ELK 日志解决方案

ELK 是目前最流行的集中式日志解决方案,提供了对日志收集、存储、展示等一站式的解决方案。
ELK 分别指 Elasticsearch、Logstash、Kibana。
- Elasticsearch:分布式数据搜索引擎,基于 Apache Lucene 实现,可集群,提供数据的集中式存储,分析,以及强大的数据搜索和聚合功能。
- Logstash:数据收集引擎,相较于Filebeat 比较重量级,但它集成了大量的插件,支持丰富的数据源收集,对收集的数据可以过滤,分析,格式化日志格式。
- Kibana:数据的可视化平台,通过该 web 平台可以实时查看 Elasticsearch 中的相关数据,并提供了丰富的图表统计功能。
- Filebeat:Filebeat 是一款轻量级,占用服务资源非常少的数据收集引擎,它是 ELK 家族的新成员,可以代替 Logstash 作为在应用服务器端的日志收集引擎,支持将收集到的数据输出到 Kafka,Redis 等队列。
一、Elasticsearch
1.1 安装配置
1.1.1 拉取镜像
[root@localhost software]# docker pull elasticsearch:7.17.7
1.1.2 配置文件
第一步:在 Linux 上创建三个数据挂载目录。
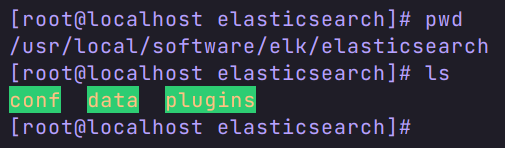
第二步:在 conf 目录下创建 elasticsearch.yml 文件,并修改权限为777。
[root@localhost elasticsearch]# cd conf/
[root@localhost conf]# touch elasticsearch.yml
[root@localhost conf]# chmod 777 elasticsearch.yml
[root@localhost conf]# ll
总用量 0
-rwxrwxrwx. 1 root root 0 12月 5 11:03 elasticsearch.yml
配置内容如下:

http:host: 0.0.0.0cors:enabled: trueallow-origin: "*"
xpack:security:enabled: false
1.1.3 修改 Linux 的 vm.max_map_count
直接启动后会报下面的异常
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
表示系统虚拟内存默认最大映射数为65530,无法满足ES系统要求,需要调整为262144以上。
修改方法如下:
查看 sysctl -a|grep vm.max_map_count
修改 sysctl -w vm.max_map_count=262144
1.2 创建运行
docker run -itd \
--name es \
--privileged \
--network docker_net \
--ip 172.18.12.80 \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \
-v /usr/local/software/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/software/elk/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/software/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.7
容器创建并运行成功后,我们在浏览器里面访问 虚拟机地址:9200,出现内容表示运行成功。
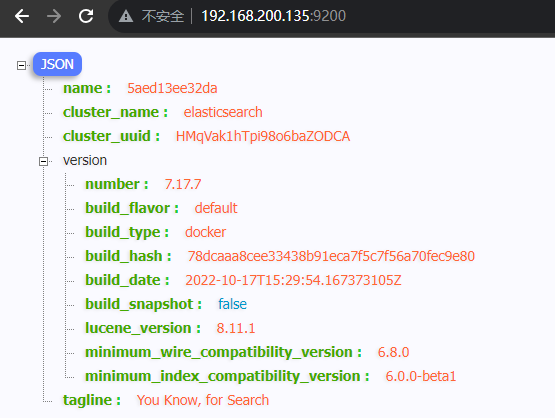
1.3 ES 的分词器
1.3.1 下载并上传分词器到 Linux 中
下载链接:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意:需下载和 es 一致的版本,避免出错。
上传到 /usr/local/software/elk/plugins/目录下。
1.3.2 拷贝分词器插件到容器 ik 文件夹
[root@localhost plugins]# docker cp elasticsearch-analysis-ik-7.17.7.zip es:/usr/share/elasticsearch/plugins/ik
1.3.3 解压分词器
进入容器 ik 文件夹下面(没有ik文件夹就手动创建),解压插件。
解压:
unzip elasticsearch-analysis-ik-7.17.7.zip
解压完将压缩包删除,并记得重启容器。
二、Kibana
2.1 安装
安装 Kibana 前需保证 ES 已经运行成功。
2.1.1 拉取镜像
docker pull kibana:7.17.7
注意版本尽量保持一致。
2.1.2 创建并运行容器
docker run -it \
--name kibana \
--privileged \
--network docker_net \
--ip 172.18.12.81 \
-e "ELASTICSEARCH_HOSTS=http://192.168.200.135:9200" \
-p 5601:5601 \
-d kibana:7.17.7
2.1.3 测试
浏览器打开 http://虚拟机地址:5601/ 成功进入即表示运行成功。
2.2 简单使用
- 打开
Dev Tools
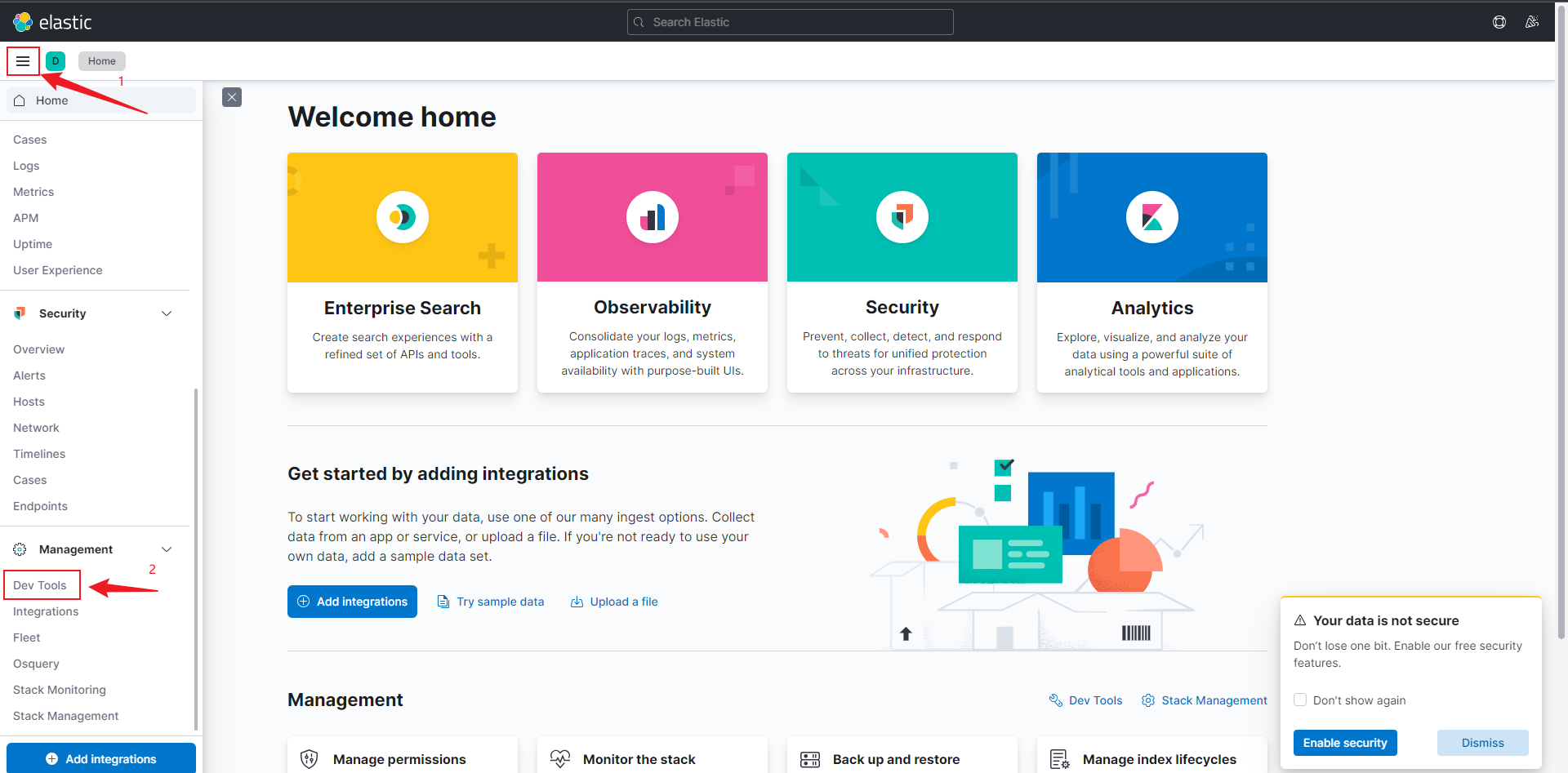
- 执行查询,可看到出现右面的数据
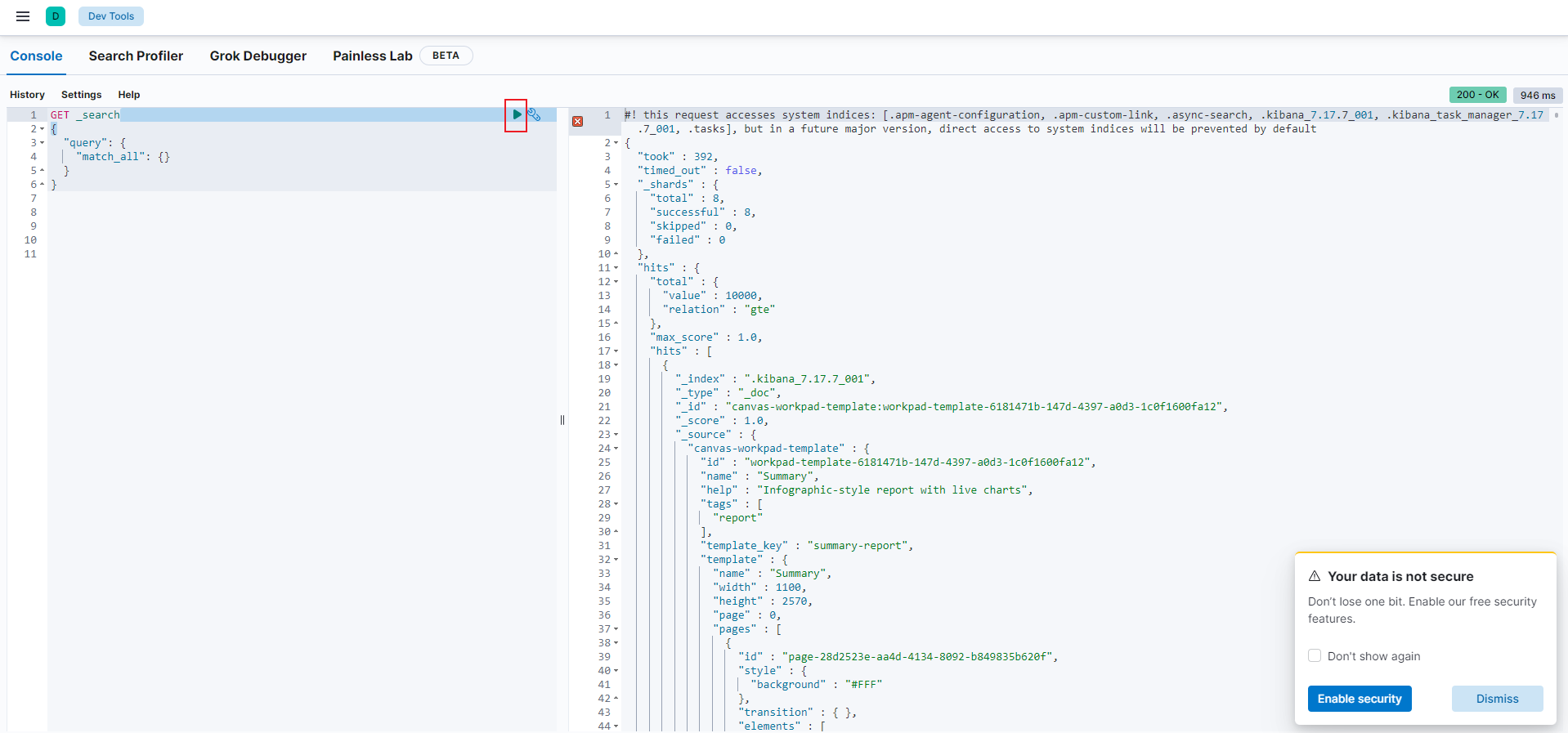
2.3 测试分词器
2.3.1 标准分词器
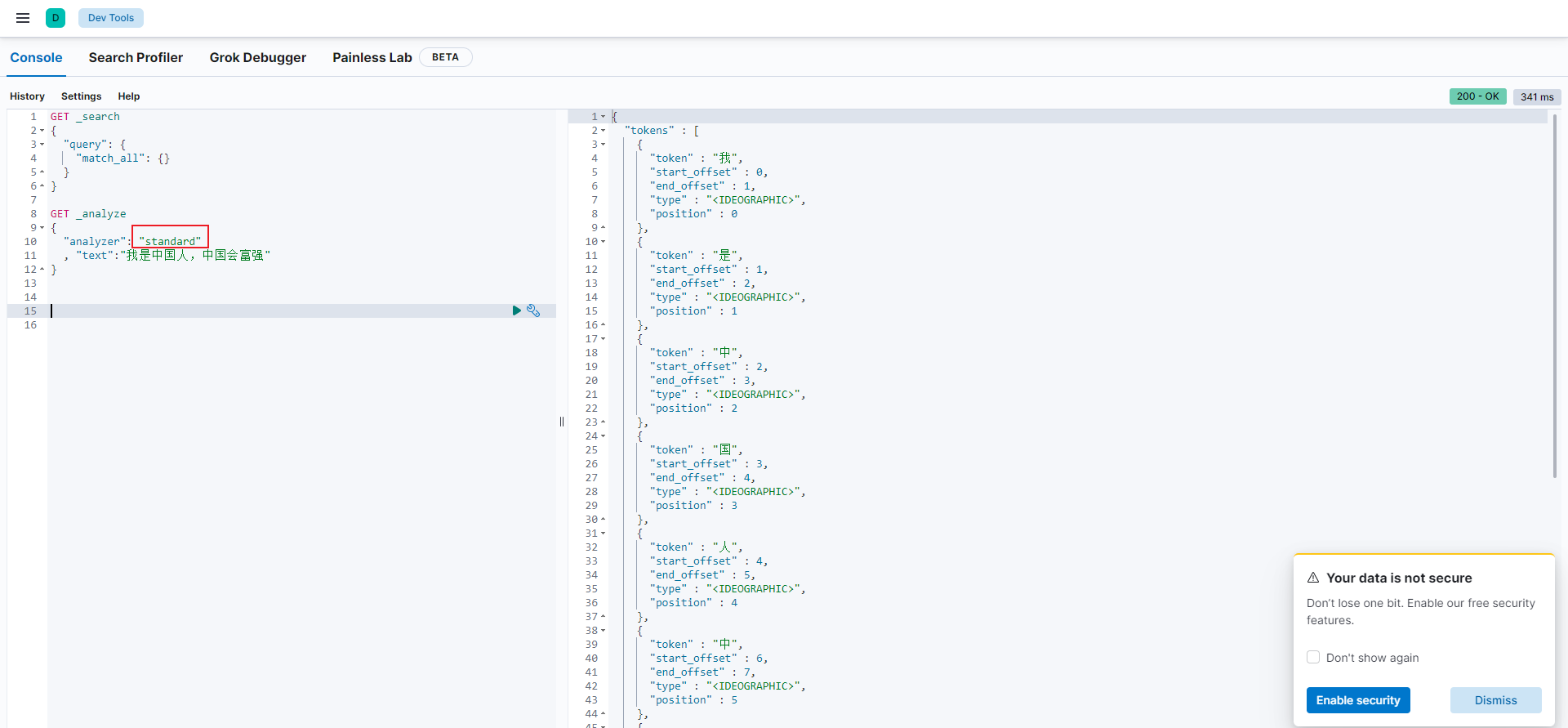
如上图所示,标准分词器对中文不太友好。
2.3.2 ES 分词器
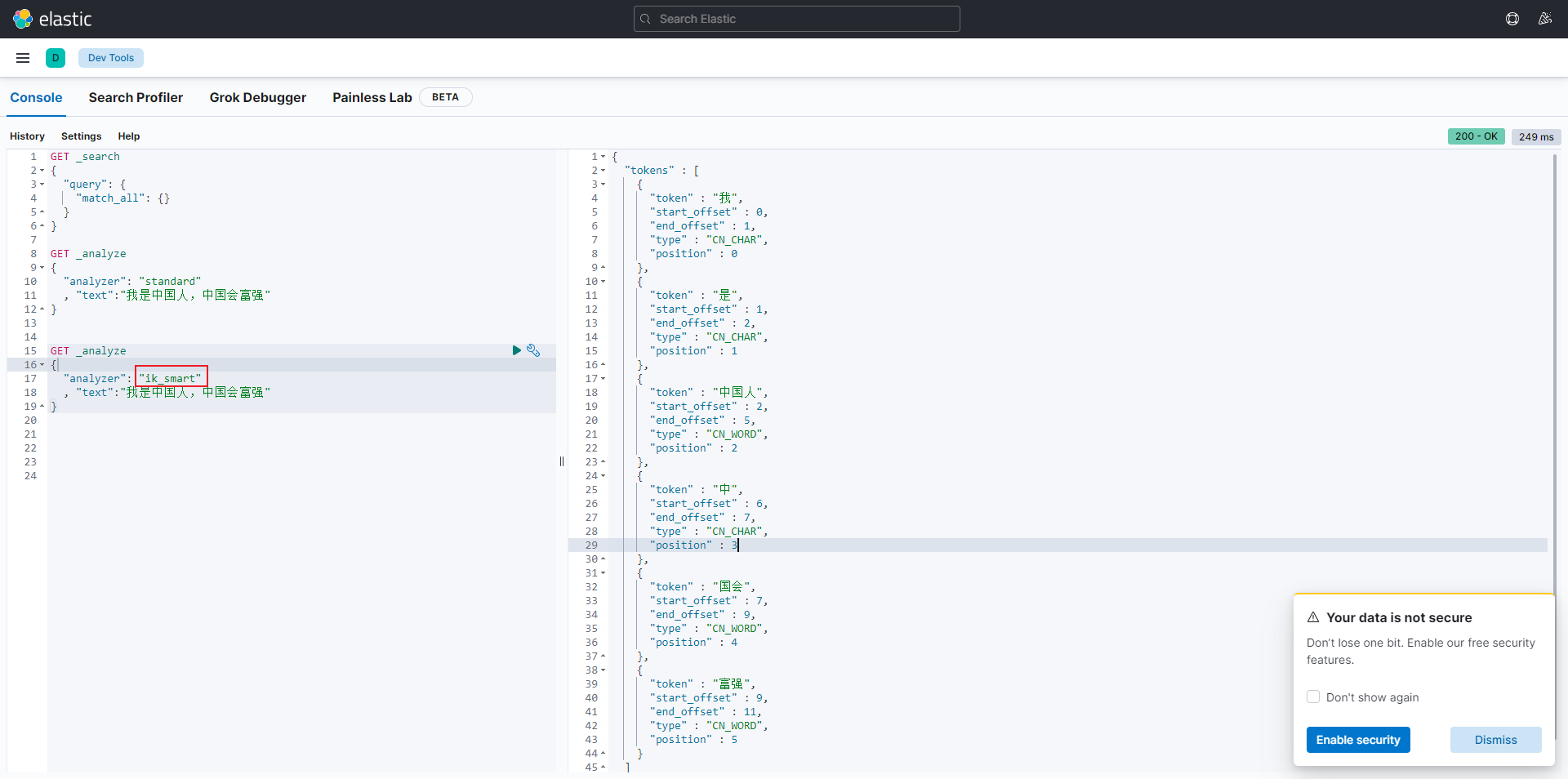
如上图所示,es 分词器对中文分词好一点,但是还是不够灵活。所以我们可以自定义一下 es 的分词器词典。
2.3.3 自定义 es 分词器词典
- 进入 es 容器的 ik/config 目录
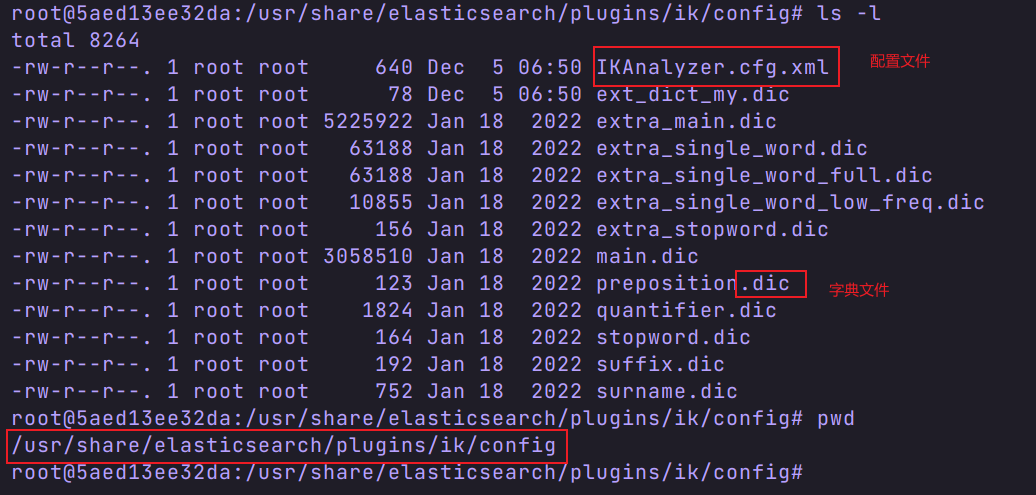
- 查看配置文件
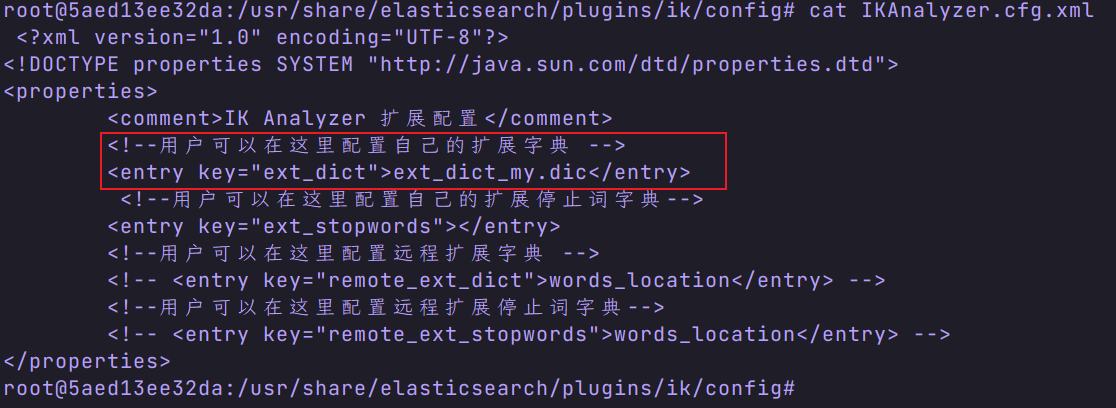
注意:ext_dict_my.dic 是我自定义的词典文件,默认没有。 - 编写自己的配置文件
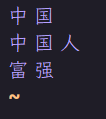
- 重启容器,并测试 。
三、Logstash
3.1 安装
3.1.1 拉取 logstash
[root@localhost ~]# docker pull logstash:7.17.7
3.1.2 创建容器
docker run -it \
--name logstash \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--network docker_net \
--ip 172.18.12.82 \
-v /etc/localtime:/etc/localtime \
-d logstash:7.17.7
3.2 容器配置
有三个配置文件,分别是
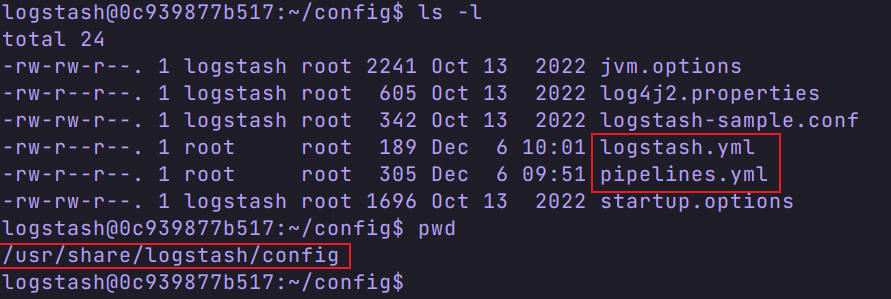
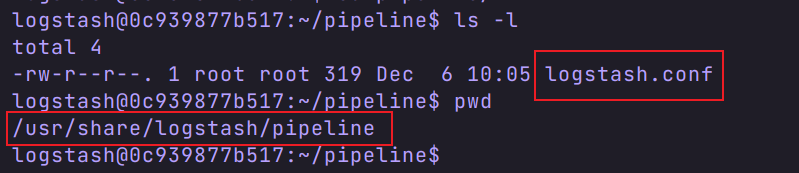
我们在宿主机创建一个 logstash 文件夹( /usr/local/software/elk/logstash),将三个配置文件复制到这个目录下,方便编辑。
logstash.yml
path.logs: /usr/share/logstash/logs
config.test_and_exit: false
config.reload.automatic: false
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.200.135:9200" ]
piplelines.xml
- pipeline.id: mainpath.config: "/usr/share/logstash/pipeline/logstash.conf"
logstash.conf
input {tcp {mode => "server"host => "0.0.0.0"port => 5044codec => json_lines}
}
filter{
}
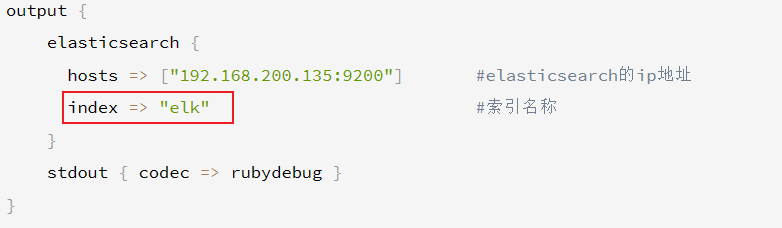
output {elasticsearch {hosts => ["192.168.200.135:9200"] #elasticsearch的ip地址 index => "elk" #索引名称}stdout { codec => rubydebug }
}
修改完成后,将配置文件拷贝到容器相应位置,并重启容器。
3.3 释放端口
firewall-cmd --add-port=9600/tcp --permanent firewall-cmd --add-port=5044/tcp --permanentfirewall-cmd --reload
四、springboot 中使用 logstash
4.1 引入框架
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>7.3</version>
</dependency>
4.2 创建 logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文档如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文档是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="10 seconds"><!--1. 输出到控制台--><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><!--此日志appender是为开发使用,只配置最低级别,控制台输出的日志级别是大于或等于此级别的日志信息--><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>DEBUG</level></filter><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern><!-- 设置字符集 --><charset>UTF-8</charset></encoder></appender><!-- 2. 输出到文件 --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><!--日志文档输出格式--><append>true</append><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} -%5level ---[%15.15thread] %-40.40logger{39} : %msg%n</pattern><charset>UTF-8</charset> <!-- 此处设置字符集 --></encoder></appender><!--3. LOGSTASH config --><appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"><destination>192.168.200.135:5044</destination><encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"><!--自定义时间戳格式, 默认是yyyy-MM-dd'T'HH:mm:ss.SSS<--><timestampPattern>yyyy-MM-dd HH:mm:ss</timestampPattern><customFields>{"appname":"QueryApp"}</customFields></encoder></appender><root level="DEBUG"><appender-ref ref="CONSOLE"/><appender-ref ref="FILE"/><appender-ref ref="LOGSTASH"/></root>
</configuration>
注意这个地址,需配置 es 的地址。
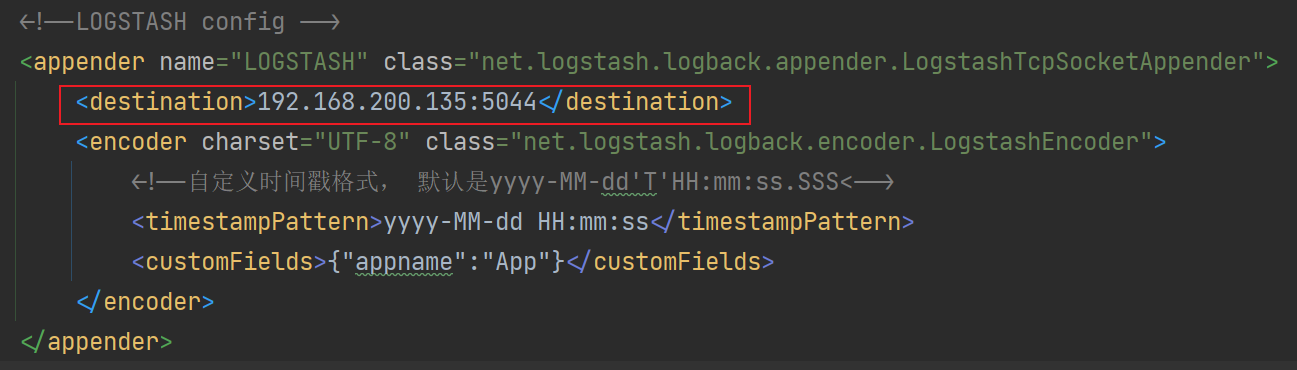
文件存放位置
4.3 测试代码
@Slf4j
@RestController
@RequestMapping("/api/query")
public class QueryController {@Autowiredprivate IBookDocService ibs;@GetMapping("/helloLog")public HttpResp helloLog(){List<BookDoc> all = ibs.findAll();log.debug("从es中查询到的数据:{}",all);log.debug("我是来测试logstash是否工作的");return HttpResp.success(all.subList(0,10));}
}
4.4 Kibana 中查看
4.4.1 创建一个索引
put elk
elk 名称是之前 logstash.conf 文件中配置的。
4.4.2 创建索引模式
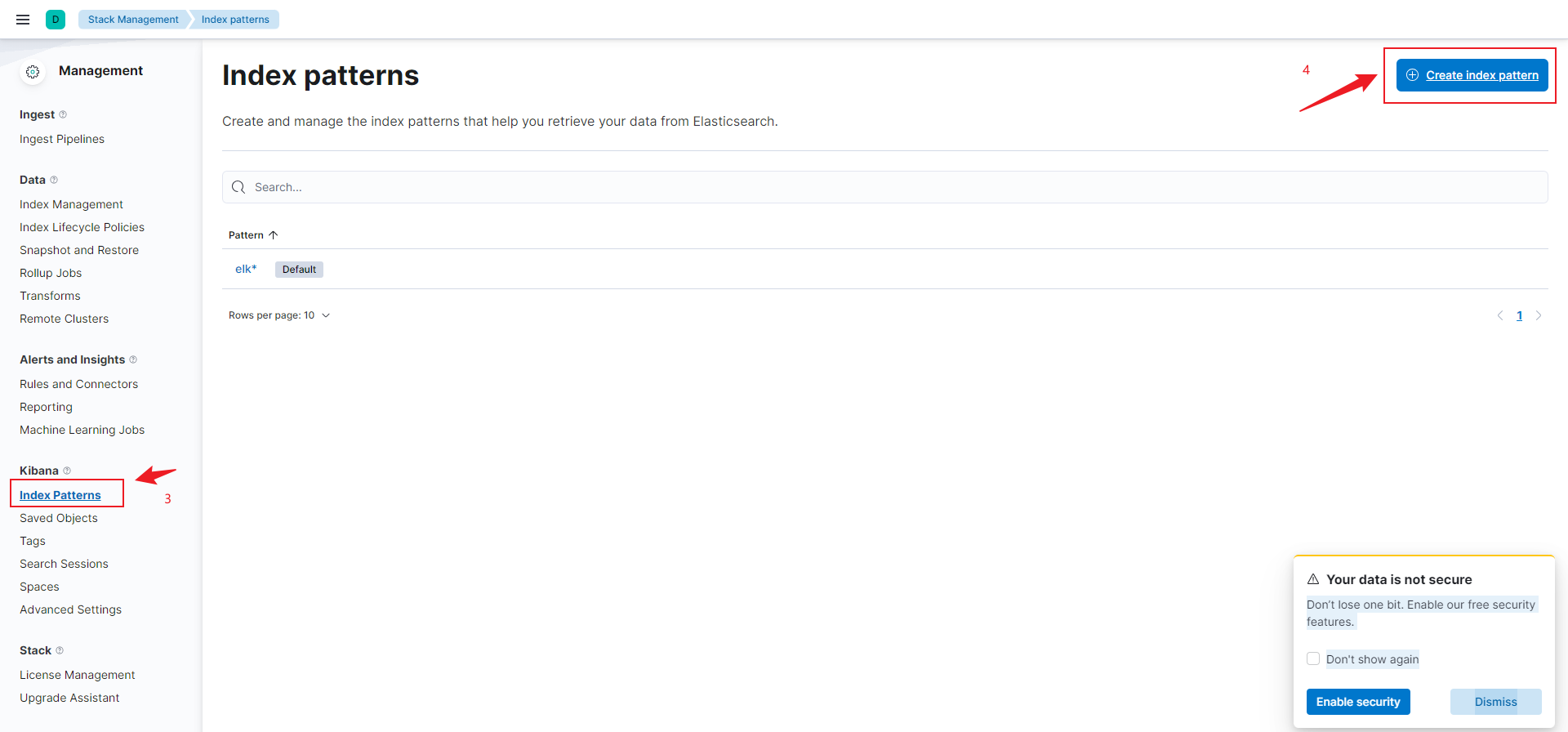
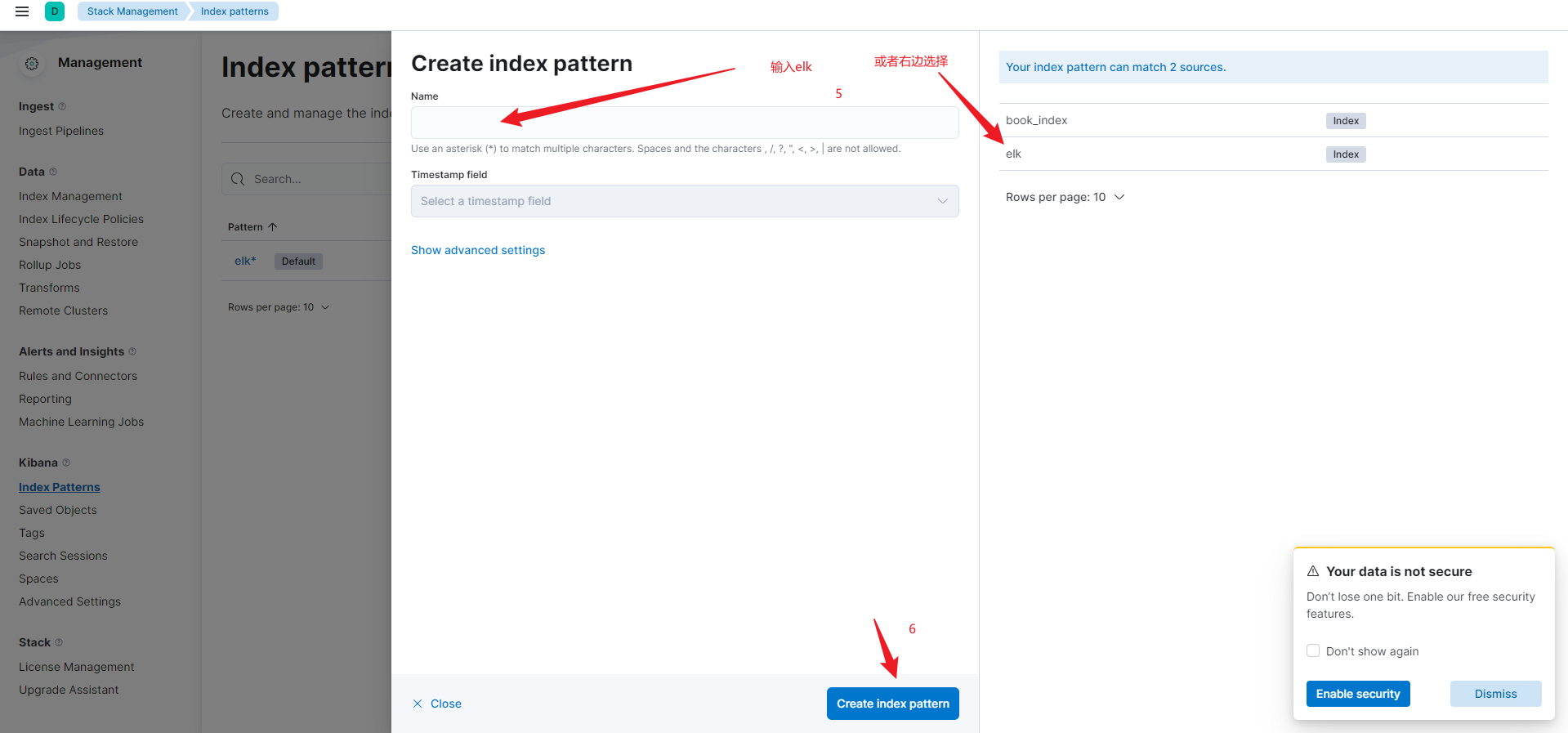
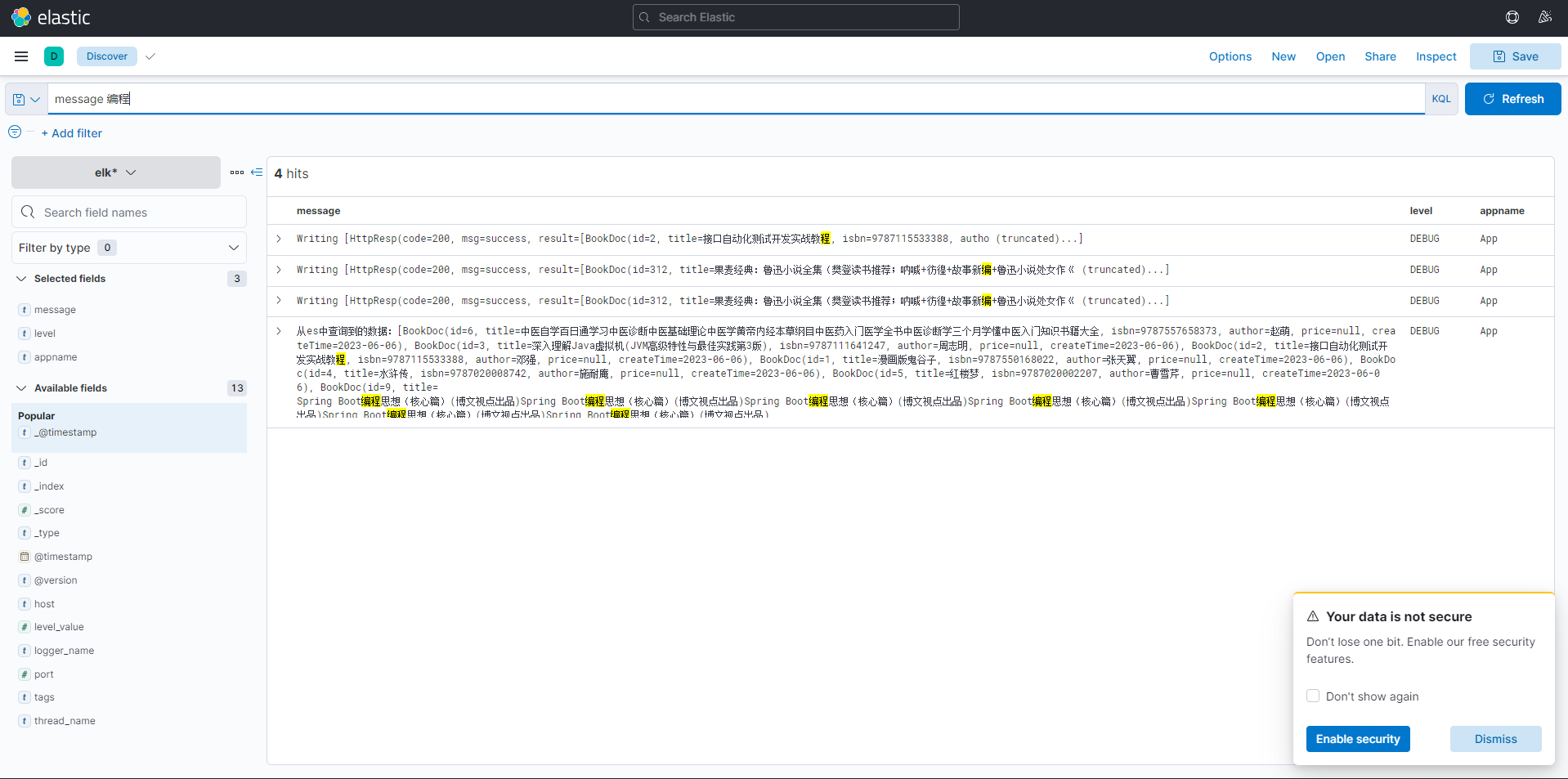
执行操作,如搜索。
相关文章:
ELK 日志解决方案
ELK 是目前最流行的集中式日志解决方案,提供了对日志收集、存储、展示等一站式的解决方案。 ELK 分别指 Elasticsearch、Logstash、Kibana。 Elasticsearch:分布式数据搜索引擎,基于 Apache Lucene 实现,可集群,提供…...
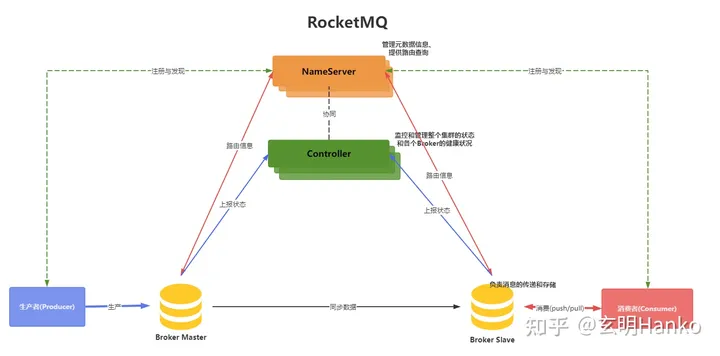
本项目基于Spring boot的AMQP模块,整合流行的开源消息队列中间件rabbitMQ,实现一个向rabbitMQ
在业务逻辑的异步处理,系统解耦,分布式通信以及控制高并发的场景下,消息队列有着广泛的应用。本项目基于Spring的AMQP模块,整合流行的开源消息队列中间件rabbitMQ,实现一个向rabbitMQ添加和读取消息的功能。并比较了两种模式&…...

freeswitch webrtc video_demo客户端进行MCU的视频会议
系统环境 一、编译服务器和加载模块 二、下载编译指定版本video_demo 三、配置verto.conf.xml 1.修改配置文件 2.重新启动 四、MCU通话测试 1.如何使用video_demo 2.测试结果 五、MCU的通话原理及音频/视频/布局/管理员等参数配置 附录 freeswitch微信交流群 系统环境 lsb_rel…...

【鸿蒙学习网络】
鸿蒙技术学习相关学习资料 官方文档:华为官方提供了鸿蒙开发者文档,包括开发指南、API参考和示例代码等。您可以访问华为开发者中心网站(https://developer.harmonyos.com/)获取最新的官方文档和教程。在 线 课 程 : …...
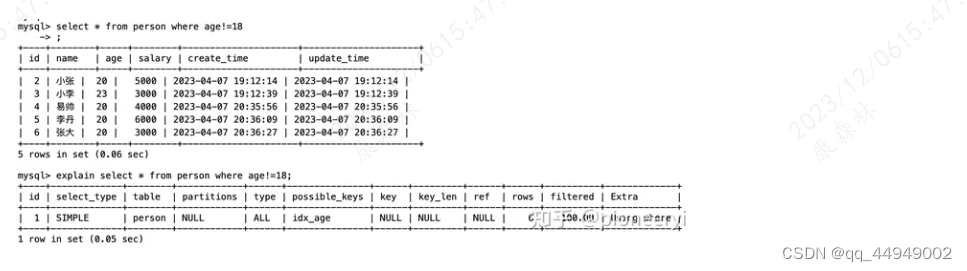
MySQL系列(一):索引篇
为什么是B树? 我们推导下,首先看下用哈希表做索引,是否可以满足需求。如果我们用哈希建了索引,那么对于如下这种SQL,通过哈希,可以快速检索出数据: select * from t_user_info where id1;但是这…...
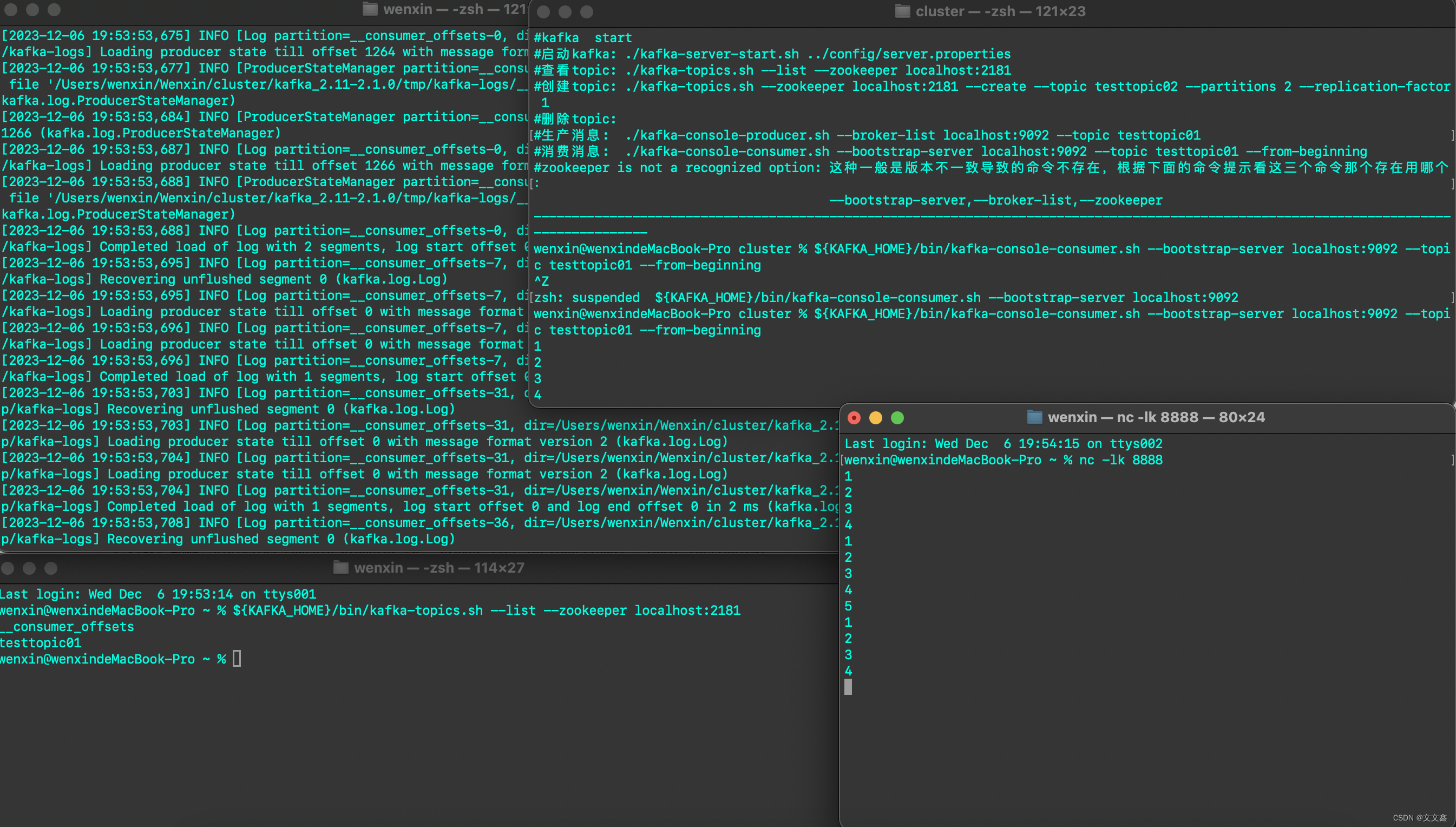
Flink Flink数据写入Kafka
一、环境准备 官网地址 flink官方集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖 <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.6</flink.version&g…...

《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 Affective Computing 2021
《论文阅读》用于情绪回复生成的情绪正则化条件变分自动编码器 前言简介模型结构实验结果总结前言 今天为大家带来的是《Emotion-Regularized Conditional Variational Autoencoder for Emotional Response Generation》 出版:IEEE Transactions on Affective Computing 时间…...

Pytorch CIFAR10图像分类 Swin Transformer篇
Pytorch CIFAR10图像分类 Swin Transformer篇 文章目录 Pytorch CIFAR10图像分类 Swin Transformer篇4. 定义网络(Swin Transformer)Swin Transformer整体架构Patch MergingW-MSASW-MSARelative position biasSwin Transformer 网络结构Patch EmbeddingP…...
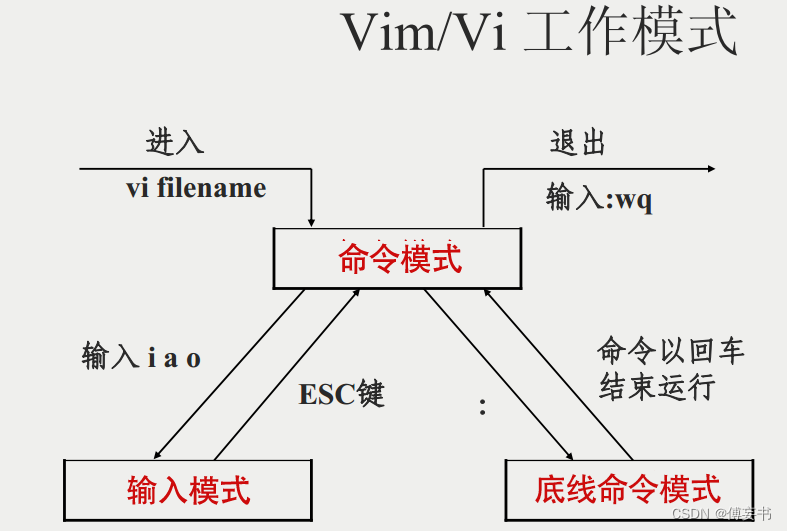
【vim】常用操作
用的时候看看,记太多也没用,下面都是最常用的,更多去查文档vim指令集。 以下均为正常模式下面操作,正在编辑的,先etc一下. 1/拷贝当前行 yy,5yy为拷贝包含当前行往下五行 2/p将拷贝的东西粘贴到当前行下…...

oracle、误操作删除数据库 数据恢复。
–查询 执行 delete 的语句 ,拿到删除的时间 FIRST_LOAD_TIME ,删除行数可参考 ROWS_PROCESSED select t.FIRST_LOAD_TIME,t.ROWS_PROCESSED,t.* from v$sql t where t.sql_text like %delete from trade% ;select *from trade as of timestamp to_time…...
【Angular开发】Angular在2023年之前不是很好
做一个简单介绍,年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师酒馆】…...
 但是 3.0.8-1ubuntu1.2 正要被安装)
记录 | 报错:libssl-dev : 依赖: libssl3 (= 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装
ubuntu 上安装 libssl-dev 失败的报错解决 报错: 下列软件包有未满足的依赖关系: libssl-dev : 依赖: libssl3 ( 3.0.8-1ubuntu1.1) 但是 3.0.8-1ubuntu1.2 正要被安装 E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破…...

MySQL联合查询、最左匹配、范围查询导致失效
服务器版本 客户端:navicat premium16.0.11 联合索引 假设有如下表 联合索引就是同时把多列设成索引,如(empno,ename)在查询的时候就会先按照empno进行查询,再按照ename进行查询其中empno是全局有序,ename是局部有…...

部署zabbix
源码下载地址: Download Zabbix sources nginx: download 防火墙和selinux都需要关闭 1、部署监控服务器 1)安装LNMP环境 Zabbix监控管理控制台需要通过Web页面展示出来,并且还需要使用MySQL来存储数据,因此需要先为Zabbix准备基础…...

服务器感染了.locked、.locked1勒索病毒,如何确保数据文件完整恢复?
尊敬的读者: locked、.locked1勒索病毒的威胁如影随形,深刻影响着数字世界的安全。本文将深入揭示locked、.locked1的狡猾特征,为您提供实用的数据恢复方法,并分享一系列特别定制的预防措施,旨在使您的数字生活摆脱勒…...
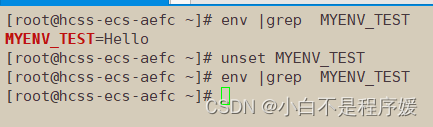
【Linux系统化学习】命令行参数 | 环境变量的再次理解
个人主页点击直达:小白不是程序媛 Linux专栏:Linux系统化学习 代码仓库:Gitee 目录 mian函数传参获取环境变量 手动添加环境变量 导出环境变量 environ获取环境变量 本地变量和环境变量的区别 Linux的命令分类 常规命令 内建命令 …...
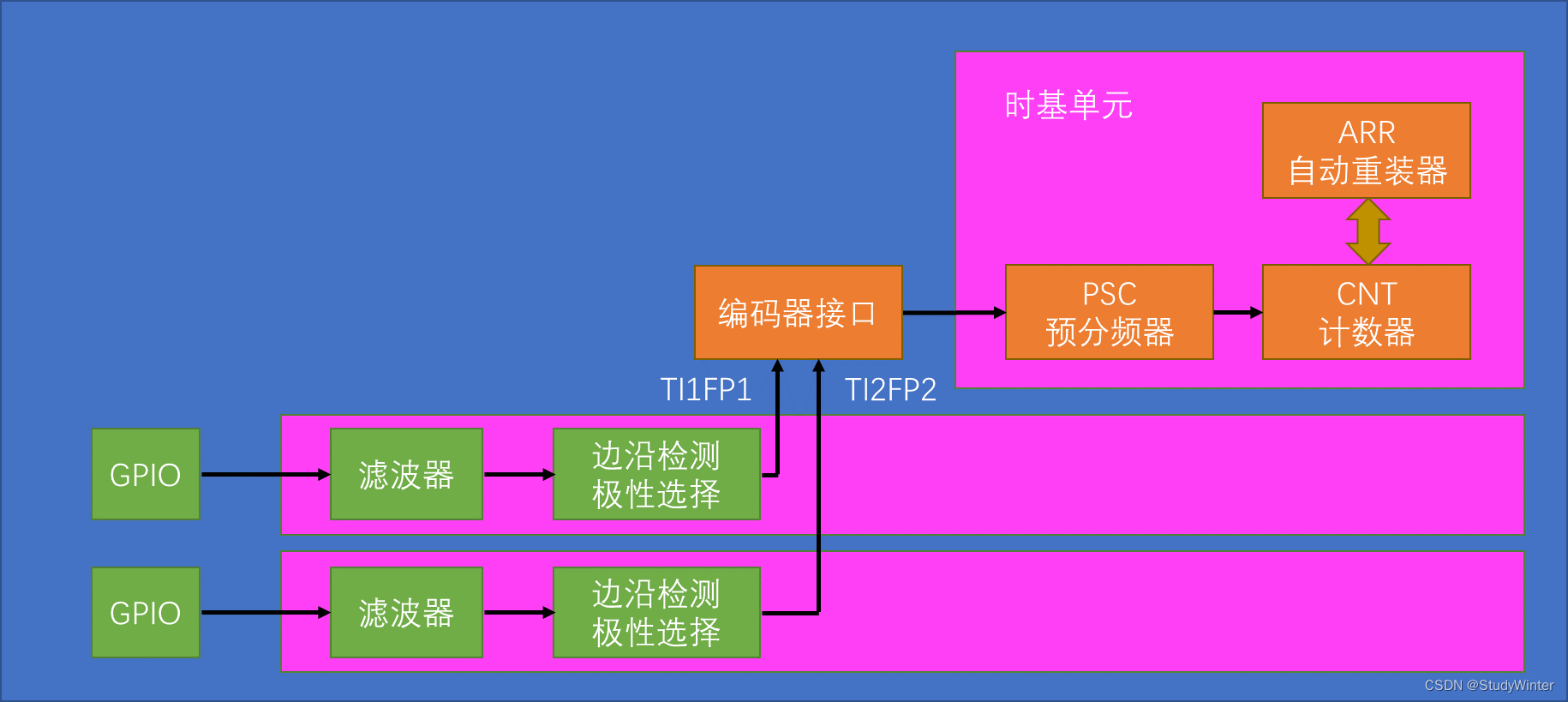
【STM32】TIM定时器编码器
1 编码器接口简介 Encoder Interface 编码器接口 编码器接口可接收增量(正交)编码器的信号,根据编码器旋转产生的正交信号脉冲,自动控制CNT自增或自减,从而指示编码器的位置、旋转方向和旋转速度 接收正交信号&#…...

力扣44题通配符匹配题解
44. 通配符匹配 - 力扣(LeetCode) 给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。* 可以匹配任意字符序列(包括空字符序列)。 …...
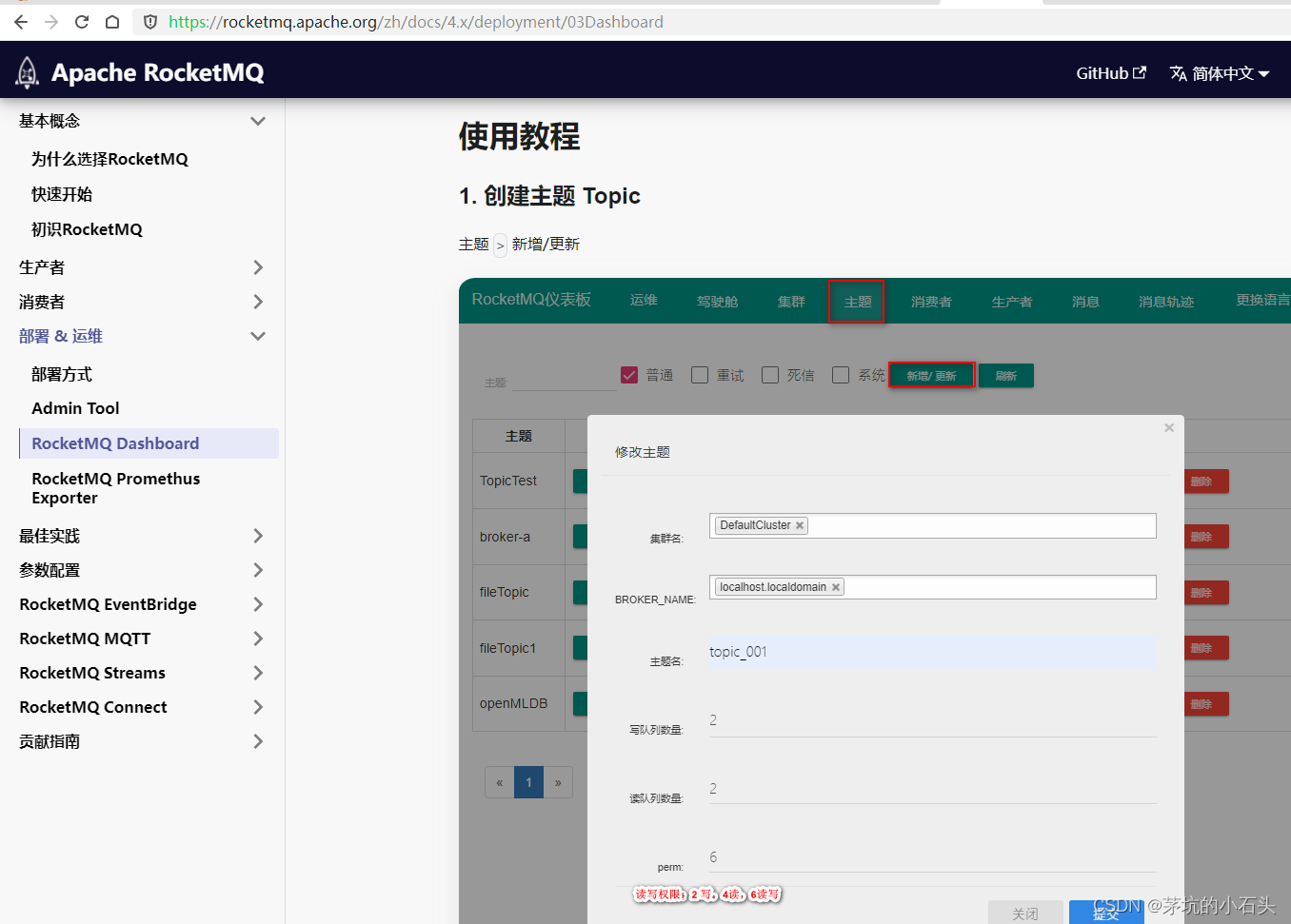
windows系统安装RocketMQ_dashboard
1.下载源码 按照官网说明下载源码 官网 官网文档 2.源码安装 2.1.① 编译rocketmq-dashboard 注释掉报错的maven插件frontend-maven-plugin、maven-antrun-plugin mvn clean package -Dmaven.test.skiptrue2.2.② 运行rocketmq-dashboard java -jar target/rocketmq-…...

ATECLOUD电源自动测试系统打破传统 助力新能源汽车电源测试
随着新能源汽车市场的逐步扩大,技术不断完善提升,新能源汽车测试变得越来越复杂,测试要求也越来越严格。作为新能源汽车的关键部件之一,电源为各个器件和整个电路提供稳定的电源,满足需求,确保新能源汽车的…...

Qt 5.9.1 MinGW 32位下,手把手搞定周立功CAN二次开发库的加载与配置
Qt 5.9.1 MinGW 32位环境下周立功CAN二次开发库的实战配置指南 在嵌入式开发领域,CAN总线通信一直是工业控制和汽车电子系统中的核心技术。对于使用Qt框架进行CAN通信开发的工程师来说,如何正确配置硬件厂商提供的二次开发库往往是项目起步阶段的第一道门…...

增程式电动汽车预测型能量管理策略【附算法】
✨ 长期致力于增程式电动汽车、能量管理策略、车速预测、广义回归神经网络、动态规划研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于AIC准则的自…...

WebPageTest:企业级分布式网页性能检测架构与优化实践
WebPageTest:企业级分布式网页性能检测架构与优化实践 【免费下载链接】WebPageTest Official repository for WebPageTest 项目地址: https://gitcode.com/gh_mirrors/we/WebPageTest WebPageTest作为全球领先的开源网页性能检测平台,为技术决策…...

排水管网可视化管理平台,免巡检、故障快速定位
城市排水管网线路长、节点多、覆盖范围广,传统人工巡检模式面临诸多痛点:巡检人员需步行逐一排查井盖、泵站、溢流口等关键设施,工作强度大、效率低,且难以保证巡检到位率和覆盖率。此外,人工无法全天候进行监管&#…...

Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁?
Adobe-GenP 3.0:为什么这款免费激活工具能让Adobe全家桶瞬间解锁? 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经因为Adobe Crea…...

拒绝“人肉搬砖”!实测AI Agent如何重塑制造企业供应链自动管理
【摘要】 站在2026年5月的技术交汇点,全球制造业正经历从“自动化”向“智能化”的深度跃迁。面对制造企业供应链管理中长期存在的系统围墙、数据孤岛及信创适配难等沉疴顽疾,传统的RPA工具与API集成方案已显疲态。本期「企服AI产品测评局」深度实测发现…...

如何用嘎嘎降AI处理土木工程论文:土木工程研究生毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理土木工程论文:土木工程研究生毕业论文降AI4.8元完整操作教程 关于土木工程论文降AI教程,有几个细节提前知道能少走很多弯路。 核心用嘎嘎降AI(www.aigcleaner.com),4.8元,达标率99.26%…...

初次使用Taotoken控制台管理账单与查看各模型消耗明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken控制台管理账单与查看各模型消耗明细 对于刚开始使用大模型服务的开发者或团队而言,清晰、透明地掌握…...

Play Integrity API Checker:快速检测Android设备安全性的完整指南
Play Integrity API Checker:快速检测Android设备安全性的完整指南 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-a…...

Android动态换肤框架深度解析:如何5分钟实现应用主题实时切换
Android动态换肤框架深度解析:如何5分钟实现应用主题实时切换 【免费下载链接】Android-Skin-Loader 一个通过动态加载本地皮肤包进行换肤的皮肤框架 项目地址: https://gitcode.com/gh_mirrors/an/Android-Skin-Loader 在Android应用开发中,主题…...