whisper深入-语者分离
文章目录
- 学习目标:如何使用whisper
- 学习内容一:whisper 转文字
- 1.1 使用whisper.load_model()方法下载,加载
- 1.2 使用实例对文件进行转录
- 1.3 实战
- 学习内容二:语者分离(pyannote.audio)pyannote.audio是huggingface开源音色包
- 第一步:安装依赖
- 第二步:创建key
- 第三步:测试pyannote.audio
- 学习内容三:整合
学习目标:如何使用whisper
学习内容一:whisper 转文字
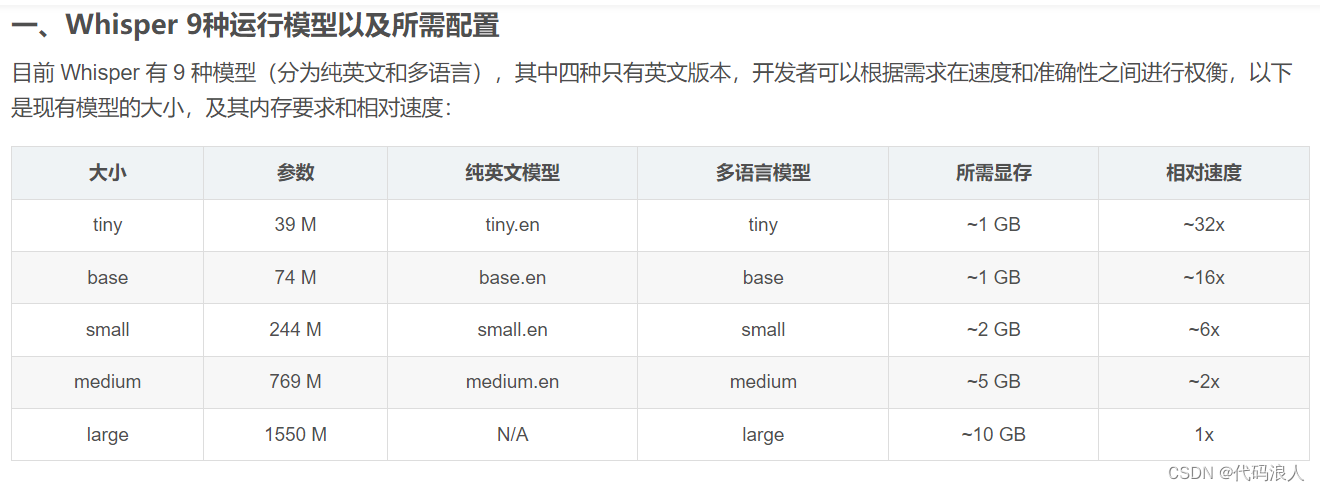
1.1 使用whisper.load_model()方法下载,加载
model=whisper.load_model(参数)
- name 需要加载的模型,如上图
- device:默认有个方法,有显存使用显存,没有使用cpu
- download_root:下载的根目录,默认使用
~/.cache/whisper - in_memory: 是否将模型权重预加载到主机内存中
返回值
model : Whisper
Whisper语音识别模型实例
def load_model(name: str,device: Optional[Union[str, torch.device]] = None,download_root: str = None,in_memory: bool = False,
) -> Whisper:"""Load a Whisper ASR modelParameters----------name : strone of the official model names listed by `whisper.available_models()`, orpath to a model checkpoint containing the model dimensions and the model state_dict.device : Union[str, torch.device]the PyTorch device to put the model intodownload_root: strpath to download the model files; by default, it uses "~/.cache/whisper"in_memory: boolwhether to preload the model weights into host memoryReturns-------model : WhisperThe Whisper ASR model instance"""if device is None:device = "cuda" if torch.cuda.is_available() else "cpu"if download_root is None:default = os.path.join(os.path.expanduser("~"), ".cache")download_root = os.path.join(os.getenv("XDG_CACHE_HOME", default), "whisper")if name in _MODELS:checkpoint_file = _download(_MODELS[name], download_root, in_memory)alignment_heads = _ALIGNMENT_HEADS[name]elif os.path.isfile(name):checkpoint_file = open(name, "rb").read() if in_memory else namealignment_heads = Noneelse:raise RuntimeError(f"Model {name} not found; available models = {available_models()}")with (io.BytesIO(checkpoint_file) if in_memory else open(checkpoint_file, "rb")) as fp:checkpoint = torch.load(fp, map_location=device)del checkpoint_filedims = ModelDimensions(**checkpoint["dims"])model = Whisper(dims)model.load_state_dict(checkpoint["model_state_dict"])if alignment_heads is not None:model.set_alignment_heads(alignment_heads)return model.to(device)
1.2 使用实例对文件进行转录
result = model.transcribe(file_path)
def transcribe(model: "Whisper",audio: Union[str, np.ndarray, torch.Tensor],*,verbose: Optional[bool] = None,temperature: Union[float, Tuple[float, ...]] = (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),compression_ratio_threshold: Optional[float] = 2.4,logprob_threshold: Optional[float] = -1.0,no_speech_threshold: Optional[float] = 0.6,condition_on_previous_text: bool = True,initial_prompt: Optional[str] = None,word_timestamps: bool = False,prepend_punctuations: str = "\"'“¿([{-",append_punctuations: str = "\"'.。,,!!??::”)]}、",**decode_options,
):"""将音频转换为文本。参数:- model: Whisper模型- audio: 音频文件路径、NumPy数组或PyTorch张量- verbose: 是否打印详细信息,默认为None- temperature: 温度参数,默认为(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)- compression_ratio_threshold: 压缩比阈值,默认为2.4- logprob_threshold: 对数概率阈值,默认为-1.0- no_speech_threshold: 无语音信号阈值,默认为0.6- condition_on_previous_text: 是否根据先前的文本进行解码,默认为True- initial_prompt: 初始提示,默认为None- word_timestamps: 是否返回单词时间戳,默认为False- prepend_punctuations: 前缀标点符号,默认为"\"'“¿([{-"- append_punctuations: 后缀标点符号,默认为"\"'.。,,!!??::”)]}、"- **decode_options: 其他解码选项返回:- 转录得到的文本"""
1.3 实战
建议load_model添加参数
- download_root:下载的根目录,默认使用
~/.cache/whisper
transcribe方法添加参数 - word_timestamps=True
import whisper
import arrow# 定义模型、音频地址、录音开始时间
def excute(model_name,file_path,start_time):model = whisper.load_model(model_name)result = model.transcribe(file_path,word_timestamps=True)for segment in result["segments"]:now = arrow.get(start_time)start = now.shift(seconds=segment["start"]).format("YYYY-MM-DD HH:mm:ss")end = now.shift(seconds=segment["end"]).format("YYYY-MM-DD HH:mm:ss")print("【"+start+"->" +end+"】:"+segment["text"])if __name__ == '__main__':excute("large","/root/autodl-tmp/no/test.mp3","2022-10-24 16:23:00")
学习内容二:语者分离(pyannote.audio)pyannote.audio是huggingface开源音色包
第一步:安装依赖
pip install pyannote.audio第二步:创建key
https://huggingface.co/settings/tokens
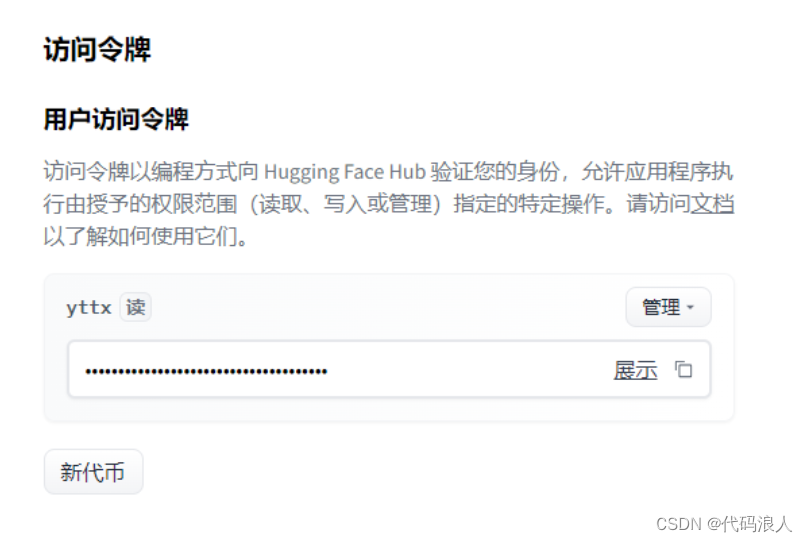
第三步:测试pyannote.audio
- 创建实例:Pipeline.from_pretrained(参数)
- 使用GPU加速:import torch # 导入torch库
pipeline.to(torch.device(“cuda”)) - 实例转化音频pipeline(“test.wav”)
from_pretrained(参数)
- cache_dir:路径或str,可选模型缓存目录的路径。默认/pyannote"当未设置时。
pipeline(参数)
- file_path:录音文件
- num_speakers:几个说话者,可以不带
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization@2.1", use_auth_token="申请的key")# send pipeline to GPU (when available)
import torch
device='cuda' if torch.cuda.is_available() else 'cpu'
pipeline.to(torch.device(device))# apply pretrained pipeline
diarization = pipeline("test.wav")
print(diarization)
# print the result
for turn, _, speaker in diarization.itertracks(yield_label=True):print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
# start=0.2s stop=1.5s speaker_0
# start=1.8s stop=3.9s speaker_1
# start=4.2s stop=5.7s speaker_0
# ...学习内容三:整合
这里要借助一个开源代码,用于整合以上两种产生的结果
报错No module named 'pyannote_whisper'
如果你使用使用AutoDL平台,你可以使用学术代理加速
source /etc/network_turbo
git clone https://github.com/yinruiqing/pyannote-whisper.git
cd pyannote-whisper
pip install -r requirements.txt

这个错误可能是由于缺少或不正确安装了所需的 sndfile 库。sndfile 是一个用于处理音频文件的库,它提供了多种格式的读写支持。
你可以尝试安装 sndfile 库,方法如下:
在 Ubuntu 上,使用以下命令安装:sudo apt-get install libsndfile1-dev
在 CentOS 上,使用以下命令安装:sudo yum install libsndfile-devel
在 macOS 上,使用 Homebrew 安装:brew install libsndfile
然后重新执行如上指令
在项目里面写代码就可以了,或者复制代码里面的pyannote_whisper.utils模块代码
import os
import whisper
from pyannote.audio import Pipeline
from pyannote_whisper.utils import diarize_text
import concurrent.futures
import subprocess
import torch
print("正在加载声纹模型")
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization@2.1",use_auth_token="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")
output_dir = '/root/autodl-tmp/no/out'
print("正在whisper模型")
model = whisper.load_model("large", device="cuda")# MP3转化为wav
def convert_to_wav(path):new_path = ''if path[-3:] != 'wav':new_path = '.'.join(path.split('.')[:-1]) + '.wav'try:subprocess.call(['ffmpeg', '-i', path, new_path, '-y', '-an'])except:return path, 'Error: Could not convert file to .wav'else:new_path = ''return new_path, Nonedef process_audio(file_path):file_path, retmsg = convert_to_wav(file_path)print(f"===={file_path}=======")asr_result = model.transcribe(file_path, initial_prompt="语音转换")pipeline.to(torch.device('cuda'))diarization_result = pipeline(file_path, num_speakers=2)final_result = diarize_text(asr_result, diarization_result)output_file = os.path.join(output_dir, os.path.basename(file_path)[:-4] + '.txt')with open(output_file, 'w') as f:for seg, spk, sent in final_result:line = f'{seg.start:.2f} {seg.end:.2f} {spk} {sent}\n'f.write(line)if not os.path.exists(output_dir):os.makedirs(output_dir)wave_dir = '/root/autodl-tmp/no'# 获取当前目录下所有wav文件名
wav_files = [os.path.join(wave_dir, file) for file in os.listdir(wave_dir) if file.endswith('.mp3')]# 处理每个wav文件
# with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:
# executor.map(process_audio, wav_files)
for wav_file in wav_files:process_audio(wav_file)
print('处理完成!')
相关文章:
whisper深入-语者分离
文章目录 学习目标:如何使用whisper学习内容一:whisper 转文字1.1 使用whisper.load_model()方法下载,加载1.2 使用实例对文件进行转录1.3 实战 学习内容二:语者分离(pyannote.audio)pyannote.audio是huggi…...
LuaJava操作Java的方法
最近在学习lua,然后顺便看了下luaj,可能用的人比较少,网上关于luaj的文章较少,其中在网上找到这个博主的相关文章,很详细,对于要学习luaj的小伙伴可以两篇一起查看,本文在此基础上进行扩展。 …...

oracle怎样才算开启了内存大页?
oracle怎样才算开启了内存大页? 关键核查下面三点: 1./etc/sysctl.conf vm.nr_hugepages16384这是给了32G,计划sga给30G,一般需多分配2-4G sysctl -p生效 看cat /proc/meminfo|grep Huge啥结果? 这种明显是配了…...
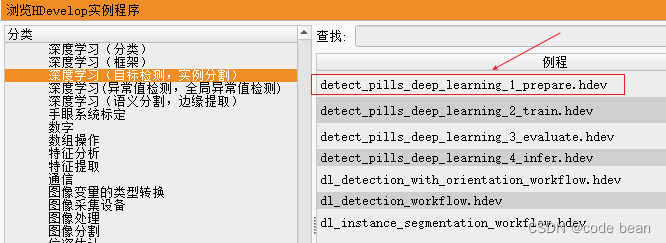
【halcon深度学习之那些封装好的库函数】determine_dl_model_detection_param
determine_dl_model_detection_param 目标检测的数据准备过程中的有一个库函数determine_dl_model_detection_param “determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议…...
跟着我学Python进阶篇:01.试用Python完成一些简单问题
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...

neo4j-Py2neo使用
neo4j-Py2neo(一):基本库介绍使用 py2neo的文档地址:https://neo4j-contrib.github.io/py2neo/ py2neo的本质是可以采用两种方式进行操作,一种是利用cypher语句,一种是使用库提供的DataTypes,Data类的实例需要和远程…...
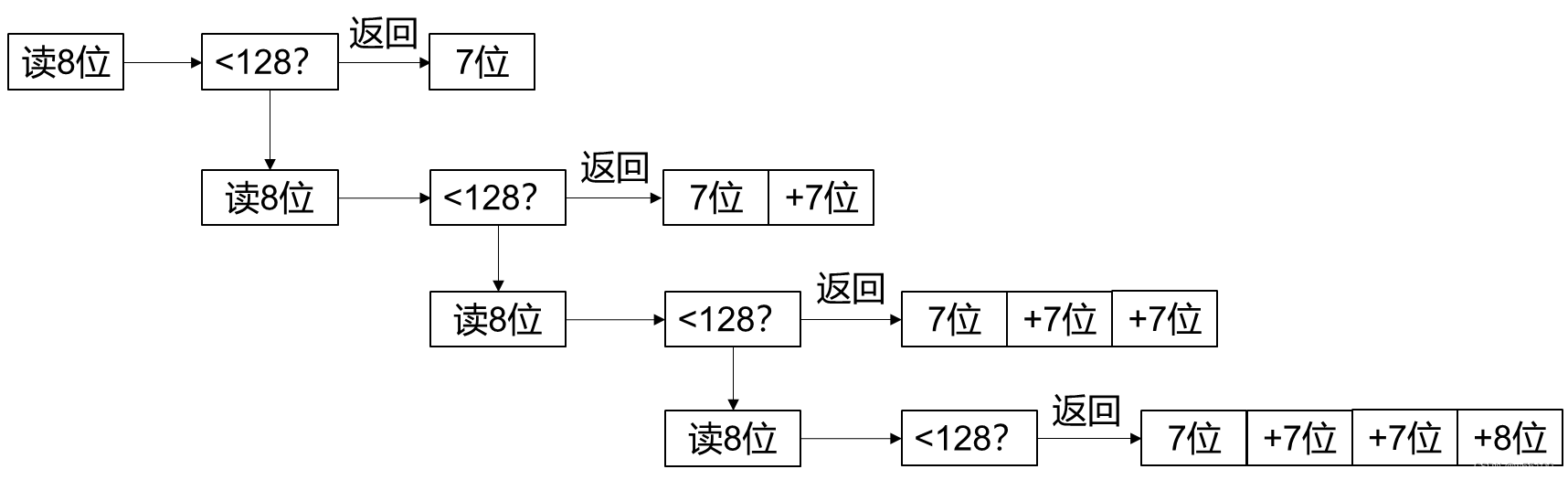
uint29传输格式
前言 不知道谁想出来的。 反正我是想不到。 我看网上也没人讲这个。 写篇博客帮一下素未谋面的网友。 uint29 本质上是网络传输的时候,借用至多4字节Bytes,表达29位的无符号整数。 读8位数字,判断小于128? 是的话,返回末7位…...
Linux:终端定时自动注销
这样防止了,当我们临时离开电脑这个空隙,被坏蛋给趁虚而入 定几十秒或者分钟,如果这个时间段没有输入东西那么就会自动退出 全局生效 这个系统中的所有用户生效 vim /etc/profile在末尾加入TMOUT10 TMOUT10 这个就是10 秒,按…...
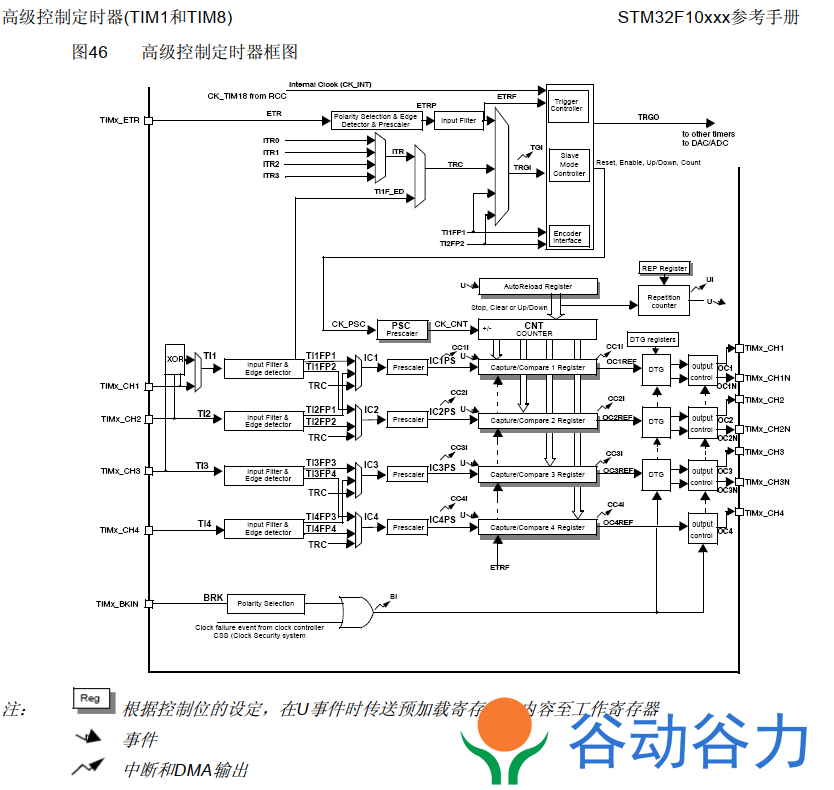
STM32F103RCT6开发板M3单片机教程06--定时器中断
前言 除非特别说明,本章节描述的模块应用于整个STM32F103xx微控制器系列,因为我们使用是STM32F103RCT6开发板是mini最小系统板。本教程使用是(光明谷SUN_STM32mini开发板) STM32F10X定时器(Timer)基础 首先了解一下是STM32F10X…...
数据库故障Waiting for table metadata lock
场景:早上来发现一个程序,链接mysql数据库有点问题,随后排查,因为容器在k8s里面。所以尝试重启了pod没有效果 一、重启pod: 这里是几种在Kubernetes中重启Pod的方法: 删除Pod,利用Deployment重建 kubectl delete pod mypodDepl…...

Springboot数据校验与异常篇
一、异常处理 1.1Http状态码 HTTP状态码是指在HTTP通信过程中,服务器向客户端返回的响应状态。它通过3位数字构成,第一个数字定义了响应的类别,后两位数字没有具体分类作用。以下是常见的HTTP状态码及其含义: - 1xx(信…...

第三十六章 XML 模式的高级选项 - 创建子类型的替换组
文章目录 第三十六章 XML 模式的高级选项 - 创建子类型的替换组创建子类型的替换组将子类限制在替换组中 第三十六章 XML 模式的高级选项 - 创建子类型的替换组 创建子类型的替换组 XML 模式规范还允许定义替换组,这可以是创建选择的替代方法。语法有些不同。无需…...
堆与二叉树(上)
本篇主要讲的是一些概念,推论和堆的实现(核心在堆的实现这一块) 涉及到的一些结论,证明放到最后,可以选择跳过,知识点过多,当复习一用差不多,如果是刚学这一块的,建议打…...

HBase查询的一些限制与解决方案
Apache HBase 是一个开源的、非关系型、分布式数据库,它是 Hadoop 生态系统的一部分,用于存储和处理大量的稀疏数据。HBase 在设计上是为了提供快速的随机读写能力,但与此同时,它也带来了一些查询上的限制: 没有SQL支持…...

软件开发 VS Web开发
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 目录 介绍: 角色和职责: 软件开发人员: Web开发人员: 技能: 软件开发人员: Web开发人…...
基于Springboot的旅游网站设计与实现(论文+调试+源码)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...
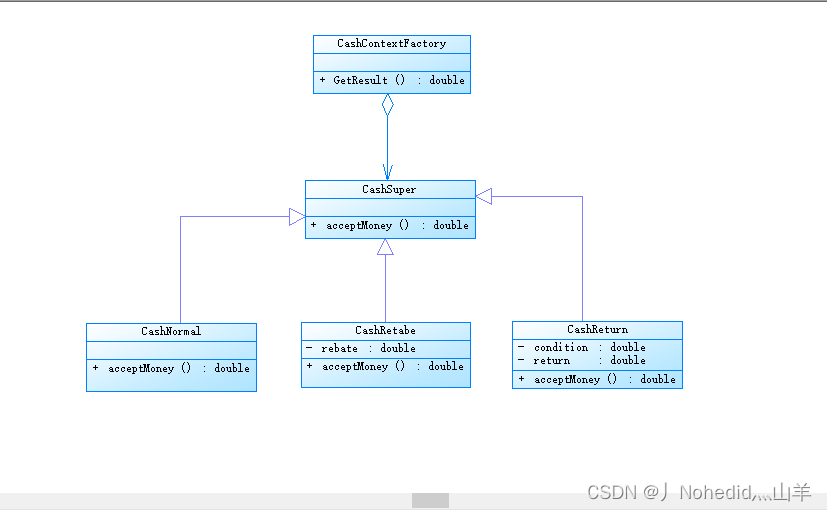
【从零开始学习--设计模式--策略模式】
返回首页 前言 感谢各位同学的关注与支持,我会一直更新此专题,竭尽所能整理出更为详细的内容分享给大家,但碍于时间及精力有限,代码分享较少,后续会把所有代码示例整理到github,敬请期待。 此章节介绍策…...
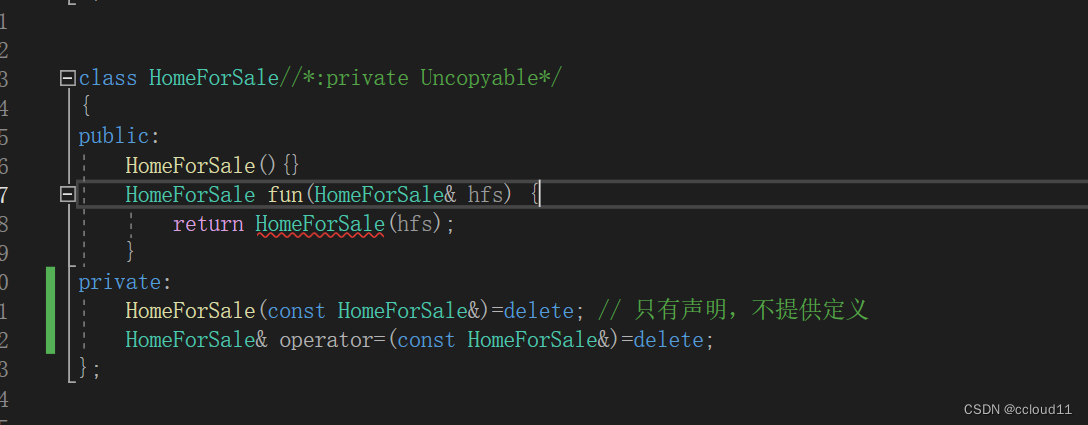
条款6:若不想使用编译器自动生成的函数,就该明确拒绝
有些场景我们不需要编译器默认实现的构造函数,拷贝构造函数,赋值函数,这时候我们应该明确的告诉编译器,我们不需要,一个可行的方法是将拷贝构造函数和赋值函数声明为private。 class HomeForSale { ... }; HomeForSal…...
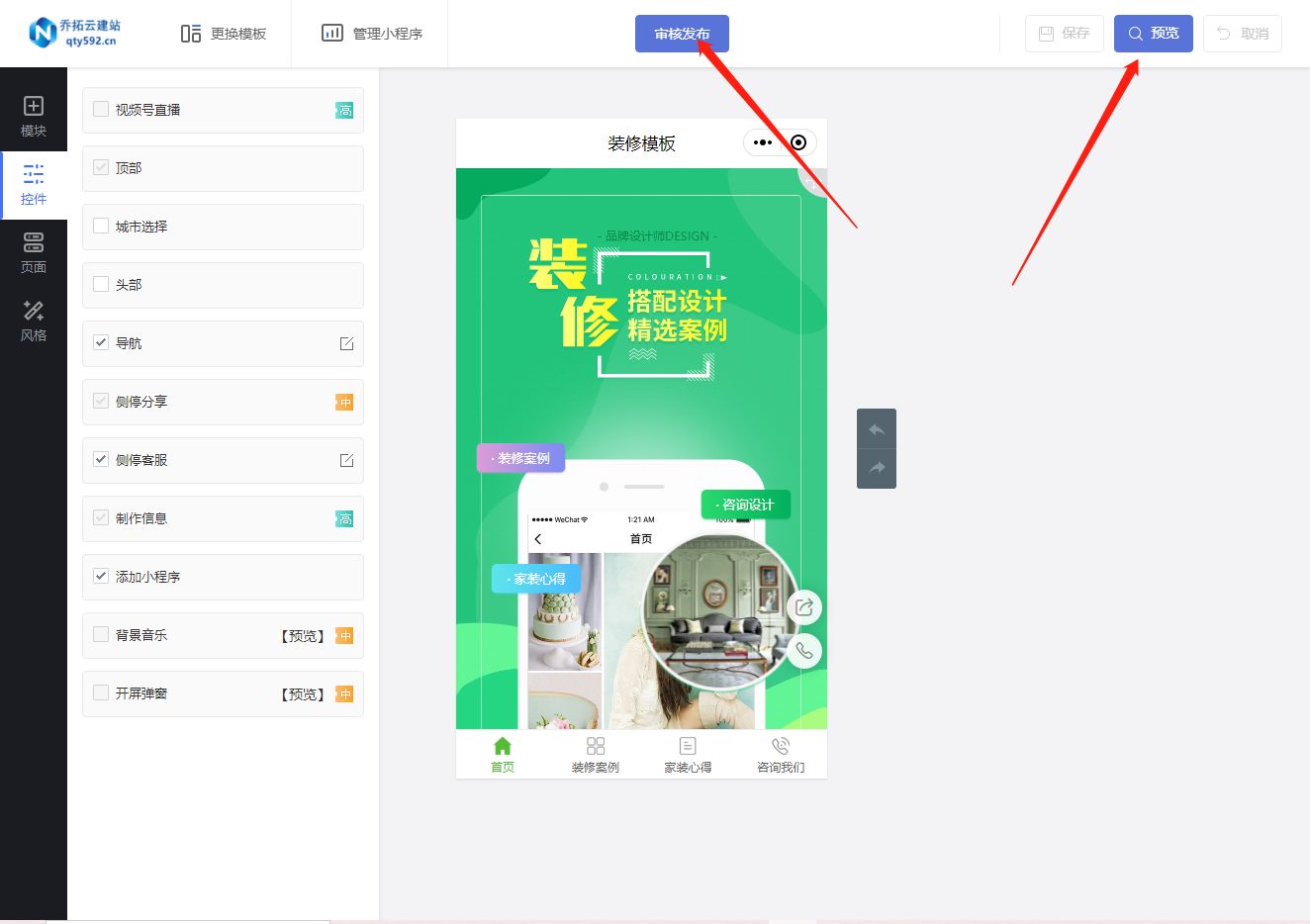
零基础也能制作家装预约咨询小程序
近年来,随着互联网的快速发展,越来越多的消费者倾向于使用手机进行购物和咨询。然而,许多家装实体店却发现自己的客流量越来越少,急需一种新的方式来吸引顾客。而开发家装预约咨询小程序则成为了一种利用互联网技术来解决这一问题…...

Mybatis的插件运⾏原理,如何编写⼀个插件?
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

PEX8796实战解析:从芯片特性到PCIe扩展设计的关键考量
1. PEX8796芯片基础认知与核心特性 第一次拿到PEX8796这颗PCIe交换芯片时,我盯着密密麻麻的引脚图发了半小时呆。作为PLX(现已被博通收购)的经典产品,这颗芯片在工业控制、服务器扩展等领域已经默默服役了十余年。实测中发现&…...

Gmail只读命令行工具gcli:云端自动化邮件查询与SSH隧道授权方案
1. 项目概述:一个专为自动化场景设计的Gmail只读命令行工具 如果你和我一样,经常需要在没有图形界面的云服务器上处理邮件查询任务,那你一定对Gmail API的授权流程深恶痛绝。传统的OAuth流程要求你在浏览器里点来点去,但服务器上哪…...

nimbus-router:声明式路由增强框架,解决SPA复杂路由管理痛点
1. 项目概述:一个为现代前端应用量身定制的路由解决方案 如果你和我一样,在过去几年里深度参与过大型前端项目的开发,那你一定对路由管理这个“甜蜜的负担”深有体会。一方面,像 React Router、Vue Router 这样的库已经非常成熟&a…...

Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你
Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你 在Python开发中,依赖管理是每个开发者必须掌握的核心技能。无论是数据科学家搭建机器学习环境,还是Web开发者部署Django应用,都离不开Python包的安装与…...

EMAC寄存器配置与网络性能优化实战
1. EMAC寄存器概述与核心功能以太网媒体访问控制器(EMAC)是现代嵌入式系统中实现网络通信的核心硬件模块,其寄存器配置直接决定了数据传输的可靠性、实时性和效率。作为硬件与协议栈之间的桥梁,EMAC通过精心设计的寄存器组实现了对…...

Gemini 辅助做创意写作:故事大纲、角色设定、世界观构建的 AI 协作
很多作者在创作卡壳时,其实不是“没有灵感”,而是缺一套可迭代的设计流程:大纲松散、角色像说明书、世界观看似宏大却前后不一致。2026 年的写作新趋势,是把 Gemini 当作“创作协作伙伴”而不是“代写引擎”,让它参与结…...

从行业会议议程到个人技能地图:嵌入式工程师系统化成长指南
1. 从行业盛会到个人技能地图:如何将MASTERs会议的精髓转化为你的嵌入式成长引擎又到了一年一度技术人“充电”的季节。如果你在工业自动化、电机控制或者机器人领域深耕,那么对Microchip Technology这家公司及其产品线一定不会陌生。每年夏天࿰…...

深入解析Arm架构TLB维护机制与A64指令集
1. TLB维护机制基础解析在处理器架构中,TLB(Translation Lookaside Buffer)是内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当CPU需要访问内存时,首先会查询TLB获取地址…...

EdgeRemover:Windows系统终极Edge浏览器管理完全指南
EdgeRemover:Windows系统终极Edge浏览器管理完全指南 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover 你是否…...

GoFrame+Vue3后台管理框架的WebSocket即时通讯实战:架构设计与消息推送
在 GoFrame Vue3 后台管理框架的开发中,即时通讯(IM)是一个高频需求——从站内信到客服系统,从通知推送到协作消息,都离不开 WebSocket 长连接。 XYGo Admin 基于 gorilla/websocket 实现了一套完整的即时通讯体系&a…...