FlinkSQL窗口实例分析
Windowing TVFs
Windowing table-valued functions (Windowing TVFs),即窗口表值函数
注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,window_end
-
TUMBLE函数采用三个必需参数,一个可选参数:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到滚动窗口。
size:是指定翻滚窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
HOP采用 4 个必需参数和 1 个可选参数:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到跳跃窗口。
slide:是指定连续跳跃窗口开始之间的持续时间的持续时间
size:是指定跳跃窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
CUMULATE采用 4 个必需参数和 1 个可选参数:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到累积窗口。
step:是指定连续累积窗口末尾之间增加的窗口大小的持续时间。
size:是指定累积窗口最大宽度的持续时间。size必须是 的整数倍step。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。
滚动窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name滑动窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(HOP(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name
累计窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' HOUR,INTERVAL '24' HOURS)) --从零点开始累计
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' MINUTE,INTERVAL '1' HOURS))
group by window_start,window_end,window_time,group_name窗口聚合-多维分析
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区--实例1:整体聚合
select window_start,window_end,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end--实例2:根据字段聚合,n个维度
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,group_name--实例3:多维分析GROUPING SETS
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name)) --等同于 实例2
group by window_start,window_end,GROUPING SETS((group_name), ()) --等同于 实例1 union all 实例2--实例4:多维分析GROUPING SETS,多个字段
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name,batch_number),(group_name),(batch_number),())--实例5:多维分析CUBE 2^n个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,CUBE(group_name) --等同于group by window_start,window_end,GROUPING SETS((group_name), ())
group by window_start,window_end,CUBE(group_name,batch_number) --等同于实例4--实例6:多维分析ROLLUP n+1个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,ROLLUP(group_name) --等同于 实例1 union all 实例2
group by window_start,window_end,ROLLUP(group_name,batch_number) --等同于GROUPING SETS((group_name,batch_number),(group_name),())窗口topN
Window Top-N 语句的语法:
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownumFROM table_name) -- relation applied windowing TVF
WHERE rownum <= N [AND conditions]
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区--方式1:窗口 Top-N 紧随窗口聚合之后
create view tmp_window as
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS))
group by window_start,window_end,window_time,group_name;--计算每个翻滚 24小时窗口内pv最高的前 3 名机构(即每天PV最高的前三名)
select * from(select * ,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY cnt DESC) as rnfrom tmp_window) t
where rn <=3--计算每个机构pv最高的前 3天
select * from(select * ,ROW_NUMBER() OVER (PARTITION BY group_name ORDER BY cnt DESC) as rnfrom tmp_window) t
where rn <=3--方式2:窗口 Top-N 紧随窗口 TVF 之后
select *
from(selectwindow_start,window_end,window_time,group_name,ts,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY ts DESC) AS rnfrom TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS)))
where rn <=3窗口去重
Flink使用去重的方式,就像Window Top-N查询ROW_NUMBER()的方式一样。理论上,
窗口重复数据删除是窗口 Top-N 的一种特殊情况,其中 N 为 1,并且按处理时间或事件时间排序
Window Deduplication 语句的语法:
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]ORDER BY time_attr [asc|desc]) AS rownumFROM table_name) -- relation applied windowing TVF
WHERE (rownum = 1 | rownum <=1 | rownum < 2) [AND conditions]
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,group_name as COALESCE(cur['group_name'], src['group_name']),batch_number as COALESCE(cur['batch_number'], src['batch_number']),event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);select *
from(selectwindow_start,window_end,group_name,event_time,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY event_time DESC) AS rnfrom TABLE(TUMBLE(TABLE kafka_table, DESCRIPTOR(event_time), INTERVAL '24' HOURS)))
where rn =1
相关文章:

FlinkSQL窗口实例分析
Windowing TVFs Windowing table-valued functions (Windowing TVFs),即窗口表值函数 注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,wind…...
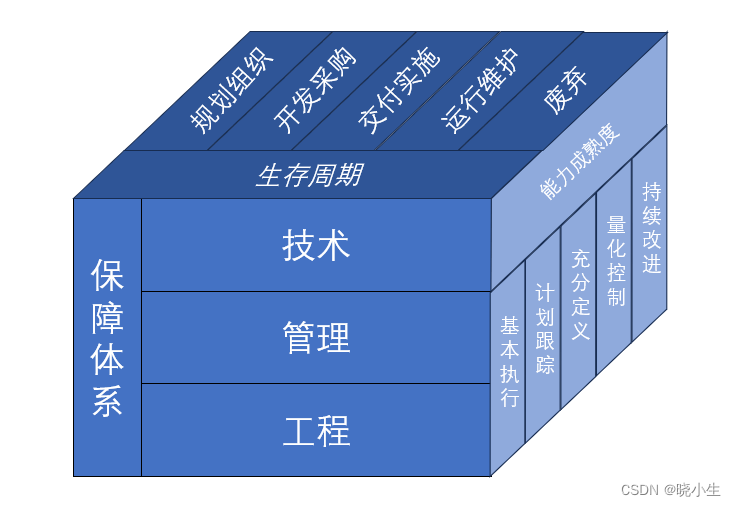
18-网络安全框架及模型-信息系统安全保障模型
信息系统安全保障模型 1 基本概念 信息系统安全保障是针对信息系统在运行环境中所面临的各种风险,制定信息系统安全保障策略,设计并实现信息系统安全保障架构或模型,采取工程、技术、管理等安全保障要素,将风险减少至预定可接受的…...
apk(安装包))
Android 提取(备份)apk(安装包)
Android 提取(备份)apk(安装包) 一、通过安卓代码的方式 主要分三步: 根据应用找到包名根据包名获得apk提取apk 提取apk代码 private static final String BACKUP_PATH "/sdcard/backup1/"; private static final String APK ".apk";pri…...
metadata和超时设置)
gRPC-Go基础(4)metadata和超时设置
文章目录 0. 简介1. metadata1.1 metadata结构1.2 metadata创建1.3 客户端处理metadata1.4 服务端处理metadata1.5 metadata的传输 2. 超时设置2.1 客户端输出超时信息2.2 服务端端接收超时信息 3. 小结 0. 简介 Go在多个go routine之间传递数据使用的是Go SDK提供的context包…...

语言模型:从n-gram到神经网络的演进
目录 1 前言2 语言模型的两个任务2.1 自然语言理解2.2 自然语言生成 3 n-gram模型4 神经网络语言模型5 结语 1 前言 语言模型是自然语言处理领域中的关键技术之一,它致力于理解和生成人类语言。从最初的n-gram模型到如今基于神经网络的深度学习模型,语言…...
docker compose 部署 grafana + loki + vector 监控kafka消息
Centos7 随笔记录记录 docker compose 统一管理 granfana loki vector 监控kafka 信息。 当然如果仅仅是想通过 Grafana 监控kafka,推荐使用 Grafana Prometheus 通过JMX监控kafka 目录 1. 目录结构 2. 前提已安装Docker-Compose 3. docker-compose 自定义服…...
kubeadm创建k8s集群
kubeadm来快速的搭建一个k8s集群: 二进制搭建适合大集群,50台以上。 kubeadm更适合中下企业的业务集群。 部署框架 master192.168.10.10dockerkubelet kubeadm kubectl flannelnode1192.168.10.20dockerkubelet kubeadm kubectl flannelnode2192.168.1…...
鸿蒙开发之android对比开发《基础知识》
基于华为鸿蒙未来可能不再兼容android应用,推出鸿蒙开发系列文档,帮助android开发人员快速上手鸿蒙应用开发。 1. 鸿蒙使用什么基础语言开发? ArkTS是鸿蒙生态的应用开发语言。它在保持TypeScript(简称TS)基本语法风…...
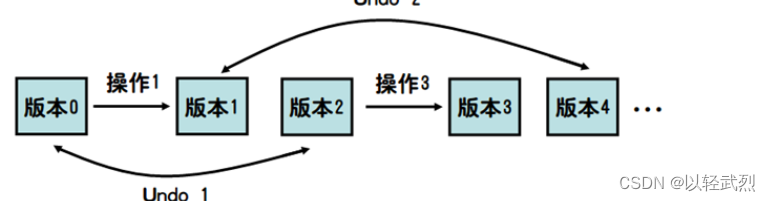
2702 高级打字机
因为Undo操作只能撤销Type操作,所以Undo x 实际上就是删除文章末尾x个字母。用一个栈即可解决(每个字母最多进出一次)。 这种情况下只需要设计一个合理的数据结构依次执行操作即可。 版本树:Undo x撤销最近的x次修改操作…...

yolov5旋转目标检测-遥感图像检测-无人机旋转目标检测-附代码和原理
综述 为了解决旋转目标检测问题,研究者们提出了多种方法和算法。以下是一些常见的旋转目标检测方法: 基于滑动窗口的方法:在图像上以不同的尺度和角度滑动窗口,通过分类器判断窗口中是否存在目标。这种方法简单直观,…...
Qt学习:Qt的意义安装Qt
Qt 的简介 QT 是一个跨平台的 C图形用户界面应用程序框架。它为程序开发者提供图形界面所需的所有功能。它是完全面向对象的,很容易扩展,并且允许真正地组件编程。 支持平台 xP 、 Vista、Win7、win8、win2008、win10Windows . Unix/Linux: Ubuntu 等…...
Anylogic Pro 8.8.x for Mac / for Linux Crack
Digital twins – a step towards a digital enterprise AnyLogic是唯一一个支持创建模拟模型的方法的模拟建模工具:面向过程(离散事件)、系统动态和代理,以及它们的任何组合。AnyLogic提供的建模语言的独特性、灵活性和强大性使…...

ROS无人机初始化GPS定位漂移误差,确保无人机稳定飞行
引言: 由于GPS在室外漂移的误差比较大,在长时间静止后启动,程序发布的位置可能已经和预期的位置相差较大,导致无法完成任务,尤其是气压计的数据不准,可能会导致无人机不能起飞或者一飞冲天。本文主要是在进…...
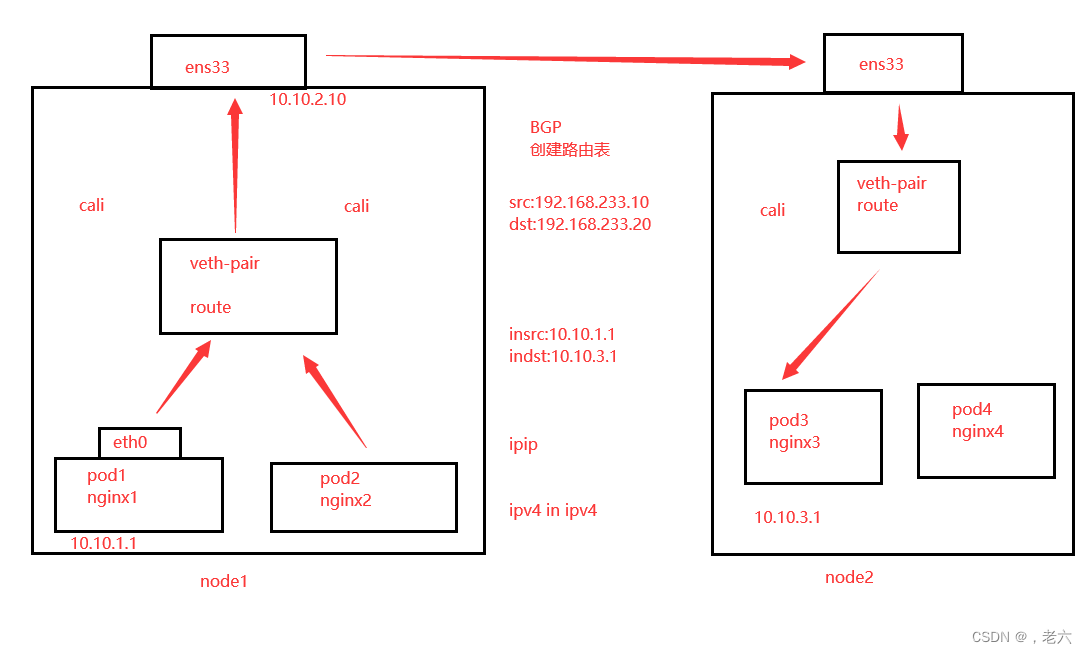
k8s网络类型
k8s中的通信模式: pod内部之间容器与容器之间的通信。 在同一个pod中的容器共享资源和网络,使用同一个网络命名空间。可以直接通信的。 同一个node节点之内,不同pod之间的通信。 每一个pod都有一个全局的真实的IP地址,同一个n…...
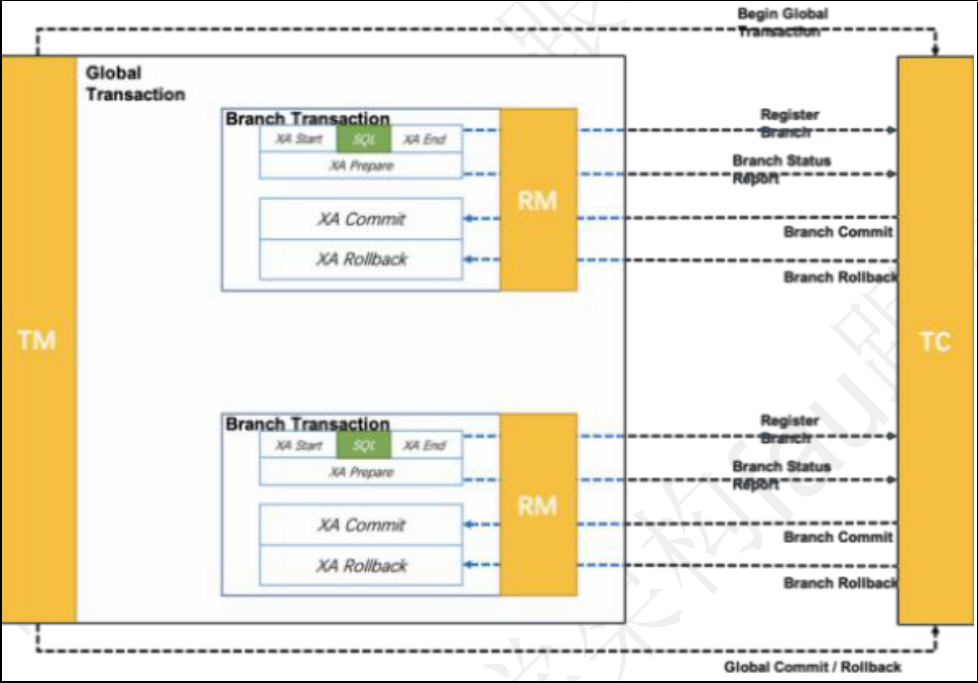
Seata 中封装了四种分布式事务模式,分别是: AT 模式, TCC 模式, Saga 模式, XA 模式,
文章目录 seata概述Seata 中封装了四种分布式事务模式,分别是:AT 模式,TCC 模式,Saga 模式,XA 模式, 今天我们来聊聊seata seata 概述 在微服务架构下,由于数据库和应用服务的拆分,…...

为什么设计制造行业需要数据加密?
设计制造行业是一个涉及多种技术、工艺、材料和产品的广泛领域,它对经济和社会的发展有着重要的影响。然而,随着数字化、智能化和网络化的发展,设计制造行业也面临着越来越多的数据安全风险,如数据泄露、数据篡改、数据窃取等。这…...

查看ios app运行日志
摘要 本文介绍了一款名为克魔助手的iOS应用日志查看工具,该工具可以方便地查看iPhone设备上应用和系统运行时的实时日志和奔溃日志。同时还提供了奔溃日志分析查看模块,可以对苹果奔溃日志进行符号化、格式化和分析,极大地简化了开发者的调试…...

怎么卸载macOS上的爱思助手如何卸载macOS上的logitech g hub,如何卸载顽固macOS应用
1.在App Store里下载Cleaner One Pro (注意,不需要订阅付费!!!白嫖基础功能就完全够了!!!) 2.运行软件,在左侧目录中选择“应用程序管理”,然后点…...

侦探IP“去推理化”:《名侦探柯南》剧场版走过26年
2023年贺岁档,柯南剧场版的第26部《黑铁的鱼影》如期上映。 这部在日本狂卷票房128亿日元的作品,被誉为有史以来柯南剧场版在商业成绩上最好的一部。 但该作在4月份日本还未上映前,就于国内陷入了巨大的争议。 试映内容里,灰原…...

图论 经典例题
1 拓扑排序 对有向图的节点排序,使得对于每一条有向边 U-->V U都出现在V之前 *有环无法拓扑排序 indegree[], nxs[];//前者表示节点 i 的入度,后者表示节点 i 指向的节点 queue [] for i in range(n):if indege[i] 0: queue.add(i)// 入度为0的节…...

HPM6750 RISC-V高性能MCU开发实战:从双核应用到图形加速
1. 项目概述与核心价值最近几年,RISC-V架构在嵌入式领域的声量越来越大,从最初的学术研究到如今在工业控制、边缘计算等场景的落地,生态的成熟度肉眼可见。作为一名长期混迹在嵌入式开发一线的工程师,我对于新架构、新平台总是抱有…...

终极 Node.js 路径管理神器:module-alias 完全指南
终极 Node.js 路径管理神器:module-alias 完全指南 【免费下载链接】module-alias Register aliases of directories and custom module paths in Node 项目地址: https://gitcode.com/gh_mirrors/mo/module-alias 你是否厌倦了在 Node.js 项目中看到像 requ…...

B站视频转文字终极指南:3步快速提取视频字幕和文案
B站视频转文字终极指南:3步快速提取视频字幕和文案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为B站视频内容无法搜索而烦恼吗࿱…...

BesTV_R3300-L S905L芯片刷机实战:从驱动识别到固件烧录的完整避坑指南
1. 认识你的BesTV_R3300-L盒子 我手头这台BesTV_R3300-L盒子已经吃灰大半年了,原厂系统用起来卡顿不说,还经常弹出各种广告。拆开外壳看到S905L芯片的那一刻,我就知道这玩意儿有救——毕竟这是刷机圈里的"老熟人"了。先给新手朋友科…...

终极指南:如何在macOS上轻松安装KLayout版图设计软件
终极指南:如何在macOS上轻松安装KLayout版图设计软件 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout 想要在macOS上安装专业级的集成电路版图设计工具KLayout吗?😊 作为一款功能…...

3DMAX建模救星实测:SmoothBoolean插件处理复杂布尔运算,到底有多稳多快?
3DMAX建模革命:SmoothBoolean插件深度测评与实战指南 在数字建模的世界里,布尔运算一直是把双刃剑——它既能快速实现复杂形状的切割与组合,又常常成为模型崩溃的导火索。对于专业建模师而言,面对机械零件、建筑构件或影视道具中那…...

深圳清关代理口碑爆棚,不找它你就亏大啦!
事件经过某外贸公司近期有一批从国外进口的电子产品要在深圳口岸清关。该公司原本以为按照常规流程操作即可顺利完成清关,便自行准备了相关单证资料。然而,当货物到达深圳口岸进行报关时,却遭遇了清关受阻的情况。海关在合规审核过程中发现&a…...

缤纷夏日 心有所“暑”
邻聚美好时光,在升腾的烟火气里我们共同收藏了夏日的N种欢乐回顾七月光影流转的坝坝电影唤醒了儿时记忆孩子们在飞舞的泡泡大作战里嬉闹篮球场上矫健的身姿瞬间定格更有贴心的便民服务磨亮生活锋刃、洗净门前地垫,便捷直达家门这个缤纷夏日,因…...

STM32F405时钟树配置避坑指南:从HSE到APB,手把手教你算对每个外设时钟
STM32F405时钟树配置避坑指南:从HSE到APB,手把手教你算对每个外设时钟 在嵌入式开发中,时钟配置是STM32项目启动的第一步,也是最容易踩坑的环节之一。很多开发者虽然理解了时钟树的基本概念,但在实际项目中仍然会遇到外…...

5分钟快速上手:AMD Ryzen处理器专业级调试工具SMUDebugTool完全指南
5分钟快速上手:AMD Ryzen处理器专业级调试工具SMUDebugTool完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...