【Python机器学习系列】一文带你了解机器学习中的Pipeline管道机制(理论+源码)
这是Python机器学习原创文章,我的第183篇原创文章。
一、引言
对于表格数据,一套完整的机器学习建模流程如下:

背景知识1:机器学习中的学习器
【Python机器学习系列】一文搞懂机器学习中的转换器和估计器(附案例)
背景知识2:机器学习中的管道机制
简介:
转换器用于数据的预处理和特征工程,它们无状态且只学习转换规则。而估计器用于模型的训练和预测,它们有状态且学习训练数据中的模式和规律。转换器和估计器在机器学习中扮演不同的角色,但它们通常可以结合在一起构建一个完整的机器学习流程。
机器学习的管道(Pipeline)机制通过将多个转换器和估计器按顺序连接在一起,可以构建一个完整的数据处理和模型训练流程。在管道机制中,可以使用Pipeline类来组织和连接不同的转换器和估计器。Pipeline类提供了一种简单的方式来定义和管理机器学习任务的流程。
好处:
1.管道机制是按照封装顺序依次执行的一种机制,在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
2.可以结合grid search对参数进行选择。
二、实现过程
导入第三方库
import pandas as pd
from sklearn.pipeline import Pipeline #管道机制
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split #分训练和测试集
#导入“流水线”各个模块(标准化,降维,分类)
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)
target = 'target'
features = df.columns.drop(target)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)
2.1 建立管道进行分类预测
steps为Pipeline类最关键的参数,sklearn规定它是一个[( ),( )]类型,列表里面是一个个元组,分别为名字和工序,从左到右是流水线上的先后顺序。Pipleline中最后一个之外的所有estimators都必须是变换器(transformers),最后一个estimator可以是任意类型(transformer,classifier,regresser),如果最后一个estimator是个分类器,则整个pipeline就可以作为分类器使用,如果最后一个estimator是个聚类器,则整个pipeline就可以作为聚类器使用。如果你不想为每一个步骤提供用户指定的名称,这种情况下,就可以用make_pipeline函数创建管道,它可以为我们创建管道并根据每个步骤所属的类为其自动命名。
# pipe=Pipeline(steps=[('standardScaler',StandardScaler()), ('pca', PCA()), ('svc',SVC())])
pipe=make_pipeline(StandardScaler(),PCA(),SVC())
pipe.predict(X_test) #预测结果
print('Test accuracy: %.3f' % pipe.score(X_test, y_test))#输出精度输出:
![]()
2.2 管道流水线+网格搜索参数
在机器学习中,超参数是模型的配置参数,需要在训练之前设置,并且不能通过模型的学习过程来自动调整。超参数的选择对于模型的性能和泛化能力非常重要,因此需要通过实验来确定最佳的超参数组合。GridSearchCV是scikit-learn库中的一个类,用于进行网格搜索(Grid Search)和交叉验证(Cross-Validation)来选择模型的最佳超参数。使用GridSearchCV时,需要提供一个估计器(Estimator)对象、超参数的候选值列表和评估指标(如准确率、均方误差等)。GridSearchCV将对所有超参数组合进行交叉验证,并返回具有最佳性能的超参数组合及其对应的模型。
pipeline=Pipeline([('scaler',StandardScaler()),('pca',PCA()),('svm',SVC())])
param_grid={'svm__C':[0.001,0.01,0.1,1,10,100],'svm__gamma':[0.001,0.01,0.1,1,10,100]}# 定义网格搜索参数,用<estimator>__<parameter>形式设置参数
grid=GridSearchCV(pipeline,param_grid,cv=5, scoring='accuracy')# 网格搜索模型实例化
grid.fit(X_train,y_train)
grid.predict(X_test)
print('Test accuracy: %.3f' % grid.score(X_test, y_test))#输出精度输出:
![]()
本文简单介绍了机器学习管道流水线机制的使用方法,事实上特征处理过程也可以加入管道,我们还可以自定义转化器加入管道中,可以对不同的特征处理划分不同的管道,这些用法我后期出文章再细说。
本期内容就到这里,我们下期再见!需要数据集和源码的小伙伴关注底部公众号添加作者微信!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
相关文章:

【Python机器学习系列】一文带你了解机器学习中的Pipeline管道机制(理论+源码)
这是Python机器学习原创文章,我的第183篇原创文章。 一、引言 对于表格数据,一套完整的机器学习建模流程如下: 背景知识1:机器学习中的学习器 【Python机器学习系列】一文搞懂机器学习中的转换器和估计器(附案例&…...
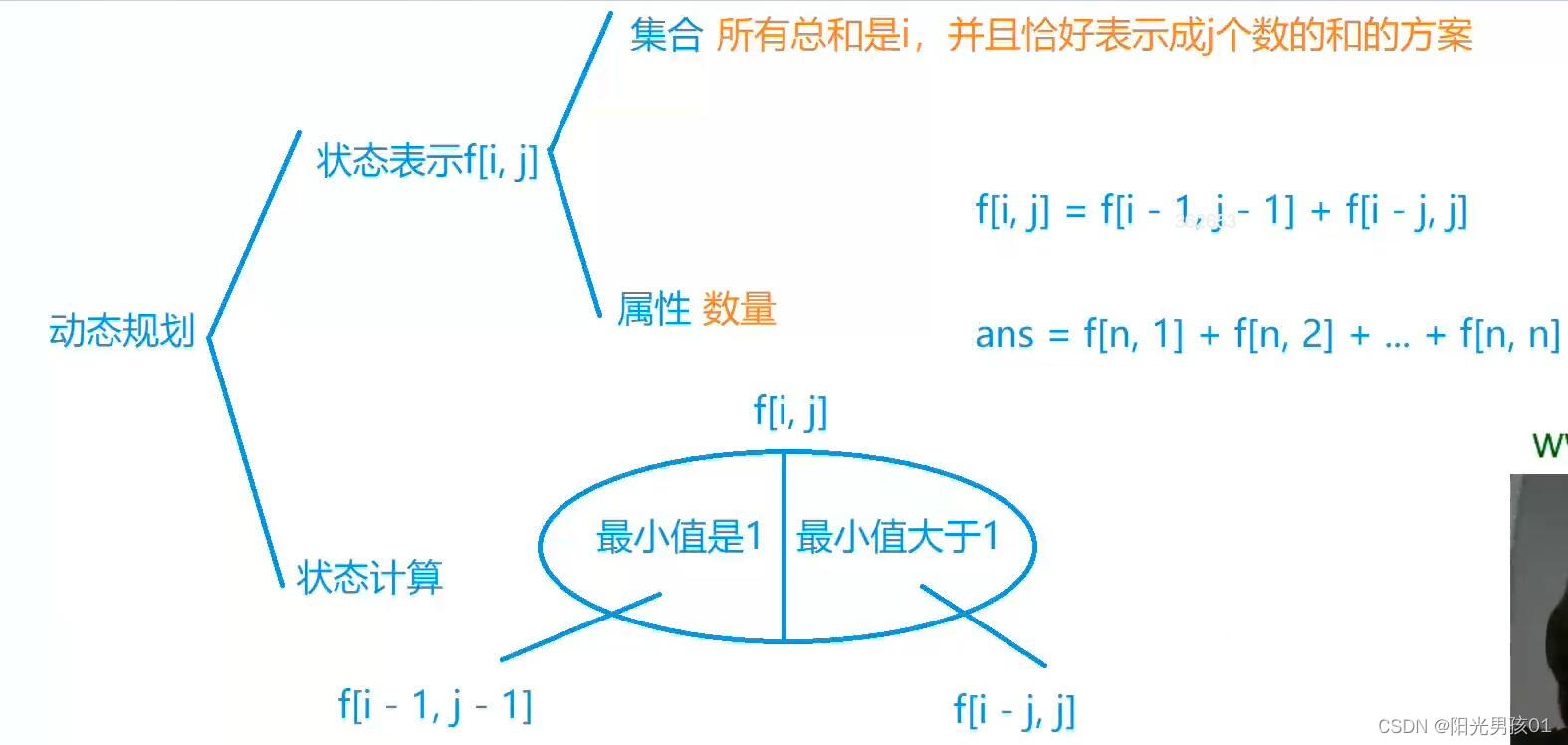
算法基础之整数划分
整数划分 核心思想: 计数类dp 背包做法 f[i][j] 表示 取 1 – i 的物品 总容量为j的选法数量 f[i][j] f[i-1][j] f[i-1][j-v[i]] f[i-1][j-2v[i]] f[i-1][j-3v[i]] ……f[i-1][j-kv[i]] f[i][j-v[i]] f[i-1][j-v[i]] f[i-1][j-2v[i]] f[i-1][j-3v[i]] ……f[i…...
关于“Python”的核心知识点整理大全47
目录 16.1.10 错误检查 highs_lows.py highs_lows.py 16.2 制作世界人口地图:JSON 格式 16.2.1 下载世界人口数据 16.2.2 提取相关的数据 population_data.json world_population.py 16.2.3 将字符串转换为数字值 world_population.py 2world_population…...
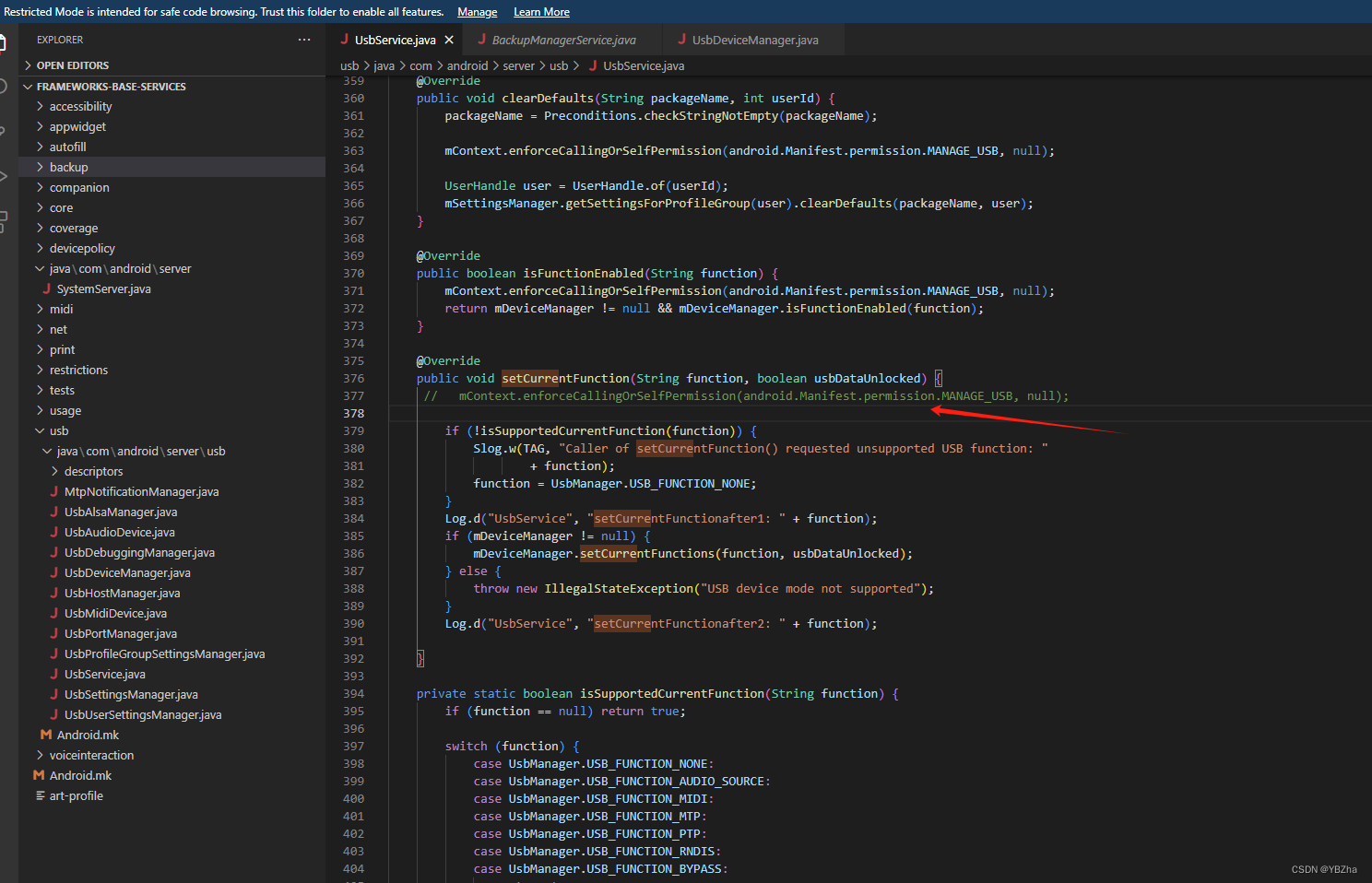
Android 8.1 设置USB传输文件模式(MTP)
项目需求,需要在电脑端adb发送通知手机端接收指令,将USB的仅充电模式更改成传输文件(MTP)模式,便捷用户在我的电脑里操作内存文件,下面是我们的常见的修改方式 1、android12以下、android21以上是这种方式…...
模型量化 | Pytorch的模型量化基础
官方网站:Quantization — PyTorch 2.1 documentation Practical Quantization in PyTorch | PyTorch 量化简介 量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度…...

adb和logcat常用命令
adb的作用 adb构成 client端,在电脑上,负责发送adb命令daemon守护进程adbd,在手机上,负责接收和执行adb命令server端,在电脑上,负责管理client和daemon之间的通信 adb工作原理 client端将命令发送给ser…...
千巡翼X4轻型无人机 赋能智慧矿山
千巡翼X4轻型无人机 赋能智慧矿山 传统的矿山测绘需要大量测绘员通过采用手持RTK、全站仪对被测区域进行外业工作,再通过方格网法、三角网法、断面法等进行计算,需要耗费大量人力和时间。随着无人机航测技术的不断发展,利用无人机作业可以大…...
:编译服务器的配置、AOSP源码的下载、编译、运行)
【Android 13】使用Android Studio调试系统应用之Settings移植(一):编译服务器的配置、AOSP源码的下载、编译、运行
文章目录 1. 篇头语2. 系列文章3. ubuntu 最佳版本3.1 下载并安装3.2 配置AOSP工具链3.3 配置Python多版本支持4. AOSP源码下载4.1 配置repo工具4.2 源码下载5. AOSP编译5.1 添加emulator模拟器配置5.1.1 哪些是支持模拟器的Products?5.1.2 添加方法5.2 编译...

【1】Docker详解与部署微服务实战
Docker 详解 Docker 简介 Docker 是一个开源的容器化平台,可以帮助开发者将应用程序和其依赖的环境打包成一个可移植、可部署的容器。Docker 的主要目标是通过容器化技术实现应用程序的快速部署、可移植性和可扩展性,从而简化应用程序的开发、测试和部…...

C# JsonString转Object以及Object转JsonString
主要讲述了两种方法的转换,最后提供了格式化输出JsonString字符串。 需要引用程序集 System.Web.Extensions.dll、Newtonsoft.Json.dll System.Web.Extensions.dll可直接在程序集中引用,Newtonsoft.Json.dll需要在NuGet中下载引用。 详细代码…...
)
华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)
题目描述: 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。 说明: 1.精确分词: 字符串分词后,不会出现重叠。即“ilovechina” ,不同词库可分割为 “i,love,china” “ilove,c…...

【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList
在并发编程领域,其实除了使用上一篇中的属性不可变。还有一种方式那就是针对读多写少的场景下。我们可以读不加锁,只针对于写操作进行加锁。本质上就是读写复制。读的直接读取,写的使用写一份数据的拷贝数据,然后进行写入。在将新…...

OpenCV中使用Mask R-CNN实现图像分割的原理与技术实现方案
本文详细介绍了在OpenCV中利用Mask R-CNN实现图像分割的原理和技术实现方案。Mask R-CNN是一种先进的深度学习模型,通过结合区域提议网络(Region Proposal Network)和全卷积网络(Fully Convolutional Network)…...

论文阅读《Rethinking Efficient Lane Detection via Curve Modeling》
目录 Abstract 1. Introduction 2. Related Work 3. BezierLaneNet 3.1. Overview 3.2. Feature Flip Fusion 3.3. End-to-end Fit of a Bezier Curve 4. Experiments 4.1. Datasets 4.2. Evalutaion Metics 4.3. Implementation Details 4.4. Comparisons 4.5. A…...
Leetcode—2660.保龄球游戏的获胜者【简单】
2023每日刷题(七十二) Leetcode—2660.保龄球游戏的获胜者 实现代码 class Solution { public:int isWinner(vector<int>& player1, vector<int>& player2) {long long sum1 0, sum2 0;int n player1.size();for(int i 0; i &…...

ubuntu服务器上安装KVM虚拟化
今天想着在ubuntu上来安装一个windwos操作系统,原因是因为我们楼上有几台不错的服务器,但是都是linux系统的。 今天我想着要给同事们搭建一个chatgpt环境,用来开发程序,但是ubuntu上其实也可以安装我嫌麻烦,刚好想折腾…...
SpreadJS 集成使用案例
SpreadJS 集成案例 介绍: SpreadJS 基于 HTML5 标准,支持跨平台开发和集成,支持所有主流浏览器,无需预装任何插件或第三方组件,以原生的方式嵌入各类应用,可以与各类后端技术框架相结合。SpreadJS 以 纯前…...
SQL题:534. 游戏玩法分析 III(难度:中等))
单挑力扣(LeetCode)SQL题:534. 游戏玩法分析 III(难度:中等)
题目:534. 游戏玩法分析 III (通过次数23,825 | 提交次数34,947,通过率68.17%) Table:Activity----------------------- | Column Name | Type | ----------------------- | player_id | int | | device_id | int…...

【OpenCV】告别人工目检:深度学习技术引领工业品缺陷检测新时代
目录 前言 机器视觉 缺陷检测 工业上常见缺陷检测方法 内容简介 作者简介 目录 读者对象 如何阅读本书 获取方式 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站 机器视觉…...

VR全景图片制作时有哪些技巧,VR全景图片能带来哪些好处
引言: VR全景图片是通过虚拟现实技术制作出的具有沉浸感的图片,能够提供给用户一种身临其境的感觉。在宣传方面,它有着独特的优势和潜力,能够帮助吸引更多的潜在客户,那么VR全景图片制作时有哪些技巧,VR全…...

OpenSpec 介绍与使用:让 AI 编程从“聊天驱动”变成“规格驱动”
一、为什么需要 OpenSpec? AI 编程工具越来越强,但很多人在使用 AI 写代码时会遇到一个问题:需求都在聊天记录里,代码越写越快,但上下文越来越乱,最终很难判断 AI 实现的到底是不是最初想要的东西。 OpenSp…...

实战指南:AI调用成本降71%——利用“推理路由”告别大模型胡乱开销
大多数 AI 应用在刚开始时,都会在代码中硬编码一个模型。对于原型开发来说,这运行得很好,但一旦单个端点需要处理多个复杂的任务类别,这种模式就会分崩崩离析。分类、紧急程度评分、面向客户的草稿以及长篇总结,这些任…...

QGIS工程文件.QGZ与.QGS到底怎么选?从团队协作到版本控制的完整避坑指南
QGIS工程文件.QGZ与.QGS深度对比:团队协作与版本控制的最佳实践 当你在QGIS中完成一天的工作,点击保存按钮时,系统默认会生成.QGZ格式的文件。但你是否想过,这个看似简单的选择可能会影响未来团队协作的效率?在GIS项目…...

从CLIP到车辆检索:解锁ViT大模型在跨摄像头ReID中的实战潜力
1. 当CLIP遇上车辆检索:ViT大模型的跨界实战 第一次看到CLIP模型在车辆重识别任务上的表现时,我对着屏幕上的mAP 84.5数据反复确认了三遍。这就像给一辆普通家用车换上了F1赛车的引擎,性能提升简单粗暴。传统ReID方法需要精心设计网络结构、调…...

VCSA底层网络配置实战:从IP修改到SSH登录的运维指南
1. 环境准备与基础概念 刚接触VMware vCenter Server Appliance(VCSA)的朋友可能会觉得底层配置有点神秘。其实就像给新买的智能手机设置Wi-Fi一样,我们需要根据实际网络环境调整它的"网络身份"。VCSA本质上是个预配置的Linux虚拟机…...

终极指南:如何用免费C工具快速管理天龙八部单机版游戏数据
终极指南:如何用免费C#工具快速管理天龙八部单机版游戏数据 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 还在为《天龙八部》单机版的数据管理而烦恼吗?TlbbGmTool是一款专为…...
)
保姆级教程:用HackRF One复现汽车钥匙重放攻击(附完整命令与避坑点)
从零掌握HackRF One信号重放:433MHz汽车钥匙实战全解析 当你在停车场按下车钥匙按钮时,那串看似神秘的无线电波背后隐藏着怎样的安全漏洞?作为硬件安全领域的入门神器,HackRF One让普通爱好者也能窥探射频世界的奥秘。本文将带你用…...
)
告别手动传图!用PicGo+Gitee给Typora配个自动图床(保姆级配置+避坑清单)
打造无缝Markdown写作体验:自动化图床配置全攻略 在技术写作和知识管理的世界里,Markdown已经成为事实上的标准格式。然而,一个长期困扰写作者的问题始终存在——图片管理。传统方式需要手动上传图片到图床,复制链接,再…...
)
Oracle SQL 十道经典练习题(附完整代码 + 解题思路)
Oracle SQL 十道经典练习题(附完整代码 解题思路) 在数据库学习和面试中,SQL 查询是核心技能之一。本文基于 Oracle 数据库,整理了 10 道经典 SQL 练习题,涵盖表创建、数据插入、多表关联、分组统计、自连接等高频考点…...
)
别再手动写代码了!用Coze工作流的Code节点,让AI帮你搞定Python/JS脚本(附IDE调试技巧)
解放双手:用Coze工作流Code节点实现智能编码全攻略 在代码的世界里,我们常常陷入重复劳动的泥潭——那些格式固定的API调用、千篇一律的数据处理、周而复始的脚本编写。有没有一种方式,能让我们从这些机械性编码中解脱出来,把创造…...