GoLong的学习之路,进阶,微服务之原理,RPC
其实我早就很想写这篇文章了,RPC是一切现代计算机应用中非常重要的思想。也是微服务和分布式的总体设计思想。只能说是非常中要,远的不说,就说进的这个是面试必问的。不管用的上不,但是就是非常重要。
文章目录
- RPC的原理
- 本地调用
- RPC调用
- server服务
- 客户端来请求上述HTTP服务
- `RPC原理`
- 如何做到透明化(封装)远程服务调用
- 对消息进行编码和解码
- 序列化
RPC的原理
RPC(Remote Procedure Call Protocol)远程过程调用协议。一个通俗的描述是:客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样。
一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
(这里我做一个解释:是不是有人会将这个与TCP等传输协议放在一起比较,而我想说这么比较是对的。这里献上一篇文章–tcp、http、rpc和grpc总结,但是要注意,这其中的区别)
不过这里我做一个强调,这篇文章必须将这些协议弄清楚了,才能看,他不是雪中送碳,而是锦上添花。
RPC是一种服务器-客户端(Client/Server)模式,经典实现是一个通过发送请求-接受回应进行信息交互的系统。
首先与RPC(远程调用)相对应的是本地调用。
本地调用
先看一个go文件
package mainimport "fmt"func add(x, y int)int{return x + y
}func main(){// 调用本地函数adda := 10b := 20ret := add(a, x)fmt.Println(ret)
}
在程序中本地调用add函数的执行流程,可以理解为以下四个步骤。
- 将变量
a和b的值分别压入堆栈上 - 执行
add函数,从堆栈中获取a和b的值,并将它们分配给x和y - 计算
x + y的值并将其保存到堆栈中 - 退出
add函数并将x + y的值赋给ret
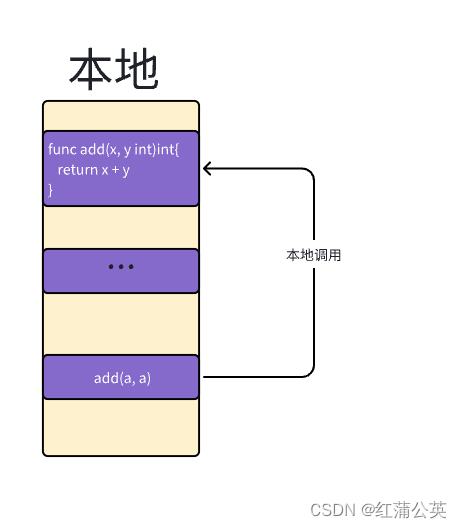
定义add函数的代码和调用add函数的代码共享同一个内存空间,所以调用能够正常执行
但是我们无法直接在另一个程序——中调用add函数,因为它们是两个程序——内存空间是相互隔离的。(两个进程不共享内存)
(两个程序可能在一个主机上,也可能在不同的主机上)
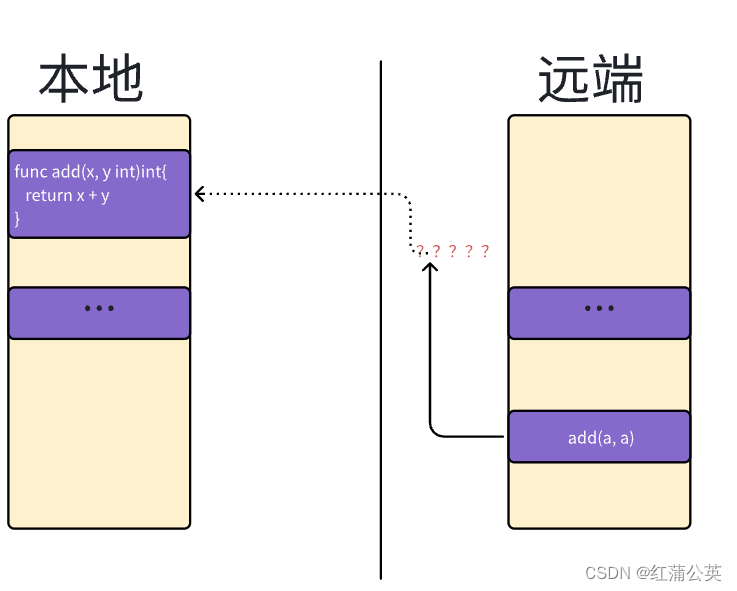
所以RPC就诞生了
RPC就是为了解决类似远程、跨内存空间、的函数或者方法调用的
RPC调用
为什么要用RPC ?
如果我们开发简单的单一应用,逻辑简单、用户不多、流量不大,那我们用不着。
当我们的系统访问量增大、业务增多时,我们会发现一台单机运行此系统已经无法承受。此时,我们可以将业务拆分成几个互不关联的应用,分别部署在各自机器上,以划清逻辑并减小压力。
此时,我们也可以不需要RPC,因为应用之间是互不关联的。
当我们的业务越来越多、应用也越来越多时,自然的,我们会发现有些功能已经不能简单划分开来或者划分不出来。
此时,可以将公共业务逻辑抽离出来,将之组成独立的服务Service应用 。而原有的、新增的应用都可以与那些独立的Service应用 交互,以此来完成完整的业务功能。
所以此时,我们急需一种高效的应用程序之间的通讯手段来完成这种需求.
描述的场景也是服务化 、微服务和分布式系统架构的基础场景。
要实现RPC就需要解决以下三个问题:
-
如何确定要执行的函数?
- 在本地调用中,函数主体通过函数指针函数指定,然后调用 add 函数,编译器通过
函数指针函数自动确定add 函数在内存中的位置。 - 在
RPC中,调用不能通过函数指针完成,因为它们的内存地址可能完全不同。因此,调用方和被调用方都需要维护一个{ function <-> ID }映射表,以确保调用正确的函数
- 在本地调用中,函数主体通过函数指针函数指定,然后调用 add 函数,编译器通过
-
如何表达参数?
- 本地过程调用中传递的参数是
通过堆栈内存结构实现的,但RPC不能直接使用内存传递参数,因此参数或返回值需要在传输期间序列化并转换成字节流,反之亦然。
- 本地过程调用中传递的参数是
-
如何进行网络传输?
- 函数的调用方和被调用方通常是通过网络连接的,也就是说,
function ID和序列化字节流需要通过网络传输,因此,只要能够完成传输,调用方和被调用方就不受某个网络协议的限制。. - 例如,一些
RPC框架使用TCP协议,一些使用HTTP
- 函数的调用方和被调用方通常是通过网络连接的,也就是说,
以往实现跨服务调用的时候,我们会采用RESTful API的方式,被调用方会对外提供一个HTTP接口,调用方按要求发起HTTP请求并接收API接口返回的响应数据。
server服务
// server/main.gopackage mainimport ("encoding/json""io/ioutil""log""net/http"
)type addParam struct {X int `json:"x"`Y int `json:"y"`
}type addResult struct {Code int `json:"code"`Data int `json:"data"`
}func add(x, y int) int {return x + y
}func addHandler(w http.ResponseWriter, r *http.Request) {// 解析参数b, _ := ioutil.ReadAll(r.Body)var param addParamjson.Unmarshal(b, ¶m)// 业务逻辑ret := add(param.X, param.Y)// 返回响应respBytes , _ := json.Marshal(addResult{Code: 0, Data: ret})w.Write(respBytes)
}func main() {http.HandleFunc("/add", addHandler)log.Fatal(http.ListenAndServe(":9090", nil))
}
客户端来请求上述HTTP服务
// client/main.gopackage mainimport ("bytes""encoding/json""fmt""io/ioutil""net/http"
)type addParam struct {X int `json:"x"`Y int `json:"y"`
}type addResult struct {Code int `json:"code"`Data int `json:"data"`
}func main() {// 通过HTTP请求调用其他服务器上的add服务url := "http://127.0.0.1:9090/add"param := addParam{X: 10,Y: 20,}paramBytes, _ := json.Marshal(param)resp, _ := http.Post(url, "application/json", bytes.NewReader(paramBytes))defer resp.Body.Close()respBytes, _ := ioutil.ReadAll(resp.Body)var respData addResultjson.Unmarshal(respBytes, &respData)fmt.Println(respData.Data) // 30
}
这中交互模式,应该是非常常见了。
这种模式是我们目前比较常见的跨服务或跨语言之间基于RESTful API的服务调用模式。
既然使用API调用也能实现类似远程调用的目的,为什么还要用RPC呢?
使用 RPC 的目的是让我们调用远程方法像调用本地方法一样无差别
并且基于RESTful API通常是基于HTTP协议,传输数据采用JSON等文本协议,相较于RPC 直接使用TCP协议,传输数据多采用二进制协议来说,RPC通常相比RESTful API性能会更好。(在我的rabbitMQ文章中有体现)
RESTful API多用于前后端之间的数据传输,而目前微服务架构下各个微服务之间多采用RPC调用
使用场景
- 服务化/微服务
- 分布式系统架构
- 服务可重用
- 系统间交互调用
总结一下:
内部子系统较多:- 众多的内部子系统是驱动采用RPC架构的原因之一,订单系统,支付系统,商品系统,用户系统…, 每个可独立单独布署。 RPC主要使用在大型企业内部子系统之间的调用。
- 基于HTTP协议的接口,包括Webservice等主要作为对外接口服务。
接口访问量巨大:- 要求满足支持 “负载均衡”,“熔断降级” 一类面向服务的高级特性
接口非常多:- 服务发现
RPC原理
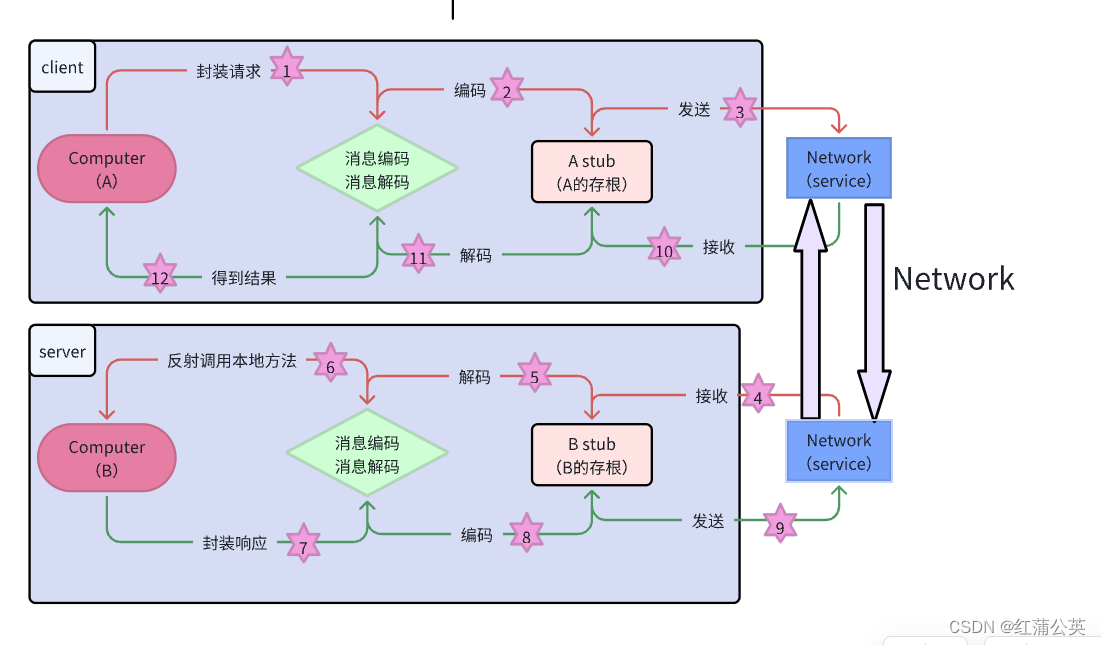
服务调用方(client)以本地调用方式调用服务client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体,client stub找到服务地址,并将消息发送到服务端server端接收到消息server stub收到消息后进行解码server stub根据解码结果调用本地的服务- 本地服务执行并将结果返回给
server stub server stub将返回结果打包成能够进行网络传输的消息体- 按地址将消息发送至调用方
client端接收到消息client stub收到消息并进行解码- 调用方得到最终结果
使用RPC框架的目标是只需要关心第1步和第12步,中间的其他步骤统统封装起来,让使用者无需关心。
例如社区中各式RPC框架(grpc、thrift等)就是为了让RPC调用更方便。
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
如何做到透明化(封装)远程服务调用
怎么封装通信细节才能让用户像以本地调用方式调用远程服务呢?
这部分有点像我用java实现的MQ一样。
就是定义一个结构体。
如果我们需要从A调用B的方法,那么意味着B需要A传来的参数和方法名等,然后通过反射来解析。
所以我们就可以这么做。
能看到这里的人相信对如何设置数据结构已经了熟与心了,所以就不写代码了。(用web实现数据结构的肯定没少做这个事)
如果还是不知道。可以看我的这篇文章,并找到创建请求和响应协议参数这一节,当然看完也可。
对消息进行编码和解码
客户端的请求消息结构一般需要包括以下内容:
接口名称:在我们的例子里接口名是“HelloWorldService”,如果不传,服务端就不知道调用哪个接口了;方法名:一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;参数类型和参数值:参数类型有很多,比如有 bool、int、long、double、string、map、list,甚至如struct等,以及相应的参数值;超时时间 + requestID(标识唯一请求id)
服务端返回的消息结构一般包括以下内容:
状态code返回值requestID
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。
序列化
什么是序列化?
- 序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。
什么是反序列化?
- 将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
为什么需要序列化?
- 转换为二进制串后才好进行网络传输(快)
为什么需要反序列化?
- 将二进制转换为对象才好进行后续处理(方便)
现如今序列化的方案越来越多,每种序列化方案都有优点和缺点,它们在设计之初有自己独特的应用场景,那到底选择哪种呢?
从RPC的角度上看,主要看三点:
通用性:比如是否能支持Map等复杂的数据结构;性能:包括时间复杂度和空间复杂度,由于RPC框架将会被公司几乎所有服务使用,如果序列化上能节约一点时间,对整个公司的收益都将非常可观,同理如果序列化上能节约一点内存,网络带宽也能省下不少可扩展性:对互联网公司而言,业务变化飞快,如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
目前互联网公司广泛使用Protobuf、Thrift、Avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
这里就不介绍了。
如果想要知道如何创建,搭建一个框架的,个人建议可以去这里,极客兔兔的文章。
下一章介绍如何使用go中的RPC的包
相关文章:
GoLong的学习之路,进阶,微服务之原理,RPC
其实我早就很想写这篇文章了,RPC是一切现代计算机应用中非常重要的思想。也是微服务和分布式的总体设计思想。只能说是非常中要,远的不说,就说进的这个是面试必问的。不管用的上不,但是就是非常重要。 文章目录 RPC的原理本地调用…...

vLLM介绍
简介 vLLM 工程github地址 Paged attention论文地址 vLLM开发者介绍 Woosuk Kwon vLLM: A high-throughput and memory-efficient inference and serving engine for LLMs. SkyPilot: A framework for easily and cost effectively running machine learning workloads on …...

DevOps搭建(一)-之swappiness安装详细步骤
1、安装swappiness yum install procps 修改配置 vim /etc/sysctl.conf 在配置文件中添加参数 vm.swappiness10 使生效 sysctl -p 如何确认swap分区是否开启 # free -mtotal used free shared buff/cache available Mem: 971 …...

微软发布Orca2,“调教式”教会小规模大语言模型如何推理!
我们都知道在大多数情况下,语言模型的体量和其推理能力之间存在着正相关的关系:模型越大,其处理复杂任务的能力往往越强。 然而,这并不意味着小型模型就永远无法展现出色的推理性能。最近,奶茶发现了微软的Orca2公开了…...
JVM 内存回收算法
文章目录 JVM 内存回收算法有哪些:一、分代收集1.分代收集理论2.垃圾收集 二、垃圾收集算法1. 标记-清除算法2. 复制算法3. 标记-整理算法 JVM就是Java虚拟机,JVM的内回收对其原理的认识也是很有必要的,当底层的系统出现内存溢出或者内存泄漏…...
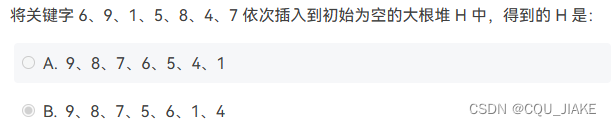
11.28~11.29基本二叉树的性质、定义、复习;排序算法;堆
完全二叉树(Complete Binary Tree)是一种特殊的二叉树结构,它具有以下特点: 所有的叶子节点都集中在树的最后两层;最后一层的叶子节点都靠左排列;除了最后一层,其他层的节点数都达到最大值。 …...

轮播插件Slick.js使用方法详解
相比于Swiper而选择使用Slick.js的原因主要是因为其兼容不错并且在手机端的滑动效果更顺畅 参数: 1.基本使用:一般使用只需前十个属性 $(.box ul).slick({autoplay: true, //是否自动播放pauseOnHover: false, //鼠标悬停暂停自动播放speed: 1500, //…...

postgresql pg_hba.conf 配置详解
配置文件之pg_hba.conf介绍 该文件用于控制访问安全性,管理客户端对于PostgreSQL服务器的访问权限,内容包括:允许哪些用户连接到哪个数据库,允许哪些IP或者哪个网段的IP连接到本服务器,以及指定连接时使用的身份验证模…...
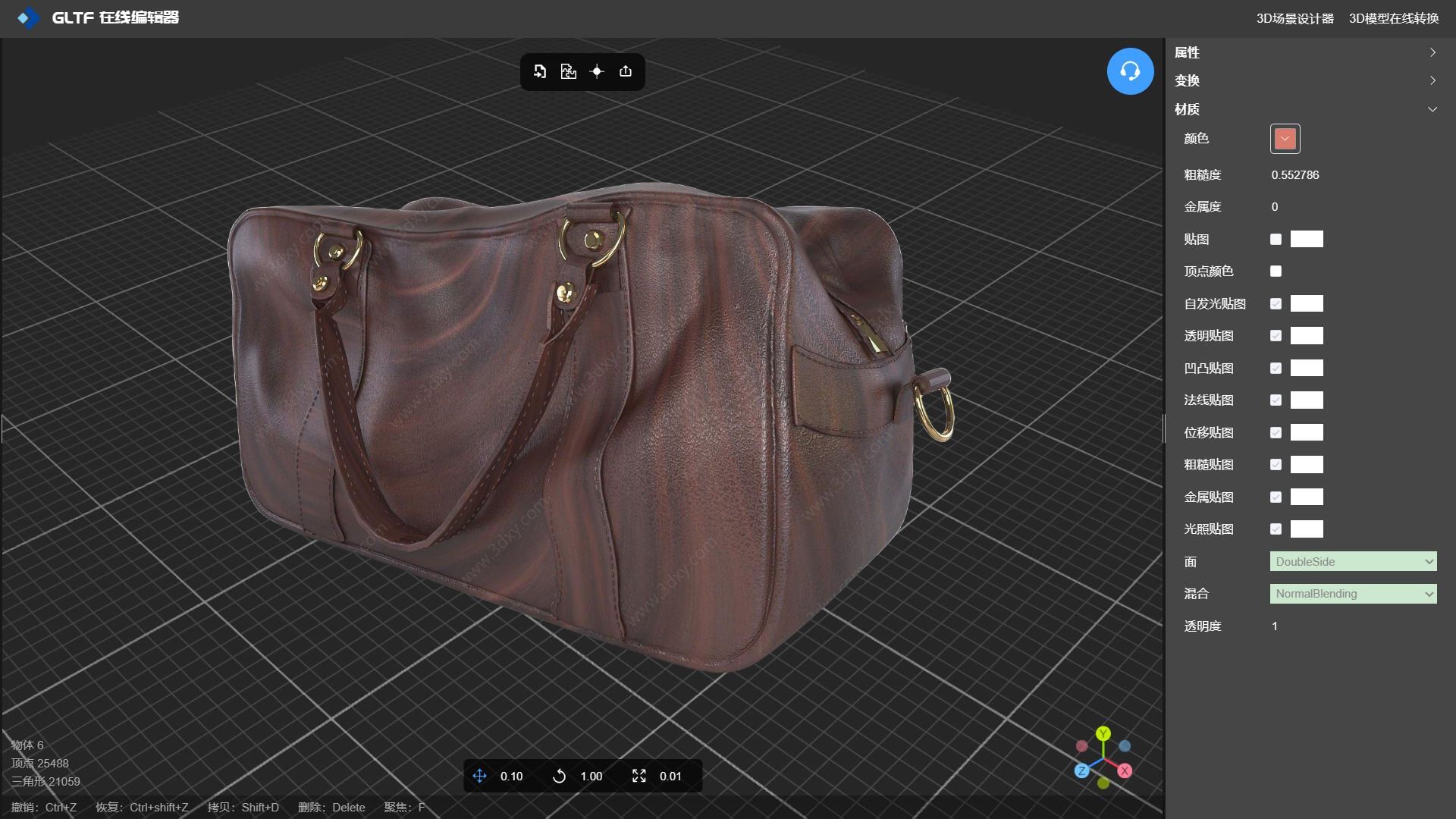
使用粗糙贴图制作粗纹皮革手提包3D模型
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 当谈到游戏角色的3D模型风格时,有几种不同的风格…...
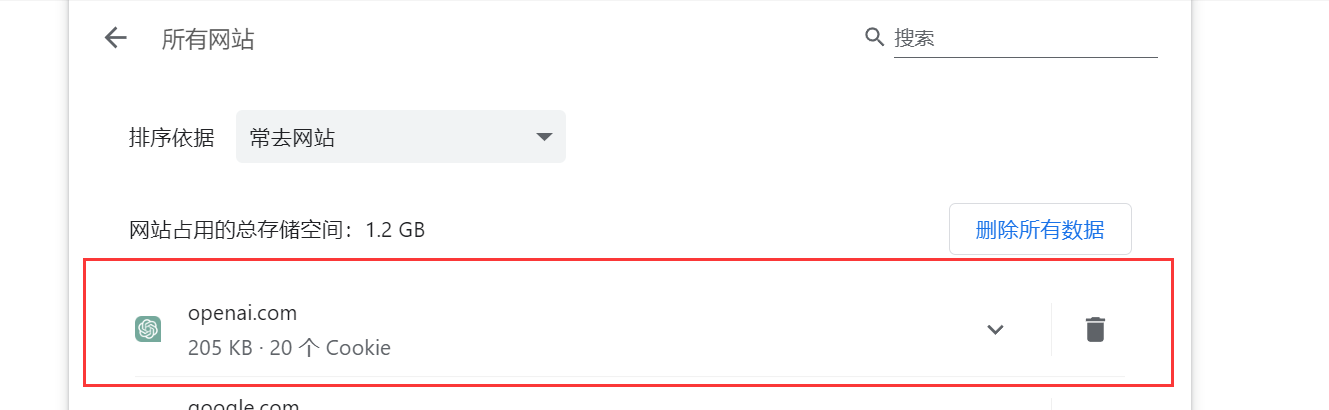
Chrome清除特定网站的Cookie,从而让网址能正常运行(例如GPT)
Chrome在使用某些网址的时候,例如GPT的时候,可能会出现无法访问这个网址的情况,就是点不动啥的 只需要把你需要重置的网址删除就好了...

history路由解决刷新出现404的问题
本文具体重点介绍怎么解决浏览器路由(history模式)解决404的问题。 在项目打包上线时,如果采用的是哈希模式,不会出现404,原因是 url 中 # 号后面的内容不会发给后端当作资源路径请求服务器。 具体流程(哈…...
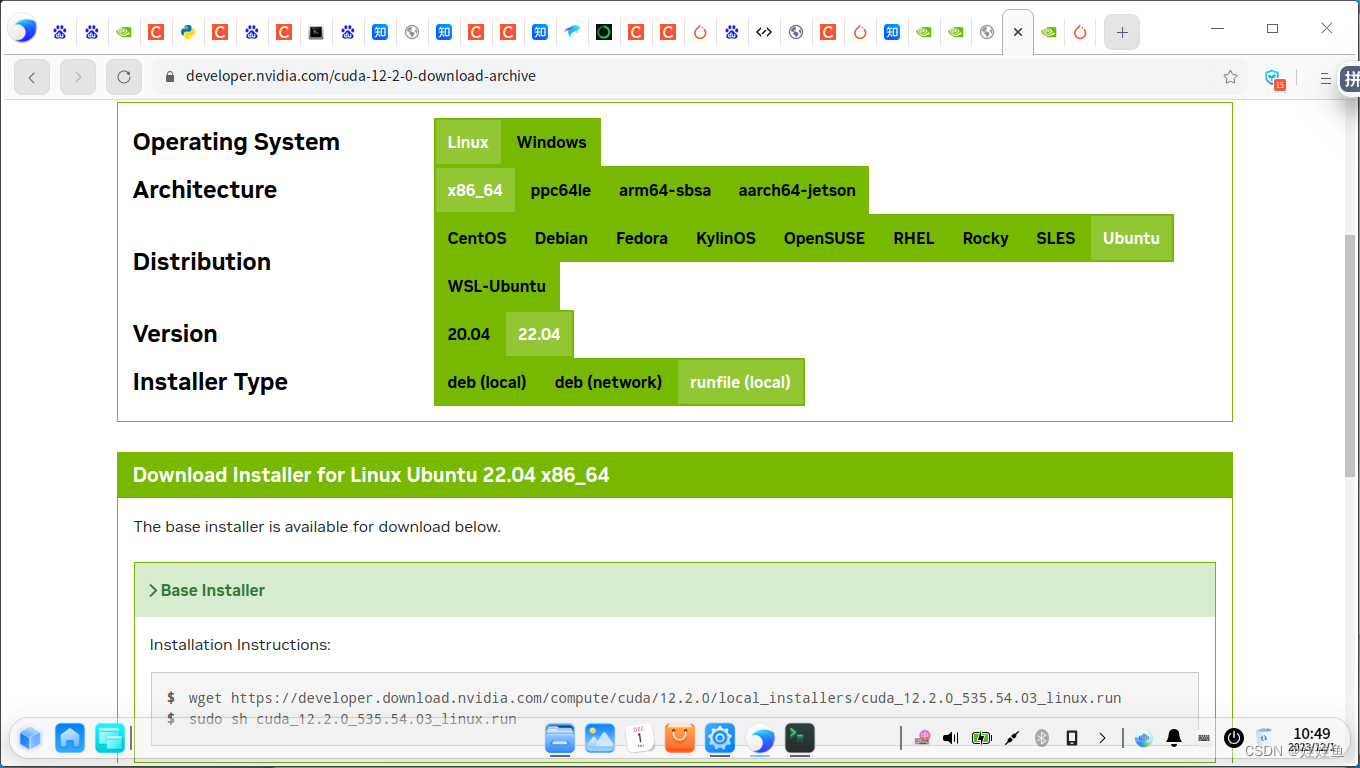
ubuntu22下使用nvidia 2080T显卡部署pytorch
1.直接到NVIDA官网下载相应的驱动,然后安装官方驱动 | NVIDIA 2.下载相应版本cuda,并安装,安装时不安装驱动 3.conda install pytorch2.1.0 torchvision0.16.0 torchaudio2.1.0 pytorch-cuda12.1 -c pytorch -c nvidia 安装pytorch。 安装…...

【Spark基础】-- 理解 Spark shuffle
目录 前言 1、什么是 Spark shuffle? 2、Spark 的三种 shuffle 实现 3、参考 前言 以前,Spark 有3种不同类型的 shuffle 实现。每种实现方式都有他们自己的优缺点。在我们理解 Spark shuffle 之前,需要先熟悉 Spark 的 execution model 和一些基础概念,如:MapReduce、…...
软件测试入门:静态测试
什么是静态测试 顾名思义,这里的静态是指程序的状态,即在不执行代码的情况下检查软件应用程序中的缺陷。进行静态测试是为了仅早在开发的早期阶段发现程序缺陷,因为这样可以更快速地识别缺陷并低成本解决缺陷,它还有助于查找动态测…...

力扣labuladong一刷day30天二叉树
力扣labuladong一刷day30天二叉树 文章目录 力扣labuladong一刷day30天二叉树一、654. 最大二叉树二、105. 从前序与中序遍历序列构造二叉树三、106. 从中序与后序遍历序列构造二叉树四、889. 根据前序和后序遍历构造二叉树 一、654. 最大二叉树 题目链接:https://…...

【云原生-K8s】检查yaml文件安全配置kubesec部署及使用
基础介绍基础描述特点 部署在线下载百度网盘下载安装 使用官网样例yamlHTTP远程调用安全建议 总结 基础介绍 基础描述 Kubesec 是一个开源项目,旨在为 Kubernetes 提供安全特性。它提供了一组工具和插件,用于保护和管理在 Kubernetes 集群中的工作负载和…...

LeetCode力扣每日一题(Java):20、有效的括号
一、题目 二、解题思路 1、我的思路 我看到题目之后,想着这可能是力扣里唯一一道我能秒杀的题目了 于是一波操作猛如虎写出了如下代码 public boolean isValid(String s) {char[] c s.toCharArray();for(int i0;i<c.length;i){switch (c[i]){case (:if(c[i]…...
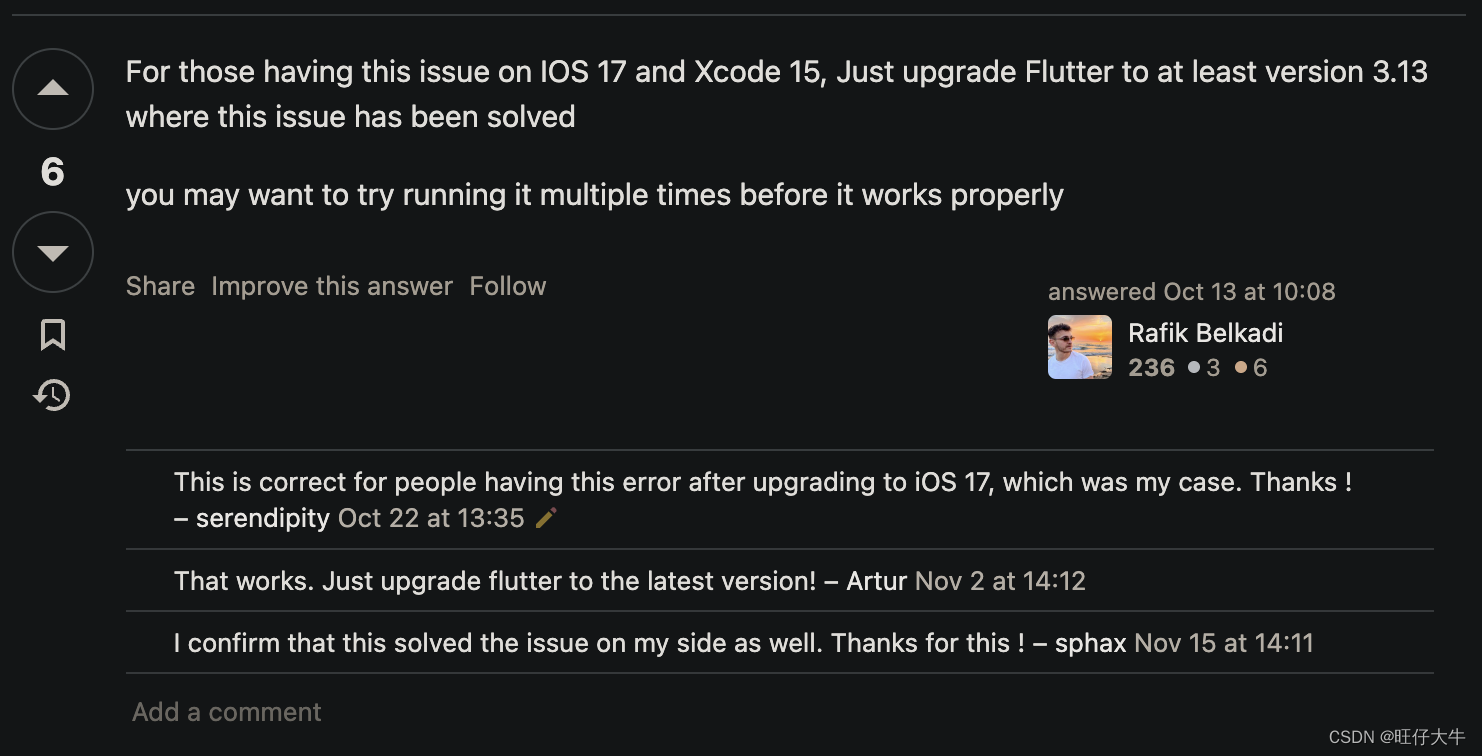
解决Flutter运行报错Could not run build/ios/iphoneos/Runner.app
错误场景 更新了IOS的系统版本为最新的17.0, 运行报以下错误 Launching lib/main.dart on iPhone in debug mode... Automatically signing iOS for device deployment using specified development team in Xcode project: GN3DCAF71C Running Xcode build... Xcode build d…...
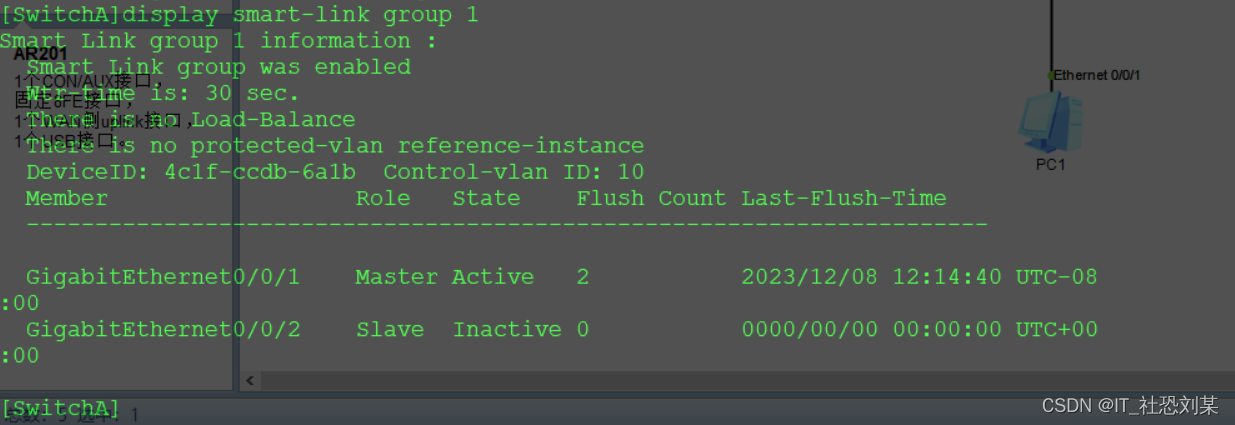
配置Smart Link主备备份示例
目录 实验拓扑 组网需求 配置思路 配置步骤 1.配置VLAN信息 2.在SwitchA上创建Smart Link备份组,并指定端口角色 3.使能回切功能并设置回切时间 4.使能发送Flush报文功能 5.使能接受Flush报文功能 验证配置结果 实验拓扑 组网需求 如上图所示,…...

03-微服务架构构建之微服务拆分
文章目录 前言一、微服务拆分的原则二、微服务拆分的时机三、微服务拆分的方法总结 前言 微服务架构是将一个单体应用程序拆分为一个个独立且保持松耦合的服务的一种架构方式,每个服务有着独立的数据库并且能独立运行部署。微服务架构的构建过程中,第一…...

MySQL-MVCC核心原理-版本链ReadView与可见性判断
MVCC 全称是 Multi-Version Concurrency Control,也就是多版本并发控制。它的核心思想是:为同一行数据维护多个版本,让读写在很多情况下不用互相阻塞。 没有 MVCC 时,读写冲突通常要大量依赖锁。MVCC 让普通 select 可以读一个可见…...

[具身智能-767]:AMCL全局撒粒子重搜与局部小范围匹配,是否算法过程是相似的,不同的是:粒子的数量、覆盖的区域、最终的精度?
AMCL 全局重搜 VS 局部匹配 详细对比核心定论二者底层算法流程、运算逻辑、执行步骤 100% 完全一致,统一遵循:运动预测→观测权重计算→粒子重采样→位姿融合输出这套粒子滤波逻辑,仅在粒子分布范围、粒子总数、收敛活动区间、定位误差精度四…...

本地大模型Web API桥梁:llm-web-api部署与OpenAI兼容实践
1. 项目概述:一个为本地大语言模型提供Web API的轻量级桥梁如果你和我一样,热衷于在本地部署各种开源大语言模型(LLM),比如Llama、Qwen、Mistral,那么你一定遇到过这样的痛点:模型本身跑起来了&…...

AI智能体工具搜索系统:从MCP协议到语义检索的工程实践
1. 项目概述:从“工具搜索”到“智能体工具箱”的进化 最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个核心问题:如何让智能体高效、准确地调用外部工具?无论是让它帮你查天气、发邮件,还…...

基于WebRTC的P2P远程控制工具vibe-remote部署与实战
1. 项目概述:一个远程控制的开源解决方案最近在折腾智能家居和远程设备管理,发现很多场景下,我们需要的并不是一个功能大而全的远程桌面软件,而是一个轻量、快速、能穿透内网的远程控制工具。比如,家里的NAS需要临时重…...

解锁专业阅读体验:Chrome本地Markdown文件智能渲染解决方案
解锁专业阅读体验:Chrome本地Markdown文件智能渲染解决方案 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader 你是否曾经在Chrome…...

别再手动拼接URL了!若依集成JimuReport报表,一个优雅的Token传递方案
若依系统与JimuReport深度集成:Token安全传递的架构实践 在当今企业级应用开发中,报表功能是不可或缺的核心模块,而如何将第三方报表系统无缝集成到现有框架中,同时确保认证体系的安全性与一致性,一直是开发者面临的挑…...

Veil-Evasion项目演进与替代方案:从Veil-Evasion到Veil 3.0的迁移指南
Veil-Evasion项目演进与替代方案:从Veil-Evasion到Veil 3.0的迁移指南 【免费下载链接】Veil-Evasion Veil Evasion is no longer supported, use Veil 3.0! 项目地址: https://gitcode.com/gh_mirrors/ve/Veil-Evasion 🚨 重要通知:V…...

别再只盯着M.2了!手把手教你玩转Mini PCIe接口,给老旧笔记本/工控设备加装4G模块和固态硬盘
别再只盯着M.2了!手把手教你玩转Mini PCIe接口,给老旧笔记本/工控设备加装4G模块和固态硬盘 当大家都在追逐M.2 NVMe固态硬盘的速度时,一个被忽视的接口正在老旧设备里"沉睡"——那就是Mini PCIe。这个藏在笔记本电脑无线网卡下方或…...

3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南
3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 还在为浏览器中那些丑陋的Markdown文件预览而烦恼吗…...