LLM之RAG实战(八)| 使用Neo4j和LlamaIndex实现多模态RAG
人工智能和大型语言模型领域正在迅速发展。一年前,没有人使用LLM来提高生产力。时至今日,很难想象我们大多数人或多或少都在使用LLM提供服务,从个人助手到文生图场景。由于大量的研究和兴趣,LLM每天都在变得越来越好、越来越聪明。不仅如此,他们的理解也开始跨越多种模态。随着GPT-4-Vision和随后的其他LLM的引入,今天的LLM似乎可以很好地处理和理解图像。以下是ChatGPT描述图像中内容的一个示例。

正如所观察到的,ChatGPT非常善于理解和描述图像。我们可以在RAG应用程序中使用其理解图像的能力,在该应用程序中,我们现在可以将文本和图片中的信息结合起来,生成比以往任何时候都更准确的答案,而不仅仅依靠文本来生成准确和最新的答案。使用LlamaIndex,实现多模态RAG pipeline非常容易。受(https://github.com/run-llama/llama_index/blob/main/docs/examples/multi_modal/gpt4v_multi_modal_retrieval.ipynb)的启发,来测试是否可以使用Neo4j作为数据库来实现多模态RAG应用程序。
要使用LlamaIndex实现多模态RAG管道,只需实例化两个矢量存储,一个用于图像,另一个用于文本,然后查询这两个矢量,以便检索相关信息以生成最终答案。
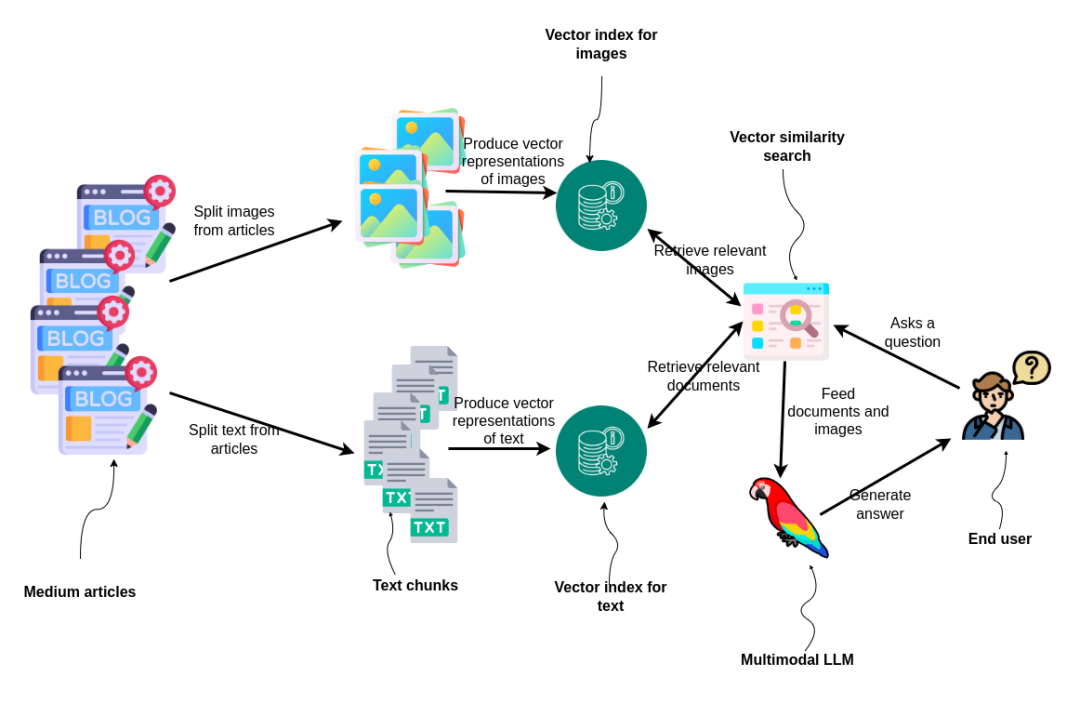
多模态RAG首先需要将数据分为图像和文本,然后分别进行embedding并单独构建索引。对于文本,我们将使用ada-002文本嵌入模型;而对于图像,我们将采用[双编码器模型CLIP](https://github.com/openai/CLIP),CLIP可以将文本和图像嵌入到同一嵌入空间中。当最终用户提出问题时,执行两个向量的相似性搜索:一个用于查找相关图像,另一个用于文档。结果被输入到多模态LLM中,该LLM为用户生成答案,展示了处理和利用混合媒体进行信息检索和响应生成的综合方法。
数据预处理
我们将使用[Medium](https://github.com/tomasonjo/blog-datasets/blob/main/articles.zip)作为RAG应用程序的基础数据集。这些文章包含了关于Neo4j图形数据科学库以及将Neo4j与LLM框架相结合的大量信息。从Medium下载的文章是HTML格式。因此,我们需要使用一些编码来分别提取文本和图像。
def process_html_file(file_path):with open(file_path, "r", encoding="utf-8") as file:soup = BeautifulSoup(file, "html.parser")# Find the required sectioncontent_section = soup.find("section", {"data-field": "body", "class": "e-content"})if not content_section:return "Section not found."sections = []current_section = {"header": "", "content": "", "source": file_path.split("/")[-1]}images = []header_found = Falsefor element in content_section.find_all(recursive=True):if element.name in ["h1", "h2", "h3", "h4"]:if header_found and (current_section["content"].strip()):sections.append(current_section)current_section = {"header": element.get_text(),"content": "","source": file_path.split("/")[-1],}header_found = Trueelif header_found:if element.name == "pre":current_section["content"] += f"```{element.get_text().strip()}```\n"elif element.name == "img":img_src = element.get("src")img_caption = element.find_next("figcaption")caption_text = img_caption.get_text().strip() if img_caption else ""images.append(ImageDocument(image_url=img_src))elif element.name in ["p", "span", "a"]:current_section["content"] += element.get_text().strip() + "\n"if current_section["content"].strip():sections.append(current_section)return images, sections
不会详细介绍解析代码,但我们根据标题h1–h4分割文本并提取图像链接。然后,我们只需通过此函数运行所有文章,即可提取所有相关信息。
all_documents = []all_images = []# Directory to search in (current working directory)directory = os.getcwd()# Walking through the directoryfor root, dirs, files in os.walk(directory):for file in files:if file.endswith(".html"):# Update the file path to be relative to the current directoryimages, documents = process_html_file(os.path.join(root, file))all_documents.extend(documents)all_images.extend(images)text_docs = [Document(text=el.pop("content"), metadata=el) for el in all_documents]print(f"Text document count: {len(text_docs)}") # Text document count: 252print(f"Image document count: {len(all_images)}") # Image document count: 328
总共得到252个文本块和328个图像。
对数据创建索引
如前所述,我们必须实例化两个矢量存储,一个用于图像,另一个用于文本。CLIP嵌入模型的尺寸为512,而ada-002的尺寸为1536。
text_store = Neo4jVectorStore(url=NEO4J_URI,username=NEO4J_USERNAME,password=NEO4J_PASSWORD,index_name="text_collection",node_label="Chunk",embedding_dimension=1536)image_store = Neo4jVectorStore(url=NEO4J_URI,username=NEO4J_USERNAME,password=NEO4J_PASSWORD,index_name="image_collection",node_label="Image",embedding_dimension=512)storage_context = StorageContext.from_defaults(vector_store=text_store)
现在向量索引已经创建好了,我们使用MultiModalVectorStoreIndex来索引这两种模态的信息。
# Takes 10 min without GPU / 1 min with GPU on Google collabindex = MultiModalVectorStoreIndex.from_documents(text_docs + all_images, storage_context=storage_context, image_vector_store=image_store)
MultiModalVectorStoreIndex使用文本和图像嵌入模型来计算嵌入,并在Neo4j中存储和索引结果。仅为图像存储URL,而不是实际的base64或图像的其他表示。
多模态RAG pipeline
这段代码是直接从LlamaIndex多模式烹饪书中复制的。我们首先定义一个多模态LLM和prompt template,然后将所有内容组合为一个查询引擎。
openai_mm_llm = OpenAIMultiModal(model="gpt-4-vision-preview", max_new_tokens=1500)qa_tmpl_str = ("Context information is below.\n""---------------------\n""{context_str}\n""---------------------\n""Given the context information and not prior knowledge, ""answer the query.\n""Query: {query_str}\n""Answer: ")qa_tmpl = PromptTemplate(qa_tmpl_str)query_engine = index.as_query_engine(multi_modal_llm=openai_mm_llm, text_qa_template=qa_tmpl)
现在我们可以继续测试它的性能了。
query_str = "How do vector RAG application work?"response = query_engine.query(query_str)print(response)

我们还可以可视化检索提取的图像以及用于帮助提供最终答案的图像。
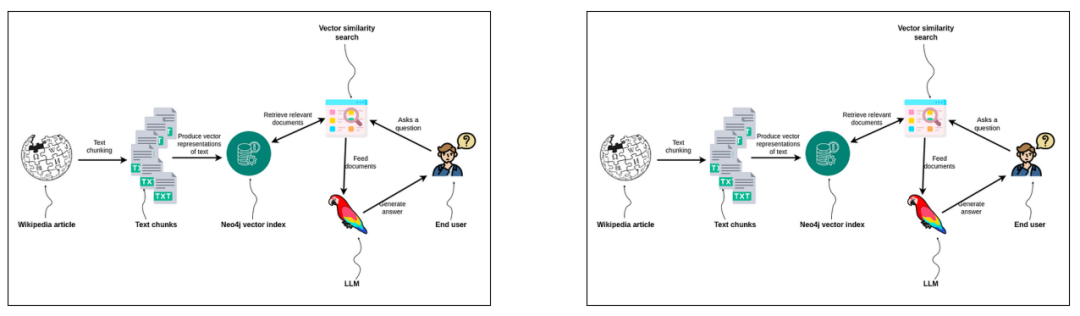
LLM得到了两个相同的图像作为输入,说明数据集中有重复的图。然而,我对CLIP嵌入感到惊喜,因为他们能够检索到该系列中最相关的图像。在生产环境中,一般需要对数据做预处理,去除重复数据,本文不做此介绍。
结论
LLM的发展速度比我们历史上习惯的要快,并且跨越了多种模态。我坚信,到明年年底,LLM将很快能够理解视频,因此能够在与你交谈时获得非语言提示。另一方面,我们可以使用图像作为RAG管道的输入,并增强传递给LLM的各种信息,使响应更好、更准确。使用LlamaIndex和Neo4j实现多模式RAG管道非常简单。
参考文献:
[1] https://blog.llamaindex.ai/multimodal-rag-pipeline-with-llamaindex-and-neo4j-a2c542eb0206
[2] https://github.com/tomasonjo/blogs/blob/master/llm/neo4j_llama_multimodal.ipynb
相关文章:
LLM之RAG实战(八)| 使用Neo4j和LlamaIndex实现多模态RAG
人工智能和大型语言模型领域正在迅速发展。一年前,没有人使用LLM来提高生产力。时至今日,很难想象我们大多数人或多或少都在使用LLM提供服务,从个人助手到文生图场景。由于大量的研究和兴趣,LLM每天都在变得越来越好、越来越聪明。…...
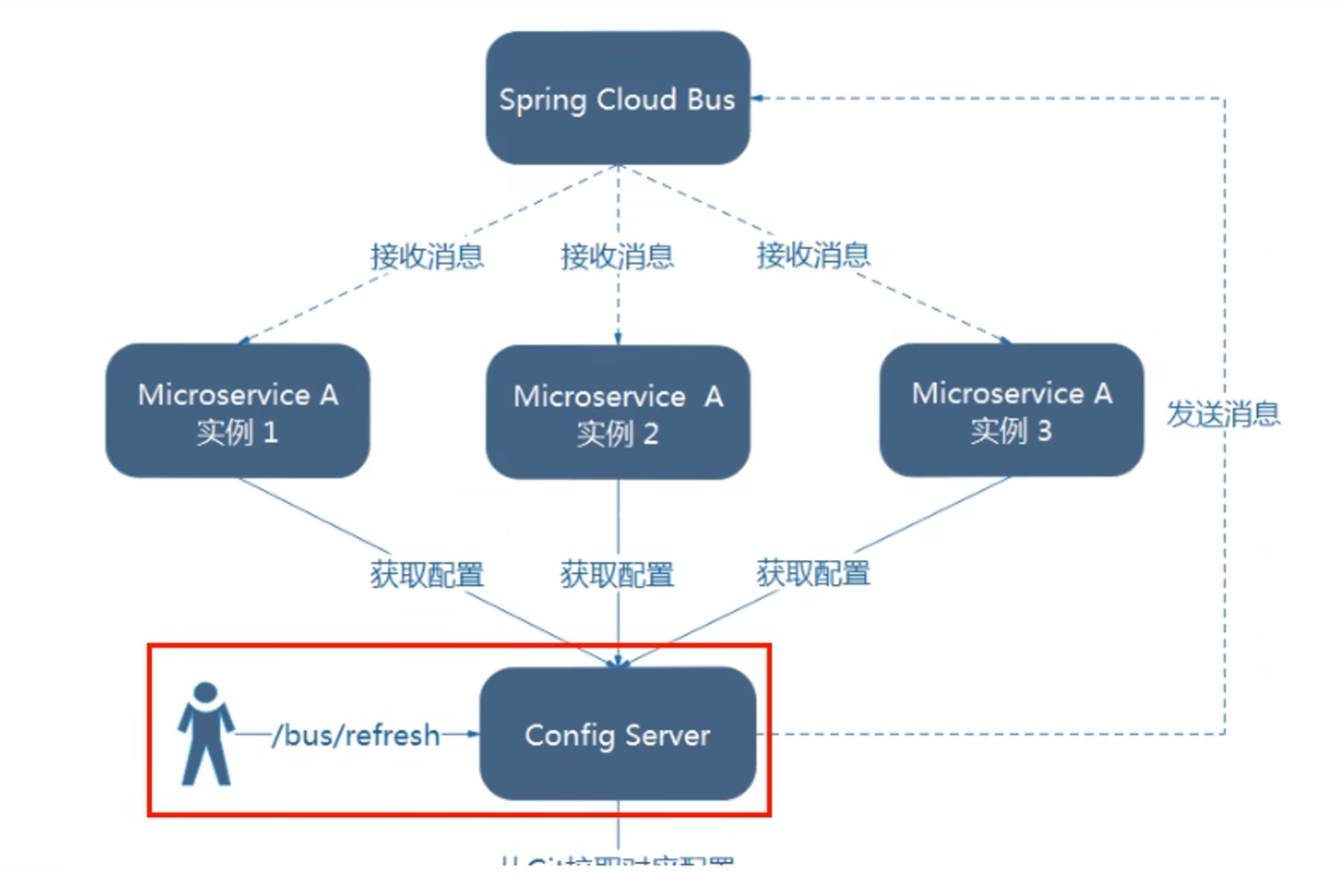
【SpringCloud笔记】(10)消息总线之Bus
Bus 前言 戳我了解Config 学习Config中我们遇到了一个问题: 当我们修改了GitHub上配置文件内容,微服务需要配置动态刷新并且需要手动向客户端发送post请求刷新微服务之后才能获取到GitHub修改过后的内容 假如有多个微服务客户端3355/3366/3377…等等…...

超酷的爬虫可视化界面
大家好,本文主要介绍使用tkinter获取本地文件夹、设置文本、创建按钮下拉框和对界面进行布局。 1.导入tkinter库 导入tkinter的库,可以使用ttkbootstrap美化生成的界面 ttkbootstrap官网地址:https://ttkbootstrap.readthedocs.io/en/late…...

【kafka消息里会有乱序消费的情况吗?如果有,是怎么解决的?】
文章目录 什么是消息乱序消费了?顺序生产,顺序存储,顺序消费如何解决乱序数据库乐观锁是怎么解决这个乱序问题吗 保证消息顺序消费两种方案固定分区方案乐观锁实现方案 前几天刷着视频看见评论区有大佬问了这个问题:你们的kafka消…...

【PID精讲12】基于MATLAB和Simulink的仿真教程
文章目录 写在前面一、基于Simulink的仿真1. 新建Simulink模型2. 保存Simulink模型3. 建模4. 运行二、基于MATLAB的仿真1. 编码2. 运行3. 调整曲线格式4. 导出图窗写在前面 第11讲介绍的连续系统的数字PID仿真是基于 Matlab的 M 语言实现的,对于初学者或者工程应用人员来说,…...

手机无人直播:解放直播的新方式
现如今,随着科技的迅猛发展,手机已经成为我们生活中不可或缺的一部分。除了通讯、娱乐等功能外,手机还能够通过直播功能将我们的生活实时分享给他人。而针对传统的直播方式,使用手机进行无人直播成为了一种全新的选择。 手机无人…...

ios 之 数据库、地理位置、应用内跳转、推送、制作静态库、CoreData
第一节:数据库 常见的API SQLite提供了一系列的API函数,用于执行各种数据库相关的操作。以下是一些常用的SQLite API函数及其简要说明:1. sqlite3_initialize:- 初始化SQLite库。通常在开始使用SQLite之前调用,但如果没有调用&a…...

Django(三)
1.快速上手 确保app已注册 【settings.py】 编写URL和视图函数对应关系 【urls.py】 编写视图函数 【views.py】 启动django项目 命令行启动python manage.py runserverPycharm启动 1.1 再写一个页面 2. templates模板 2.1 静态文件 2.1.1 static目录 2.1.2 引用静态…...
vscode括号颜色突然变成白色的了,怎么解决
更新版本后发现vscode的各种括号都变成了白色,由于分色括号已经使用习惯,突然变成白色非常不舒服,尝试多次后,为大家提供一下几种解决方式,希望能帮到同样受到此种困惑的你: 第一种: 首先打开…...

测试服务器带宽(ubuntu)
apt install python3 python3-pippip3 install speedtest-clispeestest-cli...
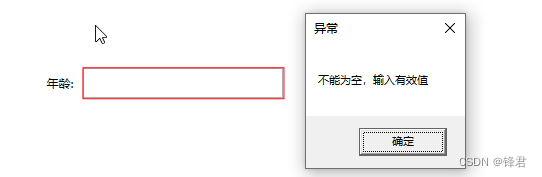
【WPF】使用Behavior以及ValidationRule实现表单校验
文章目录 使用ValidationRule实现检测用户输入EmptyValidationRule 非空校验TextBox设置非空校验TextBox设置非空校验并显示校验提示 结语 使用ValidationRule实现检测用户输入 EmptyValidationRule是TextBox内容是否为空校验,TextBox的Binding属性设置ValidationRu…...
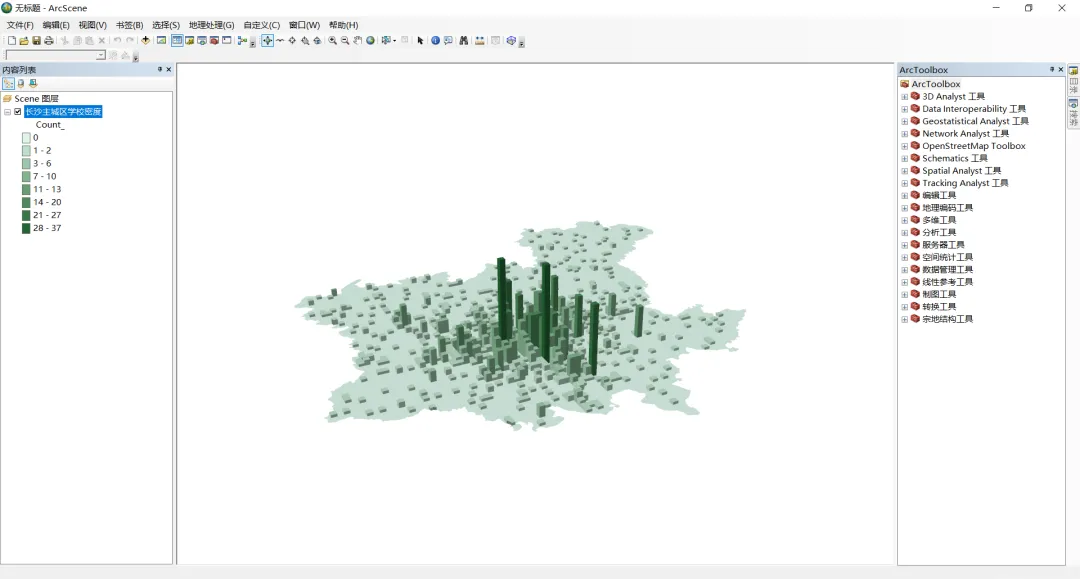
ArcGIS渔网的多种用法
在ArcGIS中有一个渔网工具,顾名思义,可以用来创建包含由矩形像元所组成网络的要素类。不太起眼,但它的用途却有很多,今天跟大家分享一篇关于渔网的多种用途。 1.马赛克地图制作 2.基于网格的设施密度统计制作马赛克地图 准备材…...

C++ 中使用 std::map 的一个示例
std::map 是一个容器,可以用来存储键值对,其中键是唯一的,每个键都映射到一个值 #include <iostream> #include <map>int main() {// 声明了一个 std::map<std::string, int> 类型的变量 myMap,它可以将字符串…...

python虚拟环境及其在项目实践中的应用
文章目录 1.问题的提出1.什么是python虚拟环境2.如何创建2.1第1步-为共享同一虚拟环境的项目创建共同的父目录2.2第2步-在父目录下创建虚拟python环境2.3在父目录下创建各个项目文件夹 1.问题的提出 假设我正在开发若干python项目,这里假定项目名分别为Project1&am…...

普中STM32-PZ6806L开发板(烧录方式)
前言 有两种方式, 串口烧录和STLink方式烧录;串口烧录 步骤 开发板USB转串口CH340驱动板接线到USB连接PC使用自带工具普中自动下载软件.exe烧录程序到开发板 ST Link方式 这种方式需要另外进行供电, 我买的如下,当年用于调试STM8的,也可…...

基于单片机设计的指纹锁(读取、录入、验证指纹)
一、前言 指纹识别技术是一种常见的生物识别技术,利用每个人指纹的唯一性进行身份认证。相比于传统的密码锁或者钥匙锁,指纹锁具有更高的安全性和便利性,以及防止钥匙丢失或密码泄露的优势。 基于单片机设计的指纹锁项目是利用STC89C52作为…...
HarmonyOS - 基础组件绘制
文章目录 所有组件开发 tipsBlankTextImageTextInputButtonLoadingProgress 本文改编自:<HarmonyOS第一课>从简单的页面开始 https://developer.huawei.com/consumer/cn/training/course/slightMooc/C101667360160710997 所有组件 在 macOS 上,组…...
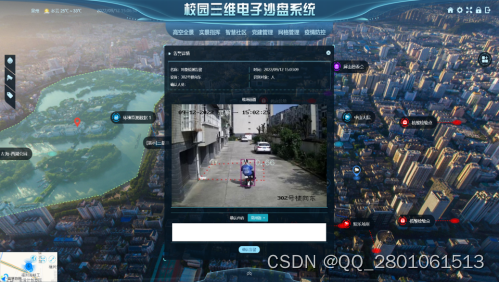
AR智慧校园三维主电子沙盘系统研究及应用
一 、概述 易图讯科技(www.3dgis.top)自主研发的智慧校园三维主电子沙盘系统,采用B/S架构模式,采用自主可控高性能WebGIS可视化引擎,支持多用户客户端通过网络请求访问服务器地图和专题数据,提供地理信息数据、专题数据的并发访问…...

web前端项目-七彩夜空烟花【附源码】
web前端项目-七彩动态夜空烟花【附源码】 本项目仅使用了HTML,代码简单,实现效果绚丽,且本项目代码直接运行即可实现,无需图片素材,接下来让我们一起实现一场美丽的烟花秀叭 运行效果:鼠标点击和移动可控制…...

在k8s中将gitlab-runner的运行pod调度到指定节点
本篇和前面的 基于helm的方式在k8s集群中部署gitlab 具有很强的关联性,因此如果有不明白的地方可以查看往期分享: 基于helm的方式在k8s集群中部署gitlab - 部署基于helm的方式在k8s集群中部署gitlab - 备份恢复基于helm的方式在k8s集群中部署gitlab - 升…...

龙芯3A5000开发板PMON升级UEFI固件实战指南
1. 项目概述:从“能用”到“好用”的固件升级之路最近折腾了一块搭载龙芯3A5000处理器的开发板,型号是迅为的LS3A5000。拿到手的时候,板子预装的固件还是传统的PMON。PMON对于玩龙芯的老朋友来说不陌生,它功能稳定,但界…...

福田区全栈式鸿蒙AI数智机关入选全市首批OR示范应用项目,深开鸿筑牢政务安全底座
5月13日,在第五次深圳市OR大会暨软信投促大会上,福田区机关事务管理局申报的全栈式鸿蒙AI数智机关,作为全市首批OR示范应用项目亮相,让区委大院成为备受瞩目的“实景展厅”,吸引了24家企业组团实地调研。作为目前在复合…...

【Perplexity环境新闻搜索实战指南】:20年老炮亲授3大避坑法则与实时情报提纯术
更多请点击: https://intelliparadigm.com 第一章:Perplexity环境新闻搜索实战指南导论 Perplexity 是一款以实时、可信与上下文感知为设计核心的 AI 搜索工具,其底层融合了多源新闻 API、语义检索模型及动态引用验证机制,特别适…...

Arm Cortex-A715向量计算优化指南:ASIMD/SVE指令深度解析
1. Cortex-A715向量计算引擎深度解析在移动计算和嵌入式领域,Arm Cortex-A715作为最新一代高性能CPU核心,其向量计算能力直接决定了AI推理、图像处理等关键场景的性能表现。本文将深入剖析A715的ASIMD/SVE指令集架构设计,从底层硬件机制到实际…...

Kubernetes Operator开发实战
Kubernetes Operator开发实战 一、Operator概述 Kubernetes Operator是一种软件扩展模式,用于管理复杂的有状态应用。 1.1 Operator模式 ┌──────────────────────────────────────────────────────────…...

别再只盯着CPU内存了!用Prometheus+Grafana打造你的K8S应用黄金监控仪表盘
从基础设施到业务价值:用PrometheusGrafana构建Kubernetes应用黄金监控体系 当Kubernetes集群中的Pod状态全部显示"Running"时,很多团队会误以为万事大吉。直到某天凌晨3点,客服系统被用户投诉淹没,才发现订单成功率已暴…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...
如何用Pixelle-Video实现零门槛AI短视频创作:新手完全指南
如何用Pixelle-Video实现零门槛AI短视频创作:新手完全指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 你是否曾经想制作…...

语音钓鱼中转窝点运作机理与全链条防控研究 —— 基于韩国仁川警方案例
摘要 2026 年 5 月 19 日韩国仁川西部警方通报,破获一起以高薪兼职为诱饵招募人员、在住宿场所运营语音钓鱼中转窝点的案件,抓获两名管理人员,查获一次性手机 105 部、冒用他人身份 SIM 卡 356 张、无线路由器 4 台,涉案人员通过远…...
)
别再只用CIoU了!手把手教你用WIoU损失函数提升YOLOv5/v8模型精度(附代码对比)
超越CIoU:用WIoU损失函数解锁YOLOv5/v8模型的隐藏潜力 当目标检测模型的mAP指标陷入停滞,许多工程师的第一反应是调整数据增强策略或更换更复杂的网络结构。但鲜少有人意识到,损失函数这个看似基础的组件,往往才是突破精度瓶颈的…...