共享单车之数据分析
文章目录
- 第1关:统计共享单车每天的平均使用时间
- 第2关:统计共享单车在指定地点的每天平均次数
- 第3关:统计共享单车指定车辆每次使用的空闲平均时间
- 第4关:统计指定时间共享单车使用次数
- 第5关:统计共享单车线路流量
第1关:统计共享单车每天的平均使用时间
任务描述
本关任务:使用Hbase的MapReduce对已经存在 Hbase 的共享单车运行数据进行分析,统计共享单车每天的平均使用时间,其中共享单车运行数据在Hbase的t_shared_bicycle表中(表结构可在编程要求中进行查看)。
相关知识
为了完成本关任务,你需要掌握:
如何配置Hbase的MapReduce类;
如何使用Hbase的MapReduce进行数据分析。
如何配置Hbase的MapReduce类
MapReduce是运行在Job上的一个并行计算框架,分为Map节点和Reduce节点。
Hbase提供了org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。
initTableMapperJob 方法:
/**
*在提交TableMap作业之前使用它。 它会适当地设置
* 工作。
*
* @param table要读取的表名。
* @param scan具有列,时间范围等的扫描实例。
* @param mapper要使用的mapper类。
* @param outputKeyClass输出键的类。
* @param outputValueClass输出值的类。
* @param job当前要调整的工作。 确保传递的作业是
*携带所有必要的HBase配置。
* @throws IOException设置细节失败。
*/
public static void initTableMapperJob(String table, Scan scan,
Class<? extends TableMapper> mapper, Class<?> outputKeyClass,
Class<?> outputValueClass, Job job)
throws IOException
/ **
initTableReducerJob 方法:
/**
*在提交TableReduce作业之前使用它。 它会
*适当设置JobConf。
*
* @param table输出表。
* @param reducer要使用的reducer类。
* @param job当前要调整的工作。
* @throws IOException确定区域计数失败时。
*/
public static void initTableReducerJob(String table,
Class<? extends TableReducer> reducer, Job job)
throws IOException
如何使用Hbase的MapReduce进行数据分析
下面我们以统计每个城市的酒店个数的例子来介绍MapReduce的Map节点和Reduce节点:
Map节点执行类需要继承抽象类TableMapper,实现其map方法,结构如下:
public static class MyMapper extends TableMapper<Text, DoubleWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) {
}
}
在 map 方法中可从输入表(原数据表)得到行数据,最后向 Reduce 节点 输出键值对(key/value) 。
String cityId = Bytes.toString(result.getValue(“cityInfo”.getBytes(), “cityId”.getBytes()));
DoubleWritable i = new DoubleWritable(1);
context.write(new Text(cityId),i);
下面介绍Reduce节点,Reduce节点执行类需要继承抽象类TableReducer,实现其reduce方法:
public static class MyTableReducer extends TableReducer<Text, DoubleWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable values, Context context) {
}
}
在reduce方法里会接收map 方法里相同key 的集合,最后把结果存到输出到表里。
double sum = 0;
for (DoubleWritable num:values){
sum += num.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(“total_infos”.getBytes(),“total”.getBytes(),Bytes.toBytes(String.valueOf(sum)));
context.write(null,put);//initTableReducerJob 设置了表名所以在这里无需设置了
编程要求
在右侧代码窗口完成代码编写:
MapReduce类已经配置好,只需完成MapReduce的数据分析;
在map方法中,获取输入表t_shared_bicycle的相关信息,计算出使用时间=结束时间 - 开始时间,并把使用时间和开始时间的日期传给reduce
在reduce方法中通过使用时间和开始时间的日期计算共享单车每天平均使用时间,并把每天平均使用时间,四舍五入保留两位有效数字,存入到列族为info,字段为avgTime,ROWKEY 为avgTime的表里。
t_shared_bicycle表结构如下:
列族名称 字段 对应的文件的描述 ROWKEY (格式为:骑行id)
info beginTime 开始时间 trip_id
info endTime 结束时间 trip_id
info bicycleId 车辆id trip_id
info departure 出发地 trip_id
info destination 目的地 trip_id
info city 所在城市 trip_id
info start_longitude 开始经度 trip_id
info stop_longitude 结束经度 trip_id
info start_latitude 开始纬度 trip_id
info stop_latitude 结束纬度 trip_id
测试说明
平台会对你编写的代码进行测试,若是与预期输出相同,则算通关。
开始你的任务吧,祝你成功!
示例代码如下:
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.text.ParseException;
import java.util.Collection;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import java.util.Scanner;
import java.math.RoundingMode;
import java.math.BigDecimal;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/*** 统计共享单车每天的平均使用时间*/
public class AveragetTimeMapReduce extends Configured implements Tool {public static final byte[] family = "info".getBytes();public static class MyMapper extends TableMapper<Text, BytesWritable> {protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {/********** Begin *********/long beginTime = Long.parseLong(Bytes.toString(result.getValue(family, "beginTime".getBytes())));long endTime = Long.parseLong(Bytes.toString(result.getValue(family, "endTime".getBytes())));// 转化为yyyy-MM-ddString format = DateFormatUtils.format(beginTime, "yyyy-MM-dd", Locale.CHINA);// 计算时间long useTime = endTime - beginTime;// 拼装value ,包含日期 + 使用时间BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(format + "_" + useTime));context.write(new Text("avgTime"), bytesWritable);/********** End *********/}}public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {@Overridepublic void reduce(Text key, Iterable<BytesWritable> values, Context context)throws IOException, InterruptedException {/********** Begin *********/double sum = 0;int length = 0;Map<String, Long> map = new HashMap<String, Long>();for (BytesWritable price : values) {byte[] copyBytes = price.copyBytes();String string = Bytes.toString(copyBytes);String[] split = string.split("_");if (map.containsKey(split[0])) {Long integer = map.get(split[0]) + Long.parseLong(split[1]);map.put(split[0], integer);} else {map.put(split[0], Long.parseLong(split[1]));}}// 统计map value平均值Collection<Long> values2 = map.values();for (Long i : values2) {length++;sum += i;}BigDecimal decimal = new BigDecimal(sum / length /1000);BigDecimal setScale = decimal.setScale(2, RoundingMode.HALF_DOWN);Put put = new Put(Bytes.toBytes(key.toString()));put.addColumn(family, "avgTime".getBytes(), Bytes.toBytes(setScale.toString()));context.write(null, put);// initTableReducerJob 设置了 表名所以在这里无需设置了/********** End *********/}}public int run(String[] args) throws Exception {// 配置JobConfiguration conf = HBaseUtil.conf;// Scanner sc = new Scanner(System.in);// String arg1 = sc.next();// String arg2 = sc.next();String arg1 = "t_shared_bicycle";String arg2 = "t_bicycle_avgtime";try {HBaseUtil.createTable(arg2, new String[] { "info" });} catch (Exception e) {// 创建表失败e.printStackTrace();}Job job = configureJob(conf, new String[] { arg1, arg2 });return job.waitForCompletion(true) ? 0 : 1;}private Job configureJob(Configuration conf, String[] args) throws IOException {String tablename = args[0];String targetTable = args[1];Job job = new Job(conf, tablename);Scan scan = new Scan();scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存// 初始化Mapreduce程序TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);// 初始化ReduceTableMapReduceUtil.initTableReducerJob(targetTable, // output tableMyTableReducer.class, // reducer classjob);job.setNumReduceTasks(1);return job;}
}
第2关:统计共享单车在指定地点的每天平均次数
任务描述
本关任务:使用Hbase的MapReduce对已经存在 Hbase 的共享单车运行数据进行分析,统计共享单车每天在指定地点的平均次数,其中共享单车运行数据在Hbase的t_shared_bicycle表中(表结构可在编程要求中进行查看)。
相关知识
为了完成本关任务,你需要掌握:
如何配置Hbase的MapReduce类;
如何使用Hbase的MapReduce进行数据分析;
如何使用过滤器过滤读取到的数据。
如何配置Hbase的MapReduce类
MapReduce是运行在Job上的一个并行计算框架,分为Map节点和Reduce节点。
Hbase提供了org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。
initTableMapperJob方法:
/**
*在提交TableMap作业之前使用它。 它会适当地设置
* 工作。
*
* @param table要读取的表名。
* @param scan具有列,时间范围等的扫描实例。
* @param mapper要使用的mapper类。
* @param outputKeyClass输出键的类。
* @param outputValueClass输出值的类。
* @param job当前要调整的工作。 确保传递的作业是
*携带所有必要的HBase配置。
* @throws IOException设置细节失败。
*/
public static void initTableMapperJob(String table, Scan scan,
Class<? extends TableMapper> mapper, Class<?> outputKeyClass,
Class<?> outputValueClass, Job job)
throws IOException
/ **
initTableReducerJob方法:
/**
*在提交TableReduce作业之前使用它。 它会
*适当设置JobConf。
*
* @param table输出表。
* @param reducer要使用的reducer类。
* @param job当前要调整的工作。
* @throws IOException确定区域计数失败时。
*/
public static void initTableReducerJob(String table,
Class<? extends TableReducer> reducer, Job job)
throws IOException
如何使用Hbase的MapReduce进行数据分析
下面我们以统计每个城市的酒店个数的例子来介绍MapReduce的Map节点和Reduce节点:
Map节点执行类需要继承抽象类TableMapper,实现其map方法,结构如下:
public static class MyMapper extends TableMapper<Text, DoubleWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) {
}
}
在 map 方法中可从输入表(原数据表)得到行数据,最后向 Reduce 节点 输出键值对(key/value) 。
String cityId = Bytes.toString(result.getValue(“cityInfo”.getBytes(), “cityId”.getBytes()));
DoubleWritable i = new DoubleWritable(1);
context.write(new Text(cityId),i);
下面介绍Reduce节点,Reduce节点执行类需要继承抽象类TableReducer,实现其reduce方法:
public static class MyTableReducer extends TableReducer<Text, DoubleWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable values, Context context) {
}
}
在reduce方法里会 接收map 方法里 相同key 的集合,最后把结果存到输出到表里。
double sum = 0;
for (DoubleWritable num:values){
sum += num.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(“total_infos”.getBytes(),“total”.getBytes(),Bytes.toBytes(String.valueOf(sum)));
context.write(null,put);//initTableReducerJob 设置了表名所以在这里无需设置了
如何使用过滤器过滤读取到的数据
请查看 HBase高级特性:过滤器系列 。
编程要求
在右侧代码窗口完成代码编写:
MapReduce类需要进行配置,请在configureJob方法里配置表数据过滤器,过滤条件为:只获取目的地包含韩庄村,出发地为河北省保定市雄县的数据。
在map方法中,获取输入表t_shared_bicycle的相关信息,通过开始时间获取当天日期,并传入到reduce
在reduce方法中通过当天日期计算共享单车每天平均次数,并把每天次数,四舍五入保留两位有效数字,存入到列族为info,字段为avgNum,ROWKEY 为河北省保定市雄县-韩庄村的表里。
t_shared_bicycle表结构如下:
列族名称 字段 对应的文件的描述 ROWKEY (格式为:骑行id)
info beginTime 开始时间 trip_id
info endTime 结束时间 trip_id
info bicycleId 车辆id trip_id
info departure 出发地 trip_id
info destination 目的地 trip_id
info city 所在城市 trip_id
info start_longitude 开始经度 trip_id
info stop_longitude 结束经度 trip_id
info start_latitude 开始纬度 trip_id
info stop_latitude 结束纬度 trip_id
测试说明
平台会对你编写的代码进行测试,若是与预期输出相同,则算通关。
开始你的任务吧,祝你成功!
示例代码如下:
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import java.util.Scanner;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/*** 共享单车每天在韩庄村的平均空闲时间*/
public class AverageVehicleMapReduce extends Configured implements Tool {public static final byte[] family = "info".getBytes();public static class MyMapper extends TableMapper<Text, BytesWritable> {protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {/********** Begin *********/// 时间String beginTime = Bytes.toString(result.getValue(family, "beginTime".getBytes()));// 转化为yyyy-MM-ddString format = DateFormatUtils.format(Long.parseLong(beginTime), "yyyy-MM-dd", Locale.CHINA);BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(format));context.write(new Text("河北省保定市雄县-韩庄村"), bytesWritable);/********** End *********/}}public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {@Overridepublic void reduce(Text key, Iterable<BytesWritable> values, Context context)throws IOException, InterruptedException {/********** Begin *********/double sum = 0;int length = 0;Map<String, Integer> map = new HashMap<String, Integer>();for (BytesWritable price : values) {byte[] copyBytes = price.copyBytes();String string = Bytes.toString(copyBytes);if (map.containsKey(string)) {Integer integer = map.get(string) + 1;map.put(string, integer);} else {map.put(string, new Integer(1));}}// 统计map value平均值Collection<Integer> values2 = map.values();for (Integer i : values2) {length++;sum += i;}BigDecimal decimal = new BigDecimal(sum / length);BigDecimal setScale = decimal.setScale(2, RoundingMode.HALF_DOWN);Put put = new Put(Bytes.toBytes(key.toString()));put.addColumn(family, "avgNum".getBytes(), Bytes.toBytes(setScale.toString()));context.write(null, put);// initTableReducerJob 设置了 表名所以在这里无需设置了/********** End *********/}}public int run(String[] args) throws Exception {// 配置JobConfiguration conf = HBaseUtil.conf;//Scanner sc = new Scanner(System.in);//String arg1 = sc.next();//String arg2 = sc.next();String arg1 = "t_shared_bicycle";String arg2 = "t_bicycle_avgnum";try {HBaseUtil.createTable(arg2, new String[] { "info" });} catch (Exception e) {// 创建表失败e.printStackTrace();}Job job = configureJob(conf, new String[] { arg1, arg2 });return job.waitForCompletion(true) ? 0 : 1;}private Job configureJob(Configuration conf, String[] args) throws IOException {String tablename = args[0];String targetTable = args[1];Job job = new Job(conf, tablename);Scan scan = new Scan();scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存/********** Begin *********///设置过滤ArrayList<Filter> listForFilters = new ArrayList<Filter>();Filter destinationFilter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("destination"),CompareOperator.EQUAL, new SubstringComparator("韩庄村"));Filter departure = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("departure"),CompareOperator.EQUAL, Bytes.toBytes("河北省保定市雄县"));listForFilters.add(departure);listForFilters.add(destinationFilter);scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存Filter filters = new FilterList(listForFilters);scan.setFilter(filters);/********** End *********/// 初始化Mapreduce程序TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);// 初始化ReduceTableMapReduceUtil.initTableReducerJob(targetTable, // output tableMyTableReducer.class, // reducer classjob);job.setNumReduceTasks(1);return job;}
}

第3关:统计共享单车指定车辆每次使用的空闲平均时间
任务描述
本关任务:使用Hbase的MapReduce对已经存在Hbase 的共享单车运行数据进行分析,统计共享单车指定车辆每次使用的平均空闲时间,其中共享单车运行数据在Hbase的t_shared_bicycle表中(表结构可在编程要求中进行查看)。
相关知识
为了完成本关任务,你需要掌握:
如何配置Hbase的MapReduce类;
如何使用Hbase的MapReduce进行数据分析。
如何配置Hbase的MapReduce类
MapReduce是运行在Job上的一个并行计算框架,分为Map节点和Reduce节点。
Hbase提供了org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。
initTableMapperJob 方法:
/**
*在提交TableMap作业之前使用它。 它会适当地设置
* 工作。
*
* @param table要读取的表名。
* @param scan具有列,时间范围等的扫描实例。
* @param mapper要使用的mapper类。
* @param outputKeyClass输出键的类。
* @param outputValueClass输出值的类。
* @param job当前要调整的工作。 确保传递的作业是
*携带所有必要的HBase配置。
* @throws IOException设置细节失败。
*/
public static void initTableMapperJob(String table, Scan scan,
Class<? extends TableMapper> mapper, Class<?> outputKeyClass,
Class<?> outputValueClass, Job job)
throws IOException
/ **
initTableReducerJob方法:
/**
*在提交TableReduce作业之前使用它。 它会
*适当设置JobConf。
*
* @param table输出表。
* @param reducer要使用的reducer类。
* @param job当前要调整的工作。
* @throws IOException确定区域计数失败时。
*/
public static void initTableReducerJob(String table,
Class<? extends TableReducer> reducer, Job job)
throws IOException
如何使用Hbase的MapReduce进行数据分析
下面我们以统计每个城市的酒店个数的例子来介绍MapReduce的Map节点和Reduce节点:
Map节点执行类需要继承抽象类TableMapper,实现其map方法,结构如下:
public static class MyMapper extends TableMapper<Text, DoubleWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) {
}
}
在 map 方法中可从输入表(原数据表)得到行数据,最后向 Reduce 节点 输出键值对(key/value) 。
String cityId = Bytes.toString(result.getValue(“cityInfo”.getBytes(), “cityId”.getBytes()));
DoubleWritable i = new DoubleWritable(1);
context.write(new Text(cityId),i);
下面介绍Reduce节点,Reduce节点执行类需要继承抽象类TableReducer,实现其reduce方法:
public static class MyTableReducer extends TableReducer<Text, DoubleWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable values, Context context) {
}
}
在reduce方法里会接收map 方法里 相同key 的集合,最后把结果存到输出到表里。
double sum = 0;
for (DoubleWritable num:values){
sum += num.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(“total_infos”.getBytes(),“total”.getBytes(),Bytes.toBytes(String.valueOf(sum)));
context.write(null,put);//initTableReducerJob 设置了表名所以在这里无需设置了
编程要求
在右侧代码窗口完成代码编写:
MapReduce类需要进行配置,请在configureJob方法里配置表数据过滤器,过滤条件为:只获取车辆id为5996的数据。
在map方法中,获取输入表t_shared_bicycle的相关信息,获取开始时间和结束时间,并传入到reduce
在reduce方法中通过开始时间和结束时间计算每次使用的平均空闲时间,并把空闲时间单位转化为小时,四舍五入保留两位有效数字,存入到列族为info,字段为freeTime,ROWKEY 为5996的表里。
t_shared_bicycle表结构如下:
列族名称 字段 对应的文件的描述 ROWKEY (格式为:骑行id)
info beginTime 开始时间 trip_id
info endTime 结束时间 trip_id
info bicycleId 车辆id trip_id
info departure 出发地 trip_id
info destination 目的地 trip_id
info city 所在城市 trip_id
info start_longitude 开始经度 trip_id
info stop_longitude 结束经度 trip_id
info start_latitude 开始纬度 trip_id
info stop_latitude 结束纬度 trip_id
测试说明
平台会对你编写的代码进行测试,若是与预期输出相同,则算通关。
开始你的任务吧,祝你成功!
示例代码如下:
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/*** * 统计5996共享单车每次使用的空闲平均时间*/
public class FreeTimeMapReduce extends Configured implements Tool {public static final byte[] family = "info".getBytes();public static class MyMapper extends TableMapper<Text, BytesWritable> {protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {// 时间long beginTime = Long.parseLong(Bytes.toString(result.getValue(family, "beginTime".getBytes())));long endTime = Long.parseLong(Bytes.toString(result.getValue(family, "endTime".getBytes())));// 拼装value ,包含开始时间和结束时间BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(beginTime + "_" + endTime));context.write(new Text("5996"), bytesWritable);}}public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {@Overridepublic void reduce(Text key, Iterable<BytesWritable> values, Context context)throws IOException, InterruptedException {long freeTime = 0;long beginTime = 0;int length = 0;for (BytesWritable time : values) {byte[] copyBytes = time.copyBytes();String timeLong = Bytes.toString(copyBytes);String[] split = timeLong.split("_");if(beginTime == 0) {beginTime = Long.parseLong(split[0]);continue;}else {//空闲时间 = 本次开始时间 - 上一次结束时间 freeTime = freeTime + beginTime - Long.parseLong(split[1]);//重新设置开始时间beginTime = Long.parseLong(split[0]);length ++;}}Put put = new Put(Bytes.toBytes(key.toString()));BigDecimal decimal = new BigDecimal(freeTime / length /1000 /60 /60);BigDecimal setScale = decimal.setScale(2, RoundingMode.HALF_DOWN);put.addColumn(family, "freeTime".getBytes(), Bytes.toBytes(setScale.toString()));context.write(null, put);// initTableReducerJob 设置了 表名所以在这里无需设置了}}public int run(String[] args) throws Exception {// 配置JobConfiguration conf = HBaseUtil.conf;// Scanner sc = new Scanner(System.in);// String arg1 = sc.next();// String arg2 = sc.next();String arg1 = "t_shared_bicycle";String arg2 = "t_bicycle_freetime";try {HBaseUtil.createTable(arg2, new String[] { "info" });} catch (Exception e) {// 创建表失败e.printStackTrace();}Job job = configureJob(conf, new String[] { arg1, arg2 });return job.waitForCompletion(true) ? 0 : 1;}private Job configureJob(Configuration conf, String[] args) throws IOException {String tablename = args[0];String targetTable = args[1];Job job = new Job(conf, tablename);Scan scan = new Scan();scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存Filter filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("bicycleId"),CompareOperator.EQUAL, Bytes.toBytes("5996"));scan.setFilter(filter);// 初始化Mapreduce程序TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);// 初始化ReduceTableMapReduceUtil.initTableReducerJob(targetTable, // output tableMyTableReducer.class, // reducer classjob);job.setNumReduceTasks(1);return job;}
}

第4关:统计指定时间共享单车使用次数
任务描述
本关任务:使用Hbase的MapReduce对已经存在Hbase的共享单车运行数据进行分析,统计共享单车指定时间的使用次数,其中共享单车运行数据在Hbase的t_shared_bicycle表中(表结构可在编程要求中进行查看)。
相关知识
为了完成本关任务,你需要掌握:
如何配置Hbase的MapReduce类;
如何使用Hbase的MapReduce进行数据分析。
如何配置Hbase的MapReduce类
MapReduce是运行在Job上的一个并行计算框架,分为Map节点和Reduce节点。
Hbase提供了org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。
initTableMapperJob方法:
/**
*在提交TableMap作业之前使用它。 它会适当地设置
* 工作。
*
* @param table要读取的表名。
* @param scan具有列,时间范围等的扫描实例。
* @param mapper要使用的mapper类。
* @param outputKeyClass输出键的类。
* @param outputValueClass输出值的类。
* @param job当前要调整的工作。 确保传递的作业是
*携带所有必要的HBase配置。
* @throws IOException设置细节失败。
*/
public static void initTableMapperJob(String table, Scan scan,
Class<? extends TableMapper> mapper, Class<?> outputKeyClass,
Class<?> outputValueClass, Job job)
throws IOException
/ **
initTableReducerJob方法:
/**
*在提交TableReduce作业之前使用它。 它会
*适当设置JobConf。
*
* @param table输出表。
* @param reducer要使用的reducer类。
* @param job当前要调整的工作。
* @throws IOException确定区域计数失败时。
*/
public static void initTableReducerJob(String table,
Class<? extends TableReducer> reducer, Job job)
throws IOException
如何使用Hbase的MapReduce进行数据分析
下面我们以统计每个城市的酒店个数的例子来介绍MapReduce的Map节点和Reduce节点:
Map节点执行类需要继承抽象类TableMapper,实现其map方法,结构如下:
public static class MyMapper extends TableMapper<Text, DoubleWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) {
}
}
在 map 方法中可从输入表(原数据表)得到行数据 ,最后向 Reduce 节点 输出键值对(key/value) 。
String cityId = Bytes.toString(result.getValue(“cityInfo”.getBytes(), “cityId”.getBytes()));
DoubleWritable i = new DoubleWritable(1);
context.write(new Text(cityId),i);
下面介绍Reduce节点,Reduce节点执行类需要继承抽象类TableReducer,实现其reduce方法:
public static class MyTableReducer extends TableReducer<Text, DoubleWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable values, Context context) {
}
}
在reduce方法里会接收map 方法里 相同key 的集合,最后把结果存到输出到表里。
double sum = 0;
for (DoubleWritable num:values){
sum += num.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(“total_infos”.getBytes(),“total”.getBytes(),Bytes.toBytes(String.valueOf(sum)));
context.write(null,put);//initTableReducerJob 设置了表名所以在这里无需设置了
编程要求
在右侧代码窗口Begin-End处完成代码编写:
MapReduce类需要进行配置,请在configureJob方法里配置表数据过滤器,过滤条件为:只获取开始时间大于等于2017-08-01,结束时间小于等于2017-09-01的数据。
在map方法中,获取输入表t_shared_bicycle的相关信息,次数设为1,并传入到reduce
在reduce方法中通过次数计算共享单车使用总次数,并把总次数存入到列族为info,字段为usageRate,ROWKEY 为departure的表里。
t_shared_bicycle表结构如下:
列族名称 字段 对应的文件的描述 ROWKEY (格式为:骑行id)
info beginTime 开始时间 trip_id
info endTime 结束时间 trip_id
info bicycleId 车辆id trip_id
info departure 出发地 trip_id
info destination 目的地 trip_id
info city 所在城市 trip_id
info start_longitude 开始经度 trip_id
info stop_longitude 结束经度 trip_id
info start_latitude 开始纬度 trip_id
info stop_latitude 结束纬度 trip_id
beginTime 和 endTime 在 Hbase 中以时间戳的形式存储
测试说明
平台会对你编写的代码进行测试,若是与预期输出相同,则算通关。
开始你的任务吧,祝你成功!
示例代码如下:
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/*** 共享单车使用次数统计*/
public class UsageRateMapReduce extends Configured implements Tool {public static final byte[] family = "info".getBytes();public static class MyMapper extends TableMapper<Text, IntWritable> {protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {/********** Begin *********/// 次数IntWritable doubleWritable = new IntWritable(1);context.write(new Text("departure"), doubleWritable);/********** End *********/}}public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {@Overridepublic void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {/********** Begin *********/ int totalNum = 0;for (IntWritable num : values) {int d = num.get();totalNum += d;}Put put = new Put(Bytes.toBytes(key.toString()));put.addColumn(family, "usageRate".getBytes(), Bytes.toBytes(String.valueOf(totalNum)));context.write(null, put);// initTableReducerJob 设置了 表名所以在这里无需设置了/********** End *********/}}public int run(String[] args) throws Exception {// 配置JobConfiguration conf = HBaseUtil.conf;// Scanner sc = new Scanner(System.in);// String arg1 = sc.next();// String arg2 = sc.next();String arg1 = "t_shared_bicycle";String arg2 = "t_bicycle_usagerate";try {HBaseUtil.createTable(arg2, new String[] { "info" });} catch (Exception e) {// 创建表失败e.printStackTrace();}Job job = configureJob(conf, new String[] { arg1, arg2 });return job.waitForCompletion(true) ? 0 : 1;}private Job configureJob(Configuration conf, String[] args) throws IOException {String tablename = args[0];String targetTable = args[1];Job job = new Job(conf, tablename);ArrayList<Filter> listForFilters = new ArrayList<Filter>();FastDateFormat instance = FastDateFormat.getInstance("yyyy-MM-dd");Scan scan = new Scan();scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存/********** Begin *********/try {Filter destinationFilter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("beginTime"),CompareOperator.GREATER_OR_EQUAL, Bytes.toBytes(String.valueOf(instance.parse("2017-08-01").getTime())));Filter departure = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("endTime"),CompareOperator.LESS_OR_EQUAL, Bytes.toBytes(String.valueOf(instance.parse("2017-09-01").getTime())));listForFilters.add(departure);listForFilters.add(destinationFilter);}catch (Exception e) {e.printStackTrace();return null;}Filter filters = new FilterList(listForFilters);scan.setFilter(filters);/********** End *********/// 初始化Mapreduce程序TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, IntWritable.class, job);// 初始化ReduceTableMapReduceUtil.initTableReducerJob(targetTable, // output tableMyTableReducer.class, // reducer classjob);job.setNumReduceTasks(1);return job;}
}

第5关:统计共享单车线路流量
任务描述
本关任务:使用Hbase的MapReduce对已经存在Hbase的共享单车运行数据进行分析,统计共享单车线路次数,其中共享单车运行数据在Hbase的t_shared_bicycle表中(表结构可在编程要求中进行查看)。
相关知识
为了完成本关任务,你需要掌握:
如何配置Hbase的MapReduce类;
如何使用Hbase的MapReduce进行数据分析。
如何配置Hbase的MapReduce类
MapReduce是运行在Job上的一个并行计算框架,分为Map节点和Reduce节点。
Hbase提供了org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil的initTableMapperJob和initTableReducerJob两个方法来完成MapReduce的配置。
initTableMapperJob 方法:
/**
*在提交TableMap作业之前使用它。 它会适当地设置
* 工作。
*
* @param table要读取的表名。
* @param scan具有列,时间范围等的扫描实例。
* @param mapper要使用的mapper类。
* @param outputKeyClass输出键的类。
* @param outputValueClass输出值的类。
* @param job当前要调整的工作。 确保传递的作业是
*携带所有必要的HBase配置。
* @throws IOException设置细节失败。
*/
public static void initTableMapperJob(String table, Scan scan,
Class<? extends TableMapper> mapper, Class<?> outputKeyClass,
Class<?> outputValueClass, Job job)
throws IOException
/ **
initTableReducerJob方法:
/**
*在提交TableReduce作业之前使用它。 它会
*适当设置JobConf。
*
* @param table输出表。
* @param reducer要使用的reducer类。
* @param job当前要调整的工作。
* @throws IOException确定区域计数失败时。
*/
public static void initTableReducerJob(String table,
Class<? extends TableReducer> reducer, Job job)
throws IOException
如何使用Hbase的MapReduce进行数据分析
下面我们以统计每个城市的酒店个数的例子来介绍MapReduce的Map节点和Reduce节点:
Map节点执行类需要继承抽象类TableMapper,实现其map方法,结构如下:
public static class MyMapper extends TableMapper<Text, DoubleWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) {
}
}
在 map 方法中可从输入表(原数据表)得到行数据 ,最后向 Reduce 节点 输出键值对(key/value) 。
String cityId = Bytes.toString(result.getValue(“cityInfo”.getBytes(), “cityId”.getBytes()));
DoubleWritable i = new DoubleWritable(1);
context.write(new Text(cityId),i);
下面介绍Reduce节点,Reduce节点执行类需要继承抽象类TableReducer,实现其reduce方法:
public static class MyTableReducer extends TableReducer<Text, DoubleWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable values, Context context) {
}
}
在reduce方法里会接收map 方法里 相同key 的集合,最后把结果存到输出到表里。
double sum = 0;
for (DoubleWritable num:values){
sum += num.get();
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(“total_infos”.getBytes(),“total”.getBytes(),Bytes.toBytes(String.valueOf(sum)));
context.write(null,put);//initTableReducerJob 设置了表名所以在这里无需设置了
编程要求
在右侧代码窗口完成代码编写:
MapReduce类已经配置好,不需要再进行配置
在map方法中,获取输入表t_shared_bicycle的相关信息,设置1为线路次数,把开始经度、结束经度、开始维度、结束维度、出发地、目的地、线路次数传入到reduce
在reduce方法中通过线路次数计算共享单车每个路线的使用次数,存入到列族为info,字段为lineTotal的表里,ROWKEY 格式为:开始经度-结束经度_开始维度-结束维度_出发地—目的地。
平台会输出前五的单车线路流量进行评测
t_shared_bicycle表结构如下:
列族名称 字段 对应的文件的描述 ROWKEY (格式为:骑行id)
info beginTime 开始时间 trip_id
info endTime 结束时间 trip_id
info bicycleId 车辆id trip_id
info departure 出发地 trip_id
info destination 目的地 trip_id
info city 所在城市 trip_id
info start_longitude 开始经度 trip_id
info stop_longitude 结束经度 trip_id
info start_latitude 开始纬度 trip_id
info stop_latitude 结束纬度 trip_id
测试说明
平台会对你编写的代码进行测试,若是与预期输出相同,则算通关。
开始你的任务吧,祝你成功!
示例代码如下:
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/*** 共享单车线路流量统计*/
public class LineTotalMapReduce extends Configured implements Tool {public static final byte[] family = "info".getBytes();public static class MyMapper extends TableMapper<Text, IntWritable> {protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {/********** Begin *********/ // 开始经纬度String start_latitude = Bytes.toString(result.getValue(family, "start_latitude".getBytes()));String start_longitude = Bytes.toString(result.getValue(family, "start_longitude".getBytes()));// 结束经纬度String stop_latitude = Bytes.toString(result.getValue(family, "stop_latitude".getBytes()));String stop_longitude = Bytes.toString(result.getValue(family, "stop_longitude".getBytes()));// 出发地String departure = Bytes.toString(result.getValue(family, "departure".getBytes()));// 目的地String destination = Bytes.toString(result.getValue(family, "destination".getBytes()));// 拼装value IntWritable doubleWritable = new IntWritable(1);context.write(new Text(start_latitude + "-" + start_longitude + "_" + stop_latitude + "-" + stop_longitude+ "_" + departure + "-" + destination), doubleWritable);/********** End *********/ }}public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {@Overridepublic void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {/********** Begin *********/ int totalNum = 0;for (IntWritable num : values) {int d = num.get();totalNum += d;}Put put = new Put(Bytes.toBytes(key.toString() + totalNum ));put.addColumn(family, "lineTotal".getBytes(), Bytes.toBytes(String.valueOf(totalNum)));context.write(null, put);// initTableReducerJob 设置了 表名所以在这里无需设置了/********** End *********/}}public int run(String[] args) throws Exception {// 配置JobConfiguration conf = HBaseUtil.conf;// Scanner sc = new Scanner(System.in);// String arg1 = sc.next();// String arg2 = sc.next();String arg1 = "t_shared_bicycle";String arg2 = "t_bicycle_linetotal";try {HBaseUtil.createTable(arg2, new String[] { "info" });} catch (Exception e) {// 创建表失败e.printStackTrace();}Job job = configureJob(conf, new String[] { arg1, arg2 });return job.waitForCompletion(true) ? 0 : 1;}private Job configureJob(Configuration conf, String[] args) throws IOException {String tablename = args[0];String targetTable = args[1];Job job = new Job(conf, tablename);Scan scan = new Scan();scan.setCaching(300);scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存// 初始化Mapreduce程序TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, IntWritable.class, job);// 初始化ReduceTableMapReduceUtil.initTableReducerJob(targetTable, // output tableMyTableReducer.class, // reducer classjob);job.setNumReduceTasks(1);return job;}
}
相关文章:
共享单车之数据分析
文章目录 第1关:统计共享单车每天的平均使用时间第2关:统计共享单车在指定地点的每天平均次数第3关:统计共享单车指定车辆每次使用的空闲平均时间第4关:统计指定时间共享单车使用次数第5关:统计共享单车线路流量 第1关…...

Spring的Bean你了解吗
Bean的配置 Spring容器支持XML(常用)和Properties两种格式的配置文件 Spring中XML配置文件的根元素是,中包含了多个子元素,每个子元素定义了一个Bean,并描述了该Bean如何装配到Spring容器中 元素包含了多个属性以及子元素,常用属性及子元素如下所示 i…...
)
MongoDB聚合:$merge 阶段(1)
$merge的用途是把聚合管道产生的结果写入指定的集合,有时候可以用$merge来做物化视图。需要注意,$meger操作必须是聚合管道的最后一个阶段。具体功能有: 能够输出到当前或不同的数据库能够输出到正在聚合的集合(慎重:…...

2. 云原生实战之kubesphere搭建
文章目录 机器介绍centos基本配置安装 VMware Tools设置静态ip关闭防火墙关闭SELinux开启时间同步配置host和hostname 安装kubesphere依赖项安装配置文件准备执行安装命令 机器介绍 在ESXI中准备虚拟机,部署参考官网:https://kubesphere.io/zh/ CentOs…...
main参数传递、反汇编、汇编混合编程
week03 一、main参数传递二、反汇编三、汇编混合编程 一、main参数传递 参考 http://www.cnblogs.com/rocedu/p/6766748.html#SECCLA 在Linux下完成“求命令行传入整数参数的和” 注意C中main: int main(int argc, char *argv[]), 字符串“12” 转为12,可以调用atoi…...
前后端分离nodejs+vue医院预约挂号系统6nrhh
医院预约挂号系统主要有管理员、用户和医生三个功能模块。以下将对这三个功能的作用进行详细的剖析。 运行软件:vscode 前端nodejsvueElementUi 语言 node.js 框架:Express/koa 前端:Vue.js 数据库:mysql 开发软件:VScode/webstorm/hbuiderx均…...
 的几种常用方法)
在pytorch中,读取GPU上张量的数值 (数据从GPU到CPU) 的几种常用方法
1、.cpu() 方法: 使用 .cpu() 方法可以将张量从 GPU 移动到 CPU。这是一种简便的方法,常用于在进行 CPU 上的操作之前将数据从 GPU 取回 import torch# 在 GPU 上创建一个张量 gpu_tensor torch.tensor([1, 2, 3], devicecuda)# 将 GPU 上的张…...
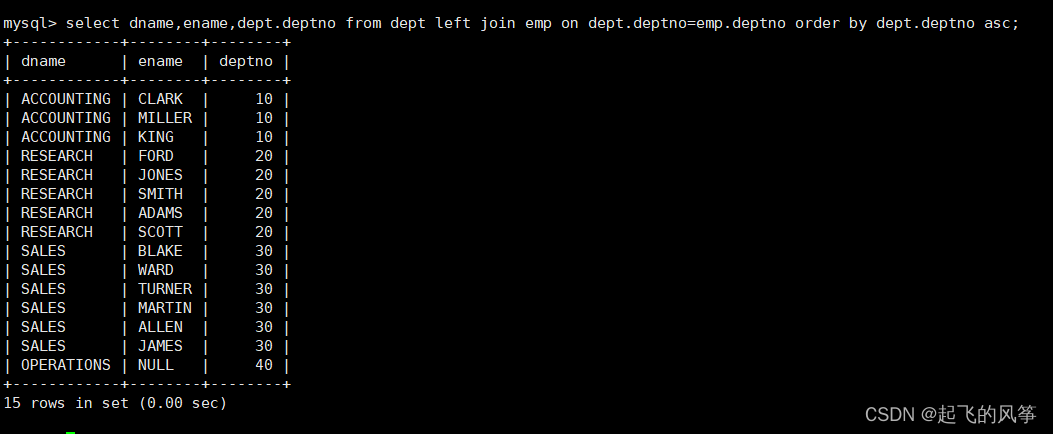
【mysql】—— 表的内连和外连
在MySQL中,内连(INNER JOIN)和外连(OUTER JOIN)是用于联接多个表的操作。接下来,我分别给大家介绍下二者。 目录 (一)内连接 1、什么叫内连接 2、语法格式 3、案例:显…...

VSCode远程开发配置
目录 概要远程开发插件安装开始连接SSH无密码登录开发环境配置 概要 现在很多公司都是直接远程到服务器上写代码,使用远程开发,可以在与生产环境相同的环境中开发、测试和部署代码,减少因环境不同而导致的问题。当下VSCode远程开发是支持的比…...

复数值神经网络可能是深度学习的未来
一、说明 复数这种东西,在人的头脑中似乎抽象、似乎复杂,然而,对于计算机来说,一点也不抽象,不复杂,那么,将复数概念推广到神经网络会是什么结果呢?本篇介绍国外的一些同行的尝试实践,请我们注意观察他们的进展。...
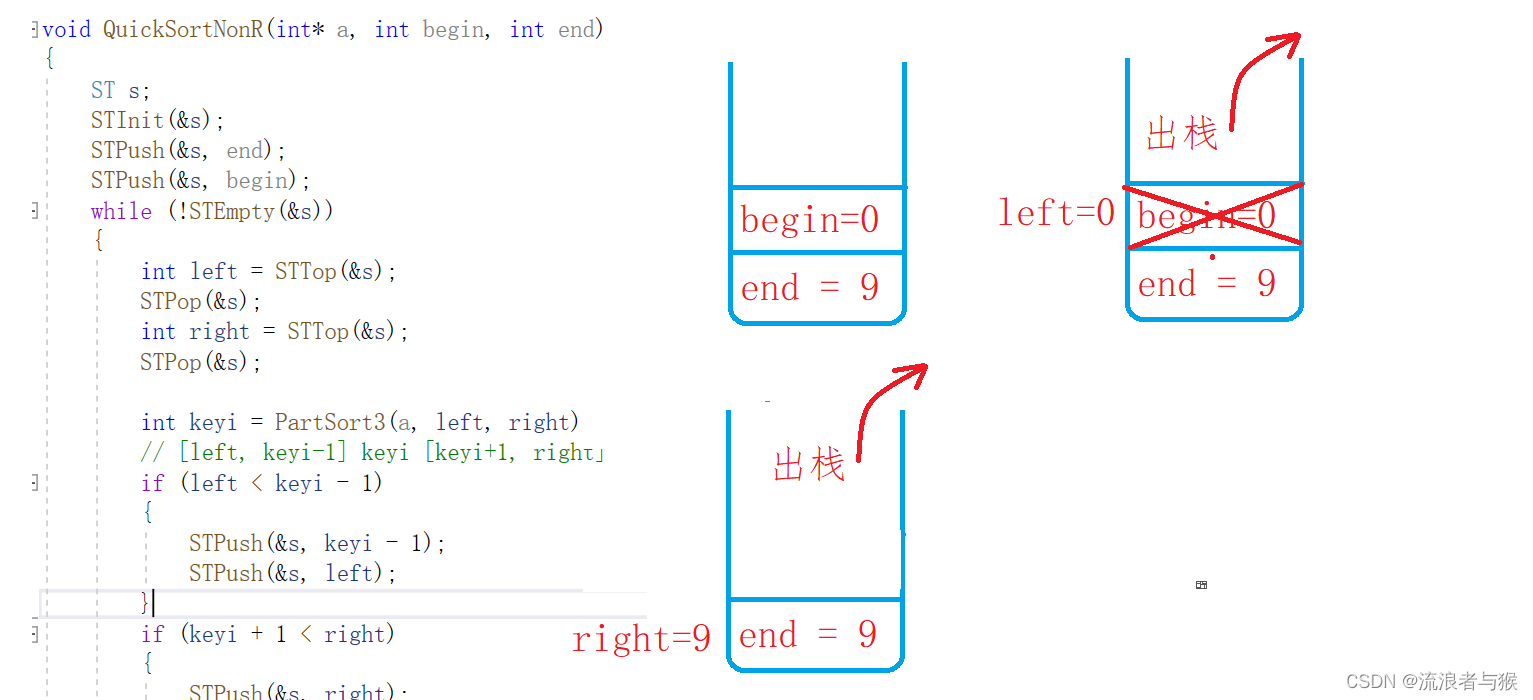
【C语言】数据结构——排序二(快排)
💗个人主页💗 ⭐个人专栏——数据结构学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:数组打印与交换1. 交换排序1.1 基本思想:1.2 冒泡与快排的异同 2. 冒泡排序2.1 基本思想2.2 …...
企业私有云容器化架构
什么是虚拟化: 虚拟化(Virtualization)技术最早出现在 20 世纪 60 年代的 IBM 大型机系统,在70年代的 System 370 系列中逐渐流行起来,这些机器通过一种叫虚拟机监控器(Virtual Machine Monitor,VMM&#x…...
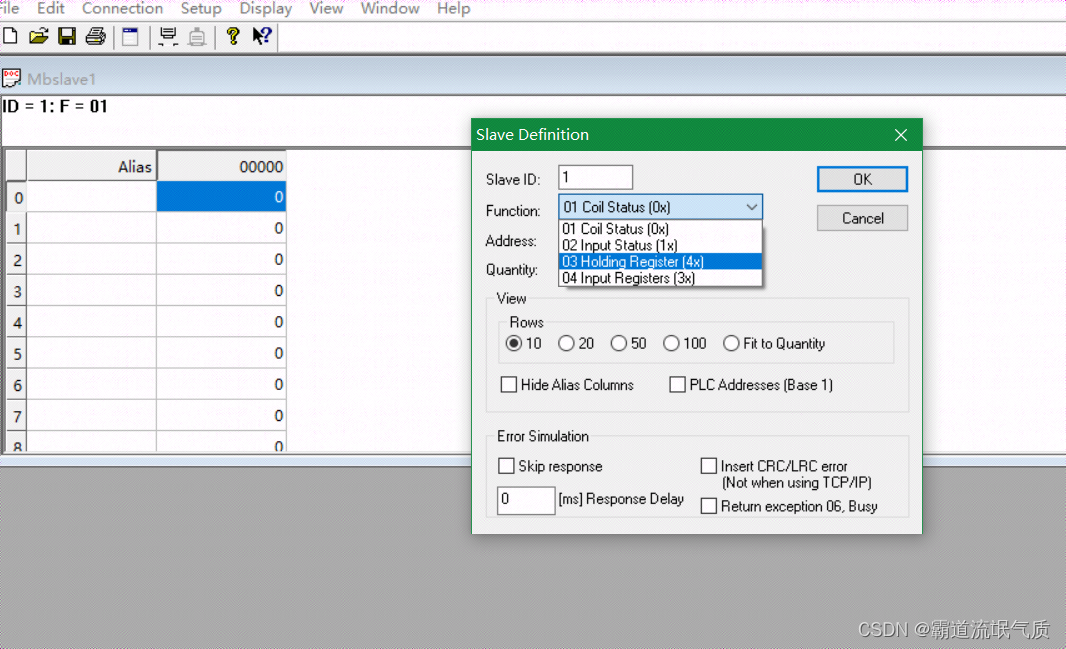
SpringBoot+modbus4j实现ModebusTCP通讯读取数据
场景 Windows上ModbusTCP模拟Master与Slave工具的使用: Windows上ModbusTCP模拟Master与Slave工具的使用-CSDN博客 Modebus TCP Modbus由MODICON公司于1979年开发,是一种工业现场总线协议标准。 1996年施耐德公司推出基于以太网TCP/IP的Modbus协议&…...

Linux性能优化全景指南
Part1 Linux性能优化 1、性能优化性能指标 高并发和响应快对应着性能优化的两个核心指标:吞吐和延时 应用负载角度:直接影响了产品终端的用户体验系统资源角度:资源使用率、饱和度等 性能问题的本质就是系统资源已经到达瓶颈,但…...
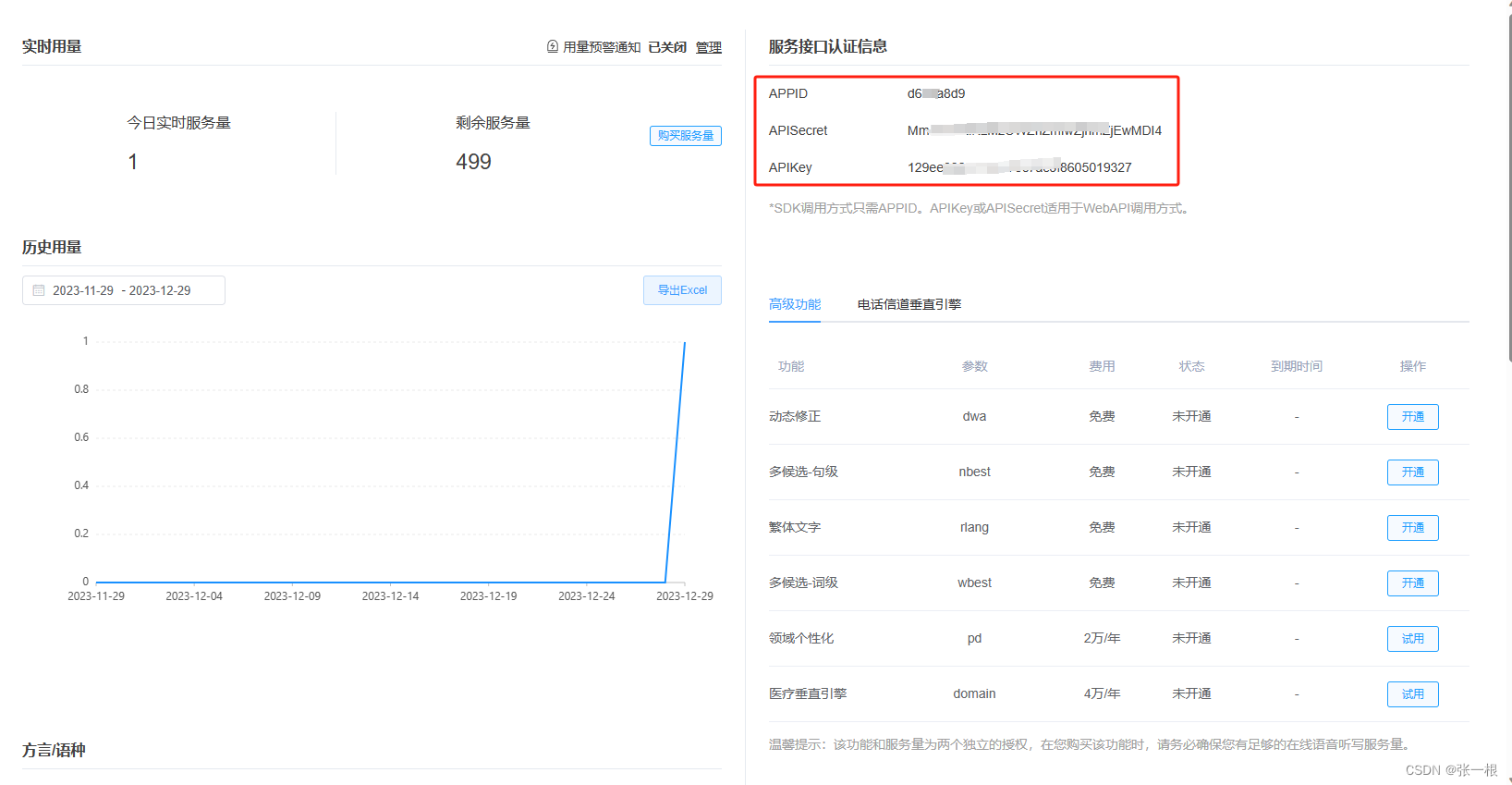
树莓派 ubuntu20.04下 python调讯飞的语音API,语音识别和语音合成
目录 1.环境搭建2.去讯飞官网申请密钥3.语音识别(sst)4.语音合成(tts)5.USB声卡可能报错 1.环境搭建 #环境说明:(尽量在ubuntu下使用, 本次代码均在该环境下实现) sudo apt-get install sox # 安装语音播放软件 pip …...
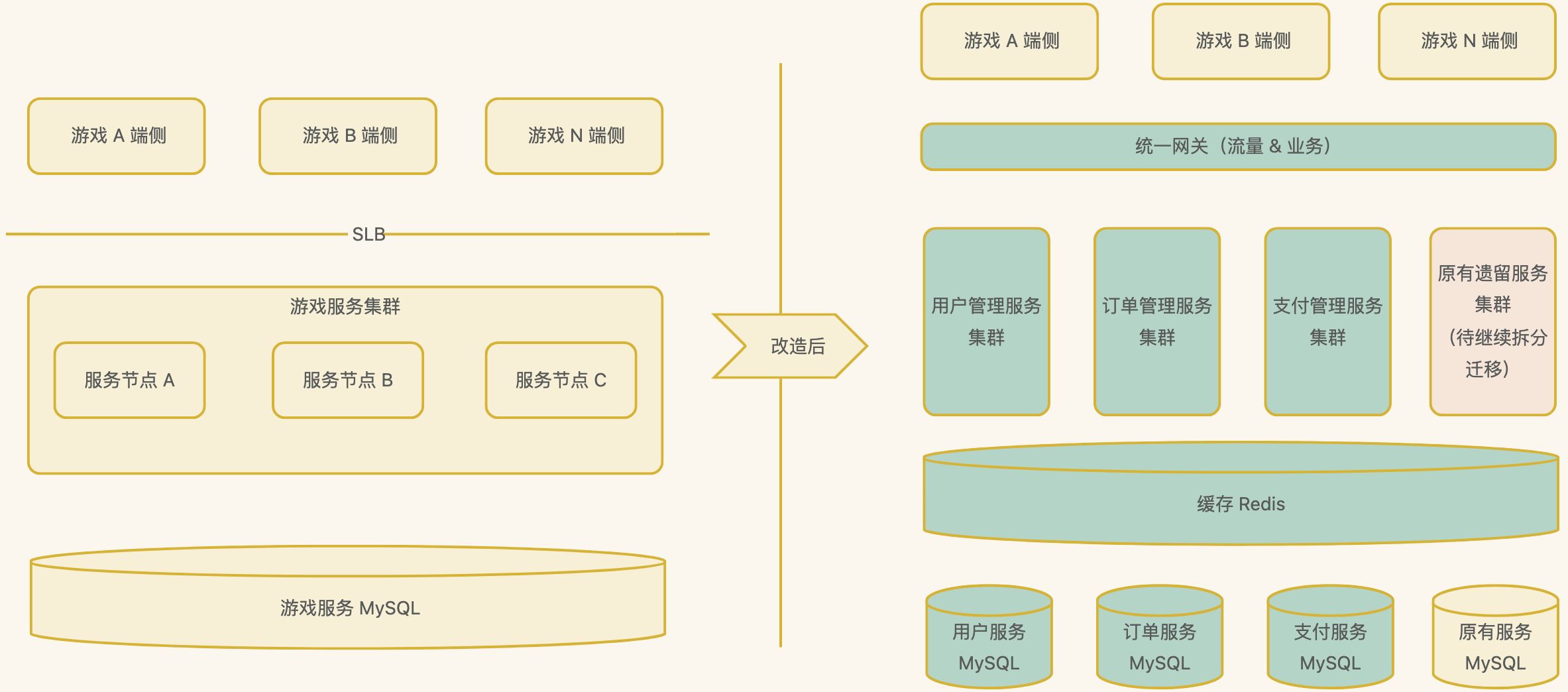
分布式系统架构设计之分布式系统实践案例和未来展望
分布式系统在过去的几十年里经历了长足的发展,从最初的简单分布式架构到今天的微服务、云原生等先进架构,取得了丰硕的成果。本文将通过实际案例分享分布式系统的架构实践,并展望未来可能的发展方向。 一、实践案例 1、微服务化实践 背景 …...
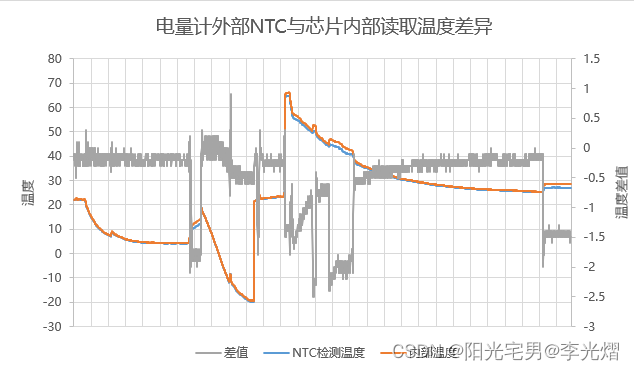
【办公软件】Excel双坐标轴图表
在工作中整理测试数据,往往需要一个图表展示两个差异较大的指标。比如共有三个数据,其中两个是要进行对比的温度值,另一个指标是两个温度的差值,这个差值可能很小。 举个实际的例子:数据如下所示,NTC检测温…...

彻底理解前端安全面试题(1)—— XSS 攻击,3种XSS攻击详解,建议收藏(含源码)
前言 前端关于网络安全看似高深莫测,其实来来回回就那么点东西,我总结一下就是 3 1 4,3个用字母描述的【分别是 XSS、CSRF、CORS】 一个中间人攻击。当然 CORS 同源策略是为了防止攻击的安全策略,其他的都是网络攻击。除了这…...

UE5.1_AI随机漫游
UE5.1_AI随机漫游 目录 UE5.1_AI随机漫游 AI随机漫游方法 方法1:AI角色蓝图直接写方法...
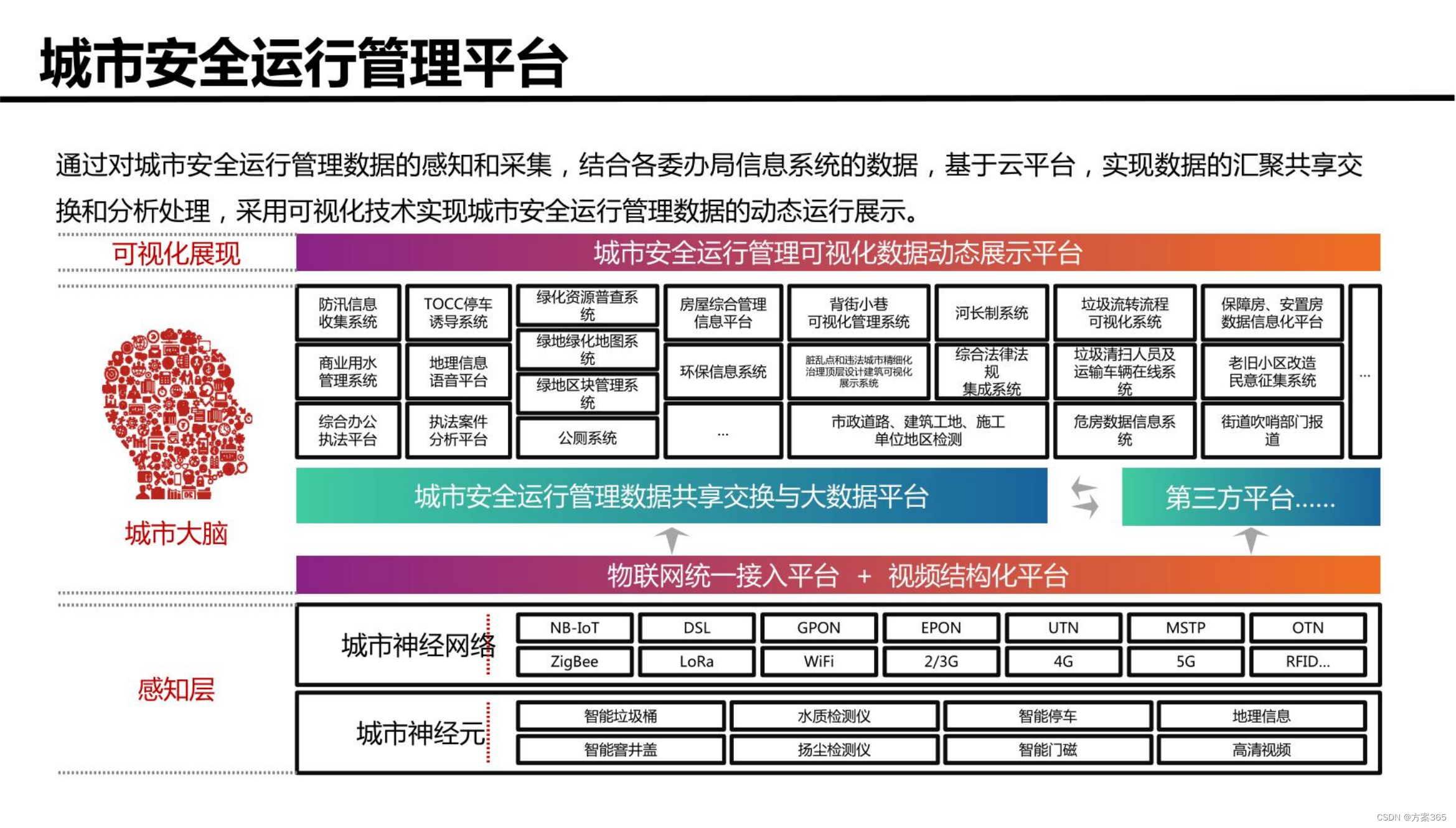
智慧城市新型基础设施建设综合方案:文件全文52页,附下载
关键词:智慧城市建设方案,智慧城市发展的前景和趋势,智慧城市项目方案,智慧城市管理平台,数字化城市,城市数字化转型 一、智慧城市新基建建设背景 1、城市化进程加速:随着城市化进程的加速&am…...

从Crustocean/conch看轻量级工作流编排:DAG原理与Python实现
1. 项目概述:从“Crustocean/conch”看现代数据管道编排的演进最近在梳理团队的数据处理流程时,我又一次被那些错综复杂的脚本、定时任务和手动依赖检查搞得焦头烂额。这让我想起了几年前第一次接触“Crustocean/conch”这个项目时的情景。当时ÿ…...
)
手把手教你用STC89C52单片机驱动DS1302时钟模块(附完整代码)
STC89C52与DS1302时钟模块实战指南:从硬件搭建到代码实现 1. 项目概述与硬件准备 在嵌入式系统开发中,实时时钟(RTC)功能是许多项目的核心需求。STC89C52作为经典的51系列单片机,与DS1302时钟模块的组合,为开发者提供了经济实惠且…...

JavaScript逆向工程的架构演进:Jsxer如何重新定义二进制脚本反编译
JavaScript逆向工程的架构演进:Jsxer如何重新定义二进制脚本反编译 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer 在Adobe创意生态系统中,ExtendScript脚本的JSXBIN二进制格…...

Linux多网卡主机路由检查方法
Linux多网卡主机路由检查方法多网卡主机在 Linux 环境中并不少见。它们可能用于业务隔离、管理面分离、双线接入、内外网分流或高可用部署。但多网卡也意味着更复杂的路由行为。很多“这台机器能 ping 通但服务异常”“流量出去后回不来”的问题,最终都与路由选择有…...

泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效
更多请点击: https://intelliparadigm.com 第一章:泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效 ElevenLabs 已于 2024 年 7 月 15 日正式发布 API v2.4.1ÿ…...

Cursor AI破解工具技术深度解析:如何实现设备标识重置与Pro功能永久激活
Cursor AI破解工具技术深度解析:如何实现设备标识重置与Pro功能永久激活 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve…...

缠论自动化分析终极指南:ChanlunX让复杂技术分析变得简单
缠论自动化分析终极指南:ChanlunX让复杂技术分析变得简单 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是否曾经面对复杂的K线图感到迷茫?是否想要掌握缠论分析却苦于手工绘制…...

终极解决方案:让苹果触控板在Windows上获得原生级精准触控体验
终极解决方案:让苹果触控板在Windows上获得原生级精准触控体验 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-tou…...

3分钟完成B站缓存视频转换:m4s-converter完整使用指南
3分钟完成B站缓存视频转换:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频下架后&…...

【模拟 IC】运放失调电压的成因剖析与版图优化策略
1. 运放失调电压的本质与影响 第一次接触运放失调电压这个概念时,我也被它搞得一头雾水。简单来说,失调电压就是理想运放和实际运放之间的"性格差异"。理想情况下,当两个输入端电压相等时,输出应该是零。但现实中&#…...