详解YOLOv5网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署
一、本文介绍
本文给大家带来的教程是利用YOLOv5训练自己的数据集,以及有关YOLOv5的网络结构讲解/数据集获取/环境搭建/训练/推理/验证/导出/部署相关的教程,同时通过示例的方式让大家来了解具体的操作流程,过程中还分享给大家一些好用的资源,我还对其中的参数进行了详细的讲解,通过本文大家可以成功训练自己的数据集,在开始之前给大家推荐一下我的YOLOv5专栏,本专栏包含上百种YOLOv5的改进机制,以及如何撰写论文的教程,手把手教大家如何改进YOLOv5非常适合科研小白。
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
目录
一、本文介绍
二、模型获取
三、数据集获取
四、环境搭建
五、训练教程
六、推理教程
七、验证教程
八、导出教程
二、模型获取
我们可以从官方的Github开源的地址进行下载即可。
官方代码下载地址:官方代码下载地址点击即可跳转
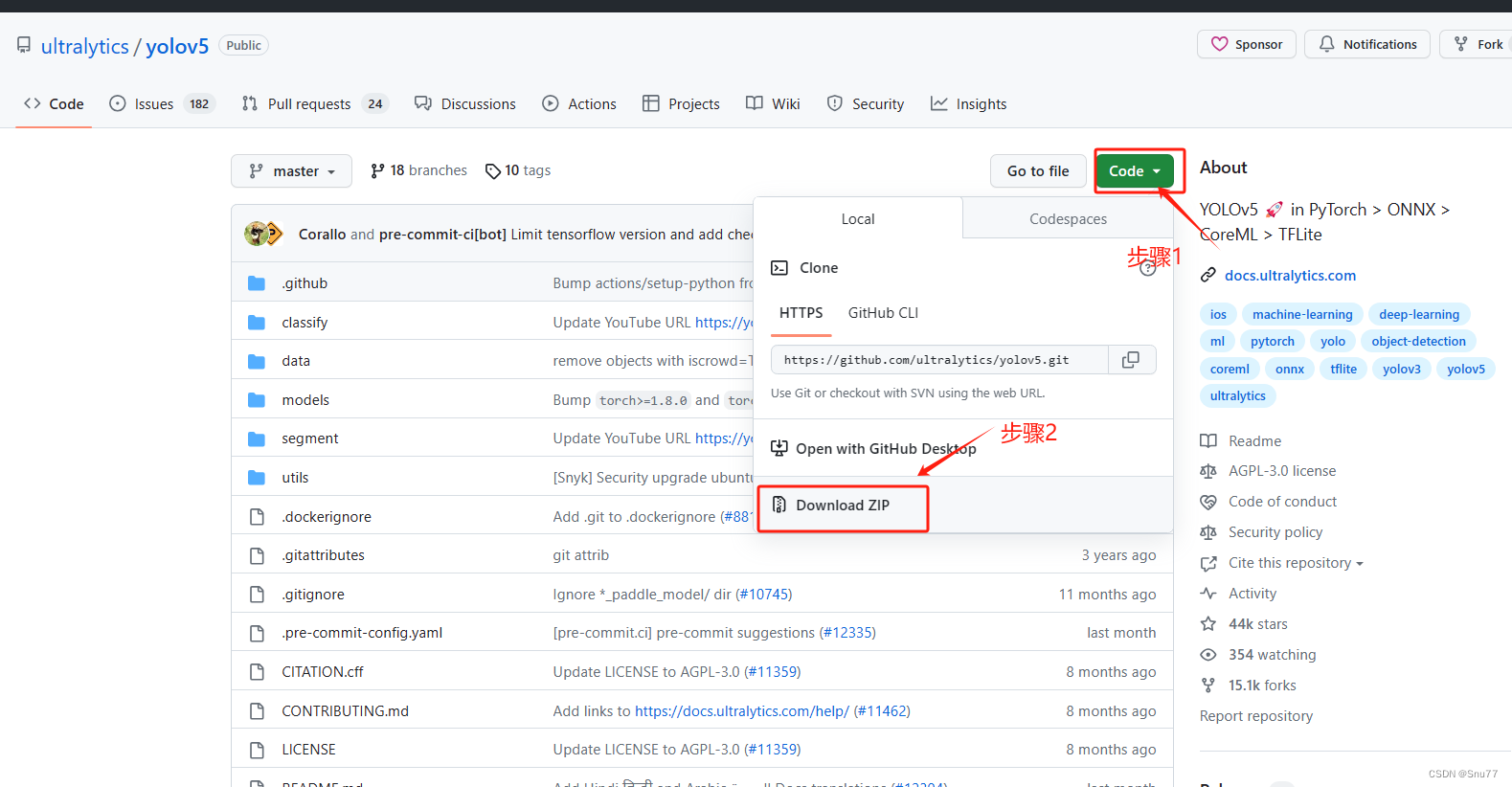 下载完之后,用我们自己熟悉的IDEA打开即可,YOLOv5不像YOLOv8可以通过pip下载,如果通过Git下载,大家也不能够统一,所以推荐大家就去官方下载最方便了,毕竟就是一个压缩包的事情。
下载完之后,用我们自己熟悉的IDEA打开即可,YOLOv5不像YOLOv8可以通过pip下载,如果通过Git下载,大家也不能够统一,所以推荐大家就去官方下载最方便了,毕竟就是一个压缩包的事情。
三、数据集获取
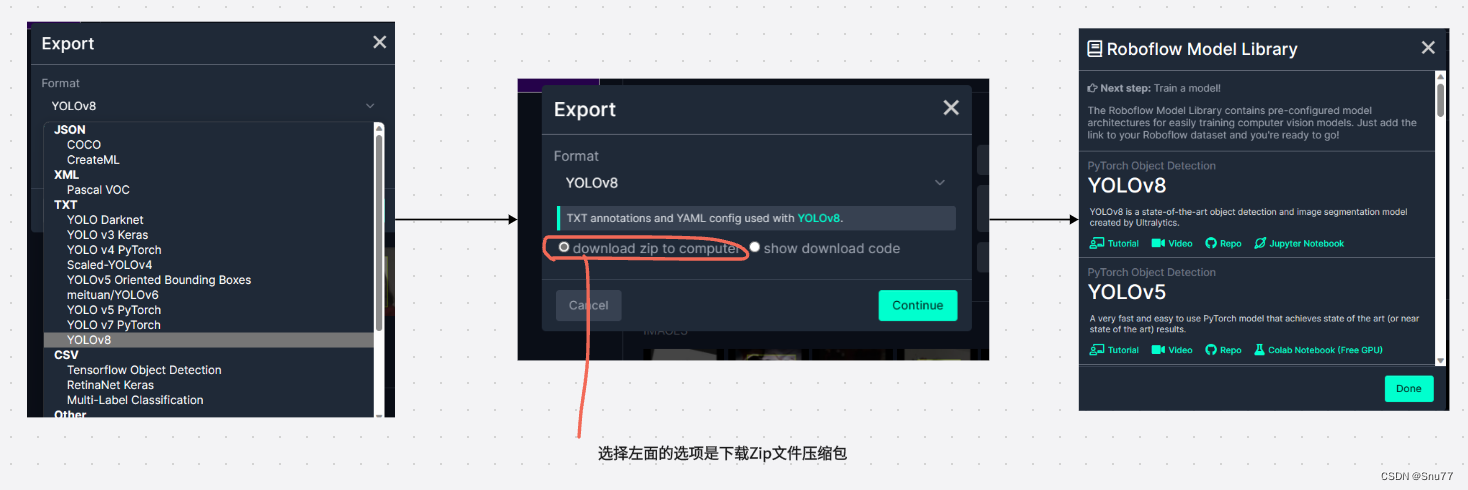
在开始训练之前,我们必须准备一份数据集,网上有很多都是给大家转换脚本,我这里给大家推荐一个免费的数据集网站,里面包含200000+的数据集包括各种VOC、COCO数据集,而且可以一键导出我们想要的数据集格式,下载过后的数据集,我们拿过来直接就可以使用无需做任何的修改了。
数据集教程:超详细教程YoloV5官方推荐免费数据集网站Roboflow一键导出Voc、COCO、Yolo、Csv等格式
四、环境搭建
大家如果没有搭建环境可以看我的另一篇博客,里面讲述了如何搭建pytorch环境(内容十分详细我每次重新更换系统都要看一遍)。
Win11上Pytorch的安装并在Pycharm上调用PyTorch最新超详细过程并附详细的系统变量添加过程,可解决pycharm中pip不好使的问题
在我们配置好环境之后,在之后模型获取完成之后,我们可以进行配置的安装我们可以在命令行下输入如下命令进行环境的配置。
pip install -r requirements.txt输入如上命令之后我们就可以看到命令行在安装模型所需的库了。
五、训练教程
YOLO采用的是文件训练的形式,每一个功能都定义了一个文件,我们通过目录下的'train.py'进行训练即可,这里主要讲解一下其中的参数含义,以及必备的设置。
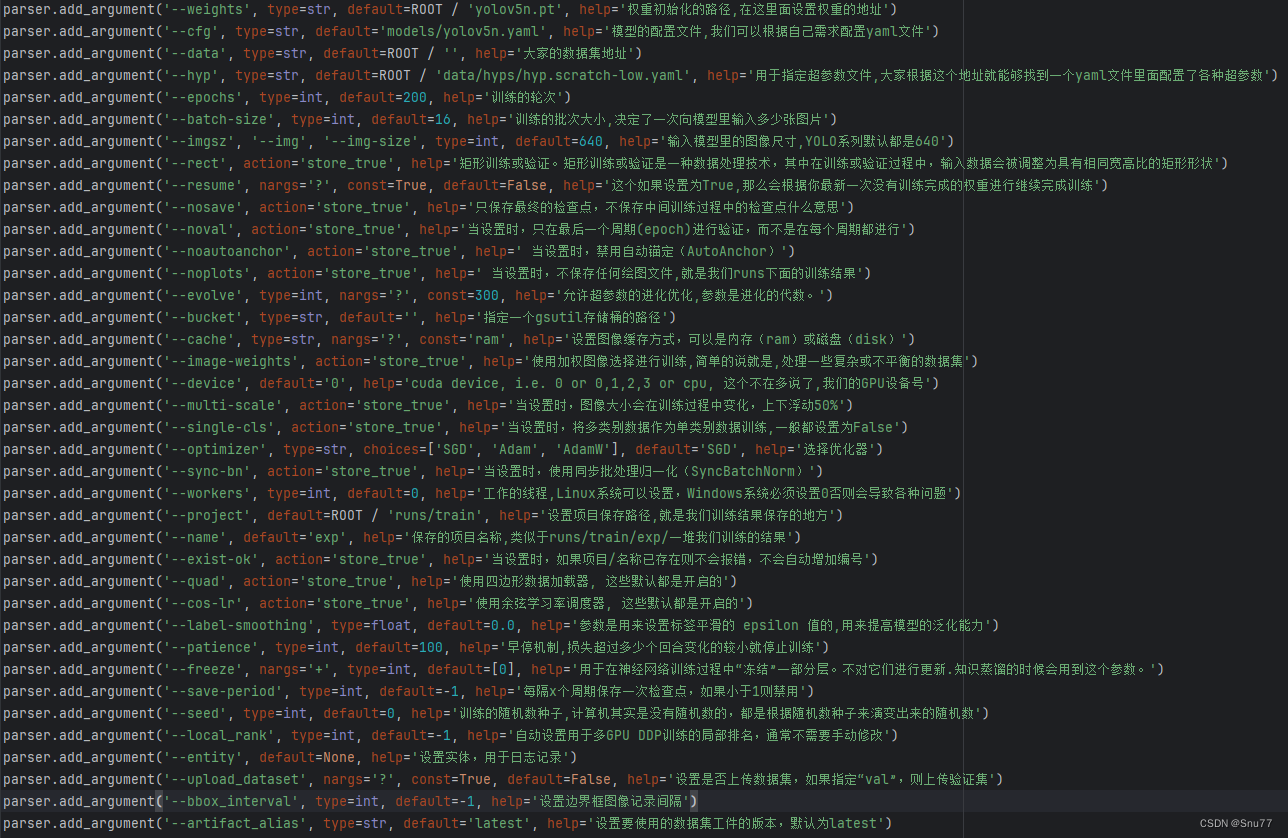
def parse_opt(known=False):parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default=ROOT / 'yolov5n.pt', help='权重初始化的路径,在这里面设置权重的地址')parser.add_argument('--cfg', type=str, default='models/yolov5n.yaml', help='模型的配置文件,我们可以根据自己需求配置yaml文件')parser.add_argument('--data', type=str, default=ROOT / '', help='大家的数据集地址')parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='用于指定超参数文件,大家根据这个地址就能够找到一个yaml文件里面配置了各种超参数')parser.add_argument('--epochs', type=int, default=200, help='训练的轮次')parser.add_argument('--batch-size', type=int, default=16, help='训练的批次大小,决定了一次向模型里输入多少张图片')parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='输入模型里的图像尺寸,YOLO系列默认都是640')parser.add_argument('--rect', action='store_true', help='矩形训练或验证。矩形训练或验证是一种数据处理技术,其中在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状')parser.add_argument('--resume', nargs='?', const=True, default=False, help='这个如果设置为True,那么会根据你最新一次没有训练完成的权重进行继续完成训练')parser.add_argument('--nosave', action='store_true', help='只保存最终的检查点,不保存中间训练过程中的检查点什么意思')parser.add_argument('--noval', action='store_true', help='当设置时,只在最后一个周期(epoch)进行验证,而不是在每个周期都进行')parser.add_argument('--noautoanchor', action='store_true', help=' 当设置时,禁用自动锚定(AutoAnchor)')parser.add_argument('--noplots', action='store_true', help=' 当设置时,不保存任何绘图文件,就是我们runs下面的训练结果')parser.add_argument('--evolve', type=int, nargs='?', const=300, help='允许超参数的进化优化,参数是进化的代数。')parser.add_argument('--bucket', type=str, default='', help='指定一个gsutil存储桶的路径')parser.add_argument('--cache', type=str, nargs='?', const='ram', help='设置图像缓存方式,可以是内存(ram)或磁盘(disk)')parser.add_argument('--image-weights', action='store_true', help='使用加权图像选择进行训练,简单的说就是,处理一些复杂或不平衡的数据集')parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu, 这个不在多说了,我们的GPU设备号')parser.add_argument('--multi-scale', action='store_true', help='当设置时,图像大小会在训练过程中变化,上下浮动50%')parser.add_argument('--single-cls', action='store_true', help='当设置时,将多类别数据作为单类别数据训练,一般都设置为False')parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='选择优化器')parser.add_argument('--sync-bn', action='store_true', help='当设置时,使用同步批处理归一化(SyncBatchNorm)')parser.add_argument('--workers', type=int, default=0, help='工作的线程,Linux系统可以设置,Windows系统必须设置0否则会导致各种问题')parser.add_argument('--project', default=ROOT / 'runs/train', help='设置项目保存路径,就是我们训练结果保存的地方')parser.add_argument('--name', default='exp', help='保存的项目名称,类似于runs/train/exp/一堆我们训练的结果')parser.add_argument('--exist-ok', action='store_true', help='当设置时,如果项目/名称已存在则不会报错,不会自动增加编号')parser.add_argument('--quad', action='store_true', help='使用四边形数据加载器, 这些默认都是开启的')parser.add_argument('--cos-lr', action='store_true', help='使用余弦学习率调度器, 这些默认都是开启的')parser.add_argument('--label-smoothing', type=float, default=0.0, help='参数是用来设置标签平滑的 epsilon 值的,用来提高模型的泛化能力')parser.add_argument('--patience', type=int, default=100, help='早停机制,损失超过多少个回合变化的较小就停止训练')parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='用于在神经网络训练过程中“冻结”(freeze)一部分层。冻结的意思是在训练过程中保持这些层的权重不变,不对它们进行更新.知识蒸馏的时候会用到这个参数。')parser.add_argument('--save-period', type=int, default=-1, help='每隔x个周期保存一次检查点,如果小于1则禁用')parser.add_argument('--seed', type=int, default=0, help='训练的随机数种子,计算机其实是没有随机数的,都是根据随机数种子来演变出来的随机数')parser.add_argument('--local_rank', type=int, default=-1, help='自动设置用于多GPU DDP训练的局部排名,通常不需要手动修改')# Logger argumentsparser.add_argument('--entity', default=None, help='设置实体,用于日志记录')parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='设置是否上传数据集,如果指定“val”,则上传验证集')parser.add_argument('--bbox_interval', type=int, default=-1, help='设置边界框图像记录间隔')parser.add_argument('--artifact_alias', type=str, default='latest', help='设置要使用的数据集工件的版本,默认为latest')return parser.parse_known_args()[0] if known else parser.parse_args()在上面的所有参数里,我们只需要填写前三个就可以开始训练了(仅需配置好前三个),填好地址即可,其中pt权重文件,如果没有会自动联网下载,大家也可以在我门前面给的官方上主动下载到本地,填好参数之后,我们运行train.py文件就可以开始训练 。
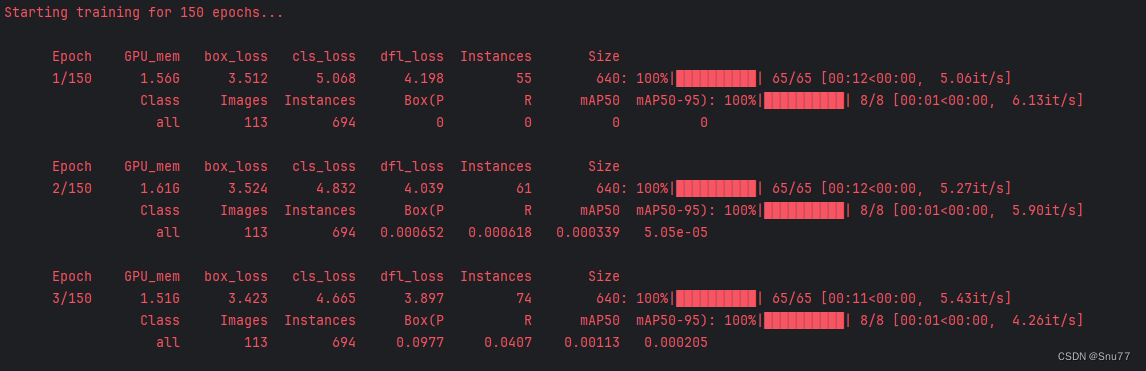
六、推理教程
推理就是,利用我们训练好的权重文件,或者是官方提供的权重文件进行加载预测的过程,功能集成在'detect.py'文件里面,我下面对其中参数含义进行讲解然后进行一个简单的视频推理示例。
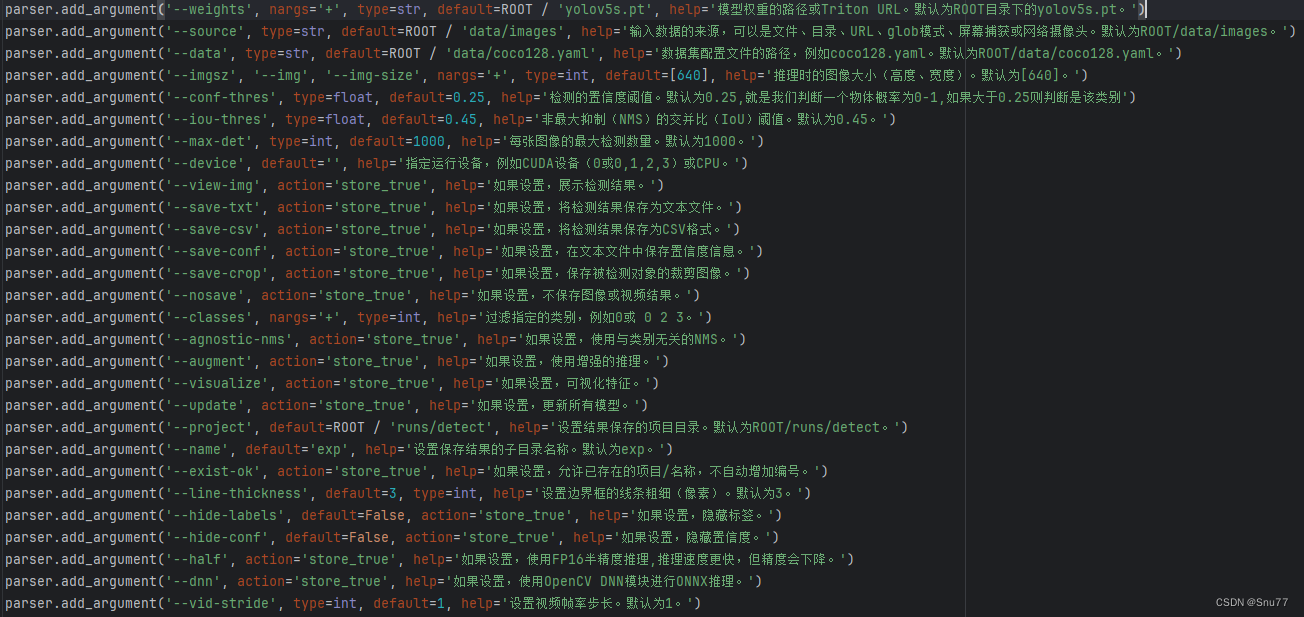
大家可以用下面的代码替换你的代码参数解析部分。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重的路径或Triton URL。默认为ROOT目录下的yolov5s.pt。')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='输入数据的来源,可以是文件、目录、URL、glob模式、屏幕捕获或网络摄像头。默认为ROOT/data/images。')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件的路径,例如coco128.yaml。默认为ROOT/data/coco128.yaml。')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='推理时的图像大小(高度、宽度)。默认为[640]。')
parser.add_argument('--conf-thres', type=float, default=0.25, help='检测的置信度阈值。默认为0.25,就是我们判断一个物体概率为0-1,如果大于0.25则判断是该类别')
parser.add_argument('--iou-thres', type=float, default=0.45, help='非最大抑制(NMS)的交并比(IoU)阈值。默认为0.45。')
parser.add_argument('--max-det', type=int, default=1000, help='每张图像的最大检测数量。默认为1000。')
parser.add_argument('--device', default='', help='指定运行设备,例如CUDA设备(0或0,1,2,3)或CPU。')
parser.add_argument('--view-img', action='store_true', help='如果设置,展示检测结果。')
parser.add_argument('--save-txt', action='store_true', help='如果设置,将检测结果保存为文本文件。')
parser.add_argument('--save-csv', action='store_true', help='如果设置,将检测结果保存为CSV格式。')
parser.add_argument('--save-conf', action='store_true', help='如果设置,在文本文件中保存置信度信息。')
parser.add_argument('--save-crop', action='store_true', help='如果设置,保存被检测对象的裁剪图像。')
parser.add_argument('--nosave', action='store_true', help='如果设置,不保存图像或视频结果。')
parser.add_argument('--classes', nargs='+', type=int, help='过滤指定的类别,例如0或 0 2 3。')
parser.add_argument('--agnostic-nms', action='store_true', help='如果设置,使用与类别无关的NMS。')
parser.add_argument('--augment', action='store_true', help='如果设置,使用增强的推理。')
parser.add_argument('--visualize', action='store_true', help='如果设置,可视化特征。')
parser.add_argument('--update', action='store_true', help='如果设置,更新所有模型。')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='设置结果保存的项目目录。默认为ROOT/runs/detect。')
parser.add_argument('--name', default='exp', help='设置保存结果的子目录名称。默认为exp。')
parser.add_argument('--exist-ok', action='store_true', help='如果设置,允许已存在的项目/名称,不自动增加编号。')
parser.add_argument('--line-thickness', default=3, type=int, help='设置边界框的线条粗细(像素)。默认为3。')
parser.add_argument('--hide-labels', default=False, action='store_true', help='如果设置,隐藏标签。')
parser.add_argument('--hide-conf', default=False, action='store_true', help='如果设置,隐藏置信度。')
parser.add_argument('--half', action='store_true', help='如果设置,使用FP16半精度推理,推理速度更快,但精度会下降。')
parser.add_argument('--dnn', action='store_true', help='如果设置,使用OpenCV DNN模块进行ONNX推理。')
parser.add_argument('--vid-stride', type=int, default=1, help='设置视频帧率步长。默认为1。')
下面我来进行一个简单的示例,
找到推理文件'detect.py',然后配置前两个参数即可,然后运行文件。

下面的是推理的过程,视频个本质就是帧处理,它会一帧一帧的处理。
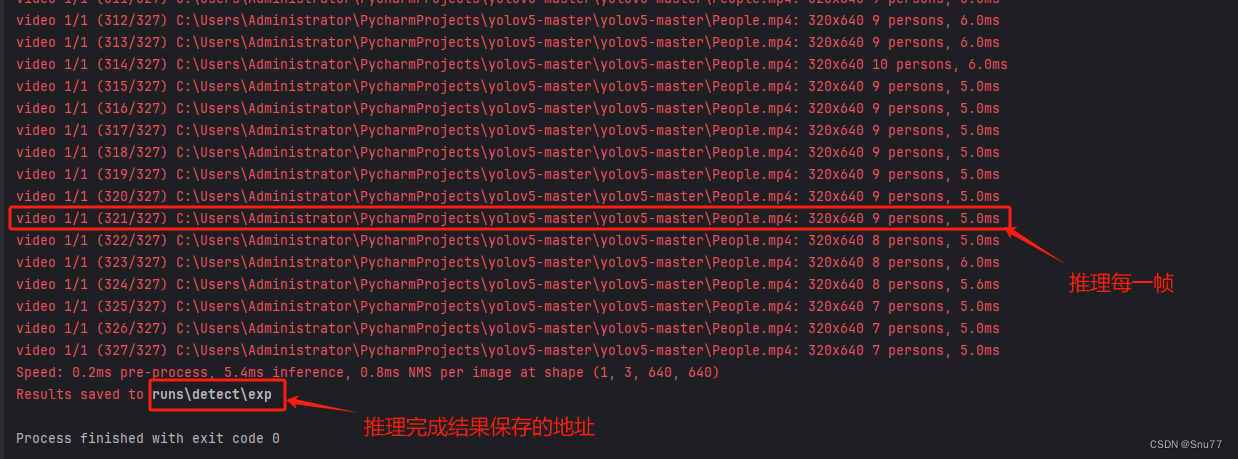
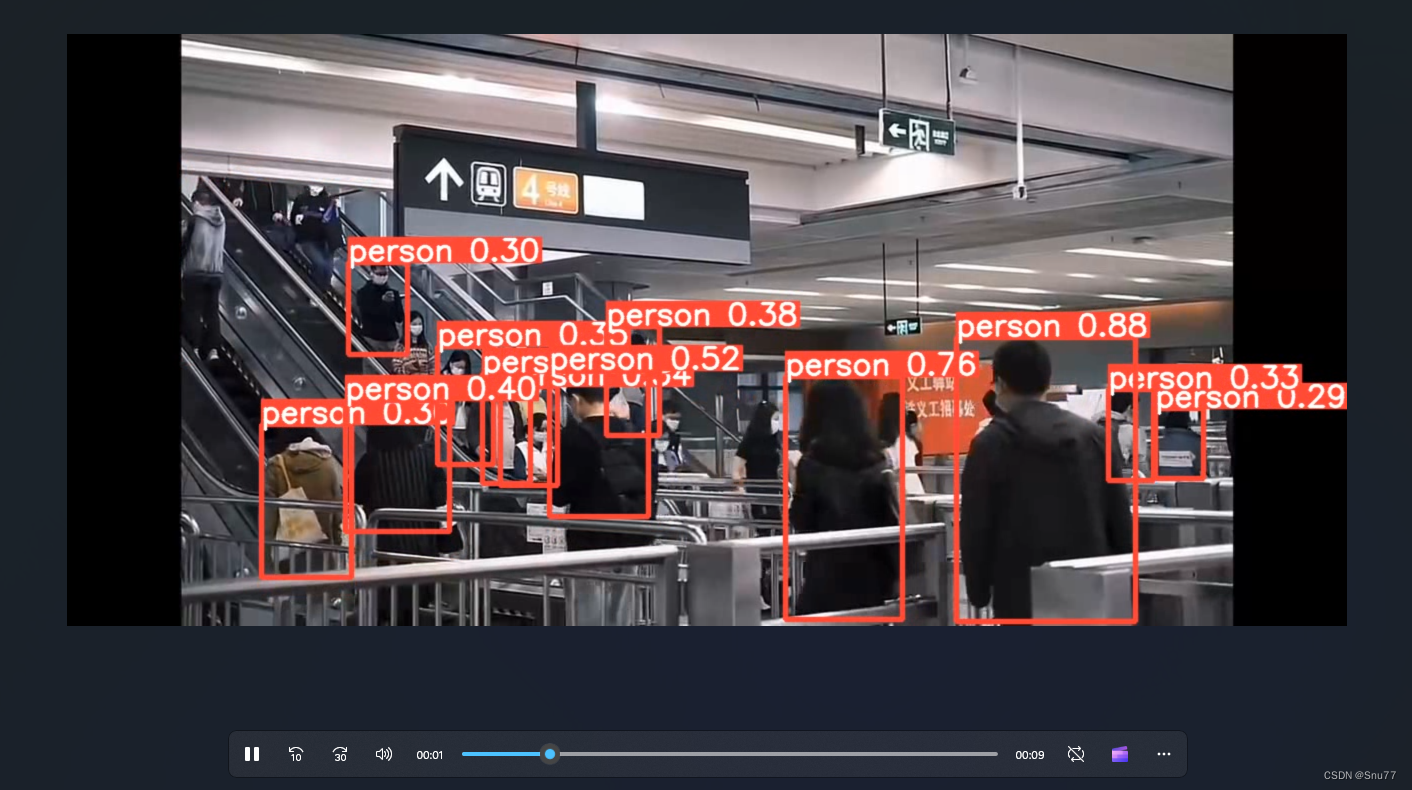
People
七、验证教程
推理的文件是'val.py'文件,其中的参数解释如下。
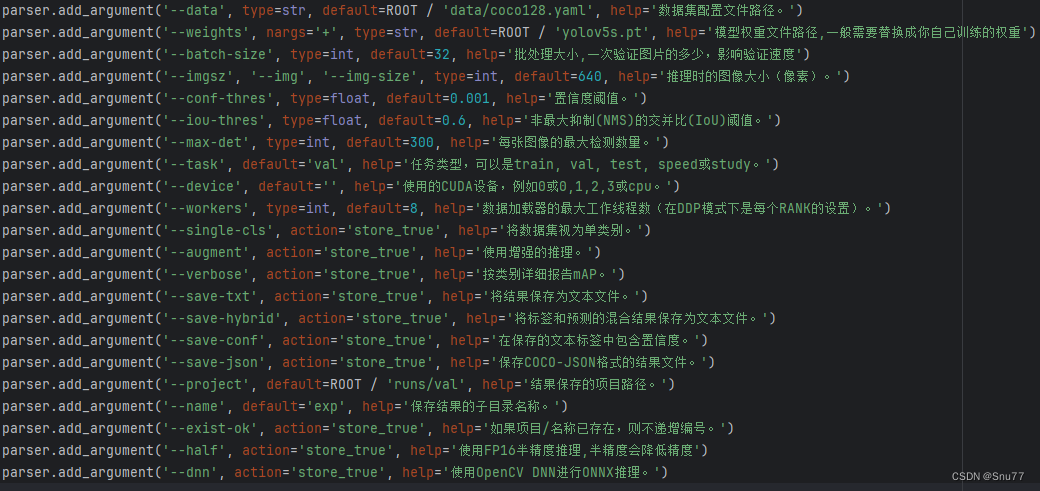
下面的是上面的代码块形式,大家可以复制粘贴。
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件路径。')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重文件路径,一般需要替换成你自己训练的权重')
parser.add_argument('--batch-size', type=int, default=32, help='批处理大小,一次验证图片的多少,影响验证速度')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='推理时的图像大小(像素)。')
parser.add_argument('--conf-thres', type=float, default=0.001, help='置信度阈值。')
parser.add_argument('--iou-thres', type=float, default=0.6, help='非最大抑制(NMS)的交并比(IoU)阈值。')
parser.add_argument('--max-det', type=int, default=300, help='每张图像的最大检测数量。')
parser.add_argument('--task', default='val', help='任务类型,可以是train, val, test, speed或study。')
parser.add_argument('--device', default='', help='使用的CUDA设备,例如0或0,1,2,3或cpu。')
parser.add_argument('--workers', type=int, default=8, help='数据加载器的最大工作线程数(在DDP模式下是每个RANK的设置)。')
parser.add_argument('--single-cls', action='store_true', help='将数据集视为单类别。')
parser.add_argument('--augment', action='store_true', help='使用增强的推理。')
parser.add_argument('--verbose', action='store_true', help='按类别详细报告mAP。')
parser.add_argument('--save-txt', action='store_true', help='将结果保存为文本文件。')
parser.add_argument('--save-hybrid', action='store_true', help='将标签和预测的混合结果保存为文本文件。')
parser.add_argument('--save-conf', action='store_true', help='在保存的文本标签中包含置信度。')
parser.add_argument('--save-json', action='store_true', help='保存COCO-JSON格式的结果文件。')
parser.add_argument('--project', default=ROOT / 'runs/val', help='结果保存的项目路径。')
parser.add_argument('--name', default='exp', help='保存结果的子目录名称。')
parser.add_argument('--exist-ok', action='store_true', help='如果项目/名称已存在,则不递增编号。')
parser.add_argument('--half', action='store_true', help='使用FP16半精度推理,半精度会降低精度')
parser.add_argument('--dnn', action='store_true', help='使用OpenCV DNN进行ONNX推理。')
八、导出教程
导出是为了将我们训练结果进行其它平台的部署,因为python的执行效率是很低的,所以为了加速推理速度,可以将模型进行导出,然后进行其它语言的部署,从而提高检测FPS。
其中的导出文件是'export.py'文件,利用这个文件我们就能将我们训练好的模型进行导出。
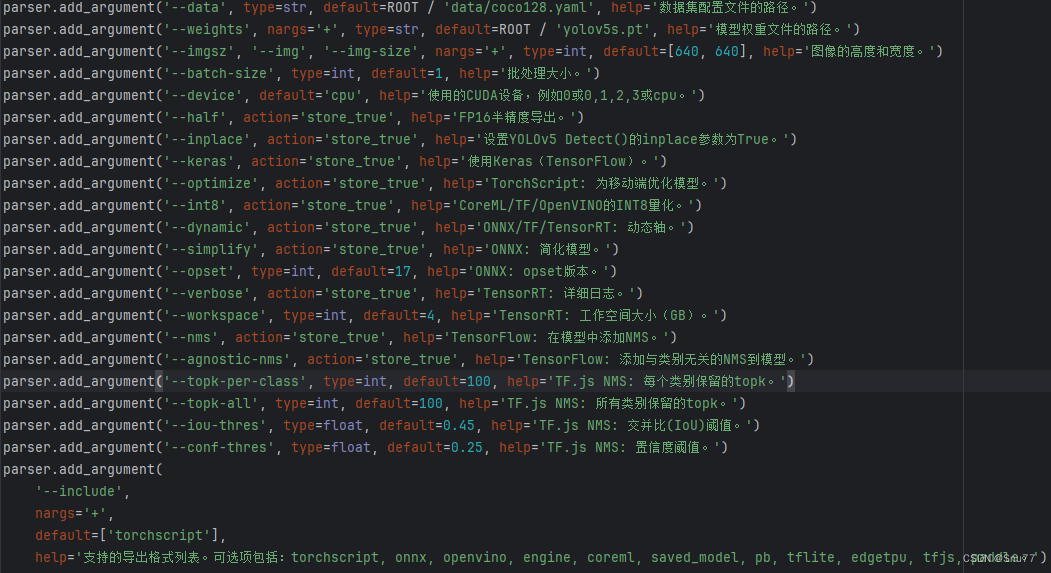
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='数据集配置文件的路径。')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='模型权重文件的路径。')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='图像的高度和宽度。')
parser.add_argument('--batch-size', type=int, default=1, help='批处理大小。')
parser.add_argument('--device', default='cpu', help='使用的CUDA设备,例如0或0,1,2,3或cpu。')
parser.add_argument('--half', action='store_true', help='FP16半精度导出。')
parser.add_argument('--inplace', action='store_true', help='设置YOLOv5 Detect()的inplace参数为True。')
parser.add_argument('--keras', action='store_true', help='使用Keras(TensorFlow)。')
parser.add_argument('--optimize', action='store_true', help='TorchScript: 为移动端优化模型。')
parser.add_argument('--int8', action='store_true', help='CoreML/TF/OpenVINO的INT8量化。')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: 动态轴。')
parser.add_argument('--simplify', action='store_true', help='ONNX: 简化模型。')
parser.add_argument('--opset', type=int, default=17, help='ONNX: opset版本。')
parser.add_argument('--verbose', action='store_true', help='TensorRT: 详细日志。')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: 工作空间大小(GB)。')
parser.add_argument('--nms', action='store_true', help='TensorFlow: 在模型中添加NMS。')
parser.add_argument('--agnostic-nms', action='store_true', help='TensorFlow: 添加与类别无关的NMS到模型。')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: 每个类别保留的topk。')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: 所有类别保留的topk。')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: 交并比(IoU)阈值。')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: 置信度阈值。')
parser.add_argument('--include',nargs='+',default=['torchscript'],help='支持的导出格式列表。可选项包括:torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle。')
相关文章:
详解YOLOv5网络结构/数据集获取/环境搭建/训练/推理/验证/导出/部署
一、本文介绍 本文给大家带来的教程是利用YOLOv5训练自己的数据集,以及有关YOLOv5的网络结构讲解/数据集获取/环境搭建/训练/推理/验证/导出/部署相关的教程,同时通过示例的方式让大家来了解具体的操作流程,过程中还分享给大家一些好用的资源…...

ansible(不能交互)
1、定义 基于python开发的一个配置管理和应用部署工具,在自动化运维中异军突起,类似于xshell一键输入的工具,不需要每次都切换主机进行操作,只要有一台ansible的固定主机,就可以实现所有节点的操作。不需要agent客户端…...
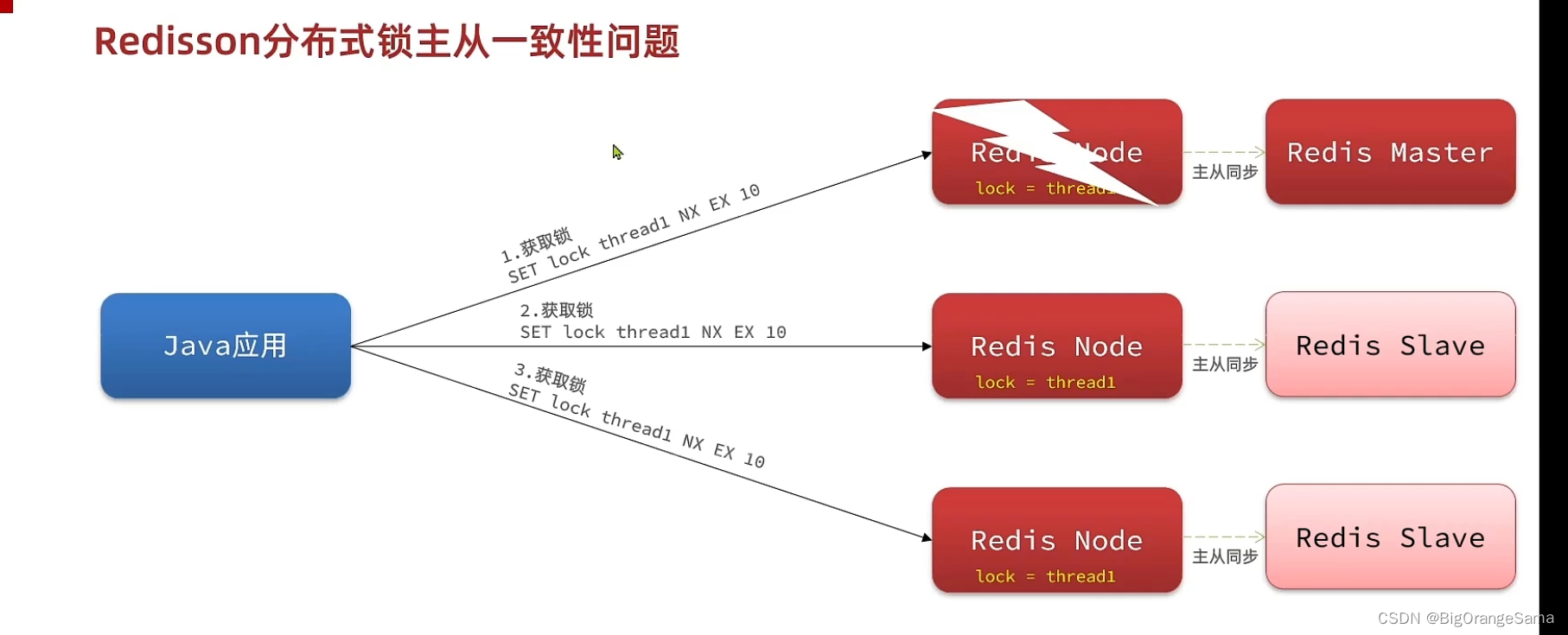
黑马点评06分布式锁 2Redisson
实战篇-17.分布式锁-Redisson功能介绍_哔哩哔哩_bilibili 1.还存在的问题 直接实现很麻烦,借鉴已有的框架。 2.Redisson用法 3.Redisson可重入原理 在获取锁的时候,看看申请的线程和拿锁的线程是否一致,然后计算该线程获取锁的次数。一个方法…...

深度剖析知识图谱:方法、工具与实战案例
💂 个人网站:【 海拥】【神级代码资源网站】【办公神器】🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交流的小伙伴,请点击【全栈技术交流群】 知识图谱作为一种强大的知识表示和关联技术&am…...

Oracle中的dblink简介
Oracle中的dblink简介 是一种用于在不同数据库之间进行通信和数据传输的工具。它允许用户在一个数据库中访问另一个数据库中的对象,而无需在本地数据库中创建这些对象。 使用dblink,用户可以在一个数据库中执行SQL语句,然后访问另一个数据库中…...
ubuntu安装显卡驱动过程中遇到的错误,及解决办法!
ubuntu安装显卡驱动的过程中,可能会遇到以下问题,可以参考解决办法! 问题1: ERROR: An error occurred while performing the step: "Building kernel modules". See /var/log/nvidia-installer.log for details. …...
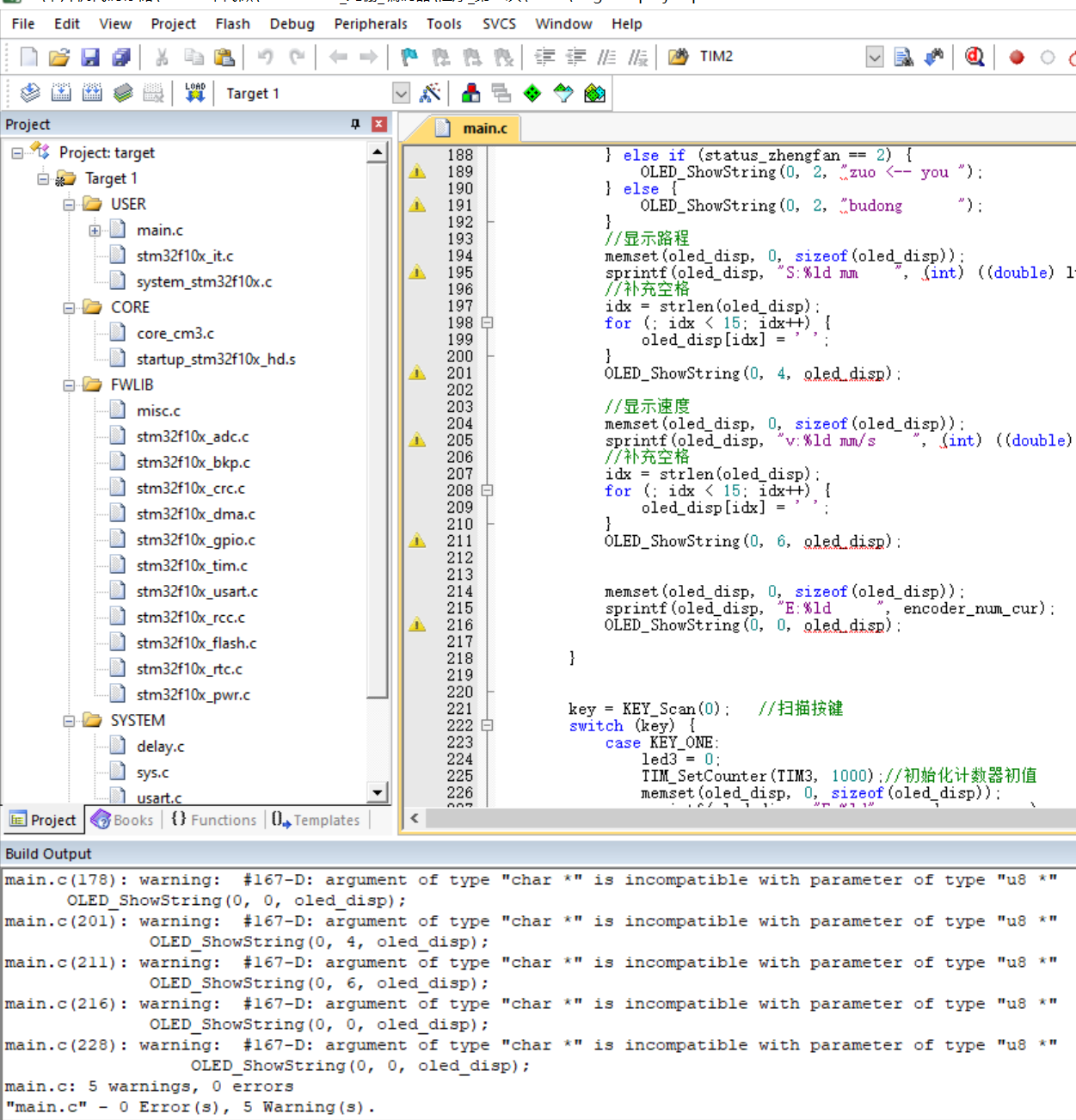
【程序】STM32 读取光栅_编码器_光栅传感器_7针OLED
文章目录 源代码工程编码器基础程序参考资料 源代码工程 源代码工程打开获取: http://dt2.8tupian.net/2/28880a55b6666.pg3这里做了四倍细分,在屏幕上显示 速度、路程、方向。 接线方法: 单片机--------------串口模块 单片机的5V-------…...
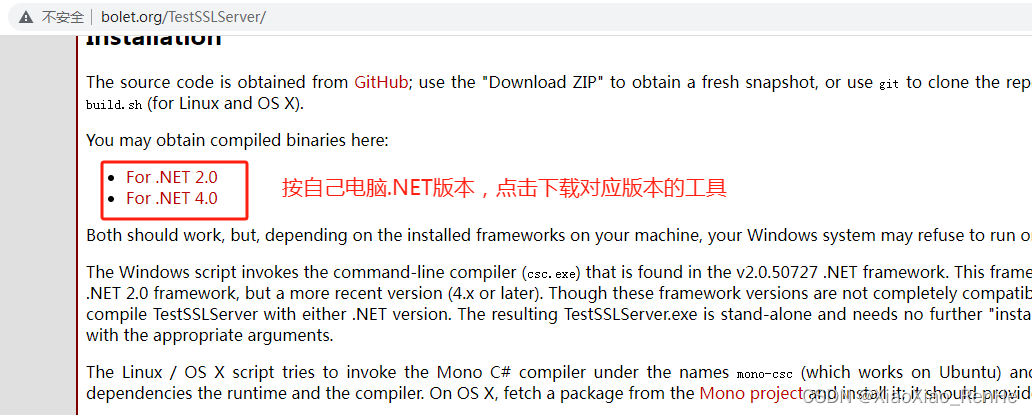
TestSSLServer4.exe工具使用方法简单介绍(查SSL的加密版本SSL3或是TLS1.2)
一、工具使用方法介绍 工具使用方法参照:http://www.bolet.org/TestSSLServer/ 全篇英文看不懂,翻译了下,能用到的简单介绍如下: 将下载的TestSSLServer4.exe工具放到桌面上,CMD命令行进入到桌面目录,执…...

新年跨年烟花超酷炫合集【内含十八个烟花酷炫效果源码】
❤️以下展示为全部烟花特效效果 ❤️下方仅展示部分代码 ❤️源码获取见文末 🎀HTML5烟花喷泉 <style> * {padding:0;margin:0; } html,body {positi...

计算机网络考研辨析(后续整理入笔记)
文章目录 体系结构物理层速率辨析交换方式辨析编码调制辨析 链路层链路层功能介质访问控制(MAC)信道划分控制之——CDMA随机访问控制轮询访问控制 扩展以太网交换机 网络层网络层功能IPv4协议IP地址IP数据报分析ICMP 网络拓扑与转发分析(重点…...
JMESPath语言
JMESPath(JSON Matching Expression Path) 一种查询语言。 主要用于从JSON文档中检索和过滤数据。 通过写表达式提取和处理JSON数据,而无需编写复杂的代码。 功能:数据提取、过滤、转换、排序。 场景:处理API响应…...
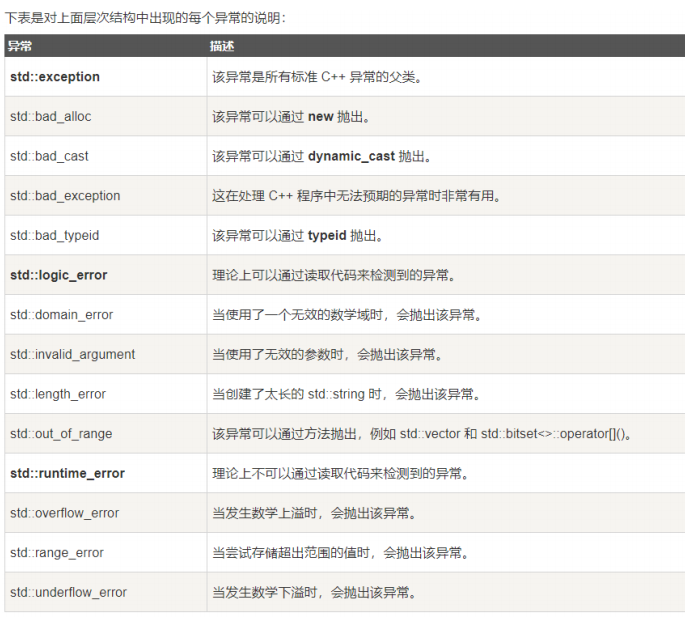
【C++高阶(七)】C++异常处理的方式
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:C从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学习C 🔝🔝 异常处理的方式 1. 前言2. C语言处理异常的方式…...

在Idea中创建基于工件的本地服务
目录 1、创建基于工件的Tomcat服务器: 2、修改名称: 3、修改服务器项: 4、部署项 5、最后记得点右下角的【应用】和【确定】保存。 1、创建基于工件的Tomcat服务器: 运行->编辑配置->【Tomcat服务器】->本地 2、修…...

十六、YARN和MapReduce配置
1、部署前提 (1)配置前提 已经配置好Hadoop集群。 配置内容: (2)部署说明 (3)集群规划 2、修改配置文件 MapReduce (1)修改mapred-env.sh配置文件 export JAVA_HOM…...

自己动手写编译器:语法解析的基本原理
在前面系列章节中我们完成了词法解析。词法解析的基本任务就是判断给定字符串是否符合特定规则,如果符合那么就给这个字符串分配一个标签(token)。词法解析完成后接下来的工作就要分配给语法解析,后者的任务就是判断一系列标签的组合是否符合特定规范。 …...
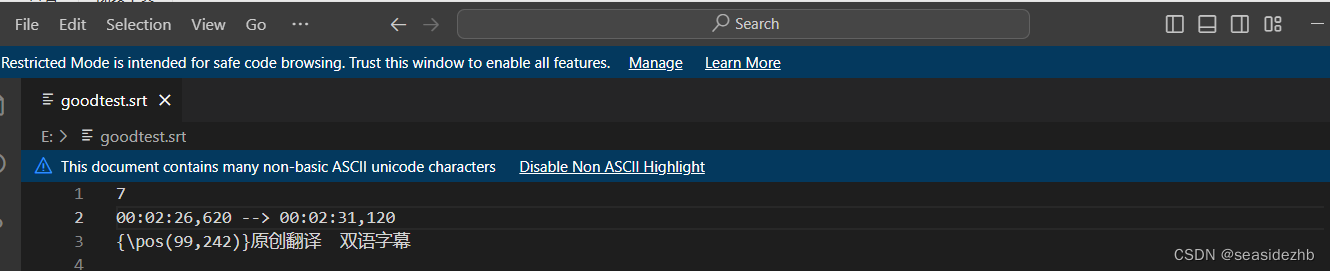
VS Code解决乱码
在上边搜索栏输入“>Change File Encoding”,更改编码格式,解决乱码格式。 VS Code会帮助确认编码格式,然后选择就好。 最后完成如下:...
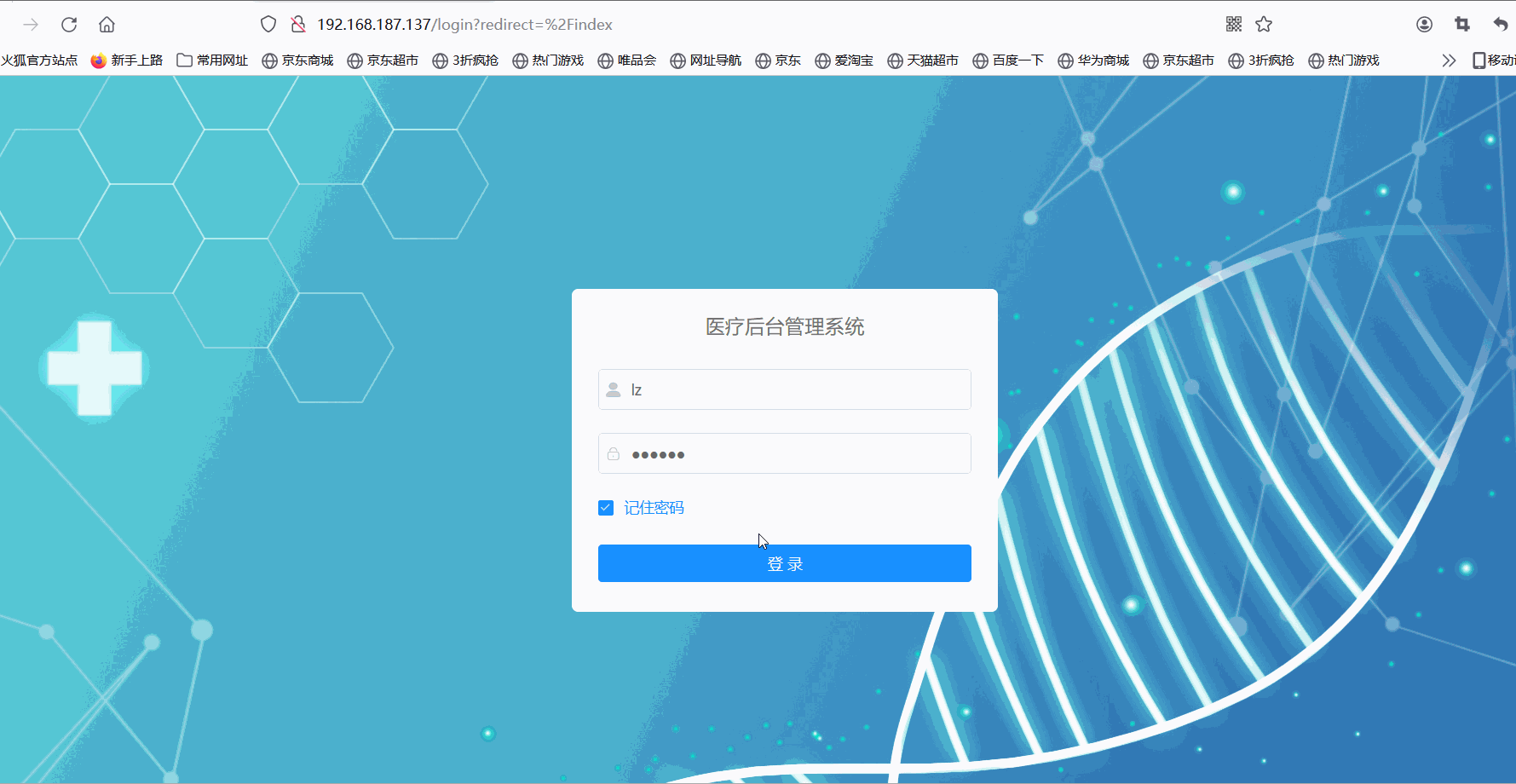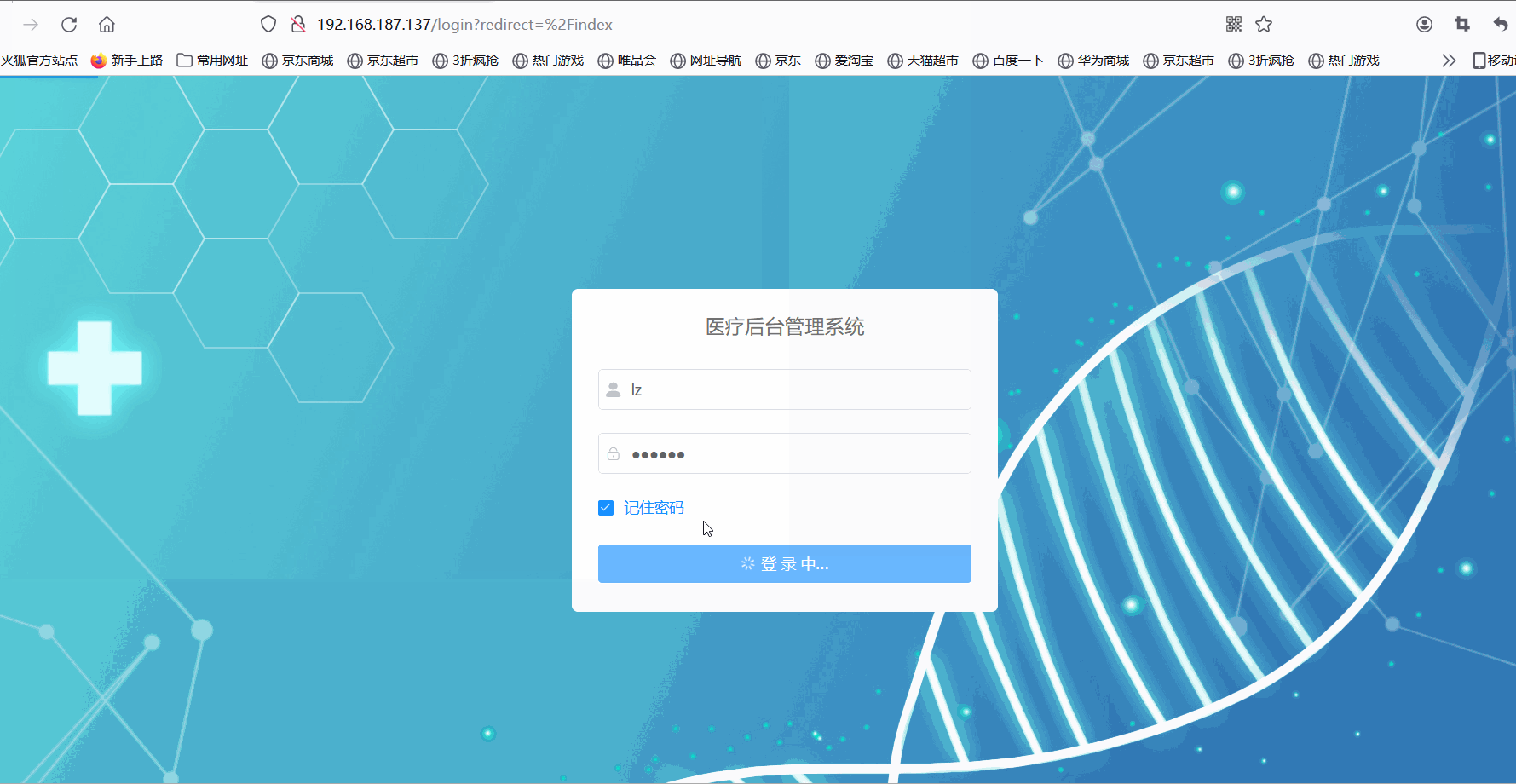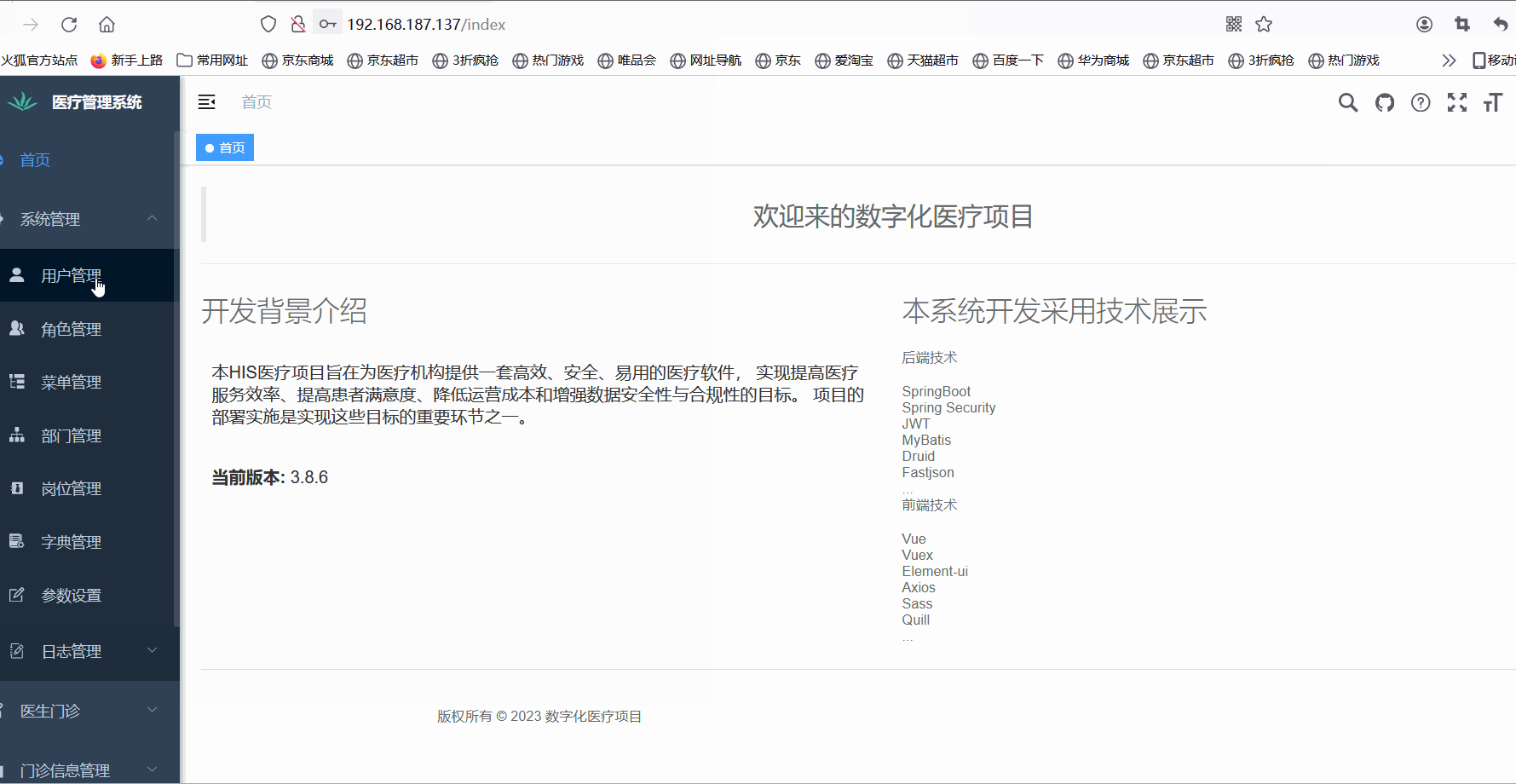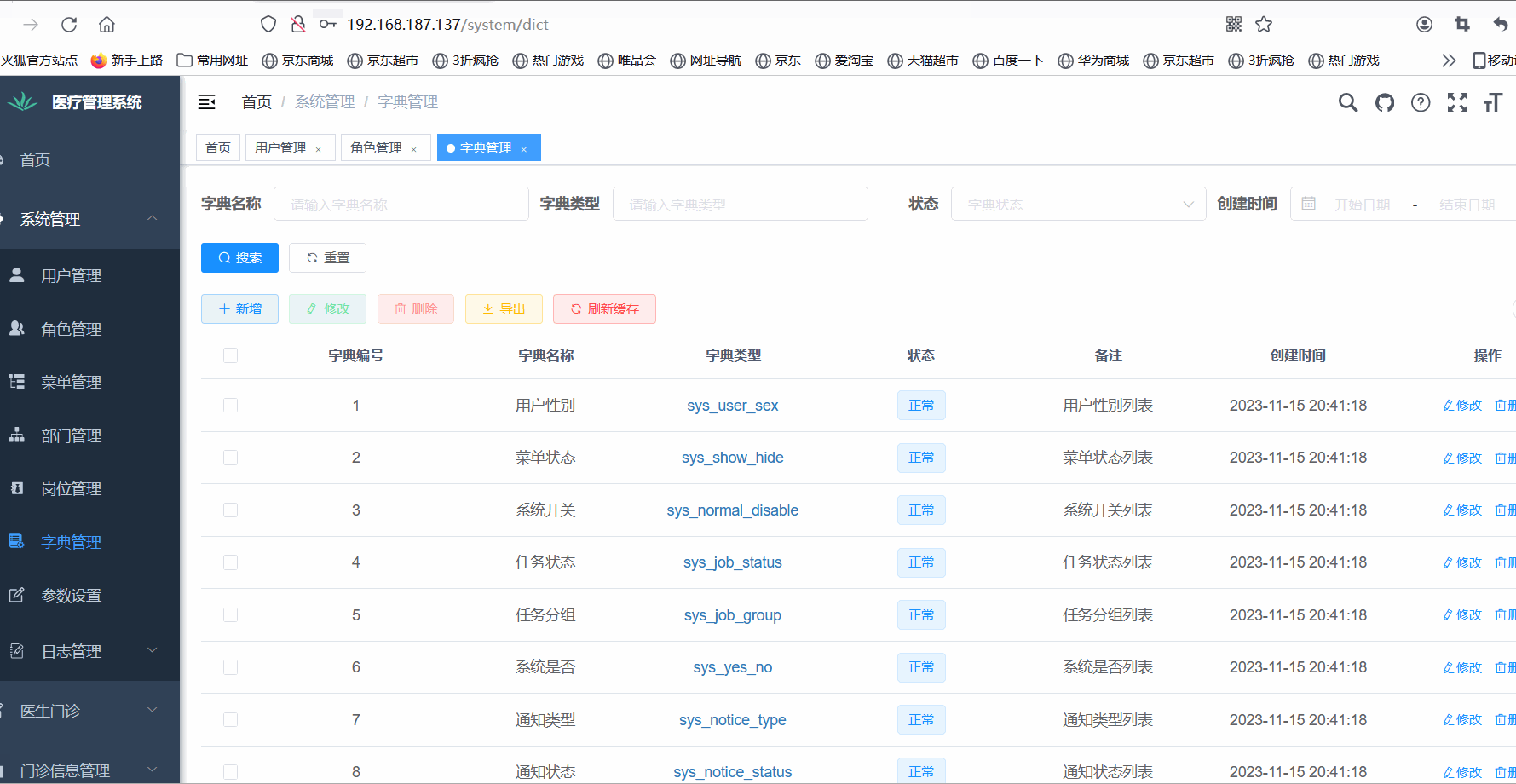
宝塔Linux:部署His医疗项目通过jar包的方式
📚📚 🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有…...

Vim命令大全(超详细,适合反复阅读学习)
Vim命令大全 Vim简介Vim中的模式光标移动命令滚屏与跳转文本插入操作文本删除操作文本复制、剪切与粘贴文本的修改与替换文本的查找与替换撤销修改、重做与保存编辑多个文件标签页与折叠栏多窗口操作总结 Vim是一款文本编辑器,是Vi编辑器的增强版。Vim的特点是快速、…...

爬虫持久化保存
## open方法- 方法名称及参数markdown **open(file, moder, bufferingNone, encodingNone, errorsNone, newlineNone, closefdTrue)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t…...
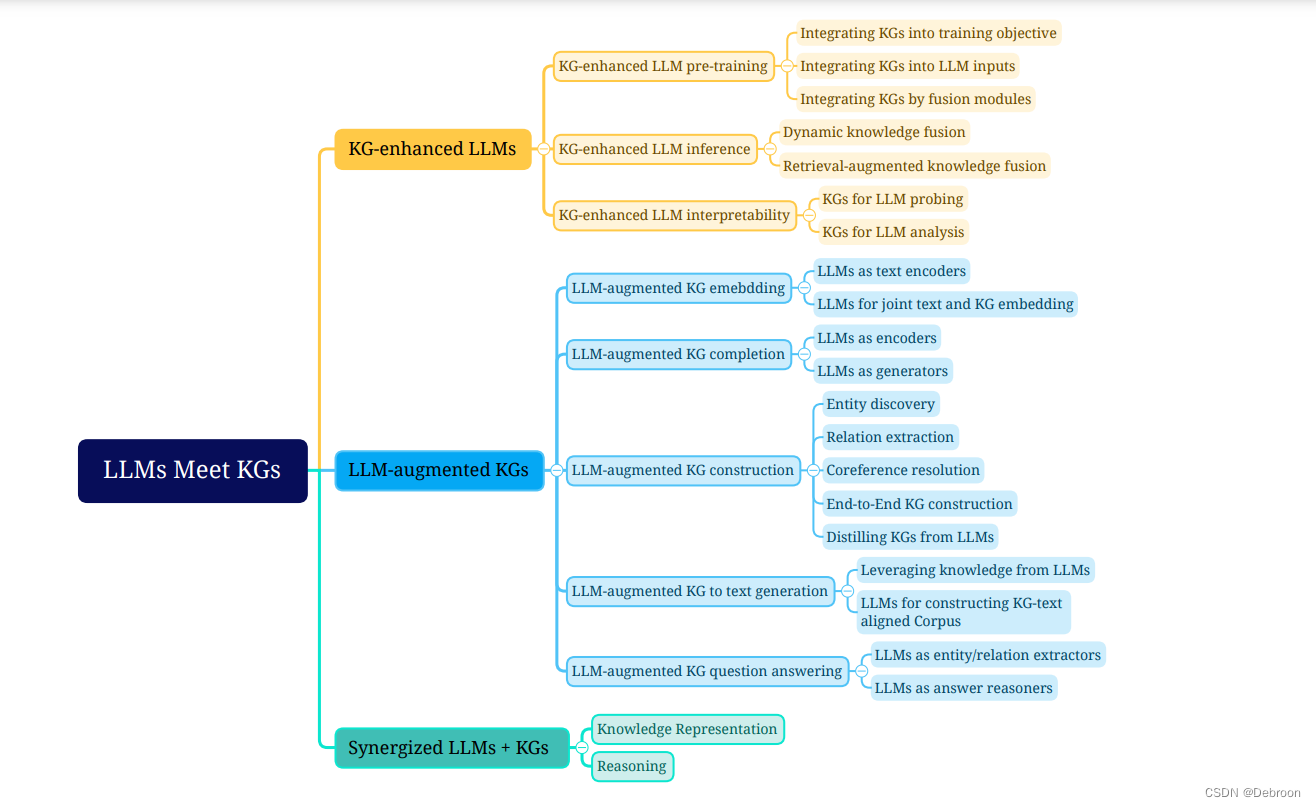
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面? 医学大模型问题如何使用知识图谱加强和补足专业能力?大模型结构知识图谱增强大模型的方法 医学大模型问题 问诊。偏离主诉和没抓住核心。…...

如何用d2s-editor高效管理暗黑破坏神2存档:终极可视化编辑指南
如何用d2s-editor高效管理暗黑破坏神2存档:终极可视化编辑指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor d2s-editor是一款免费开源的Web版暗黑破坏神2存档编辑器,它将复杂的二进制存档文件转化为直…...

3个步骤掌握163MusicLyrics:多平台歌词提取与管理完全指南
3个步骤掌握163MusicLyrics:多平台歌词提取与管理完全指南 【免费下载链接】163MusicLyrics Windows 云音乐歌词获取【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 你是否曾为找不到老歌的歌词而翻遍全网?…...

ViVe完整贡献指南:从入门到精通的开源参与秘籍
ViVe完整贡献指南:从入门到精通的开源参与秘籍 【免费下载链接】ViVe C# library and console app for using new feature control APIs available in Windows 10 version 2004 and newer 项目地址: https://gitcode.com/gh_mirrors/vi/ViVe ViVe是一个C#库&…...

基于python框架的大学生创新创业项目管理系统vue
目录功能模块分析项目管理模块评审管理模块资源协同模块技术实现要点数据安全方案扩展性设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作功能模块分析 用户管理模块 角色划分:学生、导师、管理员(支…...

GPON OMCI抓包避坑指南:Wireshark插件版本、芯片指令与实战解析全流程
GPON OMCI抓包避坑指南:Wireshark插件版本、芯片指令与实战解析全流程 在GPON网络运维和研发过程中,OMCI(ONU Management and Control Interface)协议分析是定位问题的关键手段。但许多工程师在实际操作中常陷入版本兼容性陷阱、芯…...

从零到一:在Simulink中构建SVPWM仿真模型的实践指南
1. 为什么选择Simulink搭建SVPWM模型? 第一次接触电机控制时,我被各种专业术语搞得晕头转向。直到发现Simulink这个可视化工具,才真正理解了SVPWM(空间矢量脉宽调制)的精髓。就像用乐高积木搭建城堡,Simuli…...
)
告别串口线!用STM32F103+W25Q64做个U盘式固件升级器(附完整Keil工程)
STM32SPI Flash打造零门槛U盘固件升级器:从原理到量产实战 在嵌入式设备维护和量产环节,固件升级一直是让开发者头疼的问题。传统串口升级需要专用线缆和上位机软件,而基于STM32和SPI Flash的U盘式升级方案,将复杂的刷机流程简化为…...

MCP协议实战踩坑:当Claude Desktop遇上n8n 1.93.0的混合通信
MCP协议深度解析:从混合通信模型看AI Agent生态兼容性挑战 当Claude Desktop与n8n 1.93.0的MCP协议实现相遇时,表面上的连接故障背后隐藏着AI Agent通信架构的深层设计哲学差异。本文将带您穿透现象看本质,揭示不同MCP实现方案背后的技术权衡…...

终极指南:mozjpeg Trellis量化技术如何实现最佳质量与文件大小平衡
终极指南:mozjpeg Trellis量化技术如何实现最佳质量与文件大小平衡 【免费下载链接】mozjpeg Improved JPEG encoder. 项目地址: https://gitcode.com/gh_mirrors/mo/mozjpeg mozjpeg作为一款优化的JPEG编码器,通过创新的Trellis量化技术…...

深入RealReachability FSM引擎:有限状态机在iOS网络检测中的终极应用指南
深入RealReachability FSM引擎:有限状态机在iOS网络检测中的终极应用指南 【免费下载链接】RealReachability We need to observe the REAL reachability of network. Thats what RealReachability do. 项目地址: https://gitcode.com/gh_mirrors/re/RealReachabi…...