【挑战全网最易懂】深度强化学习 --- 零基础指南
深度强化学习介绍、概念
- 强化学习介绍
- 离散场景,使用行为价值方法
- 连续场景,使用概率分布方法
- 实时反馈连续场景:使用概率分布 + 行为价值方法
- 强化学习六要素
- 设计奖励函数
- 设计评论家
- 策略学习与优化
- 算法路径
- 深度 Q 网络 DQN
- 演员-评论家算法:多智能体强化学习核心框架
- PPO 近端策略优化算法
强化学习介绍
机器学习是把带标签的数据训练模型,使得预测值尽可能接近真实值。
强化学习是通过和环境交互,奖励来训练模型,使得最后获取的奖励最大期望值。
在强化学习中,机器基于环境做出行为,正确的行为能够获得奖励。
以获得更多奖励为目标,实现机器与环境的最优互动。
如教狗子握手的时候,如果狗子正确握手,就能得到骨头奖励,不握手就没有。
如果咬了主人一口,还会受到惩罚。
长此以往,狗子为了得到更多骨头,就能学会握手这个技能。
强化学习和机器学习最大不同在于,环境未知。
因为环境未知,所以我们不能通过大量数据得到决策。
只能通过和环境的交互中,不断改进策略。
强化学习的发展历史:
- 动态规划:学过数据结构与算法的人,都了解,是传统算法策略中最难的,千变万化。
- 表格方法:时序差分、Q-Learning 、SARSA
- 函数逼近:线性函数逼近、多项式函数逼近、基函数逼近
- 深度强化学习:DQN、DDPG、AlphaStar、A2C、A3C、PPO
强化学习可分为离散、连续场景。
离散场景,使用行为价值方法
离散场景:机器行为的有限的,如动作类游戏。只有向上、向下、向左、向右这 4 个动作,移动也只能一格一格地走。
可以把每个状态下的所有行为列举出来,用评论家为每个行为打分,通过选择最高分的行为实现最优互动。
因为需要评估每个行为的价值,所以这种学习方法被称为基于行为价值的方法。
基于值的方法需要根据每个行为的价值进行打分,选出价值最高的行为。
由于要穷举出所有行为,因此它只适用于离散场景(动作类游戏),无法应对连续场景。
Q-Learning 和 DQN 算法,都属于基于值的强化学习方法。
优势在于,基于行为价值的方法能实时反馈。
可以根据每个行为的价值进行打分,这个分数就相当于每个行为的实时反馈。
连续场景,使用概率分布方法
连续场景:机器的行为是连贯的,如赛车的方向盘转动角度可以在一定区间内任意取值,角度之间可以无限分割。
还有基于行为概率的方法,无需根据每个行为的价值来打分,可以很好地胜任连续场景。
基于行为概率策略的方法并不需要考虑行为的价值,而是反应调整。
机器会在训练过程中随机抽取一些行为,与环境互动。如果行为获得了奖励,就会提高选择它的概率。以后遇到同样的状态时,有更高的概率再次做出这个行为。
相反,如果未获得奖励,或者受到了惩罚,就保持或者降低该行为的概率。
经过大量训练,最终会得出连续行为的概率分布。
基于这样的原理,一个行为能获得越多奖励,被选择的概率就越大,从而实现机器和环境的最优化互动。
PPO、演员-评论家 就是能处理连续场景的算法。
优势在于,基于策略的方法能应用连续场景上。但不能实时反馈。
实时反馈连续场景:使用概率分布 + 行为价值方法
机器在与环境互动时,难以得到实时反馈,往往要在整个回合结束后才能获得奖励。
如赢一盘棋是正向奖励,输一盘棋是负面奖励,但棋局中某一颗棋子的价值很难即时评估。
想要提高学习效率,就必须想办法提供实时反馈。
有没有办法可以在应对连续场景上的优点,和离散场景在实时反馈上的优点结合呢?
比如演员-评论家算法。
这个算法分成两半,一半是演员,另一半是评论家。
-
演员:这一半基于概率分布,策略梯度算法。它有一个神经网络,可以根据行为的概率,选出行为。
-
评论家:这一半基于行为价值,DQN 算法。它有一个神经网络,可以根据行为的价值进行打分。
将概率分布和行为价值的方法相结合:
- 由基于概率分布的策略网络在连续场景中选出行为
- 由基于行为价值的价值网络给行为提供实时反馈
概率分布网络就像写作业的学生,行为价值网络就像批改作业的老师。
二者结合,反复地写作业、改作业,对比方法,找出最好的方法。
强化学习六要素
强化学习六要素:环境、策略、状态、行为、奖励、评论家。
如在对弈的环境中,策略根据棋盘上的状态,做出落子行为,每盘棋的胜负获得奖励。
模拟足够多棋局后,评论家就可以通过计算预测出每步棋对整盘棋的价值,为其打分。
在强化学习中,容易混淆的概念有:状态奖励函数、状态价值函数、动作奖励函数、动作价值函数。
设计奖励函数
奖励函数直接与环境相连,为算法提供即时的反馈。
奖励函数有两种类型:
-
状态奖励函数:为智能体到达或处于特定状态时提供的即时奖励。如走迷宫,到达出口可能立即给予正奖励。
-
动作奖励函数:为执行特定动作而提供的即时奖励。如下棋,吃掉对方的重要棋子可能立即获得奖励。
设计评论家
评论家(或价值函数)在强化学习中用于评估和指导策略的长期效益,基于累积奖励的概念。
- 状态价值函数(V):评估处于某一特定状态的长期价值。这涉及对从该状态开始,未来可能获得的所有奖励的估计。
- 动作价值函数(Q):评估在特定状态下执行特定动作的长期价值。这不仅包括即时奖励,还包括因该动作产生的后续状态和未来可能的奖励。
状态奖励函数、状态价值函数关注到达某状态的价值 - 前者是当下回报、后者是长期回报。
动作奖励函数、动作价值函数关注执行某动作的价值 - 前者是当下回报、后者是长期回报。
奖励函数提供即时反馈,价值函数预估长期收益。
策略学习与优化
通过与环境的交互,不断更新策略和价值函数来改进决策。
- 学习:根据奖励和评论家的反馈,调整策略和价值函数。
- 探索与利用:平衡 是尝试新动作(探索更好的动作)还是 利用已知的好动作(利用已知最好)。
算法路径
深度 Q 网络 DQN
记录于 — 【OpenAI Q* 超越人类的自主系统】DQN :Q-Learning + 深度神经网络
演员-评论家算法:多智能体强化学习核心框架
记录于 — 演员-评论家算法:多智能体强化学习核心框架
PPO 近端策略优化算法
记录于 —【ChatGPT 默认强化学习策略】PPO 近端策略优化算法
相关文章:
【挑战全网最易懂】深度强化学习 --- 零基础指南
深度强化学习介绍、概念 强化学习介绍离散场景,使用行为价值方法连续场景,使用概率分布方法实时反馈连续场景:使用概率分布 行为价值方法 强化学习六要素设计奖励函数设计评论家策略学习与优化 算法路径深度 Q 网络 DQN演员-评论家算法&…...

WPF RelativeSource
RelativeSource 类在 WPF 中提供了以下几种模式: RelativeSource Self:指定当前元素作为相对源。可以在当前元素的属性中绑定到自身的属性。 示例: <TextBlock Text"{Binding Text, RelativeSource{RelativeSource Self}}" /&…...

centos 安装 配置 zsh
centos 编译安装 zsh 和 配置 oh-my-zsh 下载 wget https://jaist.dl.sourceforge.net/project/zsh/zsh/5.9/zsh-5.9.tar.xz依赖 yum install ncurses-devel安装zsh 执行: tar -xvf zsh-5.9.tar.xz cd zsh-5.9 ./configure --prefix/usr/local/zsh5.9 make &am…...
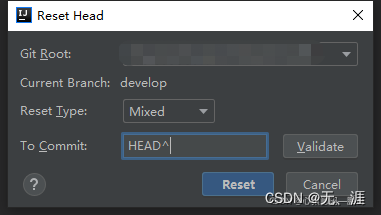
git 常用基本命令, reset 回退撤销commit,解决gitignore无效,忽略记录或未记录远程仓库的文件,删除远程仓库文件
git 基本命令 reset 撤销commit https://blog.csdn.net/a704397849/article/details/135220091 idea 中 rest 撤销commit过程如下: Git -> Rest Head… 在To Commit中的HEAD后面加上^,点击Reset即可撤回最近一次的尚未push的commit Reset Type 有三…...

Vue Echarts 多折线图只有一条X轴(合并X轴数据并去重排序) - 附完整示例
echarts:一个基于 JavaScript 的开源可视化图表库。 目录 效果 一、介绍 1、官方文档:Apache ECharts 2、官方示例 二、准备工作 1、安装依赖包 2、示例版本 三、使用步骤 1、在单页面引入 echarts 2、指定容器并设置容器宽高 3、数据处理&am…...
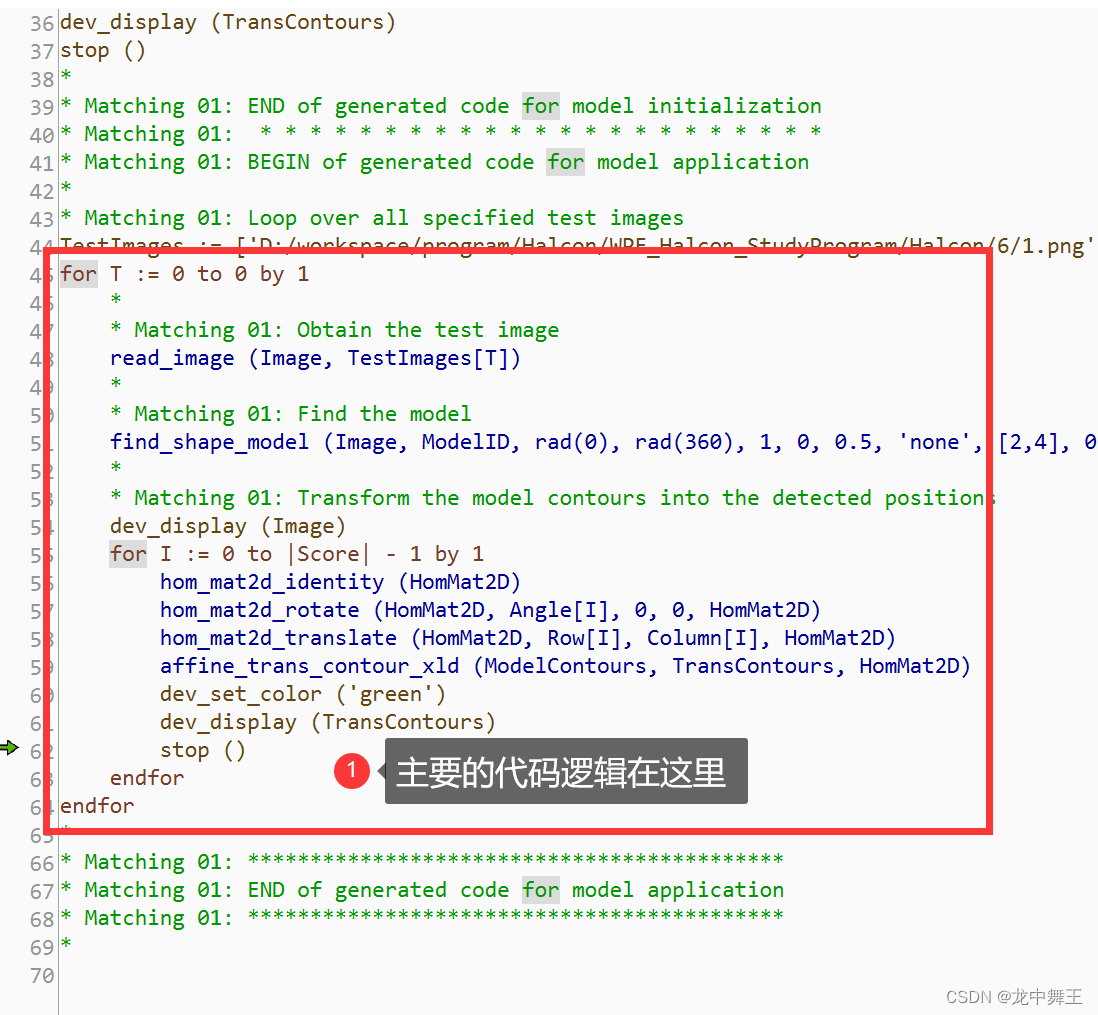
WPF+Halcon 培训项目实战(6):目标匹配助手
文章目录 前言相关链接项目专栏模板匹配助手简单使用金字塔级别参数自动选择应用插入代码 总结 前言 为了更好地去学习WPFHalcon,我决定去报个班学一下。原因无非是想换个工作。相关的教学视频来源于下方的Up主的提供的教程。这里只做笔记分享,想要源码…...

Linux管理LVM逻辑卷
目录 一、LVM逻辑卷介绍 1. 概述 2. LVM基本术语 2.1 PV(Physical Volume,物理卷) 2.2 VG (Volume Group,卷组) 2.3 LV (Logical Volume,逻辑卷) 3. 常用的磁盘命令 4. 查看系统信息的命…...

vue如何实现局部刷新?
应用场景: 比如你要切换tap栏实现刷新下面form表单等,相当于刷新页面。 如何使用如下: <div v-if"isReloadData"> 比如你想刷新那个位置就把 v-if"isReloadData"写到那个标签上 </div> 在data中定义刷新标…...

C语言,指针链表详解解说及代码示例
C语言,指针链表详解解说及代码示例 指针链表是一种常用的数据结构,用于存储和组织数据。它由一系列节点组成,每个节点包含数据和一个指向下一个节点的指针。通过这种方式,可以动态地添加、删除和访问节点,实现灵活的数…...
6、LLaVA
简介 LLaVA官网 LLaVA使用Vicuna(LLaMA-2)作为LLM f ϕ ( ⋅ ) f_\phi() fϕ(⋅),使用预训练的CLIP图像编码器 ViT-L/14 g ( X v ) g(X_v) g(Xv)。 输入图像 X v X_v Xv,首先获取feature Z v g ( X v ) Z_vg(X_v) Zvg(Xv)。考虑到最后一…...

SpringMVC核心处理流程梳理
1、处理流程图展示 当我拿出这张图,阁下又该如何应对呢?执行流程是不是一目了然了。【记住一句话:所有的注解都只是一个标签或者标记,最终都是反射找到具体方法上面的注解标记,然后找到类、属性、方法扩展自己想要的功…...

go 语言程序设计第2章--程序结构
2.1 名称 如果一个实体在函数中声明,它只在函数局部有效。如果声明在函数外,它将对包里面所有源文件可见。 实体第一个字母的大小写决定其可见性是否跨包。如果名称以大写字母开头,它是导出的,意味着它对包外是可见和可访问的。包…...
JavaScript基础知识点总结:从零开始学习JavaScript(五)
如果大家感感兴趣也可以去看: 🎉博客主页:阿猫的故乡 🎉系列专栏:JavaScript专题栏 🎉ajax专栏:ajax知识点 🎉欢迎关注:👍点赞🙌收藏✍️留言 学习…...

Intel FPGA 技术开放日
概要 时间:2023.11.14 全天 ( 9:00 - 16: 20) 地点:北京望京. 凯悦酒店 主题内容:分享交流了Intel FPGA 产品技术优势和落地实践方案。 会议的议程 开场致词: FPGA业务,是几年前intel收购而…...

分享72个Python爬虫源码总有一个是你想要的
分享72个Python爬虫源码总有一个是你想要的 学习知识费力气,收集整理更不易。 知识付费甚欢喜,为咱码农谋福利。 链接:https://pan.baidu.com/s/1v2P4l5R6KT2Ul-oe2SF8cw?pwd6666 提取码:6666 项目名称 10 photo websites…...

Mybatis 动态 SQL - foreach
动态SQL的另一个常见需求是需要迭代一个集合,通常用于构建IN条件。例如: <select id"selectPostIn" resultType"domain.blog.Post">SELECT *FROM POST P<where><foreach item"item" index"index&quo…...

编程笔记 GOLANG基础 001 为什么要学习Go语言
编程笔记 GOLANG基础 001 为什么要学Go语言 一、推荐学习的计算机程序设计语言(一)、前端设计与编程:htmlcssjavascripttypescript(二)、C/C语言(三)、Go语言(四)、Pytho…...
OrientDB使用教程:全面了解图数据库
图数据库在当今数据处理领域中扮演着越来越重要的角色,而OrientDB作为一种多模型的数据库,具有图数据库、文档数据库和对象数据库的特性,为应对不同场景提供了灵活的解决方案。本教程将简要介绍OrientDB的使用,包括基本概念、安装…...
VMware安装笔记
1、首先准备安装文件 没有的小伙伴可以网上自行下载,或者给我留言,我发给你。 2、开始安装 2.1、双击运行exe安装文件,下一步 2.2、接受许可,下一步 2.3、选择安装路径 2.4、选择好安装路径后,继续下一步 2.5、取消勾…...

MIT线性代数笔记-第27讲-复数矩阵,快速傅里叶变换
目录 27.复数矩阵,快速傅里叶变换打赏 27.复数矩阵,快速傅里叶变换 对于实矩阵而言,特征值为复数时,特征向量一定为复向量,由此引入对复向量的学习 求模长及内积 假定一个复向量 z ⃗ [ z 1 z 2 ⋮ z n ] \vec{z} \…...

ENSP实战:从Console到AAA,详解交换机安全登录的进阶配置
1. 从零开始:认识交换机登录安全的基本面 第一次接触企业级交换机时,很多新手都会被各种登录方式搞得晕头转向。我刚开始做网络运维时,就曾经因为没设置好登录认证,导致测试环境的交换机被隔壁团队的同事误操作重启。今天我们就从…...

GDB 符号检视三件套:`ptype` / `info variables` / `info functions`
调试 NuttX/Vela 这类嵌入式系统时,光会 bt 和 print 远远不够。真正能让你在陌生代码里快速定位、看清结构、批量布点的,是 GDB 的符号检视命令。本文整理三件最常用的: ptype —— 看类型长什么样info variables —— 找全局/静态变量在哪…...

5步掌握Beyond Compare 5逆向工程:RSA加密破解与密钥生成实战
5步掌握Beyond Compare 5逆向工程:RSA加密破解与密钥生成实战 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 软件授权逆向工程是信息安全领域的重要研究方向,通过分析Be…...
)
别再手动整理停用词了!分享我私藏的NLP中英文停用词库(含哈工大、百度、川大版)
NLP停用词库实战指南:如何科学选择与高效应用 在自然语言处理项目中,数据预处理环节往往消耗开发者60%以上的时间,而停用词处理又是其中最基础却最容易出错的步骤。我曾见过团队因为使用不恰当的停用词表,导致情感分析模型将&quo…...

自建密码管理器:基于Web Crypto API与Flask的零知识安全架构实践
1. 项目概述:一个基于Web的密码管理器最近在GitHub上看到一个挺有意思的项目,叫clawvault。乍一看名字,可能会联想到“爪子”和“保险库”,其实它就是一个用Python写的、基于Web界面的密码管理器。这类工具大家应该不陌生…...
)
告别手动抢红包!用Kotlin写一个Android微信红包监听助手(附完整代码)
用Kotlin构建Android微信红包自动化工具:从原理到避坑指南 春节聚会时,你是否曾因低头抢红包错过亲友的精彩对话?工作群里的手气红包总在分神时一闪而过?作为一名Android开发者,其实可以用技术优雅解决这些烦恼。本文…...

技术干货!!DeepSeek API 实战:从零到生产级的 Python 调用指南 — 流式、Function Calling、多轮对话、成本优化全覆盖
DeepSeek V3 的 API 性价比在 2026 年依然没有对手——同等能力价格只有 GPT-5.5 的 1/5。但翻了一圈中文技术社区,发现大多数「教程」只讲到第一段 chat.completions.create 就停了。生产环境真正需要的东西——流式输出怎么接、Function Calling 踩了什么坑、高并…...

RAG已死?收藏这篇,小白程序员必看:上下文工程才是大模型未来!
本文探讨了围绕RAG技术的争议,分析了三种不同观点:RAG正进化为更智能的检索系统、RAG已成为核心工程学科、RAG正被长上下文和智能体取代。文章指出,简单的RAG已过时,但提供外部知识的需求依然存在,未来RAG将作为组件之…...

autoloom:自动化工作流编排框架的设计原理与实践指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫autoloom,作者是thresher-sh。光看名字,可能有点摸不着头脑,但如果你正在处理一些需要“编织”或“缝合”多个独立数据源、API接口、微服务或者自动化流程的任务&am…...

FAST开发方法在系统分析中四个阶段
在系统分析师考试中,被频繁考查的FAST(Framework for the Application of Systems Thinking)方法,是一个聚焦于系统分析阶段的框架。 它的核心是将复杂的分析工作拆解为四个环环相扣的阶段:初始研究、问题分析、需求分析和决策分析。 📊 四个阶段速览 阶段 核心任务 1…...