ES慢查询分析——性能提升6 倍
问题
生产环境频繁报警。查询跨度91天的数据,请求耗时已经来到了30+s。报警的阈值为5s。我们期望值是5s内,大于该阈值的请求,我们认为是慢查询。这些慢查询,最终排查,是因为走到了历史集群上。受到了数据迁移的一定影响,也做了一些优化,最终从30s提升到5s。

背景
查询关键词简单,为‘北京’
单次仅检索两个字段
查询时间跨度为91天,覆盖数据为450亿数据
问题分析
使用profle分析,复现监控报警的语句,确实慢。集群分片太多,这里放一个分片的内容。
{"id" : "[YWAxM5F9Q0G1PXfTtYZKkzQ][_20230921-000001][3]","searches" : [{"query" : [{"type" : "FunctionScoreQuery","description" : "function score (+((title:北京)^2.0 | content:北京) +publish_time:[1687431307000 TO 1695254417999] +es_insert_time:[-9223372036854775808 TO 1703084327999], functions: [{scriptScript{type=stored, lang='null', idOrCode='search-score', options=null, params={}}}])","time" : "10s","time_in_nanos" : 10079315883,"breakdown" : {"set_min_competitive_score_count" : 0,"match_count" : 150,"shallow_advance_count" : 0,"set_min_competitive_score" : 0,"next_doc" : 2646164,"match" : 996954485,"next_doc_count" : 154,"score_count" : 31,"compute_max_score_count" : 0,"compute_max_score" : 0,"advance" : 1035917137,"advance_count" : 16,"score" : 3532211704,"build_scorer_count" : 40,"create_weight" : 3965124112,"shallow_advance" : 0,"create_weight_count" : 1,"build_scorer" : 546462281},
在Elasticsearch Profile API结果中,主要关注查询的time和breakdown字段,这提供了查询执行的总时间和各个步骤的时间分解。在这个例子中,查询的总时间为10秒。
具体来看,主要的时间花费在FunctionScoreQuery的create_weight步骤上,该步骤耗时为3,965,124,112纳秒(大约3.97秒)。create_weight是在查询执行之前创建用于评分的权重的阶段。
以下是一些步骤的关键信息:
- create_weight步骤耗时最长,可能是性能瓶颈。
- build_scorer步骤也占用了大量时间,这通常是评分过程中的一个重要步骤。
- next_doc步骤的时间比较大,这可能涉及到遍历文档的过程。
疑问?为什么 create_weight 过程耗时会这么长
从我的查询条件来看,请求是很简单的,没有复杂的条件,为什么 create_weight 过程耗时会这么长?
create_weight阶段的耗时主要取决于查询中使用的权重计算方式以及索引的结构和数据量。在你提供的Profile API结果中,create_weight的耗时非常大,说明这个步骤在整个查询过程中占用了大量的时间。
有几个潜在的原因可能导致create_weight步骤的性能下降:
- 脚本复杂性: 如果你在Function Score Query中使用了复杂的脚本,脚本的执行可能会消耗大量的时间。检查你的脚本逻辑,尽量确保它是高效的。
- 文档数和大小: 如果你的索引中包含大量的文档或者文档非常大,创建权重可能会变得更加耗时。在这种情况下,考虑优化索引结构、调整分片数量等。
- Function Score Query的配置: 如果在Function Score Query中使用了复杂的函数或者过多的函数,计算每个文档的权重可能会更加耗时。检查你的Function Score Query配置,确保它符合你的需求。
create_weight 究竟在干什么,源码?
这里主要是lucene去IO底层文件。这里比较明显的是性能问题。
第一个尝试,去掉脚本排序
脚本排序的时间会算在create_weight过程中(猜想,待验证)
测试把我的搜索条件,去掉脚本排序。原来是15s,现在是10s,脚本排序的耗时在我请求中,占据了30%多。
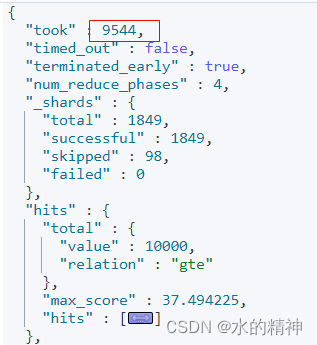
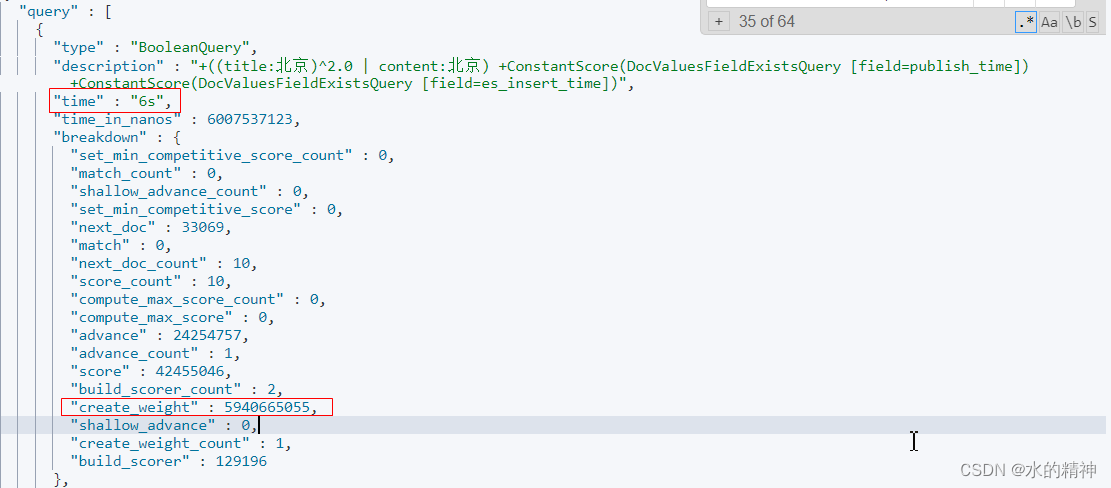
继续分析慢查询的分片
其中,耗时最长的分片还是,create_weight 过程耗时最严重。
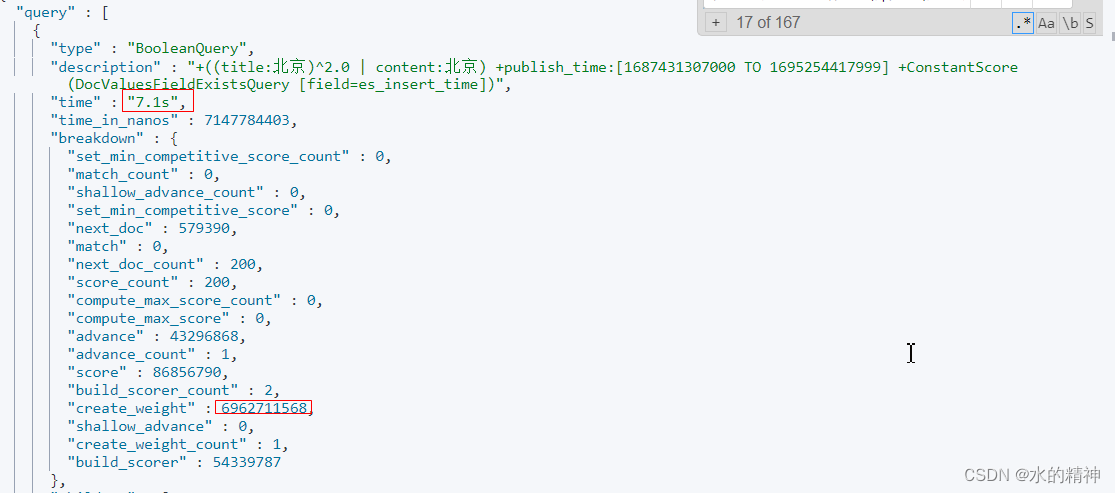
耗时发生在我的title字段上的这个子查询上。
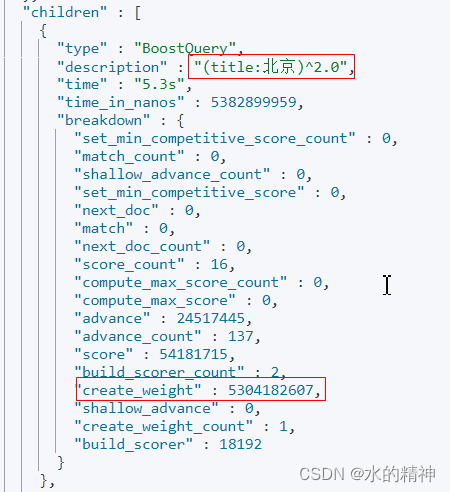
调整terminate_after 从200->10
检索耗时进一步降低。
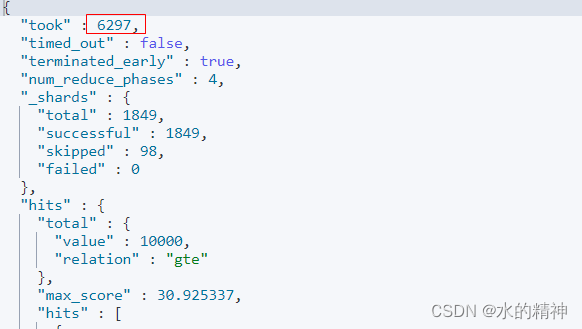
其中还是有耗时长的个别分片
整个请求6.2s,在这个分片上的请求就花了6s,并且时间还是花在了create_weight上。
如何才能降低create_weight的耗时?
降低terminate_after的值可以降低,代价是影响整体的排序效果。
减少段的个数,可以减少耗时。通过段合并。因为可以减少段的遍历。
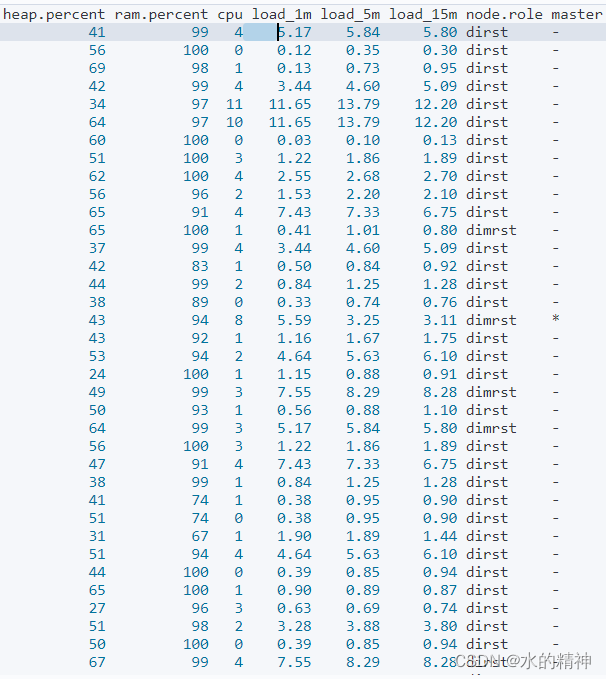
疑问?是不是在查询的时候负载高?
GET _cat/nodes?v
问题解决方案
动态调整terminate_after
并非所有的请求,都需要每个分片都200条数据。特别在大的时间跨度下,分片可能会非常多,动辄几千个,以2000个分片算,最多会匹配2000*200=400000数据。加上脚本排序,这40W数据,都需要参与分数的计算,最终才能角逐出top20的数据。最终的结果是请求耗时长。
实际上,terminate_after的取值,是可以动态调整的。检索分为乐观和悲观情况,乐观情况下,数据分布是均匀的,在分片上分配是均匀的,且检索条件命中的数据较多。在悲观情况下,检索的数据分布不均匀,且搜索的条件比较特殊,命中的数据很少,或者命中的数据在分片上分布不均匀。
大多数情况下,数据分布是均匀的,检索的数据量越大,分布可能越均匀。例如检索3个月,总数据大约450亿数据,随便一个搜索条件,搜索的数据大概率是大于10000条的。所以可以设计一个动态调整方案,来调整terminate_after的取值,能够获取更好的性能,提升200%-300%。另外需要一个悲观情况下的担保机制,避免在悲观情况下检索丢失数据。
terminate_after的值是限定在分片上的,假如一个索引有10个分片,如果设置terminate_after为200,则最后返回的数据总量为 10*200=2000条。考虑到分页为500页,每页20条数据,共计可以翻页10000条数据。如何设置terminate_after的值呢?要考虑到翻页的情况。
请求的入参,一般包含了翻页和每页的条数。 期望数据总量= 页码* 每页的数量。 es的召回总量为= 分片数*terminate_after数量*偏差。偏差可以算0.1,预期10倍可以弥补数据分布不均匀带来的影响。分片数暂时可以按每天15个来算。 页码* 每页的数量 = 分片数*terminate_after数量*偏差 。可以得出 terminate_after数量 = 页码* 每页的数量 / (分片数*偏差)。terminate_after数量不足10则向上取正为10。 当查询的天数小于7天,则可以直接取值为200。
担保机制,需要解决悲观情况下的问题。根据es返回的数据总量。 如果返回的数据总量小于期望的数据总量,则触发担保机制。需要调大terminate_after的值(暂定为500),再去搜索一次。
索引段合并
段合并可以提升减速效果。
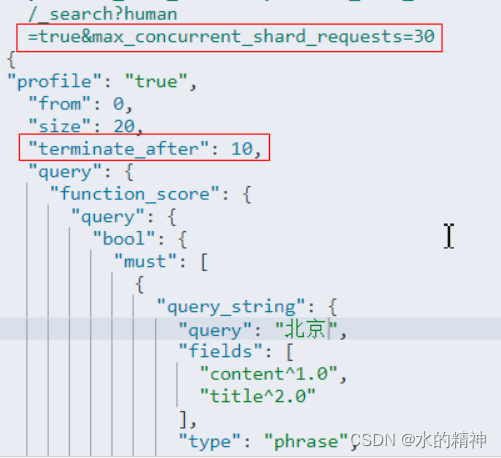
调大在请求在单个节点上的最大并发度
默认情况下,一个请求在单个节点上最大并发度为5,超过5以后则需要排队,串行执行。这里先避免排队的时间。我这里给了30。 注意此参数,在负载不高,且线程池充足和堆空间充足的情况下可以这样用。其它情况不适合,在聚合请求中不建议使用!
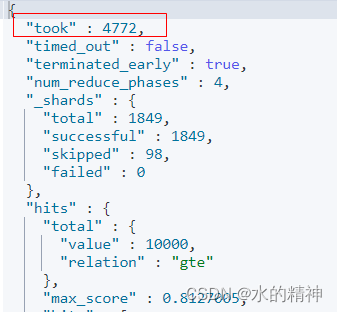
最终的检索效果
检索条件
检索耗时情况
最后
搜索优化不是一朝一夕的事情。需要长时间的知识储备。我已经做了四年优化es搜索优化。我把一些高质量的优化提升的案例放在了我的专栏里。(目前还是免费的,未来可能会收费把...)想要做更多的搜索提升,可以看看这些文章,或许会能起到抛砖引玉的作用。
https://blog.csdn.net/star1210644725/category_12341074.html
相关文章:
ES慢查询分析——性能提升6 倍
问题 生产环境频繁报警。查询跨度91天的数据,请求耗时已经来到了30s。报警的阈值为5s。我们期望值是5s内,大于该阈值的请求,我们认为是慢查询。这些慢查询,最终排查,是因为走到了历史集群上。受到了数据迁移的一定影响…...

[NAND Flash 4.3] 闪存的物理学原理_NAND Flash 的读、写、擦工作原理
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解NAND Flash》 <<<< 返回总目录 <<<< 2.1.3.1 Flash 的物理学原理与发明历程 经典物理学认为 物体越过势垒,有一阈值能量;粒子能量小于此能量则不能越过,大于此能 量则可以越过。例如骑自行…...

海豚调度 Dolphinscheduler-3.2.0/DolphinScheduler-3.1.9 离线部署 伪集群模式
Dolphinscheduler-3.2.0(离线)伪集群模式 一、依赖(前置准备工作) 1.JDK:版本要求 JDK(1.8),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到PATH 环境变量中; 2.数据库:PostgreSQL(8.2.15) 或者MySQL(5.7),两者任选其一即可,如 MySQL 则需要…...
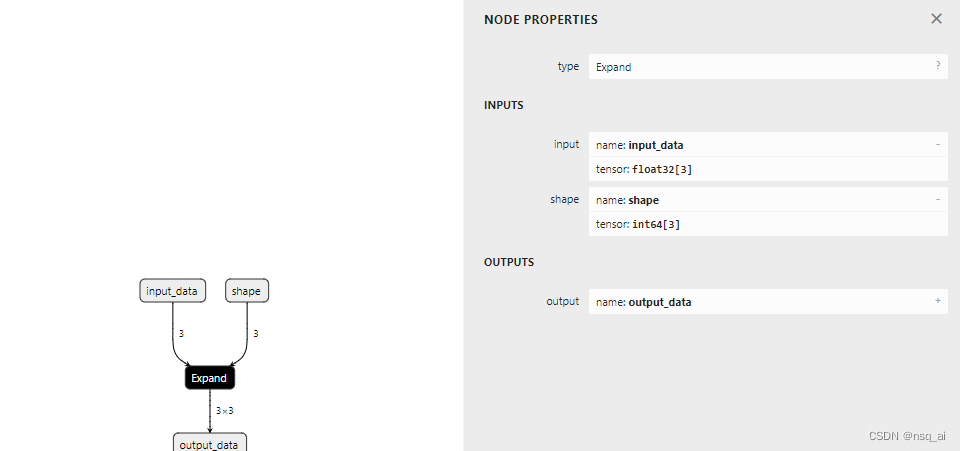
4.33 构建onnx结构模型-Expand
前言 构建onnx方式通常有两种: 1、通过代码转换成onnx结构,比如pytorch —> onnx 2、通过onnx 自定义结点,图,生成onnx结构 本文主要是简单学习和使用两种不同onnx结构, 下面以 Expand 结点进行分析 方式 方法一…...

LeetCode——1599. 经营摩天轮的最大利润
通过万岁!!! 题目:就是一个摩天轮,一共有4个仓位,一个仓位中最多可以做4个人。然后每次上一个人boardingCost钱,但是我们转动1/4圈,需要的成本是runningCost。然后给我们一个数组cu…...

从 MySQL 的事务 到 锁机制 再到 MVCC
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、事务 1.1 含义 1.2 ACID 二、锁机制 2.1 锁分类 2.2 隔离级别 三、MVCC 3.1 介绍 3.2 隔离级别 3.3 原理 四、总结 前…...

PostGreSQL远程连接
1、找到PostGreSQL安装目录,修改“postgresql.conf”配置文件(安装路径\data\postgresql.conf)。 若不知道安装目录,则通过服务,找到PostGreSQL运行的任务,右击“属性”可以进行查看安装的目录。 进入该目…...

CSS 缩减顶部动画
<template><!-- mouseenter"startAnimation" 表示在鼠标进入元素时触发 startAnimation 方法。mouseleave"stopAnimation" 表示在鼠标离开元素时触发 stopAnimation 方法。 --><!-- 容器元素 --><div class"container" mou…...

开源掌机是什么?
缘起 最近在学习小游戏的开发,偶然发现有一种叫“掌机”的游戏机,可以玩远古的各类游戏机、街机游戏!并且价格都还很便宜。这种神器的东西到底是什么?是如何工作的呢?有市场前景吗?带着这些疑问࿰…...
基于Wenet长音频分割降噪识别
Wenet是一个流行的语音处理工具,它专注于长音频的处理,具备分割、降噪和识别功能。它的长音频分割降噪识别功能允许对长时间录制的音频进行分段处理,首先对音频进行分割,将其分解成更小的段落或语音片段。接着进行降噪处理&#x…...
mysql基础-表操作
环境: 管理工具:Navicat 数据库版本:5.7.37 mysql的版本,我们可以通过函数,version()进行查看,本次使用的版本如下: 目录 1.管理工具 1.1创建表 1.2.修改表名 1.3.复制表 1.4.删除表 2…...

MySql——1146 - Table‘mysql.proc‘doesn‘t exit是这个
项目场景: 做自己的小项目需要连接mysql数据库 问题描述 点击数据库时报错 1146 - Table’mysql.proc’doesn’t exit 原因分析: 误删原生的mysql数据库 解决方案: 重新安装装部署mysql就好了 注意不要轻易删除原生的东西...
玩转贝启科技BQ3588C开源鸿蒙系统开发板 —— 代码下载(1)
本文主要参考: BQ3588C_代码下载 1. 安装依赖工具 安装命令如下: sudo apt-get update && sudo apt-get install binutils git git-lfs gnupg flexbison gperf build-essential zip curl zlib1g-dev gcc-multilib g-multiliblibc6-dev-i386 l…...
开源预约挂号平台 - 从0到上线
文章目录 开源预约挂号平台 - 从0到上线演示地址源码地址可以学到的技术前端技术后端技术部署上线开发工具其他技术业务功能 项目讲解前端创建项目 - 安装PNPM - 使用VSCODE - 安装插件首页顶部与底部 - 封装组建 - 使用scss左右布局中间内容部分路由 - vue-routerBANNER- 走马…...

Vue3的proxy
vue3.0中,使用proxy替换了原来遍历对象使用Object.defineProperty方法给属性添加set/get vue的核心能力之一是监听用户定义的状态变化并响应式刷新DOM vue2是通过替换状态对象属性的getter和setter来实现的,vue3则通过proxy进行 改为proxy后,可以突破vue当前的…...

Vue Router的介绍与引入
在这里是记录我引入Vue Router的全过程,引入方面也最好先看官方文档 一.介绍 Vue Router 是 Vue.js 的官方路由。它与 Vue.js 核心深度集成,让用 Vue.js 构建单页应用变得轻而易举。功能包括: 嵌套路由映射动态路由选择模块化、基于组件的…...

StratifiedKFold解释和代码实现
StratifiedKFold解释和代码实现 文章目录 一、StratifiedKFold是什么?二、 实验数据设置2.1 实验数据生成代码2.2 代码结果 三、实验代码3.1 实验代码3.2 实验结果3.3 结果解释3.4 数据打乱对这种交叉验证的影响。 四、总结 一、StratifiedKFold是什么? …...

四十八----react实战
一、项目中css模块化管理 1、css-loader 以下可以使用styles.xxx方式使用class是因为使用css-loader配置了module。 import styles from ./index.less export const App(){return <div className={styles.xxx}>hello word</div> }//webpack配置 {test:/\.css$/,u…...
三步实现Java的SM2前端加密后端解密
秦医如毒,无药可解。 话不多说,先上需要用到的js文件下载链接 和 jsp前端代码。 第一步:下载两个必备的js文件—— crypto-js.js、sm2.js 。 它们的下载链接如下↓(该网页不魔法上网的话会很卡,毕竟github&#x…...
)
1分钟带你了解golang(go语言)
Golang:也被称为Go语言,是一种开源的编程语言。由Google的Robert Griesemer、Rob Pike和Ken Thompson于2007年开始设计,2009年11月正式对外发布。(被誉为21世纪的C语言) 像python一样的优雅,有c一样的性能…...

STM32移植U8g2库驱动OLED:源码精简与硬件适配实战
1. 项目概述与核心思路之前玩ESP8266的时候,在Arduino环境下用U8g2库驱动OLED,画点线面、显示文字,确实方便。但很多实际项目,尤其是对成本、功耗有要求的,还是绕不开STM32这类更纯粹的MCU。最近有个小项目,…...

你的参考文献规范吗?IEEE/Elsevier投稿前必查:LaTeX引用Early Access文章的正确姿势与避坑指南
IEEE/Elsevier投稿实战:LaTeX引用Early Access文献的终极解决方案 在学术出版的快节奏世界里,Early Access(提前在线发布)已成为主流期刊加速知识传播的重要方式。当你在深夜赶完论文最后一稿,突然发现参考文献列表里…...

2026届学术党必备的降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术飞速发展着,学术研究和论文创作领域迎来了深刻变革,维普…...

MegSpot视觉对比工具:3个专业级视觉分析难题的终极解决方案
MegSpot视觉对比工具:3个专业级视觉分析难题的终极解决方案 【免费下载链接】MegSpot MegSpot是一款高效、专业、跨平台的图片&视频对比应用 项目地址: https://gitcode.com/gh_mirrors/me/MegSpot 作为一名视觉内容创作者或质量检测人员,你是…...

在macOS上运行Windows应用:为什么传统方案失败而Whisky成功
在macOS上运行Windows应用:为什么传统方案失败而Whisky成功 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 你是否曾经面临这样的困境:手头有一款必须使用的W…...

HTML图片怎么在Firefox中调试对齐_Firefox开发者工具调图方法.txt
连接数爆满主因是线程卡住而非数量多,应重点关注SHOW FULL PROCESSLIST中State非Sleep且Time>60秒的阻塞线程,优先排查应用端连接未释放、监控脚本高频查询及本地进程异常连接。直接看 SHOW PROCESSLIST 里哪些线程在“卡住”连接数爆满&…...

口碑好的芯片老化座选哪家?
芯片测试和老化是确保产品质量的关键环节。选择一款性能稳定、可靠性高的芯片老化座对于企业来说至关重要。本文将对比分析几家知名品牌的芯片老化座,并推荐其中的佼佼者——鸿怡电子。1. 鸿怡电子:国产优质IC测试座领军者产品特点设计结构:鸿…...

终极实战指南:用MifareOneTool解决Windows平台MIFARE Classic卡操作难题
终极实战指南:用MifareOneTool解决Windows平台MIFARE Classic卡操作难题 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 想象…...

基于Adafruit NeoTrellis M4打造自定义物理宏键盘:HID协议与CircuitPython实战
1. 项目概述:从通用键盘到专属启动台 如果你和我一样,每天要在电脑前处理大量任务,频繁地在不同应用间切换,或者需要执行一系列固定的快捷键操作,那么你肯定对“效率工具”有着执着的追求。我们习惯了通用键盘的“Ctrl…...

开源工作流引擎ByteChef:从组件化架构到自动化编排实战
1. 项目概述:一个面向开发者的自动化工作流引擎如果你是一名开发者,或者经常需要处理跨系统、跨应用的数据同步、定时任务、API调用编排,那么你大概率对“自动化”有着强烈的需求。我们可能都经历过这样的场景:每天手动从A系统导出…...