【深度学习】对比学习的损失函数
前言
对比学习损失(Contrastive Learning Loss)是一种用于自监督学习的损失函数。它侧重于学习一个特征空间,其中相似的样本被拉近,而不相似的样本被推远。在二分类任务中,对比学习损失可以用来学习区分正负样本的特征表示。 对比学习损失函数有多种,其中比较常用的一种是InfoNCE loss。 InfoNCE Loss损失函数是基于对比度的一个损失函数,是由NCE Loss损失函数演变而来。
1.Alignment和Uniformity
1.1 Alignment
Alignment和Uniformity都是对比学习的表示能力的评判标准。出自论文《Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere》。
Alignment指的是相似的例子,也就是正例,映射到单位超球面后,应该具有比较接近的特征,球面距离应该比较近;

1.2 Uniformity
Uniformity指的是系统应该倾向于应该在特征里保留尽可能多的信息,映射到球面上就要求,单位球面上的特征应该尽可能地均与分布在球面上,分布越均匀,意味着保留的特征也就越多越充分。因为,分布越均匀,意味着各自保留各自的独有的特征,这代表着信息保留越充分。

Uniformity特性的极端反例,所有数据都映射到单位超球面的同一个点上,这代表着所有数据的信息都被丢掉,体现为数据分布极度不均匀得到了超球面上的同一个点。也就意味着,所有数据经过两次非线性计算之后都收敛到同一个常数上,这种异常情况我们称之为:模型坍塌(collapse)
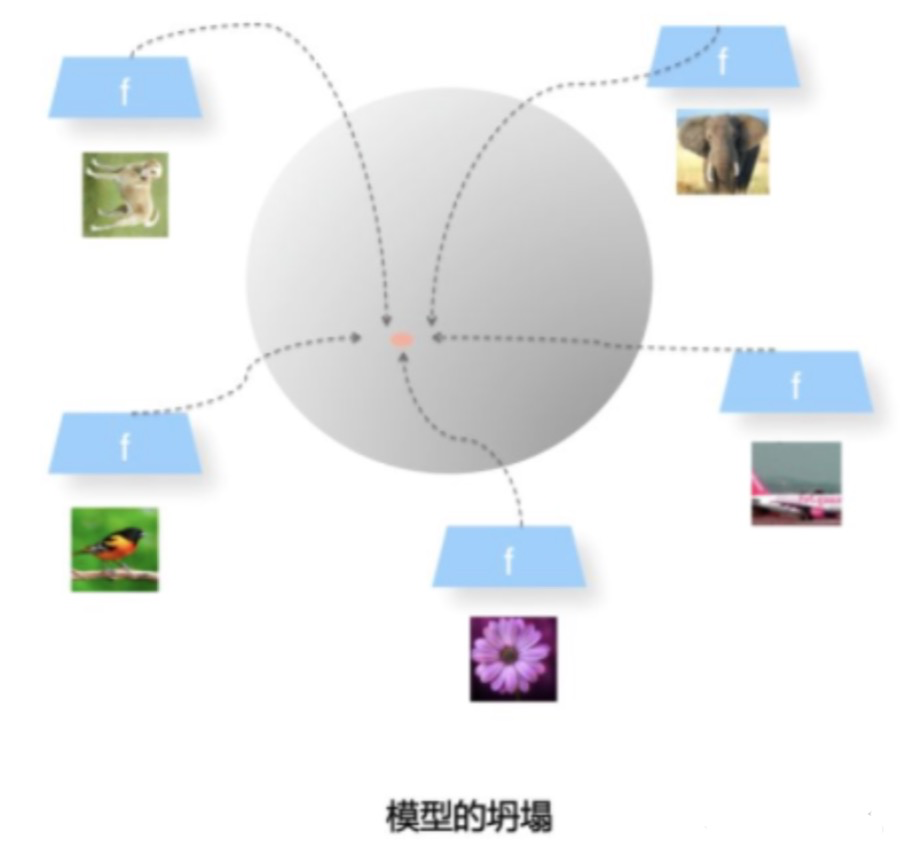
2.对比学习的损失函数
模型作决策时,假设输入到 softmax 前的结果用 sθ(w,c) 表示,实际上 sθ(w,c) 是有含义的,它是一个 socring function ,输出的分数用来量化 w 在上下文 c 中匹配性,那么 w 条件概率可以表示为以下形式:

其中分母部分是归一化常数,一个目的是用来让这个分布真的成为一个“分布”要求(分布积分=1),很多时候,比如计算一个巨大(几十上百万词)的词表在每一个词上的概率得分的时候,计算这个分母会变得非常非常非常消耗资源。
所以在一些应用,比如一个语言模型最后softmax层中,在推理阶段其实只要找到的那一项就够了,并不需要归一化(当然,这个操作其实是错误的。正确的推理是计算出每一个词的概率作为分布,然后从这个分布中采样得到一个正确的词,而不是直接挑一个分数最大的。但是一切为了运算方便)。但在模型的训练阶段,由于分母Z中是包含了模型参数的,所以也要一起参与优化,所以这个计算省不了(当然,softmax这个函数比较特殊,在实际应用中也相当于没有计算这个归一化项,只是计算了ground-truth word的那一项)。
2.1.NCE Loss
NCE(Noise contrastive estimation ),它是通过最大化同一个目标函数来估计模型参数 θ 和归一化常数,NCE 的核心思想就是通过学习数据分布样本和噪声分布样本之间的区别,从而发现数据中的一些特性,因为这个方法需要依靠与噪声数据进行对比,所以称为“噪声对比估计(Noise Contrastive Estimation)”
NCE(Noise contrastive estimation )核心思想是将多分类问题转化成二分类问题。分类器能够对数据样本和噪声样本进行二分类,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。
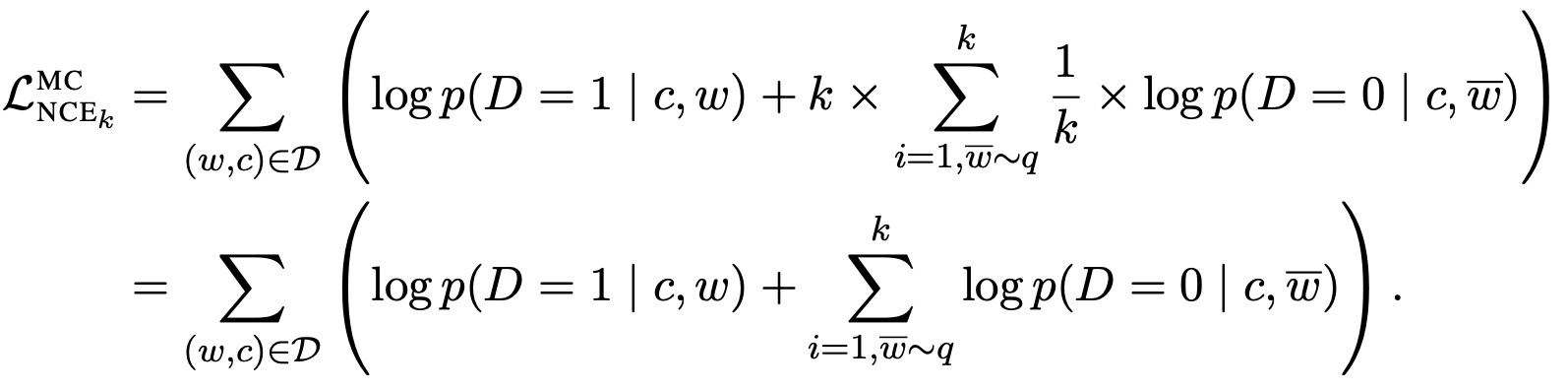
但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。
结论是:对于设置的噪声分布 ,我们实际上是希望它尽量接近数据分布,否则这个二分类任务就过于简单了,也就无法很好的学到数据特性。而作者通过实验和推导证明(我在第三节中也会简单的证明),当负样本和正样本数量之比 k 越大,那么我们的 NCE 对于噪声分布好坏的依赖程度也就越小。换句话说,作者建议我们在计算能力运行的条件下,尽可能的增大比值 k 。也许这也就是大家都默认将正样本数量设置为 1 的原因:正样本至少取要 1 个,所以最大化比值 k ,也就是尽可能取更多负样本的同时,将正样本数量取最小值 1。
另外,如果我们希望目标函数不是只针对一个特定的上下文 c ,而是使不同的上下文可以共享参数,至此 NCE 的构建就完成了。

总结一下就是:从上下文 c 中取出单词作为正样本,从噪声分布中取出单词作为负样本,正负样本数量比为 1:k ,然后训练一个二分类器,通过一个类似于交叉熵损失函数的目标函数进行训练。
2.2 InfoNEC Loss
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理,公式如下:
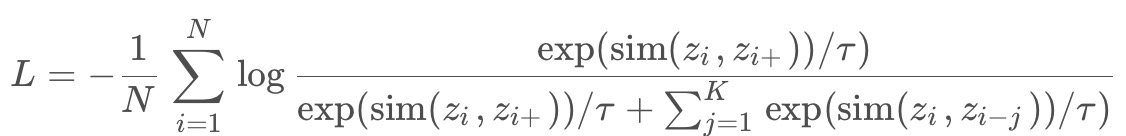
其中
是第i个样本的特征表示,
是其正样本,
是负样本,
是样本x 和y 之间的相似性度量(例如余弦相似性), τ 是一个温度参数,用于控制损失函数的形状。
在公式中可知,分子体现出了Alignment属性,它期望在超球面上正例之间的距离越近越好;分母则体现了Uniformity属性,它期望在负例对之间的距离尽可能的远,这种推力会尽量将点尽可能地均匀分布在超球面上,保留了尽可能多的有用信息。分子部分表示正例之间的相似度,分母表示正例与负例之间的相似度,因此,相同类别相似度越大,不同类别相似度越小,损失就会越小。
损失函数inforNCE会在Alignment和Uniformity之间寻找折中点。如果只有Alignment模型会很快坍塌到常数,损失函数中采用负例的对比学习计算方法,主要是靠负例的Uniformity来防止模型坍塌,很多典型的对比学习方法都是基于此的。infoNCE的思想就是正例之间相互吸引,负例之间相互排斥。
温度系数,是设定的超参数,它的作用是控制模型对负样本的区分度。温度参数会将模型更新的重点,聚焦到有难度的负例,并对他们做相应的惩罚,难度越大,也即与正例越接近,分配到的惩罚系数越多。在模型优化的过程中,需要将这些负例从正例旁边推开,使得其距离越远,是一种斥力。也就是,距离越近的负例会获得更多的权重,会具有更大的斥力,需要将其推开的力越大。
温度系数设的越大,sim的分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。
如果温度超参数设置过小,会导致损失函数分配的惩罚项范围越窄,更加聚焦在比较近的范围之内负例之中。同时,如果这些被覆盖的负例,因为数量减少了,会导致分配到的每个负例上的权重更大,斥力会更大。会导致模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。因此温度系数的设定是不可或缺的。
一般情况下,有效的负例只会聚焦在距离最近的一到两个最难的实例。我们希望能够在温度参数能够在alginment和unifoemity之间找一个平衡点。温度系数在处在一个平衡点时,超球面上的密集数据才会被打散,数据将会越来越均匀。
3.交叉熵损失函数
交叉熵损失函数的形式如图所示:
![]()
softmax公式如下所示:
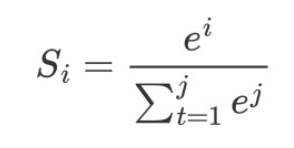
在分类中,由于输出是是one-hot向量,只有一个维度为1,其他维度都为0的向量,所以交叉熵损失函数如下所示:

这和InfoNCE Loss的损失函数的形式十分相似,不同在于,上式中的k在有监督学习里指的是这个数据集一共有多少类别,比如数据集中有1000类,k就是1000。 而在InfoNCE loss中类别只有两类或者几类,而交叉熵损失函数每一个用户或者商品自成一类,softmax操作在如此多类别上进行计算是非常耗时的,再加上有指数运算的操作,这导致计算复杂度相当高且不能实现。
Reference:
1.Noise Contrastive Estimation 前世今生——从 NCE 到 InfoNCE - 知乎
2.求通俗易懂解释下nce loss? - 知乎
3.https://blog.csdn.net/qq_46006468/article/details/126076039
4.对比学习损失 InfoNCE_contrastive loss 和infonce_UCAS_V的博客-CSDN博客
相关文章:
【深度学习】对比学习的损失函数
前言 对比学习损失(Contrastive Learning Loss)是一种用于自监督学习的损失函数。它侧重于学习一个特征空间,其中相似的样本被拉近,而不相似的样本被推远。在二分类任务中,对比学习损失可以用来学习区分正负样本的特征…...

哈夫曼解码
【问题描述】 给定一组字符的Huffman编码表(从标准输入读取),给定一个用该编码表进行编码的Huffman编码文件(存在当前目录下的in.txt中),编写程序对Huffman编码文件进行解码。 例如给定的一组字符的Huffm…...

Excel小技能:excel如何将数字20231211转化成指定日期格式2023/12/11
给了一串数字20231211,想要转成指定格式的日期格式,发现设置单元格格式为指定日期格式不生效,反而变成很长很长的一串#这个,如图所示: 其实,正确的做法如下: 1)打开数据功能界面&am…...
Selenium自动化测试框架(超详细总结分享)
设计思路 本文整理归纳以往的工作中用到的东西,现汇总成基础测试框架提供分享。 框架采用python3 selenium3 PO yaml ddt unittest等技术编写成基础测试框架,能适应日常测试工作需要。 1、使用Page Object模式将页面定位和业务操作分开ÿ…...

STM32 DAC+串口
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、DAC是什么?二、STM32 DAC1.什么型号有DAC2. 简介3. 主要特点4. DAC框图5. DAC 电压范围和引脚 三、程序步骤1. 开启DAC时钟2. 配置引脚 PA4 PA5…...
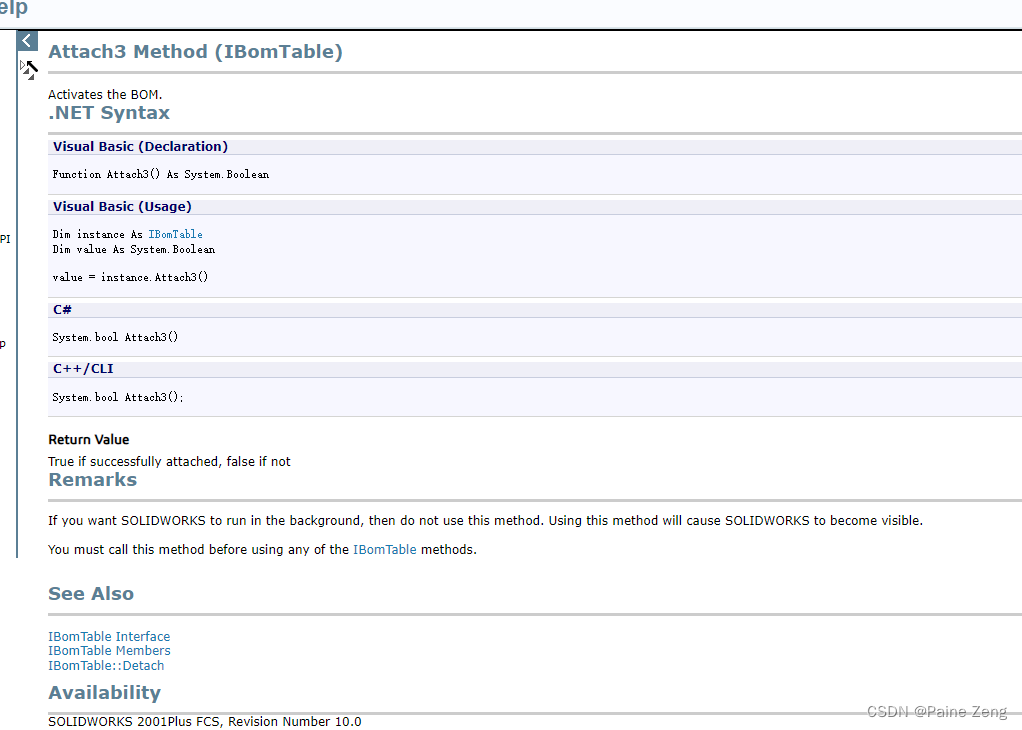
SolidWorks二次开发 C#-读取基于Excel的BOM表信息
SolidWorks二次开发 C#-读取基于Excel的BOM表信息 问题点来源解决方案及思路相关引用链接 问题点来源 这是一位粉丝问的一个问题,他说到: 老师,请问Solidworks二次开发工程图中"基于Excel的材料明细表"怎么读取里面的数据? Ps:这…...
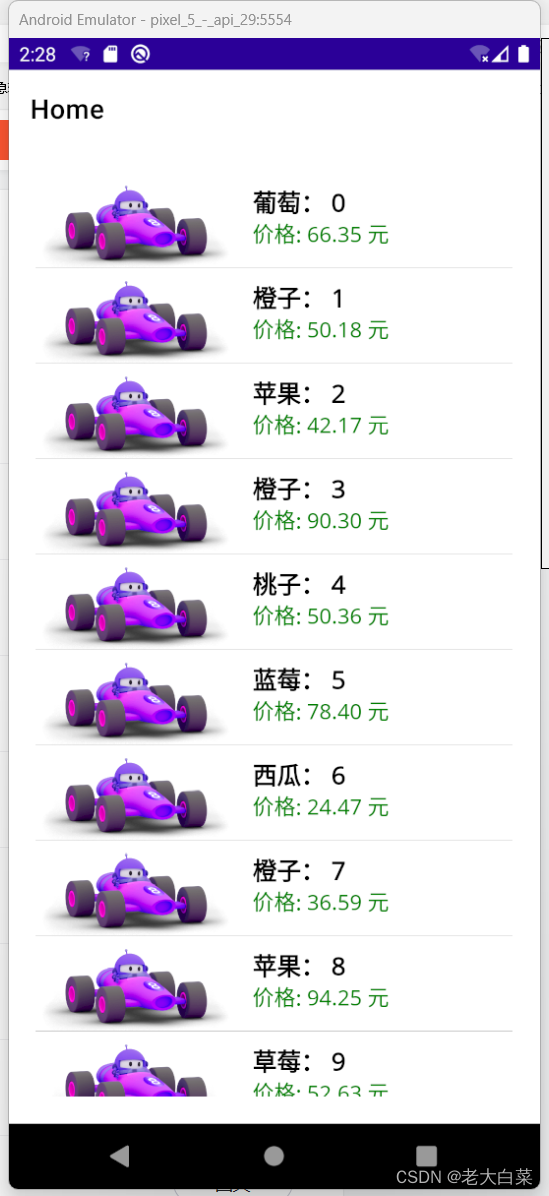
maui中实现加载更多 RefreshView跟ListView(2)
一个类似商品例表的下拉效果: 代码 新增个类为商品商体类 public class ProductItem{public string ImageSource { get; set; }public string ProductName { get; set; }public string Price { get; set; }}界面代码: <?xml version"1.0&quo…...
win10环境下git安装和基础操作
简述 关于git的作用就不多赘述了,配合GitHub,达到方便人们日常项目维护和管理,每一次项目增删改查都可以看的清清楚楚,方便团队协作和个人项目日常维护。 下载git 首先我们自然是要到官网下载git,下载地址为https:/…...

将yolo格式转化为voc格式:txt转xml(亲测有效)
1.文件目录如下所示: 对以上目录的解释: 1.dataset下面的image文件夹:里面装的是数据集的原图片 2.dataset下面的label文件夹:里面装的是图片对应得yolo格式标签 3.dataset下面的Annotations文件夹:这是一个空文件夹&…...
)
字符串 - 541.反转字符串II(C#和C实现)
字符串 - 541.反转字符串II(C#和C实现) 题目描述 给定一个字符串 s 和一个整数 k,你需要对从字符串开头算起的每隔 2k 个字符的前 k 个字符进行反转。 如果剩余字符少于 k 个,则将剩余字符全部反转。如果剩余字符小于 2k 但大于或等于 k 个࿰…...

机器视觉技术与应用实战(开运算、闭运算、细化)
开运算和闭运算的基础是膨胀和腐蚀,可以在看本文章前先阅读这篇文章机器视觉技术与应用实战(Chapter Two-04)-CSDN博客 开运算:先腐蚀后膨胀。开运算可以使图像的轮廓变得光滑,具有断开狭窄的间断和消除细小突出物的作…...

云原生之深入解析云原生架构的日志监控
一、什么是云原生架构的日志监控? 云原生架构的日志监控要求现代 Web 应用程序采用与传统应用程序略有不同的方法。部分原因是应用程序环境要复杂得多,包括从微服务中获取数据、使用 Kubernetes 和其他容器技术,以及在许多情况下集成开源组件…...
基于hfl/rbt3模型的情感分析学习研究——文本挖掘
参考书籍《HuggingFace自然语言处理详解 》 什么是文本挖掘 文本挖掘(Text mining)有时也被称为文字探勘、文本数据挖掘等,大致相当于文字分析,一般指文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生&…...

计算机网络基础——常用的中英文网络述语大全,强烈建议收藏
系统网络体系结构(System Network Architecture,SNA) 国际标准化组织(International Organization for Standardization,ISO) 开放系统互连基本参考模型(Open System Interconnection Reference Model。OSI/RM) 物理层(Physical Layer) 数据终端设备…...

c++如何自定义类及成员函数
#include <iostream>using namespace std;class Box {public:double length; // 长度double breadth; // 宽度double height; // 高度// 成员函数声明double get(void);void set( double len, double bre, double hei ); }; // 成员函数定义 double Box::get(void) …...

100G云数据中心网络建设解决方案
随着数据和流量的快速增长,近年来数据中心已经进入了一个全新的100G时代。为了更高效地提供包括人工智能、虚拟现实、4K视频等在内的云计算服务,全球范围内正在大规模建设众多大型100G数据中心,如云数据中心。作为一种新型高效的基础设施&…...

Zoho Desk为何受到跨境电商企业青睐:优势与特点解析
现如今,跨境电商已成为中国外贸发展的一支重要力量,正从一种新业态成长为外贸的新常态。越来越多的国内电商玩家加入了跨境电商这个战场。跨境电商自有其特殊性,海外客户服务不好一样惨遭投诉,Zoho Desk可以帮助您赢得客户满意度&…...

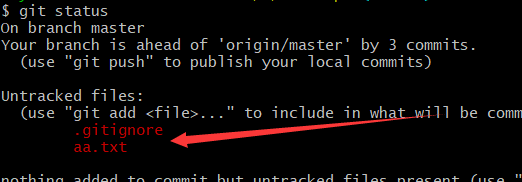
git 删除仓库中多余的文件或者文件夹
目录 问题 解决方案 第一步:同步代码 第二步:删除文件 第三步:提交 第四步:推送远端 问题 在项目开发测试阶段,将无意间将本地敏感的、或无用的文件或目录不小心提交到远程仓库,该怎么解决呢。 解决方…...
)
搭建git服务器(本地局域网)
搭建git服务器(本地局域网) 创建仓库 (假定在/home/git目录下创建仓库) git init --bare sample.git克隆远程仓库到本地 git clone git192.168.0.100:/home/git/sample.git已有项目,绑定远程仓库 # 查看远程仓库绑定 git remote -v# 解除…...

如何让营销更生动,更有效!
作为专业的营销人员,我们深知在当今竞争激烈的市场环境中,如何让自己的产品或服务脱颖而出,吸引更多的潜在客户,是企业成功的关键。而中昱维信视频短信平台,正是您实现这一目标的得力助手。 一、视频短信,…...

基于宝塔面板与Docker Compose快速部署Dify最新版实战指南
1. 为什么选择宝塔Docker Compose部署Dify? 最近在帮几个创业团队搭建AI开发环境时,发现很多小伙伴都被复杂的部署流程劝退。传统的手动部署方式需要逐个安装Python、Redis、PostgreSQL等依赖,光是版本兼容问题就能折腾大半天。直到上个月我…...
)
告别付费IP!手把手教你用ZCU102 PS端DP接口点亮显示器(附参数调试心得)
解锁ZCU102 PS端DisplayPort潜力:零成本实现高效显示输出的实战指南 在嵌入式视觉系统开发中,显示输出往往是项目落地的最后一道关卡。当我在多个Zynq UltraScale MPSoC项目中反复遭遇HDMI IP核的授权困扰和PL端实现的复杂性后,意外发现PS端集…...

如何用自然语言开发Godot游戏:3大突破性功能解析
如何用自然语言开发Godot游戏:3大突破性功能解析 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 你是否想过…...

提升开发效率:Android Studio零障碍IDE本地化配置指南
提升开发效率:Android Studio零障碍IDE本地化配置指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 开发人员在使用…...

FlexRay帧格式拆解:从Header到Trailer,手把手教你读懂汽车总线的‘数据包’
FlexRay帧格式实战解析:像拆解网络包一样掌握汽车总线通信 在汽车电子系统开发中,理解总线协议就像网络工程师需要精通TCP/IP一样重要。FlexRay作为高性能车载网络的核心协议,其帧格式设计既体现了汽车电子对确定性的严苛要求,又融…...

XHS-Downloader:构建高效采集流程的无水印内容批量管理方案
XHS-Downloader:构建高效采集流程的无水印内容批量管理方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接…...

别只看成功率!拆解AlphaFold3在抗体对接中那60%的失败案例
AlphaFold3抗体对接失败的深层解析:60%案例背后的技术挑战与突破路径 当AlphaFold3(AF3)在抗体-抗原对接领域取得8.9%的高精度成功率时,科学界为之振奋。但鲜少有人关注到,在单种子采样条件下,这一系统仍有…...

为什么92%的Java团队TCC失败?阿里P8级专家复盘6大反模式与可立即上线的加固模板
第一章:为什么92%的Java团队TCC失败?阿里P8级专家复盘6大反模式与可立即上线的加固模板TCC(Try-Confirm-Cancel)作为分布式事务的经典模式,在高并发、多服务协同场景中本应提供强一致性保障,但阿里内部审计…...
)
汽车ECU FOTA升级必备:手把手教你用C语言解析S19/HEX文件(附完整代码)
汽车ECU FOTA升级实战:C语言高效解析S19/HEX文件的技术内幕 在汽车电子控制单元(ECU)的固件空中升级(FOTA)流程中,二进制文件的解析效率直接影响着升级过程的可靠性和实时性。当编译器生成的S19或HEX文件需…...

RS232 vs RS485 vs TTL:如何为你的嵌入式项目选择正确的电平标准?
RS232 vs RS485 vs TTL:嵌入式工程师的电平标准选型指南 在嵌入式系统开发中,选择合适的电平标准往往决定了整个通信系统的可靠性和成本效益。就像建筑师需要根据不同的地质条件选择合适的地基方案一样,工程师也需要根据传输距离、环境干扰和…...