初级数据结构(二)——链表
| 文中代码源文件已上传:数据结构源码 <-上一篇 初级数据结构(一)——顺序表 | NULL 下一篇-> |
1、链表特征
与顺序表数据连续存放不同,链表中每个数据是分开存放的,而且存放的位置尤其零散,毫无规则可言。对于零散的数据而言,我们当然可以通过某种方式统一存储每一个数据存放的地址,如下图:
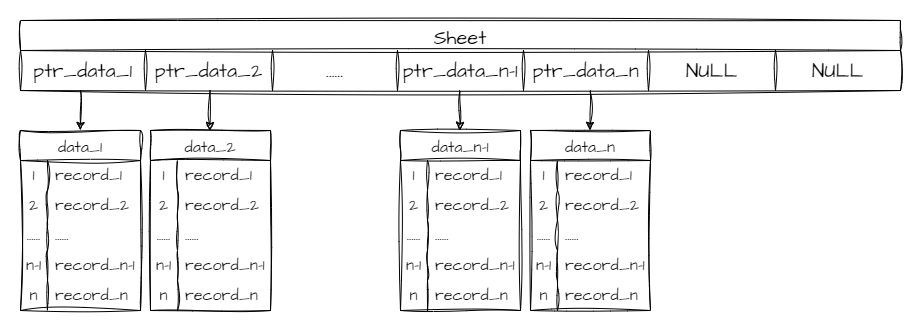
但这个 sheet 无论怎么看都是一个数组,而 ptr_data 是个指针,也就是说,以上数据结构仍然是一种顺序表,只不过表中的数据从具体的值改为指针。它仍然没有脱离顺序表的范畴。自然顺序表的优势及劣势它也照单全收。
顺序表的劣势在于,开辟空间并非随需开辟,释放空间也显得不那么灵活。如果顺序表做到每次增加数据便拓展空间,删除数据便回收空间,基于 realloc 可能异地开辟的特点,搬运数据的时间复杂度为 O(N) 。如果顺序表的长度是几千万乃至几亿,每添加或者删除一个数据,其延迟是难以忽略的。因此上篇中的顺序表每次开辟空间均是成批开辟。但这种方式也必然造成空间的浪费。
如果有一种储存方式可以解决上述问题,做到每一个数据的空间都按需开辟,且按需释放,那么在最极端的情况下,它甚至可以节省近一半存储空间。在此思想上,数组的特性完全不符合该要求,首先需要抛弃的便是数组。但上图倘若没了数组,每一个数据节点的位置便无从知晓。于是有了链表的概念。
链表可以将下一个节点的位置储存在上一个节点中,此外还可以将上一个节点的位置储存在下一个节点中。
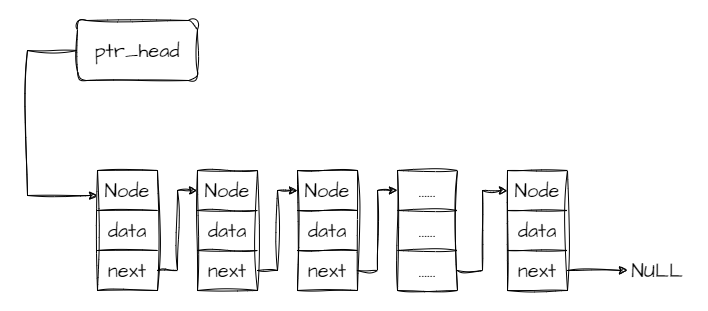
如上图。链表还需要一个头指针指向第一个节点。上述结构称为单链表。此外链表还有以下常见结构(环链、双向链)。
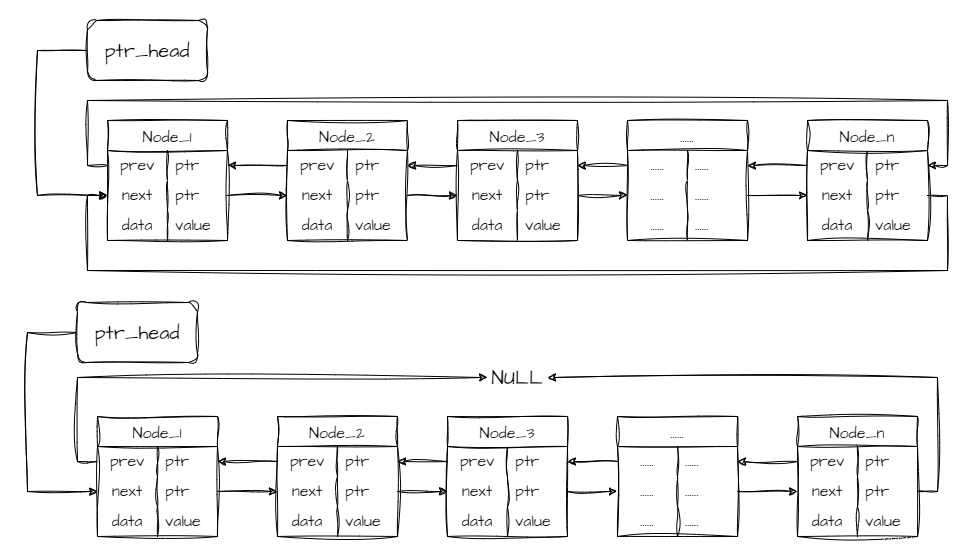
比如这篇文章最顶端“上一篇”、“下一篇”的导航链接就类似双向链。
2、链表创建
2.1、文件结构
本文以最基本的单链为例,因为其他变形比单链的复杂程度高不了多少,有机会再作补充。仍是先从文件结构开始,分别建立以下三个文件,
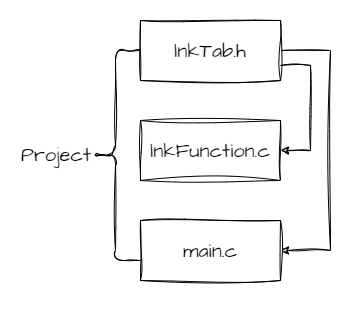
lnkTab.h :用于创建结构体类型及声明函数;
lnkFunction.c :用于创建链表各种操作功能的函数;
main.c :仅创建 main 函数,用作测试。
2.2、前期工作
在 lnkTab.h 中先码入以下内容:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>//自定义数据类型和打印类型,方便后续更改储存数据的类型
#define PRINT_FORMAT "%d"
typedef int DATATYPE;//创建链表节点的结构体类型
typedef struct LinkedListType
{DATATYPE data;struct LinkedListType* next;
}LinkedListType;//---------------------函数声明---------------------
//打印链表
extern void DataPrint(LinkedListType*);//创建节点
extern LinkedListType* NodeCreate(const DATATYPE, const LinkedListType*);//销毁链表
extern void DataDestory(LinkedListType**);在 lnkFunction.c 中包含 lnkTab.h 并分别创建一个打印链表和销毁链表的函数:
#include "lnkTab.h"//打印链表
void DataPrint(LinkedListType* ptr_headNode)
{//创建节点指针LinkedListType* currentNode = ptr_headNode;//循环打印while (currentNode){//打印printf(PRINT_FORMAT" -> ", currentNode->data);//移动节点指针currentNode = currentNode->next;}printf("NULL\n");
}//创建节点
LinkedListType* NodeCreate(const DATATYPE data, const LinkedListType* next)
{LinkedListType* node = (LinkedListType*)malloc(sizeof(LinkedListType));//加入判断防止空间开辟失败if (node == NULL){perror("Malloc Fail");return NULL;}//节点赋值node->data = data;node->next = next;return node;
}//销毁链表
void DataDestory(LinkedListType** ptr2_headNode)
{//空链表判断if (!ptr2_headNode) return;//创建节点指针LinkedListType* currentNode = *ptr2_headNode;//循环逐个销毁节点while (currentNode){LinkedListType* nextNode = currentNode->next;free(currentNode);currentNode = nextNode;}//头指针置空*ptr2_headNode = NULL;
}最后在 main.c 中包含 lnkTab.h,并创建一个链表头指针:
#include "lnkTab.h"int main()
{LinkedListType* ptr_headNode = NULL;return 0;
}至此,前期工作准备完毕。
3、链表操作
3.1、增
同顺序表一样,链表除了指定位置插入数据之外,最好也定义下头部插入数据及尾部插入数据的函数。因此先在 lnkTab.h 中加入以下函数声明:
//指定位置插入数据
extern void DataPush(LinkedListType**, const int, const DATATYPE);
//头部插入数据
extern void DataPushHead(LinkedListType**, const DATATYPE);
//尾部插入数据
extern void DataPushTail(LinkedListType**, const DATATYPE);之后先创建 DataPush 函数。在此之前把函数的流程图画出,以助于思考。画流程图的过程中能认识到空链表跟非空链表要分开处理,除了头插,其他位置插入的逻辑是相同的:
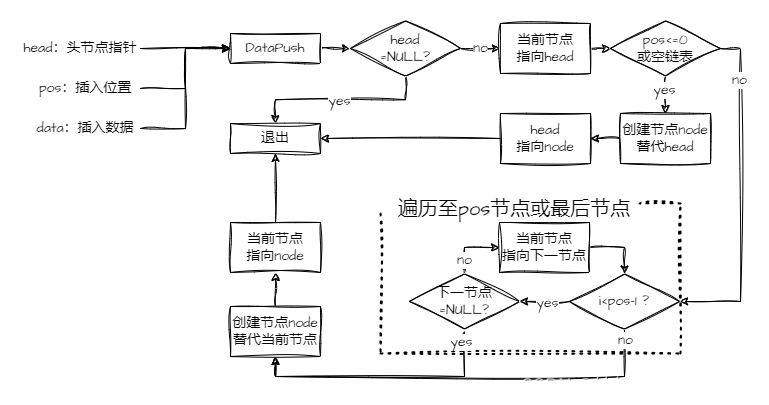
对照上图,照着在 lnkFunction.c 里写出如下代码:
void DataPush(LinkedListType** ptr2_headNode, const int pos, const DATATYPE data)
{//有效性检查if (!ptr2_headNode) return;LinkedListType* currentNode = *ptr2_headNode;//如果插入位置小于等于0或者没有节点if (pos <= 0 || !currentNode){//创建节点,将头指针的值赋予该节点的指向,并将头指针指向该节点LinkedListType* node = NodeCreate(data, currentNode);*ptr2_headNode = node;return;}//遍历节点至插入位置前一节点for (int i = 0; i < pos - 1; i++){//若遇到最后一个节点则停止遍历,当前节点指针指向最后一个节点if (currentNode->next)currentNode = currentNode->next;elsebreak;}//创建节点,将当前节点的指向值赋予创建的该节点的指向,并将当前节点指向创建的节点LinkedListType* node = NodeCreate(data, currentNode->next);currentNode->next = node;
}至于头插尾插数据,只不过是上述函数 pos 位置的区别。因此:
//pos = 0 便是头插
void DataPushHead(LinkedListType** ptr2_headNode, const DATATYPE data)
{DataPush(ptr2_headNode, 0, data);
}//由于 DataPush 函数在 pos 大于节点数时自动进行尾插
//因此 pos = INT_MAX 在任意情况下都是尾插
void DataPushTail(LinkedListType** ptr2_headNode, const DATATYPE data)
{DataPush(ptr2_headNode, INT_MAX, data);
}验证环节。在 main 函数中加入如下代码试运行:
DataPush(&ptr_headNode, 10, 1234);DataPrint(ptr_headNode); // 1234 NULLDataPushTail(&ptr_headNode, 1);DataPrint(ptr_headNode); // 1234 1 NULLDataPushHead(&ptr_headNode, 2);DataPrint(ptr_headNode); // 2 1234 1 NULLDataPushTail(&ptr_headNode, 3);DataPrint(ptr_headNode); // 2 1234 1 3 NULLDataPush(&ptr_headNode, 1, 14542);DataPrint(ptr_headNode); // 2 14542 1234 1 3 NULLDataPushHead(&ptr_headNode, 4);DataPrint(ptr_headNode); // 4 2 14542 1234 1 3 NULLDataPushTail(&ptr_headNode, 114514);DataPrint(ptr_headNode); // 4 2 14542 1234 1 3 114514 NULLDataPush(&ptr_headNode, 10, 1442);DataPrint(ptr_headNode); // 4 2 14542 1234 1 3 114514 1442 NULL
结果与预期无误。至此插入功能便已完成。
3.2、删
第一步当然是在 lnkTab.h 中加入函数声明:
//指定位置删除数据
extern void DataPop(LinkedListType**, const int, const int);
//头部删除数据
extern void DataPopHead(LinkedListType**);
//尾部删除数据
extern void DataPopTail(LinkedListType**);完毕后,二话不说,先上流程图。这里同样要注意区分空链和其他位置删除。不过删除节点还得将头删及其他位置删除分开判定。
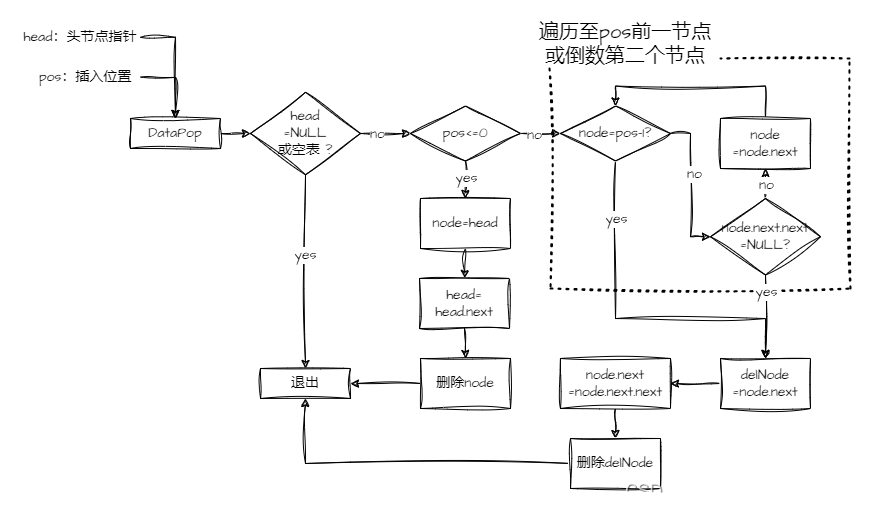
而且这里要注意的是,删除与插入不同,万一 pos 值传错导致小于 0 或者大于链表长度,便不能如上图简单粗暴地执行头删尾删。创建函数的时候多加一个参数来判断是否要在这种情况下头删或者尾删最好不过了。为了直观,还是在 lnkTab.h 头文件中加个枚举类型:
//定义删除节点的暴力模式和非暴力模式
enum Deletion { UNFORCED, FORCED };然后,在 lnkFunction.c 里码下这些:
void DataPop(LinkedListType** ptr2_headNode, const int pos, const int deletionMode)
{//如果没有节点则直接退出if (!ptr2_headNode || !*ptr2_headNode) return;LinkedListType* currentNode = *ptr2_headNode;//如果插入位置小于等于0则头删,前提是在非暴力模式下if (pos == 0 || (pos < 0 && deletionMode)){*ptr2_headNode = (*ptr2_headNode)->next;free(currentNode);return;}//遍历节点至需要删除的节点前一节点int i;for (i = 1; i <= pos - 1; i++){//若遇到倒数第二个节点则停止遍历,当前节点指针指向倒数第二个节点if (currentNode->next->next)currentNode = currentNode->next;elsebreak;}//模式不暴力的话,pos超出表长度就直接退出了if (i < pos - 1 && !deletionMode) return;//删!LinkedListType* freeNode = currentNode->next;currentNode->next = currentNode->next->next;free(freeNode);
}然后头删 pos 为 0 ,尾删 pos = INT_MAX 且删除模式为 FORCED 。就没必要再赘述了:
//删除头部节点
void DataPopHead(LinkedListType** ptr2_headNode)
{DataPop(ptr2_headNode, 0, UNFORCED);
}//删除尾部节点
void DataPopTail(LinkedListType** ptr2_headNode)
{DataPop(ptr2_headNode, INT_MAX, FORCED);
}题外话,这里再提另一种更安全的方式, 指定位置删除的 pos 如果超出链表范围直接报错,然后头删尾删单独写:
//删除头部节点
void DataPopHead(LinkedListType** ptr2_headNode)
{if (!ptr2_headNode) return;LinkedListType* currentNode = *ptr2_headNode;//如果没有节点则直接退出if (currentNode == NULL) return;//将头指针置为第一个节点的指向,并释放第一个节点*ptr2_headNode = currentNode->next;free(currentNode);
}//删除尾部节点
void DataPopTail(LinkedListType** ptr2_headNode)
{if (!ptr2_headNode) return;LinkedListType* currentNode = *ptr2_headNode;//如果没有节点则直接退出if (currentNode == NULL) return;//如果只有一个节点则采用头删else if (currentNode->next == NULL){DataPopHead(ptr2_headNode);return;}//遍历至倒数第二个节点,释放最后一个节点,并将倒数第二个节点指向置空else{while (currentNode->next->next){currentNode = currentNode->next;}free(currentNode->next);currentNode->next = NULL;}
}回归正题,之后是熟悉的测试阶段。 main 函数中添加:
printf("\n----------DataPopTest----------\n");DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // 2 14542 1234 1 3 114514 1442 NULLDataPop(&ptr_headNode, 2, UNFORCED);DataPrint(ptr_headNode); // 2 14542 1 3 114514 1442 NULLDataPop(&ptr_headNode, 1000, UNFORCED);DataPrint(ptr_headNode); // 2 14542 1 3 114514 1442 NULLDataPop(&ptr_headNode, 1000, FORCED);DataPrint(ptr_headNode); // 2 14542 1 3 114514 NULLDataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // 14542 1 3 114514 NULL DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // 1 3 114514 NULL DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // 3 114514 NULL DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // 114514 NULL DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // NULL DataPop(&ptr_headNode, 0, UNFORCED);DataPrint(ptr_headNode); // NULL 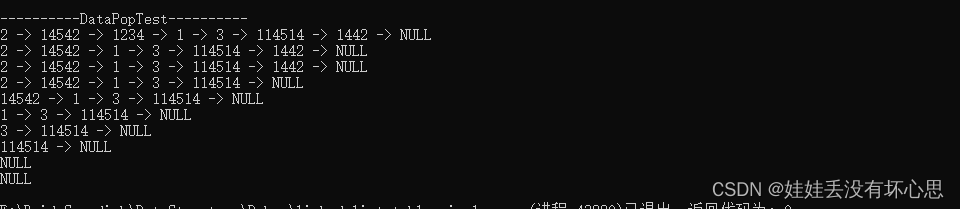
完事!
3.3、改和查
这两个功能简直不要太简单。查的逻辑跟打印逻辑一致,至于改,用查的功能返回节点地址,直接改 data 完事。
lnkTab.h :
//查找节点
extern LinkedListType* DataSearch(const LinkedListType*, const DATATYPE);
//修改节点
extern void DataModify(const LinkedListType*, DATATYPE, DATATYPE);lnkFunction.c:
//查找节点
LinkedListType* DataSearch(const LinkedListType* ptr_headNode, const DATATYPE data)
{LinkedListType* currentNode = ptr_headNode;while (currentNode){if (currentNode->data == data) break;currentNode = currentNode->next;}return currentNode;
}//修改节点
void DataModify(const LinkedListType* ptr_headNode, DATATYPE target, DATATYPE replace)
{LinkedListType* node = DataSearch(ptr_headNode, target);if (!node) return;node->data = replace;
}main.c 测试:
printf("\n----------DataSearchModifyTest----------\n");for (int i = 20; i >= 10; i--){DataPushHead(&ptr_headNode, i);}DataPrint(ptr_headNode); // 10 12 13 14 15 16 17 18 19 20 NULLDataModify(ptr_headNode, 3, 23457); DataPrint(ptr_headNode); // 10 12 13 14 15 16 17 18 19 20 NULLDataModify(ptr_headNode, 13, 23457);DataPrint(ptr_headNode); // 10 12 23457 14 15 16 17 18 19 20 NULL
搞定!准备下一篇。撒花!
4、作点补充
一开始就提到双向链表和环链。虽然结构复杂了,但是这两种结构比单链简单太多了。可以说学懂了单链,那么其他结构的链表跟玩似的。
以另一个常规的极端(不考虑中途环状),环状双向链举例。在数据操作的代码上,这个结构可比单链节省了寻找尾节点以及记录上一个节点指针的麻烦。
双向链如果一直找上一个( prev )节点,它也只不过是另一种单链,视作 next 结构的倒序。最直观的在于链表倒置:
while(currentNode)
{DATATYPE* nextNode = currentNode->next;currentNode->next = currentNode->prev;currentNode->prev = temp;currentNode = nextNode;
}一个循环搞定整个链表导致,而如果是单链,需要考虑遍历分别头插之类的,代码量直线上升。至于环链,尾节点的 next 指向头节点。事实上这种结构提供了寻找尾节点的便利( currentNode->prev )。那是更便利了,只不过不支持迭代,总有牺牲嘛。
构建节点的结构体特别自由,链表也就那么几种大体结构,细节没有规定。总之,只要实现节点内记录其他节点的信息便属于链表。奥力给!
相关文章:
初级数据结构(二)——链表
文中代码源文件已上传:数据结构源码 <-上一篇 初级数据结构(一)——顺序表 | NULL 下一篇-> 1、链表特征 与顺序表数据连续存放不同,链表中每个数据是分开存放的,而且存放的位置尤其零散&#…...
Kubernetes架构及核心部件
文章目录 1、Kubernetes集群概述1.1、概述1.2、通过声明式API即可 2、Kubernetes 集群架构2.1、Master 组件2.1.1、API Server2.1.2、集群状态存储2.1.3、控制器管理器2.1.4、调度器 2.2、Worker Node 组件2.2.1、kubelet2.2.2、容器运行时环境2.2.3、kube-proxy 2.3、图解架构…...

RAW和YUV的区别
RAW是指未经过任何压缩或处理的原始图像数据。在摄像头中,原始图像数据可以是来自图像传感器的未经处理的像素值。这些原始数据通常以一种Bayer模式的形式存在,其中每个像素仅包含一种颜色信息(红色、绿色或蓝色),需要…...
)
Linux常见问题-获取日志方法总结(Ubuntu/Debian)
1 日志基本路径和基础查看方法 在 Ubuntu 或 Debian 11 系统中,可以通过不同的日志文件来获取系统日志和内核日志。日志常见路径如下: /var/log/syslog:包含系统的整体日志,包括各种系统事件和服务日志。/var/log/auth.log&…...

【机器视觉技术栈】03 - 镜头
镜头 定焦镜头变焦镜头远心镜头 FA镜头与远心镜头的区别? 焦距越小畸变程度越大,精度要求不高的场景可以使用焦距大的FA镜头做尺寸测量,但焦距越大带来的问题就是整个机械设备越大。精度高的场景使用远心镜头进行尺寸测量。 光学基础知识…...

判断一个Series序列的值是否为单调递减Series.is_monotonic_decreasing
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 判断一个Series序列中 各值是否单调递减 s.is_monotonic_decreasing [太阳]选择题 以下代码的输出结果中正确的是? import pandas as pd s1 pd.Series([3,2,1]) s2 pd.Series([3,2,4]) pri…...
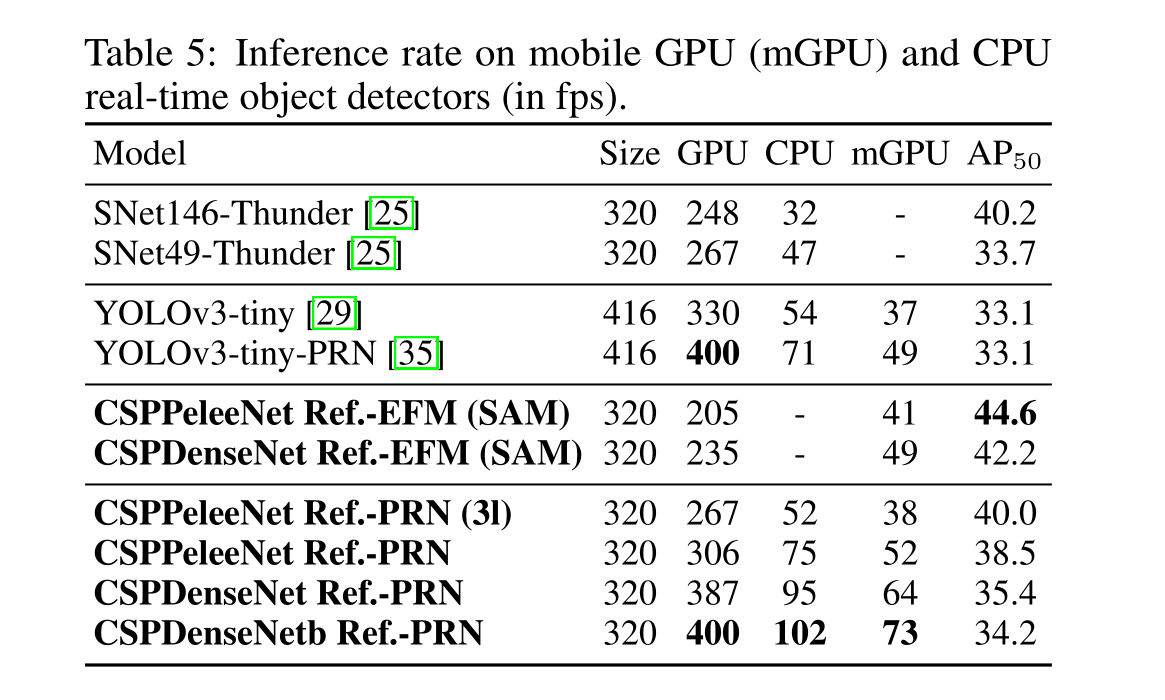
CSPNet: A New Backbone that can Enhance Learning Capability of CNN(2019)
文章目录 -Abstract1 Introduction2 Related workformer work 3 Method3.1 Cross Stage Partial Network3.2 Exact Fusion Model 4 Experiments5 Conclusion 原文链接 源代码 - 梯度信息重用(有别于冗余的梯度信息)可以减少计算量和内存占用提高效率&am…...

本科毕业论文查重的依据
大家好,今天来聊聊本科毕业论文查重的依据,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧: 本科毕业论文查重依据:维护学术诚信的基石 摘要: 本科毕业论文是衡量学生学…...

如何利用Axure制作移动端产品原型
Axure是一款专业的快速原型设计工具,作为专业的原型设计工具,Axure 能够快速、高效地创建原型,同时支持多人协作设计和版本控制管理。它已经得到了许多大公司的采用,如IBM、微软、思科、eBay等,这些公司都利用Axure 进…...

Java中时间之间的转换
Java中常见的时间类有:Date、Calendar、SimpleDateFormat等。下面对不同时间类之间的转换进行介绍。 1、Date和Calendar之间的转换 Date和Calendar都可以表示时间,但是它们的使用方式不同。Date是一个表示特定时间点的类,而Calendar则是一个…...
【win32_005】调试信息打印到控制台----2种简单方法
方法1:使用win32 api函数 PCTSTR str1 TEXT("123456789");AllocConsole();HANDLE HConsole GetStdHandle(STD_OUTPUT_HANDLE);WriteConsole(HConsole, str1, 9, NULL, NULL);https://learn.microsoft.com/zh-cn/windows/console/writeconsole 方…...
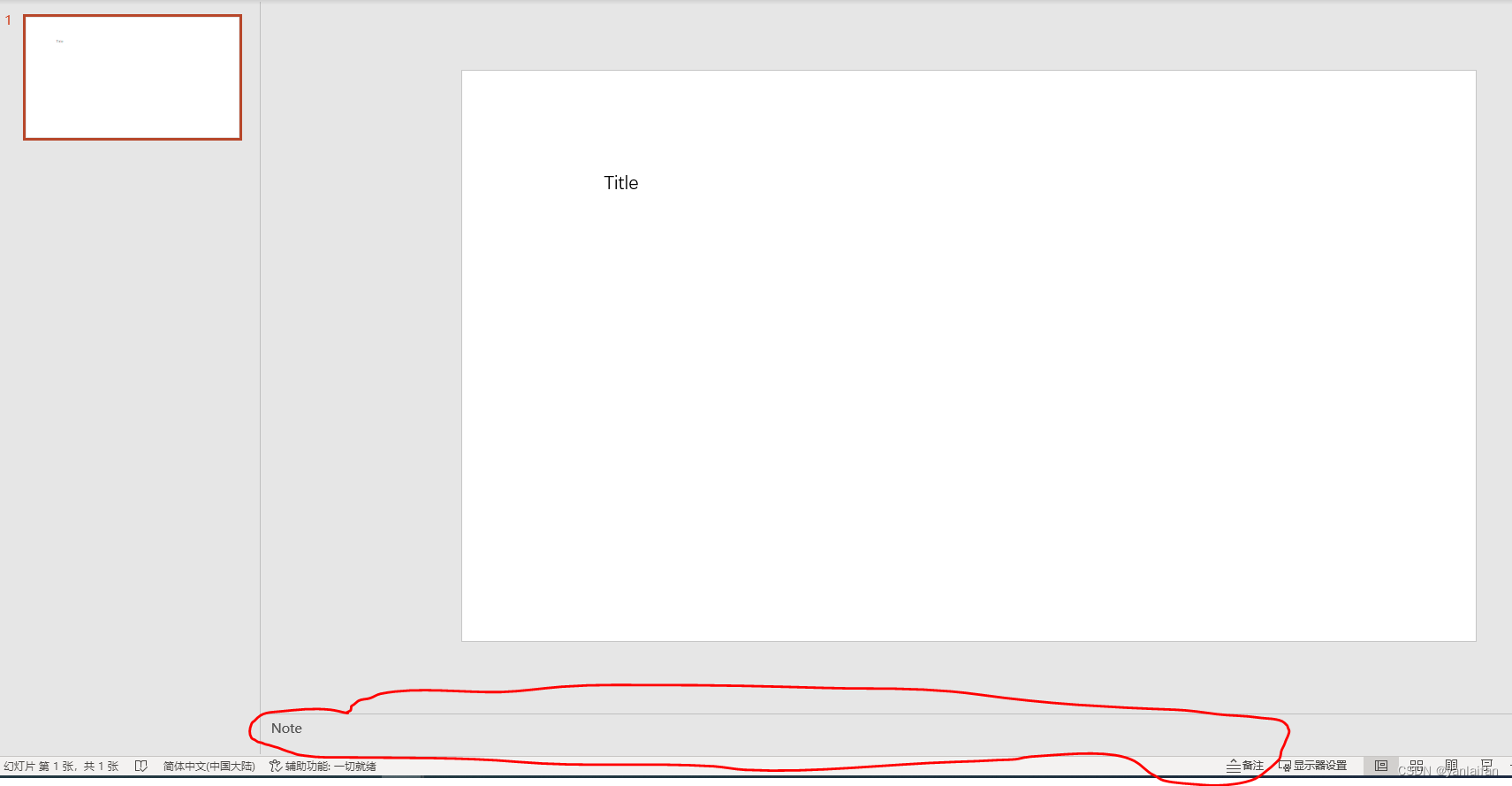
PPT添加备注
0 Preface/Foreward 1 添加备注方法 添加备注方法:在page的最下端,有一个空白文本框,该文本框用来添加备注。...
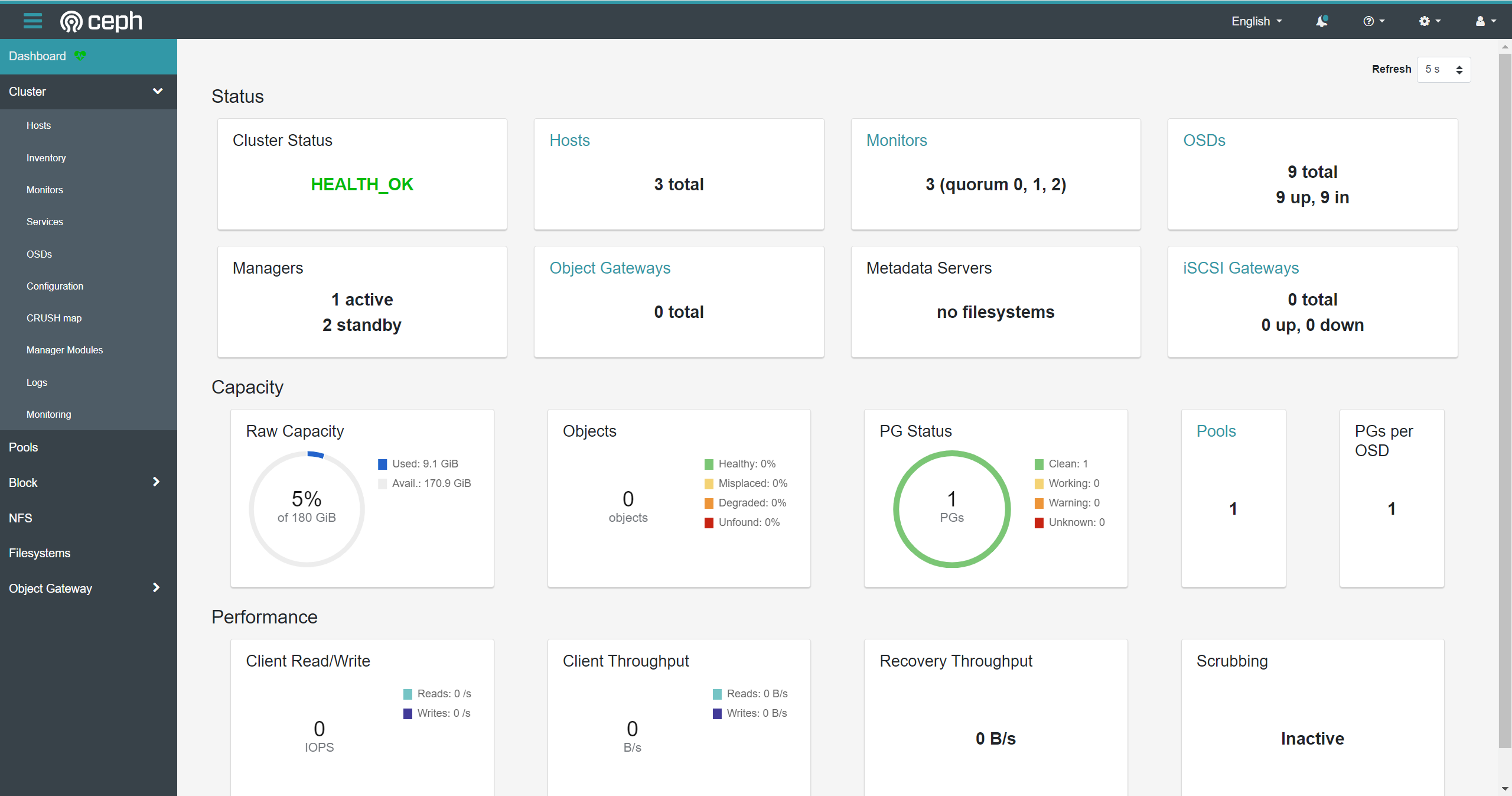
Ubuntu20.04使用cephadm部署ceph集群
文章目录 Requirements环境安装Cephadm部署Ceph单机集群引导(bootstrap)建立新集群 管理OSD列出可用的OSD设备部署OSD删除OSD 管理主机列出主机信息添加主机到集群从集群中删除主机 部署Ceph集群 Cephadm通过在单个主机上创建一个Ceph单机集群࿰…...

激光打标机在智能手表上的应用:科技与时尚的完美结合
随着科技的飞速发展,智能手表已经成为我们日常生活中不可或缺的智能设备。而在智能手表制造中,激光打标机扮演着至关重要的角色。本文将详细介绍激光打标机在智能手表制造中的应用,以及其带来的优势和影响。 一、激光打标机在智能手表制…...
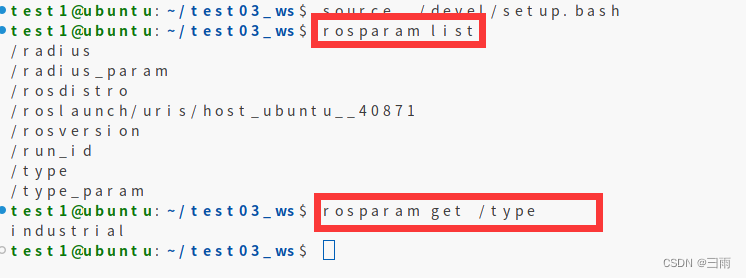
ROS-ROS通信机制-参数服务器
文章目录 一、基础理论知识二、C实现三、Python实现 一、基础理论知识 参数服务器在ROS中主要用于实现不同节点之间的数据共享。参数服务器相当于是独立于所有节点的一个公共容器,可以将数据存储在该容器中,被不同的节点调用,当然不同的节点…...

在github中通过action自动化部署 hugo academic theme,实现上传md文件更新博客内容
在github中通过action自动化部署 hugo academic theme 一、GitHub Action自动化部署Hugo博客方法 主要参考:【Hugo网站搭建】GitHub Action自动化部署Hugo博客 次要参考:使用 Github Action 自动部署 Hugo 博客 二、部署过程中遇到的问题和解决办法 …...

深入理解asyncio:异步编程的基础用法
引言: 随着计算机硬件的不断发展,对于异步编程的需求也越来越强烈。Python中的asyncio模块为开发者提供了一种强大而灵活的异步编程方式。本文将介绍asyncio的基础用法,包括async/await/run语句的使用、多个协程的并发执行、以及在协程中进行…...

Android 消息分发机制解读
前言 想必大家都知道Android系统有自己的一套消息分发机制,,从App启动那一刻起,App就创建了主线程的消息分发实例:Looper.sMainLooper,并开始无限循环,也就是App的心脏,一直跳动,负责协调分配来…...
)
【ML】LSTM应用——预测股票(基于 tensorflow2)
LSTM 应用预测股票数据 所用数据集:https://www.kaggle.com/datasets/yuanheqiuye/bank-stock 基于:tensorFlow 2.x 数据处理 import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.model_selection import tr…...

汇编语言程序设计实验报告
一、实验一 1、实验内容 (1)用Debug命令查看寄存器和内存中的内容 (2)上机过程及程序调试 2、实验目的 (1)要求掌握使用Debug命令查看寄存器和内存的方法; (2)通过…...

AI加速器安全架构:硬件级可信计算与FlexHEG技术解析
1. 前沿AI加速器的安全可信设计架构在当今AI技术快速发展的背景下,前沿AI模型的计算需求呈现指数级增长。根据行业数据,全球AI算力需求每3-4个月就会翻倍,这使得专用AI加速器成为支撑这一增长的核心基础设施。然而,随着AI模型能力…...

OpenAI大神教你如何榨干Codex
闻乐 发自 凹非寺量子位 | 公众号 QbitAI新晋员工确实毫无保留。Jason Liu,13k星开源库Instructor的作者,刚被OpenAI招进Codex团队没多久,不仅在社交平台大方发API额度;还写了篇Codex-maxxing,把自己的Codex玩法全抖出…...

8051指令集手册获取与开发优化指南
1. 8051指令集手册获取指南作为一名从事嵌入式开发十余年的工程师,我深知指令集手册在单片机开发中的核心地位。对于8051架构开发者而言,准确理解每条指令的机器周期、标志位影响和寻址方式是写出高效代码的基础。本文将系统梳理获取权威8051指令集资源的…...

Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接
Windows远程桌面免费解锁指南:家庭版也能享受多用户并发连接 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾经因为Windows家庭版无法使用远程桌面而烦恼?或者需要多人同时访问同一…...

KOSS模型:基于卡尔曼最优估计的选择性状态空间技术
1. 项目概述:KOSS模型的核心创新KOSS(Kalman-Optimal Selective State Spaces)是一种新型的选择性状态空间模型,它从根本上重构了序列建模的信息选择机制。与传统的RNN、Transformer或Mamba等模型不同,KOSS首次将卡尔曼…...

变分量子编译:用乘积态训练实现高效量子动力学模拟
1. 项目概述与核心价值量子动力学模拟,简单来说,就是用量子计算机来“播放”一个量子系统随时间变化的“电影”。这听起来像是量子计算机的“本职工作”,毕竟费曼在四十多年前就提出了这个构想。然而,把理论构想变成在真实、不完美…...

【芯片测试】:6. 向量、Sequencer 指令与高速串行 IO
Pattern 详解:向量、Sequencer 指令与高速串行 IO系列: Advantest V93000 SmarTest 8 核心概念解析|第 6 篇(共 8 篇) 适合读者: 需要理解数字测试激励数据结构的工程师前言 Pattern(模式&#…...
)
健身行业AI Agent部署失败率高达68%?(2024真实数据复盘与5步合规上线法)
更多请点击: https://intelliparadigm.com 第一章:健身行业AI Agent部署失败率高达68%?——2024真实数据复盘与5步合规上线法 2024年Q2《中国智能健身系统落地白皮书》抽样调研覆盖全国137家连锁健身房及SaaS服务商,结果显示&…...
)
火焰不飘、不燃、不爆?,Midjourney 6.6火效失效紧急修复方案(含--no参数黑名单清单与替代性热力图引导法)
更多请点击: https://codechina.net 第一章:火焰不飘、不燃、不爆?——Midjourney 6.6火效失效现象的本质溯源 近期大量用户反馈,在 Midjourney v6.6 中使用 fire、 flame、 blazing 等关键词生成图像时,火焰元素普遍…...

[智能体-42]:深度解读:Python 免编译 + 动态执行,支撑智能体落地大模型决策
一、先厘清核心概念无需编译执行:Python 属于解释型语言,区别于 C/C、Java 编译型语言。编译型语言必须先将源码整体编译成机器码 / 字节码文件,才能运行;Python 无需手动编译,源码可逐行边解析边执行,即时…...