Volcano Controller控制器源码解析
Volcano Controller控制器源码解析
本文从源码的角度分析Volcano Controller相关功能的实现。
本篇Volcano版本为v1.8.0。
Volcano项目地址: https://github.com/volcano-sh/volcano
controller命令main入口: cmd/controller-manager/main.go
controller相关代码目录: pkg/controllers
更多文章访问: https://www.cyisme.top
整体实现并不复杂, 而且项目比较简洁、风格一致(与k8s controller代码风格也一致)。可以作为学习开发k8s controller的一个参考。

代码风格
controller需要实现framework中interface的定义。
type Controller interface {Name() string// 初始化Initialize(opt *ControllerOption) error// 运行Run(stopCh <-chan struct{})
}
Initialize方法作为根据option初始化controller的入口, 像infomer设置、queue设置、cache设置等都在这里完成。
func (jf *jobflowcontroller) Initialize(opt *framework.ControllerOption) error {// clientjf.kubeClient = opt.KubeClientjf.vcClient = opt.VolcanoClient// informerjf.jobFlowInformer = informerfactory.NewSharedInformerFactory(jf.vcClient, 0).Flow().V1alpha1().JobFlows()jf.jobFlowSynced = jf.jobFlowInformer.Informer().HasSyncedjf.jobFlowLister = jf.jobFlowInformer.Lister()jf.jobFlowInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: jf.addJobFlow,UpdateFunc: jf.updateJobFlow,})// 参数jf.maxRequeueNum = opt.MaxRequeueNumif jf.maxRequeueNum < 0 {jf.maxRequeueNum = -1}// queuejf.queue = workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())// 入队的工具函数jf.enqueueJobFlow = jf.enqueue// 处理队列中数据的处理函数jf.syncHandler = jf.handleJobFlow// ...
}
Run方法会运行多个goroutine, 执行操作
func (jf *jobflowcontroller) Run(stopCh <-chan struct{}) {defer jf.queue.ShutDown()go jf.jobFlowInformer.Informer().Run(stopCh)go jf.jobTemplateInformer.Informer().Run(stopCh)go jf.jobInformer.Informer().Run(stopCh)cache.WaitForCacheSync(stopCh, jf.jobSynced, jf.jobFlowSynced, jf.jobTemplateSynced)// 使用 k8s pkg中的util , 与k8s controller的风格一致go wait.Until(jf.worker, time.Second, stopCh)klog.Infof("JobFlowController is running ...... ")<-stopCh
}
worker会负责处理队列中的数据, 交给handler处理。 vocalno中所有的controller外层都是这执行逻辑(可能会有细微差别), 具体的handler 是差异化的。所以后面的controller介绍也不会再提这一部分, 会着重handler的实现。
func (jf *jobflowcontroller) worker() {// 代理一层for jf.processNextWorkItem() {}
}func (jf *jobflowcontroller) processNextWorkItem() bool {// 获取数据obj, shutdown := jf.queue.Get()if shutdown {// Stop workingreturn false}defer jf.queue.Done(obj)req, ok := obj.(*apis.FlowRequest)if !ok {klog.Errorf("%v is not a valid queue request struct.", obj)return true}// 具体处理handlererr := jf.syncHandler(req)jf.handleJobFlowErr(err, obj)return true
}
Queue Controller
Queue Controler主要监听三个资源对象:
- Queue
- PodGroup
- Command
控制器会监听他们的状态,用以更新Queue资源的状态,从而实现依据Queue资源的调度。
func (c *queuecontroller) Initialize(opt *framework.ControllerOption) error {// 省略部分代码queueInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: c.addQueue,UpdateFunc: c.updateQueue,DeleteFunc: c.deleteQueue,})pgInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{// 省略部分代码})if utilfeature.DefaultFeatureGate.Enabled(features.QueueCommandSync) {c.cmdInformer = factory.Bus().V1alpha1().Commands()c.cmdInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{FilterFunc: func(obj interface{}) bool {switch v := obj.(type) {case *busv1alpha1.Command:return IsQueueReference(v.TargetObject)default:return false}},Handler: cache.ResourceEventHandlerFuncs{AddFunc: c.addCommand,},})c.cmdLister = c.cmdInformer.Lister()c.cmdSynced = c.cmdInformer.Informer().HasSynced}// 省略部分代码
}
监听到的消息会放到队列中, 队列是通过k8s pkg中的WorkQueue实现的。
type queuecontroller struct {// 省略部分代码// ...// queues that need to be updated.queue workqueue.RateLimitingInterfacecommandQueue workqueue.RateLimitingInterface// queue name -> podgroup namespace/namepodGroups map[string]map[string]struct{}// 省略部分代码// ...
}
queuecontroller.queue接收apis.Request对象作为消息,queuecontroller.commandQueue接收busv1alpha1.Command对象作为消息。
在经过queuecontroller.handlerCommand方法处理后, queuecontroller.commandQueue中的busv1alpha1.Command对象转换成apis.Request事件,放到queuecontroller.queue中统一处理。
func (c *queuecontroller) handleCommand(cmd *busv1alpha1.Command) error {// 接受处理, 删除commanderr := c.vcClient.BusV1alpha1().Commands(cmd.Namespace).Delete(context.TODO(), cmd.Name, metav1.DeleteOptions{})if err != nil {// 省略部分代码}// command对象中会有ownerReference, 从中提取queue对象名称req := &apis.Request{QueueName: cmd.TargetObject.Name,// CommandIssuedEvent是内部事件类型, 用户引发命令时, 会触发该事件Event: busv1alpha1.CommandIssuedEvent,Action: busv1alpha1.Action(cmd.Action),}// 将command事件转换成request事件,放到queue中c.enqueueQueue(req)return nil
}
queuecontroller.handleQueue是queuecontroller.queue的事件处理函数,主要是根据request事件的类型,调用不同的处理函数更新Queue资源的状态。
func (c *queuecontroller) handleQueue(req *apis.Request) error {// 这里的queue是k8s中的Queue资源对象queue, err := c.queueLister.Get(req.QueueName)if err != nil {// 省略部分代码}// 根据queue当前的状态, 生成不同执行器queueState := queuestate.NewState(queue)// 执行操作if err := queueState.Execute(req.Action); err != nil {// 省略部分代码}return nil
}
Queue资源有4中状态(QueueState), 四种状态分别对应四种执行器:
- Open --> openState
- Closed --> closedState
- Closing --> closingState
- Unknown --> unknownState
以closeState执行器为例,代码实现如下:(其他的执行器实现类似,不再举例)
type closedState struct {queue *v1beta1.Queue
}
func (cs *closedState) Execute(action v1alpha1.Action) error {switch action {// 开启动作case v1alpha1.OpenQueueAction:return OpenQueue(cs.queue, func(status *v1beta1.QueueStatus, podGroupList []string) {status.State = v1beta1.QueueStateOpen})// 关闭动作case v1alpha1.CloseQueueAction:return SyncQueue(cs.queue, func(status *v1beta1.QueueStatus, podGroupList []string) {status.State = v1beta1.QueueStateClosed})// 默认动作default:return SyncQueue(cs.queue, func(status *v1beta1.QueueStatus, podGroupList []string) {specState := cs.queue.Status.Stateif specState == v1beta1.QueueStateOpen {status.State = v1beta1.QueueStateOpenreturn}if specState == v1beta1.QueueStateClosed {status.State = v1beta1.QueueStateClosedreturn}status.State = v1beta1.QueueStateUnknown})}
}Queue资源在volcano中有4种动作(Action), 执行器中将根据动作执行不同的操作:
- EnqueueJob (这个动作执行器中没有用到)
- SyncQueue (这个动作执行器中执行默认操作)
- OpenQueue
- CloseQueue
实际上, 对应这三个动作会有三个处理函数,他们被定义为QueueActionFn类型
type QueueActionFn func(queue *v1beta1.Queue, fn UpdateQueueStatusFn) error
因为Queue资源可以重复的Close或者Open, 所以其实执行器中并没有拦截或者限制这种操作, 而是比较简单的对状态进行重置。
操作调用的函数如下:
closedState和closingState状态执行器中
openState状态执行器中
unknownState状态执行器中
可以看出, 执行逻辑:
- 如果当前状态与预期状态一致, 则调用
SyncQueue同步状态 - 如果当前状态与预期状态不一致, 则调用
OpenQueue或者CloseQueue更新状态 - 如果状态未知, 则调用
SyncQueue同步状态
然后来看一下具体的函数实现
// syncQueue主要是更新queue中podgroup的状态计数
func (c *queuecontroller) syncQueue(queue *schedulingv1beta1.Queue, updateStateFn state.UpdateQueueStatusFn) error {// 获取queue中的podgrouppodGroups := c.getPodGroups(queue.Name)queueStatus := schedulingv1beta1.QueueStatus{}for _, pgKey := range podGroups {// 获取podgroup对象pg, err := c.pgLister.PodGroups(ns).Get(name)// 更新计数器switch pg.Status.Phase {case schedulingv1beta1.PodGroupPending:queueStatus.Pending++case schedulingv1beta1.PodGroupRunning:queueStatus.Running++case schedulingv1beta1.PodGroupUnknown:queueStatus.Unknown++case schedulingv1beta1.PodGroupInqueue:queueStatus.Inqueue++}}// updateStateFn是在执行器中定义的函数, 用于更新queue的状态if updateStateFn != nil {updateStateFn(&queueStatus, podGroups)} else {queueStatus.State = queue.Status.State}// 省略部分代码// ...// 调用api更新queue的状态if _, err := c.vcClient.SchedulingV1beta1().Queues().UpdateStatus(context.TODO(), newQueue, metav1.UpdateOptions{}); err != nil {}return nil
}
func (c *queuecontroller) openQueue(queue *schedulingv1beta1.Queue, updateStateFn state.UpdateQueueStatusFn) error {newQueue := queue.DeepCopy()newQueue.Status.State = schedulingv1beta1.QueueStateOpen// 这里调用Update没有看懂, copy出来的对应应该除了状态,其他的都是一样的// 而Update方法是更新对象, 而不是更新状态if queue.Status.State != newQueue.Status.State {if _, err := c.vcClient.SchedulingV1beta1().Queues().Update(context.TODO(), newQueue, metav1.UpdateOptions{}); err != nil {c.recorder.Event(newQueue, v1.EventTypeWarning, string(v1alpha1.OpenQueueAction),fmt.Sprintf("Open queue failed for %v", err))return err}c.recorder.Event(newQueue, v1.EventTypeNormal, string(v1alpha1.OpenQueueAction), "Open queue succeed")} else {return nil}// 获取queue对象q, err := c.vcClient.SchedulingV1beta1().Queues().Get(context.TODO(), newQueue.Name, metav1.GetOptions{})newQueue = q.DeepCopy()// 执行操作if updateStateFn != nil {updateStateFn(&newQueue.Status, nil)} else {return fmt.Errorf("internal error, update state function should be provided")}// 调用api更新queue的状态if queue.Status.State != newQueue.Status.State {if _, err := c.vcClient.SchedulingV1beta1().Queues().UpdateStatus(context.TODO(), newQueue, metav1.UpdateOptions{}); err != nil {}}return nil
}
// closeQueue与之类似, 不再举例
PodGroup Controller
PodGroup Controller比较简单, 它负责为未指定PodGroup的Pod分配PodGroup。
func (pg *pgcontroller) processNextReq() bool {// 省略部分代码// 获取pod对象pod, err := pg.podLister.Pods(req.podNamespace).Get(req.podName)// 根据调度器名称过滤if !commonutil.Contains(pg.schedulerNames, pod.Spec.SchedulerName) {return true}// 如果pod已经有podgroup, 则不再处理if pod.Annotations != nil && pod.Annotations[scheduling.KubeGroupNameAnnotationKey] != "" {return true}// 为pod分配podgroupif err := pg.createNormalPodPGIfNotExist(pod); err != nil {// AddRateLimited将在一段时间后重新添加req到队列中pg.queue.AddRateLimited(req)return true}// 省略部分代码
}
func (pg *pgcontroller) createNormalPodPGIfNotExist(pod *v1.Pod) error {// pgname将以”podgroup-“开头pgName := helpers.GeneratePodgroupName(pod)if _, err := pg.pgLister.PodGroups(pod.Namespace).Get(pgName); err != nil {// podgroup不存在, 则创建if !apierrors.IsNotFound(err) {return err}// 省略了一些从pod中继承赋值的代码obj := &scheduling.PodGroup{ObjectMeta: metav1.ObjectMeta{// podgroup的ownerReference是podOwnerReferences: newPGOwnerReferences(pod),},Spec: scheduling.PodGroupSpec{// 最小成员数为1MinMember: 1,},Status: scheduling.PodGroupStatus{// 状态为pendingPhase: scheduling.PodGroupPending,},}// 继承pod的owner信息,写入到annotationspg.inheritUpperAnnotations(pod, obj)// 继承pod annotationsif queueName, ok := pod.Annotations[scheduling.QueueNameAnnotationKey]; ok {obj.Spec.Queue = queueName}// 省略annotations继承的代码// ...// 创建podgroupif _, err := pg.vcClient.SchedulingV1beta1().PodGroups(pod.Namespace).Create(context.TODO(), obj, metav1.CreateOptions{}); err != nil {}}// 如果存在pg,则更新pod的annotationsreturn pg.updatePodAnnotations(pod, pgName)
}
JobFlow Controller
JobFlow是在volcano 1.8之后引入的CRD对象, 它配合JobTemplate使用,用于vcjob任务的编排。
JobFlow Controller主要监听JobFlow和Job两个对象的变化, 并更新JobFlow的状态。
func (jf *jobflowcontroller) Initialize(opt *framework.ControllerOption) error {// ...jf.jobFlowInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: jf.addJobFlow,UpdateFunc: jf.updateJobFlow,})jf.jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{UpdateFunc: jf.updateJob,})// 省略部分代码
}
Job更新时,会判断是否属于JobFlow, 如果是,则将关联的JobFlow加入到队列。
func (jf *jobflowcontroller) updateJob(oldObj, newObj interface{}) {// ...if newJob.ResourceVersion == oldJob.ResourceVersion {return}jobFlowName := getJobFlowNameByJob(newJob)if jobFlowName == "" {return}req := &apis.FlowRequest{Namespace: newJob.Namespace,JobFlowName: jobFlowName,Action: jobflowv1alpha1.SyncJobFlowAction,Event: jobflowv1alpha1.OutOfSyncEvent,}jf.queue.Add(req)
}
放入队列的apis.FlowRequest对象,最终会由handleJobFlow函数处理, 然后根据当前JobFlow的状态,生成并调用不同执行器。(这里的运行逻辑和Queue的差不多)
func (jf *jobflowcontroller) handleJobFlow(req *apis.FlowRequest) error {// 省略部分代码// ...jobflow, err := jf.jobFlowLister.JobFlows(req.Namespace).Get(req.JobFlowName)// 根据jobflow的状态, 生成不同的执行器jobFlowState := jobflowstate.NewState(jobflow)if err := jobFlowState.Execute(req.Action); err != nil {}return nil
}
JobFlow有5种状态(Flow Phase), 分别对应5种执行器::
- Succeed --> succeedState
- Terminating --> terminatingState (这个状态的执行器并没有实际动作,因为资源即将释放)
- Failed --> failedState (这个状态的执行器并没有实际动作,因为状态异常)
- Running --> runningState
- Pending --> pendingState
JobFlow目前只有1种动作SyncJobFlow(Action), 由SyncJobFlow函数执行具体操作。
func (jf *jobflowcontroller) syncJobFlow(jobFlow *v1alpha1flow.JobFlow, updateStateFn state.UpdateJobFlowStatusFn) error {// ...// 如果当前jobflow的状态为succeed, 且job的保留策略为delete, 则删除所有由jobflow创建的jobif jobFlow.Spec.JobRetainPolicy == v1alpha1flow.Delete && jobFlow.Status.State.Phase == v1alpha1flow.Succeed {if err := jf.deleteAllJobsCreatedByJobFlow(jobFlow); err != nil {}return nil}// 根据jobflow中声明的jobtemplate创建job, 声明顺序即为创建顺序if err := jf.deployJob(jobFlow); err != nil {}// 获取jobflow下所有job的状态jobFlowStatus, err := jf.getAllJobStatus(jobFlow)if err != nil {return err}// 更新jobflow的状态jobFlow.Status = *jobFlowStatusupdateStateFn(&jobFlow.Status, len(jobFlow.Spec.Flows))_, err = jf.vcClient.FlowV1alpha1().JobFlows(jobFlow.Namespace).UpdateStatus(context.Background(), jobFlow, metav1.UpdateOptions{})return nil
}
func (jf *jobflowcontroller) deployJob(jobFlow *v1alpha1flow.JobFlow) error {for _, flow := range jobFlow.Spec.Flows {jobName := getJobName(jobFlow.Name, flow.Name)if _, err := jf.jobLister.Jobs(jobFlow.Namespace).Get(jobName); err != nil {if errors.IsNotFound(err) {// 如果job没有依赖, 则直接创建if flow.DependsOn == nil || flow.DependsOn.Targets == nil {// createJob根据jobtemplat创建job// 创建已经存在的job, 不会报错if err := jf.createJob(jobFlow, flow); err != nil {return err}} else {// 有依赖则判断依赖的job是否已经完成// 任何一个依赖的job未完成都不会创建flag, err := jf.judge(jobFlow, flow)if flag {if err := jf.createJob(jobFlow, flow); err != nil {return err}}}continue}return err}}return nil
}
Job Controller
Job是volcano中的核心资源对象, 为了避免与k8s中的Job对象混淆, 也会称之为vcjob或者vj。
Job Controller监听多个资源对象的变更事件:
func (cc *jobcontroller) Initialize(opt *framework.ControllerOption) error {// ...cc.jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: cc.addJob,UpdateFunc: cc.updateJob,DeleteFunc: cc.deleteJob,})cc.cmdInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{FilterFunc: func(obj interface{}) bool {switch v := obj.(type) {case *busv1alpha1.Command:if v.TargetObject != nil &&v.TargetObject.APIVersion == batchv1alpha1.SchemeGroupVersion.String() &&v.TargetObject.Kind == "Job" {return true}return falsedefault:return false}},Handler: cache.ResourceEventHandlerFuncs{AddFunc: cc.addCommand,},},)cc.podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{AddFunc: cc.addPod,UpdateFunc: cc.updatePod,DeleteFunc: cc.deletePod,})cc.pgInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{UpdateFunc: cc.updatePodGroup,})// ...
}
vcjob的处理量会比较大, 所以Job Controller会启动多个worker来处理事件, 每个worker会有属于自己的queue。
func (cc *jobcontroller) Run(stopCh <-chan struct{}) {// ...// commandQueue是用于处理busv1alpha1.Command对象的队列// 与Queue Controller中类似, 最终会转换成apis.Request对象, 放入queue中go wait.Until(cc.handleCommands, 0, stopCh)var i uint32// 启动多个workerfor i = 0; i < cc.workers; i++ {go func(num uint32) {wait.Until(func() {cc.worker(num)},time.Second,stopCh)}(i)}// cache用于缓存资源状态go cc.cache.Run(stopCh)// 处理错误taskgo wait.Until(cc.processResyncTask, 0, stopCh)// ...
}
新的事件会通过getWokerQueue函数来获取对应的queue, 然后放入队列中。
func (cc *jobcontroller) getWorkerQueue(key string) workqueue.RateLimitingInterface {// ...hashVal = fnv.New32()hashVal.Write([]byte(key))val = hashVal.Sum32()// 通过hash值取模来获取queuequeue := cc.queueList[val%cc.workers]return queue
}
command事件转换成request事件的过程与Queue Controller类似, 这里不再赘述。 queue中的数据处理是由processNextReq函数接收的。
func (cc *jobcontroller) processNextReq(count uint32) bool {// 获取queue, queue的数量与worker数量相同并一一对应queue := cc.queueList[count]req := obj.(apis.Request)key := jobcache.JobKeyByReq(&req)if !cc.belongsToThisRoutine(key, count) {// 这里做了校验, 如果key不属于当前worker, 则重新放入queue中queueLocal := cc.getWorkerQueue(key)queueLocal.Add(req)return true}jobInfo, err := cc.cache.Get(key)// state.NewState 这个名字见过很多次了, 用于生成执行器st := state.NewState(jobInfo)if st == nil {return true}// 获取当前需要执行的动作action := applyPolicies(jobInfo.Job, &req)// 非同步动作, 记录事件if action != busv1alpha1.SyncJobAction {cc.recordJobEvent(jobInfo.Job.Namespace, jobInfo.Job.Name, batchv1alpha1.ExecuteAction, fmt.Sprintf("Start to execute action %s ", action))}// 执行动作if err := st.Execute(action); err != nil {// 如果执行失败, 则根据重试次数, 决定是否重新放入queue中。// maxRequeueNum -1, 表示无限重试if cc.maxRequeueNum == -1 || queue.NumRequeues(req) < cc.maxRequeueNum {queue.AddRateLimited(req)return true}}// 如果执行成功, 则删除queue中的事件queue.Forget(req)return true
}
vcjob有10种状态(JobPhase), 对应8种执行器:
- Pending --> pendingState
- Aborting --> abortingState
- Aborted --> abortedState
- Running --> runningState
- Restarting --> restartingState
- Completing --> completingState
- Terminating --> terminatingState
- Terminated、Failed、Completed --> terminatedState
以abortedState为例, 代码实现如下:
func (as *abortedState) Execute(action v1alpha1.Action) error {switch action {case v1alpha1.ResumeJobAction:return KillJob(as.job, PodRetainPhaseSoft, func(status *vcbatch.JobStatus) bool {status.State.Phase = vcbatch.Restartingstatus.RetryCount++return true})default:return KillJob(as.job, PodRetainPhaseSoft, nil)}
}
vcjob有11种动作(Action), 执行器中将根据动作执行不同的操作:
- AbortJob 如果设置此操作,整个工作将被中止;所有作业的Pod都将被驱逐,并且不会重新创建任何Pod
- RestartJob 如果设置了此操作,整个作业将重新启动
- RestartTask 如果设置此操作,则仅重新启动任务;默认操作。
- TerminateJob 如果设置了此操作,整个工作将被终止并且无法恢复;所有作业的Pod都将被驱逐,并且不会重新创建任何Pod。
- CompleteJob 如果设置此操作,未完成的pod将被杀死,作业完成。
- ResumeJob 恢复中止的工作。
- SyncJob 同步Job/Pod状态的操作。(内部动作)
- EnqueueJob 同步作业入队状态的操作。(内部动作)
- SyncQueue 同步队列状态的操作。(内部动作)
- OpenQueue 打开队列的操作。(内部动作)
- CloseQueue 关闭队列的操作。(内部动作)
实际上, 对应这些动作会有不同的处理函数,他们被定义为ActionFn类型和KillActionFn类型。 这两个类型被声明为SyncJob和KillJob的函数,并被执行器调用。
type ActionFn func(job *apis.JobInfo, fn UpdateStatusFn) error
type KillActionFn func(job *apis.JobInfo, podRetainPhase PhaseMap, fn UpdateStatusFn) error
var (// SyncJob将根据Job的规范创建或删除Pod。SyncJob ActionFn// KillJob 将杀死状态不在podRetainPhase中的pod.KillJob KillActionFn
)
操作调用的函数如下:(虽然不同动作调用的操作可能相同, 但是会更新不同的状态信息)
pendingState和runningState状态执行器中:
restartingState状态执行器中, 直接调用KillJob。finishedState为最终状态, 所以不会执行任何动作。terminatingState直接调用KillJob。abortingState和abortedState状态执行器中:
completingState直接调用KillJob。
可以看出, 执行逻辑:
- 如果是干预vcjob状态的动作, 则调用
KillJob。 - 反之, 则调用
SyncJob。
然后来看一下具体实现函数。
killJob
killJob对应删除pod的操作。
func (cc *jobcontroller) killJob(jobInfo *apis.JobInfo, podRetainPhase state.PhaseMap, updateStatus state.UpdateStatusFn) error {// job已经处于删除状态, 则不再处理if job.DeletionTimestamp != nil {return nil}// 状态计数器, 用于更新job的状态var pending, running, terminating, succeeded, failed, unknown int32taskStatusCount := make(map[string]batch.TaskState)for _, pods := range jobInfo.Pods {for _, pod := range pods {total++if pod.DeletionTimestamp != nil {// pod处于删除状态, 则不再处理continue}maxRetry := job.Spec.MaxRetrylastRetry := false// 判断是否是最后一次重试if job.Status.RetryCount >= maxRetry-1 {lastRetry = true}// 如果是最后一次重试, 则保留失败和成功的podretainPhase := podRetainPhaseif lastRetry {// var PodRetainPhaseSoft = PhaseMap{// v1.PodSucceeded: {},// v1.PodFailed: {},// }retainPhase = state.PodRetainPhaseSoft}_, retain := retainPhase[pod.Status.Phase]// 如果不保留pod, 则删除podif !retain {err := cc.deleteJobPod(job.Name, pod)if err == nil {terminating++continue}// 失败放入重试队列errs = append(errs, err)cc.resyncTask(pod)}// 更新状态计数器classifyAndAddUpPodBaseOnPhase(pod, &pending, &running, &succeeded, &failed, &unknown)calcPodStatus(pod, taskStatusCount)}}if len(errs) != 0 {return fmt.Errorf("failed to kill %d pods of %d", len(errs), total)}// 更新job的状态计数job = job.DeepCopy()job.Status.Version++job.Status.Pending = pendingjob.Status.Running = runningjob.Status.Succeeded = succeededjob.Status.Failed = failedjob.Status.Terminating = terminatingjob.Status.Unknown = unknownjob.Status.TaskStatusCount = taskStatusCount// 更新运行持续时间job.Status.RunningDuration = &metav1.Duration{Duration: time.Since(jobInfo.Job.CreationTimestamp.Time)}// 更新job的状态if updateStatus != nil {if updateStatus(&job.Status) {job.Status.State.LastTransitionTime = metav1.Now()jobCondition := newCondition(job.Status.State.Phase, &job.Status.State.LastTransitionTime)job.Status.Conditions = append(job.Status.Conditions, jobCondition)}}// 执行删除插件if err := cc.pluginOnJobDelete(job); err != nil {return err}// 调用api更新job的状态newJob, err := cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).UpdateStatus(context.TODO(), job, metav1.UpdateOptions{})if err != nil {return err}if e := cc.cache.Update(newJob); e != nil {return e}// 删除podgrouppgName := job.Name + "-" + string(job.UID)if err := cc.vcClient.SchedulingV1beta1().PodGroups(job.Namespace).Delete(context.TODO(), pgName, metav1.DeleteOptions{}); err != nil {if !apierrors.IsNotFound(err) {return err}}return nil
}
syncJob
syncJob对应创建pod的操作。
func (cc *jobcontroller) syncJob(jobInfo *apis.JobInfo, updateStatus state.UpdateStatusFn) error {if jobInfo.Job.DeletionTimestamp != nil {return nil}// ...// 获取job的queue信息queueInfo, err := cc.GetQueueInfo(job.Spec.Queue)if err != nil {return err}var jobForwarding bool// ExtendClusters 这个属性没有找到介绍, 好像只在这里用到了if len(queueInfo.Spec.ExtendClusters) != 0 {jobForwarding = trueif len(job.Annotations) == 0 {job.Annotations = make(map[string]string)}job.Annotations[batch.JobForwardingKey] = "true"job, err = cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).Update(context.TODO(), job, metav1.UpdateOptions{})if err != nil {return err}}// 初始化jobif !isInitiated(job) {// initiateJob中会更新job状态、调用add插件、更新podgroupif job, err = cc.initiateJob(job); err != nil {return err}} else {// initOnJobUpdate会调用add插件、更新podgroupif err = cc.initOnJobUpdate(job); err != nil {return err}}// ... 省略 queueInfo.Spec.ExtendClusters 的处理var syncTask boolpgName := job.Name + "-" + string(job.UID)if pg, _ := cc.pgLister.PodGroups(job.Namespace).Get(pgName); pg != nil {if pg.Status.Phase != "" && pg.Status.Phase != scheduling.PodGroupPending {syncTask = true}// ...}var jobCondition batch.JobCondition// 如果包含刚创建的podgroup, 则更新job状态if !syncTask {if updateStatus != nil {if updateStatus(&job.Status) {job.Status.State.LastTransitionTime = metav1.Now()jobCondition = newCondition(job.Status.State.Phase, &job.Status.State.LastTransitionTime)job.Status.Conditions = append(job.Status.Conditions, jobCondition)}}newJob, err := cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).UpdateStatus(context.TODO(), job, metav1.UpdateOptions{})// ...return nil}// ... 省略一些计数声明代码// ...waitCreationGroup := sync.WaitGroup{}// 遍历job中的taskfor _, ts := range job.Spec.Tasks {// ...var podToCreateEachTask []*v1.Pod// 根据副本数, 创建或删除podfor i := 0; i < int(ts.Replicas); i++ {podName := fmt.Sprintf(jobhelpers.PodNameFmt, job.Name, name, i)if pod, found := pods[podName]; !found {newPod := createJobPod(job, tc, ts.TopologyPolicy, i, jobForwarding)if err := cc.pluginOnPodCreate(job, newPod); err != nil {return err}podToCreateEachTask = append(podToCreateEachTask, newPod)waitCreationGroup.Add(1)} else {delete(pods, podName)if pod.DeletionTimestamp != nil {atomic.AddInt32(&terminating, 1)continue}// 更新状态计数器classifyAndAddUpPodBaseOnPhase(pod, &pending, &running, &succeeded, &failed, &unknown)calcPodStatus(pod, taskStatusCount)}}// 统计需要创建和删除的podpodToCreate[ts.Name] = podToCreateEachTaskfor _, pod := range pods {podToDelete = append(podToDelete, pod)}}// 创建podfor taskName, podToCreateEachTask := range podToCreate {if len(podToCreateEachTask) == 0 {continue}go func(taskName string, podToCreateEachTask []*v1.Pod) {taskIndex := jobhelpers.GetTasklndexUnderJob(taskName, job)if job.Spec.Tasks[taskIndex].DependsOn != nil {// 统一判断依赖关系是否满足需求, 不满足则不创建podif !cc.waitDependsOnTaskMeetCondition(taskName, taskIndex, podToCreateEachTask, job) {for _, pod := range podToCreateEachTask {go func(pod *v1.Pod) {defer waitCreationGroup.Done()}(pod)}return}}// 执行创建for _, pod := range podToCreateEachTask {go func(pod *v1.Pod) {defer waitCreationGroup.Done()newPod, err := cc.kubeClient.CoreV1().Pods(pod.Namespace).Create(context.TODO(), pod, metav1.CreateOptions{})if err != nil && !apierrors.IsAlreadyExists(err) {appendError(&creationErrs, fmt.Errorf("failed to create pod %s, err: %#v", pod.Name, err))} else {classifyAndAddUpPodBaseOnPhase(newPod, &pending, &running, &succeeded, &failed, &unknown)calcPodStatus(pod, taskStatusCount)}}(pod)}}(taskName, podToCreateEachTask)}// 等待创建完成waitCreationGroup.Wait()if len(creationErrs) != 0 {return fmt.Errorf("failed to create %d pods of %d", len(creationErrs), len(podToCreate))}// 删除podfor _, pod := range podToDelete {go func(pod *v1.Pod) {defer waitDeletionGroup.Done()err := cc.deleteJobPod(job.Name, pod)if err != nil {appendError(&deletionErrs, err)cc.resyncTask(pod)} else {klog.V(3).Infof("Deleted Task <%s> of Job <%s/%s>",pod.Name, job.Namespace, job.Name)atomic.AddInt32(&terminating, 1)}}(pod)}// 等待删除完成waitDeletionGroup.Wait()if len(deletionErrs) != 0 {return fmt.Errorf("failed to delete %d pods of %d", len(deletionErrs), len(podToDelete))}job.Status = batch.JobStatus{State: job.Status.State,Pending: pending,Running: running,Succeeded: succeeded,Failed: failed,Terminating: terminating,Unknown: unknown,Version: job.Status.Version,MinAvailable: job.Spec.MinAvailable,TaskStatusCount: taskStatusCount,ControlledResources: job.Status.ControlledResources,Conditions: job.Status.Conditions,RetryCount: job.Status.RetryCount,}// 更新job状态if updateStatus != nil && updateStatus(&job.Status) {job.Status.State.LastTransitionTime = metav1.Now()jobCondition = newCondition(job.Status.State.Phase, &job.Status.State.LastTransitionTime)job.Status.Conditions = append(job.Status.Conditions, jobCondition)}// 调用api更新job状态newJob, err := cc.vcClient.BatchV1alpha1().Jobs(job.Namespace).UpdateStatus(context.TODO(), job, metav1.UpdateOptions{})if err != nil {klog.Errorf("Failed to update status of Job %v/%v: %v",job.Namespace, job.Name, err)return err}if e := cc.cache.Update(newJob); e != nil {return e}return nil
}
其他控制器
其他一些控制器因为逻辑比较简单,就不再从代码解析了:
jobTemplate controller监听vcjob和jobtemplate, 用于更新jobtemplate状态中的JobDependsOnList, 即有哪些vcjob依赖于该jobtemplate。jobTemplate被官方称之为vcjob的套壳(jobTemplate.spec = vcjob.spec), 目的是为了职责区分。gc controller监听具有.spec.ttlSecondsAfterFinished属性的vcjob, ttl过期则删除job。
相关文章:
Volcano Controller控制器源码解析
Volcano Controller控制器源码解析 本文从源码的角度分析Volcano Controller相关功能的实现。 本篇Volcano版本为v1.8.0。 Volcano项目地址: https://github.com/volcano-sh/volcano controller命令main入口: cmd/controller-manager/main.go controller相关代码目录: pkg/co…...
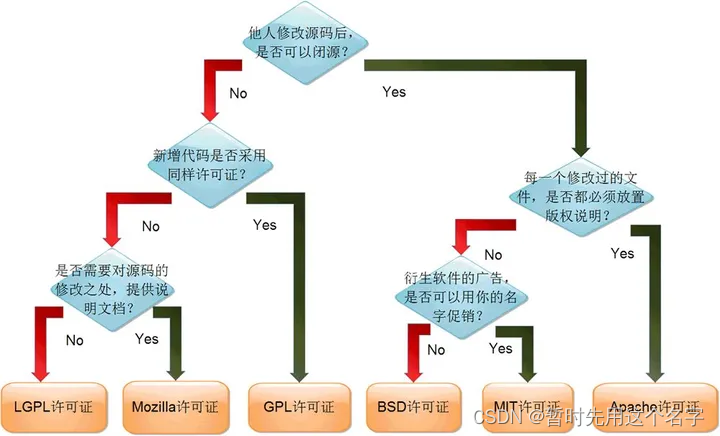
开源协议简介和选择
软件国产化已经提到日程上了,先来研究一下开源协议。 引言 在追求“自由”的开源软件领域的同时不能忽视程序员的权益。为了激发程序员的创造力,现今世界上有超过60种的开源许可协议被开源促进组织(Open Source Initiative)所认可…...

大创项目推荐 深度学习卫星遥感图像检测与识别 -opencv python 目标检测
文章目录 0 前言1 课题背景2 实现效果3 Yolov5算法4 数据处理和训练5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **深度学习卫星遥感图像检测与识别 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
pod的环节
pod 是k8s当中最小的资源管理组件 Pod也是最小化运行容器化的应用的资源管理对象 Pod是一个抽象化的概念,可以理解为一个或多个容器化的集合 在一个pod当中运行一个容器,是最常用的方式 在一个pod当中同时运行多个容器,在一个pod当中可以…...
Unity | Shader基础知识番外(向量数学知识速成)
目录 一、向量定义 二、计算向量 三、向量的加法(连续行走) 四、向量的长度 五、单位向量 六、向量的点积 1 计算 2 作用 七、向量的叉乘 1 承上启下 2 叉乘结论 3 叉乘的计算(这里看不懂就百度叉乘计算) 八、欢迎收…...

一个小白的微不足道的见解关于未来
随着科技的不断发展,IT行业日益壮大,运维工程师在其中扮演着至关重要的角色。他们负责维护和管理企业的技术基础设施,确保系统的正常运行。然而,随着技术的进步和行业的变化,运维工程师的未来将面临着一系列挑战和机遇…...
图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
一、图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次。(连通图与非连通图) 二、深度优先遍历(DFS); 1、访问指定的起始顶点; 2、若当前访问的顶点…...
抖店做不起来?新手常见起店失败问题总结,看下你中了几条?
我是王路飞。 能看到这篇文章的,肯定是处境符合标题内容了。 抖店的门槛很低,运营思路其实也不算难,但就是很多新手做不起来。 这中间,可能跟平台、项目没什么关系,而是跟你自己有关系,走错了方向&#…...

【每日面试题】精选java面试题之redis
Redis是什么?为什么要使用Redis? Redis是一个开源的高性能键值对存储数据库。它提供了多种数据结构,包括字符串、列表、集合、有序集合、哈希表等。Redis具有快速、可扩展、持久化、支持多种数据结构等特点,适用于缓存、消息队列…...
OSCP 靶场 - Vault
端口扫描 nmap nmap -O 192.168.162.172 smb枚举 smbmap(kali自带) //枚举GUEST用户可以使用的目录 smbmap -u GUEST -H 192.168.162.172 NTLMrelay—smbrelay 1.制作钓鱼文件 使用GitHub - xct/hashgrab: generate payloads that force authentication against an attacker…...

uniapp子组件向父组件传值
目录 子组件向父组件传值子组件1子组件2 父组件最后 子组件向父组件传值 子组件1 <template><view class"content"><view v-for"(item,index) in list" :key"index">{{item}}</view></view> </template>&…...

过滤特殊 微信昵称
$nickName preg_replace(/[\xf0-\xf7].{3}/, , $userData[nickName]);...

LLM、AGI、多模态AI 篇一:开源大语言模型简记
文章目录 系列开源大模型LlamaChinese-LLaMA-AlpacaLlama2-ChineseLinlyYaYiChatGLMtransformersGPT-3(未完全开源)BERTT5QwenBELLEMossBaichuan...

微信小程序中获取用户当前位置的解决方案
微信小程序中获取用户当前位置的解决方案 1 概述 微信小程序有时需要获取用户当前位置,以便为用户提供基于位置信息的服务(附近美食、出行方案等)。 获取用户当前位置的前提是用户手机需要打开 GPS 定位开关;其次,微…...
Vue3-35-路由-路由守卫的简单认识
什么是路由守卫 路由守卫,就是在 路由跳转 的过程中, 可以进行一些拦截,做一些逻辑判断, 控制该路由是否可以正常跳转的函数。常用的路由守卫有三个 : beforeEach() : 前置守卫,在路由 跳转前 就会被拦截&…...
制药企业符合CSV验证需要注意什么?
在制药行业中,计算机化系统验证(CSV)是确保生产过程的合规性和数据完整性的关键要素。通过CSV验证,制药企业可以保证其计算机化系统的可靠性和合规性,从而确保产品质量和患者安全。然而,符合CSV验证并不是一…...

再谈动态SQL
专栏精选 引入Mybatis Mybatis的快速入门 Mybatis的增删改查扩展功能说明 mapper映射的参数和结果 Mybatis复杂类型的结果映射 Mybatis基于注解的结果映射 Mybatis枚举类型处理和类型处理器 再谈动态SQL Mybatis配置入门 Mybatis行为配置之Ⅰ—缓存 Mybatis行为配置…...
【数据结构】树
一.二叉树的基本概念和性质: 1.二叉树的递归定义: 二叉树或为空树,或是由一个根结点加上两棵分别称为左子树和右子树的、互不相交的二叉树组成 2.二叉树的特点: (1)每个结点最多只有两棵子树࿰…...
【Midjourney】AI绘画新手教程(一)登录和创建服务器,生成第一幅画作
一、登录Discord 1、访问Discord官网 使用柯學尚网(亲测非必须,可加快响应速度)访问Discord官方网址:https://discord.com 选择“在您的浏览器中打开Discord” 然后,注册帐号、购买套餐等,在此不做缀述。…...

对比 PyTorch 和 TensorFlow:选择适合你的深度学习框架
目录 引言 深度学习在各行业中的应用 PyTorch 和 TensorFlow 简介 PyTorch:简介与设计理念 发展历史和背景 主要特点和设计理念 TensorFlow:简介与设计理念 发展历史和背景 主要特点和设计理念 PyTorch 和 TensorFlow 的重要性 Pytorch对比Te…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

基于 Next.js 的无头电商架构实战:从 Vercel Commerce 看现代全栈开发
1. 项目概述:一个面向未来的全栈电商起点如果你最近在琢磨着用 Next.js 搞一个电商网站,或者想找一个现代、开箱即用的全栈电商模板来启动项目,那你大概率已经听说过vercel/commerce这个仓库了。它不是某个具体的电商平台,而是一个…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

人性最残忍的真相是:你越不把自己当回事,别人就越不把你当回事
那个总给别人买贵东西的人,最后都怎么样了? 目录 那个总给别人买贵东西的人,最后都怎么样了? 我们为什么会忍不住过度付出? 真正的爱,从来都不是单方面的牺牲 爱自己,是所有健康关系的前提 昨天刷到一句话,瞬间戳中了我:“永远不要拿自己辛苦钱,去给别人买自己都舍不…...

轻量级协作平台设计:集成Git与敏捷开发的项目管理实践
1. 项目概述与核心价值最近在团队协作和项目管理工具选型上,又和几个技术负责人聊了一圈。大家普遍的感受是,市面上的工具要么太重,像Jira、Confluence,配置复杂,学习成本高,小团队用起来像“杀鸡用牛刀”&…...

3D打印LED发光史莱姆:零焊接电子制作与创意材料科学实践
1. 项目概述:当电子制作遇上创意手工几年前,我在一个社区创客空间带孩子们做活动,发现一个挺有意思的现象:一讲到电路、LED、电阻,不少孩子眼神就开始飘忽;但一旦拿出会发光的、可以随意揉捏的“史莱姆”泥…...