Spark例子
Spark例子
以下是一个简单的AI Spark例子:
假设我们有一个数据集,包含房屋大小、卧室数量和售价。我们想使用Spark来预测房屋售价。
首先,我们需要导入所需的库和数据。在这个例子中,我们将使用Pyspark。
```python
from pyspark.sql.functions import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression# 创建Spark Session
spark = SparkSession.builder.appName('house_price_prediction').getOrCreate()# 导入数据
data = spark.read.csv('house_data.csv', header=True, inferSchema=True)
```然后,我们需要将特征组合到一个向量中,以便我们可以在模型中使用它们。
```python
# 将特征组合到向量中
assembler = VectorAssembler(inputCols=['house_size', 'bedrooms'], outputCol='features')
data = assembler.transform(data)
```接下来,我们将数据集拆分为训练集和测试集。```python
# 拆分数据集
(training_data, test_data) = data.randomSplit([0.7, 0.3], seed=100)
```现在,我们可以训练线性回归模型并使用测试数据进行预测。
```python
# 训练线性回归模型
lr = LinearRegression(featuresCol='features', labelCol='price')
model = lr.fit(training_data)# 使用测试数据进行预测
predictions = model.transform(test_data)
```最后,我们可以计算模型的均方误差(MSE)和平均绝对误差(MAE)。```python
# 计算均方误差和平均绝对误差
mse = predictions.select(avg(pow(col('price') - col('prediction'), 2))).show()
mae = predictions.select(avg(abs(col('price') - col('prediction')))).show()
```这是一个简单的AI Spark例子,用于预测房屋售价。您可以根据需要修改代码以适应您自己的数据集和问题。
JAVA spark
以下是一个使用Spark Java的简单AI例子,使用决策树算法对鸢尾花数据集进行分类
```java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.classification.DecisionTreeModel;
import org.apache.spark.mllib.classification.DecisionTree;
import org.apache.spark.mllib.evaluation.MulticlassMetrics;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
import org.apache.spark.mllib.tree.configuration.Algo;
import org.apache.spark.mllib.tree.configuration.Strategy;
import org.apache.spark.mllib.tree.impurity.Entropy;
import org.apache.spark.mllib.tree.model.*;
import org.apache.spark.mllib.util.MLUtils;public class SparkDecisionTreeExample {public static void main(String[] args) {// 创建SparkConf并设置应用程序名称SparkConf conf = new SparkConf().setAppName("SparkDecisionTreeExample").setMaster("local");// 创建JavaSparkContextJavaSparkContext jsc = new JavaSparkContext(conf);// 加载数据集JavaRDD<LabeledPoint> data = MLUtils.loadLibSVMFile(jsc.sc(), "data/iris.scale").toJavaRDD();// 把数据集随机分为训练集和测试集,其中训练集占60%,测试集占40%JavaRDD<LabeledPoint>[] splits = data.randomSplit(new double[]{0.6, 0.4}, 1234);JavaRDD<LabeledPoint> trainingData = splits[0];JavaRDD<LabeledPoint> testData = splits[1];// 配置算法参数int numClasses = 3;Strategy strategy = new Strategy(Algo.Classification(), Entropy.instance(), 3, 100);// 训练决策树模型DecisionTreeModel model = DecisionTree.train(trainingData.rdd(), strategy);// 对测试集进行预测并计算准确率和召回率JavaRDD<Tuple2<Object, Object>> predictionAndLabels = testData.map(point -> new Tuple2<>(model.predict(point.features()), point.label()));MulticlassMetrics metrics = new MulticlassMetrics(predictionAndLabels.rdd());System.out.println("准确率: " + metrics.accuracy());System.out.println("召回率: " + metrics.weightedRecall());// 保存模型到本地model.save(jsc.sc(), "model");// 加载已经保存的模型DecisionTreeModel savedModel = DecisionTreeModel.load(jsc.sc(), "model");// 打印出决策树模型System.out.println(savedModel.toDebugString());// 关闭JavaSparkContextjsc.close();}
}
```其中,数据集文件iris.scale的格式如下:
```
1 1:0.222 2:0.625 3:0.068 4:0.042
1 1:0.167 2:0.417 3:0.068 4:0.042
1 1:0.111 2:0.5 3:0.051 4:0.042
1 1:0.0833 2:0.458 3:0.0851 4:0.042
1 1:0.194 2:0.667 3:0.068 4:0.042
...
2 1:0.806 2:0.25 3:0.593 4:0.625
2 1:0.944 2:0.333 3:0.694 4:0.792
2 1:0.694 2:0.417 3:0.593 4:0.625
2 1:0.806 2:0.583 3:0.694 4:0.875
2 1:0.611 2:0.25 3:0.593 4:0.583
...
3 1:0.722 2:0.458 3:0.746 4:0.833
3 1:0.694 2:0.417 3:0.694 4:0.708
3 1:0.611 2:0.417 3:0.695 4:0.708
3 1:0.944 2:0.417 3:0.864 4:1
3 1:0.722 2:0.458 3:0.746 4:0.792
...
```数据集中前四个数代表四个特征,第一个数代表该数据所属的类别(共有三个类别),特征值归一化到了[0,1]之间。
pyspark例子
以下是一个简单的AI Spark示例,使用决策树算法预测鸢尾花的品种:
```
# 导入所需的库
from pyspark.ml import Pipeline
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml.feature import VectorAssembler
from pyspark.sql.functions import col# 加载数据
data = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("iris.csv")# 将特征列组合成一个向量
assembler = VectorAssembler(inputCols=["sepal_length", "sepal_width", "petal_length", "petal_width"], outputCol="features")
data = assembler.transform(data)# 将花的种类编码为一个数字标签列
data = data.withColumn("label", col("species").cast("double"))# 拆分数据集为训练集和测试集
(trainingData, testData) = data.randomSplit([0.7, 0.3])# 建立决策树模型
dt = DecisionTreeClassifier(labelCol="label", featuresCol="features")# 建立Pipeline并进行训练
pipeline = Pipeline(stages=[dt])
model = pipeline.fit(trainingData)# 进行预测
predictions = model.transform(testData)# 评估模型性能
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print("Test Accuracy = %g" % accuracy)
```此示例通过将特征列组合成一个向量并将花的品种编码为数字标签列来准备数据。接下来,它将数据集拆分为训练集和测试集,并使用决策树算法作为模型。最后,它对训练后的模型进行了评估,并输出测试集的精度评估结果。
AI(人工智能)系统
AI(人工智能)系统可以使用 Go 语言作为其编程语言。在使用 Go 语言编写 AI 系统时,需要考虑以下方面的管理:
1. 代码管理
使用源代码管理工具(如 Git)管理代码版本并确保代码的稳定性和可重用性。
2. 数据管理
管理和存储 AI 系统所使用的数据,确保其可用性和安全性。
3. 算法管理
选择和管理适合特定任务的机器学习算法,确保其准确性和性能。
4. 资源管理
管理系统所需的硬件和软件资源,以确保系统能够高效运行。
5. 运维管理
确保系统的稳定性和安全性,通过监控、日志记录和故障排除等技术手段进行运维管理。
综上所述,对于 AI 系统的 Go 语言分析,需要对代码、数据、算法、资源和运维等方面进行全面管理。
以下是一个简单的AI Go学习笔记的例子:
第1步:学习基本规则
- 学习棋盘的基本规则和棋子的移动方式。
- 熟悉不同的胜利条件,例如围棋和五子棋。
第2步:了解基本策略
- 学习攻击和防守的基本策略。
- 掌握如何占领棋盘的关键位置。
- 了解各种棋型和它们的优缺点。
第3步:模拟人类棋手
- 学习如何模拟人类棋手的思考过程。
- 研究高水平棋手的棋谱和思路。
- 练习评估局面和制定最佳策略的能力。
假设我们想要训练一个AI来玩五子棋,并且我们希望它模拟人类棋手的行为。
第一步是提供数据集,包含了许多人类玩家的棋谱和他们的胜负情况。我们可以使用这些数据来训练AI,让它能够学习到人类玩家的棋法和战术。
第二步是设计AI的决策过程。我们可以使用深度学习模型,例如卷积神经网络,来处理当前棋盘状态和历史棋盘状态,以预测每一个可能的下一步棋子的胜率。然后,AI可以选择那些具有较高预测胜率的棋子进行下一步。
第三步是优化AI的决策过程。我们可以使用强化学习算法,例如蒙特卡罗树搜索,来模拟未来的棋局,并使用评估函数来衡量每一步的胜率。这样,AI可以在不断地尝试中学习到更好的决策,并且提高自己的棋艺水平。
最后,我们可以使用一些技术来模拟人类玩家的行为,例如调整AI的决策速度、限制AI可见的棋盘范围、随机化AI的棋局等等,从而让AI更加接近人类棋手的水平。
第4步:使用深度学习算法
- 学习如何使用深度学习算法来优化AI Go的决策。
- 训练AI Go通过自我对弈和与人类棋手对弈来提高棋艺。
- 不断改进AI Go的性能和策略,以达到更高的胜率。
五子棋
好的,以下是一个简单的Python 代码示例,使用minimax算法实现AI玩五子棋:
```python
import randomboard = [[' ' for i in range(15)] for j in range(15)]
player = 'X'
opponent = 'O'def print_board(board):print(" ", end="")for i in range(15):print(chr(ord('a')+i), end=" ")print()for i in range(15):print("%2d" % (i+1), end=" ")for j in range(15):print("%c " % board[i][j], end="")print()def check_win(board, player):# 检查水平方向for i in range(15):for j in range(11):if board[i][j] == board[i][j+1] == board[i][j+2] == board[i][j+3] == board[i][j+4] == player:return True# 检查垂直方向for i in range(11):for j in range(15):if board[i][j] == board[i+1][j] == board[i+2][j] == board[i+3][j] == board[i+4][j] == player:return True# 检查正斜向方向for i in range(11):for j in range(11):if board[i][j] == board[i+1][j+1] == board[i+2][j+2] == board[i+3][j+3] == board[i+4][j+4] == player:return True# 检查反斜向方向for i in range(4, 15):for j in range(11):if board[i][j] == board[i-1][j+1] == board[i-2][j+2] == board[i-3][j+3] == board[i-4][j+4] == player:return Truereturn Falsedef get_score(board, player):score = 0# 每个棋子可以影响多个连线,计算每个连线的得分并累加# 棋子越靠中间分数越高for i in range(15):for j in range(15):if board[i][j] == player:for k in range(1, 6):if j+k<15:if board[i][j+k] == player:score += 1elif board[i][j+k] == ' ':score += 0.5else:breakelse:breakfor k in range(1, 6):if i+k<15:if board[i+k][j] == player:score += 1elif board[i+k][j] == ' ':score += 0.5else:breakelse:breakfor k in range(1, 6):if i+k<15 and j+k<15:if board[i+k][j+k] == player:score += 1elif board[i+k][j+k] == ' ':score += 0.5else:breakelse:breakfor k in range(1, 6):if i+k<15 and j-k>=0:if board[i+k][j-k] == player:score += 1elif board[i+k][j-k] == ' ':score += 0.5else:breakelse:breakreturn scoredef minimax(board, depth, alpha, beta, is_maximizing):if check_win(board, opponent):return -1000+depth, Noneif check_win(board, player):return 1000-depth, Noneif depth == 0:return get_score(board, player)-get_score(board, opponent), Noneif is_maximizing:best_move = Nonebest_score = -10000for i in range(15):for j in range(15):if board[i][j] == ' ':board[i][j] = playerscore, _ = minimax(board, depth-1, alpha, beta, False)board[i][j] = ' 'if score > best_score:best_score = scorebest_move = (i, j)alpha = max(alpha, score)if alpha >= beta:breakreturn best_score, best_moveelse:best_move = Nonebest_score = 10000for i in range(15):for j in range(15):if board[i][j] == ' ':board[i][j] = opponentscore, _ = minimax(board, depth-1, alpha, beta, True)board[i][j] = ' 'if score < best_score:best_score = scorebest_move = (i, j)beta = min(beta, score)if beta <= alpha:breakreturn best_score, best_moveprint_board(board)while True:if player == 'X':move = input("请输入您的下棋位置,格式为”a1“:")i = int(move[1:])-1j = ord(move[0])-ord('a')if board[i][j] != ' ':print("该位置已有棋子,请重新输入!")continueboard[i][j] = playerelse:_, move = minimax(board, 3, -10000, 10000, True)i, j = moveboard[i][j] = playerprint("AI下棋到了", chr(ord('a')+j), i+1)print_board(board)if check_win(board, player):print(player, "获胜!")breakif all([all([x != ' ' for x in row]) for row in board]):print("游戏结束,平局。")breakplayer, opponent = opponent, player
```运行后,可以和AI玩五子棋。玩家用X,AI用O。玩家先手,AI后手。
AI使用minimax算法,在深度为3的情况下,可以在几秒内计算出下一步最优的位置。
Minimax算法
以下是一个简单的Python实现,使用Minimax算法来求解两个玩家在Tic Tac Toe游戏中的最佳棋步:```python
import copy# 定义游戏状态类
class GameState:def __init__(self, board, player):self.board = boardself.player = player# 返回所有合法的棋步def get_legal_moves(self):moves = []for i in range(3):for j in range(3):if self.board[i][j] == ' ':moves.append((i, j))return moves# 返回当前游戏是否结束def is_game_over(self):# 判断是否有一行、一列或者对角线都被同一玩家占满for i in range(3):if self.board[i][0] != ' ' and self.board[i][0] == self.board[i][1] == self.board[i][2]:return Trueif self.board[0][i] != ' ' and self.board[0][i] == self.board[1][i] == self.board[2][i]:return Trueif self.board[0][0] != ' ' and self.board[0][0] == self.board[1][1] == self.board[2][2]:return Trueif self.board[0][2] != ' ' and self.board[0][2] == self.board[1][1] == self.board[2][0]:return True# 判断是否所有位置都被占满for i in range(3):for j in range(3):if self.board[i][j] == ' ':return Falsereturn True# 返回当前游戏胜者(如果有)def get_winner(self):# 判断是否有一行、一列或者对角线都被同一玩家占满for i in range(3):if self.board[i][0] != ' ' and self.board[i][0] == self.board[i][1] == self.board[i][2]:return self.board[i][0]if self.board[0][i] != ' ' and self.board[0][i] == self.board[1][i] == self.board[2][i]:return self.board[0][i]if self.board[0][0] != ' ' and self.board[0][0] == self.board[1][1] == self.board[2][2]:return self.board[0][0]if self.board[0][2] != ' ' and self.board[0][2] == self.board[1][1] == self.board[2][0]:return self.board[0][2]return None# 执行一个棋步,返回一个新的GameState对象def execute_move(self, move):board = copy.deepcopy(self.board)board[move[0]][move[1]] = self.playerplayer = 'O' if self.player == 'X' else 'X'return GameState(board, player)# 定义Minimax算法
def minimax(state, depth, is_max_player):if state.is_game_over() or depth == 0:score = 0winner = state.get_winner()if winner == 'X':score = 1elif winner == 'O':score = -1return scoreif is_max_player:best_score = -float('inf')for move in state.get_legal_moves():new_state = state.execute_move(move)score = minimax(new_state, depth - 1, False)best_score = max(best_score, score)return best_scoreelse:best_score = float('inf')for move in state.get_legal_moves():new_state = state.execute_move(move)score = minimax(new_state, depth - 1, True)best_score = min(best_score, score)return best_score# 定义AI类
class AI:def get_best_move(self, state):best_move = Nonebest_score = -float('inf')for move in state.get_legal_moves():new_state = state.execute_move(move)score = minimax(new_state, 5, False)if score > best_score:best_move = movebest_score = scorereturn best_move# 运行游戏
state = GameState([[' ', ' ', ' '], [' ', ' ', ' '], [' ', ' ', ' ']], 'X')
ai = AI()while not state.is_game_over():if state.player == 'X':print("Player X's turn")x = int(input('Enter x coordinate: '))y = int(input('Enter y coordinate: '))state.board[x][y] = 'X'else:print("Player O's turn")move = ai.get_best_move(state)state.board[move[0]][move[1]] = 'O'for row in state.board:print(row)state.player = 'O' if state.player == 'X' else 'X'winner = state.get_winner()
if winner == 'X':print('Player X wins!')
elif winner == 'O':print('Player O wins!')
else:print('The game is a tie.')
```希望这个简单的例子可以帮到你理解Minimax算法的实现。Tf例子
import tensorflow as tf
import numpy as np# 定义数据
x_train = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y_train = np.array([5.0, 8.0, 11.0, 14.0, 17.0])# 定义模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(1, input_shape=(1,)))# 编译模型
model.compile(optimizer=tf.optimizers.SGD(learning_rate=0.01), loss='mse')# 训练模型
model.fit(x_train, y_train, epochs=1000)# 预测
x_test = np.array([6.0, 7.0, 8.0])
y_pred = model.predict(x_test)
print(y_pred)Stochastic Gradient Descent(SGD)
在该例子中,我们定义了一个包含一个 Dense 层的模型,使用 SGD 优化器和均方误差损失函数进行编译,并使用 fit 函数进行训练。最后,我们使用 predict 函数进行预测
下面是一份使用Stochastic Gradient Descent(SGD)算法实现二元分类的Python代码示例
```python
from sklearn.linear_model import SGDClassifier
import numpy as np# 训练数据
X_train = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y_train = np.array([0, 1, 1, 1])# 创建SGD分类器
clf = SGDClassifier(loss="hinge", penalty="l2", max_iter=1000)# 训练模型
clf.fit(X_train, y_train)# 预测新数据
X_test = np.array([[2, 2], [-1, -1]])
y_pred = clf.predict(X_test)print(y_pred) # 输出:[1 0]
```这段代码使用了`sklearn`库中的`SGDClassifier`来实现分类任务,其中`loss`参数指定为"hinge",表示使用hinge损失函数;`penalty`参数指定为"l2",表示使用L2正则化项;`max_iter`参数指定训练模型的最大迭代次数。
在训练完成后,我们可以使用`predict`方法来对新的数据进行预测,如上述代码中的`X_test`。最后,我们输出了预测结果`y_pred`,可以看到,模型成功地将第一个数据归为类别1,将第二个数据归为类别0。
AI 电商系统
是一个利用人工智能技术来提升电商平台的效率和精准度的系统。Python 是一种开源的、高级的编程语言,有着丰富的第三方库和工具,非常适合用于开发人工智能应用程序。
在开发 AI 电商系统时,Python 可以用于以下方面:
1. 数据分析和处理
Python 的 pandas、numpy 等库可以帮助电商平台对用户行为、商品销售数据等进行分析和处理。
2. 机器学习和深度学习
Python 的机器学习库 scikit-learn、深度学习框架 TensorFlow、PyTorch 等可以用于构建推荐系统、搜索引擎、图像识别等 AI 功能。
3. 网络编程和 Web 开发
Python 的 Django、Flask 等 Web 框架可以用于开发电商平台的后台管理系统、商家管理系统等。
4. 自然语言处理
Python 的自然语言处理库 NLTK、spaCy 等可以用于处理商品描述、评论等文本信息,提取关键词、情感分析等功能。
综上所述,Python 是开发 AI 电商系统的一种非常好的编程语言选择。
一个简单的PyTorch例子
import torch
import torch.nn as nn
import torch.optim as optim# 创建数据集
x_train = torch.tensor([[1.0],[2.0],[3.0],[4.0]])
y_train = torch.tensor([[0],[0],[1],[1]])# 定义模型结构
class LinearClassifier(nn.Module):def __init__(self):super(LinearClassifier, self).__init__()self.linear = nn.Linear(1, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.linear(x)x = self.sigmoid(x)return x# 定义模型实例,损失函数,优化器
model = LinearClassifier()
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(1000):optimizer.zero_grad()y_pred = model(x_train)loss = criterion(y_pred, y_train)loss.backward()optimizer.step()# 测试模型
x_test = torch.tensor([[2.5],[3.5]])
y_pred = model(x_test)
print(y_pred)AI PyTorch 视频分析是一种使用深度学习技术和 PyTorch 框架对视频数据进行分析和处理的方法。这种方法可以用于多种应用场景,比如视频分类、行为识别、物体追踪、目标检测等。
具体来说,该方法首先将视频数据转换成适合深度学习模型的张量形式,然后使用预训练的模型或自己构建的模型对视频数据进行处理。在 PyTorch 中,可以使用现成的神经网络模块(例如 torchvision 中的模块)或自己构建的模块来进行视频分析。
在视频分析中,还需要使用一些技术来提高模型的准确性和效率。例如,可使用数据增强技术来扩充数据集,采用深度学习模型优化技术来提高模型的性能,使用并行计算技术来加速模型的训练和推理过程等。
AI PyTorch 视频分析法已经在多个领域得到应用,例如
智慧城市
PyTorch 是一个流行的深度学习框架,它可以用于构建和训练各种类型的神经网络模型。智慧城市是一种利用物联网、人工智能、云计算和大数据等技术手段来提高城市管理和服务水平的城市化发展模式。在智慧城市建设中,PyTorch 可以用于构建和训练各种类型的深度学习模型,如图像识别、自然语言处理、预测和优化等。这些模型可以用于解决智慧城市中的各种问题,如交通拥堵、智慧安防、环境监测、疫情追踪等。同时,PyTorch 还可以通过分布式训练和模型部署等技术手段来提高模型的效率和性能,并支持与其他大数据工具和平台的互操作性。
以下是一个 AI 自动语言的例子:
原始文本:我爱你。
AI 自动语言输出:我也爱你。
相关文章:

Spark例子
Spark例子 以下是一个简单的AI Spark例子: 假设我们有一个数据集,包含房屋大小、卧室数量和售价。我们想使用Spark来预测房屋售价。 首先,我们需要导入所需的库和数据。在这个例子中,我们将使用Pyspark。 python from pyspark…...

linux下ls和df卡死
1. strace看下卡在哪里 https://lokie.wang/article/43 strace ls strace df -h 2. 原因 https://segmentfault.com/a/1190000040620740 3. fuser 和 umount都不行,最后只能重启 重启机器还起不来了垃圾...
iOS(swiftui)——系统悬浮窗( 可在其他应用上显示,可实时更新内容)
因为ios系统对权限的限制是比较严格的,ios系统本身是不支持全局悬浮窗(可在其他app上显示)。在iphone14及之后的iPhone机型中提供了一个叫 灵动岛的功能,可以在手机上方可以添加一个悬浮窗显示内容并实时更新,但这个功能有很多局限性 如:需要iPhone14及之后的机型且系统…...

css弹窗动画效果,示例弹窗从底部弹出
从底部弹出来,有过渡动画效果 用max-height可以自适应内容的高度,当内容会超过最大高度时可以在弹窗里加个scroll-view 弹窗不能用v-if来隐藏,不然transition没效果,transition只能对已有dom元素起效果,所以用透明和v…...

STM32CubeIDE(CUBE-MX hal库)----RTC时钟,时钟实时显示
系列文章目录 STM32CubeIDE(CUBE-MX hal库)----初尝点亮小灯 STM32CubeIDE(CUBE-MX hal库)----按键控制 STM32CubeIDE(CUBE-MX hal库)----串口通信 STM32CubeIDE(CUBE-MX hal库)----定时器 STM32CubeIDE(CUBE-MX hal库)----蓝牙模块HC-05(详细配置) 前言…...

ubuntu 安装Nvidia驱动
官网下载 sudo bash NVIDIA。。。。。跟着b站机器人工匠阿杰即可。...
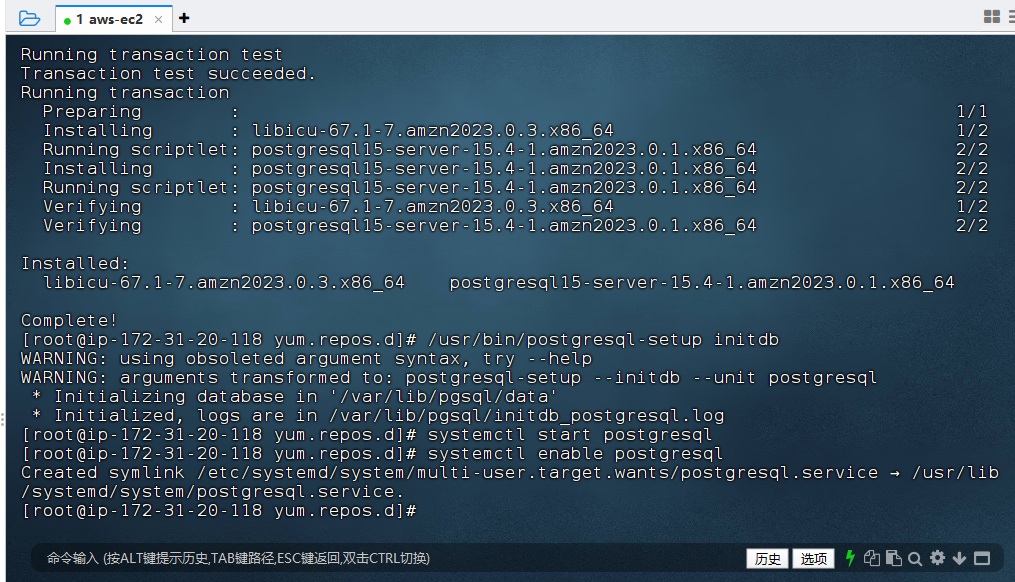
『亚马逊云科技产品测评』活动征文|基于亚马逊云EC2搭建PG开源数据库
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 亚马逊EC2云服务器(Elastic Compute Cloud)是亚马…...

【开题报告】基于J2EE的高校水电费管理系统的设计与实现
1.选题背景 随着高校规模的扩大和信息化建设的深入,学生宿舍的水电费管理成为一项复杂而重要的任务。传统的水电费管理方式通常依赖于人工操作,存在着管理效率低下、数据处理繁琐、费用统计不准确等问题。因此,设计和实现一款基于J2EE的高校…...

Revisiting Proposal-based Object Detection阅读笔记
Revisiting Proposal-based Object Detection阅读笔记 论文地址:link Abstract For any object detector, the obtained box proposals or queries need to be classified and regressed towards ground truth boxes. 对于任何物体检测器来说,获得的…...

Docker部署NFS服务
创建基础镜像 mkdir /data/nfs -p chmod 755 /data/nfs# NFS默认端口: 111、2049、20048 docker run -d \ --privileged \ --name nfs_server \ -p 111:111/tcp \ -p 111:111/udp \ -p 2049:2049/tcp \ -p 2049:2049/udp \ -p 30001-30005:30001-30005/tcp \ -p 30001-30005:3…...

深度学习TensorFlow2基础知识学习后半部分
介绍几个重要操作: 1.范数 a tf.fill([1,2], value2.) b tf.norm(a)# 二范数#第二种计算方法 # 计算验证 a tf.square(a) log("a的平方:", a) a tf.reduce_sum(a) log("a平方后的和:", a) b tf.sqrt(a) log("a平方和后开根号:"…...
电脑系统重装Win10专业版操作教程
用户想给自己的电脑重新安装上Win10专业版系统,但不知道具体的重装步骤。接下来小编将详细介绍Win10系统重新安装的步骤方法,帮助更多的用户完成Win10专业版的重装,重装后用户即可体验到Win10专业版系统带来的丰富功能。 准备工作 1. 一台正常…...

打包Python项目
打包Python项目 本教程将指导您如何打包一个简单的Python项目。它将 向您展示如何添加必要的文件和结构来创建包,如何 构建包,以及如何将其上传到Python包索引(PyPI)。 尖端 如果您在运行本教程中的命令时遇到问题,请…...

使用Python实现爬虫IP负载均衡和高可用集群
做大型爬虫项目经常遇到请求频率过高的问题,这里需要说的是使用爬虫IP可以提高抓取效率,那么我们通过什么方法才能实现爬虫IP负载均衡和高可用集群,并且能快速的部署并且完成爬虫项目。 通常在Python中实现爬虫ip负载均衡和高可用集群需要一…...
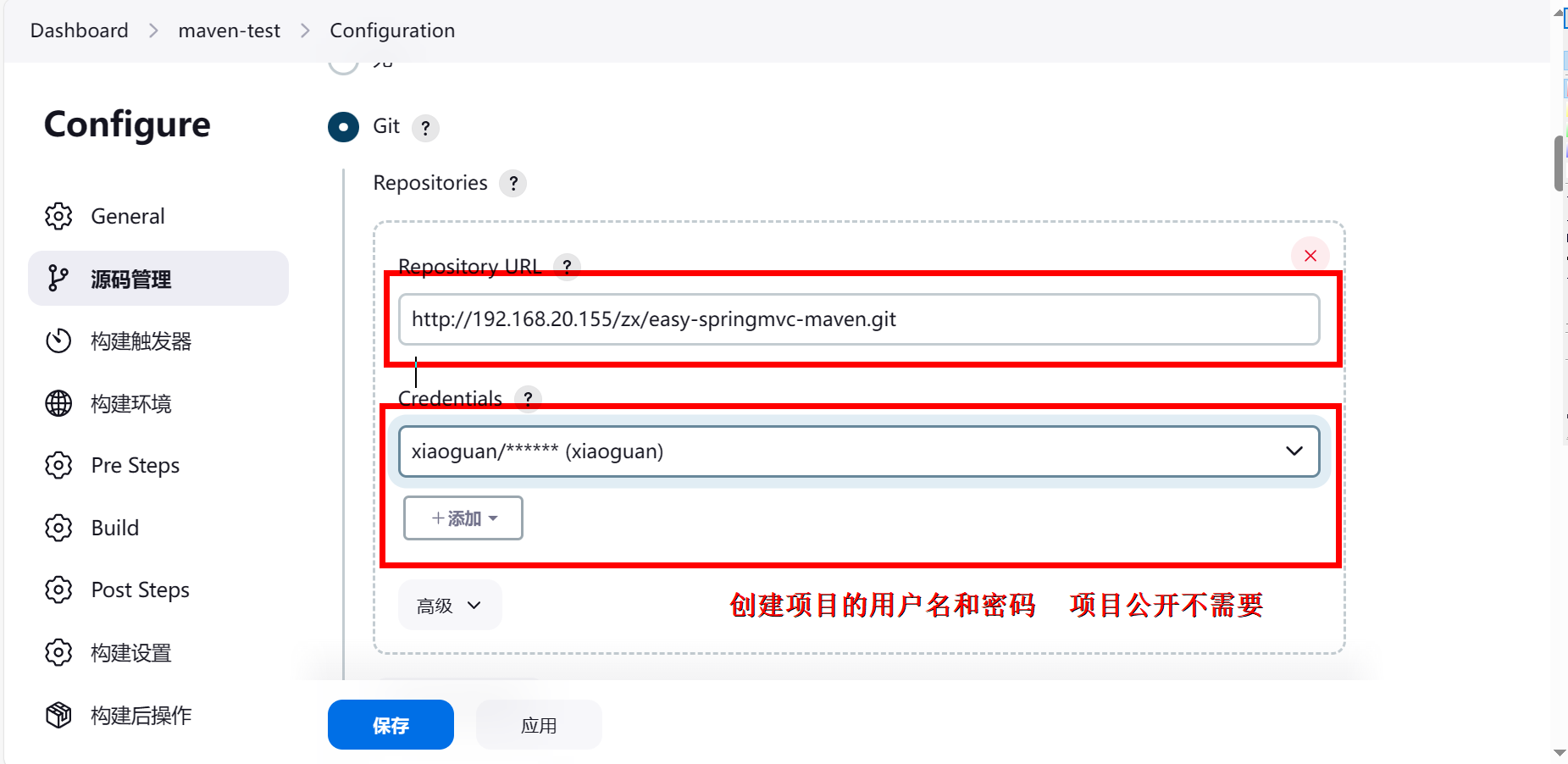
Jenkins+Maven+Gitlab+Tomcat 自动化构建打包,部署
环境准备 1、安装服务 Jenkins工具、环境、插件配置 全局变量配置 Manage Jenkins>tools>JDK 安装 安装插件 Deploy to container 安装此插件,才能将打好的包部署到tomcat上 配置国内mvn源 创建maven项目 1 2 3 4 5 6 7 8 9 10...
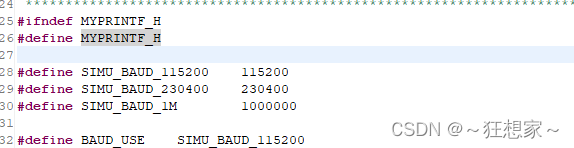
泰凌微(Telink)8258配置串口收发自定义数据
在官网下载SDK后(以Mesh SDK为例)使用Eclipse打开,对应MCU的配置文件在app_config_8258.h,默认的HCI接口是HCI_USE_NONE,如果改成HCI_USE_UART后可以通过串口收发数据,此时默认接收函数处理的是以Telink的协…...

入门低代码开发:快速构建应用程序的方法
一、什么是低代码 低代码开发是一种通过可视化建模和拖拽式设计工具来快速构建应用程序的方法。传统软件开发通常需要编写大量的代码,而低代码开发则提供了更高层次的抽象,使开发过程更加简单和高效。通过可视化界面,用户可以通过拖拽组件、配…...

常见客户端消息推送服务【Java后端】
客户端消息推送 1、推送服务 苹果 APNs(Apple Push Notification service) 谷歌 FCM(Firebase Cloud Messaging)GCM(Google Cloud Messaging) 第三方 个推(Getui)UniAppÿ…...

C++11(下)
可变参数模板 C11的新特性可变参数模板能够创建可以接受可变参数的函数模板和类模板. 相比C98/03, 类模版和函数模版中只能含固定数量的模版参数, 可变模版参数无疑是一个巨大的改进, 然而由于可变模版参数比较抽象, 使用起来需要一定的技巧, 所以这块还是比较晦涩的.掌握一些基…...

深度学习与逻辑回归模型的融合--TensorFlow多元分类的高级应用
手写数字识别 文章目录 手写数字识别1、线性回归VS逻辑回归Sigmoid函数 2、逻辑回归的基本模型-神经网络模型3、多元分类基本模型4、TensorFlow实战解决手写数字识别问题准备数据集数据集划分 特征数据归一化归一化方法归一化场景 标签数据独热编码One-Hot编码构建模型损失函数…...

终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校
终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitco…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

Linuxbonding链路稳定性治理方法
Linuxbonding链路稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限…...

JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯
JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否在使用IntelliJ IDEA、PyCharm、WebStorm等JetBrains IDE时遇到过试用期突然结束…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...