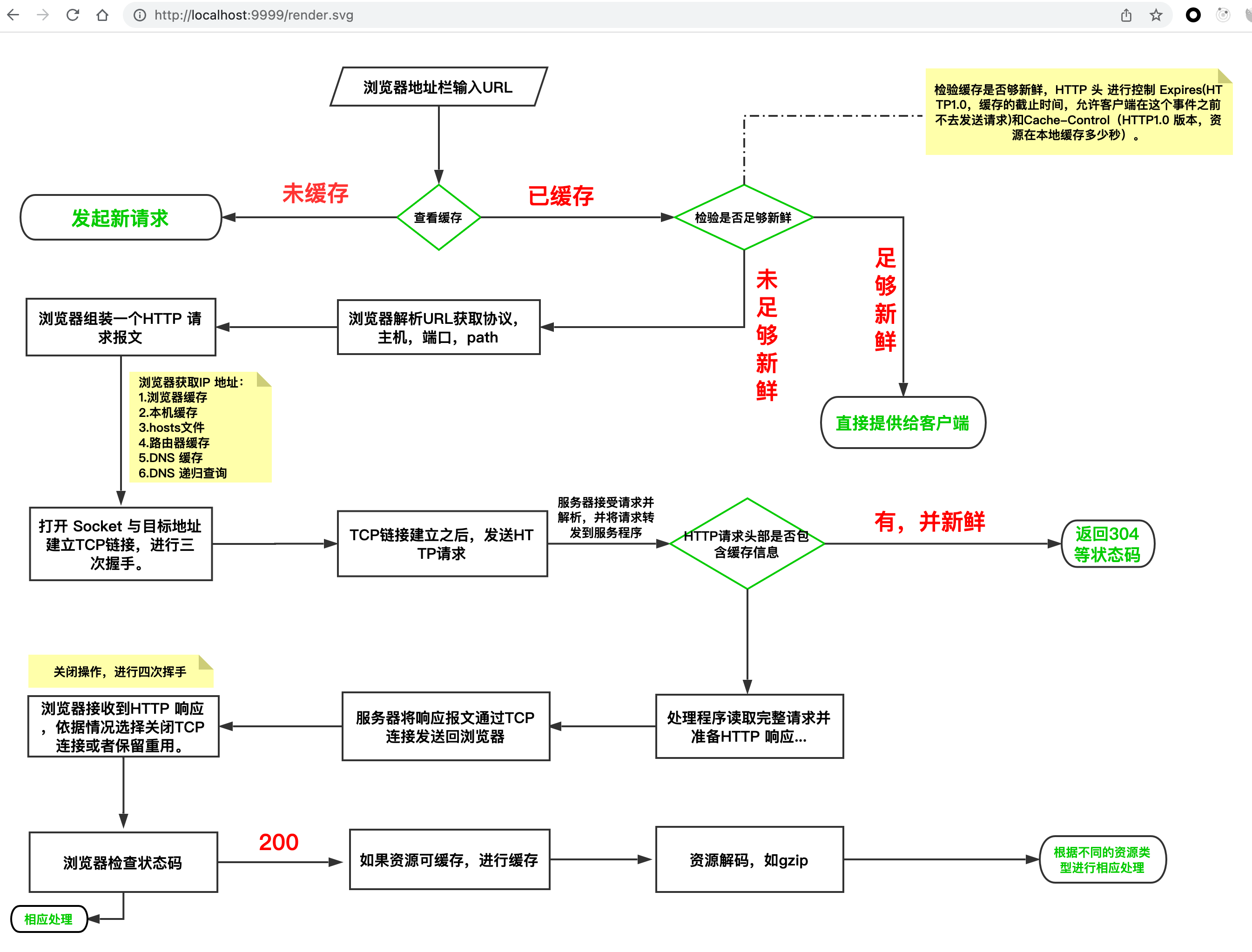
2023_Spark_实验二十九:Flume配置KafkaSink
实验目的:掌握Flume采集数据发送到Kafka的方法
实验方法:通过配置Flume的KafkaSink采集数据到Kafka中
实验步骤:
一、明确日志采集方式
一般Flume采集日志source有两种方式:
1.Exec类型的Source
可以将命令产生的输出作为源,如:
a1.sources.r1.type = exec
a1.sources.r1.command = ping 10.3.1.227 //此处输入命令
2.Spooling Directory类型的 Source
将指定的文件加入到“自动搜集 ”目录中。flume会持续监听这个目录,把文件当做source来处理。注意:一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件,如果有,flume也会报错。
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/work/data
向指定的文件目录下传送一个日志文件,发现flume的控制台打印相关的信息;此外,待收集的文件,会追加一个后缀:completed,表示已处理完。
3.确定采集策略:
采用exec方式采集数据
如果采用spooldir的方式来监控log文件夹,flume会采集log数据,flume会不断修改文件名,导致重复。
所以使用exec命令行的方式,通过tail -F *.log命令比较好!
注意: -F根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪。 而-f根据文件的nodeid即文件描述符进行追踪,当文件改名或被删除,追踪停止 。
二、配置KafkaSink
Flume版本多,网上教程多,版本之间不兼容,推荐大家以Flume官网为准。

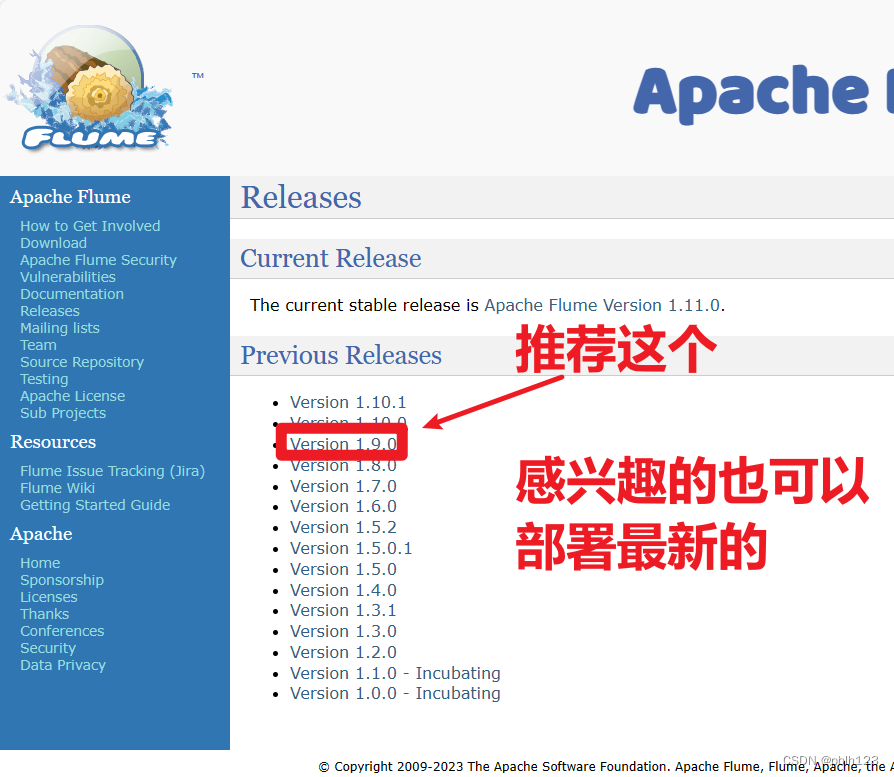

Exec Source
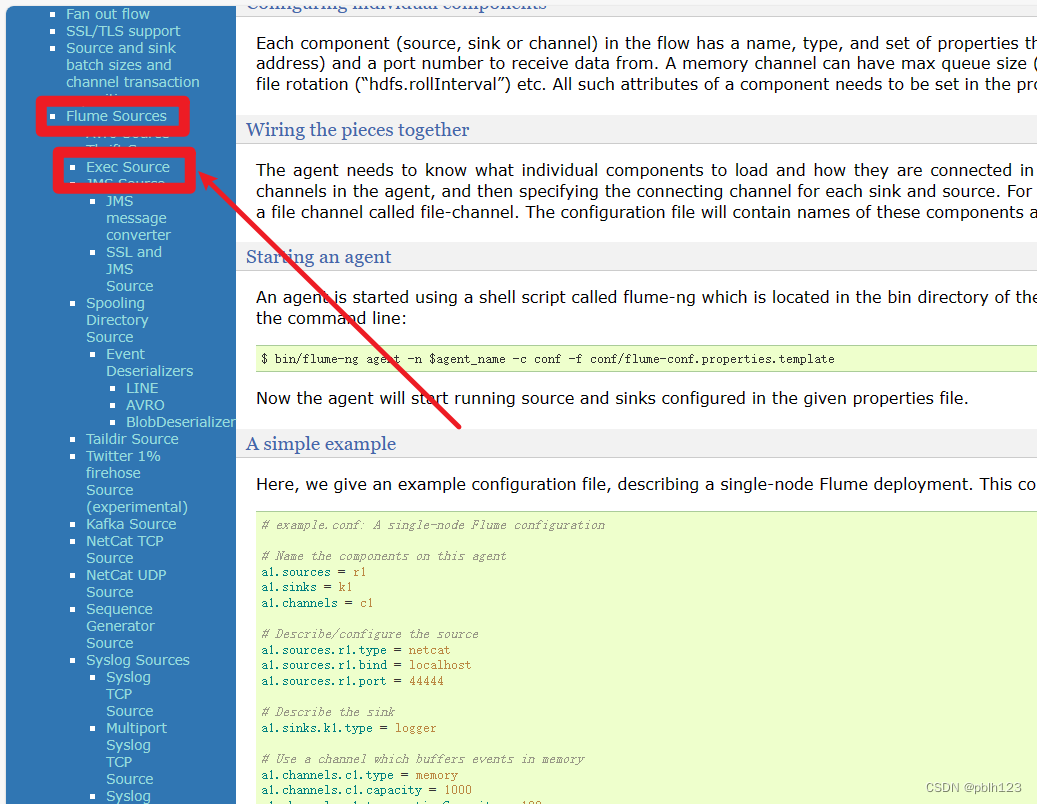

Kafka Sink

三、配置Flume配置文件
1. 拷贝一份配置文件模板
cp flume-conf.properties.template kafka.conf
2. 编辑kafka.conf
kafka.conf编辑内容如下
# 定义a2配置文件中每个组件的名称
a2.sources = execSrc
a2.channels = memoryChannel
a2.sinks = loggerSink# 配置source组件
# For each one of the sources, the type is defined
a2.sources.execSrc.type = exec
a2.sources.execSrc.command = tail -F /home/hadoop/scripts/realtime/realdata.log# 配置sink组件
# Each sink's type must be defined
a2.sinks.loggerSink.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.loggerSink.kafka.topic = RealDataTopic
a2.sinks.loggerSink.kafka.bootstrap.servers = hd1:9092
a2.sinks.loggerSink.kafka.flumeBatchSize = 20
a2.sinks.loggerSink.kafka.producer.acks = 1
a2.sinks.loggerSink.kafka.producer.linger.ms = 1
a2.sinks.loggerSink.kafka.producer.compression.type = snappy# 配置缓存方式
# Each channel's type is defined.
a2.channels.memoryChannel.type = memory
a2.channels.memoryChannel.capacity = 1000
a2.channels.memoryChannel.transactionCapacity = 100# 配置source channel sink之间的连接关系
# The channel can be defined as follows.
a2.sources.execSrc.channels = memoryChannel
a2.sinks.loggerSink.channels = memoryChannel3. 启动测试
/opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent -c conf -f /opt/module/apache-flume-1.9.0-bin/conf/kafka.conf -n a2 -Dflume.root.logger=INFO,console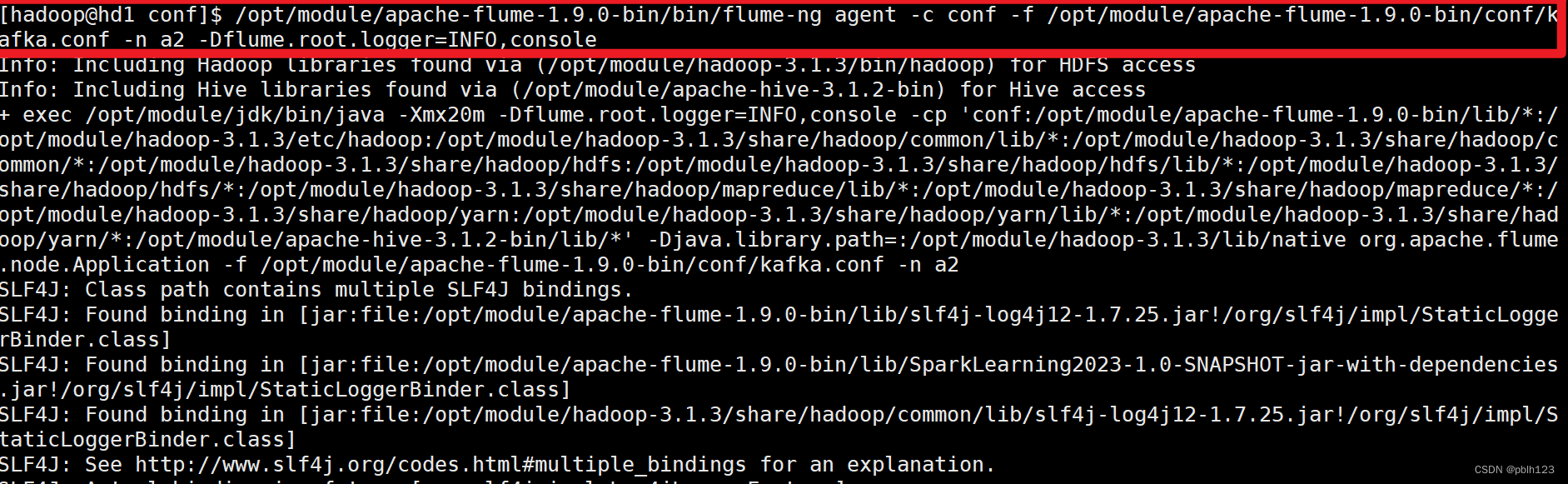
实验结果:配置kafkaSink成功,配置source为exec读取shell脚本模拟产生的实时数据
相关文章:
2023_Spark_实验二十九:Flume配置KafkaSink
实验目的:掌握Flume采集数据发送到Kafka的方法 实验方法:通过配置Flume的KafkaSink采集数据到Kafka中 实验步骤: 一、明确日志采集方式 一般Flume采集日志source有两种方式: 1.Exec类型的Source 可以将命令产生的输出作为源&…...
Koa.js 入门手册:洋葱模型插件机制详解以及常用中间件
前言 Nodejs 提供了 http 能力,我们通过如下代码可以快速创建一个http server服务 const http require(http);http.createServer((req, res) > {res.write(hello\n);res.end();}).listen(3000);使用nodejs提供的原生能力启动一个http server并不麻烦ÿ…...

零信任 SASE 办公安全解决方案:提升企业网络安全与灵活性
零信任 SASE(Secure Access Service Edge)办公安全解决方案为企业带来了许多好处,相较于以前的解决方案有明显差异。这个方案的出现是为了应对企业面临的新的网络安全挑战和远程办公的需求。 1、统一的网络安全管理:SASE 将网络…...

【提示工程】Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
解决问题 探索大语言模型解决推理问题的能力。从头训练或微调模型,需要创建大量的高质量含中间步骤的数据集,成本过大。 相关工作 1、使用中间步骤来解决推理问题 (1)使用自然语言通过一系列中间步骤解决数学应用题 ࿰…...

AWS解决方案架构师学习与备考
系列文章目录 送书第一期 《用户画像:平台构建与业务实践》 送书活动之抽奖工具的打造 《获取博客评论用户抽取幸运中奖者》 送书第二期 《Spring Cloud Alibaba核心技术与实战案例》 送书第三期 《深入浅出Java虚拟机》 送书第四期 《AI时代项目经理成长之道》 …...
如何搭建企业管理系统Odoo并远程访问管理界面【内网穿透】
文章目录 前言1. 下载安装Odoo:2. 实现公网访问Odoo本地系统:3. 固定域名访问Odoo本地系统 前言 Odoo是全球流行的开源企业管理套件,是一个一站式全功能ERP及电商平台。 开源性质:Odoo是一个开源的ERP软件,这意味着企…...

【Git】git常用问题汇总
1. gitlab如何打tag gitlab打tag的目的 git作为代码管理工具已经使用的越来越多了。而且一般开发人员在Dev分支下进行开发。但是当代码需要发布到测试环境时,需要将代码先合并到master,然后打个tag ,类似于SVN中tag处理。这样便于后期代码向…...

2024免费mac苹果电脑系统电脑管家CleanMyMac X
macOS已经成为最受欢迎的桌面操作系统之一,它提供了直观、简洁的用户界面,使用户可以轻松使用和管理系统。macOS拥有丰富的应用程序生态系统;还可以与其他苹果产品和服务紧密协作,如iPhone、iPad,用户可以通过iCloud同…...

ElasticSearch详细搭建以及常见错误high disk watermark [ES系列] - 第497篇
导读 历史文章(文章累计490) 《国内最全的Spring Boot系列之一》 《国内最全的Spring Boot系列之二》 《国内最全的Spring Boot系列之三》 《国内最全的Spring Boot系列之四》 《国内最全的Spring Boot系列之五》 《国内最全的Spring Boot系列之六…...
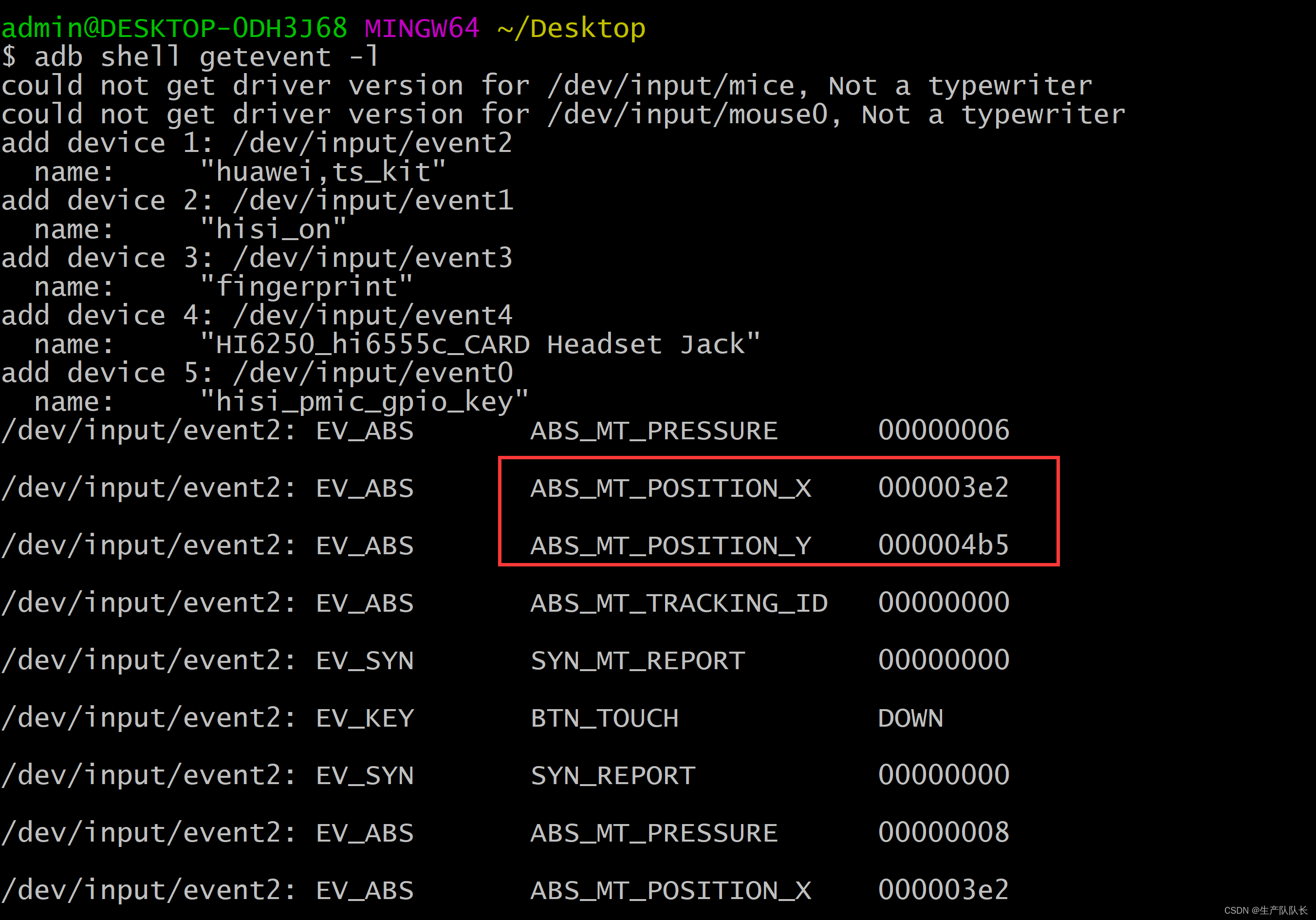
ADB:获取坐标
命令: adb shell getevent | grep -e "0035" -e "0036" adb shell getevent -l | grep -e "0035" -e "0036" 这一条正确,但是,grep给过滤了,导致没有输出 getevent -c 10 //输出10条信息…...

关于“Python”的核心知识点整理大全27
目录 10.5 小结 第11 章 测试代码 11.1 测试函数 name_function.py 函数get_formatted_name()将名和姓合并成姓名,在名和姓之间加上一个空格,并将它们的 首字母都大写,再返回结果。为核实get_formatted_name()像期望的那样工…...
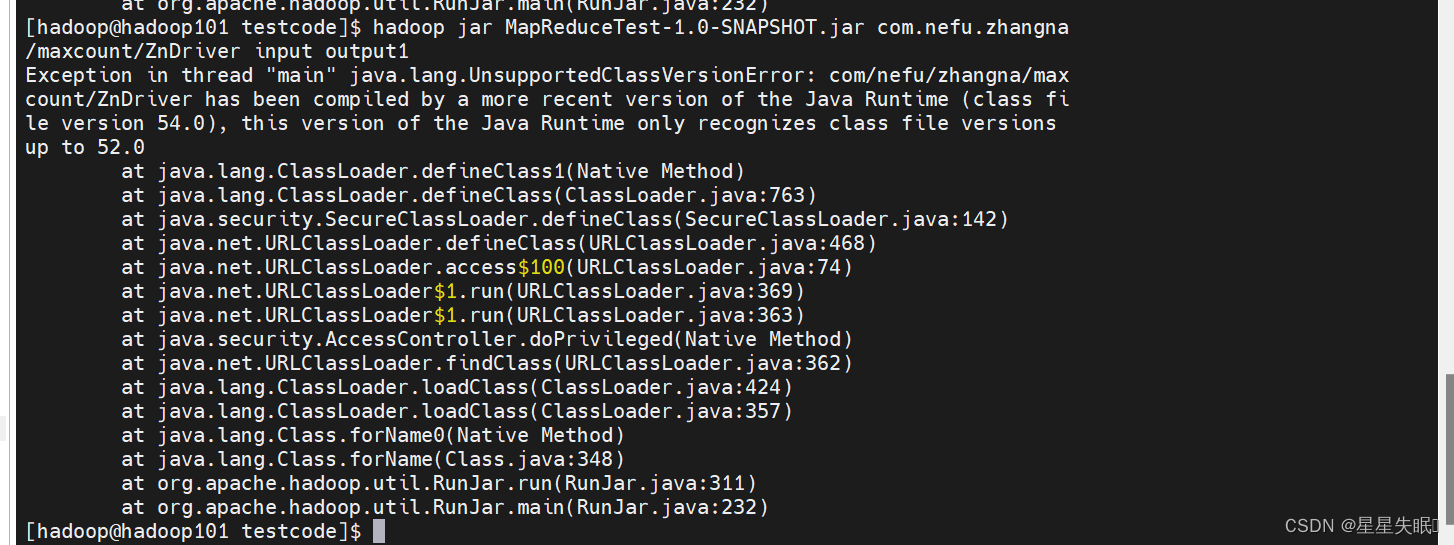
实验三 MapReduce编程
实验目的: 1.掌握MapReduce的基本编程流程; 2.掌握MapReduce序列化的使用; 实验内容: 一、在本地创建名为MapReduceTest的Maven工程,在pom.xml中引入相关依赖包,配置log4j.properties文件,搭…...
element组件库的日期选择器如何限制?
本次项目中涉及到根据日期查找出来的数据进行调整,所以修改的数据必须是查找范围内的数据.需要对调整数据的日期进行限制,效果如下: 首先我们使用了element 组件库的日期选择器,其中灌完介绍, picker-options中函数disabledDate可以设置禁用状态,代码如下: <el-date-pickerv…...

QSqlQueryModel
QSqlQueryModel 是 Qt 框架中的一个模型类,用于在 Qt 的视图组件(如 QTableView、QListView)中显示数据库查询结果。 QSqlQueryModel 继承自 QAbstractTableModel,它通过执行 SQL 查询并将结果存储在内部数据结构中,提…...
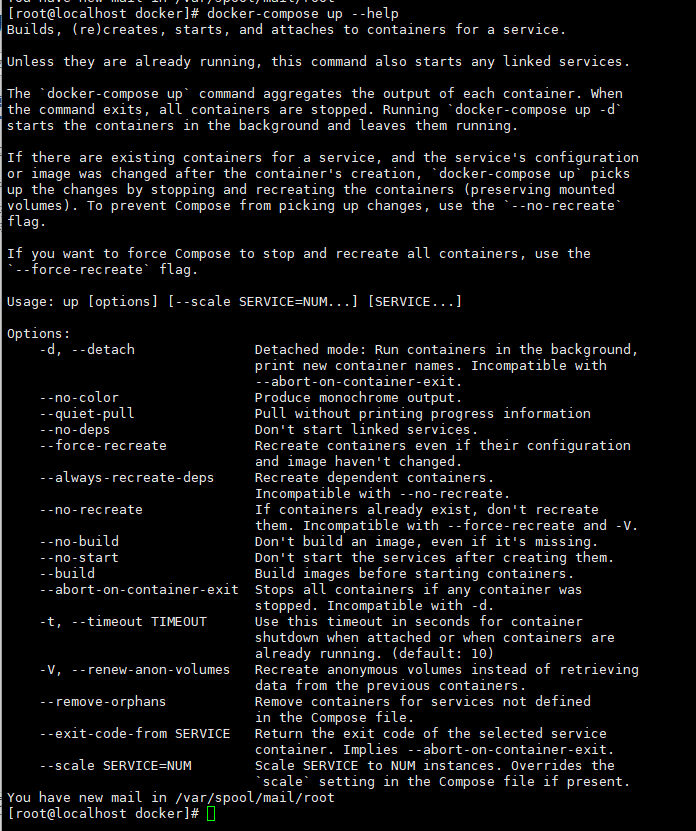
docker-compose介绍和用法
docker-compose介绍和用法详解 1、docker-compose介绍2、docker-compose build3、docker-compose down4、docker-compose up -d 1、docker-compose介绍 Docker Compose是一个用于快速配置多个Docker容器的工具。它是一个定义和运行多容器的Docker应用工具,通过YAML…...

Mac下ERROR: Cannot connect to the Docker daemon
解决Mac下ERROR: Cannot connect to the Docker daemon at unix:///Users/qq/.orbstack/run/docker.sock. Is the docker daemon running? 在Mac系统的中, 如果实际已经安装docker并且已经启动了. 但执行 docker info 时 报错: ERROR: Cannot connect to the Docker daemon …...
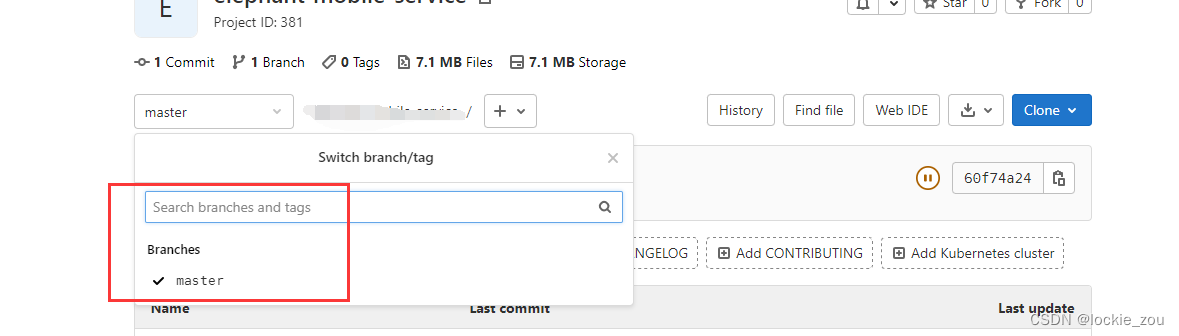
本地项目添加到gitlab命令操作
gitlab上面创建一个跟项目名同名的文件夹 创建文件夹,填写信息 添加readme文档,先保存下创建的文件夹 回到项目,复制项目的git 地址 然后进入到本地项目的文件夹,如d:/workspace/spring-demo,右键打开git bash弹框 命令…...
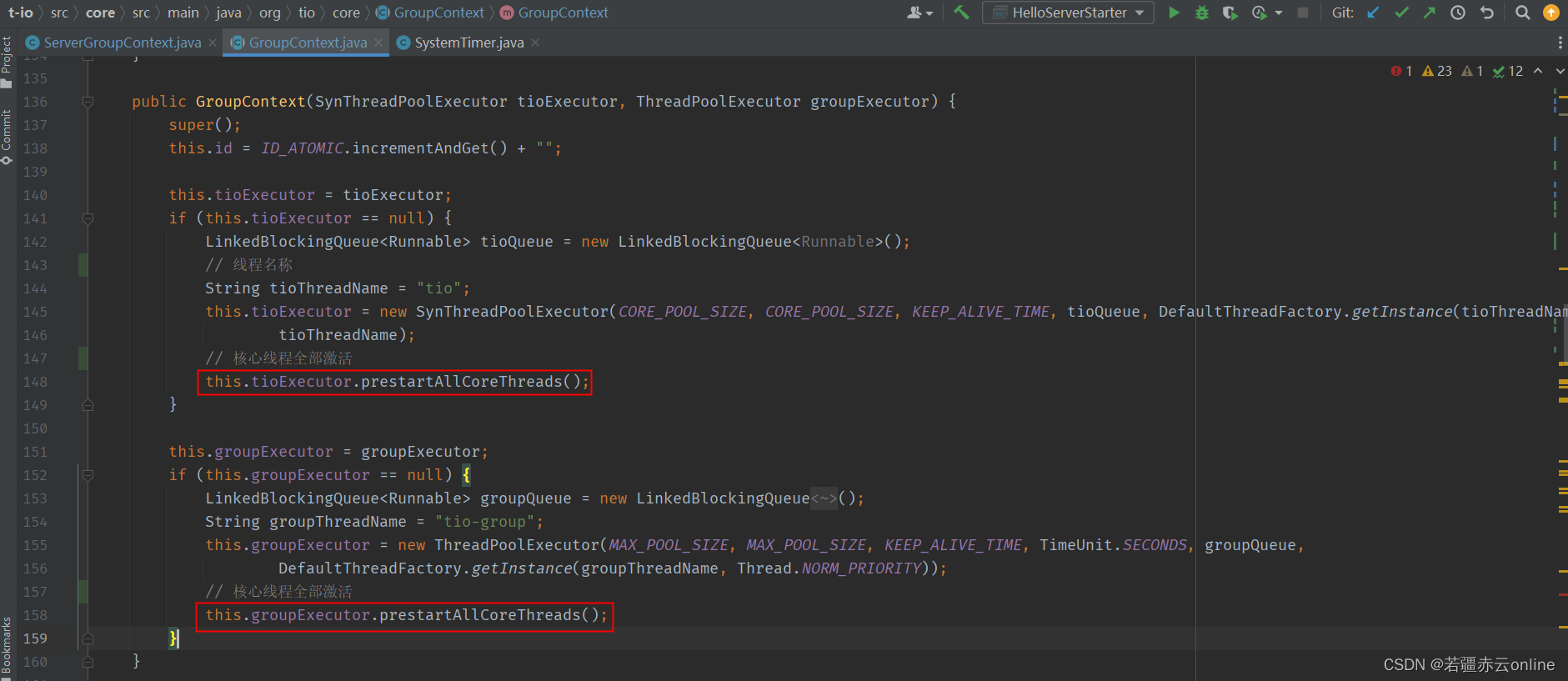
t-io 程序执行后,jvm不退出的原因
基于t-io 1.7.3 版本分析源码 1、设定当前时间,每10毫秒执行一次 (非守护线程) 2、对应线程池的核心线程在AioServer启动时全部激活,并且添加空任务到阻塞队列,让核心线程(非守护线程)一直存活...

Vue3使用Three.js导入gltf模型并解决模型为黑色的问题
背景 如今各类数字孪生场景对三维可视化的需求持续旺盛,因为它们可以用来创建数字化的双胞胎,即现实世界的物体或系统的数字化副本。这种技术在工业、建筑、医疗保健和物联网等领域有着广泛的应用,可以帮助人们更好地理解和管理现实世界的事…...

说一下 jvm 有哪些垃圾回收算法?
说一下 jvm 有哪些垃圾回收算法? 一.对象是否已死算法 1.引用计数器算法 2.可达性分析算法 二.GC算法 1.标记清除算法 如果对象被标记后进行清除,会带来一个新的问题–内存碎片化。如果下次有比较大的对象实例需要在堆上分配较大的内存空间时࿰…...

终极Markdown浏览器扩展:如何打造完美的文档阅读体验
终极Markdown浏览器扩展:如何打造完美的文档阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展,专为开发…...

从蓝牙4.2到5.4:广播包格式的‘进化史’与向后兼容那些坑
蓝牙广播协议演进史:从4.2到5.4的兼容性实战指南 当你的智能手表突然无法被旧款手机发现,或者工业传感器在新版本固件下出现广播丢包——这些看似简单的连接问题背后,往往隐藏着蓝牙协议版本迭代带来的兼容性暗礁。作为无线通信领域的"毛…...

修音翻车现场实录:用Melodyne选择工具时,这3个坑我劝你别踩
Melodyne修音避坑指南:选择工具三大致命操作误区解析 第一次用Melodyne修人声时,我对着屏幕上的波形信心满满地拖动音符,结果导出的音频听起来像电子合成器故障——音高扭曲、节奏支离破碎。后来才发现,问题都出在那个看似简单的…...

误删/lib64/libc.so.6软连接:从系统“脑死亡”到紧急救援
1. 当系统突然"脑死亡":一场由软连接引发的灾难 那天下午我正在服务器上调试一个依赖glibc 2.18版本的程序,突然看到熟悉的报错:"/lib64/libc.so.6: version GLIBC_2.18 not found"。当时脑子一热,直接执行了…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

FPGA高速ADC数据采集实战——基于AD9253 LVDS接口与ISERDESE2设计
1. AD9253高速ADC核心特性解析 AD9253这颗14位125MSPS四通道ADC芯片,在通信和医疗成像领域堪称经典。我经手过的多个雷达项目中,它的信噪比表现总能带来惊喜——75.3dBFS的实测数据比手册标称值还要稳定。但真正让工程师们又爱又恨的,是它那个…...

构建动态技能图谱:从数据模型到自动化可视化的完整实践
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。乍一看,这只是一个个人仓库,但点进去你会发现,它远不止是一个简单的代码集合。它更像是一张动态的、可视化的个人技能地图&am…...