PyTorch的Tensor(张量)
一、Tensor概念
什么是张量?
张量是一个多维数组,它是标量、向量、矩阵的高维拓展
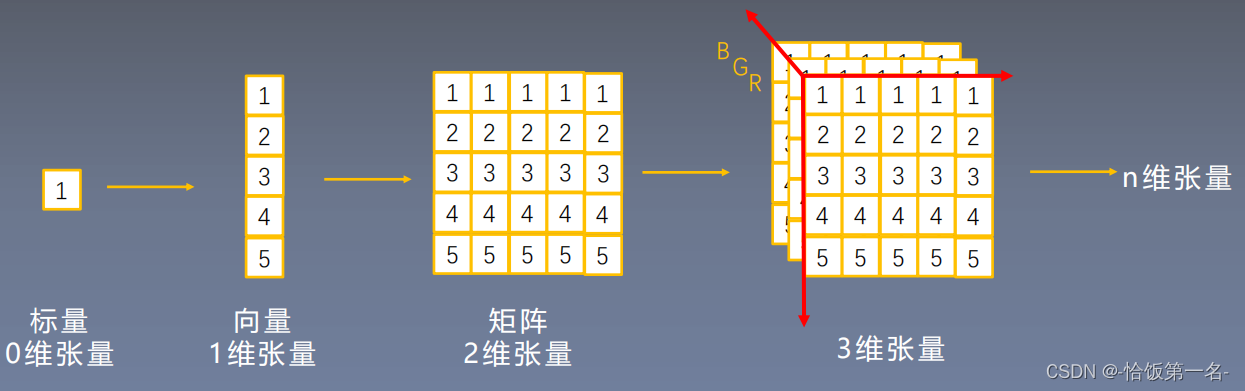
Tensor与Variable
Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。
- data: 被包装的Tensor
- grad: data的梯度(梦回数一)
- grad_fn: 创建Tensor的Function,是自动求导的关键
- requires_grad: 指示是否需要梯度
- is_leaf: 指示是否是叶子节点(张量)
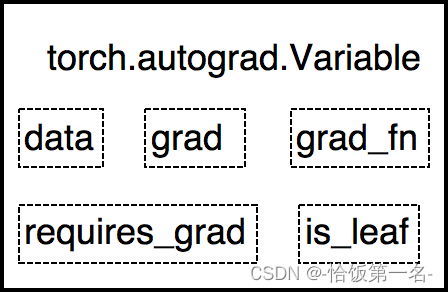
Tensor
PyTorch 0.4.0版本开始,Variable已并入Tensor。
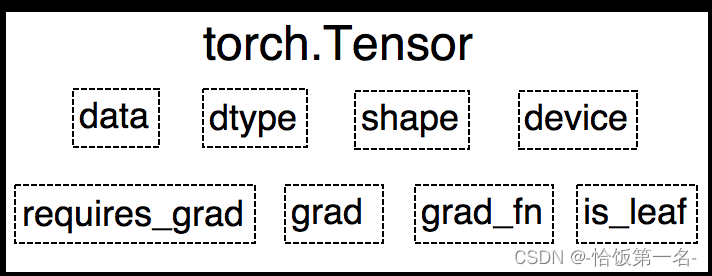
- dtype: 张量的数据类型,例如torch.FloatTensor, torch.cuda.FloatTensor
- shape: 张量的形状,例如 (64, 3, 224, 224)
- device: 张量所在设备,GPU/CPU,是加速的关键
二、 Create Tensor
1、直接创建
torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False
)
功能:从data创建tensor
• data: 数据, 可以是list, numpy
• dtype : 数据类型,默认与data的一致
• device : 所在设备, cuda/cpu
• requires_grad:是否需要梯度
• pin_memory:是否存于锁页内存
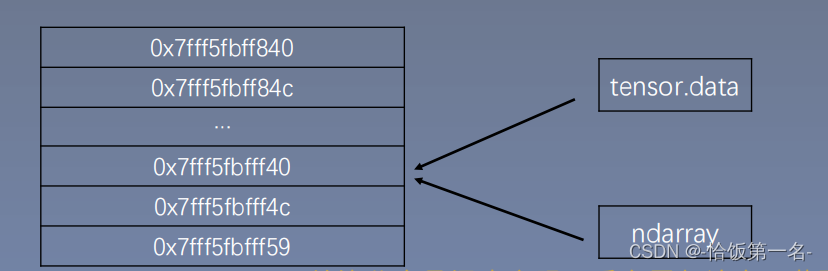
torch.from_numpy(ndarray)
功能:从numpy创建tensor。
注意事项:从torch.from_numpy创建的 tensor 与原始 ndarray 共享内存。
当修改其中一个的数据时,另一个也会被改动。
2、依据数值创建
torch.zeros(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
功能:依照size创建全0张量
• size: 张量的形状, 如(3, 3)、(3, 224,224)
• out : 输出的张量
• layout : 内存中布局形式, 有strided,sparse_coo等
• device : 所在设备, gpu/cpu
• requires_grad:是否需要梯度
torch.zeros_like(input,dtype=None,layout=None,device=None,requires_grad=False
)功能:依照 input 形状创建全0张量
参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None(即与输入张量相同)。
- layout(可选): 新创建张量的布局,默认为 None(即与输入张量相同)。
- device(可选): 新创建张量所在设备,默认为 None(即与输入张量相同)。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
torch.ones_like(input,dtype=None,layout=None,device=None,requires_grad=False
)参数说明:
- input: 作为模板的输入张量,新创建的张量将具有与此张量相同的形状和数据类型。
- dtype(可选): 新创建张量的数据类型,默认为 None,即与输入张量相同。
- layout(可选): 新创建张量的布局,默认为 None,即与输入张量相同。
- device(可选): 新创建张量所在设备,默认为 None,即与输入张量相同。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
- torch.ones() 用于创建所有元素值为1的张量,而 torch.ones_like() 则创建与输入张量形状相同的张量,但所有元素的值都为1。这两个函数都可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.full(size,fill_value,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- fill_value: 填充张量的值,可以是标量或与指定数据类型相同的张量。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建指定形状并用指定值填充的张量。填充值可以是一个标量或与指定数据类型相同的张量。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.arange(start=0,end,step=1,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值,默认为 0。
- end: 序列结束值(不包含),创建的序列不包含该值。
- step: 序列中相邻值之间的步长,默认为 1。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数用于创建一个从 start 到 end(不包含 end)的数值序列,并以 step 为步长。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.linspace(start,end,steps=100,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值。
- end: 序列结束值。
- steps: 序列中的元素数量,默认为 100。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在指定范围内(从 start 到 end)以均匀间隔的方式生成的数值序列,并且序列的元素数量由 steps 参数指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.logspace(start,end,steps=100,base=10.0,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- start: 序列起始值的指数。
- end: 序列结束值的指数。
- steps: 序列中的元素数量,默认为 100。
- base: 序列中的数值以此为底进行指数计算,默认为 10.0。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数创建一个在对数刻度上以均匀间隔分布的数值序列,start 和 end 参数指定序列起始值和结束值的指数,base 参数确定对数的底。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.eye(n,m=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)参数说明:
- n: 矩阵的行数。
- m(可选): 矩阵的列数,默认为 None,如果为 None,则创建的是 n x n 的方阵。
- out(可选): 输出张量。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数可以创建一个单位矩阵。如果提供了 m 参数,则创建的是一个 n x m 的矩阵,否则创建的是 n x n 的方阵。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
3、依概率分布创建张量
torch.normal(mean,std,out=None
)torch.normal() 是 PyTorch 中用于生成服从指定均值和标准差的正态分布随机数的函数。以下是该函数的参数说明:
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(mean,std,out=None
)用于生成服从指定均值和标准差的正态分布随机数。
- mean: 正态分布的均值。
- std: 正态分布的标准差。
- out(可选): 输出张量,用于保存生成的随机数。
torch.normal(mean,std,size,out=None
)- mean: 正态分布的均值。
- std: 正态分布的标准差。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机数。
四种模式:
mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量
这个函数与前一个函数类似,但是多了一个 size 参数,用于指定生成张量的形状。返回一个形状为 size 的张量,其中的元素服从均值为 mean、标准差为 std 的正态分布。可以选择性地提供一个输出张量 out 用于保存生成的随机数。
torch.randn(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)torch.rand() 是 PyTorch 中用于生成服从标准正态分布(均值为0,标准差为1)的随机数的函数。以下是该函数的参数说明:
torch.rand(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
- *size: 张量的形状,可以是一个数字或一个元组,用来指定张量每个维度的大小。
- out(可选): 输出张量,用于保存生成的随机数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [0, 1) 上均匀分布的随机数,形状由参数 *size 指定。可以选择性地指定数据类型、布局、设备和是否需要计算梯度。
torch.randint(low=0,high,size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False
)
- low: 区间的下界(包含在内)。
- high: 区间的上界(不包含在内)。
- size: 生成张量的形状。
- out(可选): 输出张量,用于保存生成的随机整数。
- dtype(可选): 张量的数据类型,默认为 None,即自动推断。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个张量,其中的元素是在区间 [low, high) 上均匀分布的随机整数,形状由参数 size 指定。
这个函数用于生成随机排列和按照伯努利分布生成随机二元数。
torch.randperm(n,out=None,dtype=torch.int64,layout=torch.strided,device=None,requires_grad=False
)
参数说明:
- n: 生成随机排列的长度。
- out(可选): 输出张量,用于保存生成的随机排列。
- dtype(可选): 张量的数据类型,默认为 torch.int64。
- layout(可选): 张量的布局,默认为 torch.strided。
- device(可选): 张量所在设备,默认为 None,即 CPU。
- requires_grad(可选): 是否需要计算梯度,默认为 False,即不需要计算梯度。
这个函数返回一个长度为 n 的张量,包含从 0 到 n-1 的随机排列整数。
torch.bernoulli(input,*,generator=None,out=None
)- input: 输入张量,用于指定伯努利分布的概率值。
- generator(可选): 随机数生成器,默认为 None。
- out(可选): 输出张量,用于保存生成的随机二元数。
这个函数返回一个张量,其中的元素按照输入张量中的概率值在伯努利分布上进行采样生成随机二元数(0 或 1)。
相关文章:
PyTorch的Tensor(张量)
一、Tensor概念 什么是张量? 张量是一个多维数组,它是标量、向量、矩阵的高维拓展 Tensor与Variable Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。 data: 被包装的Tensorgrad: data的梯度&…...
spug发布问题汇总记录
问题导览 1. [vite]: Rollup failed to resolve import "element-plus" from "src/main.js". 项目框架简介 vue3viteelement-plus 解决方案 - 1. 配置淘宝镜像源:npm config set registry https://registry.npm.taobao.org/ - 2. npm inst…...
SpringBoot-搭建集成Mybatis的项目
本文介绍了如何在IntelliJ IDEA中使用SpringBoot和Mybatis构建Java Web应用程序。通过本文的学习,读者将了解如何使用IntelliJ IDEA快速搭建一个基于SpringBoot和Mybatis的Java Web应用程序,提高开发效率。IntelliJ IDEA是一款功能强大的Java集成开发环境…...

mysql隐式转换规则
MySQL 中的隐式类型转换发生在比较操作或者其他一些需要特定数据类型参数的上下文中,如果参与操作的表达式或列的数据类型不匹配,MySQL 就会自动进行数据类型转换以适配预期的数据类型。 以下是 MySQL 的一些常见隐式转换规则: 字符串和数字…...

怎么解决 Nginx反向代理加载速度慢?
Nginx反向代理加载速度慢可能由多种原因引起,以下是一些可能的解决方法: 1,网络延迟: 检查目标服务器的网络状况,确保其网络连接正常。如果目标服务器位于不同的地理位置,可能会有较大的网络延迟。考虑使用…...

Eureka工作原理超详细讲解介绍
Eureka 是 Netflix 开源的一款服务注册与发现框架,主要用于构建分布式系统中的服务治理和负载均衡。下面是关于 Eureka 工作原理的详细介绍:1.Eureka 架构: Eureka 采用了客户端-服务器架构,包括 Eureka Server 和 Eureka Client …...
)
SQL WHERE 语句(条件选择)
WHERE 子句用于过滤记录。 SQL WHERE 子句 WHERE 子句用于提取那些满足指定条件的记录。 SQL WHERE 语法 SELECT column1, column2, ... FROM table_name WHERE condition; 参数说明: column1, column2, ...:要选择的字段名称,可以为多…...
用UCLI(TCL)控制verdi dump 波形
UCLI(Unified Command-line Interface)为Synopsys验证工具了提供一组通用命令,通过UCLI可以执行任意TCL(Tool Command Language)命令。在我们的验证环境中,通常跟ucli打交道的地方是用来控制开始dump和结束…...

如何使用 Python+selenium 进行 web 自动化测试?
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击、输入、选择等等。它支持多种浏览器,包括Chrome、Firefox、Safari等等,并且可以在多个平台上运行。 安装和配置Selenium 在使用Selenium之前,…...

约瑟夫问题
约瑟夫问题 题目描述 n n n 个人围成一圈,从第一个人开始报数,数到 m m m 的人出列,再由下一个人重新从 1 1 1 开始报数,数到 m m m 的人再出圈,依次类推,直到所有的人都出圈,请输出依次出圈人的编号。…...

文件管理方法:利用文件大小进行筛选,高效移动文件至目标文件夹
在日常工作中,文件管理是一项至关重要的任务。为了更高效地管理文件,可以利用文件大小进行筛选,并将文件快速移动至目标文件夹。接下来一起来看看云炫文件管理器如何利用文件大小进行筛选,以及如何高效移动文件至目标文件夹的方法…...

python报错:TypeError: Descriptors cannot be created directly.
问题 报错提示: TypeError:不能直接创建描述符。 如果此调用来自 _pb2.py 文件,则您生成的代码已过期,必须使用 protoc > 3.19.0 重新生成。 如果您不能立即重新生成原型,其他一些可能的解决方法是: 1.…...

Linux 内核调试
文章目录 一、方法论 一、方法论 qemu 虚拟机 Linux内核学习 Linux 内核调试 一:概述 Linux 内核调试 二:ubuntu20.04安装qemu Linux 内核调试 三:《QEMU ARM guest support》翻译 Linux 内核调试 四:qemu-system-arm功能选项整…...
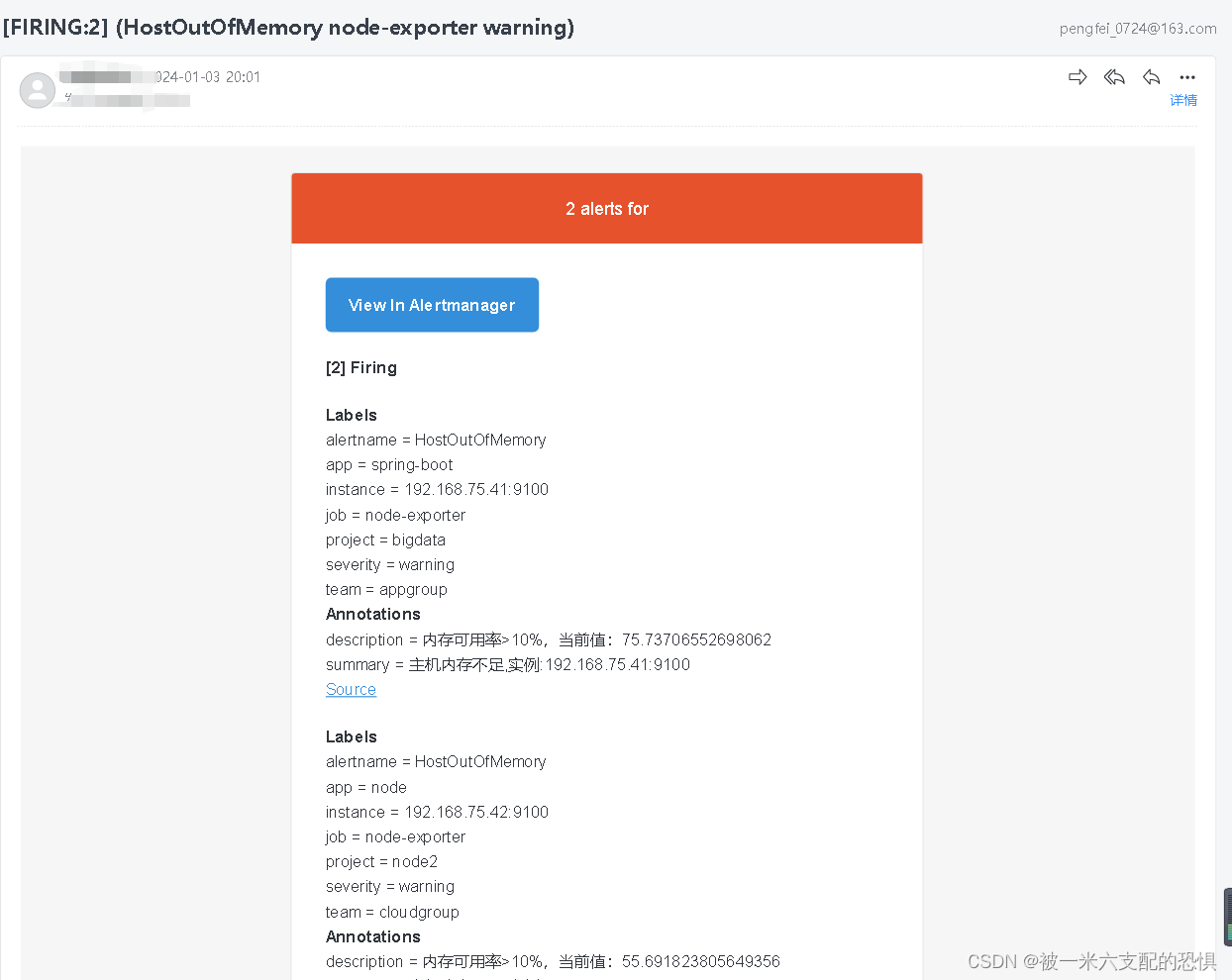
Prometheus-AlertManager 邮件告警
环境,软件准备 本次演示环境,我是在虚拟机上安装 Linux 系统来执行操作,以下是安装的软件及版本: System: CentOS Linux release 7.6Docker: 24.0.5Prometheus: v2.37.6Consul: 1.6.1 docker 安装prometheus,alertmanage,说明一下这里直接将…...

Volcano Controller控制器源码解析
Volcano Controller控制器源码解析 本文从源码的角度分析Volcano Controller相关功能的实现。 本篇Volcano版本为v1.8.0。 Volcano项目地址: https://github.com/volcano-sh/volcano controller命令main入口: cmd/controller-manager/main.go controller相关代码目录: pkg/co…...
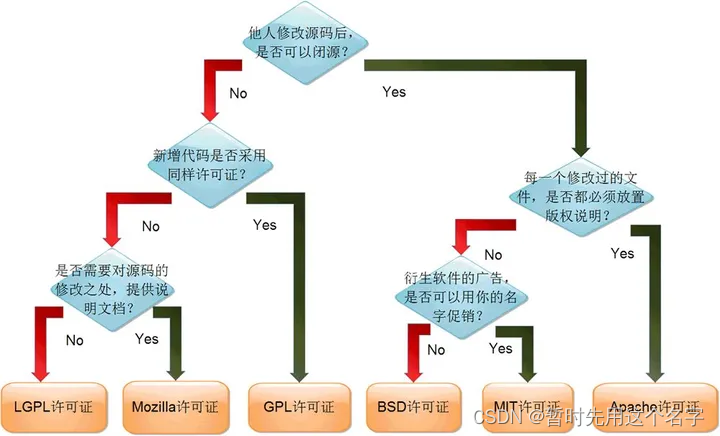
开源协议简介和选择
软件国产化已经提到日程上了,先来研究一下开源协议。 引言 在追求“自由”的开源软件领域的同时不能忽视程序员的权益。为了激发程序员的创造力,现今世界上有超过60种的开源许可协议被开源促进组织(Open Source Initiative)所认可…...

大创项目推荐 深度学习卫星遥感图像检测与识别 -opencv python 目标检测
文章目录 0 前言1 课题背景2 实现效果3 Yolov5算法4 数据处理和训练5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **深度学习卫星遥感图像检测与识别 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
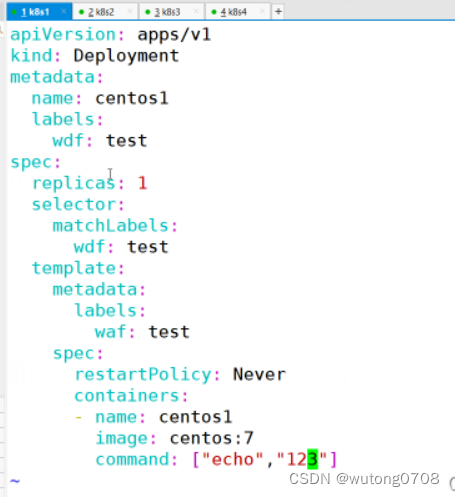
pod的环节
pod 是k8s当中最小的资源管理组件 Pod也是最小化运行容器化的应用的资源管理对象 Pod是一个抽象化的概念,可以理解为一个或多个容器化的集合 在一个pod当中运行一个容器,是最常用的方式 在一个pod当中同时运行多个容器,在一个pod当中可以…...
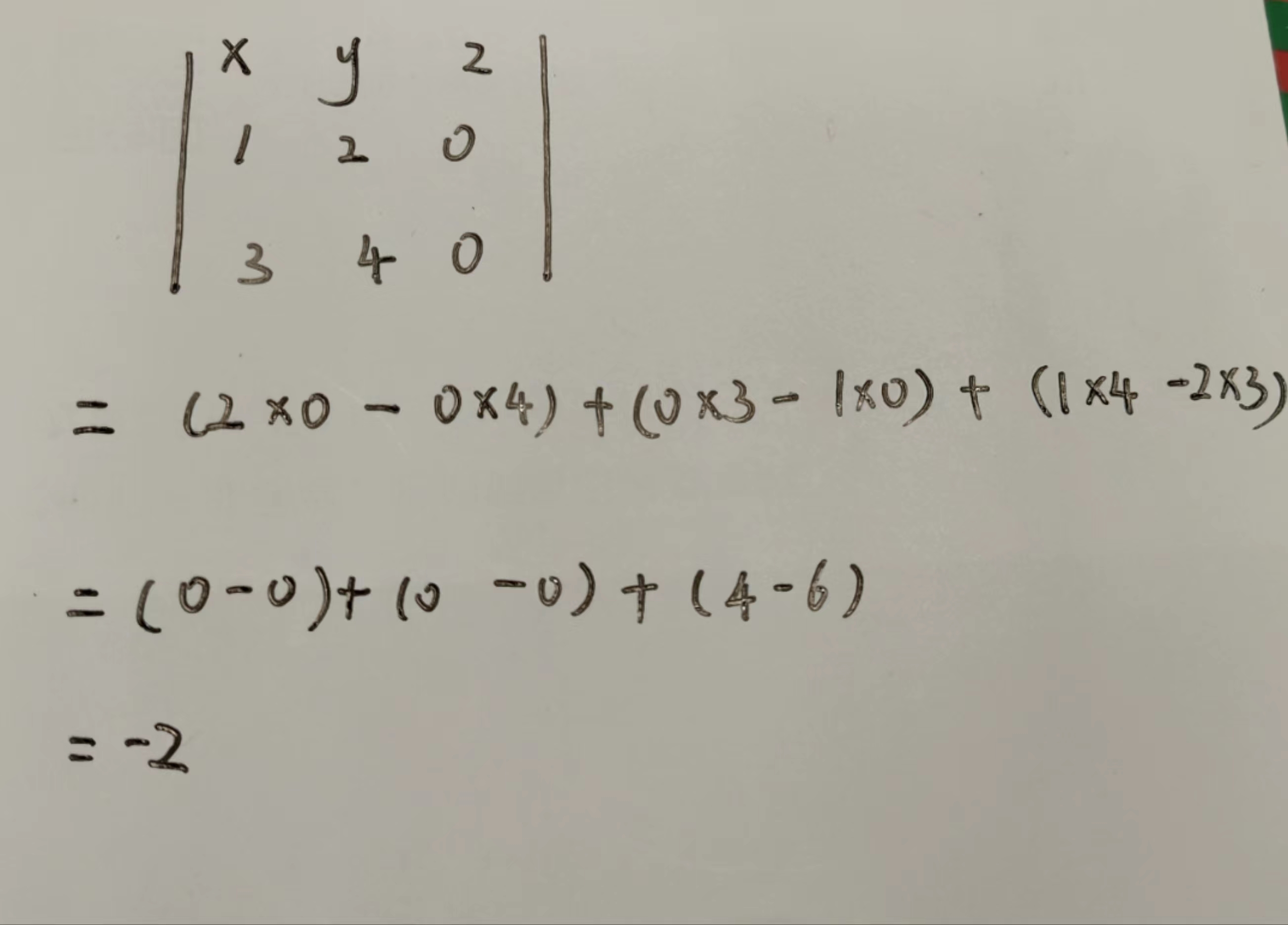
Unity | Shader基础知识番外(向量数学知识速成)
目录 一、向量定义 二、计算向量 三、向量的加法(连续行走) 四、向量的长度 五、单位向量 六、向量的点积 1 计算 2 作用 七、向量的叉乘 1 承上启下 2 叉乘结论 3 叉乘的计算(这里看不懂就百度叉乘计算) 八、欢迎收…...

一个小白的微不足道的见解关于未来
随着科技的不断发展,IT行业日益壮大,运维工程师在其中扮演着至关重要的角色。他们负责维护和管理企业的技术基础设施,确保系统的正常运行。然而,随着技术的进步和行业的变化,运维工程师的未来将面临着一系列挑战和机遇…...
)
AI原生图计算应用落地全景图(SITS 2026权威白皮书核心精要)
更多请点击: https://intelliparadigm.com 第一章:AI原生图计算应用:SITS 2026图神经网络工程化方案 SITS 2026 是面向大规模动态图场景的AI原生图计算框架,深度融合GNN训练、图拓扑实时更新与边缘-云协同推理能力。其核心设计摒…...

2026免费照片去水印软件App排行榜,手机电脑去水印哪款好用?实测推荐
2026免费照片去水印软件App排行榜,手机电脑去水印哪款好用?实测推荐 图片上的水印去不掉,一直是不少人的痛点。从社交平台保存下来的图片带着平台Logo,下载的素材图带有版权标识,或者照片里不小心拍到广告文字——这些…...

AI编程提效:用系统提示词实现测试驱动开发与可靠交付
1. 项目概述:一个为AI编程工作流设计的“系统指令集”如果你经常用Claude、Cursor或者ChatGPT来辅助写代码,大概率遇到过这种情况:AI助手给出的代码片段看起来能跑,但一放到项目里就各种报错;或者它自作主张地“优化”…...

dotUI设计系统生成器:基于品牌配置一键生成React组件库
1. 项目概述:dotUI,一个为品牌而生的设计系统在当今的Web开发领域,尤其是基于React的生态中,我们常常面临一个两难的选择:是使用现成的UI组件库快速搭建界面,还是投入大量时间从零开始构建一套完全符合品牌…...

从干扰三要素到实战:辐射发射的工程化抑制与诊断方法
1. 项目概述:从一道周五小测题聊起辐射发射那天在EE Times上翻到一篇2014年的老文章,标题叫“Friday Quiz: Radiated Emissions”,作者是Martin Rowe。文章开头就抛出了一个非常基础,但又直击电磁兼容(EMC)…...

海棠山铁哥:我写《凰标》,就是要打破资本定价权@凤凰标志
凰标宣言——夺回中国人的文化定价权流量高低决定作品好坏,资金投入定义内容价值。 当资本垄断审美、定价与生死, 创作者便只剩一条出路:宣战。一、资本逻辑:三座大山权力资本如何行使对创作者的结果审美话语权用流量模板批量复制…...

Windows系统mfc140.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

3PEAK思瑞浦 TPA2772-VS1R MSOP8 运算放大器
特性 供电电压:3V至36V 偏移电压:在25C时最大3.5mV 轨到轨输入和输出 带宽:4.6 MHz 噪声容限:-良好,THD0.0008% 低噪声:1kHz时53nV/vHz 零交叉输入: -优异的总谐波失真加噪声:0.0008%...

uniapp发开微信小程序处理手机物理按键逻辑
注意:wx.enableAlertBeforeUnload 需要微信小程序基础库 2.32.3 及以上版本如果版本不够,会发 fail 回调,在onLoad里面使用wx.enableAlertBeforeUnload开启物理返回键拦截在onUnload里面处理确认逻辑,wx.disableAlertBeforeUnload关闭物理返回键拦截监听…...

AI时代来临,键盘布局将迎来怎样的变革?
1. AI时代的硬件探索智能手机统治了过去十几年的数字生态,它是注意力的黑洞,是人们最私密的随身之物。但手机从设计之初就是为「人盯着它」而生的,其全部逻辑止于屏幕。而AI的需求却恰恰相反,它需要持续感知物理世界,见…...