打破常规思维:Scrapy处理豆瓣视频下载的方式

概述
Scrapy是一个强大的Python爬虫框架,它可以帮助我们快速地开发和部署各种类型的爬虫项目。Scrapy提供了许多方便的功能,例如请求调度、数据提取、数据存储、中间件、管道、信号等,让我们可以专注于业务逻辑,而不用担心底层的细节。
但是,Scrapy也有一些局限性,例如它不能直接处理视频下载的任务。如果我们想要用Scrapy来下载豆瓣视频,我们需要自己编写一些额外的代码,来实现视频数据的获取和保存。而且,由于豆瓣视频有一定的反爬措施,我们还需要使用代理服务器来绕过它们,否则我们可能会被封禁IP或者遭到验证码的干扰。
那么,如何用Scrapy来处理豆瓣视频下载的任务呢?本文将为您介绍一种打破常规思维的方式,让您可以用Scrapy来轻松地下载豆瓣视频,并且使用代理服务器和多线程技术来提高采集效率。
细节
1. 创建Scrapy项目和爬虫
首先,我们需要创建一个Scrapy项目和一个爬虫,用于爬取豆瓣视频的网页。我们可以使用Scrapy的命令行工具来完成这个步骤,例如:
# 创建一个名为douban_video的Scrapy项目
scrapy startproject douban_video# 进入项目目录
cd douban_video# 创建一个名为douban的爬虫,用于爬取豆瓣视频的网页
scrapy genspider douban www.douban.com
这样,我们就创建了一个Scrapy项目和一个爬虫,它们的文件结构如下:
douban_video/
├── douban_video/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ ├── __init__.py
│ └── douban.py
└── scrapy.cfg
其中,douban.py是我们的爬虫文件,它的初始代码如下:
# -*- coding: utf-8 -*-
import scrapyclass DoubanSpider(scrapy.Spider):name = 'douban'start_urls = ['https://www.douban.com']def parse(self, response):# 在这里,你可以使用Scrapy的选择器(Selector)来提取视频URL,然后使用Request对象下载视频。pass
2. 设置代理服务器
由于豆瓣视频有一定的反爬措施,我们需要使用代理服务器来绕过它们,否则我们可能会被封禁IP或者遭到验证码的干扰。我们可以使用亿牛云爬虫代理的服务,它提供了稳定的高速代理IP,支持多种协议和认证方式,可以满足我们的需求。
为了使用爬虫代理的服务,我们需要先注册一个账号,然后获取一个域名、端口、用户名和密码,用于连接代理服务器。我们可以在亿牛云爬虫代理的官网www.16yun.cn上找到相关的信息。
假设我们已经获取了以下的信息:
- 域名:
ip.16yun.cn - 端口:
31111 - 用户名:
16YUN123456 - 密码:
123456
那么,我们可以在Scrapy的settings.py文件中,设置以下的配置项,来启用代理服务器:
# 设置代理服务器的域名和端口
HTTP_PROXY = 'ip.16yun.cn'
HTTP_PROXY_PORT = 31111# 设置代理服务器的用户名和密码
HTTP_PROXY_USER = '16YUN123456'
HTTP_PROXY_PASS = '123456'
然后,我们需要在Scrapy的middlewares.py文件中,编写一个自定义的中间件类,用于给每个请求添加代理服务器的信息。我们可以参考以下的代码:
# -*- coding: utf-8 -*-
import base64
from scrapy import signals
from scrapy.exceptions import NotConfiguredclass ProxyMiddleware(object):# 初始化中间件def __init__(self, proxy, port, user, password):# 保存代理服务器的信息self.proxy = proxyself.port = portself.user = userself.password = password# 从配置文件中读取代理服务器的信息@classmethoddef from_crawler(cls, crawler):# 获取代理服务器的域名和端口proxy = crawler.settings.get('HTTP_PROXY')port = crawler.settings.get('HTTP_PROXY_PORT')# 获取代理服务器的用户名和密码user = crawler.settings.get('HTTP_PROXY_USER')password = crawler.settings.get('HTTP_PROXY_PASS')# 如果没有设置代理服务器的信息,抛出异常if not proxy or not port or not user or not password:raise NotConfigured# 创建中间件实例return cls(proxy, port, user, password)# 处理请求def process_request(self, request, spider):# 给请求添加代理服务器的信息request.meta['proxy'] = f'http://{self.proxy}:{self.port}'# 给请求添加代理服务器的认证信息auth = base64.b64encode(f'{self.user}:{self.password}'.encode()).decode()request.headers['Proxy-Authorization'] = f'Basic {auth}'
最后,我们需要在Scrapy的settings.py文件中,启用我们的自定义中间件类,让它在请求发送之前执行。我们可以在DOWNLOADER_MIDDLEWARES配置项中,添加以下的代码:
# 启用自定义的代理中间件
DOWNLOADER_MIDDLEWARES = {'douban_video.middlewares.ProxyMiddleware': 100,
}
这样,我们就完成了代理服务器的设置,我们可以用Scrapy来爬取豆瓣视频的网页了。
3. 提取视频URL
接下来,我们需要在Scrapy的douban.py文件中,编写我们的爬虫逻辑,用于提取视频URL,然后使用Request对象下载视频。
首先,我们需要定义一个起始URL,用于爬取豆瓣视频的网页。我们可以选择任意一个豆瓣视频的分类页面,例如:
# 定义一个起始URL,用于爬取豆瓣视频的网页
start_urls = ['https://www.douban.com/doulist/16002/']
然后,我们需要在parse方法中,使用Scrapy的选择器(Selector)来提取视频URL,然后使用Request对象下载视频。我们可以参考以下的代码:
def parse(self, response):# 在这里,我们使用Scrapy的选择器(Selector)来提取视频URL,然后使用Request对象下载视频。# 例如,假设视频URL在HTML中的类为`video_url`的标签内:video_url = response.xpath('//*[@class="video_url"]/@href')# 创建一个用于下载视频的Request对象video_request = scrapy.Request(url=video_url, callback=self.save_video)# 返回Request对象yield video_request
这样,我们就完成了视频URL的提取,我们可以用Scrapy来下载视频了。
4. 保存视频
最后,我们需要在Scrapy的douban.py文件中,编写一个回调函数,用于保存视频数据到本地。我们可以参考以下的代码:
def save_video(self, response):# 在这里,我们使用response.body来获取视频数据,并将其保存到本地。# 例如,将视频数据保存到名为`video.mp4`的文件中:with open('video.mp4', 'wb') as f:f.write(response.body)
这样,我们就完成了视频的保存,我们可以用Scrapy来下载豆瓣视频了。
5. 使用多线程技术
为了提高采集效率,我们可以使用多线程技术,让Scrapy同时处理多个请求和响应。Scrapy本身就支持多线程技术,我们只需要在Scrapy的settings.py文件中,设置以下的配置项,来调整线程的数量和延迟:
# 设置每个域名的最大并发请求数
CONCURRENT_REQUESTS_PER_DOMAIN = 10
# 设置每个IP的最大并发请求数
CONCURRENT_REQUESTS_PER_IP = 10
# 设置每个请求之间的延迟时间,单位为秒
DOWNLOAD_DELAY = 0.5
这样,我们就启用了多线程技术,我们可以用Scrapy来快速地下载豆瓣视频了。
总结
本文介绍了一种打破常规思维的方式,让您可以用Scrapy来轻松地下载豆瓣视频,并且使用代理服务器和多线程技术来提高采集效率。我们主要完成了以下的步骤:
- 创建Scrapy项目和爬虫
- 设置代理服务器
- 提取视频URL
- 保存视频
- 使用多线程技术
希望本文对您有所帮助,如果您有任何问题或建议,欢迎与我交流。
相关文章:
打破常规思维:Scrapy处理豆瓣视频下载的方式
概述 Scrapy是一个强大的Python爬虫框架,它可以帮助我们快速地开发和部署各种类型的爬虫项目。Scrapy提供了许多方便的功能,例如请求调度、数据提取、数据存储、中间件、管道、信号等,让我们可以专注于业务逻辑,而不用担心底层的…...
系列学习前端之第 2 章:一文精通 HTML
全套学习 HTMLCSSJavaScript 代码和笔记请下载网盘的资料: 链接: https://pan.baidu.com/s/1-vY2anBdrsBSwDZfALZ6FQ 提取码: 6666 HTML 全称:HyperText Markup Language(超文本标记语言) 1、 HTML 标签 1. 标签又称元素&#…...

SCSS Module 这样处理配置和使用太赞了
SCSS Module 只是Scss和Css Module结合,可以利用SCSS对代码静态处理的能力,使得样式处理更强大一些,并不是什么新的东西,对比css-in-js和scoped,个人偏向喜欢Scss Module做样式隔离,先说一下优点࿱…...
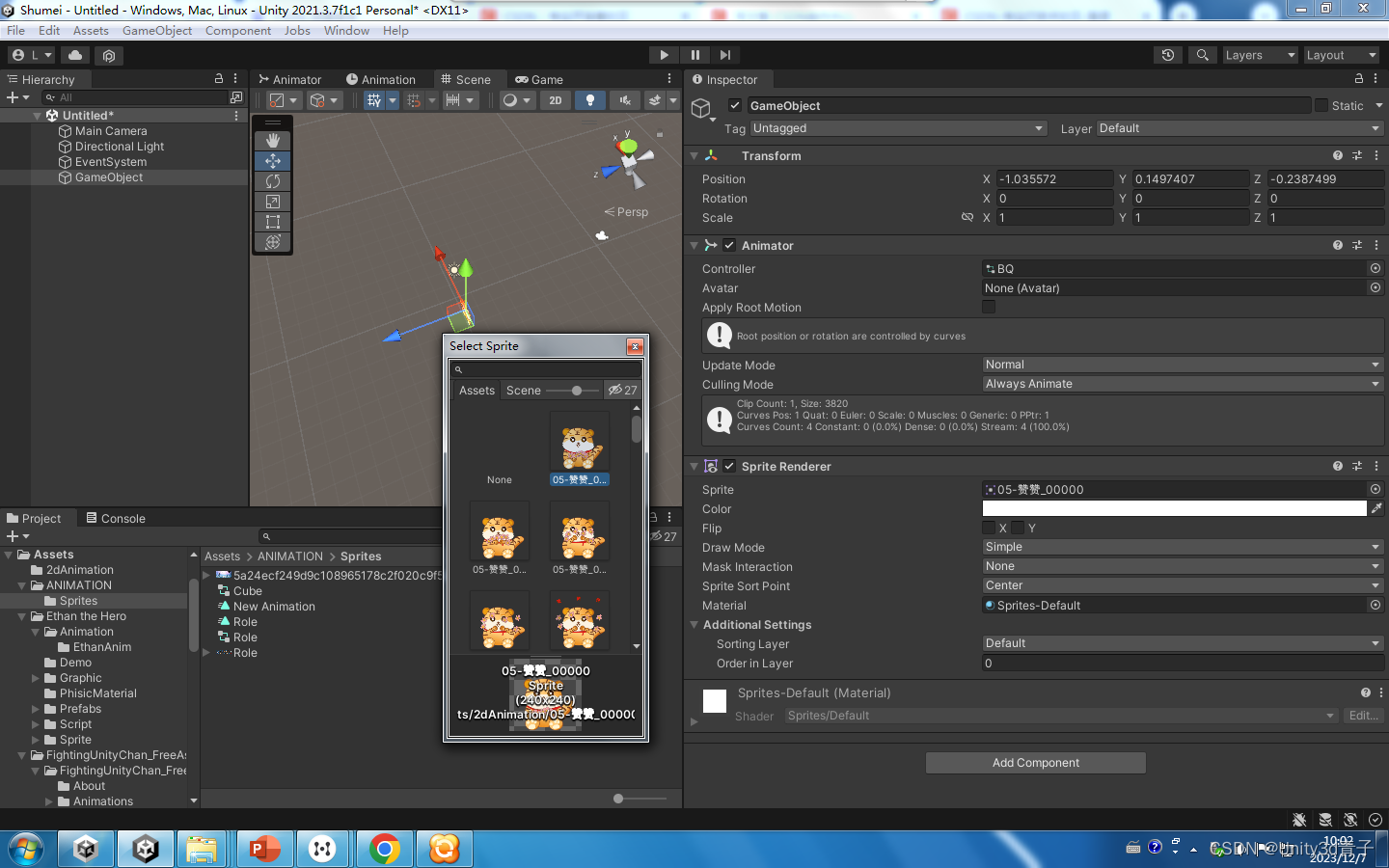
【Unity动画】Unity 2D动画创建流程
本文以2D为案例,讲解Unity 播放动画的流程 准备和导入2D动画资源 外部导入序列帧生成的 Unity内部制作的 外部导入的3D动画 2.创建动画过程 打开时间轴Ctrl6 选中场景中的一个未来需要播放动画的物体 回到时间轴点击Create一个新动画片段 拖动2D动画资源放入…...
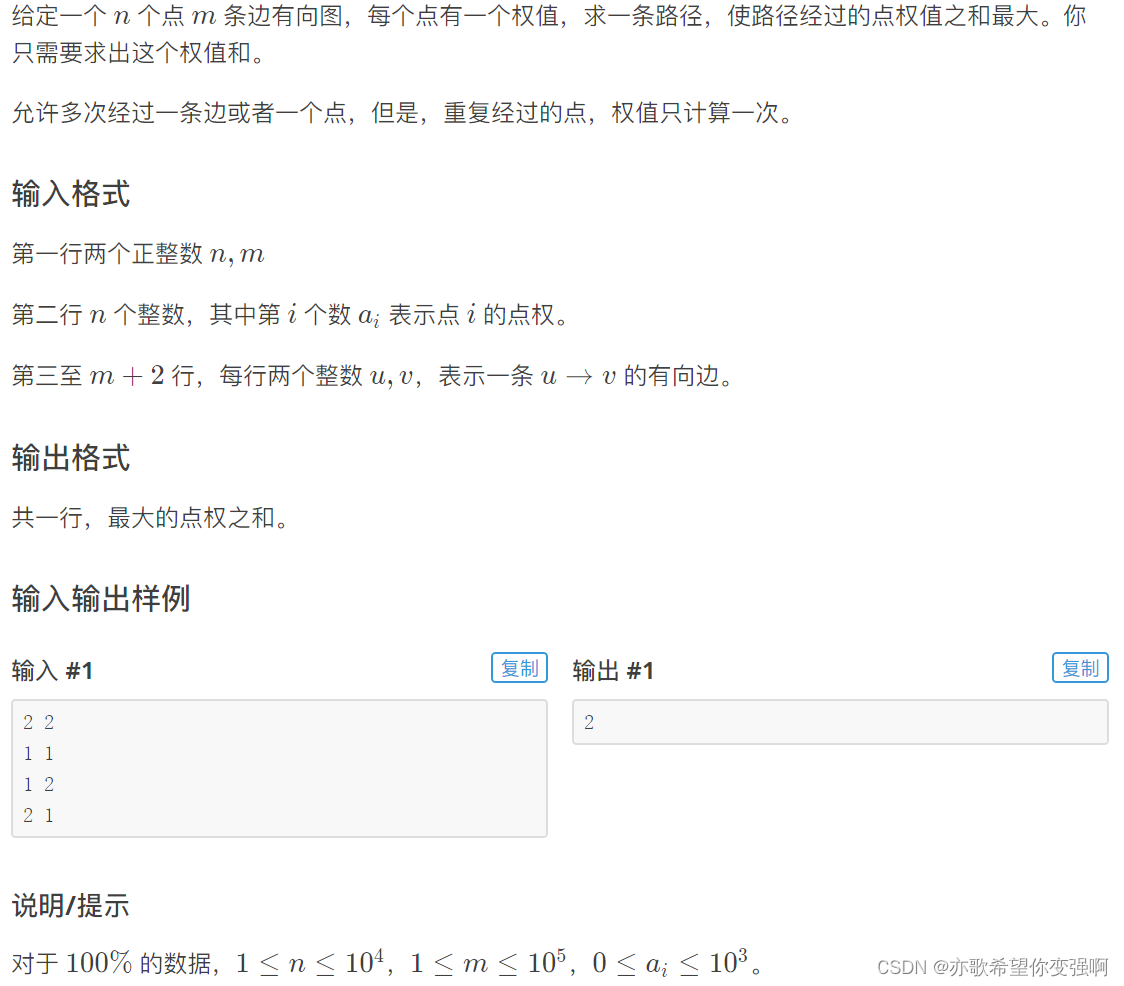
【算法每日一练]-图论(保姆级教程篇12 tarjan篇)#POJ3352道路建设 #POJ2553图的底部 #POJ1236校园网络 #缩点
目录: 今天知识点 加边使得无向图图变成双连通图 找出度为0的强连通分量 加边使得有向图变成强连通图 将有向图转成DAG图进行dp POJ3352:道路建设 思路: POJ2553:图的底部 思路: POJ1236校园网络 思路&#x…...

Python数据科学视频讲解:数据挖掘与建模的注意事项
1.7 数据挖掘与建模的注意事项 视频为《Python数据科学应用从入门到精通》张甜 杨维忠 清华大学出版社一书的随书赠送视频讲解1.7节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。内容涵盖数据科学应用的全流程,包括…...
unity | 动画模块之循环滚动选项框
一、作者的话 评论区有人问,有没有竖排循环轮播选项框,我就写了一个 二、效果动画 如果不是你们想要的,就省的你们继续往下看了 三、制作思路 把移动分成里面的方块,还有背景(父物体),方块自…...

TinyMPC - CMU (卡耐基梅隆大学)开源的机器人 MPC 控制器
系列文章目录 CasADi - 最优控制开源 Python/MATLAB 库 文章目录 系列文章目录前言一、机器人硬件对比1.1 Teensy 上的微控制器基准测试1.2 机器人硬件1.3 BibTeX 二、求解器三、功能(预期)3.1 高效3.2 鲁棒3.3 可嵌入式3.4 最小依赖性3.5 高效热启动3.…...

C++ 对象的初始化和清理:构造函数和析构函数
目录 构造函数和析构函数 构造函数 析构函数 构造函数的分类及调用 括号法 显示法 隐式转换法 拷贝构造函数的调用时机 使用一个已经创建完毕的对象来初始化一个新对象 值传递的方式给函数参数传值 以值方式返回局部对象 构造函数调用规则 初始化列表 类对象作…...

Tmux中使用Docker报错 - 解决方案
问题 进入Tmux会话后,在其中使用Docker可能会出现如下报错: Got permission denied while trying to connect to the Docker ……解决方案 退出tmux会话: tmux detach在tmux会话外部杀掉tmux进程: pkill -f tmux重新进入tmux:…...

如何在WordPress中批量替换图片路径?
很多站长在使用WordPress博客或者搬家时,需要把WordPress文章中的图片路径进行替换来解决图片不显示的问题。总结一下WordPress图片路径批量替换的过程,方便有此类需求的站长们学习。 什么情况下批量替换图片路径 1、更换了网站域名 有许多网站建设初期…...
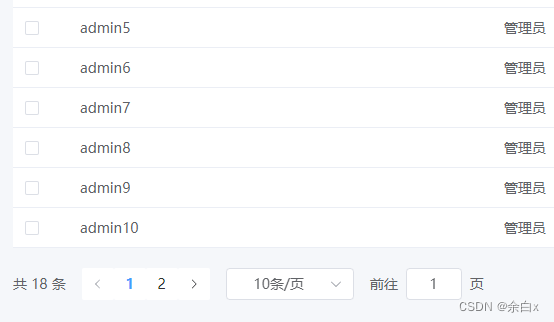
el-pagination 纯前端分页
需求:后端把所有数据都返给前端,前端进行分页渲染。 实现思路:先把数据存储到一个大数组中,然后调用方法进行切割。主要使用数组的slice方法 所有代码: html <template><div style"padding: 20px&qu…...
基于springboot的校园二手市场
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

【开源】基于Vue和SpringBoot的在线课程教学系统
项目编号: S 014 ,文末获取源码。 \color{red}{项目编号:S014,文末获取源码。} 项目编号:S014,文末获取源码。 目录 一、摘要1.1 系统介绍1.2 项目录屏 二、研究内容2.1 课程类型管理模块2.2 课程管理模块2…...
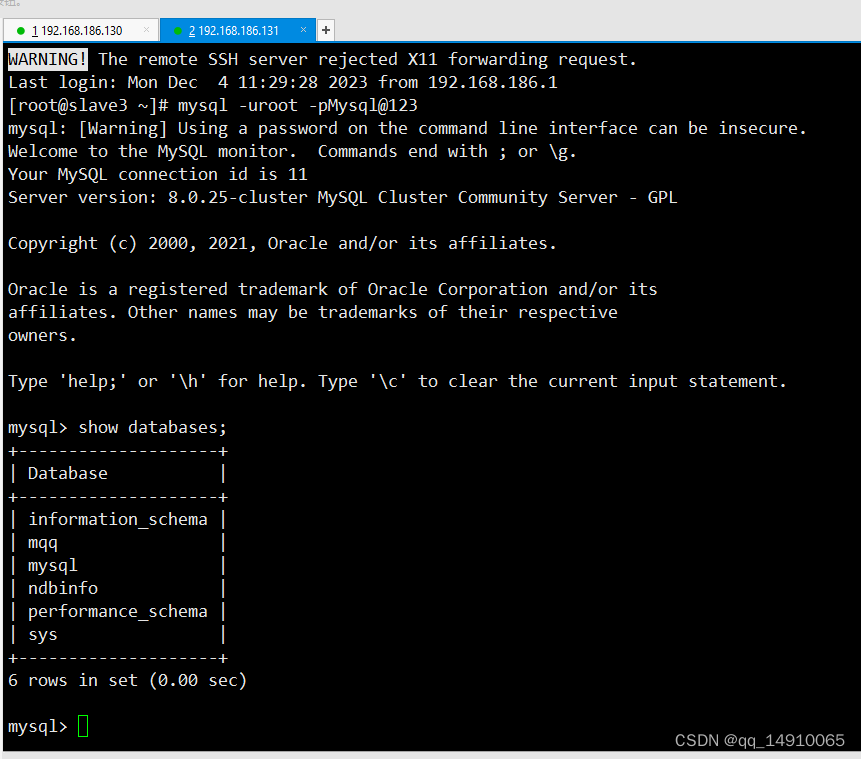
Mysql分布式集群部署---MySQL集群Cluster将数据分成多个片段,每个片段存储在不同的服务器上
1.1 目的 部署MysqlCluster集群环境 1.2 MySQL集群Cluster原理 1 数据分片 MySQL集群Cluster将数据分成多个片段,每个片段存储在不同的服务器上。这样可以将数据负载分散到多个服务器上,提高系统的性能和可扩展性。 2. 数据同步 MySQL集群Cluster使…...

身份认证技术
身份认证是对系统的用户进行有效性、真实性验证。 1.口令认证方式 使用口令认证方式,用户必须具有一个唯一的系统标识,并且保证口令在系统的使用和存储过程中是安全的,同时口令在传输过程中不能被窃取、替换。另外特别要注意的是在…...
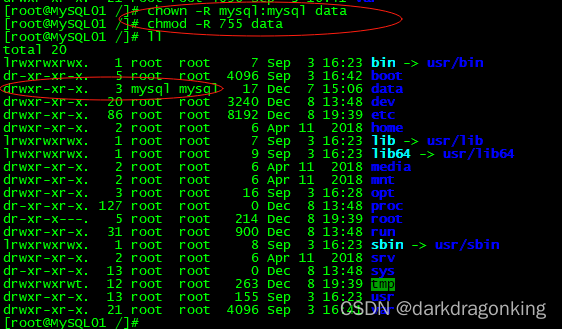
Centos7、Mysql8.0 load_file函数返回为空的终极解决方法--暨selinux的深入理解
零、问题背景 最近想换房,为了方便自己对比感兴趣的房子,因此决定将目标房源的基本信息放在表里,特别是要一目了然的看到众多房子的各种图纸和照片,因此决定要在Mysql8.0.34数据库中以二进制形式保存图片(抛开合理性和…...

基于Spring Boot的水产养殖管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于Spring Boot的水产养殖管理系统,jav…...
LCR 090. 打家劫舍 II(leetcode)动态规划
文章目录 前言一、题目分析二、算法原理1.状态表示2.状态转移方程3.初始化4.填表顺序5.返回值是什么 三、代码实现总结 前言 在本文章中,我们将要详细介绍一下LeetcodeLCR 090. 打家劫舍 II。采用动态规划解决,这是一道经典的多状态dp问题 一、题目分析…...
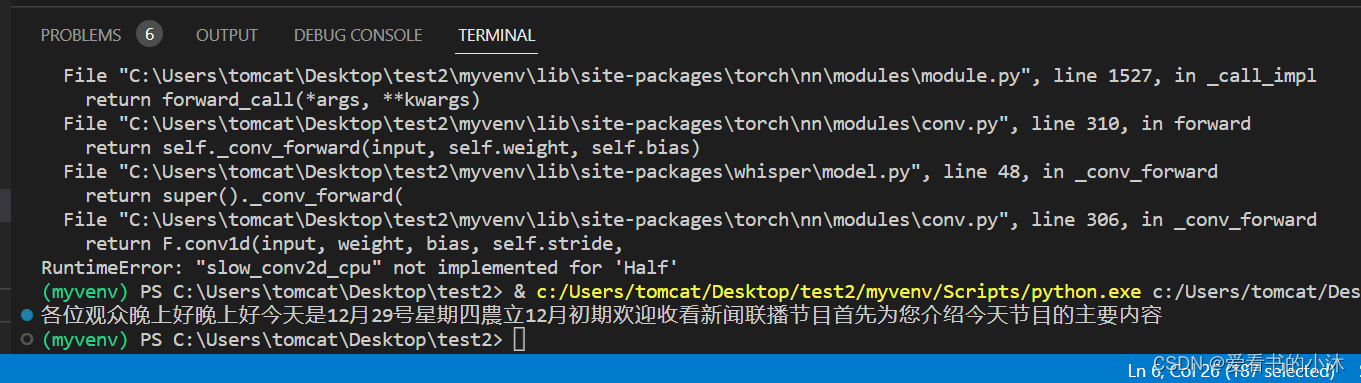
【小沐学Python】Python实现语音识别(Whisper)
文章目录 1、简介1.1 whisper简介1.2 whisper模型 2、安装2.1 whisper2.2 pytorch2.3 ffmpeg 3、测试3.1 命令测试3.2 代码测试:识别声音文件3.3 代码测试:实时录音识别 结语 1、简介 https://github.com/openai/whisper 1.1 whisper简介 Whisper 是…...

Obsidian Calendar Plugin:时间维度驱动的笔记工作流架构革新
Obsidian Calendar Plugin:时间维度驱动的笔记工作流架构革新 【免费下载链接】obsidian-calendar-plugin Simple calendar widget for Obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-calendar-plugin Obsidian Calendar Plugin 作为 Obs…...

Atlas-Learn:从点云构建流形图册的工程实践与黎曼优化应用
1. 项目概述:从点云到流形图册的工程实践在机器学习和数据科学领域,我们常常面对一个核心困境:数据点看似散落在高维的欧几里得空间中,但其内在的、有意义的规律却往往存在于一个低维的非线性结构上。想象一下,你有一堆…...

2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南
2026年怎么安装OpenClaw?阿里云部署及配置Token Plan保姆级指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主…...

AI by Hand Excel:在电子表格中实现损失函数与精度评估的完整指南
AI by Hand Excel:在电子表格中实现损失函数与精度评估的完整指南 【免费下载链接】ai-by-hand-excel 项目地址: https://gitcode.com/gh_mirrors/ai/ai-by-hand-excel 你是否想过,无需编写一行代码就能深入理解人工智能算法的核心原理ÿ…...

QuickLyric终极指南:如何在Android上免费获取自动同步歌词
QuickLyric终极指南:如何在Android上免费获取自动同步歌词 【免费下载链接】QuickLyric Android app that instantly fetches your lyrics for you. 项目地址: https://gitcode.com/gh_mirrors/qu/QuickLyric 你是否厌倦了手动搜索歌词的繁琐?Qui…...
)
别再只认ldd了!盘点5种查看Linux程序动态库依赖的方法(含静态/交叉编译场景)
超越ldd:Linux二进制依赖分析的5种专业方法解析在Linux系统管理和开发中,遇到"不是动态可执行文件"的错误提示时,很多工程师的第一反应是困惑——明明是可执行文件,为什么ldd无法识别?这个问题背后隐藏着Lin…...
模拟卷(一)以及答案)
2026年智传民韵Scratch图形化编程(小学组4-6年级)模拟卷(一)以及答案
2026年智传民韵Scratch图形化编程(小学组4-6年级)模拟卷(一) 考试时间:60分钟 总分:100 及格分:60 一、单选题 (共15题,每题5分) 1、嫦娥奔月”:按照以下程序运行: A:(100, 25) B:(1, 100) C:(120, 50) D:(80, 30) 【正确答案】 A 【试题解析】 2…...

ARM SVE2向量指令UQSHLR与URSHLR详解
1. ARM SVE2向量指令概述在ARMv9架构中,SVE2(Scalable Vector Extension 2)作为第二代可伸缩向量扩展,为高性能计算和机器学习工作负载提供了强大的并行处理能力。与传统的NEON指令集相比,SVE2最大的特点是支持向量长度…...
下载与使用指南)
Cobalt Strike(CS)下载与使用指南
⚠️ 免责声明:本文内容仅用于合法授权的网络安全测试、实验室学习与企业安全防护研究。禁止将相关工具用于任何未授权攻击、非法入侵、数据窃取或破坏行为,否则可能违反当地法律法规。 一、什么是 Cobalt Strike(CS) 1.1 简介 …...

7款完全免费的中文字体解决方案:思源宋体CN实战操作图谱
7款完全免费的中文字体解决方案:思源宋体CN实战操作图谱 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版不够专业而烦恼吗?Source Han Serif CN&…...