AI客服的评分机制及自动化测试
智能客服的评分机制及自动化测试
使用pytest来编写智能客服的测试框架:
- 准备一个CSV文件来存储测试用例和预期结果。
- 编写测试脚本,其中包含测试用例的读取、发送请求、评分逻辑和结果验证。
- 使用
pytest断言来验证测试结果。
首先安装pytest和requests库:
pip install pytest requests
创建一个CSV文件test_cases.csv,它包含示例测试用例:
#问题,预期回复
"已付款,啥时候发货?","你好,系统在24小时内发顺丰快递的"
"麻烦尽快发货!","你好,已为您加急发货~"
"最晚几号发货?","你好,系统最晚在24小时内发顺丰快递的"
"用什么快递发货?","你好,默认是发顺丰快递"...
然后编写测试脚本test_ai_responses.py
import csv
import requests
import pytest# 假设的AI服务的URL
AI_SERVICE_URL = "http://192.168.1.100:8888/query"# 函数用于发送查询到AI服务
def send_query_to_ai(query):response = requests.post(AI_SERVICE_URL, json={"query": query})if response.status_code == 200:return response.json().get('response', '')else:# 在真实测试中,这里应该处理错误情况return None# 评分函数,这里使用简单的字符串相等进行评分
def score_response(ai_response, expected_response):return ai_response.strip().lower() == expected_response.strip().lower()# 读取CSV文件并构建测试用例
def read_test_cases(csv_file):test_cases = []with open(csv_file, newline='', encoding='utf-8') as csvfile:reader = csv.DictReader(csvfile)for row in reader:test_cases.append((row['query'], row['expected_response']))return test_cases# 参数化测试用例
test_data = read_test_cases('test_cases.csv')@pytest.mark.parametrize("query,expected_response", test_data)
def test_ai_response(query, expected_response):# 发送查询并获取AI系统的响应ai_response = send_query_to_ai(query)# 断言AI的响应是否与预期相符assert score_response(ai_response, expected_response), f"Query: {query}, Expected: {expected_response}, Got: {ai_response}"
代码解析:
-
上面定义了一个
send_query_to_ai函数来发送查询到AI客服系统,并获取响应。
我们还定义了一个score_response函数来评分响应。
read_test_cases函数从CSV文件中读取测试用例,并以适合pytest参数化测试的格式返回它们。 -
最后用
pytest.mark.parametrize装饰器来参数化test_ai_response函数,这样pytest就会为CSV文件中的每个测试用例运行一个测试。
在命令行中执行pytest命令。
pytest test_ai_responses.py
总结:以上实现了一个简单的评分机制:检查字符串是否完全匹配。
下面,来点硬货,实现更复杂的、更科学有效的评分机制:
评估响应的语义相似度,一般有2个方法:
- 使用词嵌入(如Word2Vec、GloVe或BERT)来将文本转换为向量,然后计算这些向量之间的
余弦相似度。 - 使用专门的评估指标,如
BLEU(双语评估底线),这个常用在机器翻译领域。其实还有一个方案(偷懒~)是直接调用语言模型(如GPT-3或BERT)来进行语义相似度评分。
- 余弦相似度是一种计算两个非零向量夹角余弦值的度量,它可以用来评估文本向量的相似性。
- BLEU(BiLingual Evaluation Understudy)分数则通过比较机器翻译的输出和一组参考翻译来评估质量,计算n-gram的重叠度。BLEU主要关注准确性,它计算了几个不同大小的n-gram(通常是1到4)的精确匹配,并通过考虑最长的匹配序列来惩罚过短的生成句子。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分数和BLEU都是常用于评估自然语言生成系统的指标,尤其在机器翻译和文本摘要领域。ROUGE评估自动文本摘要时更关注召回率,即参考摘要中的n-gram有多少被生成摘要所覆盖。ROUGE有多个变体,如ROUGE-N(考虑n-gram重叠)、ROUGE-L(考虑最长公共子序列)等。
步骤 1: 安装所需的库
我们需要安装一些NLP库,如transformers和sentence-transformers,以及scikit-learn来计算余弦相似度。
pip install transformers sentence-transformers scikit-learn
步骤 2: 编写评分逻辑
我们将使用Hugging Face的transformers库来获取预训练的BERT模型的句子嵌入,然后使用scikit-learn来计算余弦相似度。
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity# 加载预训练的句子嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')def calculate_cosine_similarity(response1, response2):# 将文本转换为向量embeddings = model.encode([response1, response2])# 计算向量之间的余弦相似度cosine_sim = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]return cosine_simdef score_response(ai_response, expected_response):# 计算余弦相似度similarity_score = calculate_cosine_similarity(ai_response, expected_response)# 可以设置阈值来确定是否接受响应return similarity_score在测试框架中加入BLEU和ROUGE分数计算方法
安装nltk和rouge-score库:
pip install nltk rouge-score
然后,更新测试脚本以包括BLEU和ROUGE评分:
import nltk
from rouge_score import rouge_scorer
from nltk.translate.bleu_score import sentence_bleu# nltk下载器需要的数据
nltk.download('punkt')def calculate_bleu_score(candidate, reference):# 分词candidate_tokens = nltk.word_tokenize(candidate)reference_tokens = nltk.word_tokenize(reference)# 计算BLEU分数score = sentence_bleu([reference_tokens], candidate_tokens)return scoredef calculate_rouge_score(candidate, reference):# 初始化ROUGE评分器scorer = rouge_scorer.RougeScorer(['rouge1', 'rougeL'], use_stemmer=True)# 计算ROUGE分数scores = scorer.score(reference, candidate)return scores# ...其他测试代码保持不变...@pytest.mark.parametrize("query,expected_response", test_data)
def test_ai_response(query, expected_response):# 发送查询并获取AI系统的响应ai_response = send_query_to_ai(query)# 计算BLEU分数bleu_score = calculate_bleu_score(ai_response, expected_response)# 计算ROUGE分数rouge_scores = calculate_rouge_score(ai_response, expected_response)# 断言BLEU分数和ROUGE分数是否满足预期assert bleu_score > 0.5, f"Query: {query}, Expected: {expected_response}, Got: {ai_response}, BLEU: {bleu_score}"assert rouge_scores['rouge1'].fmeasure > 0.5, f"Query: {query}, Expected: {expected_response}, Got: {ai_response}, ROUGE-1: {rouge_scores['rouge1'].fmeasure}"assert rouge_scores['rougeL'].fmeasure > 0.5, f"Query: {query}, Expected: {expected_response}, Got: {ai_response}, ROUGE-L: {rouge_scores['rougeL'].fmeasure}"
前面定义了两个函数calculate_bleu_score和calculate_rouge_score来计算BLEU和ROUGE分数。然后,在测试函数test_ai_response中,我们计算这些分数并使用assert语句来检查它们是否满足预设的阈值。请注意,BLEU和ROUGE分数的阈值(在这里假设为0.5)应该根据实际情况进行调整。这些阈值可以通过对历史数据的分析来确定,以确保它们反映出对系统性能的实际期望。此外,BLEU和ROUGE分数对于某些类型的响应可能不够灵敏,因此应该结合其他评估方法使用。
步骤 3: 更新测试脚本
更新上面的test_ai_responses.py脚本,修改为最新评分逻辑。
# ...其他代码保持不变...@pytest.mark.parametrize("query,expected_response", test_data)
def test_ai_response(query, expected_response):# 发送查询并获取AI系统的响应ai_response = send_query_to_ai(query)# 计算余弦相似度similarity_score = calculate_cosine_similarity(ai_response, expected_response)# 断言相似度得分是否高于设定的阈值# 余弦相似度是一种常用的度量文本相似度的方法,但它可能不足以捕捉所有语义差异,因此我们设置了一个阈值来判断响应是否足够接近预期。assert similarity_score > 0.7, f"Query: {query}, Expected: {expected_response}, Got: {ai_response}, Similarity: {similarity_score}"
相似度阈值的设计
- 实际应用中需要根据具体情况调整相似度阈值或考虑其他评分机制,比如结合BLEU分数或ROUGE分数。
重新运行测试
使用pytest运行测试,对比结果
pytest test_ai_responses.py
写在最后:自动化测试无法完全替代人工评审,特别是在处理复杂、开放式的用户查询时。但自动化测试结合人工评审可以大大提升效率,更好地保障AI智能客服的回答质量。
相关文章:

AI客服的评分机制及自动化测试
智能客服的评分机制及自动化测试 使用pytest来编写智能客服的测试框架: 准备一个CSV文件来存储测试用例和预期结果。编写测试脚本,其中包含测试用例的读取、发送请求、评分逻辑和结果验证。使用pytest断言来验证测试结果。 首先安装pytest和requests库…...
【Matlab】ELM极限学习机时序预测算法
资源下载: https://download.csdn.net/download/vvoennvv/88681649 一,概述 ELM(Extreme Learning Machine)是一种单层前馈神经网络结构,与传统神经网络不同的是,ELM的隐层神经元权重以及偏置都是随机产生的…...
m3u8网络视频文件下载方法
在windows下,使用命令行cmd的命令下载m3u8视频文件并保存为mp4文件。 1.下载ffmpeg,访问FFmpeg官方网站:https://www.ffmpeg.org/进行下载 ffmpeg下载,安装,操作说明 https://blog.csdn.net/m0_53157282/article/det…...
相机内参标定理论篇------张正友标定法
一、为什么做相机标定? 标定是为了得到相机坐标系下的点和图像像素点的映射关系,为摄影几何、计算机视觉等应用做准备。 二、为什么需要张正友标定法? 张正友标定法使手工标定相机成为可能,使相机标定不再需要精密的设备帮助。…...
鸿蒙 Window 环境的搭建
鸿蒙操作系统是国内自研的新一代的智能终端操作系统,支持多种终端设备部署,能够适配不同类别的硬件资源和功能需求。是一款面向万物互联的全场景分布式操作系统。 下载、安装与配置 DevEco Studio支持Windows系统和macOS系统 Windows系统配置华为官方推…...

新一代大语言模型在Amazon Bedrock引领人工智能潮流
亚马逊Bedrock平台推出全新Amazon Titan大语言模型,为大型数据集预处理提供强大支持。亚马逊云科技开发者大会演讲重点介绍了Amazon Titan在文本大语言模型领域的创新,以及如何通过Bedrock平台实现定制化应用。 亚马逊Bedrock平台的主要产品经理Brent S…...

kafka实现延迟消息
背景 我们知道消息中间件mq是支持延迟消息的发送功能的,但是kafka不支持这种直接的用法,所以我们需要独立实现这个功能,以下是在kafka中实现消息延时投递功能的一种方案 kafka实现延时消息 主要的思路是增加一个检测服务,这个检…...
python+django高校教材共享管理系统PyCharm 项目
本中原工学院教材共享平台采用的数据库是mysql,使用nodejs技术开发。在设计过程中,充分保证了系统代码的良好可读性、实用性、易扩展性、通用性、便于后期维护、操作方便以及页面简洁等特点。系统所要实现的功能分析,对于现在网络方便的管理&…...

三子棋(c语言)
前言: 三子棋是一种民间传统游戏,又叫九宫棋、圈圈叉叉棋、一条龙、井字棋等。游戏规则是双方对战,双方依次在9宫格棋盘上摆放棋子,率先将自己的三个棋子走成一条线就视为胜利。但因棋盘太小,三子棋在很多时候会出现和…...

09.kubernetes 部署calico / flannel网络插件
脚本中实现了 calico 和 flannel 这两种主流的网络插件,选择其中一种部署即可 1、calico calico架构 Calico是一个三层的虚拟网络解决方案,它把每个节点都当作虚拟路由器(vRouter),并把每个节点上的Pod都当作是节点路由器后的一个终端设备并为其分配一个IP地址。各节点…...
【DevOps 工具链】搭建 项目管理软件 禅道
文章目录 1、简介2、环境要求3、搭建部署环境3.1. 安装Apache服务3.2. 安装PHP环境(以php7.0为例 )3.3. 安装MySQL服务 4、搭建禅道4.1、下载解压4.2、 配置4.2.1、 启动4.2.2、自启动4.2.3、确认是否开机启动 5、成功安装 1、简介 禅道是国产开源项目管…...

ES6的默认参数和rest参数
✨ 专栏介绍 在现代Web开发中,JavaScript已经成为了不可或缺的一部分。它不仅可以为网页增加交互性和动态性,还可以在后端开发中使用Node.js构建高效的服务器端应用程序。作为一种灵活且易学的脚本语言,JavaScript具有广泛的应用场景&#x…...

深入理解WPF MVVM:探索数据绑定与命令的优雅之道
引言: WPF(Windows Presentation Foundation)是一种用于创建富客户端应用程序的框架,而MVVM(Model-View-ViewModel)则是一种在WPF中使用的架构模式。MVVM提供了一种优雅的方式来组织和管理应用程序的代码&a…...
ssrf之gopher协议的使用和配置,以及需要注意的细节
gopher协议 目录 gopher协议 (1)安装一个cn (2)使用Gopher协议发送一个请求,环境为:nc起一个监听,curl发送gopher请求 (3)使用curl发送http请求,命令为 …...
SVN下载安装(服务器与客户端)
1.下载 服务器下载:Download | VisualSVN Server 客户端下载:自行查找 2. 服务器安装 双击执行 运行 下一步 同意下一步 下一步 选中安装目录 3. 客户端安装 双击执行 下一步 4. 服务器创建仓库 5. 服务器创建用户 6. 客户端获取资源 文件夹右键...

SpringIOC之ApplicationObjectSupport
博主介绍:✌全网粉丝5W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...

香橙派 ubuntu实现打通内网,外网双网络,有线和无线双网卡
当香橙派 ubuntu 连了有线,和无线时,默认请求外网时,只走一个网卡,如走了内网网卡,就只能访问内访问,访问不了外网;走了外网网卡就只能访问外网,访问不了内网; 实现双网…...
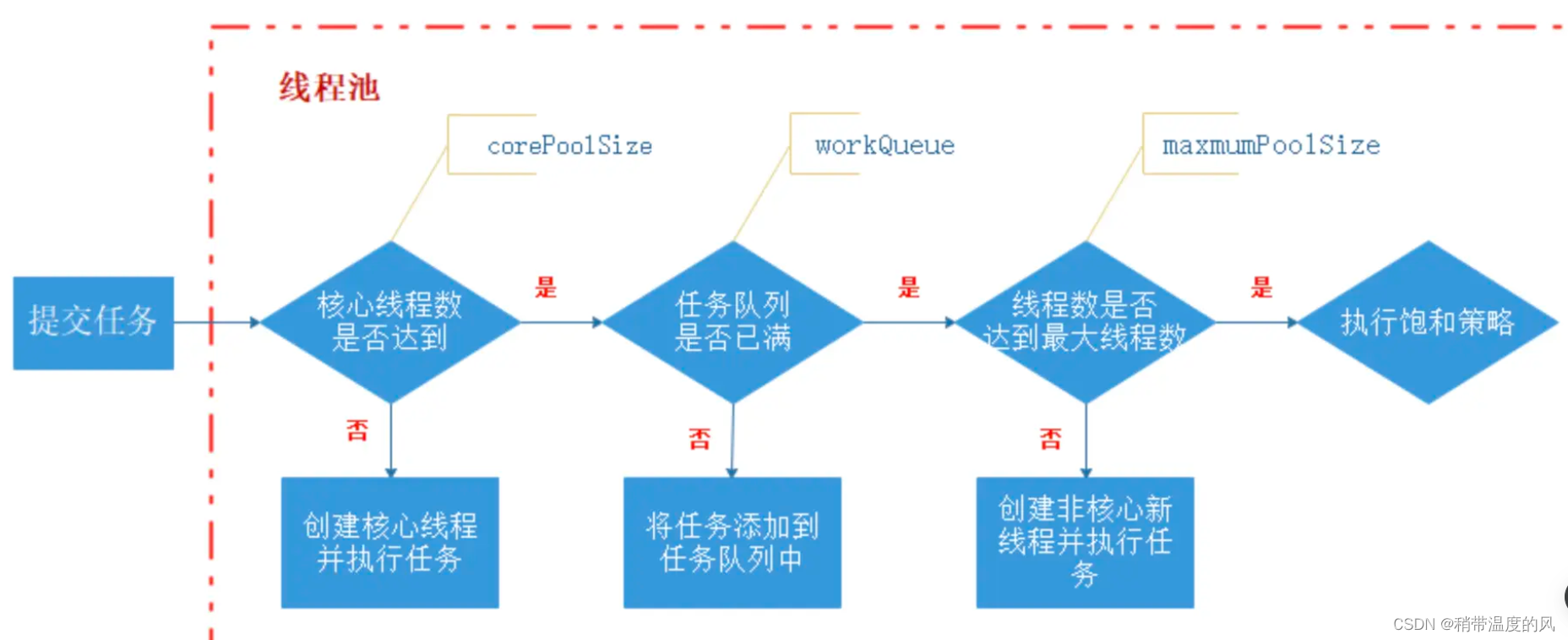
Spring Boot简单多线程定时任务实现 | @Async | @Scheduled
Spring Boot简单多线程定时任务实现 实现步骤 1 创建一个Spring Boot项目 2 定义定时任务: package com.jmd.timertasktest.task;import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.Async; impor…...
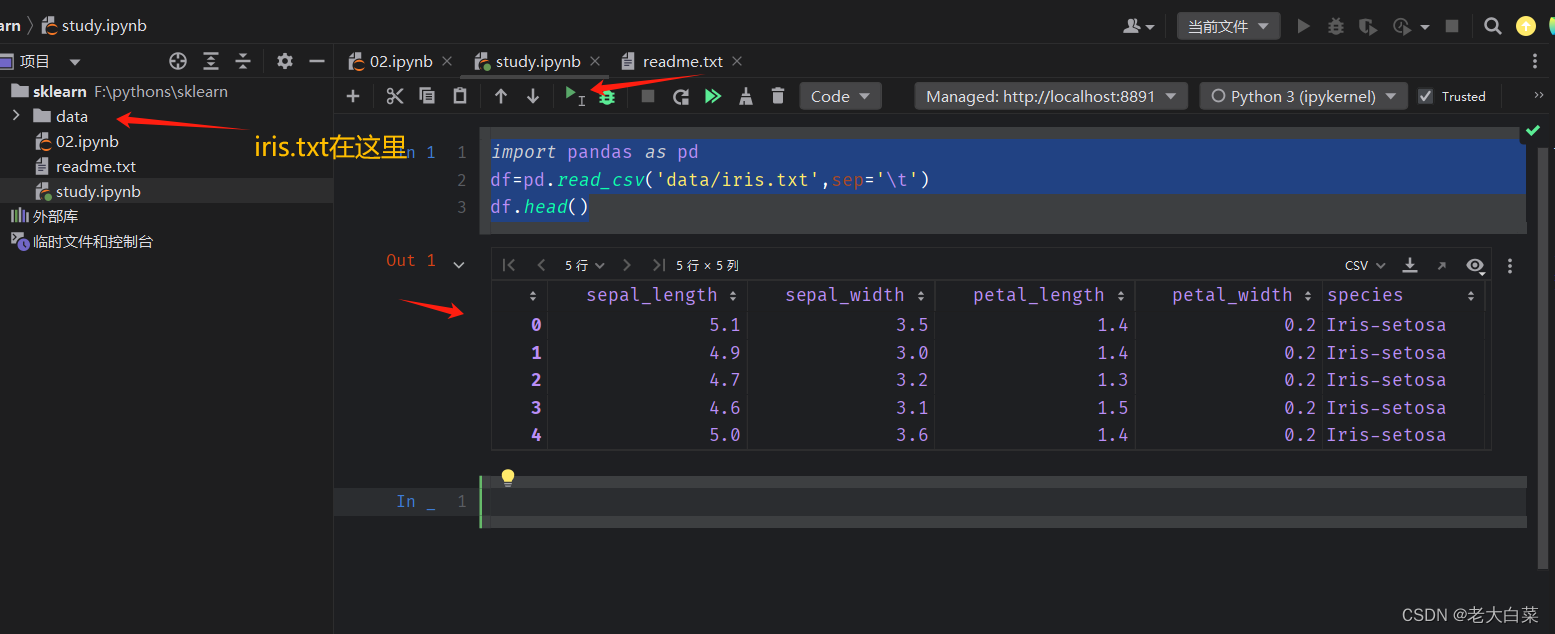
sklearn学习的一个例子用pycharm jupyter
环境 运行在jupyter 进行开发。即一个WEB端的开发工具。能适时显示开发的输出。后缀用的是ipynb.pycharm也可以支持。但也要提示按装jupyter. 或直接用andcoda 这里我们用pycharm进行项目创建 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jupyterlab pip ins…...

JVM的生命周期
1.加载(Loading): 在加载阶段,JVM会找到并加载Java字节码文件。加载阶段分为三个步骤:通过类的全限定名找到对应的字节码文件,创建一个与该类相关的Class对象,将类的静态数据结构存储在方法区中…...

企业微信消息发送踩坑实录:.NET Core下处理AccessToken过期与消息安全的最佳实践
企业微信消息发送实战:.NET Core中的AccessToken管理与消息安全策略 当企业微信API集成到生产环境时,开发者常会遇到两个看似简单却暗藏玄机的问题:AccessToken突然失效导致消息发送失败,以及敏感信息传输时的安全风险。本文将分享…...

taotoken控制台提供的api调用审计与用量分析功能体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken控制台提供的api调用审计与用量分析功能体验 对于需要统一管理多个大模型API调用的团队而言,清晰掌握调用情况…...

Termius v7.0.1汉化踩坑实录:从修改entry.js到完美中文界面的完整流程
Termius v7.0.1深度汉化实战:从逆向分析到完美本地化的技术探索 Termius作为一款广受开发者喜爱的SSH客户端,其v7.0.1版本在功能和性能上都有显著提升。但对于中文用户而言,官方未提供完整的本地化支持始终是个遗憾。本文将带你深入Termius内…...

如何用DdddOcr在3分钟内构建离线验证码识别系统
如何用DdddOcr在3分钟内构建离线验证码识别系统 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 在当今的自动化测试、数据采集和网络安全领域,验证码识别是绕不开的技术难题。传统的在线…...
切换场景及鼠标相关)
Unity(十六)切换场景及鼠标相关
场景切换空间命名:using UnityEngine.SceneManagement;直接用代码切换场景有问题要把场景加入到场景列表之中SceneList哪个场景在前面,谁在运行时就会首先进入过时方法Application.LoadLevel()if (Input.GetKeyDown(KeyCode.Space)) {SceneManager.LoadS…...

粒子群灰狼优化算法稀疏码设计【附代码】
✨ 长期致力于稀疏码多址接入、星型正交振幅调制、功率不平衡码本、粒子群算法、混合粒子群灰狼优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...

解放双手:5分钟快速上手智慧树自动化学习工具的完整指南
解放双手:5分钟快速上手智慧树自动化学习工具的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 你是否厌倦了每天重复点击智慧树视频的枯燥…...

基于SEID模型与ode45数值解的艾滋病传播动力学建模与区域防控策略评估
1. 当数学模型遇上艾滋病防控 我第一次接触传染病建模是在研究生时期,当时导师扔给我一叠艾滋病流行病学数据,说:"试试用微分方程描述这个传播过程"。那会儿对着密密麻麻的病例报告,我完全没想到数学公式真能模拟现实中…...

2026年图片换背景免费工具完全指南:一键抠图软件推荐
现在是5月,我想很多人都在为各种证件照、商品图、头像等需要换背景的图片犯愁。前两天有朋友问我"哪个软件可以给图片换背景",我才意识到很多人还在用古老的PS或者繁琐的在线工具。今天就来给大家分享一下2026年最好用的图片换背景工具&#x…...

为什么你的学术论文格式转换总是失败?docx2tex 3步解决方案
为什么你的学术论文格式转换总是失败?docx2tex 3步解决方案 【免费下载链接】docx2tex Converts Microsoft Word docx to LaTeX 项目地址: https://gitcode.com/gh_mirrors/do/docx2tex 还在为Word到LaTeX的格式转换头痛吗?每次提交学术论文、技术…...