【Linux系统基础】(6)在Linux上大数据NoSQL数据库HBase集群部署、分布式内存计算Spark环境及Flink环境部署详细教程

大数据NoSQL数据库HBase集群部署
简介
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
和Redis一样,HBase是一款KeyValue型存储的数据库。
不过和Redis设计方向不同
- Redis设计为少量数据,超快检索
- HBase设计为海量数据,快速检索
HBase在大数据领域应用十分广泛,现在我们来在node1、node2、node3上部署HBase集群。
安装
-
HBase依赖Zookeeper、JDK、Hadoop(HDFS),请确保已经完成前面
- 集群化软件前置准备(JDK)
- Zookeeper
- Hadoop
- 这些环节的软件安装
-
【node1执行】下载HBase安装包
# 下载 wget http://archive.apache.org/dist/hbase/2.1.0/hbase-2.1.0-bin.tar.gz# 解压 tar -zxvf hbase-2.1.0-bin.tar.gz -C /export/server# 配置软链接 ln -s /export/server/hbase-2.1.0 /export/server/hbase -
【node1执行】,修改配置文件,修改
conf/hbase-env.sh文件# 在28行配置JAVA_HOME export JAVA_HOME=/export/server/jdk # 在126行配置: # 意思表示,不使用HBase自带的Zookeeper,而是用独立Zookeeper export HBASE_MANAGES_ZK=false # 在任意行,比如26行,添加如下内容: export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true" -
【node1执行】,修改配置文件,修改
conf/hbase-site.xml文件# 将文件的全部内容替换成如下内容: <configuration><!-- HBase数据在HDFS中的存放的路径 --><property><name>hbase.rootdir</name><value>hdfs://node1:8020/hbase</value></property><!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- ZooKeeper的地址 --><property><name>hbase.zookeeper.quorum</name><value>node1,node2,node3</value></property><!-- ZooKeeper快照的存储位置 --><property><name>hbase.zookeeper.property.dataDir</name><value>/export/server/apache-zookeeper-3.6.0-bin/data</value></property><!-- V2.1版本,在分布式情况下, 设置为false --><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property> </configuration> -
【node1执行】,修改配置文件,修改
conf/regionservers文件# 填入如下内容 node1 node2 node3 -
【node1执行】,分发hbase到其它机器
scp -r /export/server/hbase-2.1.0 node2:/export/server/ scp -r /export/server/hbase-2.1.0 node3:/export/server/ -
【node2、node3执行】,配置软链接
ln -s /export/server/hbase-2.1.0 /export/server/hbase -
【node1、node2、node3执行】,配置环境变量
# 配置在/etc/profile内,追加如下两行 export HBASE_HOME=/export/server/hbase export PATH=$HBASE_HOME/bin:$PATHsource /etc/profile -
【node1执行】启动HBase
请确保:Hadoop HDFS、Zookeeper是已经启动了的
start-hbase.sh# 如需停止可使用 stop-hbase.sh由于我们配置了环境变量export PATH= P A T H : PATH: PATH:HBASE_HOME/bin
start-hbase.sh即在$HBASE_HOME/bin内,所以可以无论当前目录在哪,均可直接执行
-
验证HBase
浏览器打开:http://node1:16010,即可看到HBase的WEB UI页面
-
简单测试使用HBase
【node1执行】
hbase shell# 创建表 create 'test', 'cf'# 插入数据 put 'test', 'rk001', 'cf:info', 'itheima'# 查询数据 get 'test', 'rk001'# 扫描表数据 scan 'test'
分布式内存计算Spark环境部署
注意
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群
如果没有Hadoop集群,请参阅前置内容,部署好环境。
简介
Spark是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Spark在大数据体系是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上使用最多的大数据分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Spark Standalone集群。
安装
-
【node1执行】下载并解压
wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz# 解压 tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /export/server/# 软链接 ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark -
【node1执行】修改配置文件名称
# 改名 cd /export/server/spark/conf mv spark-env.sh.template spark-env.sh mv slaves.template slaves -
【node1执行】修改配置文件,
spark-env.sh## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop## 指定spark老大Master的IP和提交任务的通信端口 export SPARK_MASTER_HOST=node1 export SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080 SPARK_WORKER_CORES=1 SPARK_WORKER_MEMORY=1g -
【node1执行】修改配置文件,
slavesnode1 node2 node3 -
【node1执行】分发
scp -r spark-2.4.5-bin-hadoop2.7 node2:$PWD scp -r spark-2.4.5-bin-hadoop2.7 node3:$PWD -
【node2、node3执行】设置软链接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark -
【node1执行】启动Spark集群
/export/server/spark/sbin/start-all.sh# 如需停止,可以 /export/server/spark/sbin/stop-all.sh -
打开Spark监控页面,浏览器打开:http://node1:8081
-
【node1执行】提交测试任务
/export/server/spark/bin/spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi /export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar
分布式内存计算Flink环境部署
注意
本小节的操作,基于:大数据集群(Hadoop生态)安装部署环节中所构建的Hadoop集群
如果没有Hadoop集群,请参阅前置内容,部署好环境。
简介
Flink同Spark一样,是一款分布式内存计算引擎,可以支撑海量数据的分布式计算。
Flink在大数据体系同样是明星产品,作为最新一代的综合计算引擎,支持离线计算和实时计算。
在大数据领域广泛应用,是目前世界上除去Spark以外,应用最为广泛的分布式计算引擎。
我们将基于前面构建的Hadoop集群,部署Flink Standalone集群
Spark更加偏向于离线计算而Flink更加偏向于实时计算。
安装
-
【node1操作】下载安装包
wget https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-bin-scala_2.11.tgz# 解压 tar -zxvf flink-1.10.0-bin-scala_2.11.tgz -C /export/server/# 软链接 ln -s /export/server/flink-1.10.0 /export/server/flink -
【node1操作】修改配置文件,
conf/flink-conf.yaml# jobManager 的IP地址 jobmanager.rpc.address: node1 # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.heap.size: 1024m # TaskManager JVM heap 内存大小 taskmanager.heap.size: 1024m # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 2 #是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源 taskmanager.memory.preallocate: false # 程序默认并行计算的个数 parallelism.default: 1 #JobManager的Web界面的端口(默认:8081) jobmanager.web.port: 8081 -
【node1操作】,修改配置文件,
conf/slavesnode1 node2 node3 -
【node1操作】分发Flink安装包到其它机器
cd /export/server scp -r flink-1.10.0 node2:`pwd`/ scp -r flink-1.10.0 node3:`pwd`/ -
【node2、node3操作】
# 配置软链接 ln -s /export/server/flink-1.10.0 /export/server/flink -
【node1操作】,启动Flink
/export/server/flink/bin/start-cluster.sh -
验证Flink启动
# 浏览器打开 http://node1:8081 -
提交测试任务
【node1执行】
/export/server/flink/bin/flink run /export/server/flink-1.10.0/examples/batch/WordCount.jar
相关文章:
【Linux系统基础】(6)在Linux上大数据NoSQL数据库HBase集群部署、分布式内存计算Spark环境及Flink环境部署详细教程
大数据NoSQL数据库HBase集群部署 简介 HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。 和Redis一样,HBase是一款KeyValue型存储的数据库。 不过和Redis设计方向不同 Redis设计为少量数据,超快检索HBase设计为海量数据,…...
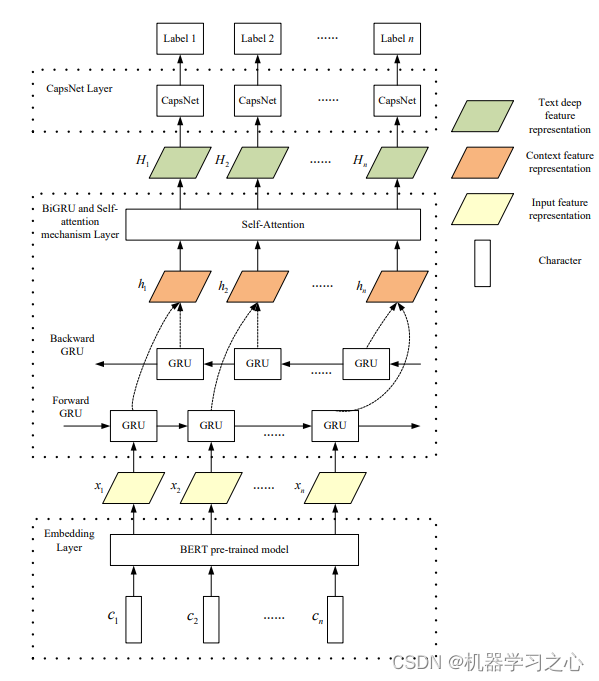
多维时序 | MATLAB实CNN-BiGRU-Mutilhead-Attention卷积网络结合双向门控循环单元网络融合多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现CNN-BiGRU-Mutilhead-Attention卷积网络结合双向门控循环单元网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现CNN-BiGRU-Mutilhead-Attention卷积网络结合双向门控循环单元网络融合多头注意力机制多变量时间序列预测预测效果基本介…...

vs快捷键
ctrlMo 折叠代码块 ctrlML 打开代码块...

linux 内核时间计量方法
定时器中断由系统定时硬件以规律地间隔产生; 这个间隔在启动时由内核根据 HZ 值来编 程, HZ 是一个体系依赖的值, 在 <linux/param.h>中定义或者它所包含的一个子平台文 件中. 在发布的内核源码中的缺省值在真实硬件上从 50 到 1200 嘀哒每秒, 在软件模拟 器中往下到 24.…...
循环神经网络中的梯度消失或梯度爆炸问题产生原因分析(二)
上一篇中讨论了一般性的原则,这里我们具体讨论通过时间反向传播(backpropagation through time,BPTT)的细节。我们将展示目标函数对于所有模型参数的梯度计算方法。 出于简单的目的,我们以一个没有偏置参数的循环神经…...

JWT signature does not match locally computed signature
1. 问题背景 最近在协助团队小盆友调试一个验签问题,结果还“节外生枝”了,原来不是签名过程的问题,是token的问题。 当你看到“JWT signature does not match locally computed signature. JWT validity cannot be asserted and should not…...
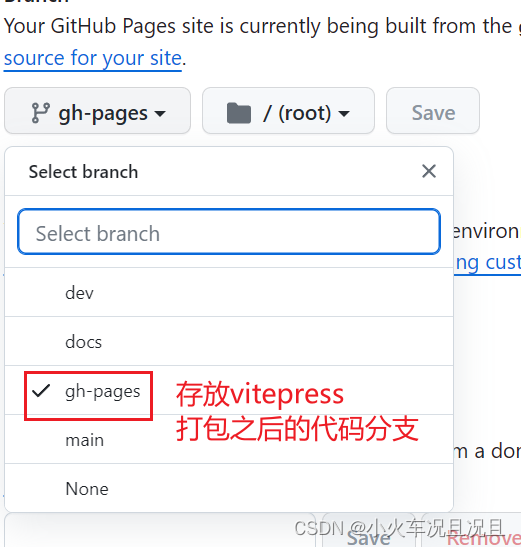
vitepress项目使用github的action自动部署到github-pages中,理论上可以通用所有
使用github的action自动部署到github-pages中 创建部署的deploy.yml文件,在项目的根目录下面 .github\workflows\deploy.yml 完整的代码:使用的是pnpm进行依赖安装。 name: 部署VitePresson:push:branches:- docs # 这段是在推送到 docs 分支时触发该…...

Python爬虫---解析---JSONPath
Xpath可以解析本地文件和服务器响应的文件,JSONPath只能解析本地文件 1. 安装jsonpath:pip install jsonpath 注意:需要安装在python解释器相同的位置,例如:D:\Program Files\Python3.11.4\Scripts 2. 使用步骤 2.1 导入&…...

路由器介绍和命令操作
先来回顾一下上次的内容: ip地址就是由32位二进制数组 二进位数就是只有数字0和1组成 网络位:类似于区号,表示区域作用 主机位:类似于号码,表示区域中编号 网络名称:网络位不变,主机位全为0 …...

Hadoop——分布式计算
一、分布式计算概述 1. 什么是计算、分布式计算? 计算:对数据进行处理,使用统计分析等手段得到需要的结果分布式计算:多台服务器协同工作,共同完成一个计算任务2. 分布式计算常见的2种工作模式分散->汇总 (MapReduce就是这种模式)将数据分片,多台服务器各自负责一…...

LaTeX引用参考文献 | Texstudio引用参考文献
图片版教程: 文字版教程: ref.bib里面写参考的文献,ref.bib和document.tex要挨着放,同一个目录里面. 解析一下bib文件格式:aboyeji2023effect是引用文献的关键字,需要在正文document.tex里面使用\cite指令…...

如何在Go中使用模板
引言 您是否需要以格式良好的输出、文本报告或HTML页面呈现一些数据?你可以使用Go模板来做到这一点。任何Go程序都可以使用text/template或html/template包(两者都包含在Go标准库中)来整齐地显示数据。 这两个包都允许你编写文本模板并将数据传递给它们,以按你喜欢的格式呈…...

云原生之深入解析基于FunctionGraph在Serverless领域的FinOps的探索和实践
一、背景 Serverless 精确到毫秒级的按用付费模式使得用户不再需要为资源的空闲时间付费。然而,对于给定的某个应用函数,由于影响其计费成本的因素并不唯一,使得用户对函数运行期间的总计费进行精确的事先估计变成了一项困难的工作。以传统云…...
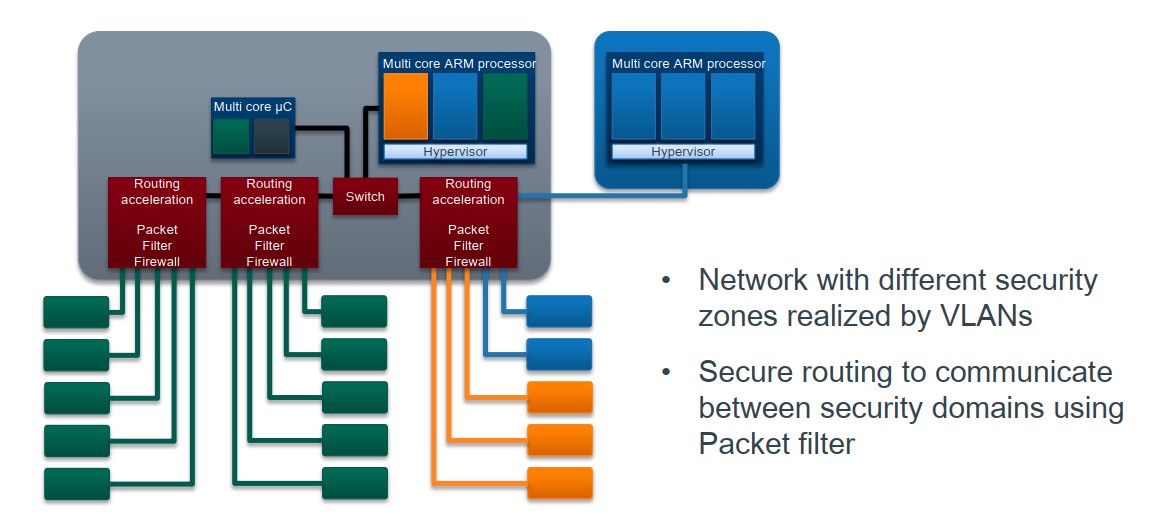
电子电器架构(E/E)演化 —— 主流主机厂域集中架构概述
电子电器架构(E/E)演化 —— 主流主机厂域集中架构概述 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。…...

Python常用的几个函数
print()函数:用于打印输出信息到控制台。 input()函数:用于从控制台获取用户输入。 len()函数:用于获取字符串、列表、元组、字典等对象的长度。 range()函数:用于生成一个整数序列,常用于循环中。 type()函数&…...
【Linux系统基础】(2)在Linux上部署MySQL、RabbitMQ、ElasticSearch等各类软件
实战章节:在Linux上部署各类软件 前言 为什么学习各类软件在Linux上的部署 在前面,我们学习了许多的Linux命令和高级技巧,这些知识点比较零散,同学们跟随着课程的内容进行练习虽然可以基础掌握这些命令和技巧的使用,…...
HarmonyOS4.0系统性深入开发01应用模型的构成要素
应用模型的构成要素 应用模型是HarmonyOS为开发者提供的应用程序所需能力的抽象提炼,它提供了应用程序必备的组件和运行机制。有了应用模型,开发者可以基于一套统一的模型进行应用开发,使应用开发更简单、高效。 HarmonyOS应用模型的构成要…...

线下终端门店调研包含哪些内容
品牌渠道一般分为线上和线下,线上的价格、促销信息、店铺优惠机制等都可以通过登录查看,但是线下门店的数据则需要进店巡查,否则无法得到真实的店铺销售数据,当然也有品牌是靠线下的业务团队报备机制获得这些信息,但是…...

倾斜摄影三维模型数据在行业应用分析
倾斜摄影三维模型数据在行业应用分析 倾斜摄影三维模型数据是一种重要的地理信息资源,可以广泛应用于各个行业和场景,以解决不同领域的问题。以下将详细探讨几个典型的行业或场景,它们利用倾斜摄影三维模型数据解决问题的应用。 1、地理测绘…...
Apache Flink 进阶教程(七):网络流控及反压剖析
目录 前言 网络流控的概念与背景 为什么需要网络流控 网络流控的实现:静态限速 网络流控的实现:动态反馈/自动反压 案例一:Storm 反压实现 案例二:Spark Streaming 反压实现 疑问:为什么 Flink(bef…...

MAX3421E USB主机控制器实战:为微控制器扩展USB外设连接能力
1. 项目概述:为你的微控制器打开USB主机世界的大门如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定对它们的USB设备功能不陌生——插上电脑就能被识别成一个串口、一个键盘或者一个U盘。但你想过反过来吗?让你的微控制器项目变成“…...

Path of Building PoE2深度技术解析:3大核心系统架构与实战优化指南
Path of Building PoE2深度技术解析:3大核心系统架构与实战优化指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 Path of Building PoE2作为流放之路2社区的顶级构建计算工具,…...

书匠策AI官网www.shujiangce.com:期刊论文从“渡劫“到“躺赢“,中间只差这一个工具
家人们,今天不讲课,今天带你们"开箱"一个我私藏很久的论文神器。 先说结论——书匠策AI( 官网直达:www.shujiangce.com) 的期刊论文功能,是我今年用过最"懂科研人"的AI工具ÿ…...

泛微E-Office V10 OfficeServer 文件上传漏洞深度剖析与实战复现
1. 漏洞背景与影响范围 泛微E-Office作为国内广泛使用的协同办公系统,其V10版本中的OfficeServer.php组件存在高危文件上传漏洞。这个漏洞的本质在于服务端未对上传文件的类型、内容及路径进行严格校验,导致攻击者可以绕过常规防护机制,直接上…...

基于eNSP的园区网络高可用与安全隔离综合实验
1. 实验背景与核心价值 园区网络作为企业数字化转型的基础设施,其稳定性和安全性直接关系到日常运营效率。记得去年参与某金融机构网络改造项目时,他们的核心业务系统因为单点故障导致全网瘫痪4小时,直接损失超过百万。这个案例让我深刻认识到…...

ChanlunX:通达信缠论分析的终极自动化解决方案
ChanlunX:通达信缠论分析的终极自动化解决方案 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX ChanlunX是一款专为通达信用户设计的开源缠论分析插件,通过智能算法将复杂的缠论理论…...

初探Taotoken平台提供的APIKey管理与访问控制功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初探Taotoken平台提供的APIKey管理与访问控制功能 效果展示类,作者以新用户视角,探索并描述在Taotoken控制…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

如何5分钟实现Windows系统自动化软件部署:winget-install完整指南
如何5分钟实现Windows系统自动化软件部署:winget-install完整指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_…...
.txt)