[PyTorch][chapter 4][李宏毅深度学习][Gradient Descent]
前言:
目录:
1: 梯度下降原理
2: 常见问题
3: 梯度更新方案
4: 梯度下降限制
一 梯度下降原理
机器学习的目标找到最优的参数,使得Loss 最小


为什么顺着梯度方向loss 就能下降了。主要原理是泰勒公式。
假设损失函数为
忽略二阶导数, 当 时候
因为要考虑二阶导数,所以损失函数一般都选凸函数,二阶为0,一阶导数有驻点的函数.
二 常见问题
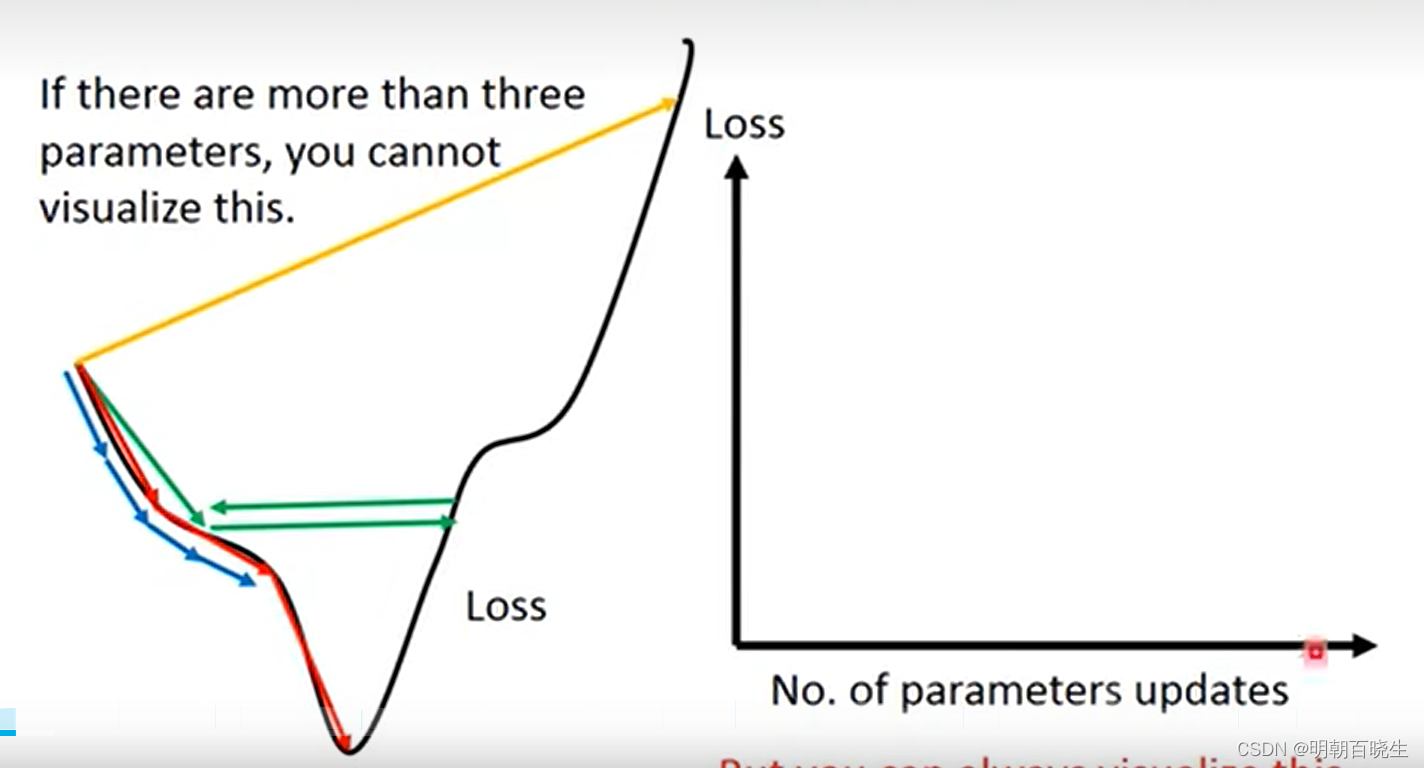
1: 学习率learning rate
红线: 学习率太小,收敛速度非常慢
绿线 : 学习率太大,无法收敛.
有什么自动调整学习率的算法?
三 梯度更新方案
3.1 vanilla gradient descent
学习率除以时间的开方:
训练开始:loss 远离极小值点,所以使用大的学习率
几次迭代后,我们接近极小值点,所以使用小的学习率
3.2 Adagrad
不同参数不同的学习率,设置不同的学习率,假设w 是权重系数里面的一个参数。
其中
例:

为什么要不同参数设置不同的学习率:
如下图,不同维度的梯度是不一样的,如果使用同一个学习率会使得
某些维度出现学习率过大或者过小问题,导致收敛速度过慢或者网络震荡问题.

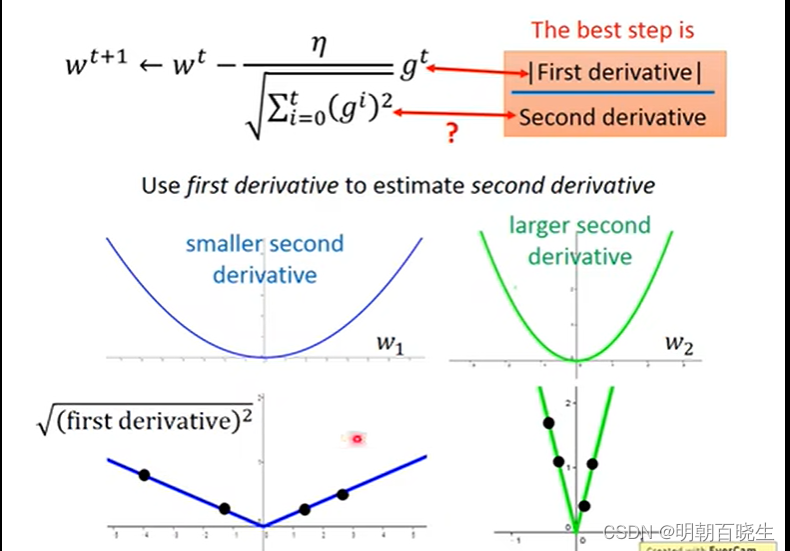
问题2: 为什么要除以
这个参数相当于二次微分。
如下图:
一次微分小的我们希望学习率大一点,能够快速收敛.
一次微分大的我们希望其学习率小一点,防止网络震荡.
我们通过采样历史微分结果相加,学习率除以该参数就达到该效果。
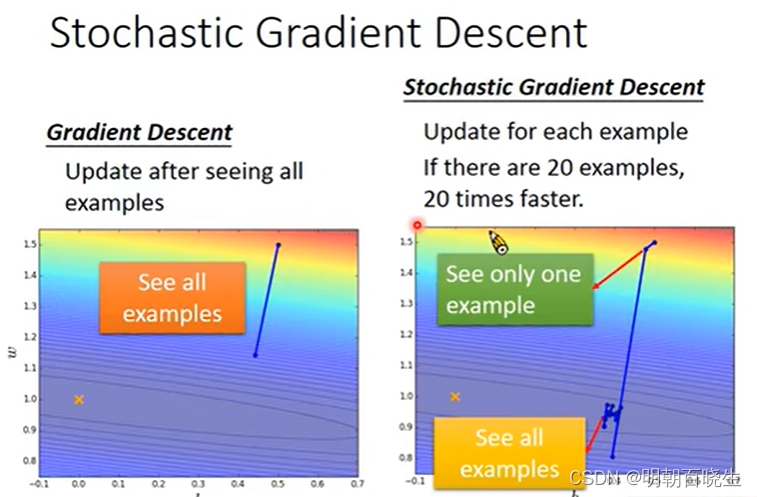
3.3 stochastic gradient descent(随机梯度下降法)
假设我们有20个样本
每轮迭代:
梯度下降法: 计算20个样本,计算20个样本的梯度,通过平均值更新梯度
随机梯度下降法: 随机选取一个样本,计算1个样本梯度,更新梯度
优点: 速度快
3.4 batchnormalization
作用:
使得不同维度上面数据分布一致。
常用方案 batchnormalization:
数据集 假设有m个样本,每个数据的维度为n
对每个维度求其均值,以及方差
,
如下图:
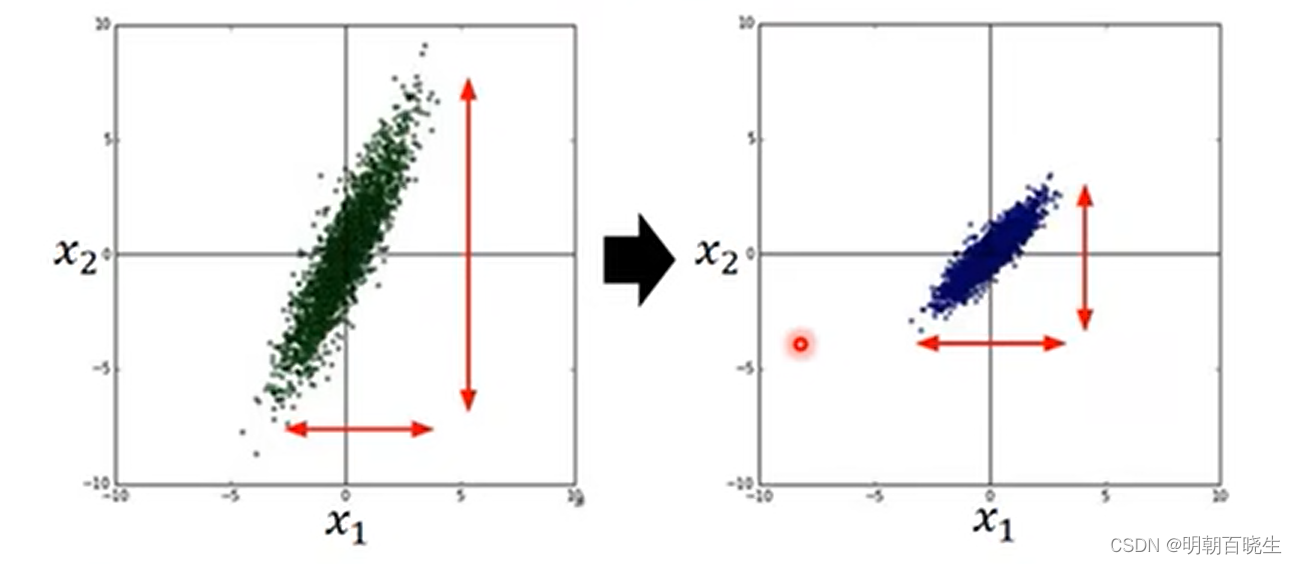
主要作用:
例子:
假设
则
如 相差很大的时候,同样的loss,会导致不同维度
梯度变化相差非常大,当使用随机梯度下降时候,不同的出发点
收敛速度会相差很大。但是使用batchnormalization 方案后,
无论从哪个出发点出发,都不会影响收敛速度.

四 梯度下降限制
4.1 任务说明:
根据前9小时的数据,预测下一个小时的PM2.5值


4.2 数据集
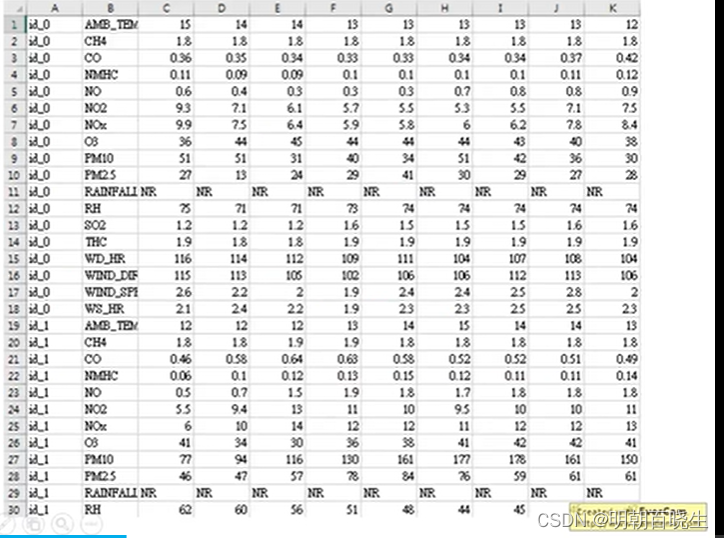
使用丰原站的观测记录,分成 train set 跟 test set,train set 是丰原站每个月的前 20 天所有资料。test set 则是从丰原站剩下的资料中取样出来。
train.csv: 每个月前 20 天的完整资料。
test.csv : 从剩下的资料当中取样出连续的 10 小时为一笔,前九小时的所有观测数据当作 feature,第十小时的 PM2.5 当作 answer。一共取出 240 笔不重複的 test data,请根据 feature 预测这 240 笔的 PM2.5。
Data 含有 18 项观测数据 AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR。

工程两个文件:
dataLoader.py
main.py
import pandas as pd
import numpy as np
import mathdef get_testData(mean_x,std_x):#[4320 个数据,18个fetature 为一组,所有共有240个testData]print("\n mean_x",mean_x)testdata = pd.read_csv('data/test.csv',header=None, encoding = 'big5')test_data = testdata.iloc[:, 2:]test_data = test_data.copy()test_data[test_data == 'NR'] = 0test_data = test_data.to_numpy()#print("\n ---",test_data[0])test_x = np.empty([240, 18*9], dtype = float)for i in range(240):a = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)#print("\n i ",i, a.shape)test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)for i in range(len(test_x)):for j in range(len(test_x[0])):if std_x[j] != 0:test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)print("\n test_x",test_x.shape)return test_xdef load_data():data = pd.read_csv('data/train.csv', encoding='big5')#提取第三列后面的资料data = data.iloc[:,3:]data[data=='NR']=0raw_data = data.to_numpy() #[4320,24]#print(raw_data.shape)#print(data.head(18))return raw_datadef extract_traindata(month_data):'''用前9小时的18个特征预测 预测第10小时的PM2.5----------month_data : TYPEkey: monthitem: day1[24小时],data2[24小时],...data20[24小时]Returns-------x : TYPEDESCRIPTION.y : TYPEDESCRIPTION.'''#每个月480小时(20天),每9小时形成一个data,共有471data,所以训练集有12*471各数据#因为作业要求用前9小时,前9小时有18各featurex = np.empty([12*471,18*9],dtype=float)y = np.empty([12*471,1],dtype=float)for month in range(12):for day in range(20):for hour in range(24):if day ==19 and hour>14: continueelse:#每个小时的18项数据data_start = day*24+hourdata_end = data_start+9x[month*471+data_start,:]=month_data[month][:,data_start:data_end].reshape(1,-1)#前9小时# pm标签值y[month*471+data_start,0]=month_data[month][9,data_end] #第10个小时return x,ydef data_normalize(x):# 4.归一化mean_x = np.mean(x, axis = 0) #求列方向的均值std_x = np.std(x, axis = 0) #1列方向的方差print("\n shape ",x.shape)m,n =x.shapefor i in range(m): #12 * 471for j in range(n): #18 * 9 if std_x[j] != 0:x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]return x,mean_x,std_xdef train_load(x,y):x_train_set = x[: math.floor(len(x) * 0.8), :]y_train_set = y[: math.floor(len(y) * 0.8), :]x_validation = x[math.floor(len(x) * 0.8): , :]y_validation = y[math.floor(len(y) * 0.8): , :]print(x_train_set)(y_train_set)print(x_validation)print(y_validation)print(len(x_train_set))print(len(y_train_set))print(len(x_validation))print(len(y_validation))def extract_features(raw_data):'''Parameters----------raw_data : TYPE行:12个月,每月20天,每天18个特征。 [AMB_TEMP,CH4,CO,NMHC,NO,NO2,NOx,O3,PM10,PM2.5,RAINFALL,RH,SO2,THC,WD_HR,WIND_DIREC,WIND_SPEED,WS_HR]列:24小时 Returns-------month_data : TYPE12个月的词典比如针对AMB_TEMP 特征: 原来分成20行(每行24小时), 现在放在一行: 20(天)*24(小时)'''month_data ={}for month in range(12):#sample = np.empty([18,480]) for day in range(20):sample[:, day * 24 : (day + 1) * 24] = raw_data[18 * (20 * month + day) : 18 * (20 * month + day + 1), :]month_data[month] = samplereturn month_datadef load_trainData():#原始的数据集[ 12个月:每个月20天: 每天24小时,18个特征 ]raw_data = load_data()month_data = extract_features(raw_data)x,y = extract_traindata(month_data)x,mean_x,std_x = data_normalize(x)return x,y,mean_x,std_x# -*- coding: utf-8 -*-
"""
Created on Fri Dec 1 16:36:16 2023@author: chengxf2
"""# -*- coding: utf-8 -*-
"""
Created on Thu Nov 30 17:49:04 2023@author: chengxf2
"""import numpy as np
import csv
from dataLoader import load_trainData
from dataLoader import get_testDatadef predict(test_x):w = np.load('weight.npy')y = np.dot(test_x, w)with open('submit.csv', mode='w', newline='') as submit_file:csv_writer = csv.writer(submit_file)header = ['id', 'value']print(header)csv_writer.writerow(header)for i in range(240):row = ['id_' + str(i), y[i][0]]csv_writer.writerow(row)#print(row)submit_file.close()def train(x,y):#w=[b,w] #y = Xwdim = 1+18 * 9 #加上1个偏置w = np.zeros([dim, 1])x = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float)learning_rate = 1e-4iter_time = 1000adagrad = np.zeros([dim, 1])eps = 1e-6for t in range(iter_time):bias = np.dot(x, w) - yloss = np.sqrt(np.sum(np.power(bias, 2))/471/12)#rmseif(t%100==0):print("\n \n %d"%t,"\t loss: %6.3f"%loss)gradient = 2 * np.dot(x.transpose(), bias) #dim*1adagrad += gradient ** 2w = w - learning_rate * gradient / np.sqrt(adagrad + eps)np.save('weight.npy', w)if __name__ == "__main__":x,y,mean_x,std_x = load_trainData()train(x,y)test_x =get_testData(mean_x,std_x)predict(test_x)
参考:
Hung-yi Lee
https://blog.csdn.net/Sinlair/article/details/127100363
相关文章:
[PyTorch][chapter 4][李宏毅深度学习][Gradient Descent]
前言: 目录: 1: 梯度下降原理 2: 常见问题 3: 梯度更新方案 4: 梯度下降限制 一 梯度下降原理 机器学习的目标找到最优的参数,使得Loss 最小 为什么顺着梯度方向loss 就能下降了。主要原理是泰勒公式。 假设损失函数为 忽略二阶导数, 当 …...
利用proteus实现串口助手和arduino Mega 2560的串口通信
本例用到的proteus版本为8.13,ardunio IDE版本为2.2.1,虚拟串口vspd版本为7.2,串口助手SSCOM V5.13.1。软件的下载安装有很多教程,大家可以自行搜索,本文只介绍如何利用这4种软件在proteus中实现arduino Mega 2560的串…...

Web APIs—介绍、获取DOM对象、操作元素内容、综合案例—年会抽奖案例、操作元素属性、间歇函数、综合案例—轮播图定时器版
版本说明 当前版本号[20231204]。 版本修改说明20231204初版 目录 文章目录 版本说明目录复习变量声明 Web APIs - 第1天笔记介绍概念DOM 树DOM 节点document 获取DOM对象案例— 控制台依次输出3个li的DOM对象 操作元素内容综合案例——年会抽奖案例操作元素属性常用属性修改…...

题目:分糖果(蓝桥OJ 2928)
题目描述: 解题思路: 本题采用贪心思想 图解 题解: #include<bits/stdc.h> using namespace std;const int N 1e6 9; char s[N];//写字符串数组的一种方法,像数组一样***int main() {int n, x;cin >> n >> x;for(int …...

Leetcode刷题笔记——摩尔投票法
摩尔投票法的核心思想为对拼消耗。 摩你妈,学不会!!!! 229. 多数元素 II - 力扣(LeetCode)...
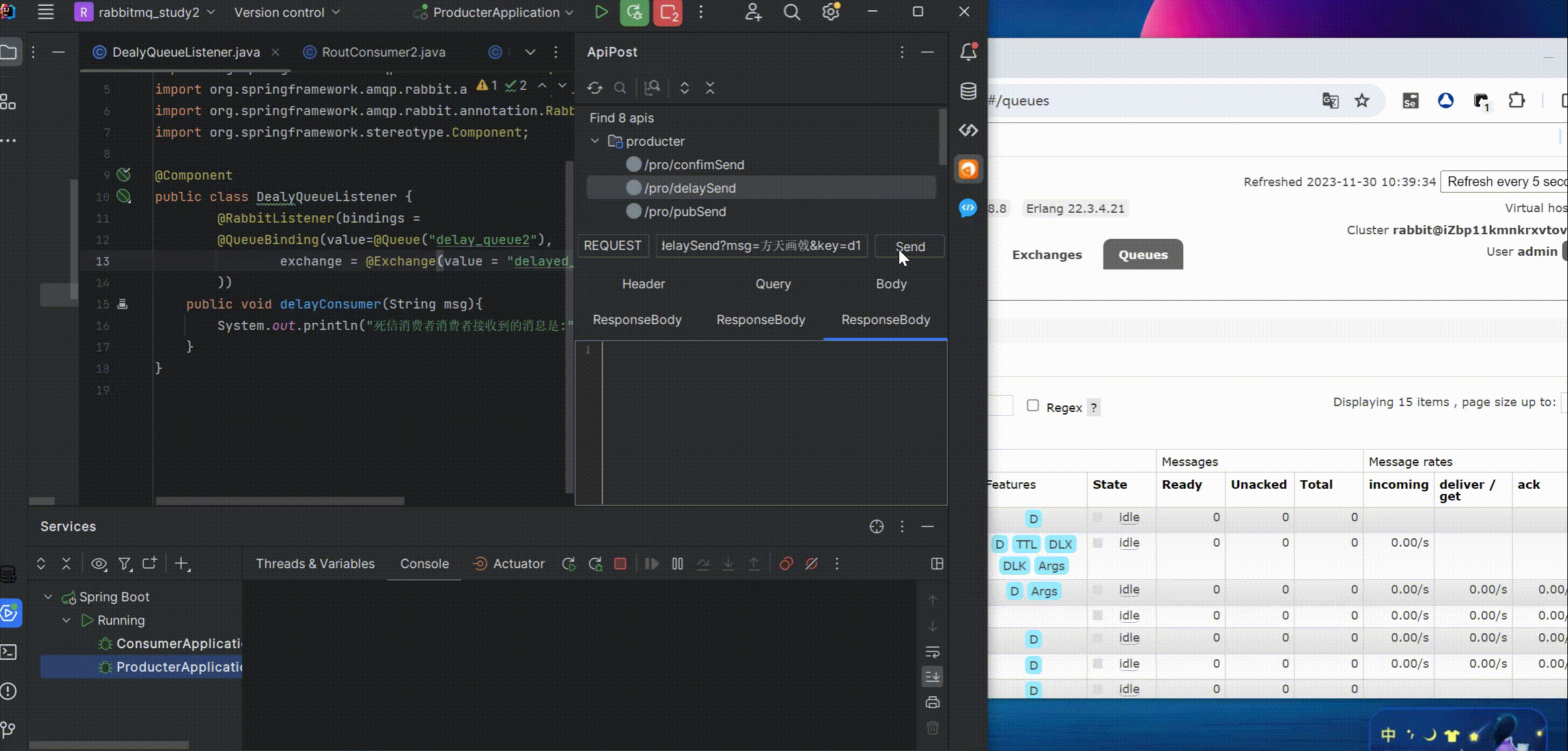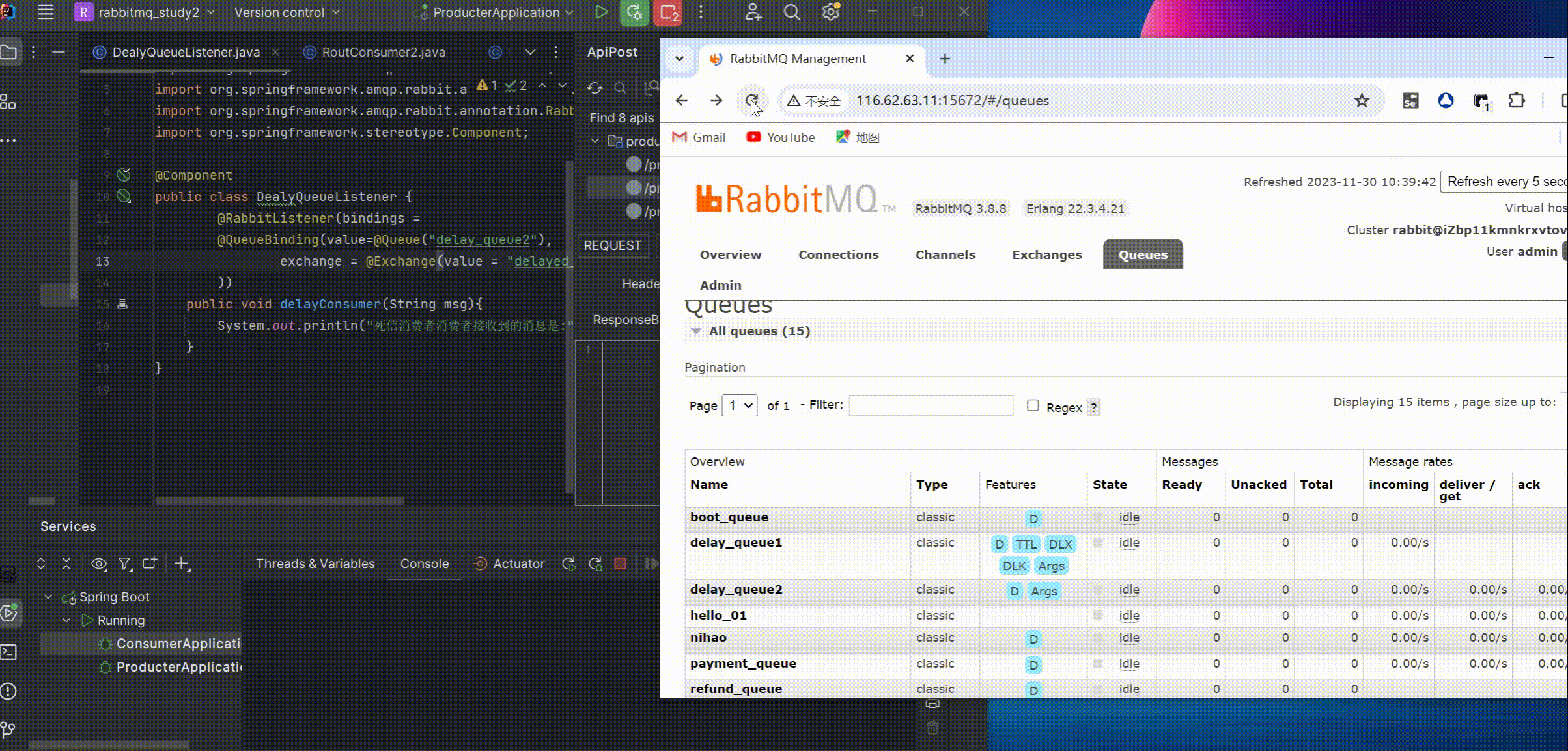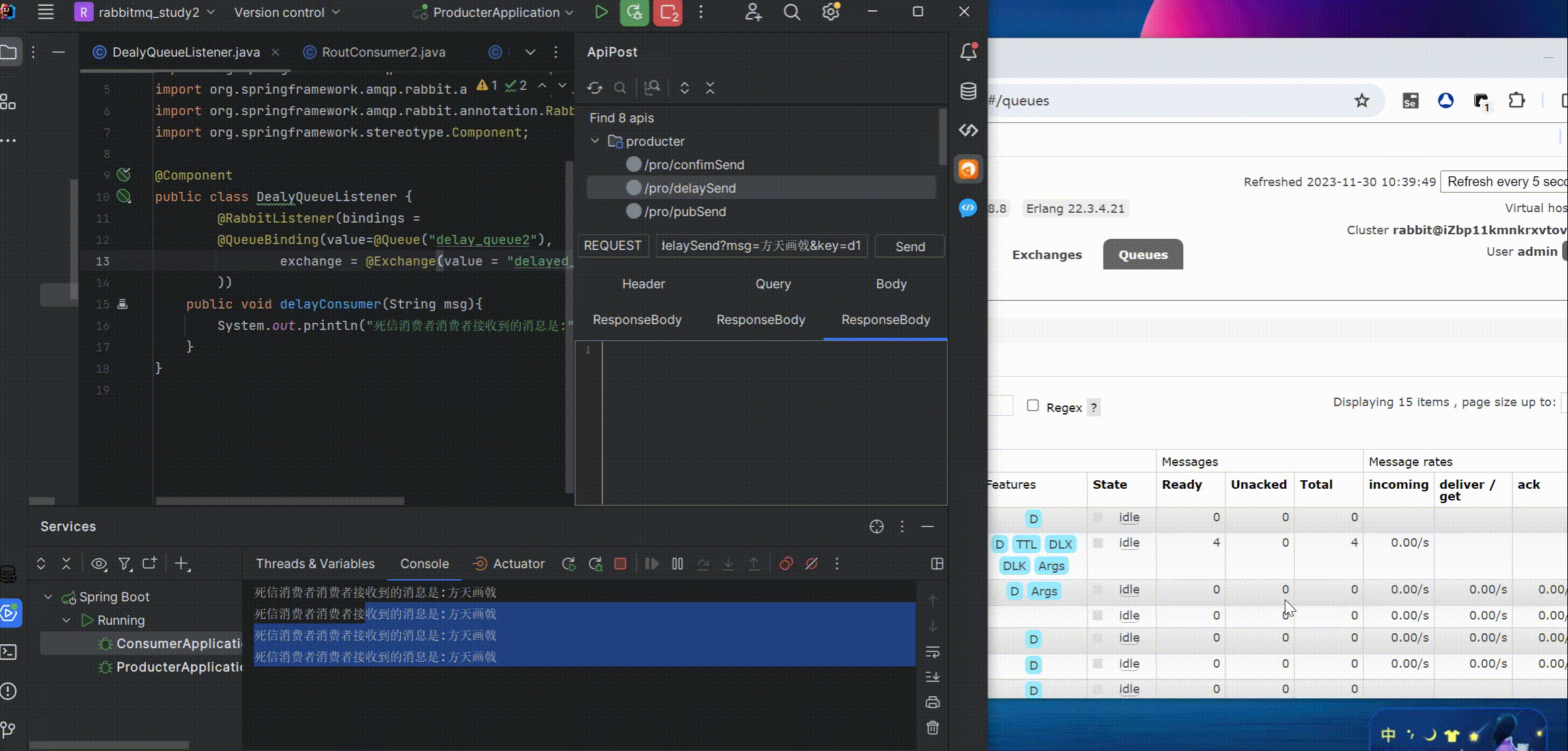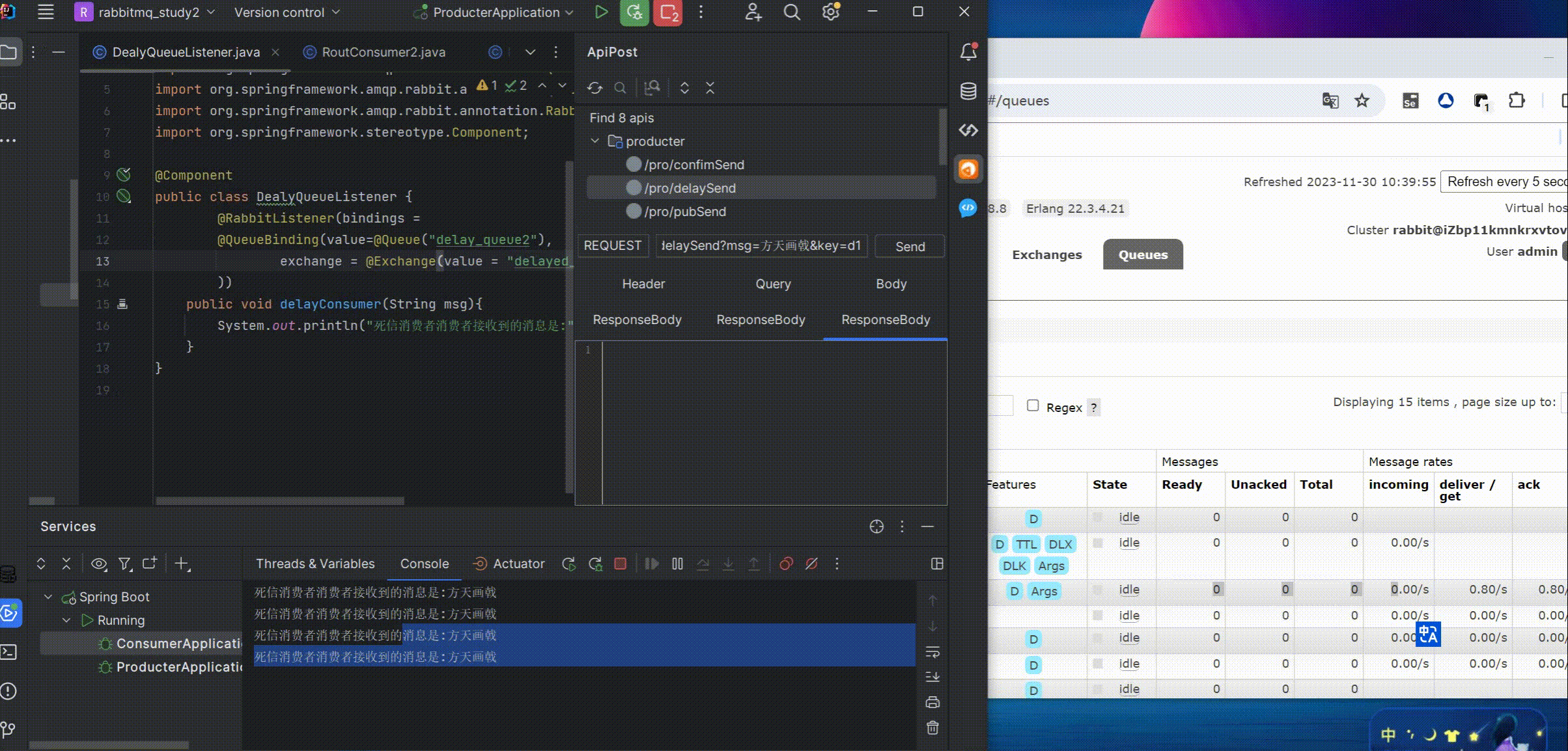
RabbitMq整合Springboot超全实战案例+图文演示+源码自取
目录 介绍 简单整合 简单模式 定义 代码示例 work模式 定义 代码示例 pubsub模式 定义 代码示例 routing模式 定义 代码示例 top模式 定义 代码 下单付款加积分示例 介绍 代码 可靠性投递示例 介绍 代码 交换机投递确认回调 队列投递确认回调 延迟消…...

10-Hadoop组件开发技术
单选题 题目1:下列选项描述错误的是? 选项: A Hadoop HA即集群中包含Secondary NameNode作为备份节点存在。 B ResourceManager负责的是整个Yarn集群资源的监控、分配和管理工作 C NodeManager负责定时的向ResourceManager汇报所在节点的资源使用情况…...
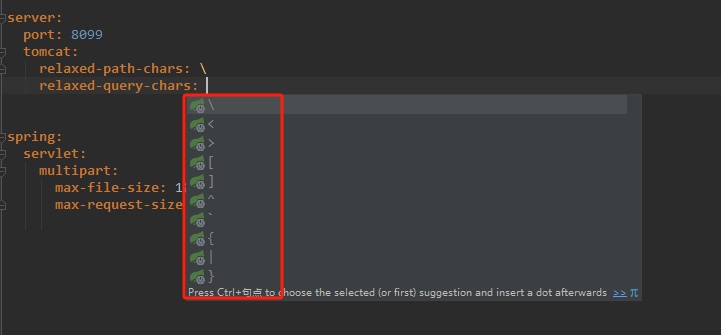
postman参数为D:\\audio\\test.mp3请求报错
报错信息 报错 java.lang.IllegalArgumentException: Invalid character found in the request target [/v1/audio/transcriptions?audioPathD:\\audio\\test.mp3 ]. The valid characters are defined in RFC 7230 and RFC 3986 解决方式 yml文件上放行指定字符 relaxed-pa…...

进行主从复制时出现的异常FATAL CONFIG FILE ERROR (Redis 6.2.6)Reading the configuration file
错误如下所示: FATAL CONFIG FILE ERROR (Redis 6.2.6) Reading the configuration file, at line 1 >>> include/myredis/redis.conf Bad directive or wrong number of arguments出现错误的原因是.conf文件中命令之间缺少空格,如下所示&…...

611.有效的三角形个数
1.题目解析 给定一个包含非负整数的数组 nums ,返回其中可以组成三角形三条边的三元组个数。 补充: 1.三角形的判断:假设有三条边按大小排序: 2.题目示例 示例 1: 输入: nums [2,2,3,4] 输出: 3 解释:有效的组合是: 2,3,4 (使用…...
超详细,使用JavaScript获取短信验证码
一、引言 短信验证码的重要性已经不言而喻,那么如何使用avaScript获取短信验证码呢?今天小编就整理了超详细的攻略,请各位看好~ 二、准备工作 1.注册短信服务提供商 注册并登录你的短信平台,然后获取AppID和AppKey,注册地址在代码里 2.创建验证码模版 三、实现步骤 …...
)
利用 Python 进行数据分析实验(七)
一、实验目的 使用Python解决问题 二、实验要求 自主编写并运行代码,按照模板要求撰写实验报告 三、实验步骤 操作书上第九章内容请画出如图2.png所示的图形通过编码获得fcity.jpg的手绘图像(如beijing.jpg所示) 四、实验结果 T2 &qu…...

前端小技巧: 写一个异步程序示例, 使用任务队列替代promise和async/await等语法糖
异步程序设定场景 1 )场景设定 可以使用懒人每做几件事,就要休息一会儿,并且不会影响做事的顺序这种场景来模拟定义单例名称为: lazyMan支持 sleep 和 eat 两个方法支持链式调用 2 ) 调用示例 const lm new LazyMan(www) lm.eat(苹果).…...

【Windows下】Eclipse 尝试 Mapreduce 编程
文章目录 配置环境环境准备连接 Hadoop查看 hadoop 文件 导入 Hadoop 包创建 MapReduce 项目测试 Mapreduce 编程代码注意事项常见报错 配置环境 环境准备 本次实验使用的 Hadoop 为 2.7.7 版本,实验可能会用到的文件 百度网盘链接:https://pan.baidu…...

Python---time库
目录 时间获取 时间格式化 程序计时 time库包含三类函数: 时间获取:time() ctime() gmtime() 时间格式化:strtime() strptime() 程序计时:sleep() perf_counter() 下面逐一介绍&#…...
unity 自由框选截图(两种方法,亲测有效)
提示:文章有错误的地方,还望诸位大神不吝指教! 文章目录 前言一、第一种方法(1)简介GL(2) GL 用法:(3)具体代码 二、第二种方法第一步:第二步第三…...

项目代码规范
editorconfig EditorConfig 是一种用于统一不同编辑器和 IDE 的代码风格的文件格式和插件,帮助开发人员在不同的编辑器和 IDE 中保持一致的代码风格,从而提高代码的可读性和可维护性 # EditorConfig is awesome: https://EditorConfig.org root true[…...
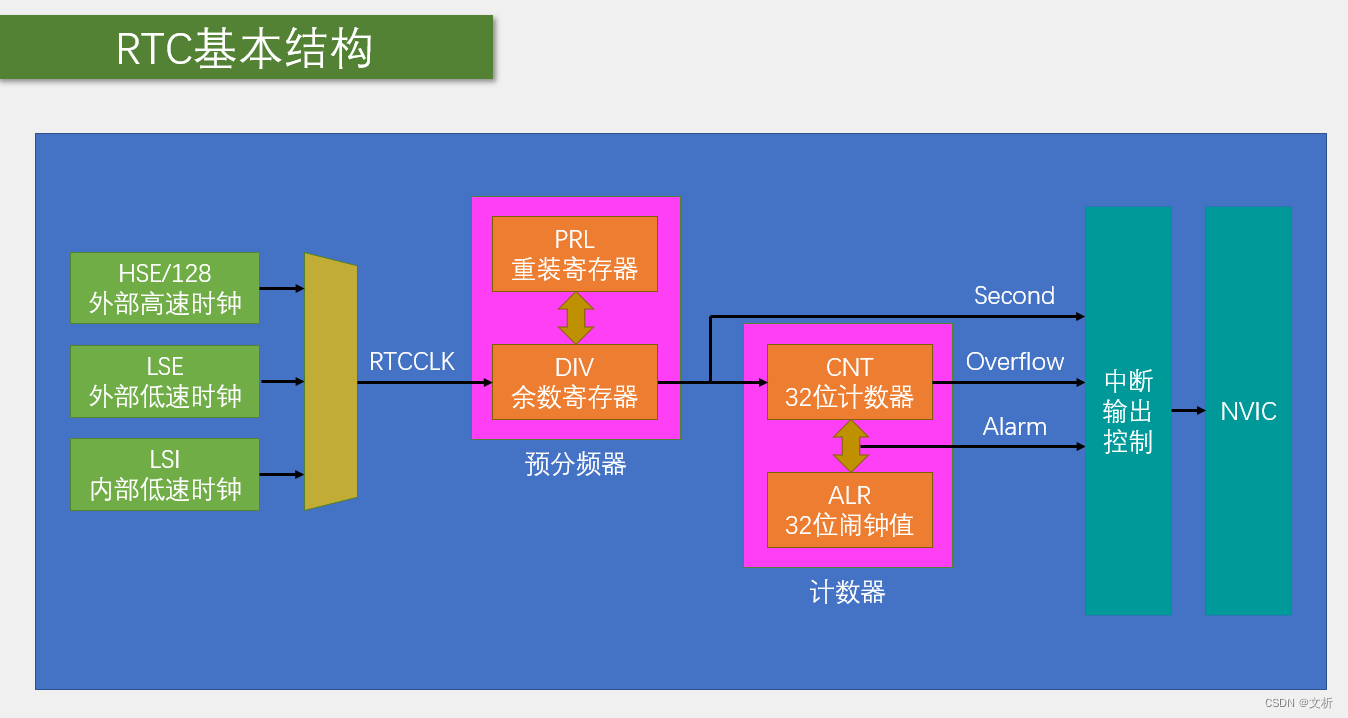
STM32的BKP与RTC简介
芯片的供电引脚 引脚表橙色的是芯片的供电引脚,其中VSS/VDD是芯片内部数字部分的供电,VSSA/VDDA是芯片内部模拟部分的供电,这4组以VDD开头的供电都是系统的主电源,正常使用时,全部都要接3.3V的电源上,VBAT是…...
11.Java安卓程序设计-基于SSM框架的Android平台健康管理系统的设计与实现
摘要 随着人们生活水平的提高和健康意识的增强,健康管理系统在日常生活中扮演着越来越重要的角色。本研究旨在设计并实现一款基于SSM框架的Android平台健康管理系统,为用户提供全面的健康监测和管理服务。 在需求分析阶段,我们明确了系统的…...
jetbrains卡顿(Pycharm等全家桶)终极解决方案,肯定解决!非常肯定!
话越短,越有用,一共四种方案,肯定能解决!!!非常肯定!! 下面四种解决方案,笔者按照实际体验后的结果,按照优先级从高到低排序。你只要按顺序试试就知道了。 m…...

NGA论坛终极美化指南:如何用开源脚本打造清爽浏览体验
NGA论坛终极美化指南:如何用开源脚本打造清爽浏览体验 【免费下载链接】NGA-BBS-Script NGA论坛增强脚本,给你完全不一样的浏览体验 项目地址: https://gitcode.com/gh_mirrors/ng/NGA-BBS-Script 还在为NGA论坛繁杂的界面而烦恼吗?想…...

3个关键步骤掌握Cellpose:如何实现超越人工的细胞分割精度?
3个关键步骤掌握Cellpose:如何实现超越人工的细胞分割精度? 【免费下载链接】cellpose a generalist algorithm for cellular segmentation with human-in-the-loop capabilities 项目地址: https://gitcode.com/gh_mirrors/ce/cellpose Cellpose…...

WarcraftHelper:魔兽争霸3引擎现代化改造与帧率优化技术方案
WarcraftHelper:魔兽争霸3引擎现代化改造与帧率优化技术方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为一款经典的即时…...

基于Notion构建自动化操作系统:OpenClaw OS核心架构与实战指南
1. 项目概述:一个为Notion深度用户打造的自动化操作系统 如果你和我一样,每天的工作和生活都重度依赖Notion,那你一定有过这样的体验:为了找一个上周随手记下的会议链接,在几十个页面里来回翻找;想快速记录…...
)
别再踩坑了!PyTorch3D 0.7.4 保姆级安装指南(附CUDA 11.3/11.7、Python 3.8/3.9版本命令)
别再踩坑了!PyTorch3D 0.7.4 保姆级安装指南(附CUDA 11.3/11.7、Python 3.8/3.9版本命令) 第一次尝试安装PyTorch3D时,我花了整整两天时间在各种报错中挣扎。明明按照官方文档操作,却总是卡在依赖冲突上。后来才发现&a…...

D2RML终极指南:如何快速掌握暗黑破坏神2重制版多开技巧
D2RML终极指南:如何快速掌握暗黑破坏神2重制版多开技巧 【免费下载链接】D2RML Diablo 2 Resurrected Multilauncher 项目地址: https://gitcode.com/gh_mirrors/d2/D2RML 暗黑破坏神2重制版多开工具D2RML让你告别繁琐的重复登录,体验革命性的游戏…...

FormCreate Designer:基于Vue框架的多端低代码表单设计解决方案
FormCreate Designer:基于Vue框架的多端低代码表单设计解决方案 【免费下载链接】form-create-designer 好用的Vue低代码可视化 AI 表单设计器,可以通过拖拽的方式快速创建表单,提高开发者对表单的开发效率。支持PC端和移动端,目前…...

ChatGPT账号自动化创建:Selenium实战与反检测策略详解
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现很多有意思的想法都卡在了一个看似简单、实则麻烦的环节上:获取一个可用的ChatGPT账号。无论是想测试最新的API功能,还是想搭建一个内部使用的对话机器人,账号都是绕不过去的门…...

Flux2-Klein-9B-True-V2图生图编辑入门必看:上传图片→智能重绘→风格迁移三步法
Flux2-Klein-9B-True-V2图生图编辑入门必看:上传图片→智能重绘→风格迁移三步法 1. 认识Flux2-Klein-9B-True-V2 Flux2-Klein-9B-True-V2是一款基于官方FLUX.2 [klein] 9B改进的AI图像处理模型,专为创意工作者和设计师打造。它不仅能从文字描述生成图…...
)
VSCode 2026 + Trace32深度协同指南:实现AURIX TC4xx实时变量观测、CoreSight ETM流解析与UDS诊断会话一键触发(仅限首批内测License持有者公开)
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026 车载开发适配教程 VSCode 2026 版本深度集成了 AUTOSAR Adaptive Platform(ARA)开发支持,专为符合 ISO 21434 和 ASPICE L2 标准的车载嵌入式系统设计。…...