【大数据面试】MapReduce常见问题与答案
目录
介绍下MapReduce
MapReduce优缺点
MapReduce架构
MapReduce工作原理
MapReduce哪个阶段最费时间
✅MapReduce中的Combine是干嘛的?有什么好出?
✅MapReduce环形缓冲区是什么
✅MapReduce为什么一定要有环型缓冲区
MapReduce为什么一定要有Shuffle过程
MapReduce的Shuffle过程及其优化
Reduce怎么知道去哪里拉Map结果集?
Reduce阶段都发生了什么,有没有进行分组
MapReduce Shuffle的排序算法
shuffle为什么要排序?
说一下map是怎么到reduce的?
说一下你了解的用哪几种shuffle机制?
MapReduce的数据处理过程
mapjoin的原理(实现)?应用场景?
reducejoin如何执行(原理)
MapReduce为什么不能产生过多小文件
MapReduce分区及作用
ReduceTask数量和分区数量关系
Map的分片有多大
MapReduce join两个表的流程?
手撕一段简单的MapReduce程序
reduce任务什么时候开始?
MapReduce的reduce使用的是什么排序?
MapReduce怎么确定MapTask的数量?
Map数量由什么决定
MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
MapReduce的task数目划分
MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中么?
Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduece端的数据量会怎么变?
map输出的数据如何超出它的小文件内存之后,是落地到磁盘还是落地到HDFS中?
Map到Reduce默认的分区机制是什么?
结合wordcount述说MapReduce,具体各个流程,map怎么做,reduce怎么做
MapReduce数据倾斜产生的原因及其解决方案
Map Join为什么能解决数据倾斜
MapReduce运行过程中会发生OOM,OOM发生的位置?
MapReduce用了几次排序,分别是什么?
MapReduce压缩方式
MapReduce中怎么处理一个大文件
介绍下MapReduce
MapReduce优缺点
MapReduce架构
MapReduce工作原理
MapReduce哪个阶段最费时间
✅MapReduce中的Combine是干嘛的?有什么好出?
Combiner合并
1)Combiner是MR程序汇总Mapper和Reducer之外的一种组件
2)Combiner组件的父类就是Reducer
3) Combiner和Reducer组件的区别局在于运行的位置
■ Combiner是在每一个MapTask所在的节点运行 ■ Reducer是接受全局的所有Mapper的输出结果,然后进行运算。
4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减少网络传输量。
5)Combiner能够应用的前提是不能影响最终的业务逻辑。
自定义Combiner实现步骤:
■ 1.自定义一个Combiner并继承Reducer,重写Reduce方法 ■ 2.在Job驱动中配置使用。
✅MapReduce环形缓冲区是什么
环形缓冲区分为三块,空闲区、数据区、索引区。初始位置取名叫做“赤道”,就是圆环上的白线那个位置。初始状态的时候,数据和索引都为0,所有空间都是空闲状态。数据是从赤道的右边开始写入,索引(每次申请4kb)是从赤道是左边开始写,两个文件是独立的,执行期间互不干涉。
在数据和索引的大小到了mapreduce.map.sort.spill.percent参数设置的比例时(默认80%,这个是调优的参数),会有两个动作:
1、对写入的数据进行原地排序,并把排序好的数据和索引spill到磁盘上去;
2、在空闲的20%区域中,重新算一个新的赤道,然后在新赤道的右边写入数据,左边写入索引;
3、当20%写满了,但是上一次80%的数据还没写到磁盘的时候,程序就会panding一下,等80%空间腾出来之后再继续写。
如此循环往复,永不停歇,直到所有任务全部结束。整个操作都在内存,形状像一个环,所以才叫环形缓冲区。
✅MapReduce为什么一定要有环型缓冲区
环形缓冲区不需要重新申请新的内存,始终用的都是这个内存空间。大家知道MR是用java写的,而Java有一个最讨厌的机制就是Full GC。Full GC总是会出来捣乱,这个bug也非常隐蔽,发现了也不好处理。环形缓冲区从头到尾都在用那一个内存,不断重复利用,因此完美的规避了Full GC导致的各种问题,同时也规避了频繁申请内存引发的其他问题。
另外呢,环形缓冲区同时做了两件事情:1、排序;2、索引。在这里一次排序,将无序的数据变为有序,写磁盘的时候顺序写,读数据的时候顺序读,效率高非常多!
在这里设置索引区也是为了能够持续的处理任务。每读取一段数据,就往索引文件里也写一段,这样在排序的时候能加快速度。
MapReduce为什么一定要有Shuffle过程
MapReduce的Shuffle过程及其优化
Reduce怎么知道去哪里拉Map结果集?
Reduce阶段都发生了什么,有没有进行分组
MapReduce Shuffle的排序算法
shuffle为什么要排序?
说一下map是怎么到reduce的?
说一下你了解的用哪几种shuffle机制?
MapReduce的数据处理过程
mapjoin的原理(实现)?应用场景?
reducejoin如何执行(原理)
MapReduce为什么不能产生过多小文件
MapReduce分区及作用
ReduceTask数量和分区数量关系
Map的分片有多大
MapReduce join两个表的流程?
手撕一段简单的MapReduce程序
reduce任务什么时候开始?
MapReduce的reduce使用的是什么排序?
MapReduce怎么确定MapTask的数量?
Map数量由什么决定
MapReduce的map进程和reducer进程的ivm垃圾回收器怎么选择可以提高吞吐量?
MapReduce的task数目划分
MapReduce作业执行的过程中,中间的数据会存在什么地方?不会存在内存中么?
Mapper端进行combiner之后,除了速度会提升,那从Mapper端到Reduece端的数据量会怎么变?
map输出的数据如何超出它的小文件内存之后,是落地到磁盘还是落地到HDFS中?
Map到Reduce默认的分区机制是什么?
结合wordcount述说MapReduce,具体各个流程,map怎么做,reduce怎么做
MapReduce数据倾斜产生的原因及其解决方案
Map Join为什么能解决数据倾斜
MapReduce运行过程中会发生OOM,OOM发生的位置?
MapReduce用了几次排序,分别是什么?
MapReduce压缩方式
MapReduce中怎么处理一个大文件
参考:大数据(MapReduce)面试题及答案_牛客网
相关文章:

【大数据面试】MapReduce常见问题与答案
目录 介绍下MapReduce MapReduce优缺点 MapReduce架构 MapReduce工作原理 MapReduce哪个阶段最费时间 ✅MapReduce中的Combine是干嘛的?有什么好出? ✅MapReduce环形缓冲区是什么 ✅MapReduce为什么一定要有环型缓冲区 MapReduce为什么一定要有Shuffle过程 MapRedu…...

数组深入学习感悟
注:本文学习借鉴于《代码随想录》 一.介绍数组 数组是储存在连续内存空间中的相同类型数据的集合 数组名的理解: 数组名就是数组⾸元素(第⼀个元素)的地址是对的,但是有两个例外: sizeof(数组名),sizeof中单独放数…...
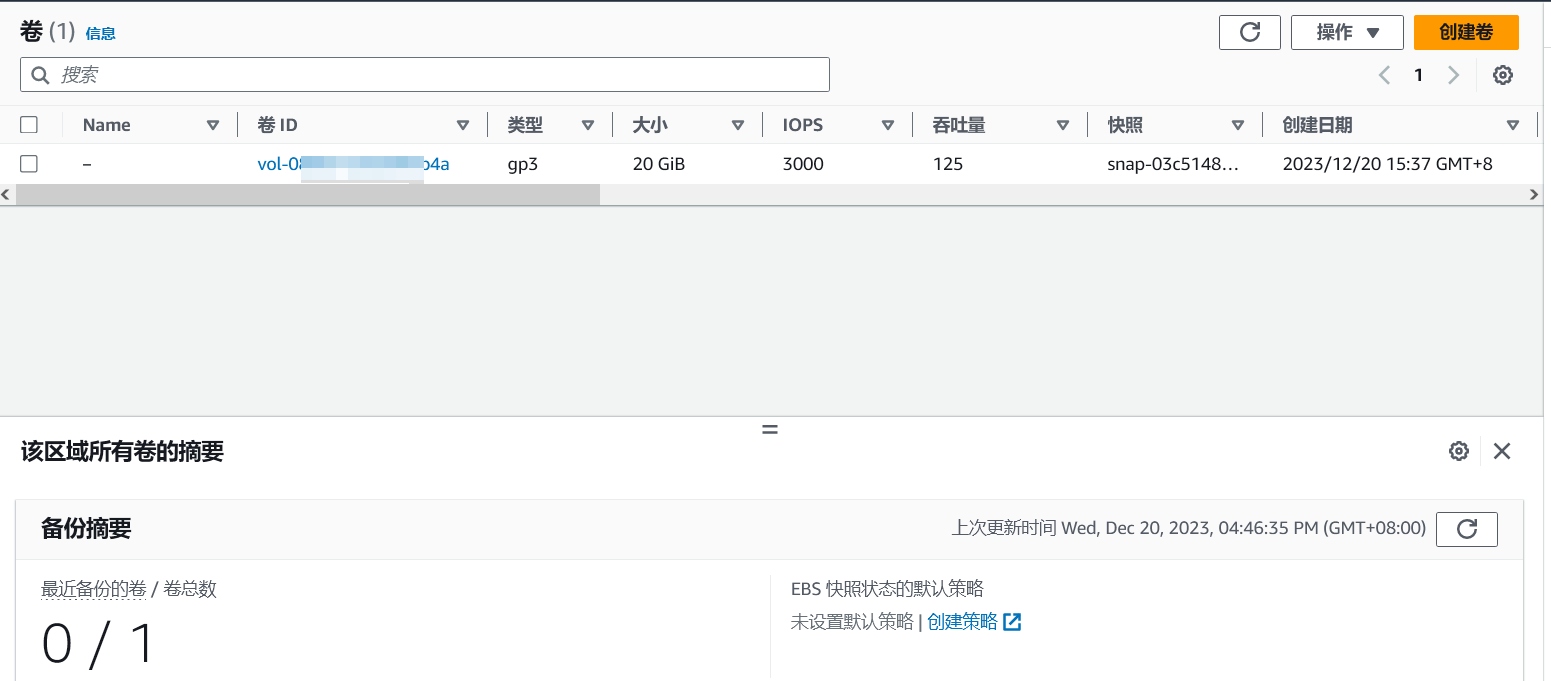
亚马逊云科技-如何缩容/减小您的AWS EC2根卷大小-简明教程
一、背景 Amazon EBS提供了块级存储卷以用于 EC2 实例,EBS具备弹性的特点,可以动态的增加容量、更改卷类型以及修改预配置的IOPS值。但是EBS不能动态的减少容量,在实际使用中,用户也许会存在此类场景: 在创建AWS EC2…...

[Java 基础] Java Stream
Java Stream 是 Java 8 引入的新特性之一,它提供了一种新的处理数据集合的方式。Stream 可以使我们更加方便地对集合进行处理和操作,同时还能提高代码的简洁性和可读性。 文章目录 什么是 Stream常见用法创建 Stream中间操作终端操作 总结 什么是 Stream…...
达芬奇18.6DaVinci ResolveStudio(Win/Mac)激活版
DaVinci Resolve Studio 18是一款业界领先的视频后期制作软件,它集成了剪辑、调色、视觉特效、动态图形和音频后期制作等功能,为用户提供了完整的创作解决方案。该软件不仅适用于电影、电视和网页内容的制作,还广泛应用于广告、纪录片和独立电…...
16. 最接近的三数之和)
力扣题目学习笔记(OC + Swift)16. 最接近的三数之和
16. 最接近的三数之和 给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums 中选出三个整数,使它们的和与 target 最接近。 返回这三个数的和。 假定每组输入只存在恰好一个解。 排序 双指针 思路同15. 三数之和 简单地使用三重循环枚举所有的三…...

基于STM32的DHT11温湿度传感器与LCD显示器的集成设计
在本文中,我们将详细介绍如何基于STM32微控制器实现DHT11温湿度传感器与LCD显示器的集成设计。我们将包括硬件连接、软件编程以及涉及的STM32库函数和相关知识。这个项目旨在帮助您理解如何使用STM32来读取DHT11温湿度传感器的数据,并将数据显示在LCD显示…...

解决浏览器自动将http跳转至https导致无法访问的问题
以下只针对Chrome浏览器 方法一: 1.地址栏中输入chrome://net-internals/#hsts。 2.在Delete domain中输入项目的域名,并Delete(删除)。 3.可以在Query domain测试是否删除成功。 HSTS全称:HTTP Strict Transport Se…...

小程序面试题 | 07.精选小程序面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...

深度学习的推理部分
深度学习的推理部分指的是已经训练好的深度学习模型应用于新数据(通常是测试或实际应用数据)以进行预测、分类、分割等任务的过程。在深度学习中,训练和推理是两个阶段: 训练阶段: 在这个阶段,深度学习模型…...
如何用 CleanMyMac 来保护 Mac 隐私
大家早上好,中午好,下午好,晚上好。 在我们使用MacBook上的自带浏览器-Safari(或者一些其他浏览器)进行网页浏览的时候,往往会留下一些痕迹。如果这些痕迹涉及一些敏感数据信息的话,那么我们肯…...
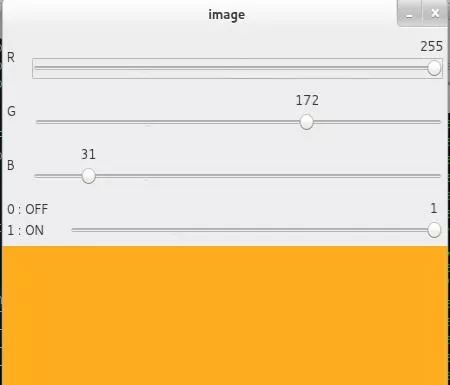
opencv入门到精通——鼠标事件和Trackbar控件的使用
目标 了解如何在OpenCV中处理鼠标事件 您将学习以下功能:cv.setMouseCallback() 了解将轨迹栏固定到OpenCV窗口 您将学习以下功能:cv.getTrackbarPos,cv.createTrackbar等。 简单演示 在这里,我们创建一个简单的应用程序&am…...

iOS 收集 SDK 内部 log
为 SDK 设置 log 等级,设置 RCIMClient 的 logLevel 为您期望的,可以在 SDK initWithAppkey 之后设置,比如希望只收集错误 log,那么可以设置为 RC_Log_Level_Error,如果想一般信息、警告信息,错误信息都收集…...
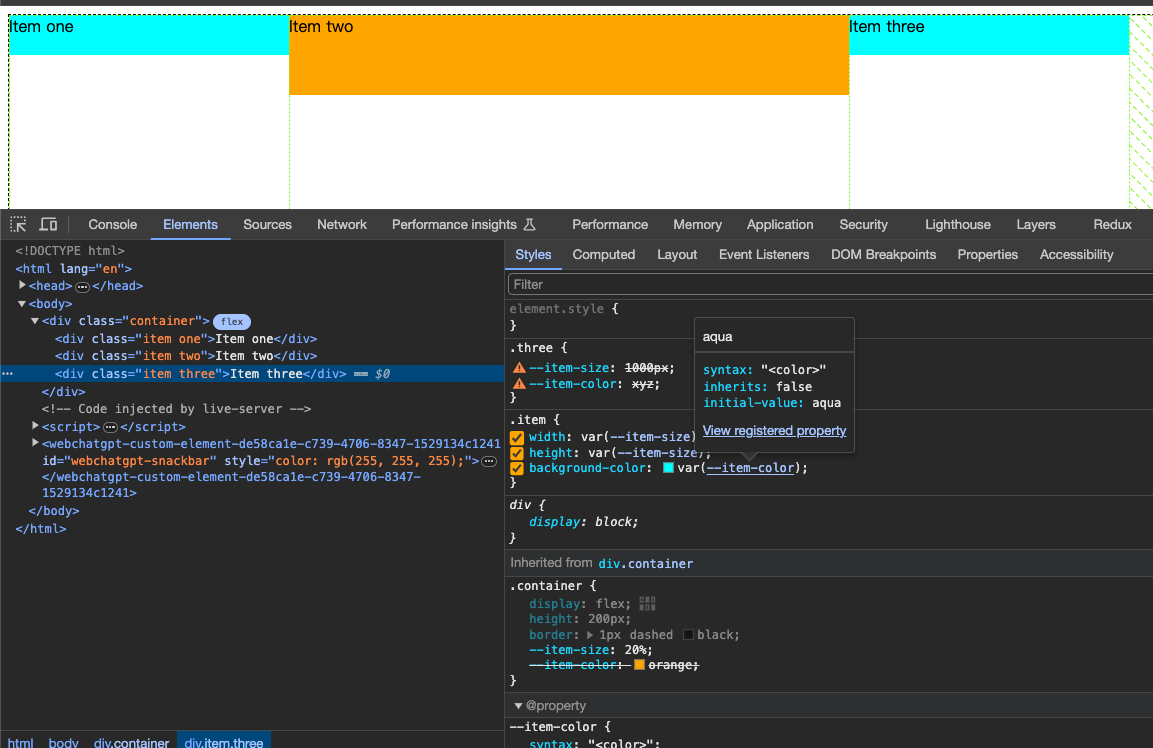
【CSS @property】CSS自定义属性说明与demo
CSS property property - CSS: Cascading Style Sheets | MDN At 规则 - CSS:层叠样式表 | MDN Custom properties (–*): CSS variables - CSS: Cascading Style Sheets | MDN CSS Houdini - Developer guides | MDN 📚 什么是property? property CSS…...

【华为数据之道学习笔记】6-3数据服务分类与建设规范
数据服务是为了更好地满足用户的数据消费需求而产生的,因此数据消费方的差异是数据服务分类的最关键因素。具体包括两大类:数据集服务和数据API服务。 1. 数据集服务 (1)数据集服务定义 比较常见的数据消费者有两类:一…...

Vue的脚手架
脚手架配置 脚手架文档:Vue CLI npm config set registry https://registry.npm.taobao.org vue.config.js配置选项: 配置参考 | Vue CLI ref选项 ref和id类似,给标签打标识。 document.getElementById(btn); this.$ref.btn; 父子组…...

Java实现Word中插入上标和下标
Java实现Word中插入上标和下标 Java不能直接在Word中插入上标和下标,但是可以通过POI库来实现。 下面提供一个Java代码示例,使用POI库向Word中插入带有上标和下标的文字: import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.…...

Java和Python中的目标堆栈规划实现
目标堆栈规划是一种简单高效的人工智能规划算法,用于解决复合目标问题。它的工作原理是**将总体目标分解为更小的子目标,然后以向后的顺序逐一解决它们。 让我们考虑一个简单的例子来说明目标堆栈规划。想象一下你想要烤一个蛋糕,目标是准备…...
后管系统登录后隐藏url上信息同时获取url上携带参数~开发需求(bug)总结7)
(前端)后管系统登录后隐藏url上信息同时获取url上携带参数~开发需求(bug)总结7
问题描述: 首先我这个后管项目是若依权限管理系统,路由实现都是动态加载的。现在有一个需求,后端会邮件发送系统中的链接,这个链接是携带参数(id、用户的加密信息),比如:https://47.23.12.1/task/list?id…...

CSS3新增样式
1,圆角边框 在CSS3中,新增了圆角边框样式,这样我们的盒子就可以变圆角了 border-radious属性用于设置元素的外边框圆角 语法: border-radious:length; radious 半径(圆的半径)原理…...

Exclusively Dark数据集:破解低光照视觉难题的7363张真实图像基准
Exclusively Dark数据集:破解低光照视觉难题的7363张真实图像基准 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very low-li…...

惠普开发了一架3D打印无人机,超轻、超快组装、成功试飞!
3D打印技术参考注意到,惠普于日前自行开发了一架基于增材制造设计的结构优化无人机,来展示使用其MJF技术进行3D打印制造的巨大潜力。它的核心观点是,无人机开发与制造的一个重大挑战,是团队花了几个月时间进行的优化设计ÿ…...

004、TinyML技术栈全景图:从模型到部署
004 TinyML技术栈全景图:从模型到部署 去年冬天调试一个智能门磁项目,板子是STM32L4,Flash只有256KB。模型在PC上跑F1值0.97,烧进去直接死机——不是推理结果不对,是内存分配直接溢出。我盯着map文件看了三个小时,最后发现是TensorFlow Lite Micro的arena大小设错了,多…...
DenseNet参数量比ResNet少?从Bottleneck和Transition层设计,聊聊模型轻量化的核心思路
DenseNet与ResNet参数效率对比:从结构设计看模型轻量化本质 在深度学习模型设计中,参数量与计算效率一直是工程师们关注的核心指标。当DenseNet首次提出时,许多研究者对其参数效率感到惊讶——看似复杂的密集连接结构,实际参数量却…...

稀疏记忆微调技术:解决LLM持续学习中的灾难性遗忘
1. 稀疏记忆微调技术解析 1.1 持续学习的核心挑战 在大型语言模型(LLM)的实际应用中,灾难性遗忘(Catastrophic Forgetting)是持续学习面临的最大障碍。想象一下,当你教会一个学生新知识时,他却…...

工业物联网长距离蓝牙环境监测方案解析
1. 项目概述在工业物联网和远程环境监测领域,如何实现低功耗、长距离的数据传输一直是个技术难点。传统蓝牙技术受限于通信距离(通常10米以内),而Wi-Fi方案又面临功耗过高的问题。最近我在一个工厂环境监测项目中,成功…...

ElevenLabs Enterprise方案深度拆解:从API限流策略到GDPR语音数据主权管理的7层安全加固实践
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs Enterprise方案全景概览 ElevenLabs Enterprise 是面向中大型组织构建的语音合成与语音识别一体化平台,专为高并发、多租户、合规性敏感场景设计。其核心能力覆盖实时TTS流式输出…...

手把手教你用RecFusion和3D Scan:Kinect v2与RealSense D435三维重建完整流程与软件配置
手把手教你用RecFusion和3D Scan:Kinect v2与RealSense D435三维重建完整流程与软件配置 刚拿到Kinect v2或RealSense D435时,许多开发者最迫切的需求不是理解原理,而是快速完成第一次三维扫描。本文将用最简明的操作流,带你在30分…...
实战对比:我们团队为什么最终选了它?)
Davinci vs. 其他开源BI工具(Superset/Metabase)实战对比:我们团队为什么最终选了它?
Davinci vs. 其他开源BI工具实战对比:技术选型的深度思考 在数据驱动决策的时代,企业级BI工具的选择直接影响着数据分析的效率和深度。当我们团队面临开源BI工具选型时,Davinci、Apache Superset和Metabase成为了主要候选对象。经过三个月的实…...

Go+SQLite构建极简自托管笔记共享平台:从原理到部署实战
1. 项目概述:一个极简、自托管的笔记共享平台最近在折腾个人知识管理工具时,我一直在寻找一个能让我快速分享单篇笔记或代码片段,同时又不想依赖第三方云服务的方案。市面上的Pastebin类工具很多,但要么功能臃肿,要么隐…...