Hive 部署
一、介绍
Apache Hive是一个分布式、容错的数据仓库系统,支持大规模的分析。Hive Metastore(HMS)提供了一个中央元数据存储库,可以轻松地进行分析,以做出明智的数据驱动决策,因此它是许多数据湖架构的关键组件。Hive构建在Apache Hadoop之上,并通过hdfs支持S3,adls,gs等存储。Hive允许用户使用SQL读取、写入和管理PB级数据。
官网地址
二、架构
Hive中主要包含:Hive-Server 2 (HS2)、Hive Metastore Server (HMS)、以及Hive Client CLI
Hive-Server 2 (HS2):HS2支持多客户端并发和身份验证。它旨在为JDBC和ODBC等开放式API客户端提供更好的支持。
简单来说:HS2提供JDBC/ODBC访问接口和用户认证
Hive Metastore Server (HMS):是关系数据库中Hive表和分区的元数据的中央存储库,并使用元存储库服务API为客户端(包括Hive、Impala和Spark)提供对此信息的访问。
简单来说:Metastore提供元数据访问接口,不负责存储元数据,通常保存在MySQL当中
元数据:在Hive中创建的数据库、表、字段信息(不包含数据信息,数据信息存储在HDFS中)
Hive Client CLI:提供客户端访问,只能在安装了Hive的本地使用
三、环境搭建
3.1、最小化安装
部署版本:3.1.3
- 下载压缩包
下载地址
- 解压缩
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/modulemv apache-hive-3.1.3-bin/ /opt/module/hive
- 修改环境变量
vim /etc/profile.d/my_env.sh#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE/bin
- 刷新环境变量
source /etc/profile.d/my_env.sh
- 初始化元数据(默认使用derby数据库)
/opt/module/hive/bin/schematool -dbType derby -initSchema
- 启动hive
$HIVE_HOME/bin/hive
3.2、使用mysql存储元数据
- 创建元数据库
create database metastore;
- 将mysql的jdbc驱动上传到Hive的lib目录下

- 新建hive-site.xml文件
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
</configuration>
- 初始化元数据库
$HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose

3.3、Hive-Server 2(HS2) 部署
上面部署完hive只能在本地客户端访问,需要部署HS2才能使用远程jdcb连接访问
修改配置
# 该配置需要分发到所有hadoop节点
vim $HADOOP_HOME/etc/hadoop/core-site.xml<!--配置所有节点的root用户都可作为代理用户-->
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property><!--配置root用户能够代理的用户组为任意组-->
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property><!--配置root用户能够代理的用户为任意用户-->
<property><name>hadoop.proxyuser.root.users</name><value>*</value>
</property>
vim $HADOOP_HOME/etc/hadoop/hive-site.xml<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value>
</property><!-- 指定hiveserver2连接的端口号 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>
启动HS2
nohup $HIVE_HOME/bin/hive --service hiveserver2 &
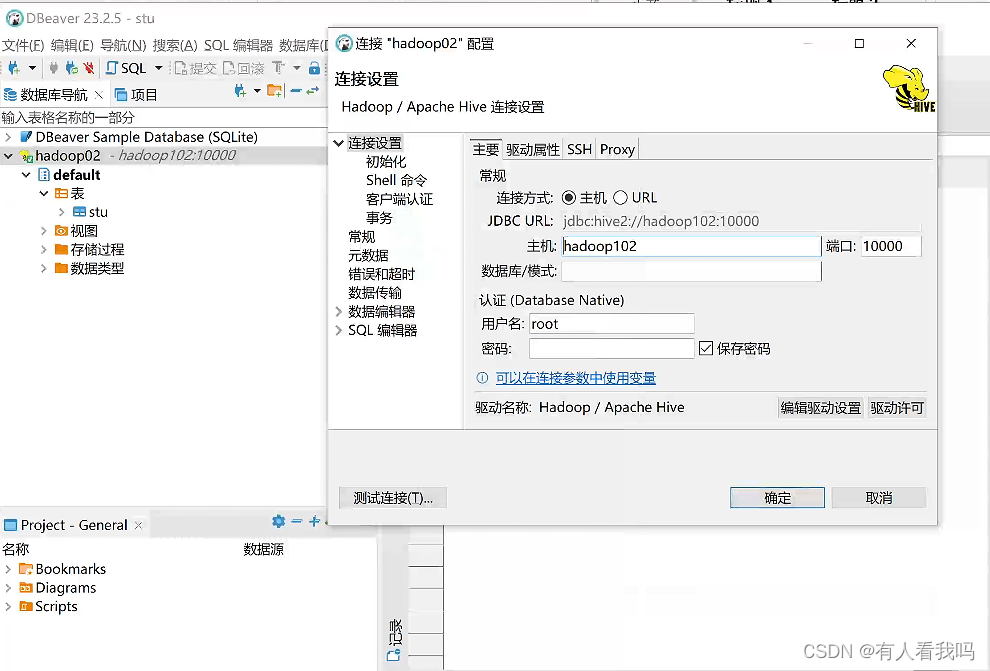
使用DBeaver远程连接
3.4、Hive Metastore Server (HMS) 部署
为Hive CLI或者Hiveserver2提供元数据访问接口(其本身不存储元数据)
HMS分为两种运行模式:嵌入式模式、独立服务模式
嵌入模式:在每个HS2和Hive CLI中都都嵌入HMS,不做额外配置的情况下,采用的是嵌入模式
独立模式:HMS独立部署,HS2和Hive CLI获取元数据信息通过访问HMS,再由HMS访问元数据
3.4.1、嵌入模式
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
</configuration>
3.4.1、独立模式
在嵌入模式的配置基础上增加,HS2和Hive CLI访问HMS的地址
<!-- 指定metastore服务的地址 -->
<property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value>
</property>
启动HMS
nohup $HIVE_HOME/bin/hive --service metastore &
相关文章:
Hive 部署
一、介绍 Apache Hive是一个分布式、容错的数据仓库系统,支持大规模的分析。Hive Metastore(HMS)提供了一个中央元数据存储库,可以轻松地进行分析,以做出明智的数据驱动决策,因此它是许多数据湖架构的关键组…...

CopyOnWriteArrayList源码阅读
1、构造方法 无参构造函数 //创建一个空数组,赋值给array引用 public CopyOnWriteArrayList() {setArray(new Object[0]); }//仅通过getArray / setArray访问的数组。 private transient volatile Object[] array;//设置数组 final void setArray(Object[] a) {arra…...

Windows操作系统:共享文件夹,防火墙的设置
1.共享文件夹 1.1 共享文件夹的优点 1.2 共享文件夹的优缺点 1.3 实例操作 编辑 2.防火墙设置 2.1 8080端口设置 3.思维导图 1.共享文件夹 1.1 共享文件夹的优点 优点 协作和团队合作:共享文件夹使多个用户能够在同一文件夹中协作和编辑文件。这促进了团…...
STM32独立看门狗
时钟频率 40KHZ 看门狗简介 STM32F10xxx 内置两个看门狗,提供了更高的安全性、时间的精确性和使用的灵活性。两个看 门狗设备 ( 独立看门狗和窗口看门狗 ) 可用来检测和解决由软件错误引起的故障;当计数器达到给 定的超时值时,触发一个中…...

财务数据智能化:用AI工具高效制作财务分析PPT报告
Step1: 文章内容提取 WPS AI 直接打开文件,在AI对话框里输入下面指令: 假设你是财务总监,公司考虑与茅台进行业务合作、投资或收购,请整合下面茅台2021年和2022年的财务报告信息。整理有关茅台财务状况和潜在投资回报的信息&…...

vue3中使用three.js记录
记录一下three.js配合vitevue3的使用。 安装three.js 使用npm安装: npm install --save three开始使用 1.定义一个div <template><div ref"threeContainer" class"w-full h-full"></div> </template>可以给这个di…...
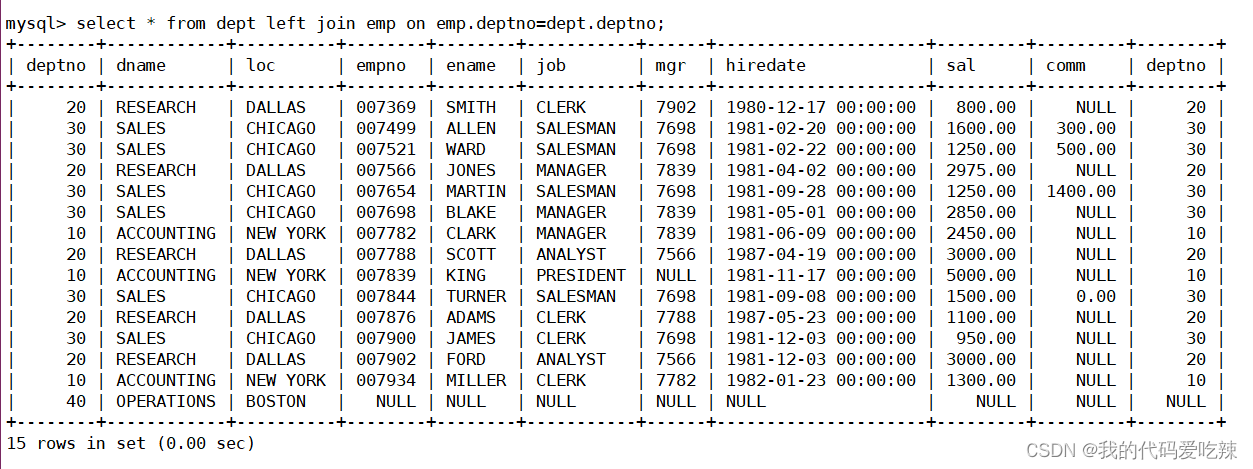
MySQL——表的内外连接
目录 一.内连接 二.外连接 1.左外连接 2.右外连接 一.内连接 表的连接分为内连和外连 内连接实际上就是利用where子句对两种表形成的笛卡儿积进行筛选,我们前面学习的查询都是内连接,也是在开发过程中使用的最多的连接查询。 语法: s…...

基于IPP-FFT的线性调频Z(Chirp-Z,CZT)的C++类库封装并导出为dll(固定接口支持更新)
上一篇分析了三种不同导出C++类方法的优缺点,同时也讲了如何基于IPP库将FFT函数封装为C++类库,并导出为支持更新的dll库供他人调用。 在此基础上,结合前面的CZT的原理及代码实现,可以很容易将CZT变换也封装为C++类库并导出为dll,关于CZT的原理和实现,如有问题请参考: …...

【C语言】指针
基本概念 在C语言中,指针是一种非常重要的数据类型,它用于存储变量的内存地址。指针提供了对内存中数据的直接访问,使得在C语言中可以进行灵活的内存操作和数据传递。以下是关于C语言指针的一些基本概念: 1. 指针的声明ÿ…...

PostgreSql 索引使用技巧
索引种类详情可参考《PostgreSql 索引》 一、适合创建索引的场景 经常与其他表进行连接的表,在连接字段上应该建索引。经常出现在 WHERE 子句中的字段,特别是大表的字段,应该建索引。经常出现在 ORDER BY 子句中的字段,应该建索…...

【华为数据之道学习笔记】6-7打造业务自助分析的关键能力
华为公司将自助分析作为一种公共能力,在企业层面进行了统一构建。一方面,面向不同的消费用户提供了差异性的能力和工具支撑;另一方面,引入了“租户”概念,不同类型的用户可以在一定范围内分析数据、共享数据结果。 1. …...

K8S从harbor中拉取镜像的规则imagePullPolicy
1、参数 配制参数为:imagePullPolicy: 可以选择的值有:Always,IfNotPresent,Never 2、参数结果 如果pod的镜像拉取策略为imagePullPolicy: Always:当harbor不能运行后,pod会一直从harbor上拉…...
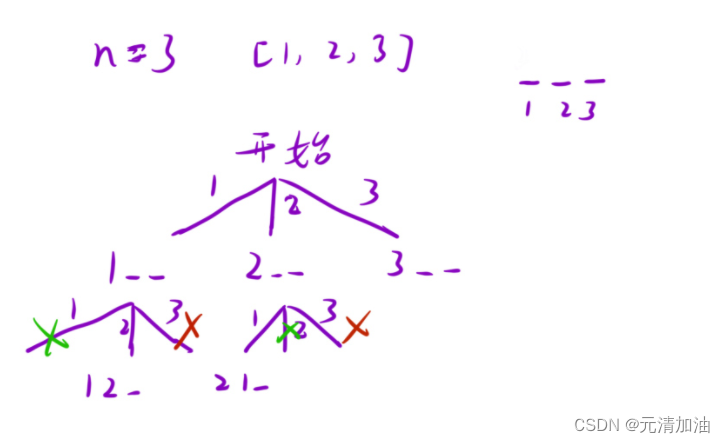
LeetCode刷题--- 优美的排列
个人主页:元清加油_【C】,【C语言】,【数据结构与算法】-CSDN博客元清加油_【C】,【C语言】,【数据结构与算法】-CSDN博客 个人专栏 力扣递归算法题 http://t.csdnimg.cn/yUl2I 【C】 http://t.csdnimg.cn/6AbpV 数据结构与算法 http://t.cs…...
关于edge浏览器以及插件推荐【亲测好用】
一.edge浏览器介绍 Edge 浏览器是由微软公司开发的一款新一代网络浏览器。它最初于2015年发布,是微软Windows 10 操作系统的默认浏览器,后来还推出了适用于 Android 和 iOS 等移动设备的版本。Edge 浏览器采用了全新的浏览器内核,称为 Micros…...
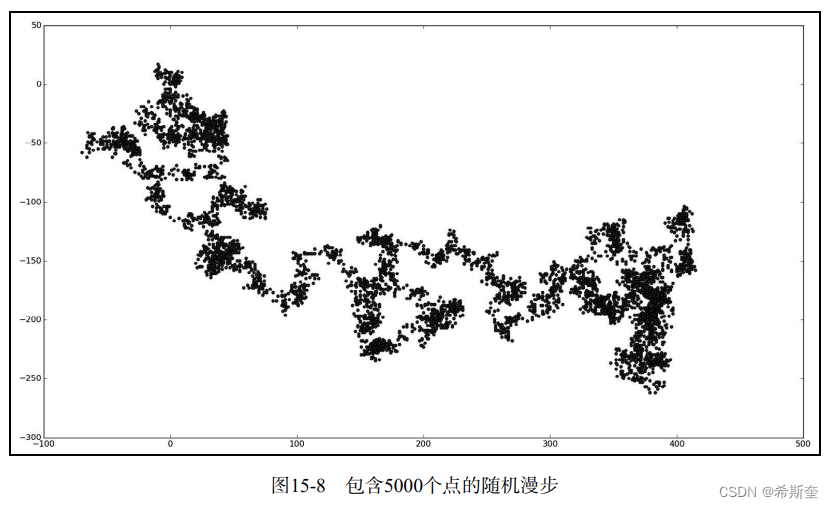
关于“Python”的核心知识点整理大全43
目录 编辑 15.2.3 使2散点图并设置其样式 scatter_squares.py 15.2.4 使用 scatter()绘制一系列点 scatter_squares.py 15.2.5 自动计算数据 scatter_squares.py 15.2.6 删除数据点的轮廓 15.2.7 自定义颜色 15.2.8 使用颜色映射 scatter_squares.py 注意 15.2.9…...

Android Framework一些问题思考
一,zygote通信为什么用socket,而不是binder? 1,binder通信依赖用户空间进程Servicemanager,socket通信不依赖用户空间进程。zygote与servicemanager, surfaceflinger等都是通过各自init.rc文件被init进程解析加载,时…...

2024年安全员-C证证考试题库及安全员-C证试题解析
题库来源:安全生产模拟考试一点通公众号小程序 2024年安全员-C证证考试题库及安全员-C证试题解析是安全生产模拟考试一点通结合(安监局)特种作业人员操作证考试大纲和(质检局)特种设备作业人员上岗证考试大纲随机出的…...

推广主要指标及定义
推广主要指标以直通车为例解释,如图所示 1.展示量:当消费者搜索某个词,推广计划在天猫直通车展示位上被买家看到的次数(去掉被消费者快进划过、主图未完金展现等情况产生的曝光); 2.点击量:消费者看到广告…...
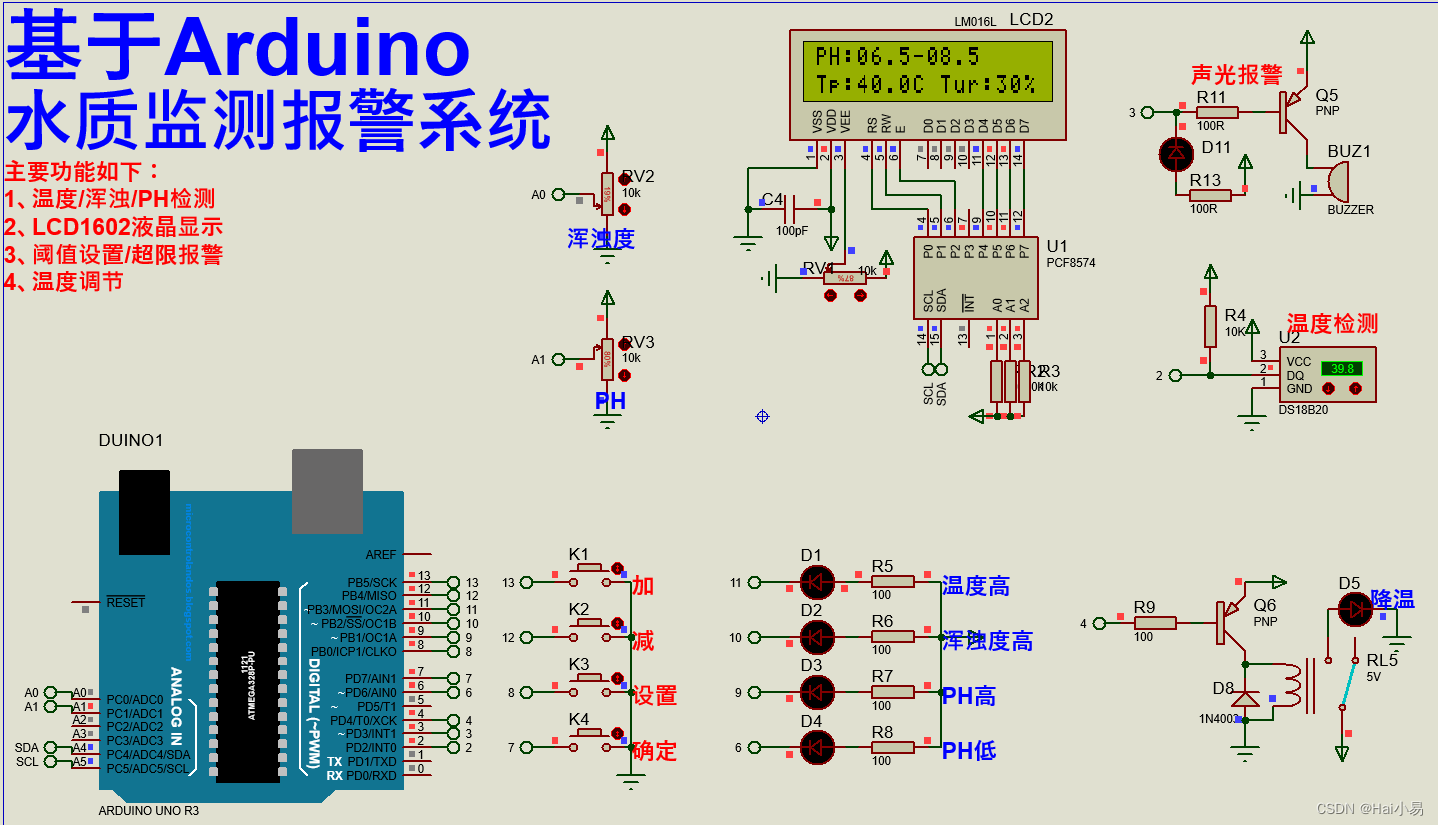
【Proteus仿真】【Arduino单片机】水质监测报警系统设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真Arduino单片机控制器,使用按键、LED、蜂鸣器、LCD1602、ADC、PH传感器、浑浊度传感器、DS18B20温度传感器、继电器模块等。 主要功能: 系统运行后…...
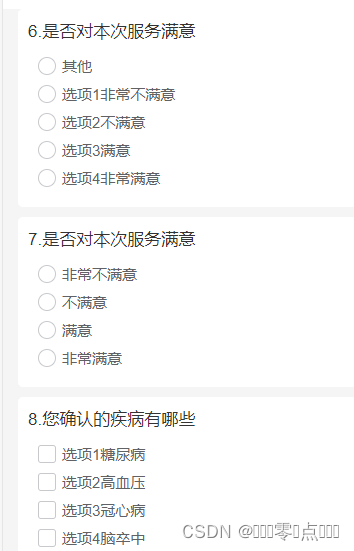
随机问卷调查数据的处理(uniapp)
需求:问卷调查 1.返回的数据中包含单选、多选、多项文本框、单文本框、图片上传 2.需要对必填的选项进行校验 3.非必填的多项文本框内容 如果不填写 不提交 表单数据格式 res{"code": 0,"msg": null,"data": [{"executeDay&…...

MapReduce与Spark核心原理对比:从批处理到内存计算的演进
1. 从“批处理之王”到“内存计算引擎”:大数据处理范式的演进如果你刚接触大数据领域,可能会被Hadoop、MapReduce、Spark这些名词搞得晕头转向。它们听起来都像是处理海量数据的“重型武器”,但各自的设计哲学和适用场景却大相径庭。简单来说…...
)
保姆级教程:在Vue3项目中用ZLMediaKit+WebRTC实现超低延迟监控直播(附完整代码)
Vue3WebRTC超低延迟监控直播实战指南 在实时视频监控领域,延迟是衡量系统性能的核心指标之一。传统RTSP流媒体方案在Web端实现时,往往面临秒级甚至更长的延迟,这在对实时性要求极高的安防监控、工业检测等场景中成为致命短板。本文将深入探讨…...

大规模矩阵SVD与GSVD计算方法【附代码】
✨ 长期致力于办公建筑设计、建筑能耗、光性能、热性能、modeFRONTIER、多目标优化、性能模拟、寒冷地区研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...

MoE大模型核心揭秘:Router路由机制与活跃参数原理
1. 这不是“参数越多越强”的简单故事:拆解大模型里那个被悄悄藏起来的“开关”你肯定见过这类标题:“GPT-4参数量达1.8万亿!”、“DeepSeek-R1狂堆6710亿参数!”——光看数字,像在比谁家粮仓更大。但真正干过模型部署…...

GEO优化的时间窗口期:从流量分发到语义占位的技术范式转移
过去几十年,互联网的信息检索逻辑建立在倒排索引与超链接分析的基础之上:用户输入关键词,搜索引擎通过爬虫抓取并返回链接列表,网站则通过SEO(搜索引擎优化)争夺SERP(搜索结果页)的排…...
)
从V2L到V2G:深度解析双向OBC的HIL测试如何模拟真实用车场景(含CANoe SmartCharging配置)
从露营供电到电网互动:双向OBC的HIL测试实战指南 清晨的山谷里,一辆新能源车静静停驻在营地旁。车主取出便携式电烤盘,将充电枪插入车辆交流充电口,几分钟后烤盘上的牛排开始滋滋作响——这看似简单的场景背后,是双向O…...

为什么你的ElevenLabs挪威语输出总被用户投诉“像AI朗读”?——基于217小时母语者A/B测试的5个声学参数调优阈值
更多请点击: https://intelliparadigm.com 第一章:挪威语语音“AI感”感知机制与母语者听觉认知模型 当挪威语母语者听到由现代TTS系统(如Coqui TTS或Azure Neural TTS)生成的挪威语语音时,常产生一种微妙的“AI感”—…...

Godot 4.3 RTS开发实战:事件驱动架构与指令队列优化
1. 这不是又一个“Hello World”教程:RTS游戏在Godot里到底难在哪?你点开过十几个“Godot RTS教程”,结果发现前两分钟还在画UI按钮,第三分钟就跳到“接下来我们用NavigationServer实现寻路”——然后卡住。你翻遍官方文档&#x…...

基于项目代码实测:XCP/CCP 模块“标定差异”全流程深度操作指南
在实际项目的 XCP/CCP 标定业务中,核对与同步底层内存参数是一项极其高频的操作。本指南将完全基于最新版“标定差异(Calibration Difference)”界面的真实功能逻辑,为你提供一份严谨、详细、且立即可用的三倍容量操作手册。无论你…...
)
从零开始学AI Agent:软件工程视角下的企业数字化转型实践指南(收藏版)
本文从软件工程视角出发,探讨了AI Agent在企业数字化转型中的应用与构建。首先强调需求分析的重要性,指出应从业务问题出发判断Agent是否适用。接着,介绍了Agent的系统设计,包括任务编排、上下文管理、记忆存储和工具扩展四个核心…...