差生文具多之(二): perf
栈回溯和符号解析是使用 perf 的两大阻力,本文以应用程序 fio 的观测为例子,提供一些处理它们的经验法则,希望帮助大家无痛使用 perf。
前言
系统级性能优化通常包括两个阶段:性能剖析和代码优化:
-
性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码;
-
代码优化的目标是针对具体性能问题而优化代码或调整编译选项,以改善软件性能。
在步骤一性能剖析阶段,最常用的工具就是 perf。perf 是 linux 官方提供的性能分析工具,被包含在 Linux 内核源码树中。它是一个庞大的工具集合,功能相当繁杂。但在工作中,通常我们只会使用到 perf 其中相当小的一个子集,主要包含以下四个步骤:
-
perf record: 采集数据,采的时间越长越心安;
-
perf report: 查看采集数据,因为采集太长时间,解析数据会卡很久,我们试图理解数据,通常无法理解;
-
perf script: 尝试查看原始采样点,通常无法理解;
-
生成火焰图: 色彩丰富,通常发给领导理解。
综上,后三个步骤是我们无法控制的,本文主要聊聊如何在步骤一尽量生成可信的采样数据。
workflow of perf
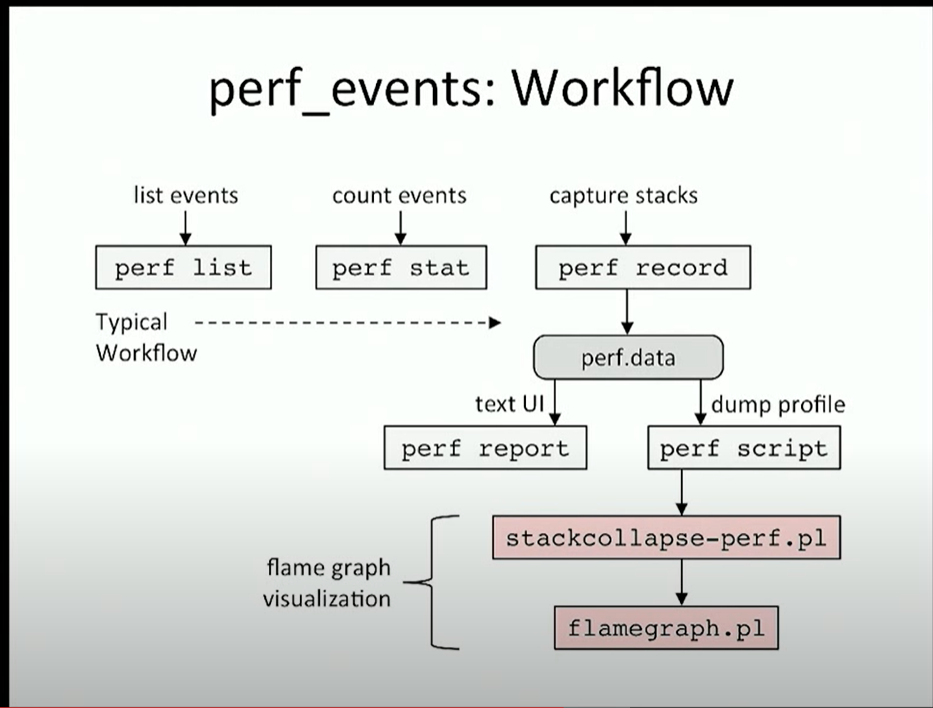
虽然听起来调侃,但上述步骤确实是标准的分析流程,毕竟有火焰图发明人 Brandon 的背书:
@Brandon
可以看到,它们被包含在 perf 工作流第三列的 capture stacks 中,简单回顾一下这四个步骤:
-
perf record: 通过指定 -g 选项可以收集系统整体的函数调用栈(包含用户态和内核态),默认以 4000HZ 的频率收集,大约每秒生成 4000 个采样点,被保存在 perf.data 文件中;
$ perf record -g -C 0 -- sleep 1
[ perf record: Captured and wrote 0.906 MB perf.data (4001 samples) ]
-
perf report: 通过解析 perf.data,生成热点函数占用 CPU 的比例。例如以下输出中,CPU0 大部分时间(99.73%)停留在内核代码的 idle 函数中,即 CPU0 大部分时间处于空闲状态:
$ perf report --no-child --stdio
99.73% swapper [kernel.kallsyms] [k] native_safe_halt|---native_safe_haltacpi_idle_do_entryacpi_idle_entercpuidle_enter_statecpuidle_enterdo_idlecpu_startup_entrystart_kernelsecondary_startup_64_no_verify
-
perf script: 查看每个采样样本(栈),例如以下栈样本表明:
cpu-clock:pppH:事件于时间45399.463561发生,在 CPU0 触发了中断,中断打断的任务是进程号为 0 的内核线程swapper,栈从下往上看,被打断时 CPU 正在执行 native_safe_halt 偏移 0xe 处的指令:
$ perf script
swapper 0 [000] 45399。463561: 250000 cpu-clock:pppH: ffffffffa234c45e native_safe_halt+0xe ([kernel.kallsyms])ffffffffa234c806 acpi_idle_do_entry+0x46 ([kernel.kallsyms])ffffffffa1f4bafb acpi_idle_enter+0x9b ([kernel.kallsyms])ffffffffa211efb7 cpuidle_enter_state+0x87 ([kernel.kallsyms])ffffffffa211f33c cpuidle_enter+0x2c ([kernel.kallsyms])ffffffffa1b16ff4 do_idle+0x234 ([kernel.kallsyms])ffffffffa1b171ef cpu_startup_entry+0x6f ([kernel.kallsyms])ffffffffa3601262 start_kernel+0x518 ([kernel.kallsyms])ffffffffa1a00107 secondary_startup_64_no_verify+0xc2 ([kernel.kallsyms])
-
使用脚本生成火焰图,以下是官网例图:
可以发现,后续的分析步骤都基于步骤一采集得到的 perf.data。显然,只有获取到足够精准的调用栈信息,后续才能准确定位到性能瓶颈。可惜的是,获取函数调用栈并没有一个通用解,导致我们需要额外了解一些小知识。
choose your unwinder
获取函数调用栈过程又称栈回溯(unwind),栈回溯的方法被称为 unwinder,常见的 unwinder 有:
-
fp:perf 默认选项,ARM 和 X86 都支持,消耗低;
-
dwarf:通过
--call-graph=dwarf指定,ARM 和 X86 都支持,对CPU和磁盘消耗高; -
lbr:通过
--call-graph=lbr指定,仅 Intel 新型号支持,消耗低,但可回溯的栈深度有限; -
orc:内核 unwinder,无需指定。 在 perf record 中,若不通过
--call-graph指定 unwinder,默认使用 fp 作为用户态栈的 unwinder;至于内核态的 unwinder,不由 perf 参数指定,由内核编译选项控制,低版本内核使用 fp,高版本内核使用 orc。
因此问题转化为:用户态使用哪个 unwinder 是更合适的?结论先行,以下是可供参考的方案:
-
Intel CPU:优先使用 lbr,lbr 的好处是硬件实现,精准可靠,大部分情况下深度够用;
-
ARM 架构:优先使用 fp,因为 ARM 架构寄存器比较多,保留了寄存器记录栈基址;
- X86 上没有 lbr 时:优先使用 dwarf,虽然 X86 架构也把栈基址保存在 %rbp,但只要编译优化大于等于
-O1,%rbp 寄存器基本作为通用寄存器使用,使得在 X86 上用 fp 获取用户态栈大部分时候不可靠。有以下注意点:-
在 linux 5.19 版本以下,dwarf 可能采样不到动态链接库的栈(参考提交 perf unwind: Fix egbase for ld.lld linked objects);
-
dwarf 需要复制保存每一个采样点的用户栈,因此采样期间 CPU 消耗较高,生成的采样数据也远大于其它 unwinder;
-
如果 dwarf 无法满足需求,可以 gcc 编译时添加选项
-fno-omit-frame-pointer放弃复用 %rbp 寄存器的编译优化,重新编译应用后使用 fp。虽然该选项无法百分百保证 %rbp 一定可靠,但总体可信。
-
让我们通过在 X86 架构上观测应用程序 fio,对这些 unwinder 有个初步的了解:
$ perf record -a --user-callchains --call-graph=dwarf -p `pidof fio` -o perf.data.dwarf -- sleep 2
$ perf report --no-ch --stdio -i perf.data.dwarf10.69% fio [kernel.kallsyms] [k] iowrite16|---syscallio_submit0x55a0a986682e # <- 我们会在下下节解决符号问题td_io_committd_io_queue0x55a0a985945a <-0x55a0a985b7d0 <- start_thread__GI___clone (inlined)
$ perf record -a --user-callchains --call-graph=fp -p `pidof fio` -o perf.data.fp -- sleep 2
$ perf report --no-ch --stdio -i perf.data.fp8.27% fio [kernel.kallsyms] [k] iowrite16|---syscall|--0.75%--0x70700000707|--0.75%--0x62d0000062d|--0.75%--0x5e1000005e1|--0.75%--0x55b0000055a|--0.75%--0x54800000548|--0.75%--0x52f0000052f|--0.75%--0x51000000510|--0.75%--0x44f0000044f|--0.75%--0x3cb000003cb|--0.75%--0x39800000398--0.75%--0x37c0000037b
以上采集数据的命令中使用 --user-callchains 选项指定了 perf 采样时只采集用户栈,排除掉我们暂时不关心的内核栈。输出中可以看到虽然 dwarf 采集得到的栈没有被完全翻译,但正确地回溯到了进程刚诞生的函数 __GI___clone,这表明 dwarf 采样得到了完整的栈;反观 fp,只得到了些奇怪的地址。我们的方案三是有效的!
what do dwarf do
为叙述完整,该节补充一点 dwarf 栈回溯原理,不影响 perf 使用,不涉及的朋友可以跳转下一节解决符号问题。
在编译过程中 gcc 无论是否指定 -g 选项, 默认都会生成 .eh_frame 和 .eh_frame_hdr 段. gcc 在翻译代码为汇编代码时, 会帮忙插上一些 CFI 伪指令, 如
$ gcc -S test.c # c语言生成汇编代码
$ vim test.s # 查看汇编代码
$ cat test.s.cfi_startproc # 刚进函数, 当前我们处于 callee 栈帧的起始处, 更新 CFA = rsp + 8pushq %rbp# 每次 push 寄存器到栈上, 需要将 CFA += 8, 因为相比上一状态需要多往前走一个单位才是 caller 的栈帧.cfi_def_cfa_offset 16.cfi_offset 6, -16 # 并且更新该寄存器关于 CFA 的偏移, 使回溯过程可以恢复该寄存器的值# ...movq %rsp %rbp # 将 rsp 寄存器赋值给 rbp.cfi_def_cfa_register 6 # 将寄存器 6 (rbp) 定义为 CFA 寄存器, 之后 CFA 的计算都基于 rbp# ...leave.cfi_def_cfa 7, 8 # leave 中将 rbp 寄存器的值赋值给 rsp, 即 rsp 此时指向 callee 栈帧开始处, 此时 CFA = rsp + 8.cfi_endproc
$ readelf -wF test.o # 查看对应的 .eh_frame 印证
0000000000000661 rsp+8 u c-8
0000000000000662 rsp+16 c-16 c-8
0000000000000665 rbp+16 c-16 c-8
00000000000006a6 rsp+8 c-16 c-8
其中 CFA (Canonical Frame Address, which is the address of %rsp in the caller frame) 指上一级调用者的堆栈指针.
如上所示, 汇编器会将这些 CFI 伪指令收集到可执行文件中的 .eh_frame 段. 典型形式如下:
$ readelf -wF a.out
Contents of the .eh_frame section:00000000 0000000000000014 00000000 CIE "zR" cf=1 df=-8 ra=16LOC CFA ra
0000000000000000 rsp+8 u ...000000c8 0000000000000044 0000009c FDE cie=00000030 pc=00000000000006b0..0000000000000715LOC CFA rbx rbp r12 r13 r14 r15 ra
00000000000006b0 rsp+8 u u u u u u c-8
00000000000006b2 rsp+16 u u u u u c-16 c-8
00000000000006b4 rsp+24 u u u u c-24 c-16 c-8
00000000000006b9 rsp+32 u u u c-32 c-24 c-16 c-8
00000000000006bb rsp+40 u u c-40 c-32 c-24 c-16 c-8
00000000000006c3 rsp+48 u c-48 c-40 c-32 c-24 c-16 c-8
00000000000006cb rsp+56 c-56 c-48 c-40 c-32 c-24 c-16 c-8
00000000000006d8 rsp+64 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070a rsp+56 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070b rsp+48 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070c rsp+40 c-56 c-48 c-40 c-32 c-24 c-16 c-8
000000000000070e rsp+32 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000710 rsp+24 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000712 rsp+16 c-56 c-48 c-40 c-32 c-24 c-16 c-8
0000000000000714 rsp+8 c-56 c-48 c-40 c-32 c-24 c-16 c-8
可以看到 .eh_frame 总体架构由 CIE 和 FDE 组成。通常一个 CIE 代表一个文件, 一个 FDE 代表一个函数. 其中核心的是 FDE 的组织:

利用 .eh_frame 进行栈 unwind 时候, 遵循以下步骤:
-
根据当前的PC在
.eh_frame中找到对应的条目,根据条目提供的各种偏移计算其他信息。 -
首先根据
CFA = rsp+4,把当前rsp+4得到CFA的值。再根据CFA的值计算出通用寄存器和返回地址在堆栈中的位置。 -
通用寄存器栈位置计算。例如:rbx = CFA-56。
-
返回地址ra的栈位置计算。ra = CFA-8。
-
根据ra的值,重复步骤1到4,就形成了完整的栈回溯。
handle missing symbols
函数调用栈本质是一串地址,perf 会尽量将地址翻译人类可读的符号。在以下样本点中,可以看到 IP 寄存器保存的地址属于 libc 库,它被正确翻译为 syscall+0x1d,但再往下回溯,我们只知道 syscall 函数是由 libaio 库某不知名函数调用的。这里出现 [unknown] 通常由于可执行程序的符号被裁剪所致,裁剪符号是有效减小可执行程序体积的做法。
$ perf script -D -i perf.data.dwarf
259594741631398 0x2d840 [0x20f8]: PERF_RECORD_SAMPLE(IP, 0x1): 273245/273258: 0xffffffff89d1869d period: 250000 addr: 0
... FP chain: nr:0
[...]
.... IP 0x00007f3afb87f52d
... ustack: size 8192, offset 0xe0
[...]
fio 273258 259594.741631: 250000 cpu-clock:pppH: 7f3afb87f52d syscall+0x1d (/usr/lib64/libc-2.28.so)7f3afc50ab7d [unknown] (/usr/lib64/libaio.so.1.0.1)55a0a9866a95 [unknown] (/usr/bin/fio)55a0a98197a5 td_io_getevents+0x75 (/usr/bin/fio)55a0a983b216 io_u_queued_complete+0x66 (/usr/bin/fio)55a0a98577d4 [unknown] (/usr/bin/fio)55a0a98591fa [unknown] (/usr/bin/fio)55a0a985b7d0 [unknown] (/usr/bin/fio)7f3afc0db179 start_thread+0xe9 (/usr/lib64/libpthread-2.28.so)7f3afb884dc2 __GI___clone+0x42
那怎么将符号补全呢?我们可以通过安装 -debuginfo 或 -dbgsym 包解决,例如对于 fio:
# centos 上,先使能 yum 的 debuginfo 源,再安装对应应用的 -debuginfo 包即可
$ cat /etc/yum.repos.d/CentOS-Linux-Debuginfo.repo
[debuginfo]
name=CentOS Linux $releasever - Debuginfo
baseurl=http://debuginfo.centos.org/$releasever/$basearch/
gpgcheck=0
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
$ yum clean all && yum makecache
$ yum -y install fio-debuginfo.x86_64# ubuntu 上,先导入调试符号签名密钥,再安装对应应用的 -dbgsym 包即可
$ apt install ubuntu-dbgsym-keyring
$ apt install fio-dbgsym
补全后的栈如下所示:
$ perf script -i perf.data.dwarf
fio 2469 2823.211391: 250000 cpu-clock:pppH: 7f03631a89bd syscall+0x1d (/usr/lib64/libc-2.28.so)7f0363ef1c14 io_submit+0x34 (/usr/lib64/libaio.so.1.0.1)555976f418ce fio_libaio_commit+0xde (/usr/bin/fio)555976ef4a98 td_io_commit+0x58 (/usr/bin/fio)555976ef4fb5 td_io_queue+0x3f5 (/usr/bin/fio)555976f344ea do_io+0x71a (/usr/bin/fio)555976f36880 thread_main+0x18b0 (/usr/bin/fio)555976f38561 run_threads+0xcb1 (/usr/bin/fio)
后记
当你面对一个性能问题,如果选择使用 perf 观测,那么问题就变成了三个,另外两个是在解决性能问题前,必须先解决栈回溯和符号解析,前者影响观测准确性,后者影响观测可读性。perf 大部分时候都帮忙做好了,但如果遇到了些小困难,希望本文能有幸帮上一点忙。

相关文章:
差生文具多之(二): perf
栈回溯和符号解析是使用 perf 的两大阻力,本文以应用程序 fio 的观测为例子,提供一些处理它们的经验法则,希望帮助大家无痛使用 perf。 前言 系统级性能优化通常包括两个阶段:性能剖析和代码优化: 性能剖析的目标是寻…...

【SPI和API有什么区别】
✅什么是SPI,和API有什么区别 ✅典型解析🟢拓展知识仓🟢如何定义一个SPI🟢SPI的实现原理 ✅SPI的应用场景SpringDubbo ✅典型解析 Java 中区分 API和 SPI,通俗的进: API和 SPI 都是相对的概念,他们的差别只…...
Day67力扣打卡
打卡记录 美丽塔 II(前缀和 单调栈) 链接 class Solution:def maximumSumOfHeights(self, maxHeights: List[int]) -> int:n len(maxHeights)stack collections.deque()pre, suf [0] * n, [0] * nfor i in range(n):while stack and maxHeights…...

什么是网站监控?
网站监控是跟踪网站的可用性和性能,以最小化宕机时间,优化性能并确保顺畅的用户体验。维护网站正常运行对于任何企业来说都是至关重要的,因而对大多数业务来说,网站应用监控都是一个严峻的挑战。Applications Manager网站应用监控…...
游戏软件提示d3dcompiler_43.dll的五个解决方法,亲测靠谱
在使用电脑进行工作,玩游戏的时候,我们常常会遇到一些错误提示,其中之一就是“D3DCompiler_43.dll丢失”的提示。D3DCompiler_43.dll是一个非常重要的动态链接库文件。它是由DirectX SDK提供的,用于编译和优化DirectX着色器代码的…...
python使用opencv提取视频中的每一帧、最后一帧,并存储成图片
提取视频每一帧存储图片 最近在搞视频检测问题,在用到将视频分帧保存为图片时,图片可以保存,但是会出现(-215:Assertion failed) !_img.empty() in function cv::imwrite问题而不能正常运行,在检查代码、检查路径等措施均无果后&…...

说说对React refs 的理解?应用场景?
先了解,是什么? React 中的 Refs提供了一种方式,允许我们访问 DOM节点或在 render方法中创建的 React元素。 本质为ReactDOM.render()返回的组件实例,如果是渲染组件则返回的是组件实例,如果渲染dom则返回的是具体的do…...

Pytorch 读取t7文件
Pytorch 1.0以上可以使用: import torchfileth_path r"./path/xx.t7" data torchfile.load(th_path)print(data.shape)若data的尺寸为0,则将torch版本降为0.4.1,并使用以下函数: from torch.utils.serialization im…...

【YOLOV8预测篇】使用Ultralytics YOLO进行检测、分割、姿态估计和分类实践
目录 一 安装Ultralytics 二 使用预训练的YOLOv8n检测模型 三 使用预训练的YOLOv8n-seg分割模型 四 使用预训练的YOLOv8n-pose姿态模型 五 使用预训练的YOLOv8n-cls分类模型 <...

[Linux] MySQL数据库之索引
一、索引的相关知识 1.1 索引的简介 索引是一个排序列表,包含索引值和包含该值的数据行的物理地址(类似于 c 语言链表,通过指针指向数据记录的内存地址)。 使用索引后可以不用扫描全表来定位某行的数据,而是先通过索…...

【期末考试】计算机网络、网络及其计算 考试重点
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 计算机网络及其计算 期末考点 🚀数…...

力扣labuladong——一刷day79
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣785. 判断二分图二、力扣886. 可能的二分法 前言 给你一幅「图」,请你用两种颜色将图中的所有顶点着色,且使得任意一条边的两个…...

【数据结构入门精讲 | 第十篇】考研408排序算法专项练习(二)
在上文中我们进行了排序算法的判断题、选择题的专项练习,在这一篇中我们将进行排序算法中编程题的练习。 目录 编程题R7-1 字符串的冒泡排序R7-1 抢红包R7-1 PAT排名汇总R7-2 统计工龄R7-1 插入排序还是堆排序R7-2 龙龙送外卖R7-3 家谱处理 编程题 R7-1 字符串的冒…...

【ES实战】Elasticsearch6开始的CCR
【ES实战】学习使用Elasticsearch6开始的CCR 本文涉及官网文章地址 OverviewRequirements for leader indicesAutomatically following indicesGetting started with cross-cluster replicationUpgrading clusters CCR > Cross-cluster replication 文章目录 【ES实战】学…...
Deployment Pay
axure watermark...

MySQL创建member表失败
最近在做一个项目,在台式机上可以跑通,也测试了各个已完成的接口,提交到了GitHub后想着用宿舍的电脑跑一下,在测试member表相关接口时就出错了。报了SQL语法错误,但SQL语句很简单,就根据手机号查询不至于出…...
使用minio实现大文件断点续传
部署 minio 拉取镜像 docker pull minio/minio docker images新建映射目录 新建下面图片里的俩个目录 data(存放对象-实际的数据) config 存放配置开放对应端口 我使用的是腾讯服务器所以 在腾讯的安全页面开启 9000,9090 两个端口就可以了(根据大家实际…...

插入排序之C++实现
描述 插入排序是一种简单直观的排序算法。它的基本思想是将一个待排序的数据序列分为已排序和未排序两部分,每次从未排序序列中取出一个元素,然后将它插入到已排序序列的适当位置,直到所有元素都插入完毕,即完成排序。 实现思路…...
Tomcat日志乱码了怎么处理?
【前言】 tomacat日志有三个地方,分别是Output(控制台)、Tomcat Localhost Log(tomcat本地日志)、Tomcat Catalina Log。 启动日志和大部分报错日志、普通日志都在output打印;有些错误日志,在Tomcat Localhost Log。 三个日志显示区,都可能…...

[node] Node.js的路由
[node] Node.js的路由 路由 & 路由解析路由信息的整合URL信息路由处理逻辑路由逻辑与URL信息的整合路由的使用 路由 & 路由解析 路由需要提供请求的 URL 和其他需要的 GET/POST 参数,随后路由需要根据这些数据来执行相应的代码。 因此,根据 HT…...

5个实用技巧解决AKShare金融数据接口的HTTP API调用问题
5个实用技巧解决AKShare金融数据接口的HTTP API调用问题 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools 在量化投资和金融数据分析领域…...

Claude Code高效开发指南:精选工具、技能与工作流实践
1. 项目概述:一个为Claude Code开发者量身定制的“军火库”如果你正在使用Claude Code进行开发,并且已经度过了最初的新鲜感,开始思考如何让它真正成为你工作流中不可或缺的、高效且可靠的伙伴,那么你很可能已经遇到了一个核心问题…...

可视化大屏怎么做?可视化大屏工具你会用吗?
可视化大屏早已不只是技术人员的专属,越来越多的运营、产品和市场人也开始尝试,但是常常陷入各种问题:比如硬件效果一般、数据堆积没重点、动效杂乱干扰信息传达……其实归根结底,这些问题都指向一个核心:缺少一个专业…...

FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程
FAST-LIO2后端优化代码逐行解读:从残差计算到地图更新的完整流程 当激光雷达在复杂环境中高速移动时,如何实现精准的实时定位与建图?FAST-LIO2通过创新的迭代误差状态卡尔曼滤波(IEKF)框架,将IMU预积分与激…...

5分钟解决Mac NTFS读写难题:免费开源工具完全指南
5分钟解决Mac NTFS读写难题:免费开源工具完全指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NT…...

POE是什么?
POE 一般指 Power over Ethernet(以太网供电)。 通俗理解 用 一根网线(RJ45) 同时做两件事: 传数据(上网、通信) 给设备供电(不用单独再接电源适配器) 常见场景:IP 摄像头、无线 AP、部分 Orange Dongle / 底座,实验室用 PoE 交换机或 PoE 适配器 给 Dongle 供电…...

基于Arduino与蓝牙的智能夜灯DIY:从硬件到App全流程解析
1. 项目概述:打造你的专属蓝牙智能夜灯如果你对Arduino和物联网项目感兴趣,一直想亲手做一个既能远程控制、又能播放音乐的智能小玩意儿,那么这个“8BitBox”项目绝对值得一试。它本质上是一个由Arduino驱动、通过Android手机蓝牙控制的智能夜…...

从零上手Ranorex:录制、验证与参数化测试实战解析
1. Ranorex自动化测试入门指南 第一次接触Ranorex时,我和大多数测试工程师一样,被它强大的功能所震撼。作为一款专业的自动化测试工具,Ranorex能够显著提升测试效率,特别适合需要频繁回归测试的项目场景。记得我第一次用它完成计算…...
:滤波)
彩色血流成像(三):滤波
文章目录1回波信号1.1 杂波信号1.2血流信号1.3噪声信号1.4回波信号模拟方法2滤波目的3滤波限制4滤波算法5高通数字滤波器5.1单一回波抵消器5.2FIR滤波器5.3IIR滤波器 无限冲激响应滤波器定义:实现缺点:5.4回归滤波器5.5优化6参数化方法7非参数化方法7.1特…...

Spinning Up模型保存终极指南:checkpoint管理完整教程
Spinning Up模型保存终极指南:checkpoint管理完整教程 【免费下载链接】spinningup An educational resource to help anyone learn deep reinforcement learning. 项目地址: https://gitcode.com/gh_mirrors/sp/spinningup 深度强化学习训练过程中ÿ…...