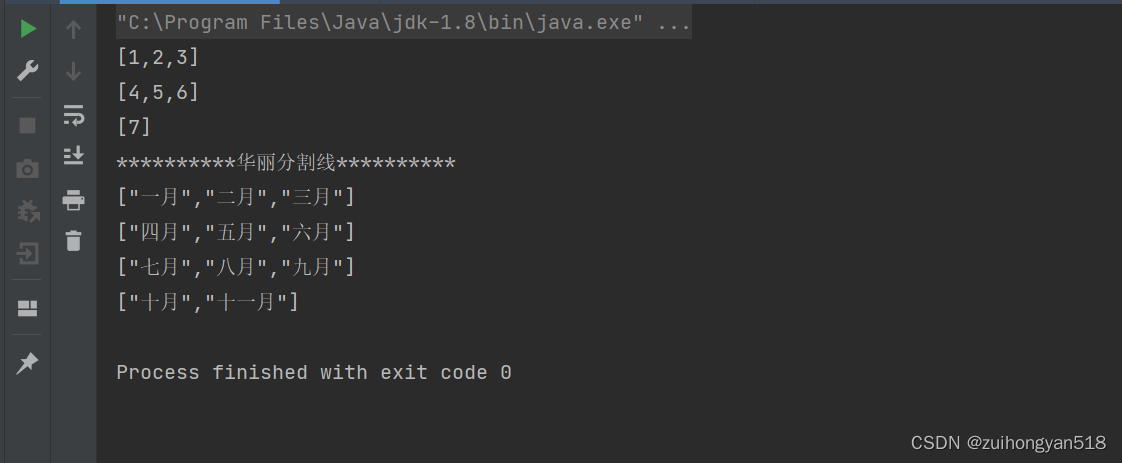
python测试工具: 实现数据源自动核对
测试业务需要:
现有A系统作为下游数据系统,上游系统有A1,A2,A3...
需要将A1,A2,A3...的数据达到某条件后(比如:A1系统销售单提交出库成功)自动触发MQ然后再经过数据清洗落到A系统,并将清洗后数据通过特定规则汇总在A系统报表中
现在需要QA同学验证的功能是:
A系统存储数据清洗后的库表(为切片表)有几十个,且前置系统较多,测试工作量也较多
需要核对清洗后A存库数据是否准确
清洗规则:(1)直接取数 (2)拼接取数 (3)映射取数
直接取数字段在2系统表中字段命名规则一致
so,以下测试工具是针对直接取数规则来开发,以便于测试
代码实现步骤:
(1)将表字段,来源系统表和切片表 数据库链接信息,查询字段 作为变量
将这些信息填入input.xlsx 作为入参


(2)读取表字段,根据来源系统表 数据库链接信息,查询字段
查询来源库表,将查询出字段值存储outfbi.xlsx
(3)读取表字段,根据切片表 数据库链接信息,查询字段
查询切片库表,将查询出字段值存储outods.xlsx
(4)对比outfbi.xlsx,outods.xlsx的字段值
对比后生成result.xlsx文件,新增列校验结果
核对字段值一致校验结果为Success,否则为Fail

代码如下:

入参文件见附件
DbcheckApi.py
import os
import pymysql
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
import datetime
import ast"""测试数据路径管理"""
SCRIPTS_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
GENERATECASE_DIR = os.path.join(SCRIPTS_DIR, "dbcheck")
inputDATAS_DIR = os.path.join(GENERATECASE_DIR, "inputdata")
outDATAS_DIR = os.path.join(GENERATECASE_DIR, "outdata")class DbcheckApi():def __init__(self,data):self.inputexcel=dataworkbook = load_workbook(filename=self.inputexcel)sheet = workbook['数据源']# 读取来源表-连接信息sourcedb_connection_info = ast.literal_eval(sheet['B3'].value)odsdb_connection_info = ast.literal_eval(sheet['B4'].value)source_db = sheet['C3'].value.strip()ods_db = sheet['C4'].value.strip()source_queryby = sheet['D3'].value.strip()ods_queryby = sheet['D4'].value.strip()print(sourcedb_connection_info)print(odsdb_connection_info)print(source_db)print(ods_db)print(source_queryby)print(ods_queryby)self.sourcedb = sourcedb_connection_infoself.odsdb = odsdb_connection_infoself.source_db = source_dbself.ods_db = ods_dbself.source_queryby = source_querybyself.ods_queryby = ods_querybydef source_select_db(self):host = self.sourcedb.get('host')port = self.sourcedb.get('port')user = self.sourcedb.get('user')passwd = self.sourcedb.get('passwd')db = self.sourcedb.get('db')if not host or not port or not user or not passwd or not db:error_msg = "连接信息不完整"return {"code": -1, "msg": error_msg, "data": ""}cnnfbi = pymysql.connect(host=host,port=port,user=user,passwd=passwd,db=db)cursor = cnnfbi.cursor()try:# 读取Excel文件df = pd.read_excel(self.inputexcel, sheet_name='Sheet1')# 获取第1列,从第2行开始读取的字段名fields = df.iloc[1:, 0].tolist()print(fields)# 构建查询SQL语句sql = "SELECT {} FROM {} WHERE {}".format(', '.join(fields), self.source_db, self.source_queryby)print(sql)# 执行查询语句cursor.execute(sql)except pymysql.err.OperationalError as e:error_msg = str(e)if "Unknown column" in error_msg:column_name = error_msg.split("'")[1]msg={"code": -1, "msg": f"列字段 {column_name} 在 "+self.source_db+" 表结构中不存在,请检查!", "data": ""}print(msg)return {"code": -1, "msg": f"列字段 {column_name} 在 "+self.source_db+" 表结构中不存在,请检查!", "data": ""}else:return {"code": -1, "msg": error_msg, "data": ""}print(error_msg)# 获取查询结果result = cursor.fetchall()# 关闭游标和连接cursor.close()cnnfbi.close()# 检查查询结果是否为空if not result:return {"code": -1, "msg": f"查询无数据,请检查sql: {sql}", "data": ""}else:# 将结果转换为DataFrame对象df = pd.DataFrame(result, columns=fields)odskey=self.source_db+'表-字段'odsvalue=self.source_db+'表-字段值'# 创建新的DataFrame对象,将字段和对应值放在两列df_new = pd.DataFrame({odskey: fields, odsvalue: df.iloc[0].values})outexcel = os.path.join(outDATAS_DIR, 'outputfbi.xlsx')# 导出结果到Excel文件df_new.to_excel(outexcel, index=False)def ods_select_db(self):host = self.odsdb.get('host')port = self.odsdb.get('port')user = self.odsdb.get('user')passwd = self.odsdb.get('passwd')db = self.odsdb.get('db')if not host or not port or not user or not passwd or not db:raise ValueError("连接信息不完整")cnnfbi = pymysql.connect(host=host,port=port,user=user,passwd=passwd,db=db)cursor = cnnfbi.cursor()try:# 读取Excel文件df = pd.read_excel(self.inputexcel, sheet_name='Sheet1')# 获取第1列,从第2行开始读取的字段名fields = df.iloc[1:, 0].tolist()print(fields)# 构建查询SQL语句sql = "SELECT {} FROM {} WHERE {}".format(', '.join(fields), self.ods_db, self.ods_queryby)print(sql)# 执行查询语句cursor.execute(sql)except pymysql.err.OperationalError as e:error_msg = str(e)if "Unknown column" in error_msg:column_name = error_msg.split("'")[1]return {"code": -1, "msg": f"列 {column_name} 不存在"+self.ods_db+" 表结构中,请检查!", "data": ""}else:return {"code": -1, "msg": error_msg, "data": ""}# 获取查询结果result = cursor.fetchall()# 关闭游标和连接cursor.close()cnnfbi.close()# 将结果转换为DataFrame对象df = pd.DataFrame(result, columns=fields)# 创建新的DataFrame对象,将字段和对应值放在两列odskey=self.ods_db+'表-字段'odsvalue=self.ods_db+'表-字段值'df_new = pd.DataFrame({odskey: fields, odsvalue: df.iloc[0].values})# 导出结果到Excel文件outexcel = os.path.join(outDATAS_DIR, 'outputfms.xlsx')df_new.to_excel(outexcel, index=False)def check_order(self):self.source_select_db()self.ods_select_db()outputfbi = os.path.join(outDATAS_DIR, 'outputfbi.xlsx')outputfms = os.path.join(outDATAS_DIR, 'outputfms.xlsx')df_a = pd.read_excel(outputfbi)df_b = pd.read_excel(outputfms)# 创建新的DataFrame对象用于存储C表的数据df_c = pd.DataFrame()# 将A表的列写入C表for col in df_a.columns:df_c[col] = df_a[col]# 将B表的列���入C表for col in df_b.columns:df_c[col] = df_b[col]odsvalue=self.ods_db+'表-字段值'fbivalue=self.source_db+'表-字段值'# 比对A2和B2列的值,如果不一致,则在第5列写入"校验失败"df_c['校验结果'] = ''for i in range(len(df_c)):if pd.notnull(df_c.at[i, fbivalue]) and pd.notnull(df_c.at[i, odsvalue]):fbivalue_rounded = df_c.at[i, fbivalue]odsvalue_rounded = df_c.at[i, odsvalue]if isinstance(fbivalue_rounded, (int, float)):fbivalue_rounded = round(fbivalue_rounded, 3)elif isinstance(fbivalue_rounded, datetime.datetime):fbivalue_rounded = round(fbivalue_rounded.timestamp(), 3)else:try:fbivalue_rounded = round(float(fbivalue_rounded), 3)except ValueError:passif isinstance(odsvalue_rounded, (int, float)):odsvalue_rounded = round(odsvalue_rounded, 3)elif isinstance(odsvalue_rounded, datetime.datetime):odsvalue_rounded = round(odsvalue_rounded.timestamp(), 3)else:try:odsvalue_rounded = round(float(odsvalue_rounded), 3)except ValueError:passif fbivalue_rounded != odsvalue_rounded:df_c.at[i, '校验结果'] = 'Fail'else:df_c.at[i, '校验结果'] = 'Success'# 将结果写入到C.xlsx文件df_c.to_excel('checkhead_result.xlsx', index=False)# 打开C.xlsx文件并设置背景色book = load_workbook('checkhead_result.xlsx')writer = pd.ExcelWriter('checkhead_result.xlsx', engine='openpyxl')writer.book = book# 获取C.xlsx的工作表sheet_name = 'Sheet1'ws = writer.book[sheet_name]# 设置背景色为红色red_fill = PatternFill(start_color='FFFF0000', end_color='FFFF0000', fill_type='solid')# 遍历校验结果列,将不一致的单元格设置为红色背景for row in ws.iter_rows(min_row=2, min_col=len(df_c.columns), max_row=len(df_c), max_col=len(df_c.columns)):for cell in row:if cell.value == 'Fail':cell.fill = red_fill# 保存Excel文件writer.save()writer.close()if __name__ == '__main__':inputexcel = os.path.join(inputDATAS_DIR, 'input.xlsx')DbcheckApi(inputexcel).check_order()相关文章:
python测试工具: 实现数据源自动核对
测试业务需要: 现有A系统作为下游数据系统,上游系统有A1,A2,A3... 需要将A1,A2,A3...的数据达到某条件后(比如:A1系统销售单提交出库成功)自动触发MQ然后再经过数据清洗落到A系统,并将清洗后数据通过特定…...
要学习openfoam,c++需要掌握到什么程度?
要学习openfoam,c需要掌握到什么程度? 在开始前我有一些资料,是我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「c的资料从专业入门到高级教程工具包」,点个关注,全部无偿共享给大家&…...

web一些实验代码——Servlet请求与响应
实验4:Servlet请求与响应 1、在页面输入学生学号,从数据库中查询学生信息并显示。 (1)启动MySQL数据库服务,新建数据库,将student.sql文件导入到新建数据库(建立表,并插入3条数据&…...
GPT系列概述
OPENAI做的东西 Openai老窝在爱荷华州,微软投资的数据中心 万物皆可GPT下咱们要失业了? 但是世界不仅仅是GPT GPT其实也只是冰山一角,2022年每4天就有一个大型模型问世 GPT历史时刻 GPT-1 带回到2018年的NLP 所有下游任务都需要微调&#x…...

基于遗传算法的集装箱吊装优化,基于遗传算法的集装箱装卸优化
目录 背影 遗传算法的原理及步骤 基本定义 编码方式 适应度函数 运算过程 代码 结果分析 完整代码下载: 基于遗传算法的集装箱吊装优化,基于遗传算法的集装箱装卸优化(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88674652 背影 …...

postgreSQL单机部署
一、环境准备 架构操作系统IP主机名PG版本端口磁盘空间内存CPUsingle 单机centos7192.168.1.10pgserver01PostgreSQL 14.7543350G4G2 1、官网下载源码包 https://www.postgresql.org/download/2、操作系统参数修改 2.1 sysctl.conf配置 vi /etc/sysctl.conf kernel.sysrq …...

思维逻辑题3
题目1: 如果所有A都是B,且某个对象是B,那么它一定是A吗? 答案:不一定,尽管所有A都是B,但还有其他的对象可能也是B。 题目2: 如果A和B都是真,那么以下哪个选项是真&…...

强大的音乐乐谱控件库
2023 Conmajia, 2018 Ajcek84 SN: 23C.1 本中文翻译已获原作者首肯。 简介 PSAM 控件库——波兰音乐文档系统——是用于显示、排版乐谱的强大 WinForm 库,包含用于绘制乐谱的名为 IncipitViewer 控件,乐谱内容可以从 MusicXml 文件读取,或者…...
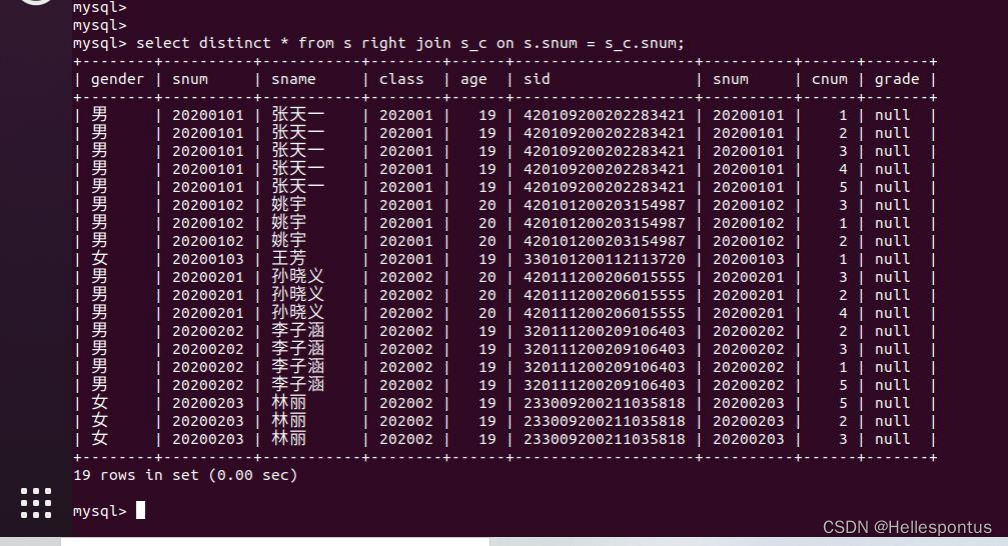
数据库——简单查询复杂查询
1.实验内容及原理 1. 在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,并在 Ubuntu 中搭建 LAMP 实验环境。 2. 使用 MySQL 进行一些基本操作: (1)登录 MySQL,在 MySQL 中创建用户,…...
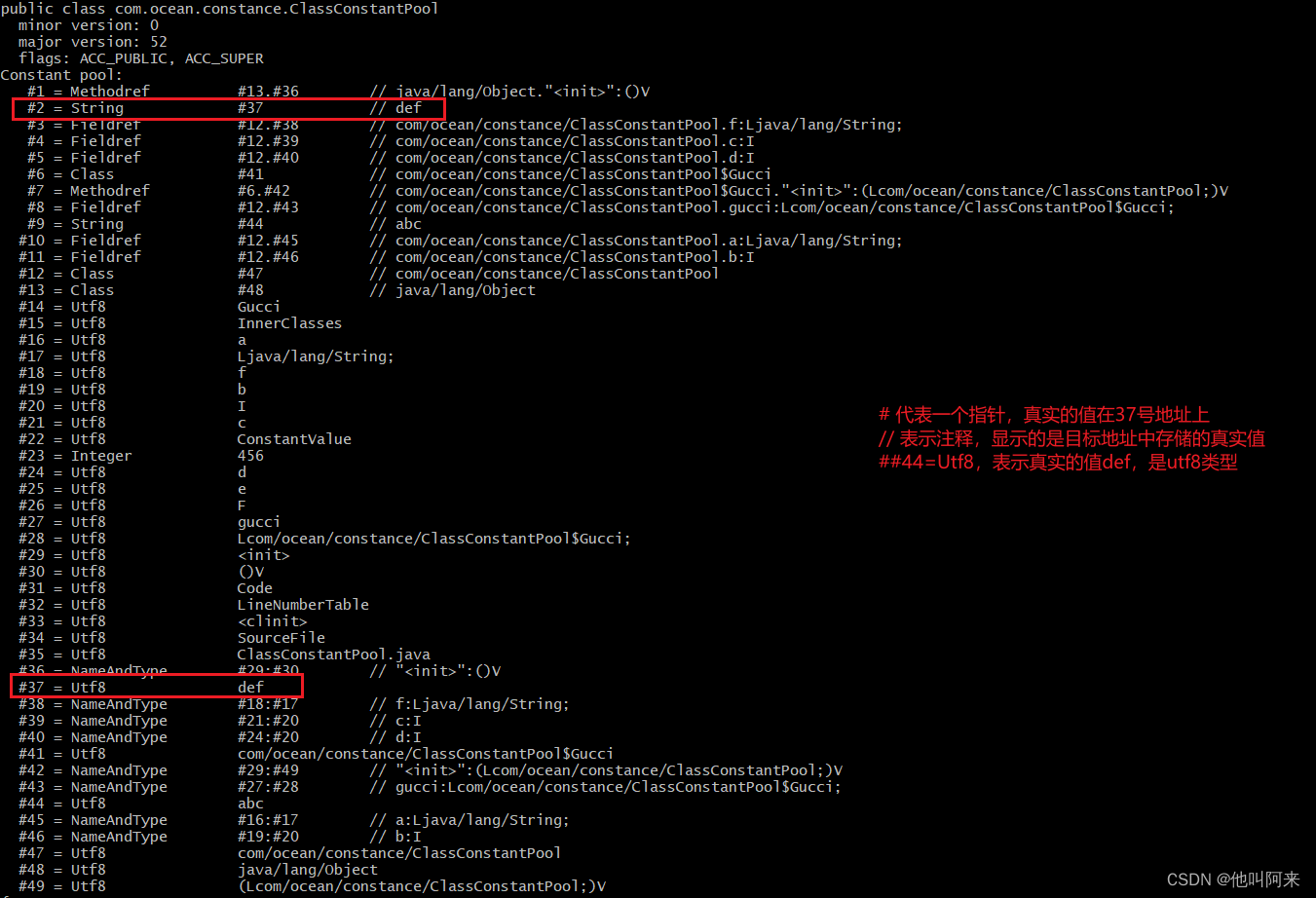
java虚拟机内存管理
文章目录 概要一、jdk7与jdk8内存结构的差异二、程序计数器三、虚拟机栈3.1 什么是虚拟机栈3.2 什么是栈帧3.3 栈帧的组成 四、本地方法栈五、堆5.1 堆的特点5.2 堆的结构5.3 堆的参数配置 六、方法区6.1 方法区结构6.2 运行时常量池 七、元空间 概要 根据 JVM 规范࿰…...
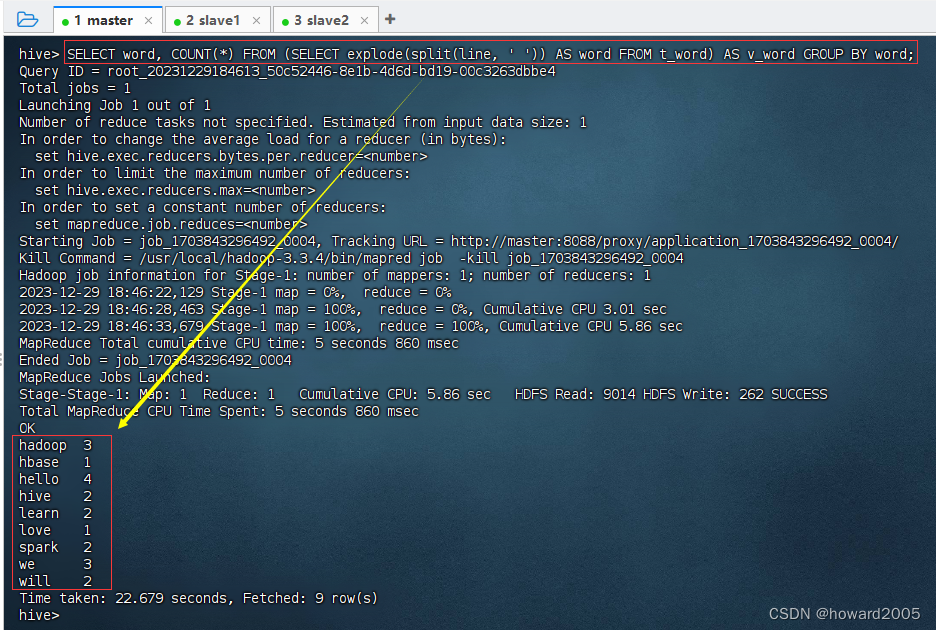
Hive实战:词频统计
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS文件创建外部表4、查询单词表&a…...
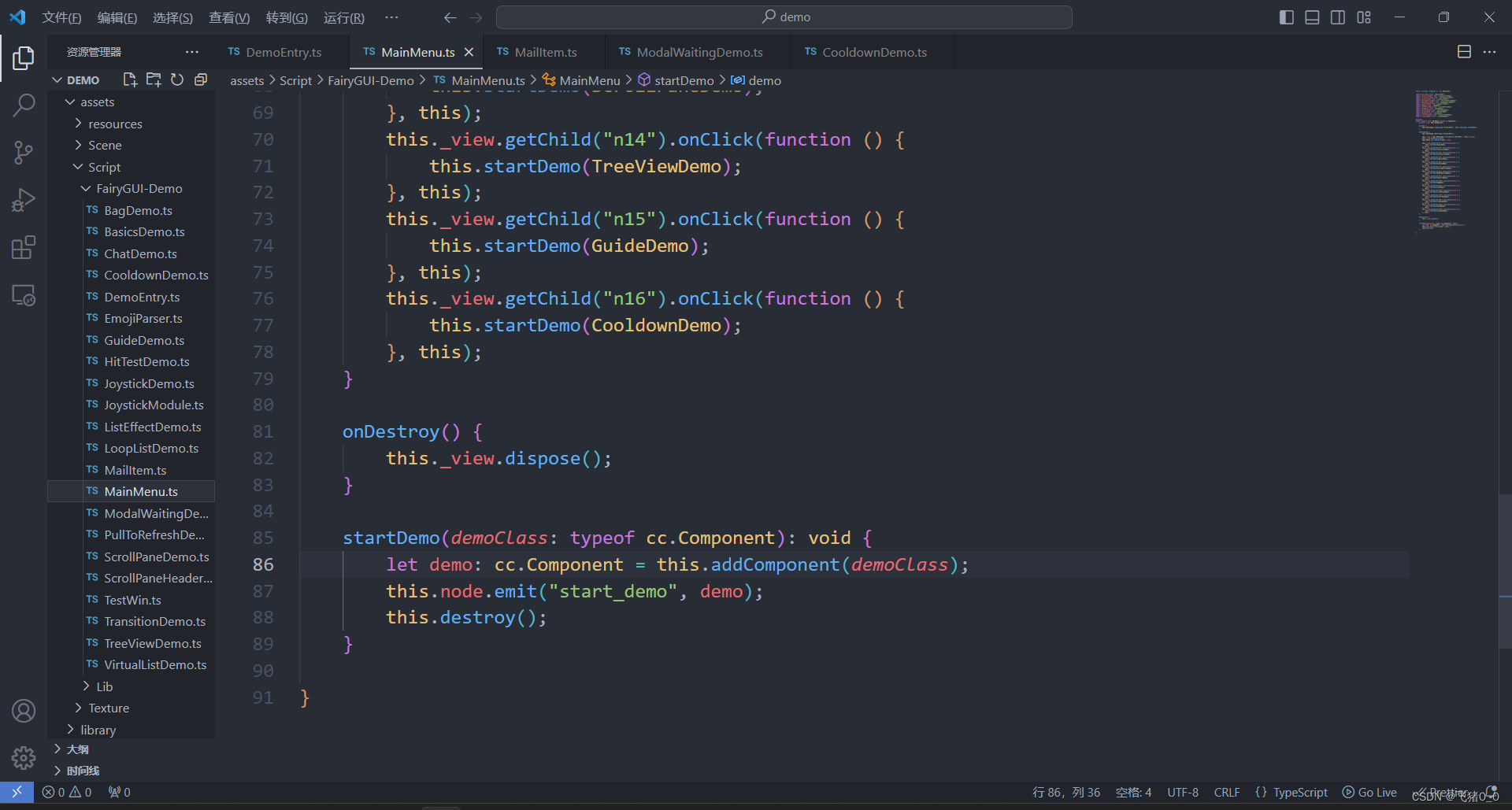
FairyGUI-Cocos Creator官方Demo源码解读
博主在学习Cocos Creator的时候,发现了一款免费的UI编辑器FairyGUI。这款编辑器的能力十分强大,但是网上的学习资源比较少,坑比较多,主要学习方式就是阅读官方文档和练习官方Demo。这里博主进行官方Demo的解读。 从gitee上克隆项目…...
LabVIEW利用视觉引导机开发器人精准抓取
LabVIEW利用视觉引导机开发器人精准抓取 本项目利用单目视觉技术指导多关节机器人精确抓取三维物体的技术。通过改进传统的相机标定方法,结合LabVIEW平台的Vision Development和Vision Builder forAutomated Inspection组件,优化了摄像系统的标定过程&a…...

【Linux】指令(本人使用比较少的)——笔记(持续更新)
文章目录 ps -axj:查看进程ps -aL:查看线程echo $?:查看最近程序的退出码jobs:查看后台运行的线程组fd 任务号:将后台任务提到前台bg 任务号:将暂停的后台程序重启netstat -nltp:查看服务及监听…...

032 - STM32学习笔记 - TIM基本定时器(一) - 定时器基本知识
032 - STM32学习笔记 - TIM定时器(一) - 基本定时器知识 这节开始学习一下TIM定时器功能,从字面意思上理解,定时器的基本功能就是用来定时,与定时器相结合,可以实现一些周期性的数据发送、采集等功能&#…...
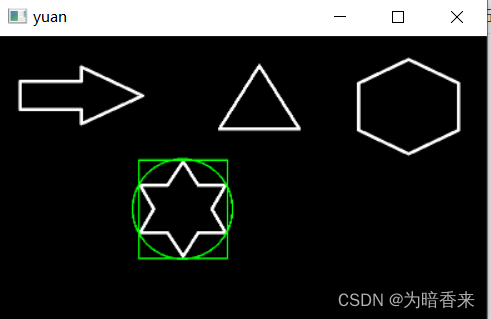
轮廓检测与处理
轮廓检测 先将图像转换成二值 gray cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 灰度图 ret, thresh cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) # 变为二值,大于127置为255,小于100置为0.使用cv2.findContours(thresh, cv2.RETR_TREE, cv2.…...

跟着LearnOpenGL学习11--材质
文章目录 一、材质二、设置材质三、光的属性四、不同的光源颜色 一、材质 在现实世界里,每个物体会对光产生不同的反应。 比如,钢制物体看起来通常会比陶土花瓶更闪闪发光,一个木头箱子也不会与一个钢制箱子反射同样程度的光。 有些物体反…...
Java guava partition方法拆分集合自定义集合拆分方法
日常开发中,经常遇到拆分集合处理的场景,现在记录2中拆分集合的方法。 1. 使用Guava包提供的集合操作工具栏 Lists.partition()方法拆分 首先,引入maven依赖 <dependency><groupId>com.google.guava</groupId><artifa…...
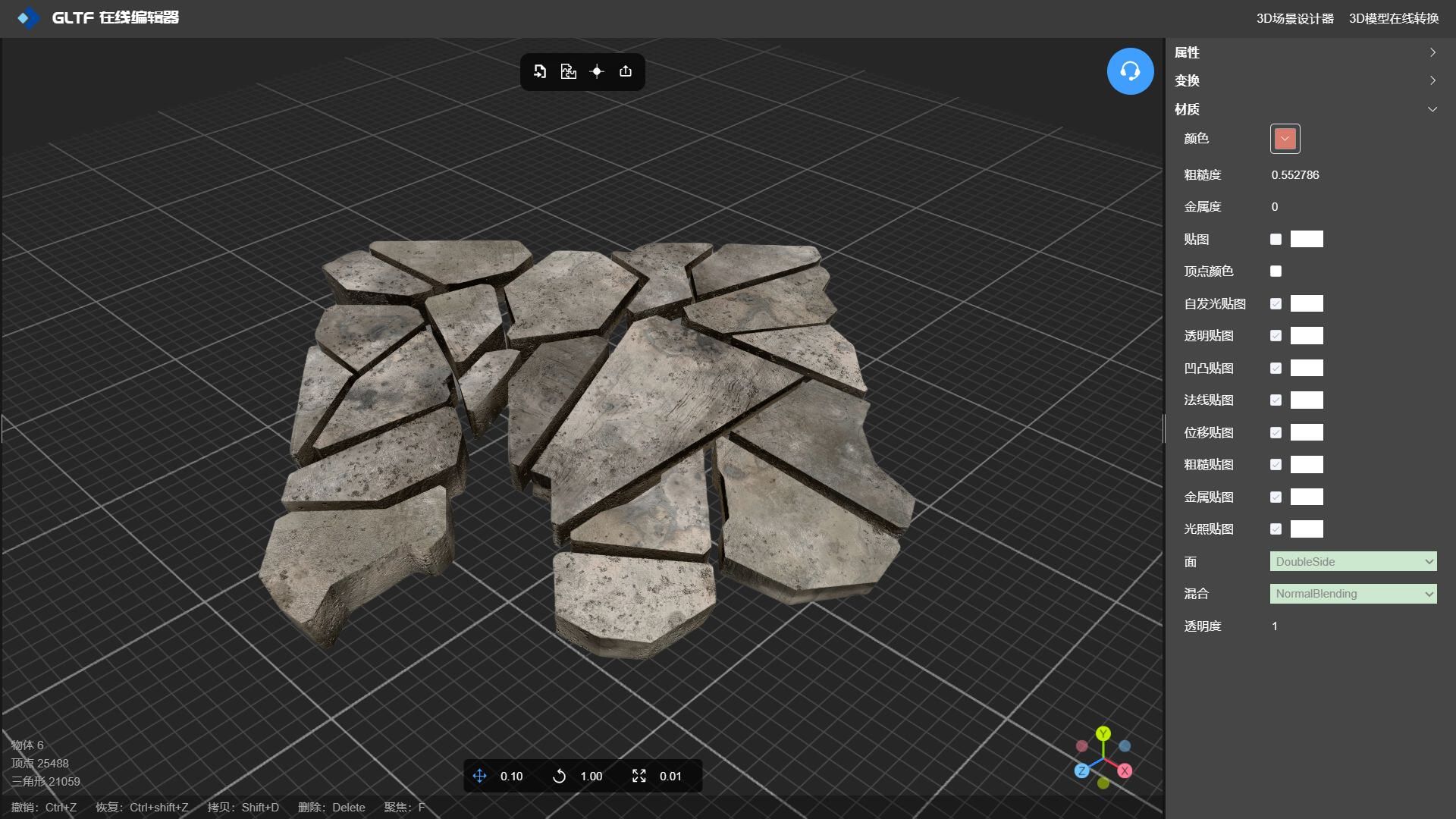
GLTF编辑器-位移贴图实现破碎的路面
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 位移贴图是一种可以用于增加模型细节和形状的贴图。它能够在渲染时针…...

多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测
多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-BiLSTM麻雀算法优化双向长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现SSA-BiLSTM麻雀算法优化…...

从2013年俄罗斯科技路演看技术商业化:硬件集成、异构计算与生态挑战
1. 项目概述:一次被遗忘的科技路演及其启示2013年秋天,在硅谷的心脏圣克拉拉,发生了一场如今看来颇具历史意味的科技路演。俄罗斯,这个在世人印象中与能源、重工业紧密相连的国家,派出了一支由政府和产业界高层领衔的代…...

破解大规模3D地理空间数据转换瓶颈:5大技术突破实现10倍性能提升
破解大规模3D地理空间数据转换瓶颈:5大技术突破实现10倍性能提升 【免费下载链接】3d-tiles-tools 项目地址: https://gitcode.com/gh_mirrors/3d/3d-tiles-tools 行业痛点:当3D数据量级遭遇技术天花板 在数字孪生、智慧城市和地理信息系统领域…...

解锁HexView自动化:Bat脚本驱动S19/HEX文件处理实战
1. 为什么需要自动化处理S19/HEX文件 在汽车电子开发领域,我们经常需要处理各种固件文件,比如S19、HEX等格式。这些文件包含了嵌入式系统的机器代码,是软件最终要烧录到芯片中的形态。每次软件更新时,开发人员都要对这些文件进行一…...

Nucleus MCP:构建AI智能体标准化工具层的核心架构与实践
1. 项目概述:一个为AI智能体打造的“工具箱”中枢最近在折腾AI智能体(Agent)开发的朋友,可能都遇到过类似的困境:你有一个绝佳的想法,想让AI去调用某个API、查询数据库,或者操作一个本地工具。你…...

Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力
Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

魔兽争霸3终极优化:WarcraftHelper让你的经典游戏在现代电脑上焕然新生
魔兽争霸3终极优化:WarcraftHelper让你的经典游戏在现代电脑上焕然新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3…...
)
手把手教你用STM32G030F6P6的HAL库模拟SPI点亮1.8寸ST7735屏(附完整代码)
从零开始:STM32G030F6P6 HAL库模拟SPI驱动ST7735屏幕实战指南 刚拿到STM32G030F6P6这款性价比爆表的MCU时,我第一反应就是找块屏幕来验证它的性能。1.8寸ST7735驱动的TFT屏是个不错的选择——价格低廉、接口简单,但官方例程往往不够友好。本文…...

ArchivePasswordTestTool:5分钟掌握加密压缩包密码恢复的智能方案
ArchivePasswordTestTool:5分钟掌握加密压缩包密码恢复的智能方案 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾因遗…...

终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案
终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

ClawdOS:为AI Agent构建可视化操作系统的全栈实践
1. 项目概述:为你的AI大脑装上眼睛和手如果你和我一样,是OpenClaw(前身是Moltbot/Clawdbot)的早期用户,那你一定经历过这种场景:在终端里,你的AI助手聪明绝顶,能写代码、查资料、分析…...