Prometheus-AlertManager 邮件告警
环境,软件准备
本次演示环境,我是在虚拟机上安装 Linux 系统来执行操作,以下是安装的软件及版本:
- System: CentOS Linux release 7.6
- Docker: 24.0.5
- Prometheus: v2.37.6
- Consul: 1.6.1
docker 安装prometheus,alertmanage,说明一下这里直接将exporter,grafana等组件一起安装完成.
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus]$cat docker-compose.yaml
version: '3.3'volumes:prometheus_data: {}grafana_data: {}networks:monitoring:driver: bridgeservices:prometheus:image: prom/prometheus:v2.37.6container_name: prometheusrestart: alwaysvolumes:- /etc/localtime:/etc/localtime:ro- ./prometheus/:/etc/prometheus/- prometheus_data:/prometheuscommand:- '--config.file=/etc/prometheus/prometheus.yml'- '--storage.tsdb.path=/prometheus'- '--web.console.libraries=/usr/share/prometheus/console_libraries'- '--web.console.templates=/usr/share/prometheus/consoles'#热加载配置- '--web.enable-lifecycle'#api配置#- '--web.enable-admin-api'#历史数据最大保留时间,默认15天- '--storage.tsdb.retention.time=30d'networks:- monitoringlinks:- alertmanager- cadvisor- node_exporterexpose:- '9090'ports:- 9090:9090depends_on:- cadvisoralertmanager:image: prom/alertmanager:v0.25.0container_name: alertmanagerrestart: alwaysvolumes:- /etc/localtime:/etc/localtime:ro- ./alertmanager/:/etc/alertmanager/command:- '--config.file=/etc/alertmanager/config.yml'- '--storage.path=/alertmanager'networks:- monitoringexpose:- '9093'ports:- 9093:9093cadvisor:image: google/cadvisor:latestcontainer_name: cadvisorrestart: alwaysvolumes:- /etc/localtime:/etc/localtime:ro- /:/rootfs:ro- /var/run:/var/run:rw- /sys:/sys:ro- /var/lib/docker/:/var/lib/docker:ronetworks:- monitoringexpose:- '8080'node_exporter:image: prom/node-exporter:v1.5.0container_name: node-exporterrestart: alwaysvolumes:- /etc/localtime:/etc/localtime:ro- /proc:/host/proc:ro- /sys:/host/sys:ro- /:/rootfs:rocommand:- '--path.procfs=/host/proc'- '--path.sysfs=/host/sys'- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc|rootfs/var/lib/docker)($$|/)'networks:- monitoringports:- '9100:9100'grafana:image: registry.cn-beijing.aliyuncs.com/scorpio/grafana-cn:v9.4.0container_name: grafanarestart: alwaysvolumes:- /etc/localtime:/etc/localtime:ro- grafana_data:/var/lib/grafana- ./grafana/provisioning/:/etc/grafana/provisioning/env_file:- ./grafana/config.monitoringnetworks:- monitoringlinks:- prometheusports:- 3000:3000depends_on:- prometheus
docker-compose中将部分容器的配置文件目录映射到了宿主机上做了持久化.方便修改配置项.
创建prometheus配置文件.*这里rule_files:下面的事报警触发器配置.可以是单个文件.也可以是整个目录.生产环境中可能会有多个目录进行报警的触发配置.
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/prometheus]$cat prometheus.yml
# 全局配置
global:scrape_interval: 15s # 将搜刮间隔设置为每15秒一次。默认是每1分钟一次。evaluation_interval: 15s # 每15秒评估一次规则。默认是每1分钟一次。# Alertmanager 配置
alerting:alertmanagers:- static_configs:- targets: ['alertmanager:9093']# 报警(触发器)配置
rule_files:- "alert.yml"- "rules/*.yml"# 搜刮配置
scrape_configs:- job_name: 'prometheus'# 覆盖全局默认值,每15秒从该作业中刮取一次目标scrape_interval: 15sstatic_configs:- targets: ['192.168.75.41:9090']- job_name: 'alertmanager'# 覆盖全局默认值,每15秒从该作业中刮取一次目标scrape_interval: 15sstatic_configs:- targets: ['alertmanager:9093']- job_name: 'node-exporter'consul_sd_configs:- server: '192.168.75.41:8500'services: []relabel_configs:- source_labels: [__meta_consul_tags]regex: .*node-exporter.*action: keep- regex: __meta_consul_service_metadata_(.+)action: labelmap创建node-exporter的监控项信息,
说明一下.为了后面的报警触发,这里将没存利用率设置为只要内存可用率大于10就触发报警.(其实就是node-exporter中的一堆监控项的运算组合.)最后达到预期的阈值就会进行报警.
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/prometheus]$cat alert.yml
groups:
- name: node-exporterrules:- alert: HostOutOfMemory
# expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 10for: 1mlabels:severity: warningannotations:summary: "主机内存不足,实例:{{ $labels.instance }}"
# description: "内存可用率<10%,当前值:{{ $value }}"description: "内存可用率>10%,当前值:{{ $value }}"- alert: HostMemoryUnderMemoryPressureexpr: rate(node_vmstat_pgmajfault[1m]) > 1000for: 2mlabels:severity: warningannotations:summary: "内存压力不足,实例:{{ $labels.instance }}"description: "节点内存压力大。 重大页面错误率高,当前值为:{{ $value }}"- alert: HostUnusualNetworkThroughputInexpr: sum by (instance) (rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100for: 5mlabels:severity: warningannotations:summary: "异常流入网络吞吐量,实例:{{ $labels.instance }}"description: "网络流入流量 > 100 MB/s,当前值:{{ $value }}"- alert: HostUnusualNetworkThroughputOutexpr: sum by (instance) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100for: 5mlabels:severity: warningannotations:summary: "异常流出网络吞吐量,实例:{{ $labels.instance }}"description: "网络流出流量 > 100 MB/s,当前值为:{{ $value }}"- alert: HostUnusualDiskReadRateexpr: sum by (instance) (rate(node_disk_read_bytes_total[2m])) / 1024 / 1024 > 50for: 5mlabels:severity: warningannotations:summary: "异常磁盘读取,实例:{{ $labels.instance }}"description: "磁盘读取> 50 MB/s,当前值:{{ $value }}"- alert: HostUnusualDiskWriteRateexpr: sum by (instance) (rate(node_disk_written_bytes_total[2m])) / 1024 / 1024 > 50for: 2mlabels:severity: warningannotations:summary: "异常磁盘写入,实例:{{ $labels.instance }}"description: "磁盘写入> 50 MB/s,当前值:{{ $value }}"- alert: HostOutOfDiskSpaceexpr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0for: 2mlabels:severity: warningannotations:summary: "磁盘空间不足告警,实例:{{ $labels.instance }}"description: "剩余磁盘空间< 10% ,当前值:{{ $value }}"- alert: HostDiskWillFillIn24Hoursexpr: (node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs"}[1h], 24 * 3600) < 0 and ON (instance, device, mountpoint) node_filesystem_readonly == 0for: 2mlabels:severity: warningannotations:summary: "磁盘空间将在24小时内耗尽,实例:{{ $labels.instance }}"description: "以当前写入速率预计磁盘空间将在 24 小时内耗尽,当前值:{{ $value }}"- alert: HostOutOfInodesexpr: node_filesystem_files_free{mountpoint ="/"} / node_filesystem_files{mountpoint="/"} * 100 < 10 and ON (instance, device, mountpoint) node_filesystem_readonly{mountpoint="/"} == 0for: 2mlabels:severity: warningannotations:summary: "磁盘Inodes不足,实例:{{ $labels.instance }}"description: "剩余磁盘 inodes < 10%,当前值: {{ $value }}"- alert: HostUnusualDiskReadLatencyexpr: rate(node_disk_read_time_seconds_total[1m]) / rate(node_disk_reads_completed_total[1m]) > 0.1 and rate(node_disk_reads_completed_total[1m]) > 0for: 2mlabels:severity: warningannotations:summary: "异常磁盘读取延迟,实例:{{ $labels.instance }}"description: "磁盘读取延迟 > 100ms,当前值:{{ $value }}"- alert: HostUnusualDiskWriteLatencyexpr: rate(node_disk_write_time_seconds_total[1m]) / rate(node_disk_writes_completed_total[1m]) > 0.1 and rate(node_disk_writes_completed_total[1m]) > 0for: 2mlabels:severity: warningannotations:summary: "异常磁盘写入延迟,实例:{{ $labels.instance }}"description: "磁盘写入延迟 > 100ms,当前值:{{ $value }}"- alert: high_loadexpr: node_load1 > 4for: 2mlabels:severity: pageannotations:summary: "CPU1分钟负载过高,实例:{{ $labels.instance }}"description: "CPU1分钟负载>4,已经持续2分钟。当前值为:{{ $value }}"- alert: HostCpuIsUnderUtilizedexpr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80for: 1mlabels:severity: warningannotations:summary: "cpu负载高,实例:{{ $labels.instance }}"description: "cpu负载> 80%,当前值:{{ $value }}"- alert: HostCpuStealNoisyNeighborexpr: avg by(instance) (rate(node_cpu_seconds_total{mode="steal"}[5m])) * 100 > 10for: 0mlabels:severity: warningannotations:summary: "CPU窃取率异常,实例:{{ $labels.instance }}"description: "CPU 窃取率 > 10%。 嘈杂的邻居正在扼杀 VM 性能,或者 Spot 实例可能失去信用,当前值:{{ $value }}"- alert: HostSwapIsFillingUpexpr: (1 - (node_memory_SwapFree_bytes / node_memory_SwapTotal_bytes)) * 100 > 80for: 2mlabels:severity: warningannotations:summary: "磁盘swap空间使用率异常,实例:{{ $labels.instance }}"description: "磁盘swap空间使用率>80%"- alert: HostNetworkReceiveErrorsexpr: rate(node_network_receive_errs_total[2m]) / rate(node_network_receive_packets_total[2m]) > 0.01for: 2mlabels:severity: warningannotations:summary: "异常网络接收错误,实例:{{ $labels.instance }}"description: "网卡{{ $labels.device }}在过去2分钟接收错误率大于0.01,当前值:{{ $value }}"- alert: HostNetworkTransmitErrorsexpr: rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01for: 2mlabels:severity: warningannotations:summary: "异常网络传输错误,实例:{{ $labels.instance }}"description: "网卡{{ $labels.device }}在过去2分钟传输错误率大于0.01,当前值:{{ $value }}"- alert: HostNetworkInterfaceSaturatedexpr: (rate(node_network_receive_bytes_total{device!~"^tap.*"}[1m]) + rate(node_network_transmit_bytes_total{device!~"^tap.*"}[1m])) / node_network_speed_bytes{device!~"^tap.*"} > 0.8 < 10000for: 1mlabels:severity: warningannotations:summary: "异常网络接口饱和,实例:{{ $labels.instance }}"description: "网卡{{ $labels.device }}正在超载,当前值{{ $value }}"- alert: HostConntrackLimitexpr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8for: 5mlabels:severity: warningannotations:summary: "异常连接数,实例:{{ $labels.instance }}"description: "连接数过大,当前连接数:{{ $value }}"- alert: HostClockSkewexpr: (node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0) or (node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0)for: 2mlabels:severity: warningannotations:summary: "异常时钟偏差,实例:{{ $labels.instance }}"description: "检测到时钟偏差,时钟不同步。值为:{{ $value }}"- alert: HostClockNotSynchronisingexpr: min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16for: 2mlabels:severity: warningannotations:summary: "时钟不同步,实例:{{ $labels.instance }}"description: "时钟不同步"- alert: NodeFileDescriptorLimitexpr: node_filefd_allocated / node_filefd_maximum * 100 > 80for: 1mlabels:severity: warningannotations:summary: "预计内核将很快耗尽文件描述符限制"description: "{{ $labels.instance }}}已分配的文件描述符数超过了限制的80%,当前值为:{{ $value }}"
配置alertmanage的全局报警配置信息.
[root@node1-prome /zpf/k8s/prometheus/docker-prometheus/alertmanager]$cat config.yml
global:#163服务器smtp_smarthost: 'smtp.qq.com:465'#发邮件的邮箱smtp_from: 'xxxx@qq.com'#发邮件的邮箱用户名,也就是你的邮箱smtp_auth_username: 'xxxx@qq.com'#发邮件的邮箱密码(注意一下这里并不是你qq账号的密码,而是邮箱生产的一个第三方登陆的密码.一般来说可能是十几位的组合形式.具体方法自行查找相关文档smtp_auth_password: 'asdalsdjlk'#进行tls验证smtp_require_tls: falseroute:group_by: ['warn']# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去group_wait: 10s# 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待group_interval配置的时间才可以发送出去group_interval: 10s# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval配置的时间再次发送告警数据repeat_interval: 10m# 全局报警组,这个参数是必选的,意思就是上面是发件人以及告警服务器相关信息,下面是接收人相关信息.receiver: emailreceivers:
- name: 'email' #报警组名称#收邮件的邮箱email_configs:- to: 'xxxxxx@163.com' #收件邮箱
inhibit_rules:- source_match: #表示抑制规则的定义.原匹配条件.severity: 'critical' #事件级别是紧急target_match: #severity: 'warning' #事件严重性equal: ['alertname', 'dev', 'instance'] #匹配规则.
当告警的源匹配条件中的严重性级别为'critical',并且目标匹配条件中的严重性级别为'warning',同时源匹配条件和目标匹配条件的标签值都相等时,该告警将被抑制.不是太明白为啥会有两个级别.得再研究研究.
重启alertmanager加载配置信息(一般我会重启服务来让配置重新加载.)
等待告警邮件发送,
查看告警信息
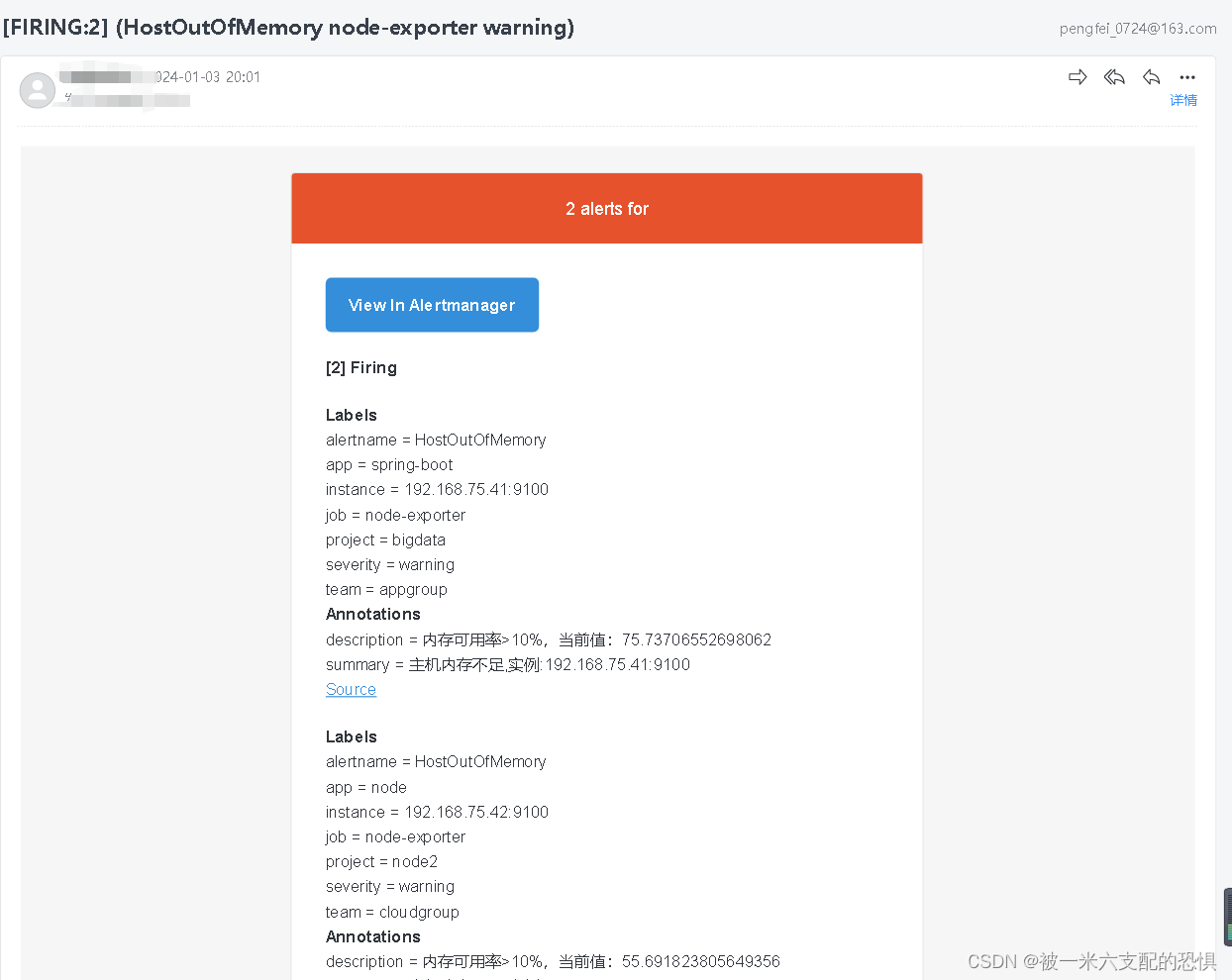
相关文章:
Prometheus-AlertManager 邮件告警
环境,软件准备 本次演示环境,我是在虚拟机上安装 Linux 系统来执行操作,以下是安装的软件及版本: System: CentOS Linux release 7.6Docker: 24.0.5Prometheus: v2.37.6Consul: 1.6.1 docker 安装prometheus,alertmanage,说明一下这里直接将…...

Volcano Controller控制器源码解析
Volcano Controller控制器源码解析 本文从源码的角度分析Volcano Controller相关功能的实现。 本篇Volcano版本为v1.8.0。 Volcano项目地址: https://github.com/volcano-sh/volcano controller命令main入口: cmd/controller-manager/main.go controller相关代码目录: pkg/co…...
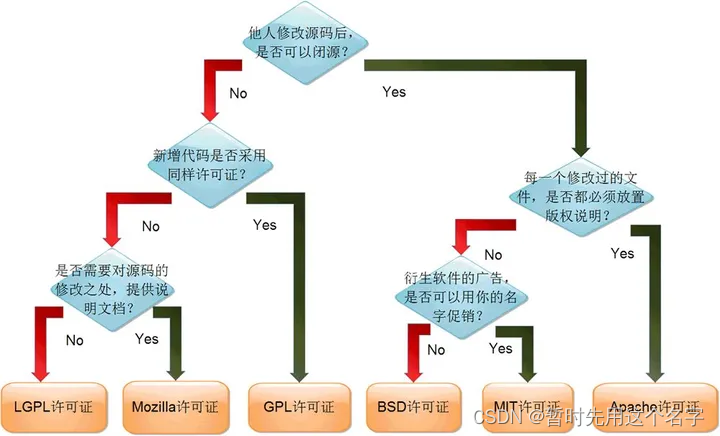
开源协议简介和选择
软件国产化已经提到日程上了,先来研究一下开源协议。 引言 在追求“自由”的开源软件领域的同时不能忽视程序员的权益。为了激发程序员的创造力,现今世界上有超过60种的开源许可协议被开源促进组织(Open Source Initiative)所认可…...

大创项目推荐 深度学习卫星遥感图像检测与识别 -opencv python 目标检测
文章目录 0 前言1 课题背景2 实现效果3 Yolov5算法4 数据处理和训练5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **深度学习卫星遥感图像检测与识别 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
pod的环节
pod 是k8s当中最小的资源管理组件 Pod也是最小化运行容器化的应用的资源管理对象 Pod是一个抽象化的概念,可以理解为一个或多个容器化的集合 在一个pod当中运行一个容器,是最常用的方式 在一个pod当中同时运行多个容器,在一个pod当中可以…...
Unity | Shader基础知识番外(向量数学知识速成)
目录 一、向量定义 二、计算向量 三、向量的加法(连续行走) 四、向量的长度 五、单位向量 六、向量的点积 1 计算 2 作用 七、向量的叉乘 1 承上启下 2 叉乘结论 3 叉乘的计算(这里看不懂就百度叉乘计算) 八、欢迎收…...

一个小白的微不足道的见解关于未来
随着科技的不断发展,IT行业日益壮大,运维工程师在其中扮演着至关重要的角色。他们负责维护和管理企业的技术基础设施,确保系统的正常运行。然而,随着技术的进步和行业的变化,运维工程师的未来将面临着一系列挑战和机遇…...
图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
一、图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次。(连通图与非连通图) 二、深度优先遍历(DFS); 1、访问指定的起始顶点; 2、若当前访问的顶点…...
抖店做不起来?新手常见起店失败问题总结,看下你中了几条?
我是王路飞。 能看到这篇文章的,肯定是处境符合标题内容了。 抖店的门槛很低,运营思路其实也不算难,但就是很多新手做不起来。 这中间,可能跟平台、项目没什么关系,而是跟你自己有关系,走错了方向&#…...

【每日面试题】精选java面试题之redis
Redis是什么?为什么要使用Redis? Redis是一个开源的高性能键值对存储数据库。它提供了多种数据结构,包括字符串、列表、集合、有序集合、哈希表等。Redis具有快速、可扩展、持久化、支持多种数据结构等特点,适用于缓存、消息队列…...
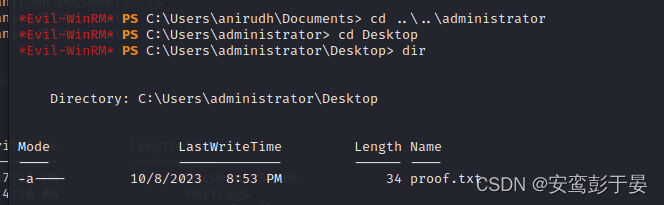
OSCP 靶场 - Vault
端口扫描 nmap nmap -O 192.168.162.172 smb枚举 smbmap(kali自带) //枚举GUEST用户可以使用的目录 smbmap -u GUEST -H 192.168.162.172 NTLMrelay—smbrelay 1.制作钓鱼文件 使用GitHub - xct/hashgrab: generate payloads that force authentication against an attacker…...

uniapp子组件向父组件传值
目录 子组件向父组件传值子组件1子组件2 父组件最后 子组件向父组件传值 子组件1 <template><view class"content"><view v-for"(item,index) in list" :key"index">{{item}}</view></view> </template>&…...

过滤特殊 微信昵称
$nickName preg_replace(/[\xf0-\xf7].{3}/, , $userData[nickName]);...

LLM、AGI、多模态AI 篇一:开源大语言模型简记
文章目录 系列开源大模型LlamaChinese-LLaMA-AlpacaLlama2-ChineseLinlyYaYiChatGLMtransformersGPT-3(未完全开源)BERTT5QwenBELLEMossBaichuan...

微信小程序中获取用户当前位置的解决方案
微信小程序中获取用户当前位置的解决方案 1 概述 微信小程序有时需要获取用户当前位置,以便为用户提供基于位置信息的服务(附近美食、出行方案等)。 获取用户当前位置的前提是用户手机需要打开 GPS 定位开关;其次,微…...
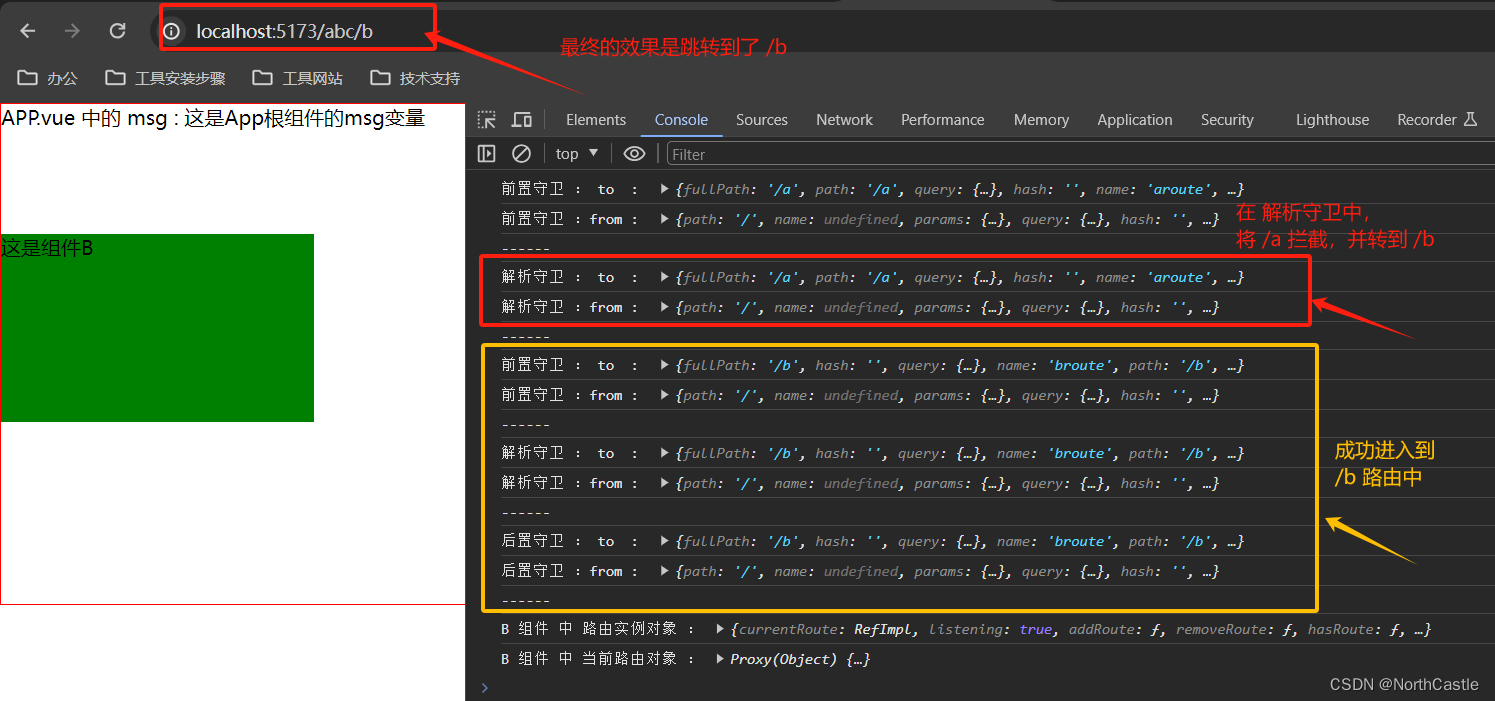
Vue3-35-路由-路由守卫的简单认识
什么是路由守卫 路由守卫,就是在 路由跳转 的过程中, 可以进行一些拦截,做一些逻辑判断, 控制该路由是否可以正常跳转的函数。常用的路由守卫有三个 : beforeEach() : 前置守卫,在路由 跳转前 就会被拦截&…...
制药企业符合CSV验证需要注意什么?
在制药行业中,计算机化系统验证(CSV)是确保生产过程的合规性和数据完整性的关键要素。通过CSV验证,制药企业可以保证其计算机化系统的可靠性和合规性,从而确保产品质量和患者安全。然而,符合CSV验证并不是一…...

再谈动态SQL
专栏精选 引入Mybatis Mybatis的快速入门 Mybatis的增删改查扩展功能说明 mapper映射的参数和结果 Mybatis复杂类型的结果映射 Mybatis基于注解的结果映射 Mybatis枚举类型处理和类型处理器 再谈动态SQL Mybatis配置入门 Mybatis行为配置之Ⅰ—缓存 Mybatis行为配置…...
【数据结构】树
一.二叉树的基本概念和性质: 1.二叉树的递归定义: 二叉树或为空树,或是由一个根结点加上两棵分别称为左子树和右子树的、互不相交的二叉树组成 2.二叉树的特点: (1)每个结点最多只有两棵子树࿰…...
【Midjourney】AI绘画新手教程(一)登录和创建服务器,生成第一幅画作
一、登录Discord 1、访问Discord官网 使用柯學尚网(亲测非必须,可加快响应速度)访问Discord官方网址:https://discord.com 选择“在您的浏览器中打开Discord” 然后,注册帐号、购买套餐等,在此不做缀述。…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

AI助手开发实战:从资源索引到生产级系统搭建指南
1. 项目概述:一个为AI助手开发者准备的“藏宝图” 如果你正在开发一个AI助手应用,或者正打算将大语言模型的能力集成到你的产品里,那你大概率会遇到一个经典难题:面对市面上眼花缭乱的模型、API和工具,我到底该怎么选&…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

揭秘Midjourney“树胶重铬酸盐”风格指令:3步精准触发古典印相质感,92%用户从未用对的隐藏参数组合
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的光学原理与数字映射本质 树胶重铬酸盐(Gum Bichromate)工艺是19世纪末发展起来的经典光敏印相技术,其核心光学原理基于重铬酸盐在紫外光照射下发生…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...