实验三 MapReduce编程
实验目的:
1.掌握MapReduce的基本编程流程;
2.掌握MapReduce序列化的使用;
实验内容:
一、在本地创建名为MapReduceTest的Maven工程,在pom.xml中引入相关依赖包,配置log4j.properties文件,搭建windwos开发环境。 编程实现以下内容:
(1)创建com.nefu.(xingming).maxcount包,编写wordcountMapper、Reducer、Driver三个类,实现统计每个学号的最高消费。
输入数据data.txt格式如下:
序号 \t 学号 \t 日期 \t 消费总额
输出数据格式要求如下:
学号 \t 最高消费
ZnMapper.java
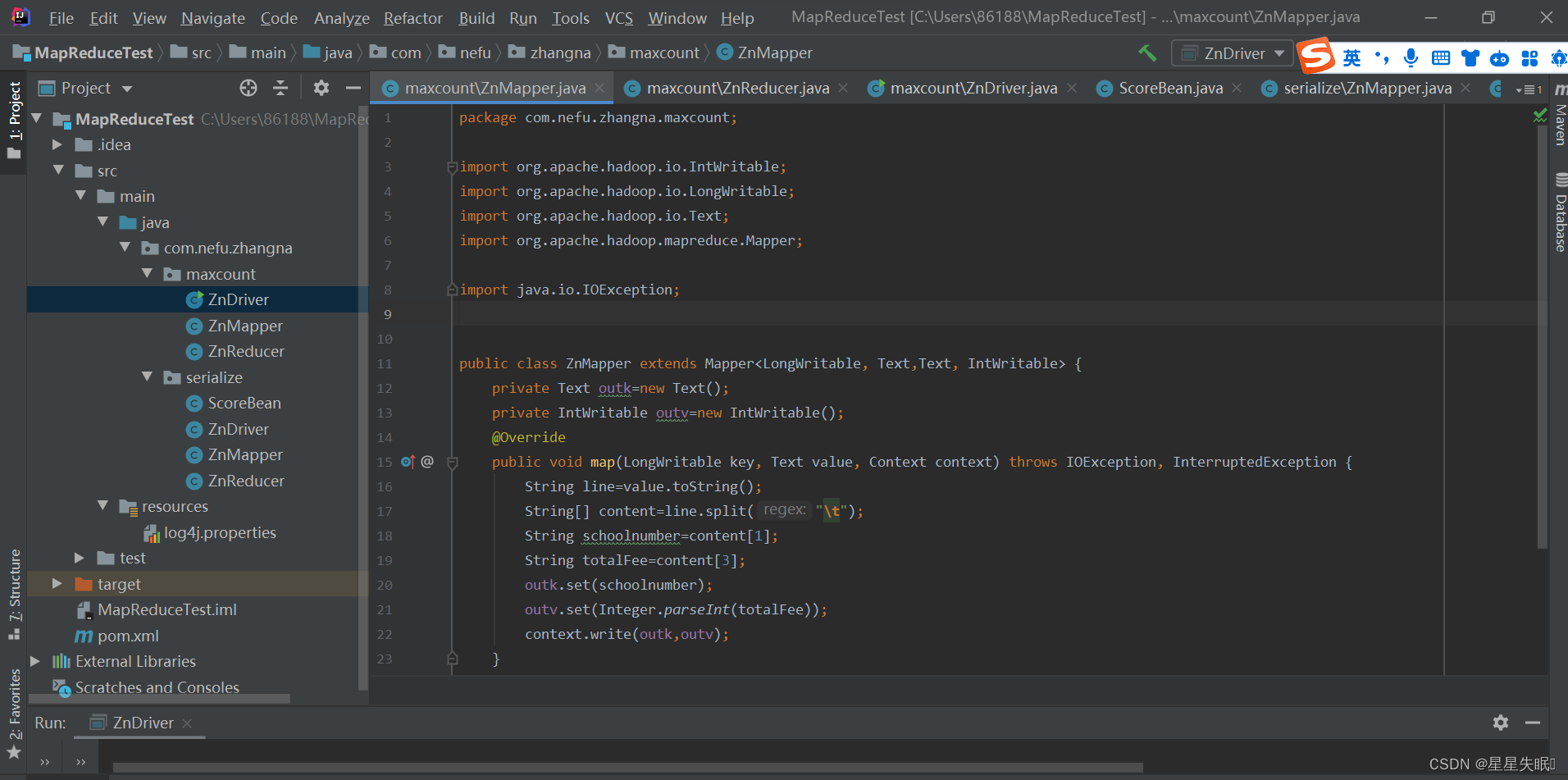
package com.nefu.zhangna.maxcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class ZnMapper extends Mapper<LongWritable, Text,Text, IntWritable> {private Text outk=new Text();private IntWritable outv=new IntWritable();@Overridepublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line=value.toString();String[] content=line.split("\t");String schoolnumber=content[1];String totalFee=content[3];outk.set(schoolnumber);outv.set(Integer.parseInt(totalFee));context.write(outk,outv);}
}
ZnReducer.java
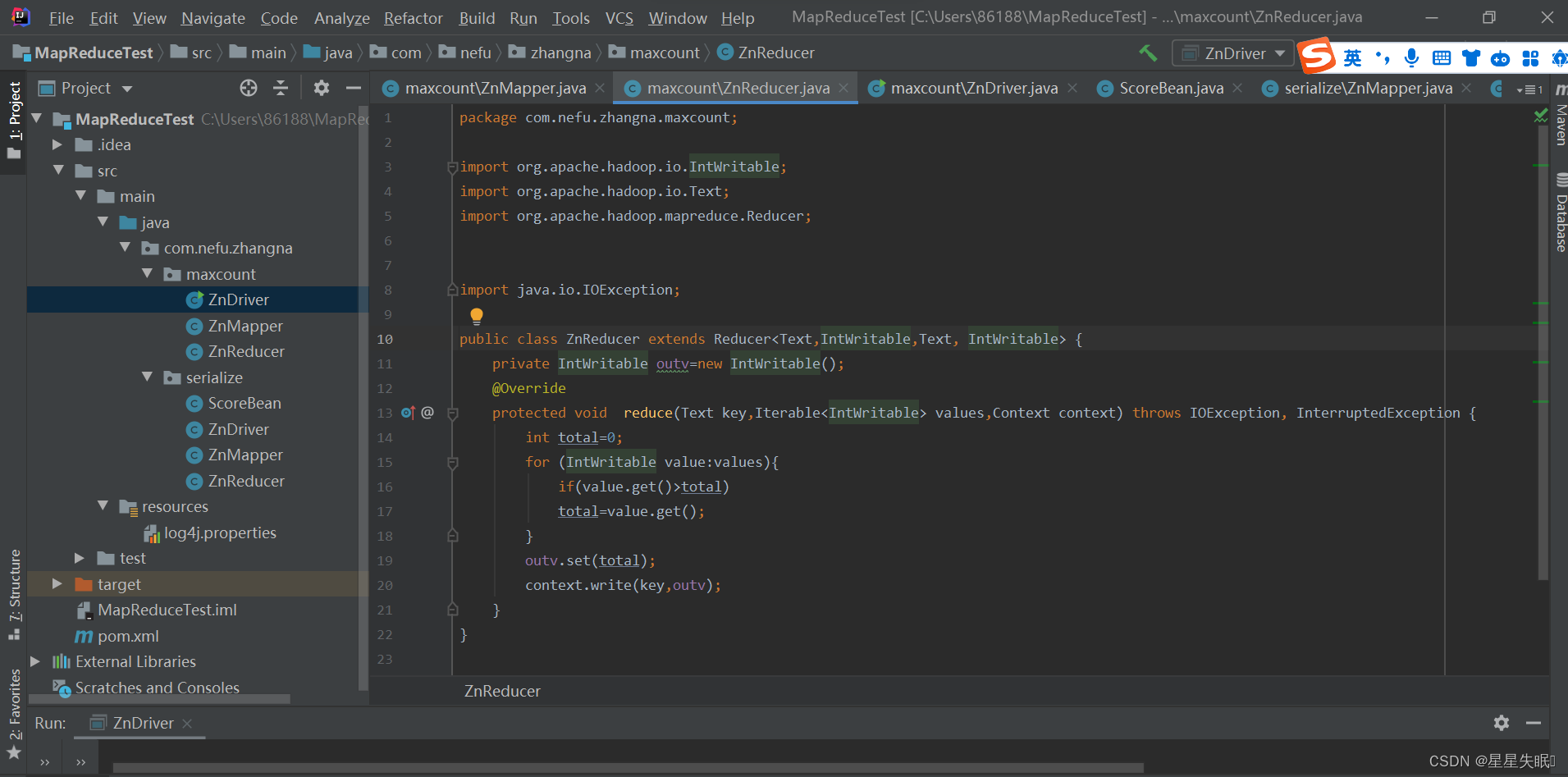
package com.nefu.zhangna.maxcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class ZnReducer extends Reducer<Text,IntWritable,Text, IntWritable> {private IntWritable outv=new IntWritable();@Overrideprotected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int total=0;for (IntWritable value:values){if(value.get()>total)total=value.get();}outv.set(total);context.write(key,outv);}
}
ZnDriver.java
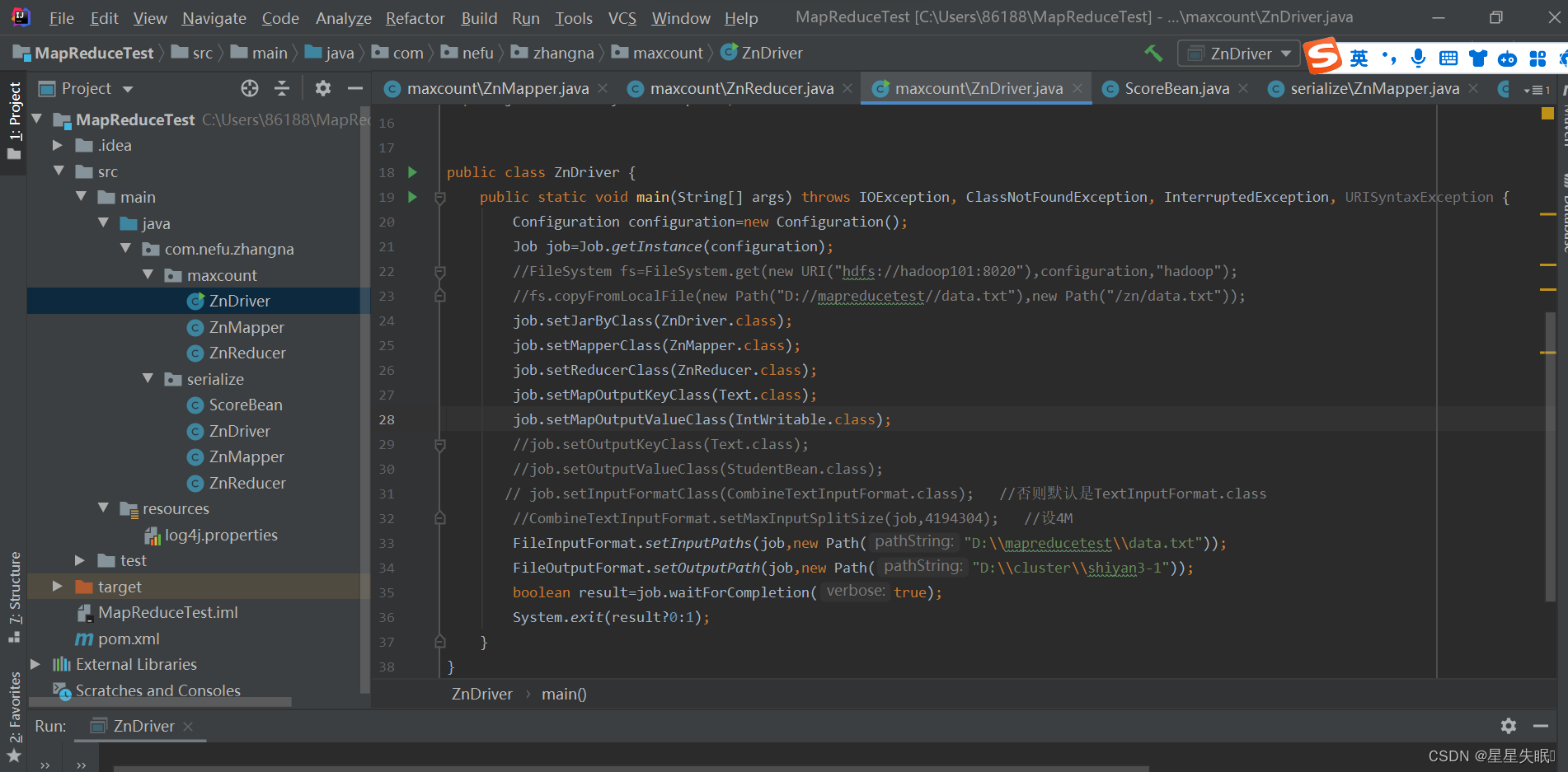
package com.nefu.zhangna.maxcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;public class ZnDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {Configuration configuration=new Configuration();Job job=Job.getInstance(configuration);//FileSystem fs=FileSystem.get(new URI("hdfs://hadoop101:8020"),configuration,"hadoop");//fs.copyFromLocalFile(new Path("D://mapreducetest//data.txt"),new Path("/zn/data.txt"));job.setJarByClass(ZnDriver.class);job.setMapperClass(ZnMapper.class);job.setReducerClass(ZnReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//job.setOutputKeyClass(Text.class);//job.setOutputValueClass(StudentBean.class);// job.setInputFormatClass(CombineTextInputFormat.class); //否则默认是TextInputFormat.class//CombineTextInputFormat.setMaxInputSplitSize(job,4194304); //设4MFileInputFormat.setInputPaths(job,new Path("D:\\mapreducetest\\data.txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\shiyan3-1"));boolean result=job.waitForCompletion(true);System.exit(result?0:1);}
}
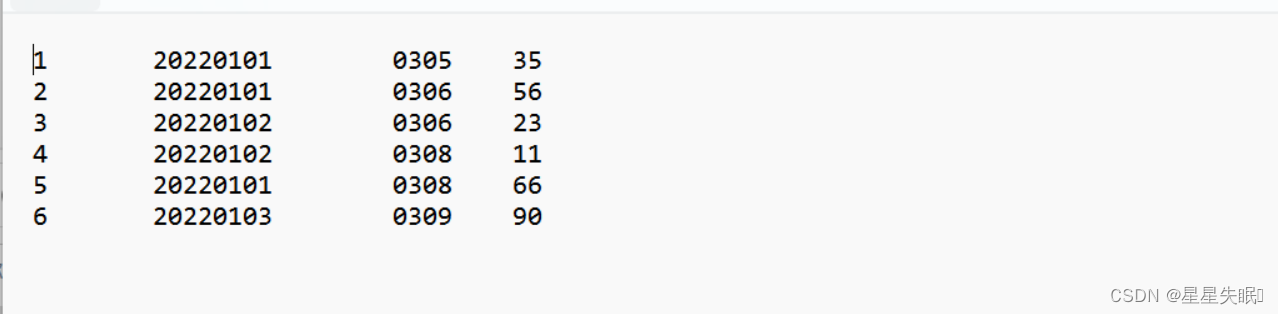
(2)测试上述程序,查看运行结果
原数据
mapreduce之后

(3)查看日志,共有几个切片,几个MapTask(截图)
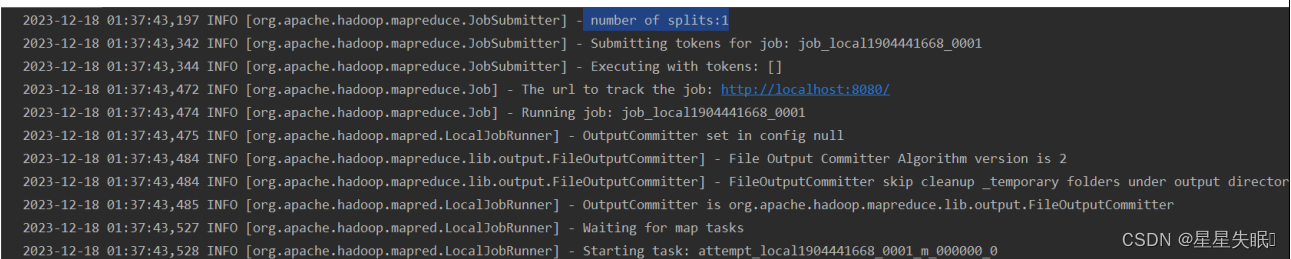
Number of split表示有一个切片,Starting task: attempt_local649325949_0001_m_000000_0表示有一个Map Tast任务
(4)添加文件data1.txt,重新运行程序,共有几个切片,几个MapTask(截图)
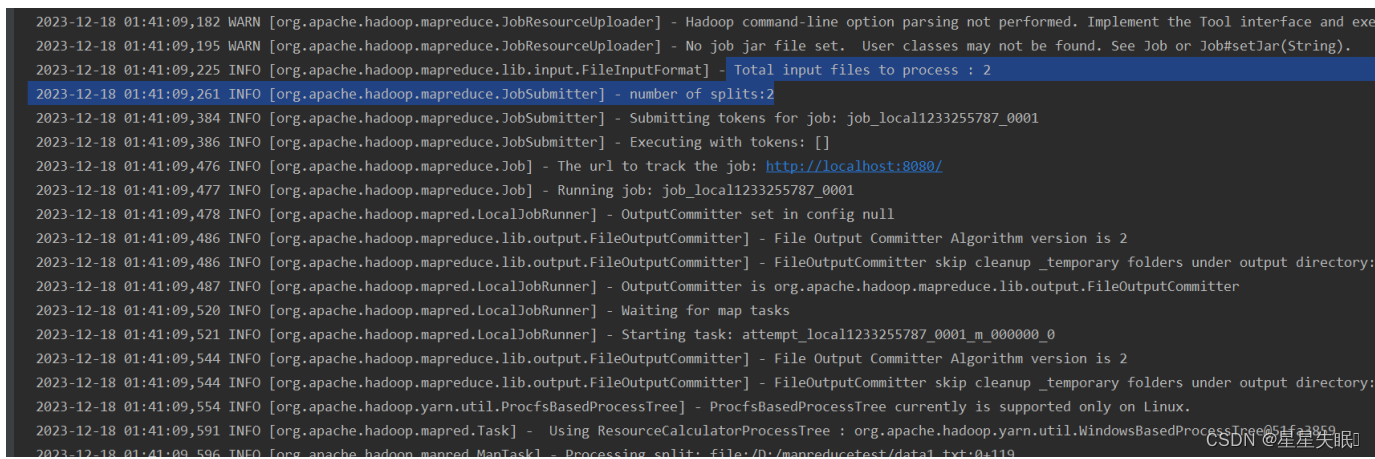
可见我输入了两个文件,切片的数目为2,也就有两个Map Text任务
(5)使用CombinTextInputFormat,让data.txt,data1.txt两个文件在一个切片中

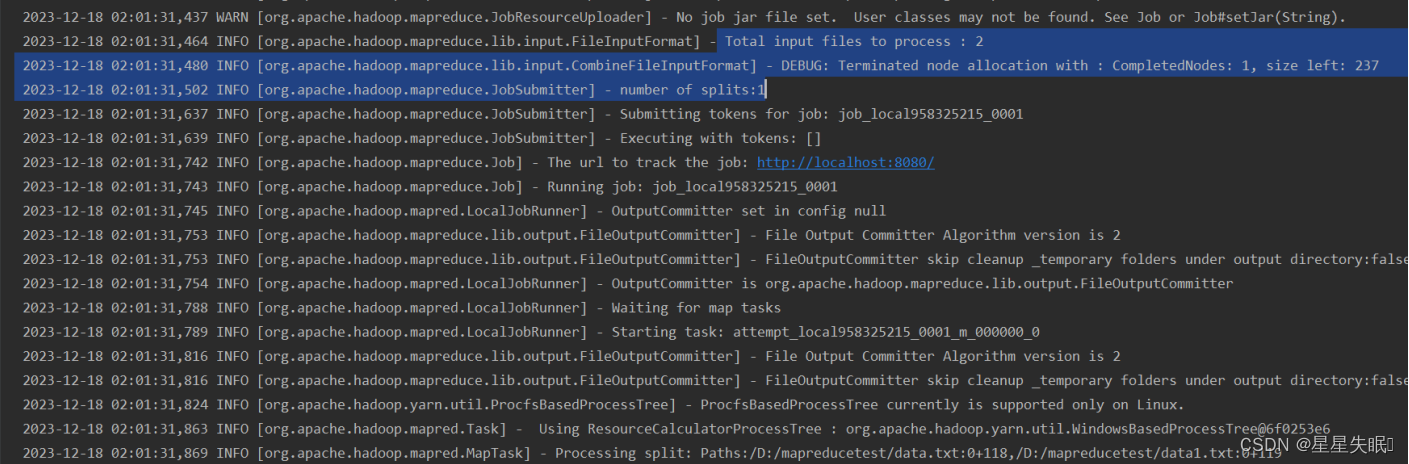
在驱动类中CombinTextInputFormat,可见只有一个切片
(6)将data.txt上传至HDFS

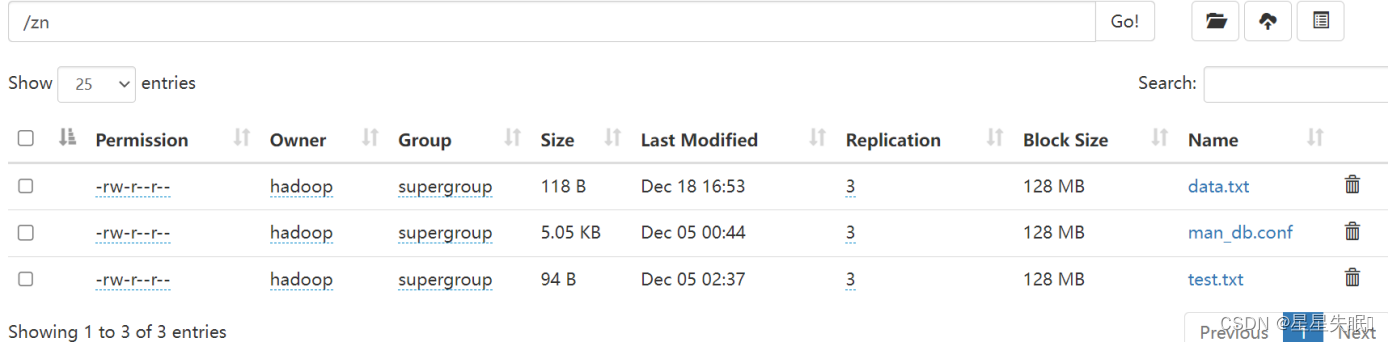

(7)使用maven将程序打成jar包并上传至hadoop集群运行,观察是否能正确运行。
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>将程序打成jar包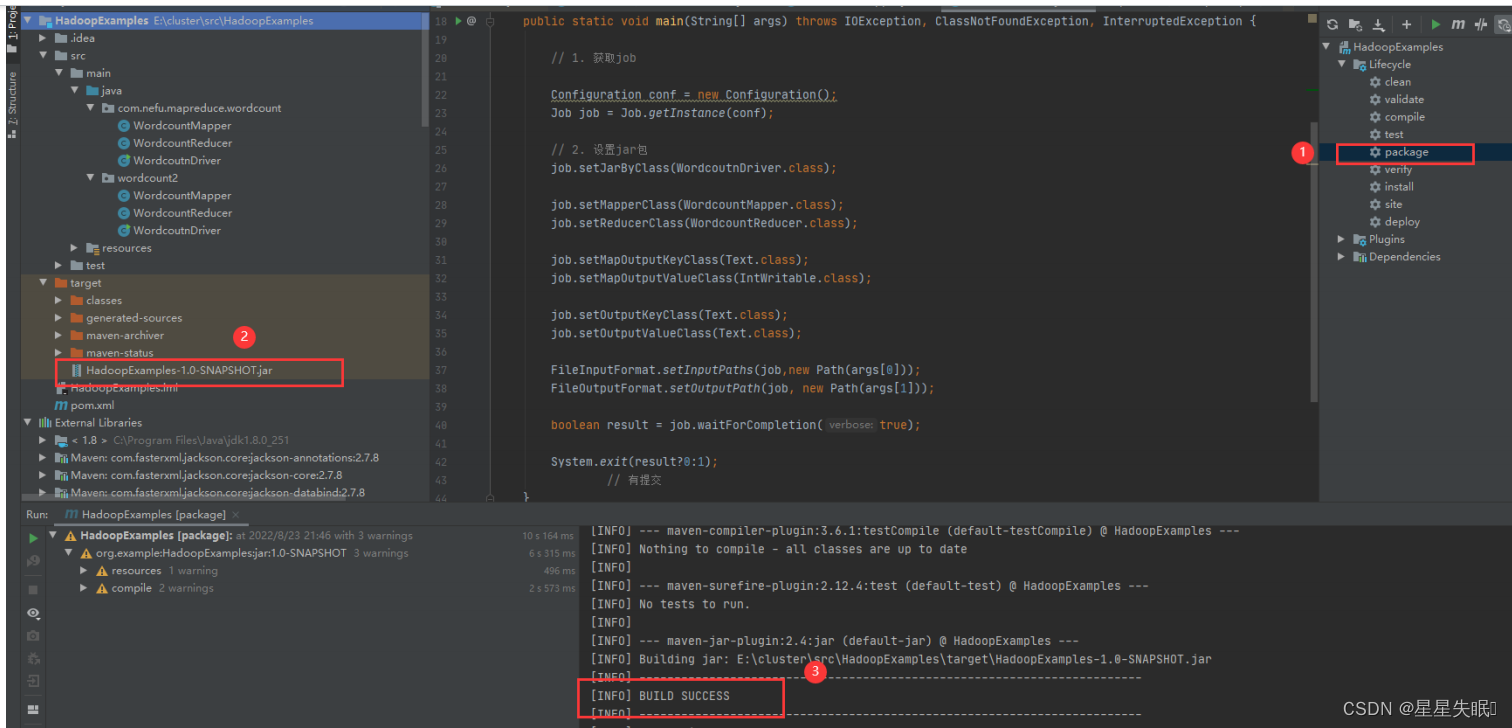
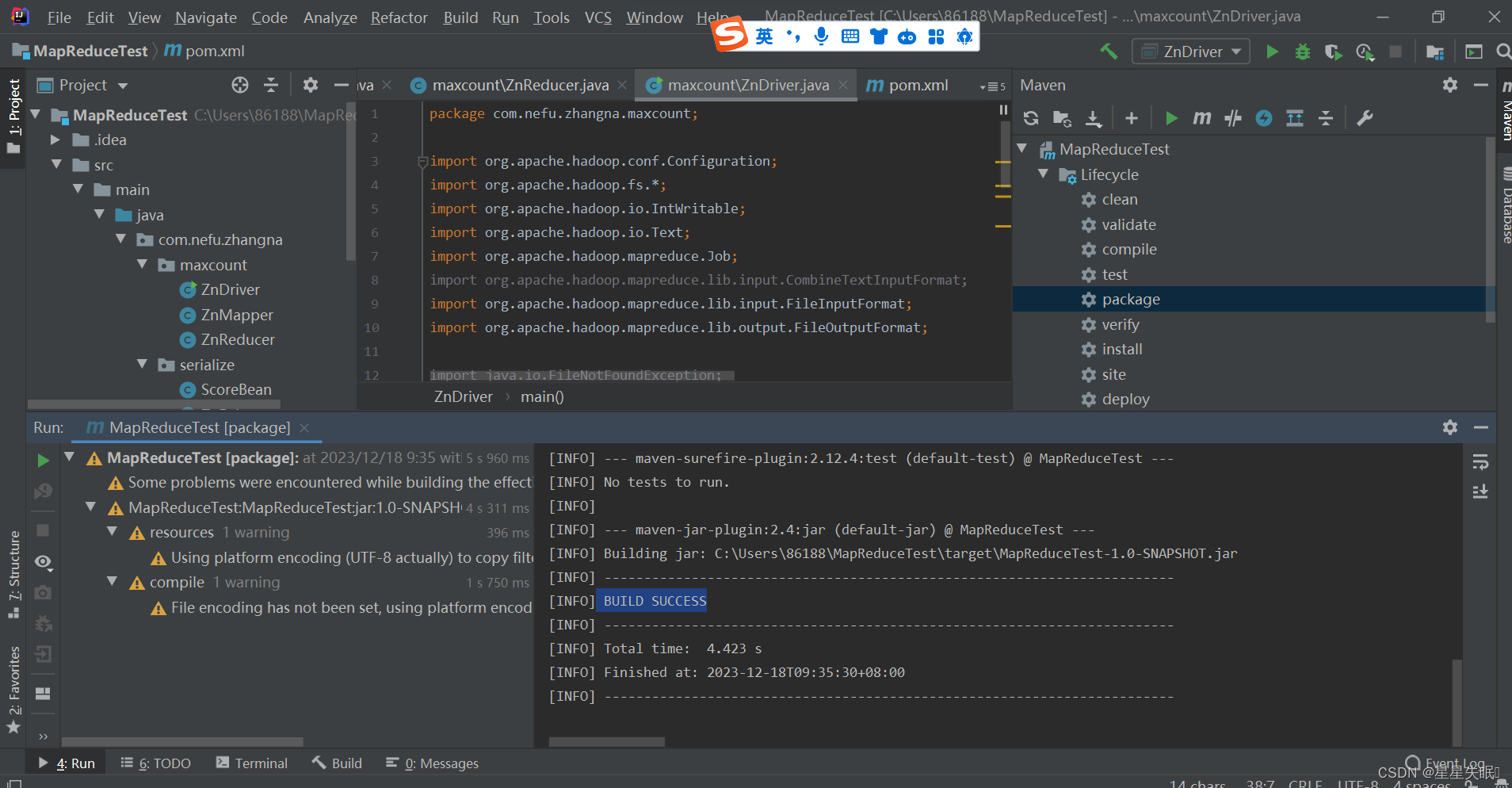

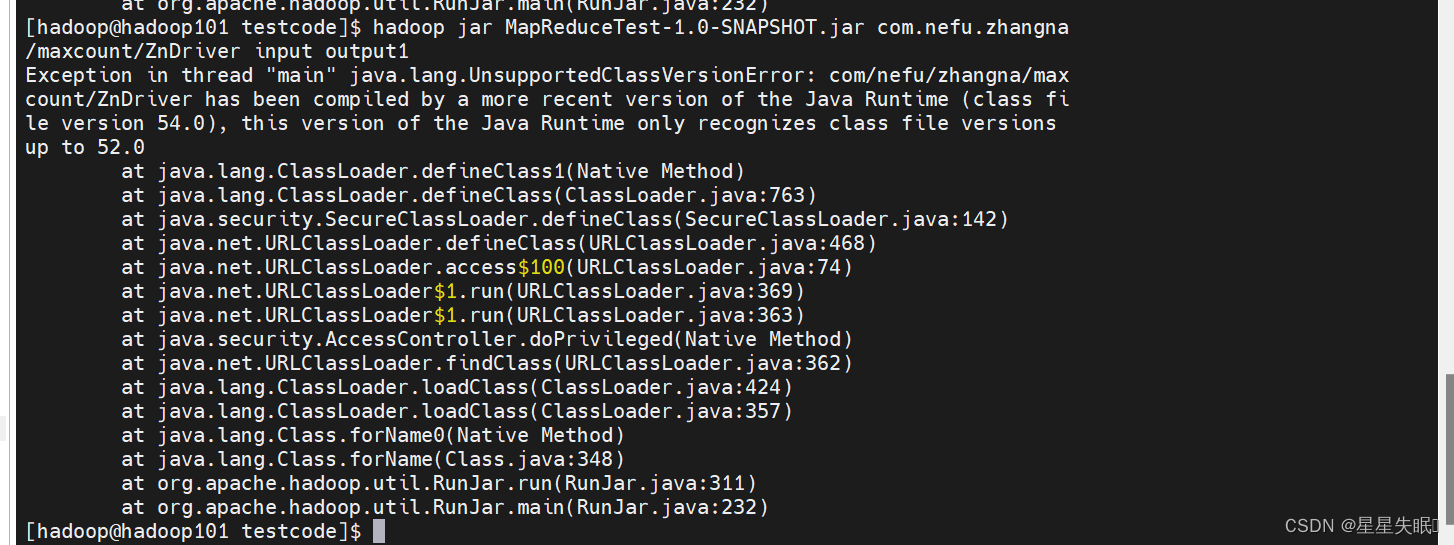
二、创建com.nefu.(xingming).serialize包,编写ScoreBean、Mapper、Reducer、Driver三个类,实现统计每个学号的平均成绩。并将结果按照年级分别写到三个文件中。
输入数据mydata.txt文件格式:
学号 \t 姓名 \t 成绩
输出数据格式(共3个文件):
学号 \t 姓名 \t 平均成绩
MyPartition
package com.nefu.zhangna.serialize;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class MyPartition extends Partitioner<Text,ScoreBean > {@Overridepublic int getPartition(Text text,ScoreBean studentBean,int numPartitions) {String snum = text.toString();int partition;if (snum.contains("2021")) {partition = 0;} else if (snum.contains("2022")) {partition = 1;} else{partition=2;}return partition;}
}
Scorebean
package com.nefu.zhangna.serialize;import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class ScoreBean implements Writable{private String name;private Double score;public ScoreBean(){}public String getName() {return name;}public void setName(String name) {this.name = name;}public Double getScore() {return score;}public void setScore(Double score) {this.score = score;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(name);out.writeDouble(score);}@Overridepublic void readFields(DataInput in) throws IOException {this.name=in.readUTF();this.score=in.readDouble();}@Overridepublic String toString(){return this.name+"\t"+this.score;}
}
ZnMapper1
package com.nefu.zhangna.serialize;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class ZnMapper1 extends Mapper<LongWritable, Text, Text,ScoreBean> {private Text outk=new Text();private ScoreBean outv=new ScoreBean();@Overrideprotected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {String line=value.toString();String[] content=line.split("\t");String schoolnumber=content[0];String name=content[1];String score=content[2];outk.set(schoolnumber);outv.setName(name);outv.setScore(Double.parseDouble(score));context.write(outk,outv);}
}
ZnReducer1
package com.nefu.zhangna.serialize;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class ZnReducer1 extends Reducer<Text, ScoreBean,Text,ScoreBean> {private ScoreBean outv=new ScoreBean();@Overrideprotected void reduce(Text key,Iterable<ScoreBean> values,Context context) throws IOException, InterruptedException {double score=0;int sum=0;String name = null;for (ScoreBean value:values){sum=sum+1;score=score+value.getScore();name=value.getName();}outv.setName(name);outv.setScore(score/sum);context.write(key,outv);}
}
ZnDriver1
package com.nefu.zhangna.serialize;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class ZnDriver1 {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration configuration=new Configuration();Job job=Job.getInstance(configuration);job.setJarByClass(ZnDriver1.class);job.setMapperClass(ZnMapper1.class);job.setReducerClass(ZnReducer1.class);job.setMapOutputKeyClass(Text.class);job.setOutputValueClass(ScoreBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(ScoreBean.class);job.setPartitionerClass(MyPartition.class);job.setNumReduceTasks(3);FileInputFormat.setInputPaths(job,new Path("D:\\mapreducetest\\mydata.txt"));FileOutputFormat.setOutputPath(job,new Path("D:\\cluster\\serialize"));boolean result=job.waitForCompletion(true);System.exit(result?0:1);}
}
相关文章:
实验三 MapReduce编程
实验目的: 1.掌握MapReduce的基本编程流程; 2.掌握MapReduce序列化的使用; 实验内容: 一、在本地创建名为MapReduceTest的Maven工程,在pom.xml中引入相关依赖包,配置log4j.properties文件,搭…...
element组件库的日期选择器如何限制?
本次项目中涉及到根据日期查找出来的数据进行调整,所以修改的数据必须是查找范围内的数据.需要对调整数据的日期进行限制,效果如下: 首先我们使用了element 组件库的日期选择器,其中灌完介绍, picker-options中函数disabledDate可以设置禁用状态,代码如下: <el-date-pickerv…...

QSqlQueryModel
QSqlQueryModel 是 Qt 框架中的一个模型类,用于在 Qt 的视图组件(如 QTableView、QListView)中显示数据库查询结果。 QSqlQueryModel 继承自 QAbstractTableModel,它通过执行 SQL 查询并将结果存储在内部数据结构中,提…...
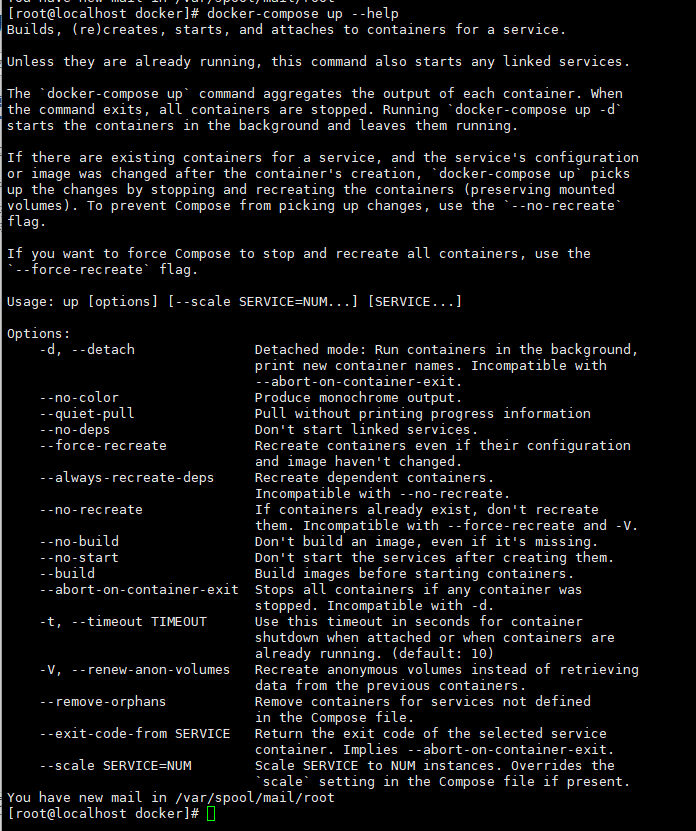
docker-compose介绍和用法
docker-compose介绍和用法详解 1、docker-compose介绍2、docker-compose build3、docker-compose down4、docker-compose up -d 1、docker-compose介绍 Docker Compose是一个用于快速配置多个Docker容器的工具。它是一个定义和运行多容器的Docker应用工具,通过YAML…...

Mac下ERROR: Cannot connect to the Docker daemon
解决Mac下ERROR: Cannot connect to the Docker daemon at unix:///Users/qq/.orbstack/run/docker.sock. Is the docker daemon running? 在Mac系统的中, 如果实际已经安装docker并且已经启动了. 但执行 docker info 时 报错: ERROR: Cannot connect to the Docker daemon …...
本地项目添加到gitlab命令操作
gitlab上面创建一个跟项目名同名的文件夹 创建文件夹,填写信息 添加readme文档,先保存下创建的文件夹 回到项目,复制项目的git 地址 然后进入到本地项目的文件夹,如d:/workspace/spring-demo,右键打开git bash弹框 命令…...
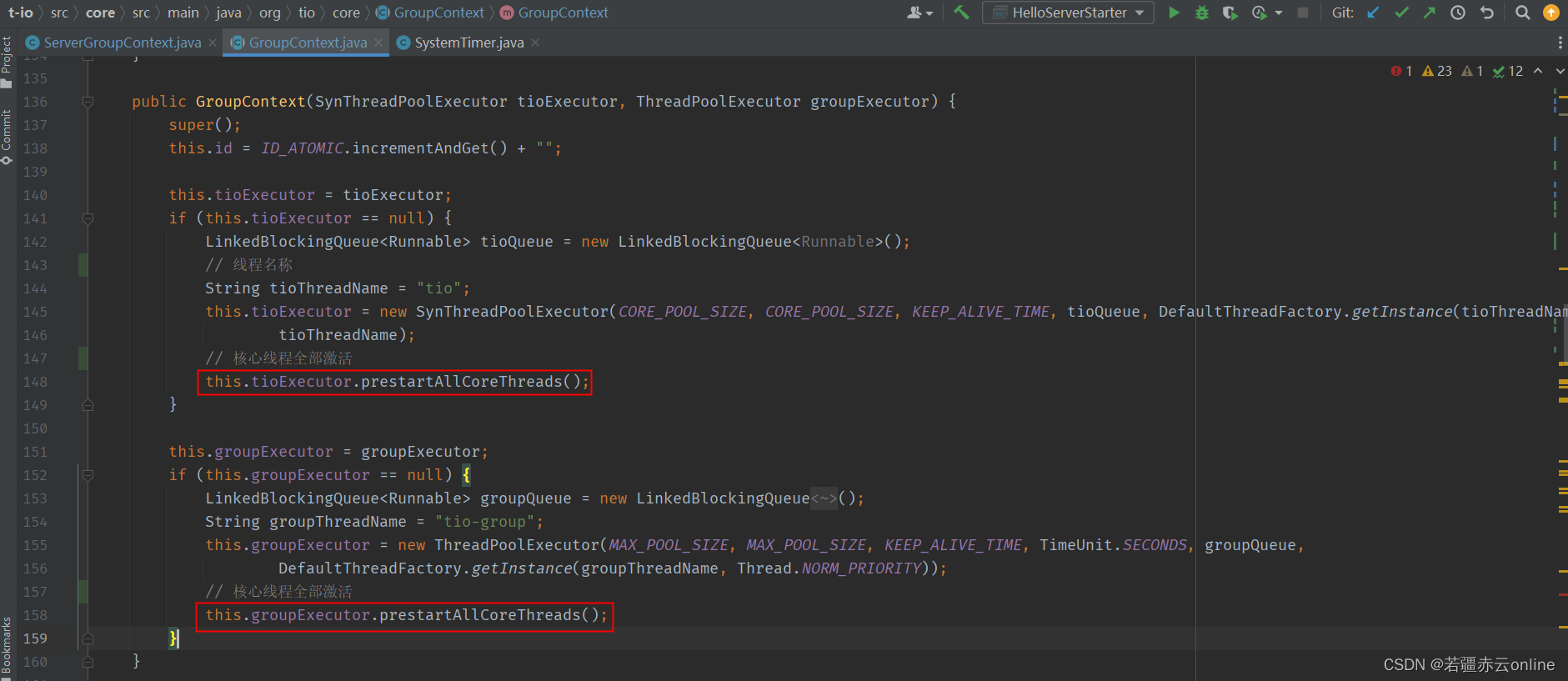
t-io 程序执行后,jvm不退出的原因
基于t-io 1.7.3 版本分析源码 1、设定当前时间,每10毫秒执行一次 (非守护线程) 2、对应线程池的核心线程在AioServer启动时全部激活,并且添加空任务到阻塞队列,让核心线程(非守护线程)一直存活...

Vue3使用Three.js导入gltf模型并解决模型为黑色的问题
背景 如今各类数字孪生场景对三维可视化的需求持续旺盛,因为它们可以用来创建数字化的双胞胎,即现实世界的物体或系统的数字化副本。这种技术在工业、建筑、医疗保健和物联网等领域有着广泛的应用,可以帮助人们更好地理解和管理现实世界的事…...

说一下 jvm 有哪些垃圾回收算法?
说一下 jvm 有哪些垃圾回收算法? 一.对象是否已死算法 1.引用计数器算法 2.可达性分析算法 二.GC算法 1.标记清除算法 如果对象被标记后进行清除,会带来一个新的问题–内存碎片化。如果下次有比较大的对象实例需要在堆上分配较大的内存空间时࿰…...

【23真题】一共10道题,押题卷5道!
哈喽大家好,现在这个时间节点,有很多同学开始刷真题了!所以23真题系列正式启动!小马哥将全面发布23真题及详细解析! 小马哥Tips: 今天分享的是23年天津师范大学804的信号与系统试题及解析。这所院校一共出…...

JS的浅拷贝和深拷贝
首先理解什么是浅拷贝和深拷贝: 浅拷贝: 浅拷贝只会复制对象的第一层属性,而不会递归地复制嵌套的对象。浅拷贝仅复制对象的引用,新对象和原始对象仍然共享相同的引用,因此对新对象的修改可能会影响到原始对象。浅拷…...
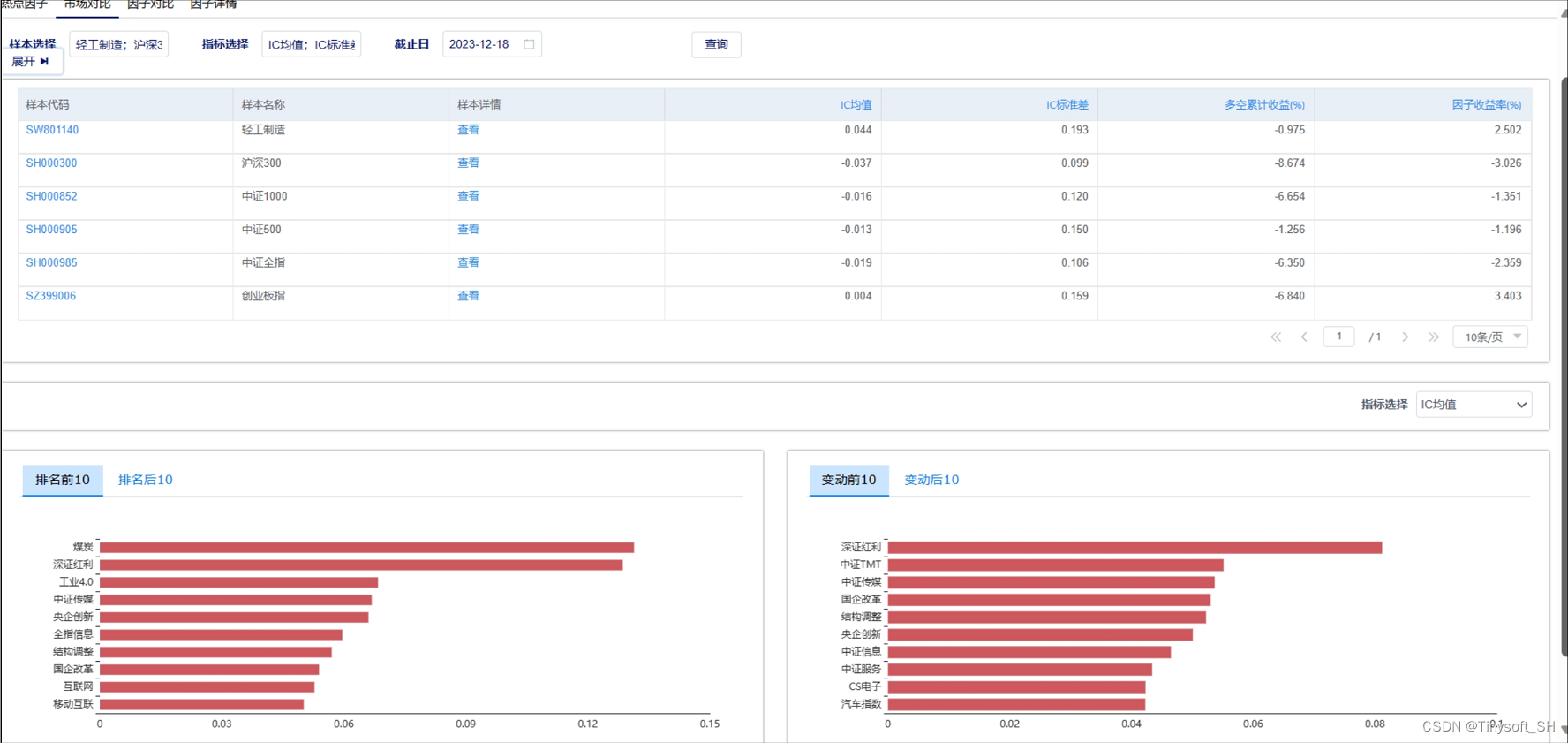
天软特色因子看板 (2023.12 第12期)
该因子看板跟踪天软特色因子A06008(聪明钱因子(beta),该因子为以分钟行情价量信息为基础,识别聪明钱交易,用以刻画机构交易行为 值越大,越反映其悲观情绪,反之,反映其乐观情绪。 今日为该因子跟踪第12期&am…...

【Logback技术专题】「入门到精通系列教程」深入探索Logback日志框架的原理分析和开发实战技术指南(上篇)
深入探索Logback日志框架的原理分析和开发实战指南系列 Logback日志框架Logback基本模块logback-corelogback-classiclogback-accessLogback的核心类LoggerAppenderLayoutLayout和Appender filterlogback模块和核心所属关系 Logbackj日志级别日志输出级别日志级别介绍 Logback的…...

vue3+element Plus 清空el-tree复选框选中项
前提问题:el-tree加了show-checkbox复选框属性后,在选择完复选框后切换,不会自动清空选中内容,要求在切换时清空复选框选中内容,解决过程:设置el-tree的ref值,使用setCheckedKeys方法可清空复选…...
【VScode】设置语言为中文
1、下载安装好vscode 2、此时可看到页面为英文,为方便使用可切换为中文 3、键盘按下 ctrlshiftP 4、在输入框内输入configure display language 5、选择中文,restart即可(首次会有install安装过程,等待安装成功后重启即可&am…...
C++ Qt开发:TableWidget表格组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍TableWidget表格组件的常用方法及灵活运用。 …...
layui框架实战案例(25):table组件筛选列记忆功能
即点击当前表格右上角筛选图标后,对表头进行显示隐藏勾选,再刷新页面依然保留当前筛选状态。 要实现layui表格组件的筛选列记忆功能,可以采取以下步骤: 存储筛选数据:当用户进行筛选操作时,将筛选的数据…...

20、WEB攻防——PHP特性缺陷对比函数CTF考点CMS审计实例
文章目录 一、PHP常用过滤函数:1.1 与1.2 md51.3 intval1.4 strpos1.5 in_array1.6 preg_match1.7 str_replace CTFshow演示三、参考资料 一、PHP常用过滤函数: 1.1 与 :弱类型对比(不考虑数据类型),甚至…...

互换数组的两个轴 numpy.swapaxes()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 互换数组的两个轴 numpy.swapaxes() 选择题 请问下列程序运行的的结果是: import numpy as np arr1 np.array([[11,12],[21,22]]).reshape((2,2)) print("【显示】arr1:\n…...
金蝶云星空修改业务对象标识
文章目录 金蝶云星空修改业务对象标识说明解决方案具体操作实操 金蝶云星空修改业务对象标识 说明 一个业务对象的产生,涉及10个表起。 解决方案 还是手工删除重新创建保险。 具体操作 先备份需要删除的元数据,或者扩展,然后重新创建或…...

新手避坑指南:用PEAK CAN卡和ROS快速上手大陆ARS408-21XX毫米波雷达
新手避坑指南:用PEAK CAN卡和ROS快速上手大陆ARS408-21XX毫米波雷达 毫米波雷达在自动驾驶和机器人感知领域扮演着关键角色,而大陆ARS408-21XX系列雷达因其高性价比和稳定性能,成为许多开发者的首选。然而,对于刚接触这一领域的新…...
别再只调XGBoost参数了!试试阿里PAI这篇AAAI 2024新作AMFormer,用Transformer做表格数据效果真香
突破表格数据建模瓶颈:AMFormer如何用算术特征交互重塑深度学习方法 在金融风控、医疗诊断和推荐系统等实际业务场景中,结构化表格数据始终占据着核心地位。传统树模型如XGBoost和LightGBM凭借对特征缺失和噪声的鲁棒性,长期统治着这一领域。…...

Python websocket-client库避坑指南:从回调地狱到优雅关闭长连接
Python websocket-client库深度实战:从长连接管理到生产级解决方案 引言 在实时数据传输领域,WebSocket协议已经成为现代应用的基石。无论是金融行情推送、即时通讯系统还是物联网设备监控,WebSocket的双向通信特性都展现出无可替代的价值。P…...

零成本替代 Zendesk,个人 / 小团队专属开源客服系统
零成本替代 Zendesk,个人 / 小团队专属开源客服系统 前言 在线客服这个赛道,Intercom、Zendesk 这些产品做得确实成熟,但价格对于小团队来说始终是个门槛。随便看一家,每月订阅费基本从几百到几千不等,企业版功能更是直…...

快充协议芯片技术解析:从原理到选型与实战应用
1. 市场爆发与资本热潮:快充芯片的“黄金时代”最近两年,如果你关注半导体和消费电子行业,会发现一个很有意思的现象:一批做快充协议芯片的公司,正在扎堆冲刺IPO。从科创板到创业板,再到港交所,…...
)
从原理到批量利用:深入剖析Apache Superset默认密钥漏洞(CVE-2023-27524)
1. Apache Superset安全漏洞背景 Apache Superset作为一款流行的开源数据可视化工具,在企业数据分析领域有着广泛应用。但正是这样一个看似无害的工具,却因为开发者的一个常见疏忽——使用默认密钥,导致了严重的身份验证绕过漏洞。这个编号为…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

第08章 FastAPI 与 SSE 流式 RAG 后端
第08章 FastAPI 与 SSE 流式 RAG 后端 到目前为止,知识库、检索工具、MCP 客户端都已经就绪,但仍缺少一个面向最终用户的入口。本章用 FastAPI 把整条 RAG 链路串起来:接收前端发来的自然语言问题,调用 MCP 工具检索相关工单&…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...