【Spark精讲】一文讲透Spark RDD
MapReduce的缺陷
MR虽然在编程接口的种类和丰富程度上已经比较完善了,但这些系统普遍都缺乏操作分布式内存的接口抽象,导致很多应用在性能上非常低效 。 这些应用的共同特点是需要在多个并行操 作之间重用工作数据集 ,典型的场景就是机器学习和图应用中常用的迭代算法 (每一步对数据 执行相似的函数) 。
RDD
RDD是只读的。
RDD五大属性:①分区、②依赖、③计算函数、④分区器、⑤首选运行位置。
RDD 则是直接在编程接口层面提供了一种高度受限的共享内存模型,如图下图所示。 RDD 是 Spark 的核心数据结构,全称是弹性分布式数据集 (Resilient Distributed Dataset),其本质是一种分布式的内存抽象,表示一个只读的数据分区( Partition)集合 。一个 RDD 通常只能通过其他的 RDD转换而创建。 RDD 定义了各种丰富的转换操作(如 map、 join和 filter等),通过这些转换操作,新的 RDD 包含了如何从其他 RDD 衍生所必需的信息,这些信息构成了 RDD 之间的依赖关系( Dependency) 。 依赖具体分为两种, 一种是窄依赖, RDD 之间分区是一一对应的;另一种是宽依赖,下游 RDD 的每个分区与上游 RDD (也称之为父 RDD)的每个分区都有关,是多对多的关系 。 窄依赖中的所有转换操作可以通过类似管道(Pipeline)的方式全部执行,宽依赖意味着数据需要在不同节点之间 Shuffle 传输 。

RDD计算的时候会通过一个 compute函数得到每个分区的数据。 若 RDD是通过已有的文件系统构建的,则 compute 函数读取指定文件系统中的数据;如果 RDD 是通过其他 RDD 转换而来的,则 compute 函数执行转换逻辑,将其他 RDD 的数据进行转换。 RDD 的操作算子包括两 类, 一类是 transformation,用来将 RDD 进行转换,构建 RDD 的依赖关系;另一类称为 action, 用来触发 RDD 的计算,得到 RDD 的相关计算结果或将 RDD 保存到文件系统中。
在 Spark 中, RDD 可以创建为对象 ,通过对象上的各种方法调用来对 RDD 进行转换 。 经过一系列的 transformation逻辑之后,就可以调用 action来触发 RDD 的最终计算。 通常来讲, action 包括多种方式,可以 是 向应用程序返回结果( show、 count 和 collect等),也可以是向存 储系统保存数据(saveAsTextFile等)。 在Spark中,只有遇到 action,才会真正地执行 RDD 的计算(注:这被称为惰性计算,英文为 LazyEvqluation),这样在运行时可以通过管道的方式传输多个转换 。
总结而言,基于 RDD 的计算任务可描述为从稳定的物理存储(如分布式文件系统 HDFS) 中加载记录,记录被传入由一组确定性操作构成的 DAG (有向无环图),然后写回稳定存储。 RDD还可以将数据集缓存到内存中,使得在多个操作之间可以很方便地重用数据集。 总的来讲,RDD 能够很方便地支持 MapReduce 应用、关系型数据处理、流式数据处理(Stream Processing) 和迭代型应用(图计算、机器学习等)。
在容错性方面,基于 RDD 之间的依赖, 一个任务流可以描述为 DAG。 在实际执行的时候, RDD 通过 Lineage 信息(血缘关系)来完成容错,即使出现数据分区丢失,也可以通过 Lineage 信息重建分区。 如果在应用程序中多次使用同一个 RDD,则可以将这个 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据 Lineage 信息得到分区的数据,在后续其他地方用到这个 RDD 的时候,会直接从缓存处读取而不用再根据 Lineage信息计算,通过重用达到提升性能的目的 。 虽然 RDD 的 Lineage 信息可以天然地实现容错(当 RDD 的某个分区数据计算失败或丢 失时,可以通过 Lineage信息重建),但是对于长时间迭代型应用来说,随着迭代的进行,RDD 与 RDD之间的 Lineage信息会越来越长,一旦在后续迭代过程中出错,就需要通过非常长的 Lineage信息去重建,对性能产生很大的影响。 为此,RDD 支持用 checkpoint机制将数据保存到持久化的存储中,这样就可以切断之前的 Lineage信息,因为 checkpoint后的 RDD不再需要知道它的父 RDD ,可以从 checkpoint 处获取数据。
DAG
顾名思义,DAG 是一种“图”,图计算模型的应用由来已久,早在上个世纪就被应用于数据库系统(Graph databases)的实现中。任何一个图都包含两种基本元素:节点(Vertex)和边(Edge),节点通常用于表示实体,而边则代表实体间的关系。
DAG,有向无环图,Directed Acyclic Graph的缩写,常用于建模。Spark中使用DAG对RDD的关系进行建模,描述了RDD的依赖关系,这种关系也被称之为lineage,RDD的依赖关系使用Dependency维护,参考Spark RDD之Dependency,DAG在Spark中的对应的实现为DAGScheduler。
基础概念
介绍DAGScheduler中的一些概念,有助于理解后续流程。
- Job:调用RDD的一个action,如count,即触发一个Job,spark中对应实现为ActiveJob,DAGScheduler中使用集合activeJobs和jobIdToActiveJob维护Job
- Stage:代表一个Job的DAG,会在发生shuffle处被切分,切分后每一个部分即为一个Stage,Stage实现分为ShuffleMapStage和ResultStage,一个Job切分的结果是0个或多个ShuffleMapStage加一个ResultStage
- TaskSet:一组Task
- Task:最终被发送到Executor执行的任务,和stage的ShuffleMapStage和ResultStage对应,其实现分为ShuffleMapTask和ResultTask
把 DAG 图反向解析成多个阶段,每个阶段中包含多个任务,每个任务会被任务调度器分发给工作节点上的 Executor 上执行。

Web UI上DAG举例
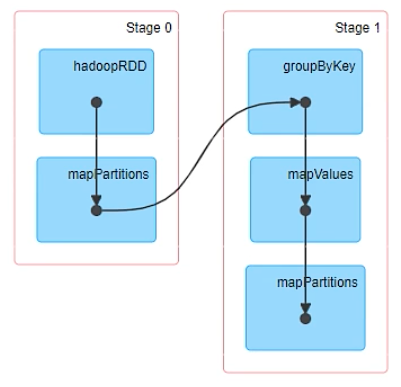
Checkpoint
RDD的依赖
checkpoint先了解一下RDD的依赖,比如计算wordcount:
scala> sc.textFile("hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd").flatMap(_.split("\\\t")).map((_,1)).reduceByKey(_+_);
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:28scala> res0.toDebugString
res1: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:28 []+-(2) MapPartitionsRDD[3] at map at <console>:28 []| MapPartitionsRDD[2] at flatMap at <console>:28 []| hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd MapPartitionsRDD[1] at textFile at <console>:28 []| hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd HadoopRDD[0] at textFile at <console>:28 []1、在textFile读取hdfs的时候就会先创建一个HadoopRDD,其中这个RDD是去读取hdfs的数据key为偏移量value为一行数据,因为通常来讲偏移量没有太大的作用所以然后会将HadoopRDD转化为MapPartitionsRDD,这个RDD只保留了hdfs的数据。
2、flatMap 产生一个RDD MapPartitionsRDD
3、map 产生一个RDD MapPartitionsRDD
4、reduceByKey 产生一个RDD ShuffledRDD
如何建立checkPoint
1、首先需要用sparkContext设置hdfs的checkpoint的目录,如果不设置使用checkpoint会抛出异常:
scala> res0.checkpoint
org.apache.spark.SparkException: Checkpoint directory has not been set in the SparkContextscala> sc.setCheckpointDir("hdfs://leen:8020/checkPointDir")sc.setCheckpointDir("hdfs://leen:8020/checkPointDir")
执行了上面的代码,hdfs里面会创建一个目录:
/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d
2、然后执行checkpoint
scala> res0.checkpoint
1发现hdfs中还是没有数据,说明checkpoint也是个transformation的算子。
scala> res0.count()
INFO ReliableRDDCheckpointData: Done checkpointing RDD 4 to hdfs://leen:8020/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4, new parent is RDD 5
res5: Long = 73689
1
2
3
hive > dfs -du -h /checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4;
147 147 /checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/_partitioner
1.2 M 1.2 M /checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/part-00000
1.2 M 1.2 M /checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/part-00001但是执行的时候相当于走了两次流程,前面计算了一遍,然后checkpoint又会计算一次,所以一般我们先进行cache然后做checkpoint就会只走一次流程,checkpoint的时候就会从刚cache到内存中取数据写入hdfs中,如下:
rdd.cache()
rdd.checkpoint()
rdd.collect在源码中,在checkpoint的时候强烈建议先进行cache,并且当你checkpoint执行成功了,那么前面所有的RDD依赖都会被销毁,如下:
/*** Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint* directory set with `SparkContext#setCheckpointDir` and all references to its parent* RDDs will be removed. This function must be called before any job has been* executed on this RDD. It is strongly recommended that this RDD is persisted in* memory, otherwise saving it on a file will require recomputation.*/def checkpoint(): Unit = RDDCheckpointData.synchronized {// NOTE: we use a global lock here due to complexities downstream with ensuring// children RDD partitions point to the correct parent partitions. In the future// we should revisit this consideration.if (context.checkpointDir.isEmpty) {throw new SparkException("Checkpoint directory has not been set in the SparkContext")} else if (checkpointData.isEmpty) {checkpointData = Some(new ReliableRDDCheckpointData(this))}}RDD依赖被销毁
scala> res0.toDebugString
res6: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:28 []| ReliableCheckpointRDD[5] at count at <console>:30 []相关文章:
【Spark精讲】一文讲透Spark RDD
MapReduce的缺陷 MR虽然在编程接口的种类和丰富程度上已经比较完善了,但这些系统普遍都缺乏操作分布式内存的接口抽象,导致很多应用在性能上非常低效 。 这些应用的共同特点是需要在多个并行操 作之间重用工作数据集 ,典型的场景就是机器学习…...

如在MT9040、IDT82V3001A 等锁相环上电后或输入参考频率改变后必须复位锁相环。
锁相环是一种反馈控制系统,它能够将输出信号的相位锁定到输入参考信号的相位上。在实际应用中,如MT9040、IDT82V3001A等PLL集成电路在上电后或者当输入参考频率发生变化后通常需要复位的原因涉及到几个方面: 1、初始化状态: 当PLL电路上电时,其内部的各个组件可能…...

构建安全的SSH服务体系
某公司的电子商务站点由专门的网站管理员进行配置和维护,并需要随时从Internet进行远程管理,考虑到易用性和灵活性,在Web服务器上启用OpenSSH服务,同时基于安全性考虑,需要对 SSH登录进行严格的控制,如图10…...

wpf ComboBox绑定数据及变更事件
定义ComboBox,以及SelectionChanged事件 <ComboBox x:Name"cmb_radius" Height"30" Width"65" FontSize"15" DisplayMemberPath"Value" SelectedValuePath"Key" HorizontalAlignment"Center&…...

SQL BETWEEN 操作符
BETWEEN 操作符选取介于两个值之间的数据范围内的值。这些值可以是数值、文本或者日期。 SQL BETWEEN 语法 SELECT column1, column2, ... FROM table_name WHERE column BETWEEN value1 AND value2; 参数说明: column1, column2, ...:要选择的字段名…...

Java位运算及移位运算
java中能表示整数数据类型的有byte、short、char、int、long,在计算机中占用的空间使用字节描述,1个字节使用8位二进制表示。 数据类型字节数二进制位数表示范围默认值byte18-27 – 27-10char2160 – 216-1\u0000 (代表字符为空 转成int就是0)short216-…...
)
上界通配符(? extends Type)
在Java中,? extends Type是一个上界通配符,表示参数化类型的上限是Type。这意味着容器可以持有Type类型的任何对象或者Type的子类型对象。 使用场景 这种类型的通配符常用于泛型方法中,允许方法接受Type的实例或其子类型的集合。这同样基于…...
zlib.decompressFile报错 【Bug已解决-鸿蒙开发】
文章目录 项目场景:问题描述原因分析:解决方案:方案1方案2此Bug解决方案总结寄语项目场景: 最近也是遇到了这个问题,看到网上也有人在询问这个问题,本文总结了自己和其他人的解决经验,解决了zlib.decompressFile报错 的问题。 问题: zlib.decompressFile报错,怎么解…...

54.网游逆向分析与插件开发-游戏增加自动化助手接口-项目需求与需求拆解
内容来源于:易道云信息技术研究院VIP课 项目需求: 为游戏增加VIP功能-自动化助手。自动化助手做的是首先要说一下背景,对于授权游戏来讲它往往年限都比较老,老游戏和新游戏设计理念是不同的,比如说老游戏基本上在10年…...

Spring Boot笔记2
3. SpringBoot原理分析 3.1. 起步依赖原理解析 3.1.1. 分析spring-boot-starter-parent 按住Ctrl键,然后点击pom.xml中的spring-boot-starter-parent,跳转到了spring-boot-starter-parent的pom.xml,xml配置如下(只摘抄了部分重…...

MySQL5.7服务器 SQL 模式
官网地址:MySQL :: MySQL 5.7 Reference Manual :: 5.1.10 Server SQL Modes 欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯. MySQL 5.7 参考手册 / ... / 服务器 SQL 模式 5.1.10 服务器 SQL 模式…...
关于LayUI表格重载数据问题
目的 搜索框搜索内容重载数据只显示搜索到的结果 遇到的问题 在layui官方文档里介绍的table属性有data项,但使用下列代码 table.reload(test, {data:data //data为json数据}); 时发现,会会重新调用table.render的url拿到原来的数据,并不会显示出来传…...

MyBatis-mapper.xml配置
1、配置获取添加对象的ID <!-- 配置我们的添加方法,获取到新增加了一个monster对象的iduseGeneratedKeys"true" 意思是需要获取新加对象的主键值keyProperty"monster_id" 表示将获取到的id值赋值给Monster对象的monster_id属性 --><…...

【如何选择Mysql服务器的CPU核数及内存大小】
文章目录 🔊博主介绍🥤本文内容📢文章总结📥博主目标 🔊博主介绍 🌟我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO专家博主、阿里云专家博主、清华大学出版社签约作…...

【从浅到深的算法技巧】4.静态方法
1.1.6静态方法 在许多语言中,静态方法被称为函教,静态方法是一组在被调用时会被顺序执行的语句。修饰符static将这类方法和1.2的实例方法区别开来。当讨论两类方法共有的属性时我们会使用不加定语的方法一词。 1.1.6.1静态方法 方法封装了由一系列语句…...

YOLO手部目标检测
手部目标检测原文地址如下:手部关键点检测2:YOLOv5实现手部检测(含训练代码和数据集)_yolov5 关键点检测-CSDN博客 手部检测数据集地址如下: 手部关键点检测1:手部关键点(手部姿势估计)数据集(含下载链接)_手关键点数据集-CSDN博…...

网络IP地址如何更改?怎么使用动态代理IP提高网速?
网络IP地址更改以及使用动态代理IP提高网速的步骤如下: 一、更改IP地址 1. 打开浏览器,输入路由器登陆地址并登陆路由器后台管理界面。 2. 找到“高级设置”或“无线设置”或“VPN设置”一栏,点击“断开”,即可断开网络࿰…...
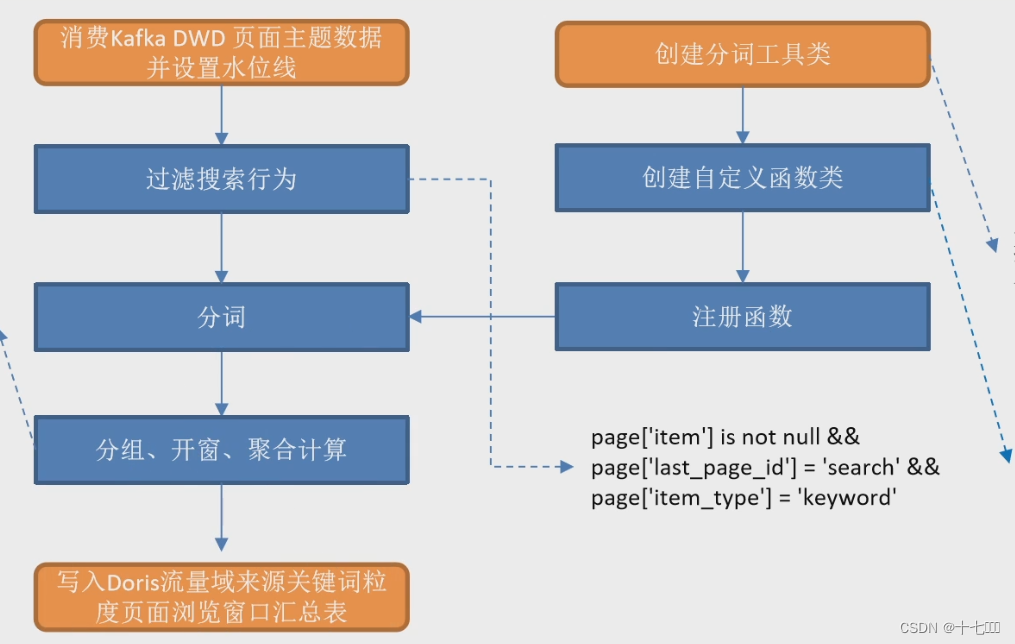
Flink实时电商数仓之DWS层
需求分析 关键词 统计关键词出现的频率 IK分词 进行分词需要引入IK分词器,使用它时需要引入相关的依赖。它能够将搜索的关键字按照日常的使用习惯进行拆分。比如将苹果iphone 手机,拆分为苹果,iphone, 手机。 <dependency><grou…...

MFC - CArchive/内存之间的序列化应用细节
文章目录 MFC - CArchive/内存之间的序列化应用细节概述笔记END MFC - CArchive/内存之间的序列化应用细节 概述 有个参数文件, 开始直接序列化到文件. 现在优化程序, 不想这个参数文件被用户看到. 想先由参数发布程序(自己用)设置好参数后, 加个密落地. 等用户拿到后, 由程序…...
C语言实验4:指针
目录 一、实验要求 二、实验原理 1. 指针的基本概念 1.1 指针的定义 1.2 取地址运算符(&) 1.3 间接引用运算符(*) 2. 指针的基本操作 2.1 指针的赋值 2.2 空指针 3. 指针和数组 3.1 数组和指针的关系 3.2 指针和数…...

知识竞赛代表队分组方法详解
🎲 知识竞赛代表队分组方法详解公平 均衡 策略 让每一支队伍都在合适的起点🎯 引言知识竞赛中,代表队的合理分组是赛事公平与精彩的基础。无论是学校比赛、企业活动还是大型公开赛,组织者都需要根据队伍数量和赛制选择合适的分…...

RISC-V开发踩坑实录:从编译错误‘csrr a5,mhartid’到GDB报错‘E14’的完整排错指南
RISC-V开发实战:从编译到调试的完整排错手册 在嵌入式开发领域,RISC-V架构正以惊人的速度改变着行业格局。作为一名长期从事ARM架构开发的工程师,当我第一次接触RISC-V时,本以为凭借多年的嵌入式经验可以轻松上手,却没…...

texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜
texgen.js扩展开发终极指南:如何自定义纹理生成器和滤镜 【免费下载链接】texgen.js JavaScript Texture Generator 项目地址: https://gitcode.com/gh_mirrors/te/texgen.js texgen.js 是一个功能强大的JavaScript纹理生成器库,它让开发者能够通…...

Ubuntu 20.04上virt-manager报GDBus错误?别慌,三步排查法搞定它
Ubuntu 20.04 virt-manager报GDBus错误的深度排查指南 当你正准备用virt-manager管理KVM虚拟机时,突然弹出一个令人困惑的GDBus错误——这种场景对于Linux虚拟化用户来说并不陌生。这个看似简单的错误背后,其实涉及Linux桌面环境中多个关键组件的协同工作…...
)
Midjourney铂金印相风格实战手册(从Prompt工程到Lightroom精修全流程)
更多请点击: https://intelliparadigm.com 第一章:铂金印相风格的美学溯源与数字复现逻辑 铂金印相(Platinum Print)诞生于19世纪晚期,以铂族金属盐在纸基上直接成像,呈现无光泽、宽广影调与近乎永久的化学…...

告别手动写测试报告:用AI自动生成可视化测试总结
测试报告的价值困境与破局在软件交付的最后关头,测试报告往往陷入一种尴尬的境地。一方面是倒计时的上线压力,另一方面是堆积如山的测试数据。许多测试工程师都有过这样的经历:打开Excel,机械地复制用例执行数、通过率、缺陷数&am…...

BEAGLE库终极指南:如何快速实现高性能系统发育分析
BEAGLE库终极指南:如何快速实现高性能系统发育分析 【免费下载链接】beagle-lib general purpose library for evaluating the likelihood of sequence evolution on trees 项目地址: https://gitcode.com/gh_mirrors/be/beagle-lib 你是否在系统发育分析中遇…...

别再拿冰河木马当玩具了!从一次真实的渗透测试复盘,聊聊Windows XP时代的安全漏洞与防御思路
从冰河木马看Windows XP时代的安全漏洞与现代防御启示 2000年代初的互联网环境与今天截然不同。那时,Windows XP系统占据着绝对市场份额,而安全意识对大多数用户来说还是个陌生概念。正是在这样的背景下,"冰河"这类远程控制工具得以…...

UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法
UEFI开发避坑指南:WaitForEvent和CreateEvent的5个实战陷阱与正确用法 如果你正在开发UEFI驱动或应用,事件机制(Event)一定是绕不开的核心功能。但看似简单的WaitForEvent和CreateEvent,在实际编码中却暗藏玄机。本文将…...

STM32F407 USART3串口DMA不定长接收与中断发送实战:从零构建高效通信框架
1. 为什么需要DMAUSART组合方案 在嵌入式开发中,串口通信就像设备与外界对话的"嘴巴"和"耳朵"。传统的中断方式就像每次只说一个字就要停下来等回应,效率实在太低。想象一下,如果你跟朋友聊天,每说一个字就要…...