精选博客系列|将基于决策树的Ensemble方法用于边缘计算
在即将到来的边缘计算时代,越来越需要边缘设备执行本地快速训练和分类的能力。事实上,无论是手机上的健康应用程序、冰箱上的传感器还是扫地机器人上的摄像头,由于许多原因,例如需要快速响应时间、增强安全性、数据隐私,甚至考虑到盈利能力,通常都需要进行本地计算。
无论是以什么方式进行机器学习,对于此类设备来说,具有异构性、有限的连接和有限的硬件资源是一个持续存在的、我们必须解决的挑战。事实上,人们经常面临着矛盾的需求,边缘设备必须在本地执行大量的计算、存储和通信,同时还要遵守如有限的内存、网络连接和计算的资源限制。这通常是由于时间或功率限制以及增加的数据和可用信息量。
这里,我们重点讨论利用基于决策树的 Ensemble 方法进行计算和内存高效的本地(即设备上)训练和分类,这是处理表格数据的实际标准。
基于决策树的 Ensemble 方法
事实上,基于树的 Ensemble 方法,例如随机森林(RF)和 XGBoost,由于其健壮性、易用性和泛化性,经常用于对表格数据进行分类。反过来,分类任务通常用作许多应用域中的子例程,例如金融、欺诈检测、医疗保健和入侵检测。因此,这种方法的效率和精度与效用之间的权衡至关重要。
让我们特别关注随机森林和 XGBoost,并了解它们的优势:
随机森林可以说是最流行的 bagging 方法,它使用数据的随机子样本来生长每个决策树,从而生成不同且弱相关的树。然后,使用多数票确定分类。随机森林有几个优点,包括健壮性、快速训练、处理不平衡数据集的能力、嵌入式特征选择、处理缺失的、分类的和连续的特征,以及高级人工分析或法规要求的、任何时候的可解释性。
XGBoost 是一种著名且流行的 boosting 算法,它在每次迭代时都会生成一个小的决策树(例如,具有 8–32 个终端节点)。每个这样的树都是为了减少以前树的错误分类。XGBoost 分享了随机森林的大部分优点,并且由于其可控偏差,通常可以实现更高的精度。
然而,这些方法也带来了一些与资源相关的缺点:
随机森林往往受内存限制,分类速度较慢。此外,由于随机森林占用大量内存,因此通常无法部署在内存有限的边缘设备上,而这些设备通常需要执行分类任务。
XGBoost 模型通常比随机森林需要更少的内存,但它们是计算密集型的,导致训练速度较慢。
我们解决了随机森林和 XGBoost 的资源消耗缺点。特别的是,我们引入了一种新的混合方法,该方法继承了 bagging 和 boosting 方法的良好特性,具有可比较的机器学习性能,同时大大提高了资源效率。
数据集中的冗余
众所周知,机器学习模型的资源消耗与用于训练的数据集的大小高度相关。因此,减少数据集大小是可取的。因此,我们想提出以下问题:
数据集中的所有数据实例对于基于树的 ensemble 模型的训练是否同样重要?
如果没有,我们应该如何在训练期间区分数据实例以节省资源?这将如何影响分类?
事实上,数据集通常包含许多简单的(例如 90%)数据实例,因为它们很容易识别,因此很容易分类;以及罕见或更独特的数据实例,因此更难分类。
直观地说,如果在培训之前可以进行这种区分,那么应该能够利用这些知识来节省资源,而不会对准确性产生重大影响。其中一个想法是在培训期间使用较少的 “简单” 数据实例。面临的挑战是如何制定这样的计划,并以有效的方式这样做。
RADE–资源高效的异常检测模型
数据集只有两个类,其中大多数实例是正常的或良性的(例如 99%)。
RADE 以以下方式利用上述观察结果:它首先使用整个数据集构建一个小(粗粒度)模型。然后,它使用该模型对用于训练的所有数据实例进行分类。正确分类且具有高度可信度的实例被标记为简单实例(通常是大多数正常实例),而所有其他实例都被标记为困难实例(通常为大多数异常实例)。
如图所示,RADE 引入了一种高级体系结构,只要粗粒度模型及其分类提供了有意义的分类置信水平,就可以与不同的分类模型一起使用。
直观地说,由于粗粒度模型足以正确分类简单的查询,所以我们只剩下困难查询。利用这些,我们构建了两个专家(细粒度)模型,用于处理与粗粒度模型的分类结果有关的两种不同情况:细粒度模型 1 负责(低置信度)正常分类和细粒度模型 2 用于(低置信度)异常分类。这些模型可能具有比粗粒度模型更大的内存占用需求,但明显低于基于整体的树模型。
训练效率
如前所述,RADE 分两个阶段进行训练。首先,使用整个数据集训练粗粒度模型。由于我们使用的是一个小模型,所以这个训练阶段相对较快。然后,我们使用粗粒度模型对整个训练数据集进行分类,并根据所得到的分类和置信度,生成两个数据子集用于训练细粒度模型。由于我们只使用训练数据的子集(例如 10%)训练每个细粒度模型,所以这个训练阶段也相对较快。
分类效率
RADE 的分类也有两个阶段。首先,根据粗粒度模型对实例进行分类。如果得到的分类置信度较高(例如 0.9),则完成分类。否则,根据粗粒度模型分类结果,由其中一个细粒度模型转发查询以进行重新分类。这意味着 RADE 的分类时间等于仅由粗粒度模型提供服务的分类,以及由粗粒度和细粒度模型提供的分类时间的加权平均值。直觉上,因为目的是为了只通过粗粒度模型(例如 90%)服务大多数查询,平均分类时间预计将比标准的整体模型显著改进。
Duet–资源高效的多类分类模型
RADE 是为二进制分类设计的,因此使用两个细粒度模型。就多类分类用例而言,扩展 RADE 的体系结构并不是一个可扩展的解决方案,因为它需要 K 类的 K 个细粒度模型,因此需要一个新的体系结构。
为此,我们开发了 Duet。Duet 遵循 RADE 的原则,即使用粗粒度模型,该模型在整个数据集上经过训练,并对简单的查询进行分类。然而,与 RADE 不同,Duet 只使用单个细粒度分类器,该分类器在训练数据集的子集上进行训练,并对困难(低置信度)查询进行分类。
Duet 的高级体系结构如图所示。从本质上讲,它使用了两个分类器:一个小型 bagging 分类器(随机森林),提供有意义的分类置信度、受控方差和内存限制,另一个 boosting 分类器(XGBoost),提供受控偏差和计算限制。总的来说,与单例分类器相比,Duet 引入了一种不同且通常更好的系统 / 机器学习性能的权衡。
Duet 的主要问题是如何确定 boosting 分类器的训练数据子集。
在这种情况下,使用 RADE 中的置信度指标是不够的,因为我们有一个多维问题。因此,我们使用类概率分布向量(通过粗粒度模型)来确定实例对训练过程的重要性。
对于六个类别的分类任务,考虑两个具有相同(第一)分类置信度的分类结果。第一个在两个类别上的概率(几乎)相等(例如 [0.5,0.5,0,0,0,0]),第二个在正确类别上概率较高,而在所有剩余类别上概率低得多(例如 [0.5,0.1,0.1,0.1,0.1,0.1])。显然,第一个查询比较困难,可能更有利于增强分类器的训练。
为了捕获此属性,我们定义了一个新的度量标准–可预测性这是由欧几里得距离函数给出的,该函数测量得到的类概率分布向量相对于实例的真实标签与完美分布向量之间的距离。完美分布向量在正确标签(即类)中的概率应为 1。
请注意,可预测性是训练过的 bagging 分类器和训练数据集的具体度量,因此是 Duet 训练过程中的一个集成步骤。此外,使用可预测性不同于仅依赖于数据集属性的采样方法(例如,分层采样,它保留了每个类的实例百分比)。
进一步的潜力
上述设计原则可能适用于其他机器学习领域。虽然 Duet 主要使用可预测性度量来降低训练和分类过程的计算成本,但可以使用可预测度度量来减少训练数据集的大小,从而降低存储和通信成本。
此外,RADE 和 Duet 还可能适用于分布式学习。例如,参与方可以联合训练一个粗粒度模型,然后使用该模型从本地数据集中选择子集,最后使用这些子集训练全局细粒度模型。
这里的挑战是确定参与方选择其子集的标准。例如,一种高级方法是使用安全计算来收集有关全局训练数据的一些统计信息。这样的统计数据可能会使每个参与者选择更好的子集,总的来说,对于细粒度模型的分布式训练,这样有更高的训练价值。
内容来源|公众号:VMware 中国研发中心
相关文章:

精选博客系列|将基于决策树的Ensemble方法用于边缘计算
在即将到来的边缘计算时代,越来越需要边缘设备执行本地快速训练和分类的能力。事实上,无论是手机上的健康应用程序、冰箱上的传感器还是扫地机器人上的摄像头,由于许多原因,例如需要快速响应时间、增强安全性、数据隐私࿰…...
JS混淆加密:Eval的未公开用法
JavaScript奇技淫巧:Eval的未公开用法 作者:http://JShaman.com w2sft,转载请保留此信息很多人都知道,Eval是用来执行JS代码的,可以执行运算、可以输出结果。 但它还有一种未公开的用途,想必很少有人用过。…...
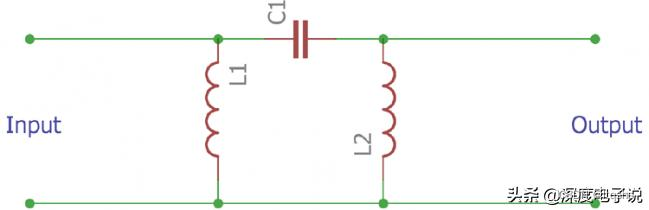
π型滤波器 计算_π型滤波电路
滤波器在功率和音频电子中常用于滤除不必要的频率。而电路设计中,基于不同应用有着许多不同种类的滤波器,但它们的基本理念都是一致的,那就是移除不必要的信号。所有滤波器都可以被分为两类,有源滤波器和无源滤波器。有源滤波器用…...
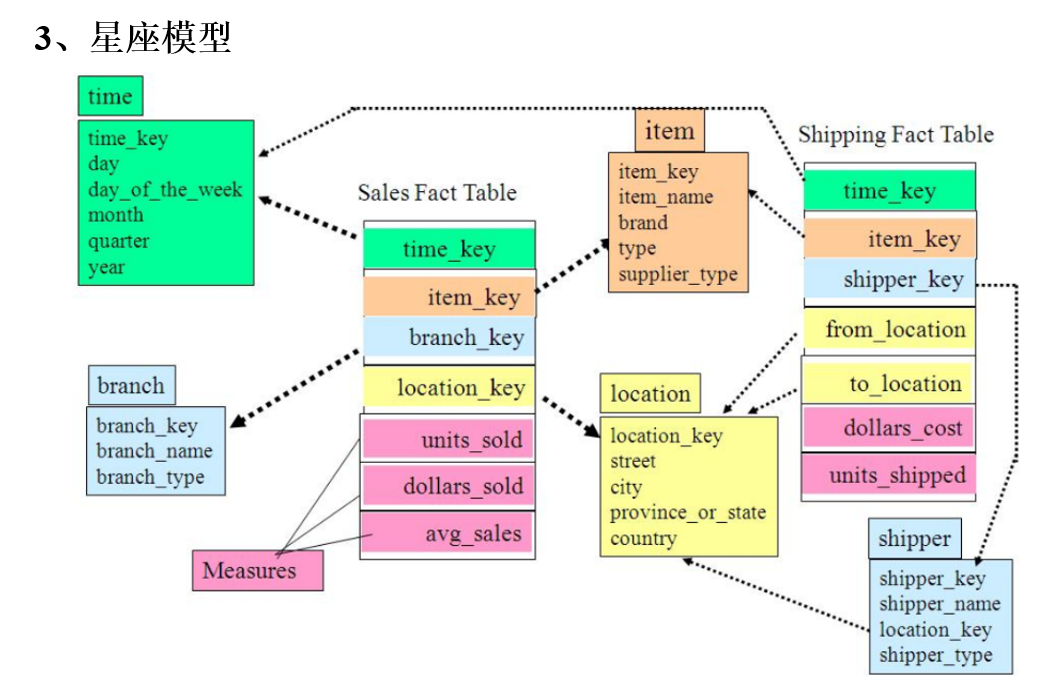
大数据常见术语
大数据常见术语一览 主要内容包含以下(收藏,转发给你身边的朋友) 雪花模型、星型模型和星座模型 事实表 维度表 上钻与下钻 维度退化 数据湖 UV与PV 画像 ETL 机器学习 大数据杀熟 SKU与SPU 即席查询 数据湖 数据中台 ODS,DWD&…...

带你了解“函数递归”
目录 1. 什么是递归? 2. 函数递归的必要条件 2.1 接收一个整型值(无符号),按照顺序打印它的每一位。 代码如下: 2.2 编写一个函数,不用临时变量求字符串长度 代码如下: 2.3 递归与迭代 …...
网络资源面经2
文章目录Kafka 原理,数据怎么平分到消费者生产者分区消费者分区Flume HDFS Sink 小文件处理Flink 与 Spark Streaming 的差异,具体效果Spark 背压机制具体实现原理Yarn 调度策略Spark Streaming消费方式及区别Zookeeper 怎么避免脑裂,什么是脑…...
4年经验来面试20K的测试岗,一问三不知,我还真不如去招应届生。
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。看简历很多都是4年工作经验,但面试…...

K8S搭建NACOS集群踩坑问题
一、NACOS容器启动成功无法访问现象描述:通过K8S的statefulset启动,通过NodePort暴露不能在外网访问,只能在MASTER主节点访问。yaml配置:apiVersion: apps/v1 kind: StatefulSet metadata:name: nacos-${parameters.nameSpace}-dm…...

怎么避免计算机SCI论文的重复率过高? - 易智编译EaseEditing
论文成稿前 在撰写阶段就避免重复:在撰写阶段就避免文章中的重复内容,可以减少后期修改的工作量。 在写作前,可以制定良好的计划和大纲,规划好文章的结构和内容,从而减少重复内容。 加强对相关文献的阅读 为了避免自己…...

uni-app路由拦截
新建一个auth.js /** * description 权限存储函数 */ const authorizationKey Authorization export function getAuthorization() { return uni.getStorageSync(authorizationKey) } export function setAuthorization(authorization) { return uni.setStorageSync(aut…...
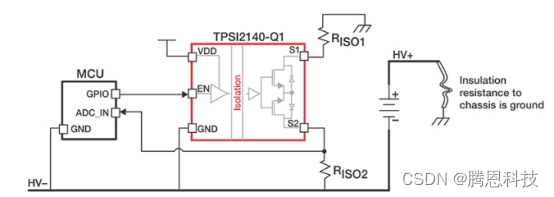
如何使用固态继电器实现更高可靠性的隔离和更小的解决方案尺寸
自晶体管发明之前,继电器就已被用作开关。从低压信号安全控制高压系统的能力,如隔离电阻监控,对于许多汽车系统的开发是必要的。虽然机电继电器和接触器的技术多年来有所改进,但设计人员要实现其终身可靠性和快速开关速度以及低噪…...

【YOLOv8/YOLOv7/YOLOv5系列算法改进NO.56】引入Contextual Transformer模块(sci期刊创新点之一)
文章目录前言一、解决问题二、基本原理三、添加方法四、总结前言 作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列…...

深圳大学计软《面向对象的程序设计》实验3 指针2
A. 月份查询(指针数组) 题目描述 已知每个月份的英文单词如下,要求创建一个指针数组,数组中的每个指针指向一个月份的英文字符串,要求根据输入的月份数字输出相应的英文单词 1月 January 2月 February 3月 March …...

【基于机器学习的推荐系统项目实战-2】项目介绍与技术选型
本节目录一、项目介绍1.1 采用的数据源1.2 Concrec架构技术选型1.3 Sprak介绍1.4 Flink1.5 TensorFlow一、项目介绍 1.1 采用的数据源 Kaggle Anime Recommendations Dataset。 其中的动漫数据源自myanimelist.net。 1.2 Concrec架构技术选型 数据预处理模块:汇总…...

对称锥规划:锥与对称锥
文章目录对称锥规划:锥与对称锥锥的几何形状常用的指向锥Nonnegative Orthant二阶锥半定锥对称锥对称锥的平方操作对称锥的谱分解对称锥的自身对偶性二阶锥规划SOCP参考文献对称锥规划:锥与对称锥 本文主要讲锥与对称锥的一些基本概念。 基础预备&…...

4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
情感分析任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…...
算法拾遗二十五之暴力递归到动态规划五
算法拾遗二十七之暴力递归到动态规划七题目一【数组累加和最小的】题目二什么暴力递归可以继续优化暴力递归和动态规划的关系面试题和动态规划的关系如何找到某个问题的动态规划方式面试中设计暴力递归的原则知道了暴力递归的原则 然后设计常见的四种尝试模型如何分析有没有重复…...

Linux进程的创建结束类系统调用总结
tags: Linux OS Syscall C 写在前面 总结一下Linux系统的进程创建/终止/等待等系统调用, 参考: Linux/Unix系统编程手册. 下面主要给出例子, 关于函数原型可以参考书中或者man 2 syscall(例如man 2 fork). 测试环境: Ubuntu 20.04 x86_64 gcc-9 进程创建: fork() 用于创建…...

Git分支的合并策略有哪些?Merge和Rebase有什么区别?关于Merge和Rebase的使用建议
Git分支的合并策略有哪些?Merge和Rebase有什么区别?关于Merge和Rebase的使用建议1. 关于Git的一些基本原理1.1 Git的工作流程原理2. Git的分支合并方式浅析2.1 分支是什么2.2 分支的合并策略2.2.1 Three-way-merge(三向合并原理)2…...
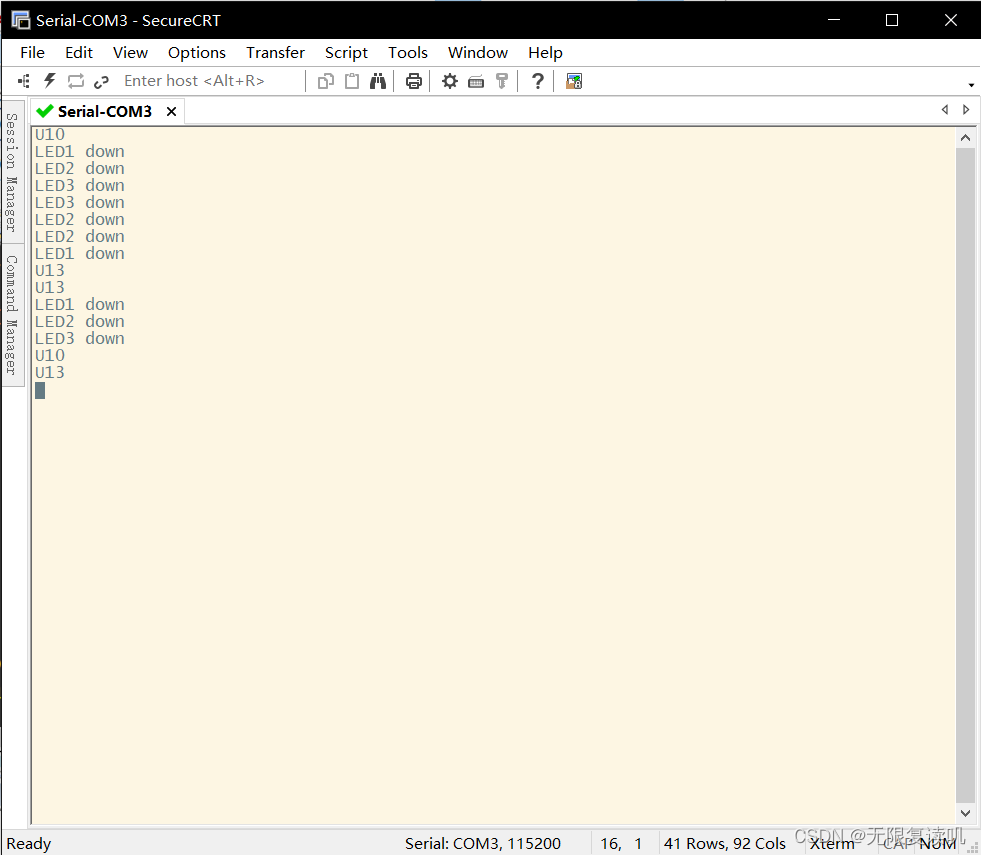
2022-2-23作业
一、通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作 1.例如在串口输入led1on,开饭led1灯点亮 2.例如在串口输入led1off,开饭led1灯熄灭 3.例如在串口输入led2on,开饭led2灯点亮 4.例如在串口输入led2off,开饭led2灯熄灭 5.例如在串口输…...

PiliPlus:用Flutter重新定义你的B站观影体验
PiliPlus:用Flutter重新定义你的B站观影体验 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 在众多视频平台中,B站以其独特的社区文化和丰富内容生态深受用户喜爱。然而,官方客户端的一些…...

初次使用Taotoken平台从注册到完成API调用的全程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken平台从注册到完成API调用的全程指引 对于初次接触大模型API的开发者而言,从注册平台到成功发出第一个…...

基于LangGraph与MCP构建Farcaster AI智能体:从架构到DeFi集成实战
1. 项目概述:一个面向Farcaster生态的AI智能体最近在探索SocialFi和AI Agent的结合点,发现了一个挺有意思的项目:oceantruong/farcaster-agent。简单来说,这是一个专门为Farcaster社交网络设计的AI智能体框架。Farcaster本身是一个…...

龙为权,凰为心:凰标守住文化最柔软的底线@凤凰标志
龙为权凰为心 中国文艺生态的双轨平衡宣言秩序权力与创作初心,一刚一柔, 如日月轮值,缺一不可。 龙标掌「权」,凰标守「心」, 双轨并行,方可让文化既筋骨强健,又血肉温润。一、龙标:…...
)
别再只点灯了!用ESP32和WebServer库做个智能家居控制面板原型(附完整代码)
用ESP32打造智能家居控制面板:从网页控制到硬件交互实战 想象一下,清晨醒来无需下床,轻点手机就能打开窗帘、调节灯光;离家时一键关闭所有电器,还能实时查看家中温湿度——这些看似未来的场景,如今用一块ES…...

高性能ai编程工具zed配置deepseek 开启ai agent对话及代码补全
配置ai助手 进入设置页配置deepseek apikey配置代码补全 进入setting->edit pridic -> config.json文件。替换下面内容{"show_edit_predictions": true,// ✅ 代码补全核心配置(关键修改)"edit_predictions": {"provide…...

免费在线PPT制作工具PPTist:浏览器中的专业演示文稿创作平台
免费在线PPT制作工具PPTist:浏览器中的专业演示文稿创作平台 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allow…...

AI和大模型——拟合
一、拟合 Fitting,中文翻译成拟合,这个翻译还是比较贴切的。怎么理解拟合呢?其实非常好理解,如果接受过九年义务教育,基本都有极限或微积分的概念。有没有想起过积分中用高低不等的小矩形来拼凑出曲线面的面积,那个过程…...

普遍认为赠送福利越多客户留存越高,编程统计福利投入,客户留存数据过度福利,会造成客户贪婪流失率上升。
“福利投入强度与客户留存的非线性关系分析” 为主题。一、实际应用场景描述(Business Context)在 SaaS、电商、会员制平台、在线教育等商业场景中,赠送福利(优惠券、积分、试用权益、赠品等)被广泛用于:- …...

开源贡献者如何优雅管理上游补丁:隔离、消毒与自动化工作流实践
1. 项目概述:一个开源贡献者的“清洁”工作流如果你和我一样,长期维护着一些开源项目,同时又基于这些项目进行深度定制和二次开发,那你一定遇到过这个经典难题:如何优雅地管理那些你为上游项目(即原始开源项…...