Flink 客户端操作命令及可视化工具
Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、Scala Shell、SQL Client、Restful API和 Web五个方面进行整理。
在Flink安装目录的bin目录下可以看到flink,start-scala-shell.sh和sql-client.sh等文件,这些都是客户端操作的入口。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0641e2577aab4433bdf972f8cc8250cc.png)
flink 常见操作:可以通过 -help 查看帮助
run 运行任务
-d:以分离模式运行作业
-c:如果没有在jar包中指定入口类,则需要在这里通过这个参数指定;
-m:指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager,可以说是yarn集群名称;
-p:指定程序的并行度。可以覆盖配置文件中的默认值;
-s:保存点savepoint的路径以还原作业来自(例如hdfs:///flink/savepoint-1537);
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID dce7b69ad15e8756766967c46122736f
就可以看到我们提交的JobManager,默认是一个并发。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/668711322ab84cb094da11a12ac990eb.png)
点进去就可以看到详细的信息
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/f0e73bf42a394838a8f74d2e2deb6400.png)
点击左侧TaskManager —Stdout能看到具体输出的日志信息。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/5229a6c1d4d6459dbb7b4cb5cef0f8d8.png)
或者查看TaskManager节点的log目录下的*.out文件,也能看到具体的输出信息。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/0c40b1ae05d140458cf205d6874d4d6a.png)
list 查看任务列表
-m:jobmanager<arg>作业管理器(主)的地址连接。
[root@hadoop1 flink-1.10.1]# bin/flink list -m 127.0.0.1:8081
Waiting for response...
------------------ Running/Restarting Jobs -------------------
09.07.2020 16:44:09 : dce7b69ad15e8756766967c46122736f : CarTopSpeedWindowingExample (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
Stop 停止任务
需要指定jobmanager的ip:prot和jobId。如下报错可知,一个job能够被stop要求所有的source都是可以stoppable的,即实现了 StoppableFunction接口。
[root@hadoop1 flink-1.10.1]# bin/flink stop -m 127.0.0.1:8081 dce7b69ad15e8756766967c46122736f
Suspending job "dce7b69ad15e8756766967c46122736f" with a savepoint.------------------------------------------------------------The program finished with the following exception:org.apache.flink.util.FlinkException: Could not stop with a savepoint job "dce7b69ad15e8756766967c46122736f".at org.apache.flink.client.cli.CliFrontend.lambda$stop$5(CliFrontend.java:458)
StoppableFunction接口如下,属于优雅停止任务。
/*** @Description 需要 stoppabel 的函数必须实现此接口,例如流式任务 source** stop() 方法在任务收到 stop信号的时候调用* source 在接收到这个信号后,必须停止发送新的数据优雅的停止。* @Date 2020/7/9 17:26*/@PublicEvolvingpublic interface StoppableFunction {/*** 停止 source,与 cancel() 不同的是,这是一个让 source优雅停止的请求。* 等待中的数据可以继续发送出去,不需要立即停止*/void stop();
}
Cancel 取消任务
如果在conf/flink-conf.yaml里面配置state.savepoints.dir,会保存savepoint,否则不会保存savepoint。(重启)
state.savepoints.dir: file:///tmp/savepoint
执行 Cancel命令 取消任务
[root@hadoop1 flink-1.10.1]# bin/flink cancel -m 127.0.0.1:8081 -s e8ce0d111262c52bf8228d5722742d47
DEPRECATION WARNING: Cancelling a job with savepoint is deprecated. Use "stop" instead.
Cancelling job e8ce0d111262c52bf8228d5722742d47 with savepoint to default savepoint directory.
Cancelled job e8ce0d111262c52bf8228d5722742d47. Savepoint stored in file:/tmp/savepoint/savepoint-e8ce0d-f7fa96a085d8.
也可以在停止的时候显示指定savepoint目录
1 [root@hadoop1 flink-1.10.1]# bin/flink cancel -m 127.0.0.1:8081 -s /tmp/savepoint f58bb4c49ee5580ab5f27fdb24083353
DEPRECATION WARNING: Cancelling a job with savepoint is deprecated. Use "stop" instead.
Cancelling job f58bb4c49ee5580ab5f27fdb24083353 with savepoint to /tmp/savepoint.
Cancelled job f58bb4c49ee5580ab5f27fdb24083353. Savepoint stored in file:/tmp/savepoint/savepoint-f58bb4-127b7e84910e.
取消和停止(流作业)的区别如下:
● cancel()调用, 立即调用作业算子的cancel()方法,以尽快取消它们。如果算子在接到cancel()调用后没有停止,Flink将开始定期中断算子线程的执行,直到所有算子停止为止。
● stop()调用 ,是更优雅的停止正在运行流作业的方式。stop()仅适用于source实现了StoppableFunction接口的作业。当用户请求停止作业时,作业的所有source都将接收stop()方法调用。直到所有source正常关闭时,作业才会正常结束。这种方式,使 作业正常处理完所有作业。
触发 savepoint
当需要生成savepoint文件时,需要手动触发savepoint。如下,需要指定正在运行的 JobID 和生成文件的存放目录。同时,我们也可以看到它会返回给用户存放的savepoint的文件名称等信息。
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar Executing TopSpeedWindowing example with default input data set.Use --input to specify file input.Printing result to stdout. Use --output to specify output path.Job has been submitted with JobID 216c427d63e3754eb757d2cc268a448d[root@hadoop1 flink-1.10.1]# bin/flink savepoint -m 127.0.0.1:8081 216c427d63e3754eb757d2cc268a448d /tmp/savepoint/Triggering savepoint for job 216c427d63e3754eb757d2cc268a448d.Waiting for response...Savepoint completed. Path: file:/tmp/savepoint/savepoint-216c42-154a34cf6bfdYou can resume your program from this savepoint with the run command.
savepoint和checkpoint的区别:
● checkpoint是增量做的,每次的时间较短,数据量较小,只要在程序里面启用后会自动触发,用户无须感知;savepoint是全量做的,每次的时间较长,数据量较大,需要用户主动去触发。
● checkpoint是作业failover的时候自动使用,不需要用户指定。savepoint一般用于程序的版本更新,bug修复,A/B Test等场景,需要用户指定。
从指定 savepoint 中启动
[root@hadoop1 flink-1.10.1]# bin/flink run -d -s /tmp/savepoint/savepoint-f58bb4-127b7e84910e/ examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 1a5c5ce279e0e4bd8609f541b37652e2
查看JobManager的日志能够看到Reset the checkpoint ID为我们指定的savepoint文件中的ID
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/4db15037b5554195a289c273572b4c7b.png)
modify 修改任务并行度
这里修改master的conf/flink-conf.yaml将task slot数修改为4。并通过xsync分发到 两个slave节点上。
taskmanager.numberOfTaskSlots: 4
修改参数后需要重启集群生效:关闭/启动集群
[root@hadoop1 flink-1.10.1]# bin/stop-cluster.sh && bin/start-cluster.sh
Stopping taskexecutor daemon (pid: 8236) on host hadoop2.
Stopping taskexecutor daemon (pid: 8141) on host hadoop3.
Stopping standalonesession daemon (pid: 22633) on host hadoop1.
Starting cluster.
Starting standalonesession daemon on host hadoop1.
Starting taskexecutor daemon on host hadoop2.
Starting taskexecutor daemon on host hadoop3.
启动任务
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/TopSpeedWindowing.jar
Executing TopSpeedWindowing example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 2e833a438da7d8052f14d5433910515a
从页面上能看到Task Slots总计变为了8,运行的Slot为1,剩余Slot数量为7。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/a3840dc2c17f411e901d20419435b7af.png)
这时候默认的并行度是1
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/30e6676adc0c4e7e8d8fe2bfb9a15128.png)
Flink1.0版本命令行flink modify已经没有这个行为了,被移除了。。。Flink1.7上是可以运行的。
[root@hadoop1 flink-1.10.1]# bin/flink modify -p 4 cc22cc3d09f5d65651d637be6fb0a1c3
"modify" is not a valid action.
Info 显示程序的执行计划
[root@hadoop1 flink-1.10.1]# bin/flink info examples/streaming/TopSpeedWindowing.jar
----------------------- Execution Plan -----------------------
{"nodes":[{"id":1,"type":"Source: Custom Source","pact":"Data Source","contents":"Source: Custom Source","parallelism":1},{"id":2,"type":"Timestamps/Watermarks","pact":"Operator","contents":"Timestamps/Watermarks","parallelism":1,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","pact":"Operator","contents":"Window(GlobalWindows(), DeltaTrigger, TimeEvictor, ComparableAggregator, PassThroughWindowFunction)","parallelism":1,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Print to Std. Out","pact":"Data Sink","contents":"Sink: Print to Std. Out","parallelism":1,"predecessors":[{"id":4,"ship_strategy":"FORWARD","side":"second"}]}]}
--------------------------------------------------------------
拷贝输出的json内容,粘贴到这个网站:http://flink.apache.org/visualizer/可以生成类似如下的执行图。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/f691bb698954496b8f0dd957c86d0cd9.png)
可以与实际运行的物理执行计划进行对比。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/3e520b005fcc4ba8abf894fab4ec924c.png)
SQL Client Beta
进入 Flink SQL
[root@hadoop1 flink-1.10.1]# bin/sql-client.sh embedded
Select查询,按Q退出如下界面;
Flink SQL> select 'hello word';SQL Query Result (Table)Table program finished. Page: Last of 1 Updated: 16:37:04.649EXPR$0hello wordQ Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
打开http://hadoop1:8081能看到这条select语句产生的查询任务已经结束了。这个查询采用的是读取固定数据集的Custom Source,输出用的是Stream Collect Sink,且只输出一条结果。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/8f7df91d86a0494fa84962471ba16f02.png)
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/845f52fc8c6e401da5be70008d3a62a5.png)
explain 查看 SQL 的执行计划。
Flink SQL> explain SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
== Abstract Syntax Tree == //抽象语法树
LogicalAggregate(group=[{0}], cnt=[COUNT()])
+- LogicalValues(type=[RecordType(VARCHAR(5) name)], tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])== Optimized Logical Plan == //优化后的逻辑执行计划
GroupAggregate(groupBy=[name], select=[name, COUNT(*) AS cnt])
+- Exchange(distribution=[hash[name]])+- Values(type=[RecordType(VARCHAR(5) name)], tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])== Physical Execution Plan == //物理执行计划
Stage 13 : Data Sourcecontent : Source: Values(tuples=[[{ _UTF-16LE'Bob' }, { _UTF-16LE'Alice' }, { _UTF-16LE'Greg' }, { _UTF-16LE'Bob' }]])Stage 15 : Operatorcontent : GroupAggregate(groupBy=[name], select=[name, COUNT(*) AS cnt])ship_strategy : HASH
结果展示
SQL Client支持两种模式来维护并展示查询结果:
table mode
在内存中物化查询结果,并以分页table形式展示。用户可以通过以下命令启用table mode:例如如下案例;
Flink SQL> SET execution.result-mode=table;
[INFO] Session property has been set.Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;SQL Query Result (Table)Table program finished. Page: Last of 1 Updated: 16:55:08.589name cntAlice 1Greg 1Bob 2Q Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/c7412859eabf4b3fad3ddb2cccfc710a.png)
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/1087d007317045dcaa030439ca6b627d.png)
changelog mode
不会物化查询结果,而是直接对continuous query产生的添加和撤回retractions结果进行展示:如下案例中的-表示撤回消息
Flink SQL> SET execution.result-mode=changelog;
[INFO] Session property has been set.Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;SQL Query Result (Changelog)Table program finished. Updated: 16:58:05.777+/- name cnt+ Bob 1+ Alice 1+ Greg 1- Bob 1+ Bob 2Q Quit + Inc Refresh O Open Row
R Refresh - Dec Refresh
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/374f6f2c91a3467683fc7c43959dcaae.png)
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/e97f9ece7ebc4cc292b619996a030755.png)
Environment Files
CREATE TABLE 创建表DDL语句:
Flink SQL> CREATE TABLE pvuv_sink (
> dt VARCHAR,
> pv BIGINT,
> uv BIGINT
> ) ;
[INFO] Table has been created.
SHOW TABLES 查看所有表名
Flink SQL> show tables;
pvuv_sink
DESCRIBE 表名 查看表的详细信息;
Flink SQL> describe pvuv_sink;
root|-- dt: STRING|-- pv: BIGINT|-- uv: BIGINT
插入等操作均与关系型数据库操作语句一样,省略N个操作
Restful API
接下来我们演示如何通过rest api来提交jar包和执行任务。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/4952f119ae2a4bf692e62fb5d85ec0fd.png)
通过Show Plan可以看到执行图
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/339bf285020b462b82ea13836b939fd4.png)
提交之后的操作,取消的话点击页面的Cancel Job
![ [点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/a1011c88daf04744967d1cc2c2e23848.png)
相关文章:
Flink 客户端操作命令及可视化工具
Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、Scala Shell、SQL Client、Restful API和 Web五个方面进行整理。 在Flink安装目录的bin目录下可以看到flink,start-scala-shell.sh和sql-client.sh等文件,这些都是客户…...

csrf自动化检测调研
https://github.com/pillarjs/understanding-csrf/blob/master/README_zh.md CSRF 攻击者在钓鱼站点,可以通过创建一个AJAX按钮或者表单来针对你的网站创建一个请求: <form action"https://my.site.com/me/something-destructive" metho…...

记录一个Python鼠标自动模块用法和selenium加载网页插件的设置
写爬虫,或者网页自动化,让程序自动完成一些重复性的枯燥的网页操作,是最常见的需求。能够解放双手,空出时间看看手机,或者学习别的东西,甚至还能帮朋友亲戚减轻工作量。 然而,网页自动化代码编写…...

【数据库系统概论】第3章-关系数据库标准语言SQL(1)
文章目录 3.1 SQL概述3.2 学生-课程数据库3.3 数据定义3.3.1 数据库定义3.3.2 模式的定义3.3.3 基本表的定义3.3.4 索引的建立与删除3.3.5 数据字典 3.1 SQL概述 动词 分类 三级模式 3.2 学生-课程数据库 3.3 数据定义 3.3.1 数据库定义 创建数据库 tips:[ ]表…...

【Python】基于flaskMVT架构与session实现博客前台登录登出功能
目录 一、MVT说明 1.Model层 2.View层 3.Template层 二、功能说明 三、代码框架展示 四、具体代码实现 models.py 登录界面前端代码 博客界面前端代码(profile.html) main.py 一、MVT说明 MVT架构是Model-View-Template的缩写,是…...
为什么有的开关电源需要加自举电容?
一、什么是自举电路? 1.1 自举的概念 首先,自举电路也叫升压电路,是利用自举升压二极管,自举升压电容等电子元件,使电容放电电压和电源电压叠加,从而使电压升高。有的电路升高的电压能达到数倍电源电压。…...
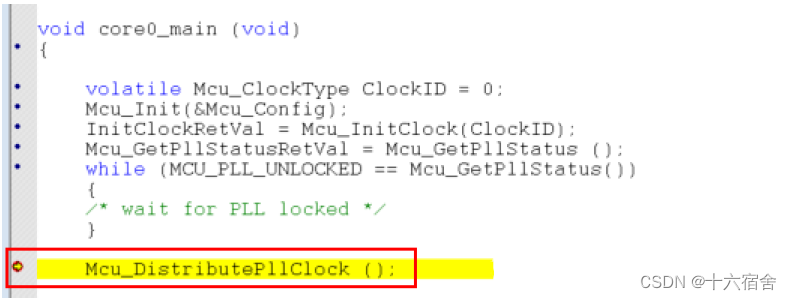
【MCAL】TC397+EB-treso之MCU配置实战 - 芯片时钟
本篇文章介绍了在TC397平台使用EB-treso对MCU驱动模块进行配置的实战过程,主要介绍了后续基本每个外设模块都要涉及的芯片时钟部分,帮助读者了解TC397芯片的时钟树结构,在后续计算配置不同外设模块诸如通信速率,定时器周期等&…...
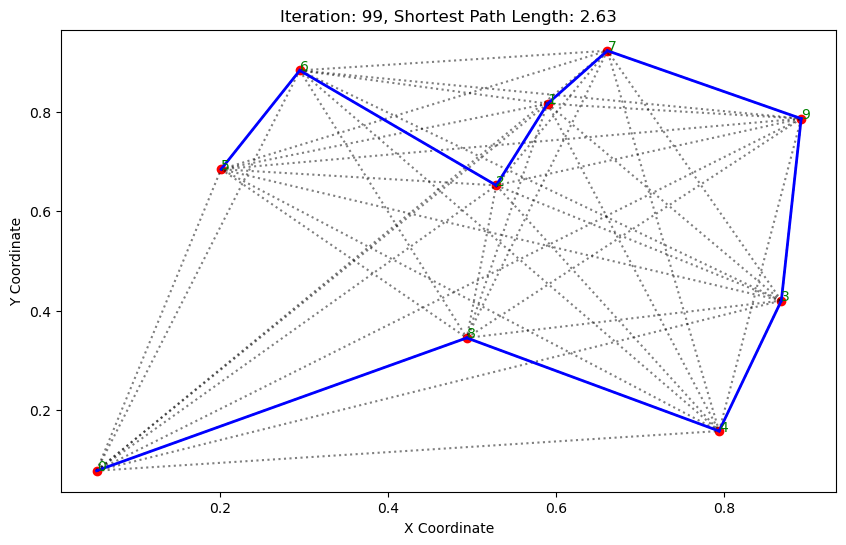
高级人工智能之群体智能:蚁群算法
群体智能 鸟群: 鱼群: 1.基本介绍 蚁群算法(Ant Colony Optimization, ACO)是一种模拟自然界蚂蚁觅食行为的优化算法。它通常用于解决路径优化问题,如旅行商问题(TSP)。 蚁群算法的基本步骤…...

【SpringBoot应用篇】【AOP+注解】SpringBoot+SpEL表达式基于注解实现权限控制
【SpringBoot应用篇】【AOP注解】SpringBootSpEL表达式基于注解实现权限控制 Spring SpEL基本表达式类相关表达式表达式模板 SpEL表达式实现权限控制PreAuthAuthFunPreAuthAspectUserControllerSpelParserUtils Spring SpEL Spring 表达式语言 SpEL 是一种非常强大的表达式语言…...
Java研学-HTTP 协议
一 概述 1 概念和作用 概念:HTTP 是 HyperText Transfer Protocol (超文本传输协议)的简写,它是 TCP/IP 协议之上的一个应用层协议。简单理解就是 HTTP 协议底层是对 TCP/IP 协议的封装。 作用:用于规定浏览器和服务器之间数据传输的格式…...

差生文具多之(二): perf
栈回溯和符号解析是使用 perf 的两大阻力,本文以应用程序 fio 的观测为例子,提供一些处理它们的经验法则,希望帮助大家无痛使用 perf。 前言 系统级性能优化通常包括两个阶段:性能剖析和代码优化: 性能剖析的目标是寻…...

【SPI和API有什么区别】
✅什么是SPI,和API有什么区别 ✅典型解析🟢拓展知识仓🟢如何定义一个SPI🟢SPI的实现原理 ✅SPI的应用场景SpringDubbo ✅典型解析 Java 中区分 API和 SPI,通俗的进: API和 SPI 都是相对的概念,他们的差别只…...
Day67力扣打卡
打卡记录 美丽塔 II(前缀和 单调栈) 链接 class Solution:def maximumSumOfHeights(self, maxHeights: List[int]) -> int:n len(maxHeights)stack collections.deque()pre, suf [0] * n, [0] * nfor i in range(n):while stack and maxHeights…...

什么是网站监控?
网站监控是跟踪网站的可用性和性能,以最小化宕机时间,优化性能并确保顺畅的用户体验。维护网站正常运行对于任何企业来说都是至关重要的,因而对大多数业务来说,网站应用监控都是一个严峻的挑战。Applications Manager网站应用监控…...
游戏软件提示d3dcompiler_43.dll的五个解决方法,亲测靠谱
在使用电脑进行工作,玩游戏的时候,我们常常会遇到一些错误提示,其中之一就是“D3DCompiler_43.dll丢失”的提示。D3DCompiler_43.dll是一个非常重要的动态链接库文件。它是由DirectX SDK提供的,用于编译和优化DirectX着色器代码的…...
python使用opencv提取视频中的每一帧、最后一帧,并存储成图片
提取视频每一帧存储图片 最近在搞视频检测问题,在用到将视频分帧保存为图片时,图片可以保存,但是会出现(-215:Assertion failed) !_img.empty() in function cv::imwrite问题而不能正常运行,在检查代码、检查路径等措施均无果后&…...

说说对React refs 的理解?应用场景?
先了解,是什么? React 中的 Refs提供了一种方式,允许我们访问 DOM节点或在 render方法中创建的 React元素。 本质为ReactDOM.render()返回的组件实例,如果是渲染组件则返回的是组件实例,如果渲染dom则返回的是具体的do…...

Pytorch 读取t7文件
Pytorch 1.0以上可以使用: import torchfileth_path r"./path/xx.t7" data torchfile.load(th_path)print(data.shape)若data的尺寸为0,则将torch版本降为0.4.1,并使用以下函数: from torch.utils.serialization im…...

【YOLOV8预测篇】使用Ultralytics YOLO进行检测、分割、姿态估计和分类实践
目录 一 安装Ultralytics 二 使用预训练的YOLOv8n检测模型 三 使用预训练的YOLOv8n-seg分割模型 四 使用预训练的YOLOv8n-pose姿态模型 五 使用预训练的YOLOv8n-cls分类模型 <...

[Linux] MySQL数据库之索引
一、索引的相关知识 1.1 索引的简介 索引是一个排序列表,包含索引值和包含该值的数据行的物理地址(类似于 c 语言链表,通过指针指向数据记录的内存地址)。 使用索引后可以不用扫描全表来定位某行的数据,而是先通过索…...

第五课:YOLOv5-Lite模型适配AK3918AV130转换实战
文章目录一、课程导学二、课程核心关键词三、模型转换整体原理与流程概述四、YOLOv5-Lite转ONNX标准化实战五、安凯微工具链模型适配与量化实战六、AK3918AV130专属模型编译实战七、模型仿真校验与异常排查八、课堂实操示例九、本节课核心总结十、课后作业十一、课程回顾总结上…...

Compose-Skill:为Jetpack Compose应用注入AI能力的组件化技能库
1. 项目概述:一个为Compose应用注入AI能力的技能库最近在折腾Jetpack Compose项目时,我一直在想,能不能让UI开发也“智能”一点?比如,用户输入一段模糊的描述,界面就能自动生成对应的组件布局;或…...

AI记忆库CoPaw-Memory:向量检索与结构化存储融合实践
1. 项目概述:当AI学会“记笔记”,一个开源记忆库的诞生最近在折腾AI应用开发的朋友,可能都遇到过同一个痛点:如何让AI记住我们说过的话?无论是构建一个长期陪伴的聊天机器人,还是开发一个能理解复杂上下文的…...

PromethAI-Backend:构建标准化AI智能体后端框架的工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想搞一个能处理复杂工作流的智能体系统,发现了一个挺有意思的开源项目——PromethAI-Backend。这名字听着就有点“普罗米修斯”盗火种给人类的意思,挺形象的,它本质上就是一个为…...

写给读者看的从来不是 Markdown:Anthropic 停用 MD 背后,这个本地 HTML 编辑器解决多平台发布之苦
写完一篇东西,发布时 Markdown 的短板才显出来——渲染器各行其是,同一段文字在公众号、知乎、X 上各是一副面孔,代码块的样式、标题的缩进、引用块的背景,没有一处能跨平台保持一致,你只能逐平台手调,或者…...

AI应用网关ai-proxy:统一管理多模型API调用,实现路由、缓存与限流
1. 项目概述:一个为AI应用量身打造的智能代理网关如果你正在开发或部署基于大语言模型(LLM)的应用,比如一个聊天机器人、一个代码助手,或者一个内容生成工具,那么你大概率会遇到一个头疼的问题:…...

对比官方价格Taotoken的活动价确实带来了可观节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格,Taotoken的活动价确实带来了可观节省 作为一名长期使用多个大模型API进行项目开发的个人开发者ÿ…...

iMeta | 伦敦国王学院量化系统生物学组-解析肝硬化中口腔-肠道转移细菌与宿主互作
点击蓝字 关注我们整合宿主–微生物组建模揭示了口腔–肠道微生物转移在晚期肝硬化中的潜在作用iMeta主页:http://www.imeta.science研究论文● 期刊: iMeta (IF 33.2,中科院双一区Top)● 英文题目: Integrative host-microbiome modelling uncovers the implicatio…...

为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱 陷阱一:事件序列号(Sequence ID)与数据库事务隔离级别的隐式冲突 Deep…...

在微服务架构中统一接入Taotoken管理所有AI调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中统一接入Taotoken管理所有AI调用 当企业采用微服务架构时,AI能力的调用往往分散在各个独立的服务中。每…...