MongoDB聚合:$merge 阶段(1)
$merge的用途是把聚合管道产生的结果写入指定的集合,有时候可以用$merge来做物化视图。需要注意,$meger操作必须是聚合管道的最后一个阶段。具体功能有:
- 能够输出到当前或不同的数据库
- 能够输出到正在聚合的集合(慎重:可能会导致频繁的更新甚至死循环)
- 可以在副本集的二级节点运行,前提是群集所有节点的
featureCompatibilityVersion不小于4.4,且读选项允许二级读取。注意:$merge读取操作会发送到二级节点,写入操作只发生在主节点。- 并非所有版本的驱动都支持
$merge在副本集二级节点的操作,在使用前要确认驱动支持。
- 输出集合不存在时可以自动创建输出集合,数据库不存在时也可以自动创建
- 输出结果可以与现有集合合并,包括:插入新文档、合并文档、替换文档、保持已存在的文档、让操作失败、使用自定义的更新管道处理文档等。
语法
{ $merge: {into: <collection> -or- { db: <db>, coll: <collection> },on: <identifier field> -or- [ <identifier field1>, ...], // 可选let: <variables>, // 可选whenMatched: <replace|keepExisting|merge|fail|pipeline>, // 可选whenNotMatched: <insert|discard|fail> //可选
} }
举例:
{ $merge: {into: "mycollection", on: "_id", whenMatched: "replace", whenNotMatched: "insert" } }
如果都使用$merge的默认选项并且输出到当前数据库,可以使用简化形式:
{ $merge: <collection> } //输出到当前数据库
字段说明
into
输出到的集合,可以指定到数据库,也可以不指定数据库,输出到当前数据库。例如:
输出到当前库的my_coll集合:into: "my_coll"
输出到mydb的my_coll集合:into:{db:"mydb", coll:"my_coll"}
注意:
- 如果目标库或集合不存在,会自动创建
- 如果是共享的群集,目标集合必须要存在
- 输出集合也可以是共享集合
on
可选字段,可以指定一个或多个字段作为判断文档唯一性的ID,用于匹配目标集合中是否已经存在相同ID的文档。
举例:
- 一个字段:
on: "_id" - 多个字段:
on: ["date", "name"]
注意:
- 如果指定了
on字段,除非on是_id,否则在聚合结果文档中必须存在on中指定的字段,如果聚合结果中没有_id字段,会自动添加一个。 on指定的字段的值不允许为空或数组。$merge必须要有一个包含on字段的唯一索引,索引键顺序无关紧要。- 索引必须有跟聚合集合同样的集合
- 唯一索引必须是一个稀疏索引
- 唯一索引不能是部分索引
- 对已经存在的输出集合,相应的索引必须已经存在
on的缺省值依赖于输出集合:- 如果输出集合不存在,
on的标识符必须且缺省为_id字段,相应的唯一索引_id是被自动创建的。 - 如果输出集合是已经存在的分片集合,
on标识符缺省为_id字段 - 如果输出集合是已经存在的非分片集合,
on标识符缺省为所有分片键值字段和_id字段,如果指定了一个不同的on标识符,on必须包含所有的分片键值字段。
- 如果输出集合不存在,
whenMatched
可选字段,指定当输出集合中存在与on字段指定的键值相同的文档时的处理方式,可以为以下值:
“replace” 替换
使用聚合结果替换已经存在的文档。当执行替换的时候不能修改对应文档_id字段的值,如果输出集合是分片集合,也不能修改分片键值,否则操作会产生错误。为了避免这个错误,如果on字段中没有包含_id字段,可以从聚合结果中移除_id字段以避免这个错误,比如可以使用类似$unset的阶段预先处理以下。
“keepExistin” 保留已存在的
不替换已经存在的文档
“merge" 合并
缺省值,合并匹配的文档,类似于$mergeObjects操作
- 如果聚合结果文档的字段在目标文档中不存在,就添加
- 如果聚合结果文档的字段在目标文档中已存在,则替换
举例:
如果目标集合有一个文档:
{_id: 1, a: 1, b: 1 }
聚合结果的文档是:
{ _id: 1, b: 5, z: 1 }则合并后的文档是:
{ _id: 1, a: 1, b: 5, z: 1 }
跟"replace"类似,合并的时候"_id"字段或分片键值是不能被修改的。
“fail” 失败
停止并且报错,之前所有的输出和更改都不能撤销。
使用聚合管道更新输出集合文档
当on指定的键值相同时,使用一个聚合管道更新输出集合的文档,如:
[ <stage1>, <stage2> ... ]
但是,管道只能包含下面的阶段:
$addFields及其别名$set$projecct及其别名$unset$replaceRoot及其别名$replaceWith
管道不能修改on涉及字段的值,比如匹配字段year,管道是不能修改year字段值的。另外whenMatched管道可以使用$<field>直接访问输出文档的字段。如果要在管道中访问聚合结果文档(就是输入文档)的字段,可以使用下面两种方式:
- 使用内置的
$$new变量来访问字段,就是$$new.<field>。$$new变量只能在省略let时才能使用。 - 在
let字段使用用户自定义的变量。以$$符号为前缀指定变量名$$<variable_name>,如:$$year。如果变量是文档,也可以包含文档字段,格式为$$<变量名>.<字段>。例如,$$year.month。
let
可选字段,为whenMatched的管道指定变量。可以指定文档的变量名和表达式:
{ <variable_name_1>: <expression_1>,...,<variable_name_n>: <expression_n> }
whenNotMatch
可选字段,决定了$merge在输出文档匹没有配到对应文档的情况,可以指定下面的预定义的字符串常量:
"insert"插入,缺省值,将聚合后的文档插入到输出集合。discard丢弃,就是不向输出集合中插入文档。fail失败,停止并宣告聚合操作失败,之前已经在输出集合中写入或修改的文档不能回滚。
相关文章:
)
MongoDB聚合:$merge 阶段(1)
$merge的用途是把聚合管道产生的结果写入指定的集合,有时候可以用$merge来做物化视图。需要注意,$meger操作必须是聚合管道的最后一个阶段。具体功能有: 能够输出到当前或不同的数据库能够输出到正在聚合的集合(慎重:…...

2. 云原生实战之kubesphere搭建
文章目录 机器介绍centos基本配置安装 VMware Tools设置静态ip关闭防火墙关闭SELinux开启时间同步配置host和hostname 安装kubesphere依赖项安装配置文件准备执行安装命令 机器介绍 在ESXI中准备虚拟机,部署参考官网:https://kubesphere.io/zh/ CentOs…...
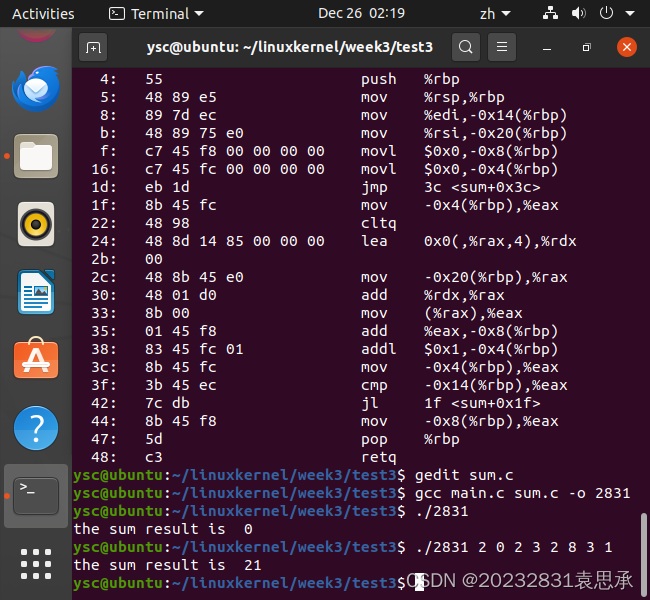
main参数传递、反汇编、汇编混合编程
week03 一、main参数传递二、反汇编三、汇编混合编程 一、main参数传递 参考 http://www.cnblogs.com/rocedu/p/6766748.html#SECCLA 在Linux下完成“求命令行传入整数参数的和” 注意C中main: int main(int argc, char *argv[]), 字符串“12” 转为12,可以调用atoi…...
前后端分离nodejs+vue医院预约挂号系统6nrhh
医院预约挂号系统主要有管理员、用户和医生三个功能模块。以下将对这三个功能的作用进行详细的剖析。 运行软件:vscode 前端nodejsvueElementUi 语言 node.js 框架:Express/koa 前端:Vue.js 数据库:mysql 开发软件:VScode/webstorm/hbuiderx均…...
 的几种常用方法)
在pytorch中,读取GPU上张量的数值 (数据从GPU到CPU) 的几种常用方法
1、.cpu() 方法: 使用 .cpu() 方法可以将张量从 GPU 移动到 CPU。这是一种简便的方法,常用于在进行 CPU 上的操作之前将数据从 GPU 取回 import torch# 在 GPU 上创建一个张量 gpu_tensor torch.tensor([1, 2, 3], devicecuda)# 将 GPU 上的张…...
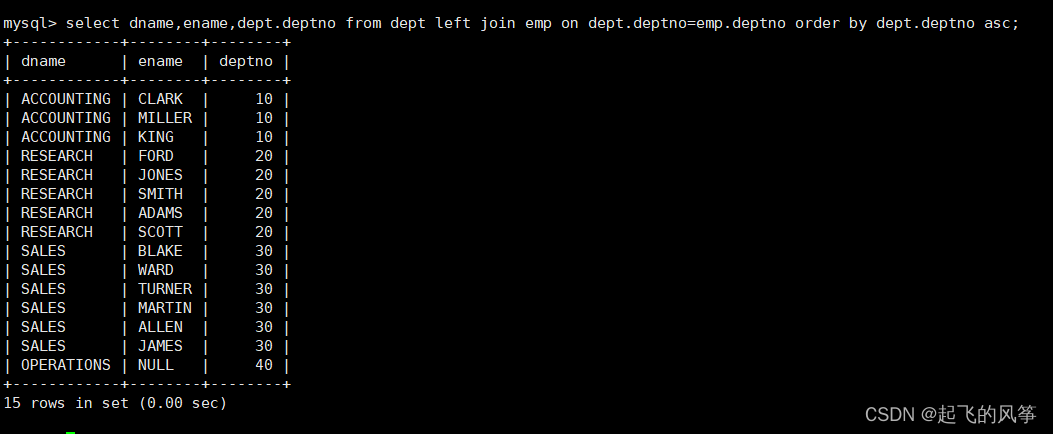
【mysql】—— 表的内连和外连
在MySQL中,内连(INNER JOIN)和外连(OUTER JOIN)是用于联接多个表的操作。接下来,我分别给大家介绍下二者。 目录 (一)内连接 1、什么叫内连接 2、语法格式 3、案例:显…...

VSCode远程开发配置
目录 概要远程开发插件安装开始连接SSH无密码登录开发环境配置 概要 现在很多公司都是直接远程到服务器上写代码,使用远程开发,可以在与生产环境相同的环境中开发、测试和部署代码,减少因环境不同而导致的问题。当下VSCode远程开发是支持的比…...

复数值神经网络可能是深度学习的未来
一、说明 复数这种东西,在人的头脑中似乎抽象、似乎复杂,然而,对于计算机来说,一点也不抽象,不复杂,那么,将复数概念推广到神经网络会是什么结果呢?本篇介绍国外的一些同行的尝试实践,请我们注意观察他们的进展。...
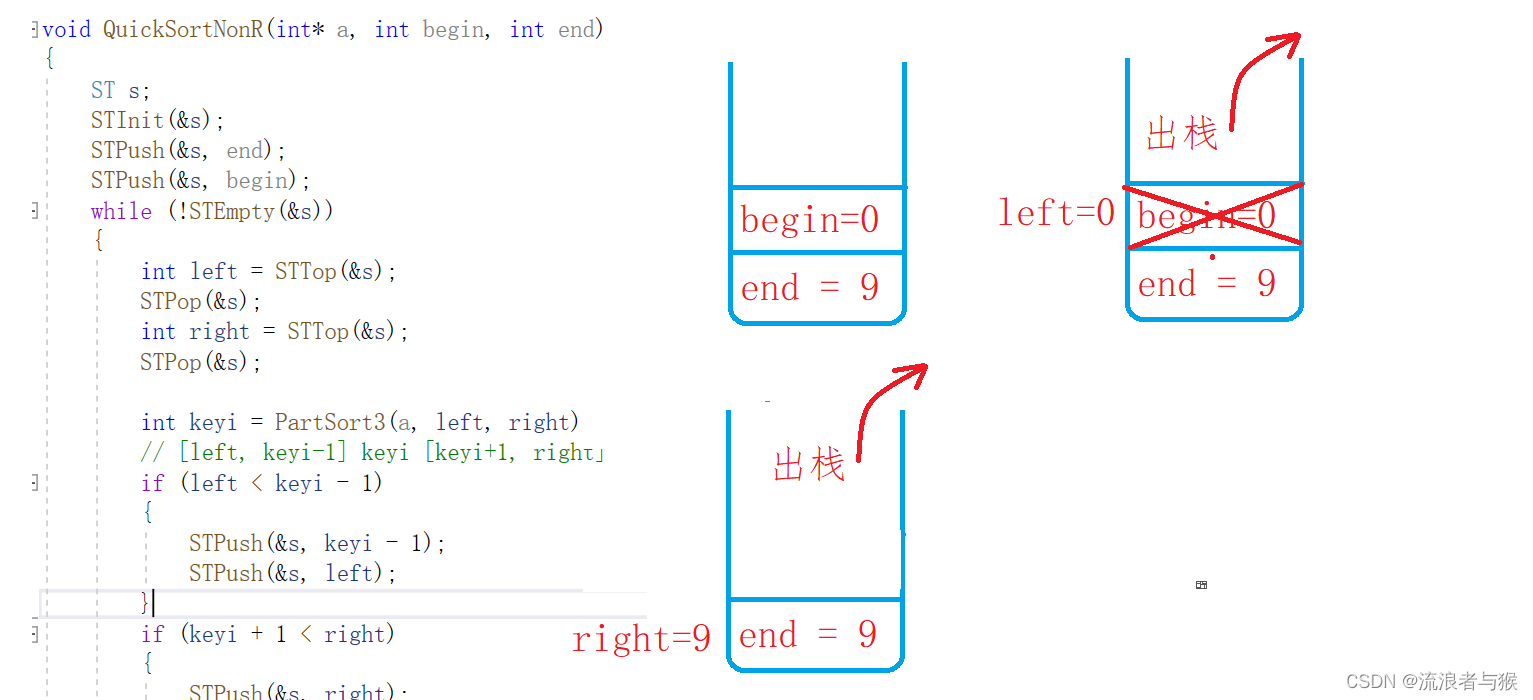
【C语言】数据结构——排序二(快排)
💗个人主页💗 ⭐个人专栏——数据结构学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:数组打印与交换1. 交换排序1.1 基本思想:1.2 冒泡与快排的异同 2. 冒泡排序2.1 基本思想2.2 …...
企业私有云容器化架构
什么是虚拟化: 虚拟化(Virtualization)技术最早出现在 20 世纪 60 年代的 IBM 大型机系统,在70年代的 System 370 系列中逐渐流行起来,这些机器通过一种叫虚拟机监控器(Virtual Machine Monitor,VMM&#x…...
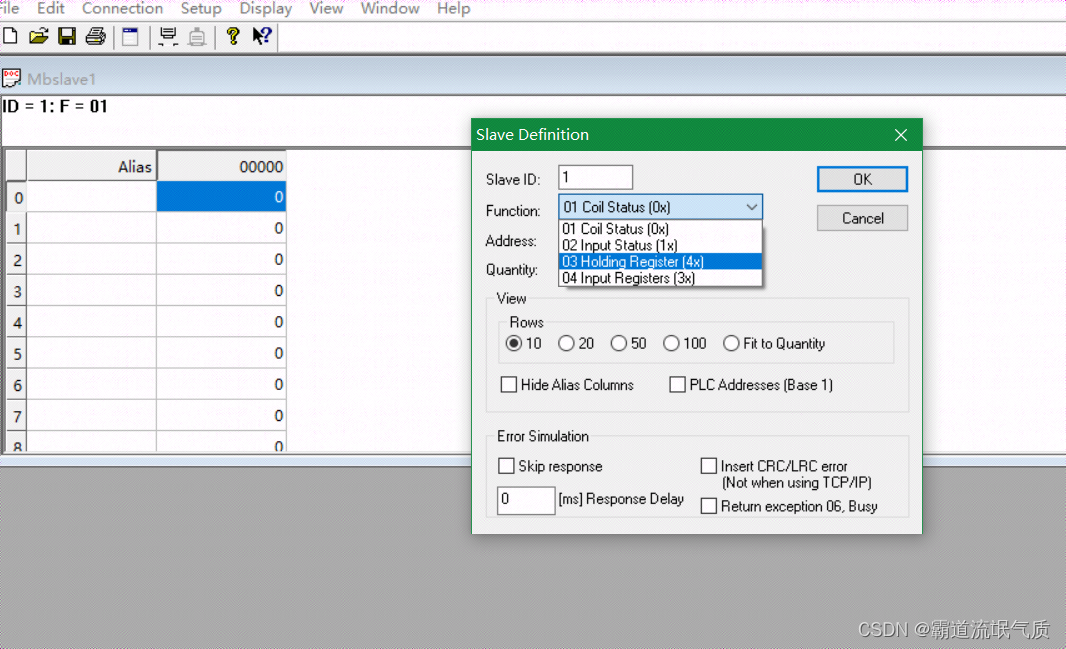
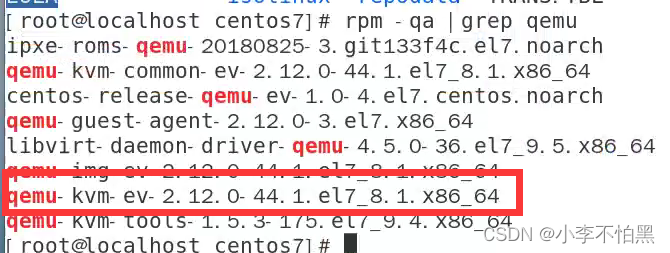
SpringBoot+modbus4j实现ModebusTCP通讯读取数据
场景 Windows上ModbusTCP模拟Master与Slave工具的使用: Windows上ModbusTCP模拟Master与Slave工具的使用-CSDN博客 Modebus TCP Modbus由MODICON公司于1979年开发,是一种工业现场总线协议标准。 1996年施耐德公司推出基于以太网TCP/IP的Modbus协议&…...

Linux性能优化全景指南
Part1 Linux性能优化 1、性能优化性能指标 高并发和响应快对应着性能优化的两个核心指标:吞吐和延时 应用负载角度:直接影响了产品终端的用户体验系统资源角度:资源使用率、饱和度等 性能问题的本质就是系统资源已经到达瓶颈,但…...
树莓派 ubuntu20.04下 python调讯飞的语音API,语音识别和语音合成
目录 1.环境搭建2.去讯飞官网申请密钥3.语音识别(sst)4.语音合成(tts)5.USB声卡可能报错 1.环境搭建 #环境说明:(尽量在ubuntu下使用, 本次代码均在该环境下实现) sudo apt-get install sox # 安装语音播放软件 pip …...
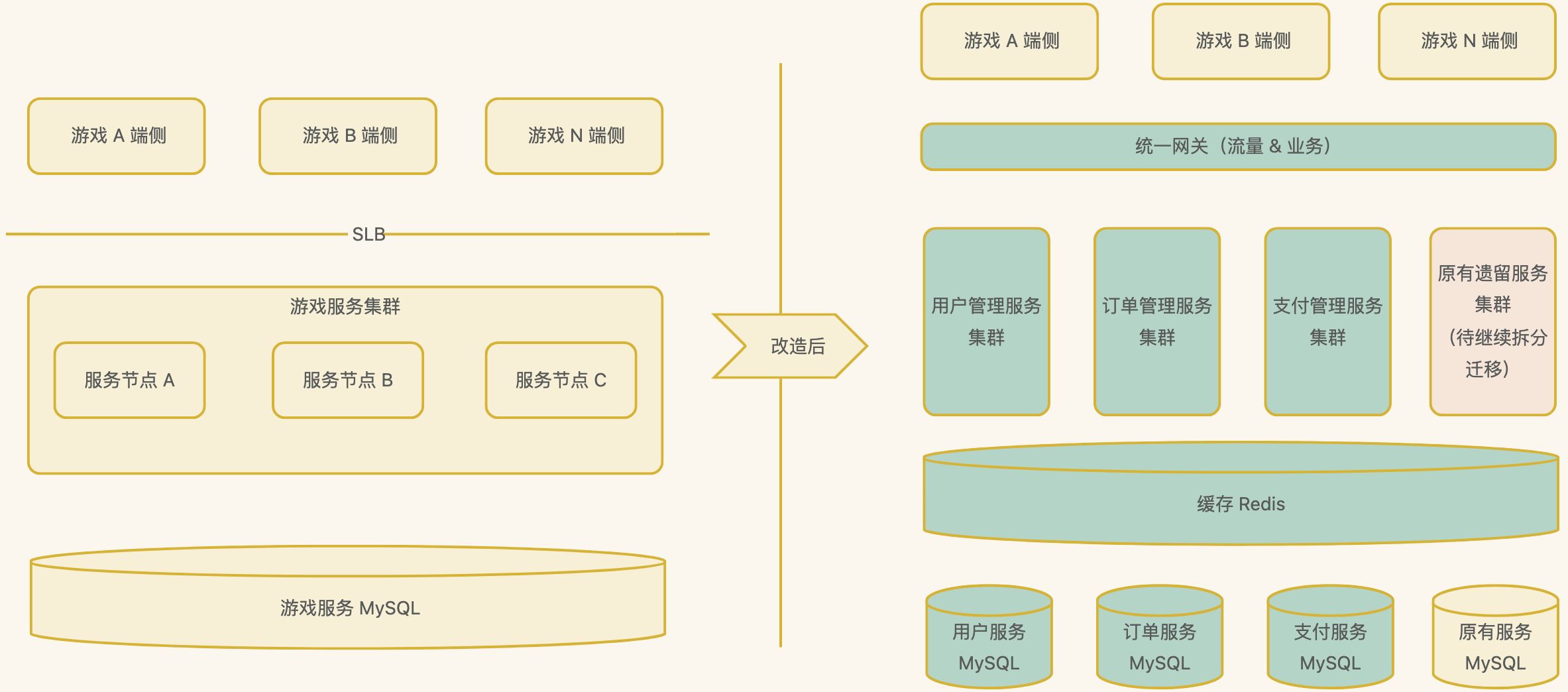
分布式系统架构设计之分布式系统实践案例和未来展望
分布式系统在过去的几十年里经历了长足的发展,从最初的简单分布式架构到今天的微服务、云原生等先进架构,取得了丰硕的成果。本文将通过实际案例分享分布式系统的架构实践,并展望未来可能的发展方向。 一、实践案例 1、微服务化实践 背景 …...
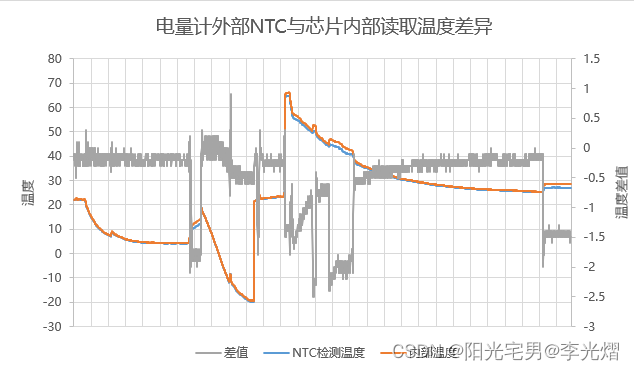
【办公软件】Excel双坐标轴图表
在工作中整理测试数据,往往需要一个图表展示两个差异较大的指标。比如共有三个数据,其中两个是要进行对比的温度值,另一个指标是两个温度的差值,这个差值可能很小。 举个实际的例子:数据如下所示,NTC检测温…...

彻底理解前端安全面试题(1)—— XSS 攻击,3种XSS攻击详解,建议收藏(含源码)
前言 前端关于网络安全看似高深莫测,其实来来回回就那么点东西,我总结一下就是 3 1 4,3个用字母描述的【分别是 XSS、CSRF、CORS】 一个中间人攻击。当然 CORS 同源策略是为了防止攻击的安全策略,其他的都是网络攻击。除了这…...

UE5.1_AI随机漫游
UE5.1_AI随机漫游 目录 UE5.1_AI随机漫游 AI随机漫游方法 方法1:AI角色蓝图直接写方法...
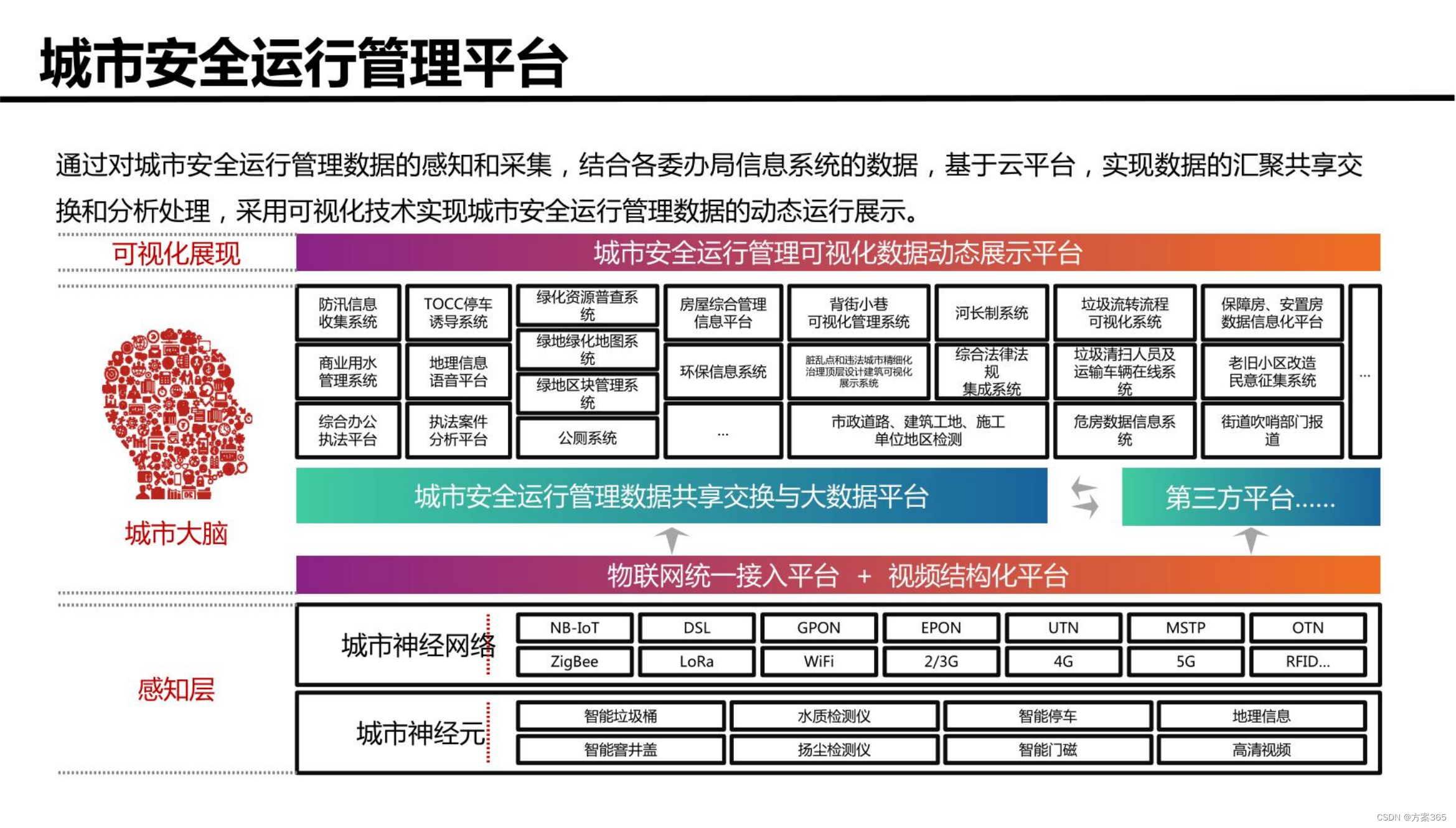
智慧城市新型基础设施建设综合方案:文件全文52页,附下载
关键词:智慧城市建设方案,智慧城市发展的前景和趋势,智慧城市项目方案,智慧城市管理平台,数字化城市,城市数字化转型 一、智慧城市新基建建设背景 1、城市化进程加速:随着城市化进程的加速&am…...
GitHub Copilot 终极详细介绍
编写代码通常是一项乏味且耗时的任务。现代开发人员一直在寻找新的方法来提高编程的生产力、准确性和效率。 像 GitHub Copilot 这样的自动代码生成工具可以使这成为可能。 GitHub Copilot 到底是什么? GitHub Copilot 于 2021 年 10 月推出,是 GitHub 的…...

LeetCode第63题 - 不同路径 II
题目 解答 class Solution {public int uniquePathsWithObstacles(int[][] obstacleGrid) {int m obstacleGrid.length;int n obstacleGrid[0].length;if (obstacleGrid[0][0] 1) {return 0;}if (obstacleGrid[m - 1][n - 1] 1) {return 0;}int[][] dp new int[m][n];dp…...

利用UptimeFlare与Cloudflare Workers自动化保活Huggingface Space
1. 为什么需要保活Huggingface Space Huggingface Space是个好东西,能让我们免费部署各种AI应用。但有个头疼的问题:如果48小时内没人访问,Space就会自动休眠。下次有人访问时,又要重新启动,等得花儿都谢了。我自己做…...

联想ideapad700-15ISK双系统迁移实战:Win10+Arch无缝切换到SSD的完整流程
联想ideapad700-15ISK双系统迁移实战:Win10Arch无缝切换到SSD的完整流程 当你的笔记本电脑运行速度开始变慢,开机时间越来越长,或许该考虑升级到SSD了。对于使用联想ideapad700-15ISK并安装了Win10和Arch双系统的用户来说,迁移系统…...

CodeHub:解锁3大效率革命,重新定义GitHub项目管理体验
CodeHub:解锁3大效率革命,重新定义GitHub项目管理体验 【免费下载链接】CodeHub A UWP GitHub Client 项目地址: https://gitcode.com/gh_mirrors/code/CodeHub 作为开发者,你是否曾在GitHub网页版中迷失于多标签页切换的混乱&#x…...

KART-RERANK与MySQL集成:构建企业级智能搜索系统
KART-RERANK与MySQL集成:构建企业级智能搜索系统 你是不是也遇到过这样的问题?自家电商平台或者内容社区里,用户搜“适合夏天穿的轻薄外套”,结果系统返回一堆“冬季加厚羽绒服”或者“春秋季夹克”。用户抱怨搜不准,…...

实测Qwen3-VL-30B:上传图片就能问,智能识别效果惊艳
实测Qwen3-VL-30B:上传图片就能问,智能识别效果惊艳 你有没有想过,给电脑看一张照片,它不仅能告诉你照片里有什么,还能像朋友一样跟你讨论照片里的故事?比如,你拍了一张晚餐的照片,…...

3秒守护隐私:Boss-Key重新定义窗口智能管理
3秒守护隐私:Boss-Key重新定义窗口智能管理 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办公环境中,窗…...

手机高频麦克风音频采样技术
随着移动终端音频应用的多元化发展,从超声通信、高频声纹识别到医疗级音频监测,对手机麦克风的高频采样能力提出了更高要求。手机高频麦克风音频采样技术,是实现高频音频信号捕捉、传输与后续处理的核心支撑,其性能直接决定了高频…...

WorkshopDL:跨平台资源获取的开源工具解决方案
WorkshopDL:跨平台资源获取的开源工具解决方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 在游戏模组生态中,跨平台资源访问与高效下载一直是技术爱…...

WebPlotDigitizer实战指南:从科研图表中智能提取数据的完整方案
WebPlotDigitizer实战指南:从科研图表中智能提取数据的完整方案 【免费下载链接】WebPlotDigitizer WebPlotDigitizer: 一个基于 Web 的工具,用于从图形图像中提取数值数据,支持 XY、极地、三角图和地图。 项目地址: https://gitcode.com/g…...

自抗扰顺序模型预测PWM整流器控制的Matlab仿真之旅
自抗扰顺序模型预测PWM整流器控制 matlab仿真,算法用.m文件编写 配套论文及理论推导公式和参数在电力电子领域,PWM整流器的控制一直是研究热点。今天咱就来唠唠自抗扰顺序模型预测(ADRC - SMPC)对PWM整流器控制的Matlab仿真实现&a…...