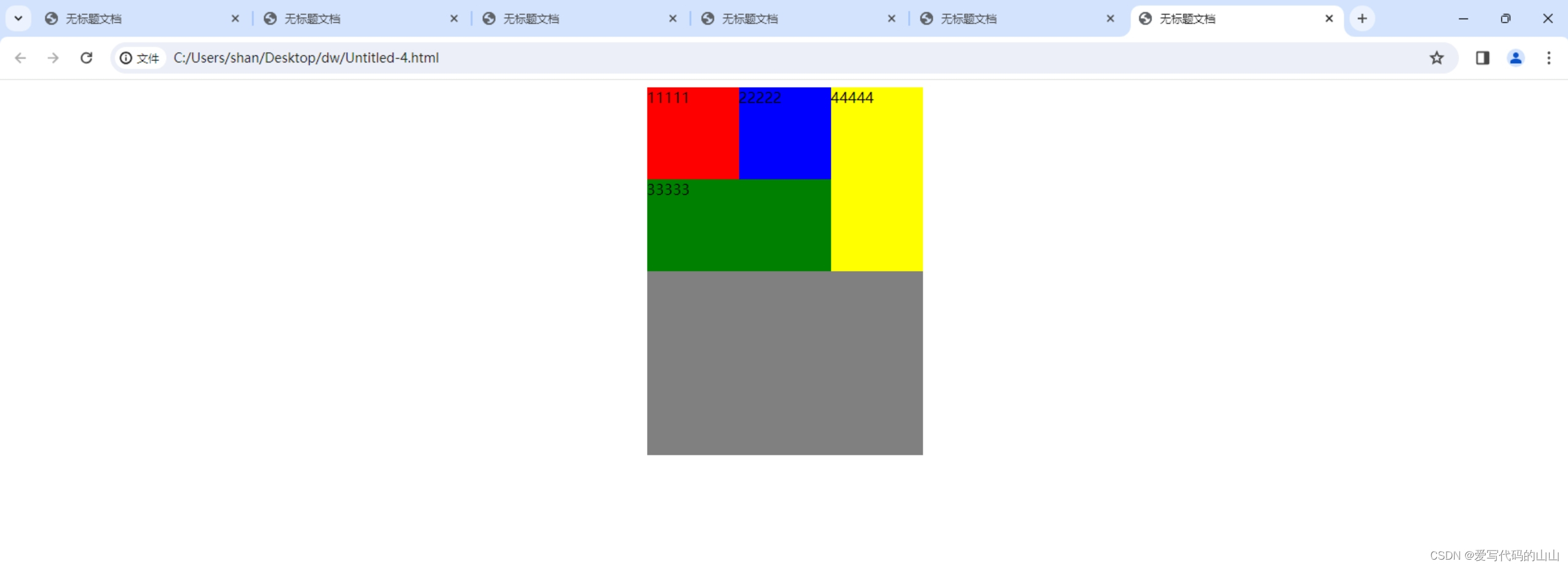
html/css中用float实现的盒子案例
运行效果: 代码部分: <!doctype html> <html> <head> <meta charset"utf-8"> <title>无标题文档</title> <style type"text/css">.father{width:300px; height:400px; background:gray;…...
simulink中 Data store memory、write和read模块及案例介绍
目录 1.Data store memory模块 2.data store write模块 3.data store read模块 4.仿真分析 4.1简单使用三个模块 4.2 模块间的调用顺序剖析 1.Data store memory模块 向右拖拉得到Data store read模块,向左拉得到Data write模块 理解:可视为定义变量…...
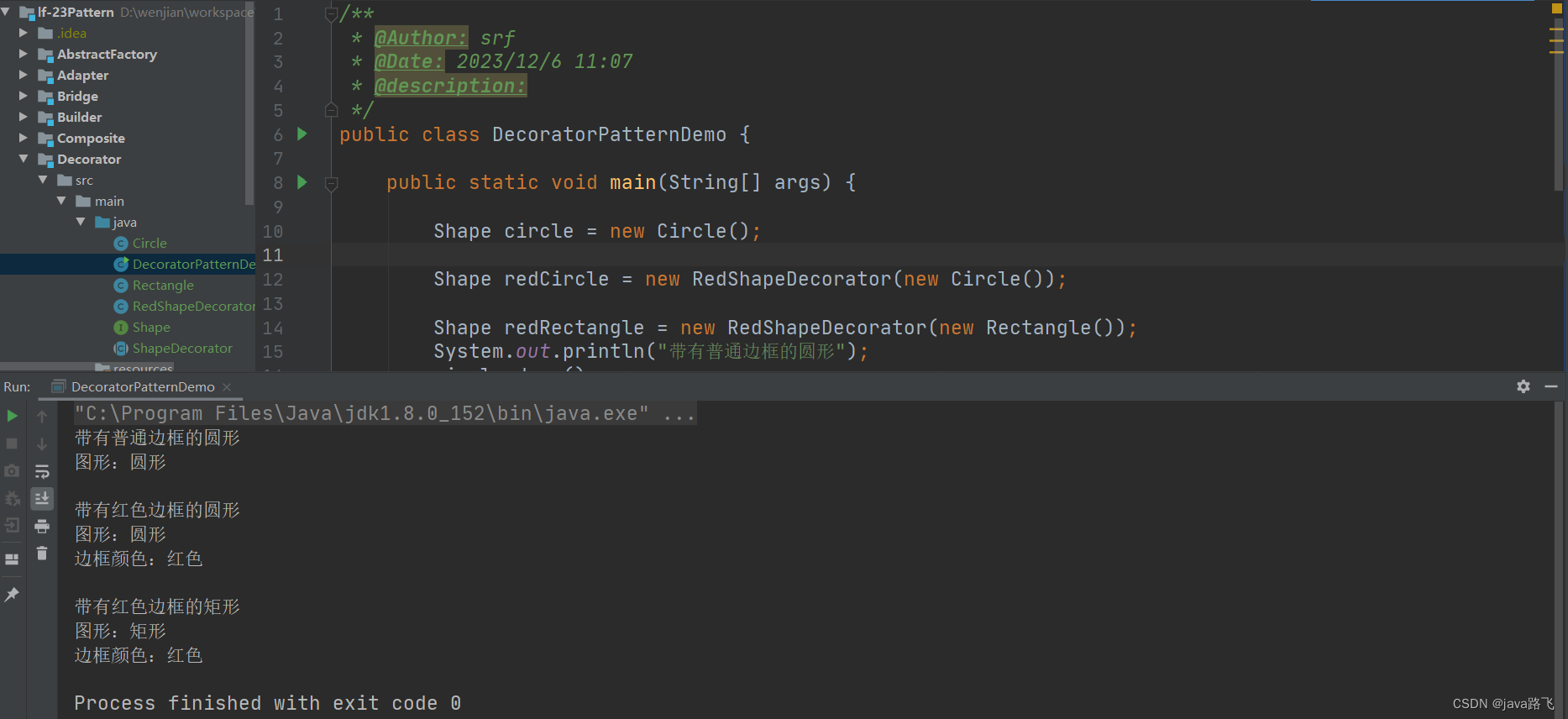
java设计模式学习之【装饰器模式】
文章目录 引言装饰器模式简介定义与用途实现方式 使用场景优势与劣势装饰器模式在Spring中的应用画图示例代码地址 引言 在日常生活中,我们常常对基本事物添加额外的装饰以增强其功能或美观。例如,给手机加一个保护壳来提升其防护能力,或者在…...
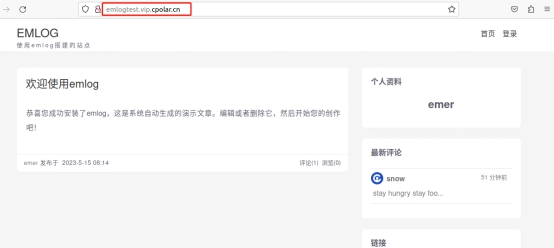
Ubuntu宝塔面板本地部署Emlog个人博客网站并远程访问【内网穿透】
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

简述IO流的使用以及使用时需要注意的事项
Hi i,m JinXiang ⭐ 前言 ⭐ 本篇文章主要介绍介绍IO流的使用以及使用时需要注意的事项以及部分理论知识 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主收将持续更新学习记录获,友友们有任何问题可…...
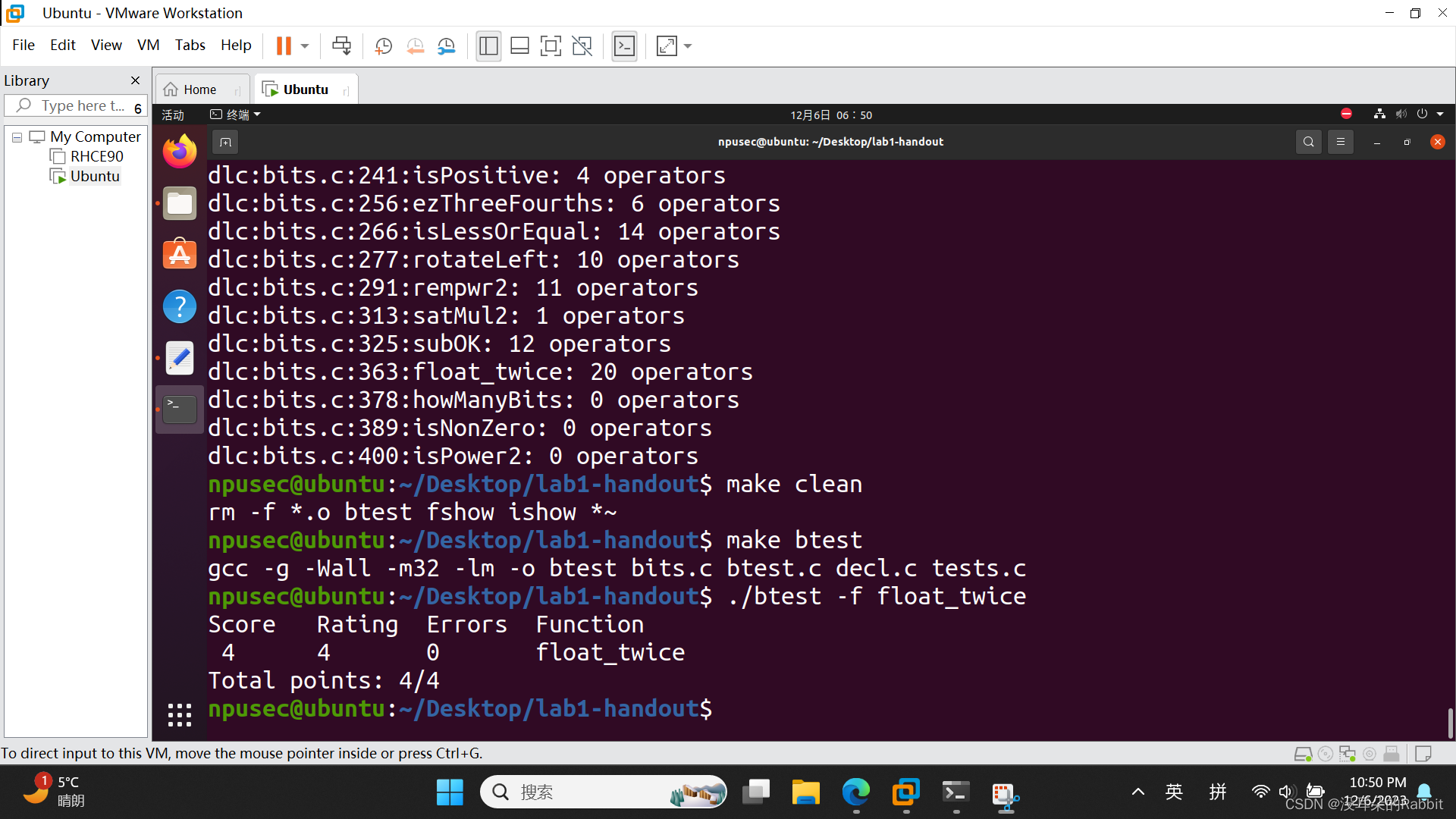
西工大计算机学院计算机系统基础实验一(函数编写11~14)
稳住心态不要慌,如果考试周冲突的话,可以直接复制这篇博客和上一篇博客西工大计算机学院计算机系统基础实验一(函数编写1~10)-CSDN博客最后的代码,然后直接提交,等熬过考试周之后回过头再慢慢做也可以。 第…...
Spring 声明式事务
Spring 声明式事务 1.Spring 事务管理概述1.1 事务管理的重要性1.2 Spring事务管理的两种方式1.2.1 编程式事务管理1.2.2 声明式事务管理 1.3 为什么选择声明式事务管理 2. 声明式事务管理2.1 基本用法2.2 常用属性2.2.1 propagation(传播行为)2.2.2 iso…...

通达OA inc/package/down.php接口存在未授权访问漏洞
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。 一. 产品简介 通达OA(Office Anywhere网络智能办公系统&am…...

数据库原理: 笛卡儿积
笛卡儿积(Cartesian Product)是集合论中的一个概念,也在数据库中的查询操作中经常使用。笛卡儿积是指两个集合(或更多集合)之间所有可能的组合。如果有两个集合A和B,它们的笛卡儿积记作A B,表示…...
docker安装配置prometheus+node_export+grafana
简介 Prometheus是一套开源的监控预警时间序列数据库的组合,Prometheus本身不具备收集监控数据功能,通过获取不同的export收集的数据,存储到时序数据库中。Grafana是一个跨平台的开源的分析和可视化工具,将采集过来的数据实现可视…...
【JavaScript】JS——Map数据类型
【JavaScript】JS——Map数据类型 什么是Map?特性Map与Object的比较 map的创建map的属性map相关方法map的遍历 什么是Map? 存储键值对的对象。 能够记住键的原始插入顺序任何值(对象或原始值)都可以作为键或值。 特性 Map中的一个键只能出现一次&am…...
【【FPGA的 MicroBlaze 的 介绍与使用 】】
FPGA的 MicroBlaze 的 介绍与使用 可编程片上系统(SOPC)的设计 在进行系统设计时,倘若系统非常复杂,采用传统 FPGA 单独用 Verilog/VHDL 语言进行开发的方式,工作量无疑是巨大的,这时调用 MicroBlaze 软核…...

PyQt pdf格式保存
参考文章 pyqt5:利用QFileDialog从本地选择图片\文本文档显示到label、保存图片\label文本到本地(附代码)_pyqt5中qfiledialog.getopenfileurl-CSDN博客 txt文件的打开与保存 def openTextFile(self): # 选择文本文件上传fd,fp QFileDialog.getOpen…...

微前端介绍
目录 微前端概念 微前端特性 场景演示 微前端方案 iframe 方案 qiankun 方案 micro-app 方案 EMP 方案 无界微前端 方案 无界方案 成本低 速度快 原生隔离 功能强大 总结 前言:微前端已经是一个非常成熟的领域了,但开发者不管采用哪个现…...
使用说明书(一,轻量级的visionpro))
工业机器视觉megauging(向光有光)使用说明书(一,轻量级的visionpro)
机器视觉megauging(未名之光,向光有光)程序软件资源已经发布,欢迎下载尝新 8:11 2023/12/2 首先,既然觉得可以发表了,就发表。 其次,我这个人没写过什么软件使用说明书,既然走到这路…...

Java——面试:String 和 StringBuffer 的区别?
相同点: String 和 StringBuffer,它们可以储存和操作字符串, 即包含多个字符的字符数据。 String 和 StringBuffer 的区别有以下几点: 1.String 类提供了数值不可改变的字符串。而 StringBuffer 类提供的字符串进行修改。 当你知…...

移动Git客户端:Android上的完整版本控制解决方案
移动Git客户端:Android上的完整版本控制解决方案 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 在移动开发日益普及的今天,开发者需要在不同场景下管理代码版本。移动Git客户端MGit为Andro…...

Tungsten自适应采样算法:如何智能分配计算资源提升渲染质量
Tungsten自适应采样算法:如何智能分配计算资源提升渲染质量 【免费下载链接】tungsten High performance physically based renderer in C11 项目地址: https://gitcode.com/gh_mirrors/tu/tungsten Tungsten渲染器的自适应采样算法是一种革命性的渲染优化技…...

3步搞定Windows安卓应用安装:告别模拟器的全新体验
3步搞定Windows安卓应用安装:告别模拟器的全新体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行手机应用,却…...

对比直接使用厂商API,Taotoken在账单清晰度上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在账单清晰度上的优势 在集成多个大语言模型到业务中时,开发者或团队通常会面…...

SoC与SoM技术解析:嵌入式开发的双刃剑与选型实战
1. 项目概述:当“系统”成为商品最近几年,无论是消费电子、工业控制还是物联网设备,一个明显的趋势是:越来越多的产品不再从零开始设计核心计算单元。取而代之的,是直接采用一颗高度集成的“片上系统”,或者…...
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在当今内容爆炸的时…...

双机并联自适应虚拟阻抗下垂控制仿真模型附Simulink仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

如何快速构建工业通信系统:SECS4Net的完整实战指南
如何快速构建工业通信系统:SECS4Net的完整实战指南 【免费下载链接】secs4net SECS-II/HSMS-SS/GEM implementation on .NET 项目地址: https://gitcode.com/gh_mirrors/se/secs4net SECS4Net是一个基于.NET平台的开源库,完整实现了SEMI标准的SEC…...

嵌入式九轴传感器融合:LIS2MDL磁力计驱动与六轴IMU集成实战
1. 项目概述:从六轴到九轴,磁力计如何补全运动感知的最后一块拼图在之前的系列文章中,我们已经成功驱动了LSM6DS3TR-C这颗六轴IMU(惯性测量单元),实现了对加速度和角速度的高精度采集与运动检测。但如果你想…...

5分钟搭建Windows离线语音转文字系统:TMSpeech让你的会议记录零压力
5分钟搭建Windows离线语音转文字系统:TMSpeech让你的会议记录零压力 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字化办公时代,实时语音转文字已成为提升工作效率的关键技术。TMSpeec…...