2023年12月24日学习总结
今日to do list:
- 做kaggle上面的流量预测项目☠️
- 学习时不刷手机🤡
okkkkkkkkkkkkkk
开始👍🍎

0、我在干什么?
我在预测一个名字叫做elborn基站的下行链路流量,用过去29天的数据预测未来10天的数据
1、import libararies
一般必须都要导入的库有
- import pandas as pd : data processing, like pd.read.csv…
- import numpy as np :线性代数
- import matplotlib.pyplot as plt :画图
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import numpy as np # linear algebra
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
import matplotlib.pyplot as plt
2、加载数据load data
对csv数据使用pandas.read_csv函数读取
一些参数:
- filepath_or_buffer: 文件路径或缓冲区。可以是本地文件路径,也可以是文件对象、URL等
- header: 列名索引。指定数据文件中列名的索引。默认为None,表示没有列名。取值可以是整数,表示第几行为列名;也可以是None,表示自动检测列名;还可以是列表,表示指定列名的位置。
- na_values: 缺失值。指定用于替换缺失值的字符或列表。默认为[‘NA’, ‘null’, ‘NaN’]。
- index_col: 索引列。指定数据文件中用于索引的列。默认为None,表示没有索引列。取值可以是整数,表示第几列用于索引;也可以是列名,表示指定列用于索引。
- sep: 分隔符。用于分隔数据行的字段。默认为逗号,。
- delimiter: 分隔符。与sep类似,但它是更通用的参数,可以用于其他类型的分隔符,如制表符\t等。
elborn_df = pd.read_csv('dataset/ElBorn.csv')
elborn_test_df = pd.read_csv('dataset/ElBorn_test.csv')
3、独家观察数据函数 💓
💥basic_eda💥
- 前五行
- 显示DataFrame的详细信息,包括列名、数据类型、缺失值
- 显示DataFrame的统计摘要信息,包括每列的平均值、标准差、最小值、最大值等
- 显示列名
- 各列的数据类型
- 是否有缺失值
- 是否有NULL值
- 数据的形状
def basic_eda(df):print("-------------------------------TOP 5 RECORDS-----------------------------")print(df.head(5))print("-------------------------------INFO--------------------------------------")print(df.info())print("-------------------------------Describe----------------------------------")print(df.describe())print("-------------------------------Columns-----------------------------------")print(df.columns)print("-------------------------------Data Types--------------------------------")print(df.dtypes)print("----------------------------Missing Values-------------------------------")print(df.isnull().sum())print("----------------------------NULL values----------------------------------")print(df.isna().sum())print("--------------------------Shape Of Data---------------------------------")print(df.shape)print("============================================================================ \n")
basic_eda(elborn_df)
basic_eda(elborn_test_df)
然后画图看一下💥
# 我现在想把elborn_df画出来,横坐标是时间,纵坐标是down,并且横坐标的标签要旋转45度书写
plt.plot(elborn_df.index, elborn_df.down)
plt.xlabel('Time')
plt.ylabel('Down')
plt.title('Down')
# 我想把横坐标的日期标签旋转45
plt.xticks(rotation=45)

在这里面的Python小知识总结(纯小白哈🌸)
- DataFrame.index:将得到DataFrame的索引(日期),作为Series对象
- 如果DataFrame的index是整数,则返回一个从0开始的整数序列
- 0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
Name: index, dtype: int64
- plt.plot():绘制折线的基本函数
以下是一些参数- x: x轴数据,可以是列表、元组、NumPy数组等。
- y: y轴数据,可以是列表、元组、NumPy数组等。
- fmt: 折线图的样式和颜色。
- 例如,'ro-'表示红色圆圈加短横线,
- 'b–'表示蓝色虚线。
- label:为折线图添加一个标签,可以在plt.legend()函数中使用该标签(用于显示图例)。
- linewidth: 折线图的宽度。
- color: 折线图的颜色。
- marker: 折线图的标记形状,例如圆圈、叉号等。
- markeredgecolor: 标记的边缘颜色。
- markerfacecolor: 标记的填充颜色。
- markevery: 标记的间隔,例如每隔10个数据点标记一次。
- plt.xticks(rotation=45):设置x轴刻度标签的位置和显示方式
4、数据预处理pre-processing
(1)将时间戳转换为一个日期时间索引
elborn_df.set_index(pd.DatetimeIndex(elborn_df["time"]), inplace=True)
elborn_df.drop(["time"], axis=1, inplace=True)
(2)填充所有缺失的值
不填充的话后续fit模型的时候会出现loss全部为NAN的情况
elborn_df.down.fillna(elborn_df.down.mean(), inplace=True)
print(elborn_df.isna().sum())
(3)将时间序列数据转换成监督学习数据
在训练监督学习(深度学习)模型前,要把time series数据转化成samples的形式
那什么是sample?有一个输入组件 X X X和一个输出组件 y y y
深度学习模型就是一个映射函数: y = f ( X ) y=f(X) y=f(X)
对于一个单变量的one-step预测:输入组件就是前一个时间步的滞后数据,输出组件就是当前时间步的数据,如下:
X, y
[1, 2, 3], [4]
[2, 3, 4], [5]
[3, 4, 5], [6]
…
这里就是手动转换啦,之前写过使用TimeseriesGenerator自动转换的方法,看看对比
手动转换
def series_to_supervised(data, window=3, lag=1, dropnan=True):cols, names = list(), list()# Input sequence (t-n, ... t-1)for i in range(window, 0, -1):cols.append(data.shift(i))names += [('%s(t-%d)' % (col, i)) for col in data.columns]# Current timestep (t=0)cols.append(data)names += [('%s(t)' % (col)) for col in data.columns]# Target timestep (t=lag)cols.append(data.shift(-lag))names += [('%s(t+%d)' % (col, lag)) for col in data.columns]# Put it all togetheragg = pd.concat(cols, axis=1)agg.columns = namesreturn agg
window =29
lag = 10
elborn_df_supervised = series_to_supervised(elborn_df, window, lag)
(4)数据集划分(split)为训练集和验证集
-
训练集和测试集的区别
- 使用验证集是为了快速调参,也就是用验证集选择超参数(网络层数,网络节点数,迭代次数,学习率这些)。另外用验证集还可以监控模型是否异常(过拟合啦什么的),然后决定是不是要提前停止训练。
- 验证集的关键在于选择超参数,我们手动调参是为了让模型在验证集上的表现越来越好,如果把测试集作为验证集,调参去拟合测试集,就有点像作弊了。
- 而测试集既不参与参数的学习过程,也不参与参数的选择过程,仅仅用于模型评价。
-
训练集在建模过程中会被大量经常使用,验证集用于对模型少量偶尔的调整,而测试集只作为最终模型的评价出现,因此训练集,验证集和测试集所需的数据量也是不一致的,在数据量不是特别大的情况下一般遵循6:2:2的划分比例
-
为了使模型“训练”效果能合理泛化至“测试”效果,从而推广应用至现实世界中,因此一般要求训练集,验证集和测试集数据分布近似。但需要注意,三个数据集所用数据是不同的。
from sklearn.model_selection import train_test_split
label_name = 'down(t+%d)' % (lag)
label = elborn_df_supervised[label_name]
elborn_df_supervised = elborn_df_supervised.drop(label_name, axis=1)
X_train, X_valid, Y_train, Y_valid = train_test_split(elborn_df_supervised, label, test_size=0.4, random_state=0)
print('Train set shape', X_train.shape)
print('Validation set shape', X_valid.shape)
4、创建MLP模型
(1)设置超参数
epochs = 40
batch = 256
lr = 0.0003
adam = optimizers.Adam(lr)
(2)创建模型(keras)
model_mlp = Sequential()
model_mlp.add(Dense(100, activation='relu', input_dim=X_train.shape[1]))
model_mlp.add(Dense(1))
model_mlp.compile(loss='mse', optimizer=adam)
model_mlp.summary()

(3)训练模型
mlp_hitstory = model_mlp.fit(X_train.values, Y_train, epochs=epochs, batch_size=batch, validation_data=(X_valid.values, Y_valid), verbose=2)
(4)画随epoch变化的loss图
# 画图,横坐标是epochs,纵坐标是loss,分别画出train loss和validation loss
import matplotlib.pyplot as pltplt.plot(mlp_hitstory.history['loss'])
plt.plot(mlp_hitstory.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()

(5)计算预测值和实际值之间的均方误差
from sklearn.metrics import mean_squared_error
mlp_train_pred = model_mlp.predict(X_train.values)
mlp_valid_pred = model_mlp.predict(X_valid.values)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, mlp_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_valid, mlp_valid_pred)))
接写到这里吧,今天效率太低了,明天继续

相关文章:
2023年12月24日学习总结
今日to do list: 做kaggle上面的流量预测项目☠️ 学习时不刷手机🤡 okkkkkkkkkkkkkk 开始👍🍎 0、我在干什么? 我在预测一个名字叫做elborn基站的下行链路流量,用过去29天的数据预测未来10天的数据 1、…...

第26关 K8s日志收集揭秘:利用Log-pilot收集POD内业务日志文件
------> 课程视频同步分享在今日头条和B站 大家好,我是博哥爱运维。 OK,到目前为止,我们的服务顺利容器化并上了K8s,同时也能通过外部网络进行请求访问,相关的服务数据也能进行持久化存储了,那么接下来…...

芯科科技以卓越的企业发展和杰出的产品创新获得多项殊荣
2023年共获颁全球及囯內近20个行业奖项 Silicon Labs(亦称“芯科科技”)日前在全球半导体联盟(Global Semiconductor Alliance,GSA)举行的颁奖典礼上,再次荣获最受尊敬上市半导体企业奖,这是公…...

计算机视觉基础(11)——语义分割和实例分割
前言 在这节课,我们将学习语义分割和实例分割。在语义分割中,我们需要重点掌握语义分割的概念、常用数据集、评价指标(IoU)以及经典的语义分割方法(Deeplab系列);在实例分割中,需要知…...

CNAS中兴新支点——什么是软件压力测试?软件压力测试工具和流程
一、含义:软件压力测试是一种测试应用程序性能的方法,通过模拟大量用户并发访问,测试应用程序在压力情况下的表现和响应能力。软件压力测试的目的是发现系统潜在的问题,如内存泄漏、线程锁、资源泄漏等,以及在高峰期或…...
jQuery: 整理3---操作元素的内容
1.html("内容") ->设置元素的内容,包含html标签(非表单元素) <div id"html1"></div><div id"html2"></div>$("#html1").html("<h2>上海</h2>") …...
:项目jar包配置(重要),网关配置,商品服务基础数据设置)
22、商城系统(四):项目jar包配置(重要),网关配置,商品服务基础数据设置
目录 0.重要:整个项目的配置 最外层的pom.xml renren-fast renren-generator xpmall-common xpmall-coupon...

循环链表的学习以及问题汇总
[TOC](循环链表常见的问题) # 问题一: **报错** 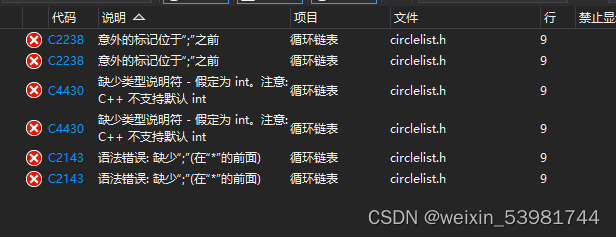 **报错原因:**因为没有提前对_tag_CircleListNode重命名为CircleListNode,所以,在定义…...

C++期末复习总结继承
继承是软件复用的一种形式,他是在现有类的基础上建立新类,新类继承了现有类的属性和方法,并且还拥有了其特有的属性和方法,继承的过程称为派生,新建的类称为派生类(子类),原有的成为…...

CloudCanal x Debezium 打造实时数据流动新范式
简述 Debezium 是一个开源的数据订阅工具,主要功能为捕获数据库变更事件发送到 Kafka。 CloudCanal 近期实现了从 Kafka 消费 Debezium 格式数据,将其 同步到 StarRocks、Doris、Elasticsearch、MongoDB、ClickHouse 等 12 种数据库和数仓,…...

Nodejs+Express搭建HTTPS服务
最近开发需要搭建一个https的服务,正好最近在用nodejs和express,于是乎想到就近就使用这两东西来搭建一个https的服务吧。这里搭建过程总共需要两步,第一步生成证书,第二步使用https模块启动服务。 生成自签名证书 这里因为是自…...

设计模式之-策略模式,快速掌握策略模式,通俗易懂的讲解策略模式以及它的使用场景
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...
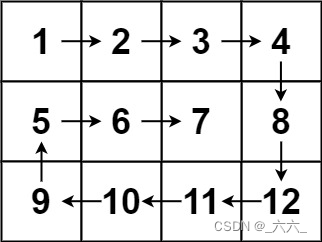
【leetcode100-019】【矩阵】螺旋矩阵
【题干】 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 【思路】 不难注意到,每进行一次转向,都有一行/列被输出(并失效);既然已经失效,那我…...

【计算机视觉中的多视图几何系列】深入浅出理解针孔相机模型
温故而知新,可以为师矣! 一、参考资料 《计算机视觉中的多视图几何-第五章》-Richard Hartley, Andrew Zisserman. 二、针孔模型相关介绍 1. 重要概念 1.1 投影中心/摄像机中心/光心 投影中心称为摄像机中心,也称为光心。投影中心位于一…...
——函数)
轻量级Python IDE使用(三)——函数
1、函数 1.1、函数的概述 在程序设计中,函数的使用可以提升代码的复用率和可维护性。 系统内建函数pow()进行幂运算: a pow(2,4)自定义函数func() def func(a,b):return a ** b afunc(2,4) print(a)自定义函数func(),功能是输出a的b次幂 1.2、函数的定义 py…...
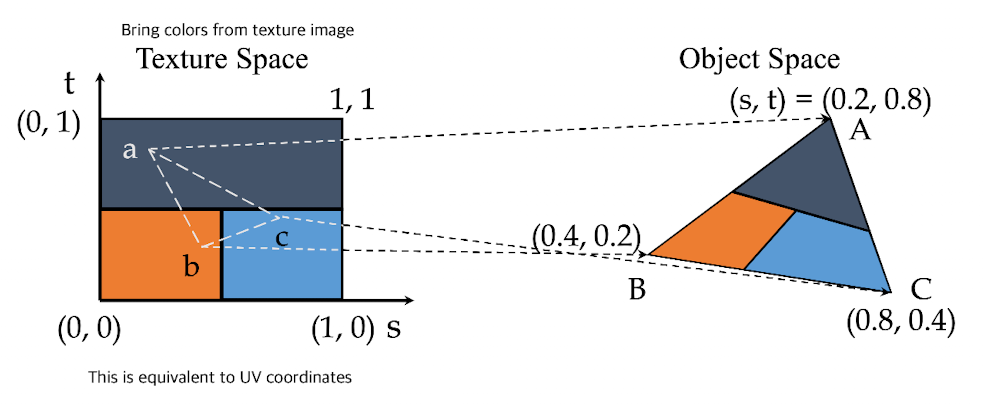
计算机图形学理论(3):着色器编程
本系列根据国外一个图形小哥的讲解为本,整合互联网的一些资料,结合自己的一些理解。 CPU vs GPU CPU支持: 快速缓存分支适应性高性能 GPU支持: 多个 ALU快速板载内存并行任务的高吞吐量(在每个片段、顶点上执行着色…...
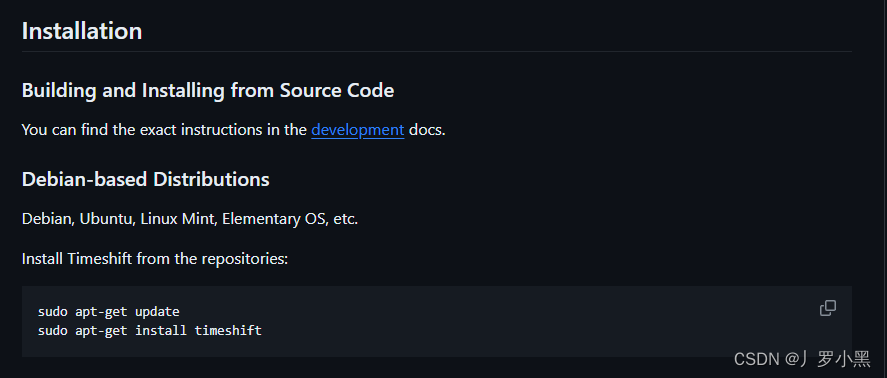
ubuntu20.04安装timeshift最新方法
总结: 现在可以使用如下代码安装 sudo apt-get update sudo apt-get install timeshift原因: 在尝试Timeshift系统备份与还原中的方法时, sudo apt-add-repository -y ppa:teejee2008/ppa运行失败。 更改为以下代码: sudo a…...
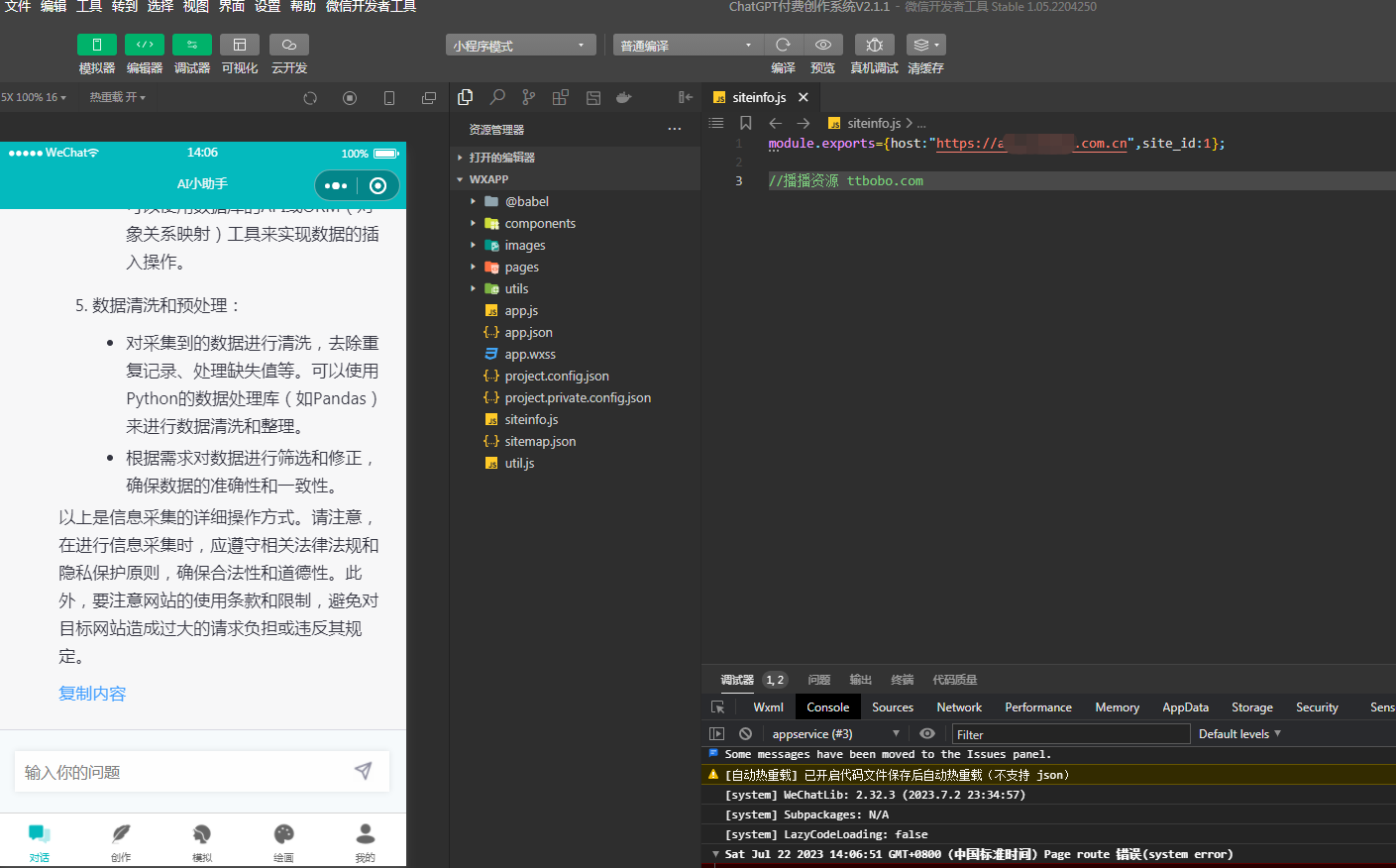
小狐狸ChatGPT付费创作系统小程序端开发工具提示打开显示无法打开页面解决办法
最新版2.6.7版下载:https://download.csdn.net/download/mo3408/88656497 很多会员在上传小程序前端时经常出现首页无法打开的情况,错误提示无法打开该页面,不支持打开,这种问题其实就是权限问题,页面是通过调用web-v…...
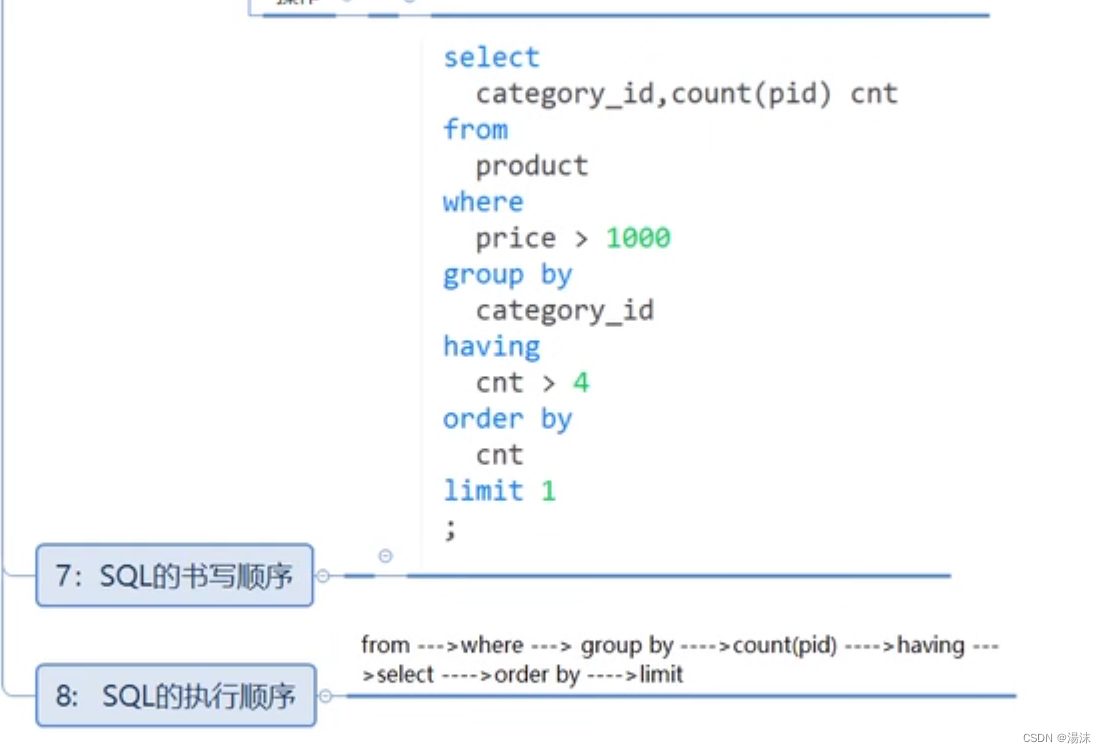
DQL-基本查询
概念: 1,数据库管理系统一个重要功能就是数据查询,数据查询不应只是简单返回数据库中存储的数据,还应该根据需要对数据进行筛选以及确定数据以什么样的格式显示 2,MySQL提供了功能强大、灵活的语句来实现这些操作 3…...
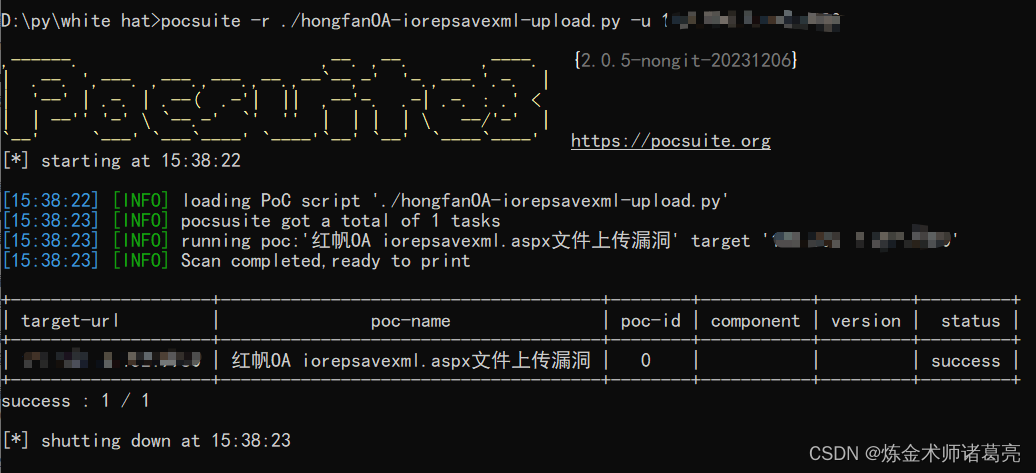
漏洞复现-红帆OA iorepsavexml.aspx文件上传漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...

Go语言系统编程与命令行工具
Go语言系统编程与命令行工具 一、命令行参数解析 Go语言提供了多个标准库来处理命令行参数,包括flag包和os包。 使用flag包 package mainimport ("flag""fmt" )func main() {// 定义命令行参数name : flag.String("name", "Gues…...

OBS多路RTMP推流插件:一站式解决多平台同步直播难题
OBS多路RTMP推流插件:一站式解决多平台同步直播难题 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 还在为每次直播需要在不同平台间手动切换而烦恼吗?obs-multi…...

3个创新视角:重新定义AMD平台内存监控的新范式
3个创新视角:重新定义AMD平台内存监控的新范式 【免费下载链接】ZenTimings 项目地址: https://gitcode.com/gh_mirrors/ze/ZenTimings 在AMD Ryzen平台的性能调优领域,内存时序监控一直是个技术门槛较高的领域。传统监控工具往往停留在表面参数…...

终极免费风扇控制软件:如何让你的电脑既安静又凉爽
终极免费风扇控制软件:如何让你的电脑既安静又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...
:异步事件总线+快照版本向量的组合拳揭秘)
DeepSeek Saga模式性能压测实录(TPS从1.2K飙升至8.6K):异步事件总线+快照版本向量的组合拳揭秘
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Saga模式性能压测实录(TPS从1.2K飙升至8.6K):异步事件总线快照版本向量的组合拳揭秘 在真实生产级负载下,DeepSeek R1模型启用Saga模式后&#…...

域自适应学习研究新进展
篇名问题背景方法其他域自适应学习研究进展目前关于域自适应学 习产生了大量的理论研究成果, 提出了新的学习算 法, 但是这些理论研究所涉及的领域庞杂, 如统计分 类、自然语言处理、情感分析、机器翻译、气象分析 等领域, 研究内容往往涉及域自适应学习的某一方 面, 存在着概念…...

告别笨重MCU:用纯Verilog在FPGA里实现I2C Slave与EEPROM通信
纯Verilog实现FPGA内I2C从机与EEPROM仿真实战指南 当树莓派需要通过I2C读取传感器数据时,传统方案需要外挂一颗AT24C02之类的EEPROM芯片。但如果你手头正好有闲置的FPGA,完全可以用硬件描述语言在可编程逻辑内部虚拟出一个I2C从设备,既能节省…...

避开这些坑!RT-Thread+lwip网卡驱动开发中的5个常见误区与实战解法
RT-Thread与lwIP网卡驱动开发中的五大性能陷阱与实战突围 在嵌入式网络开发领域,RT-Thread与lwIP的组合已经成为许多开发者的首选方案。然而,这套看似成熟的网络协议栈背后,却隐藏着诸多性能陷阱。本文将揭示五个最常见的开发误区,…...

用GitHub仓库构建个人技能树:结构化、版本化知识管理实践
1. 项目概述:从“技能”仓库到个人知识体系的构建最近在GitHub上看到一个挺有意思的仓库,名字叫Apolinariolanga/skills。乍一看,这名字很直白——“技能”。在技术社区里,以“skills”命名的仓库并不少见,但每一个背后…...

告别驱动烦恼:Win10系统下CY7C68013A USB芯片驱动安装与固件烧录保姆级教程
告别驱动烦恼:Win10系统下CY7C68013A USB芯片驱动安装与固件烧录保姆级教程 在硬件开发领域,CY7C68013A作为一款经典的USB 2.0控制芯片,凭借其高性价比和稳定性能,至今仍被广泛应用于各类数据采集、FPGA通信和设备控制场景。然而&…...