【霹雳吧啦】手把手带你入门语义分割の番外11:U2-Net 源码讲解(PyTorch)—— 代码的使用
目录
前言
Preparation
一、U2-Net 网络结构图
二、U2-Net 网络源代码
1、train.py
(1)parse_args 参数
(2)SODPresetTrain 类
(3)SODPresetEval 类
(4)main 函数
(5)train.py 源代码
前言
文章性质:学习笔记 📖
视频教程:U2-Net 源码解析(Pytorch)- 1 代码的使用
主要内容:根据 视频教程 中提供的 U2-Net 源代码(PyTorch),对 train.py 文件进行具体讲解。
Preparation
源代码:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_segmentation/u2net
在原官方的代码中只提供了训练脚本,并且训练脚本中没有提供验证功能,也就是说,只能去训练,而不知道它具体的验证指标。但在霹雳吧啦提供的项目代码中,补充了 评价验证指标 的功能。

U2-Net 的文件结构:
├── src: 搭建网络相关代码
├── train_utils: 训练以及验证相关代码
├── my_dataset.py: 自定义数据集读取相关代码
├── predict.py: 简易的预测代码
├── train.py: 单GPU或CPU训练代码
├── train_multi_GPU.py: 多GPU并行训练代码
├── validation.py: 单独验证模型相关代码
├── transforms.py: 数据预处理相关代码
└── requirements.txt: 项目依赖
【说明】validation.py 文件中是可以用来单独验证模型相关代码,在我们的训练样本中也包含了验证部分代码,只不过在 validation.py 这个文件中单独将验证部分的内容提取出来了。

【说明】霹雳吧啦搭建网络的方法与官方的仓库代码有所不同,按照霹雳吧啦提供的代码去搭建网络后,权重的名称将发生变化,因此提供了转换好的模型权重,分别是标准的 u2net_full.pth 和轻量的 u2net_lite.pth 。
一、U2-Net 网络结构图
原论文提供的 U2-Net 网络结构图如下所示:
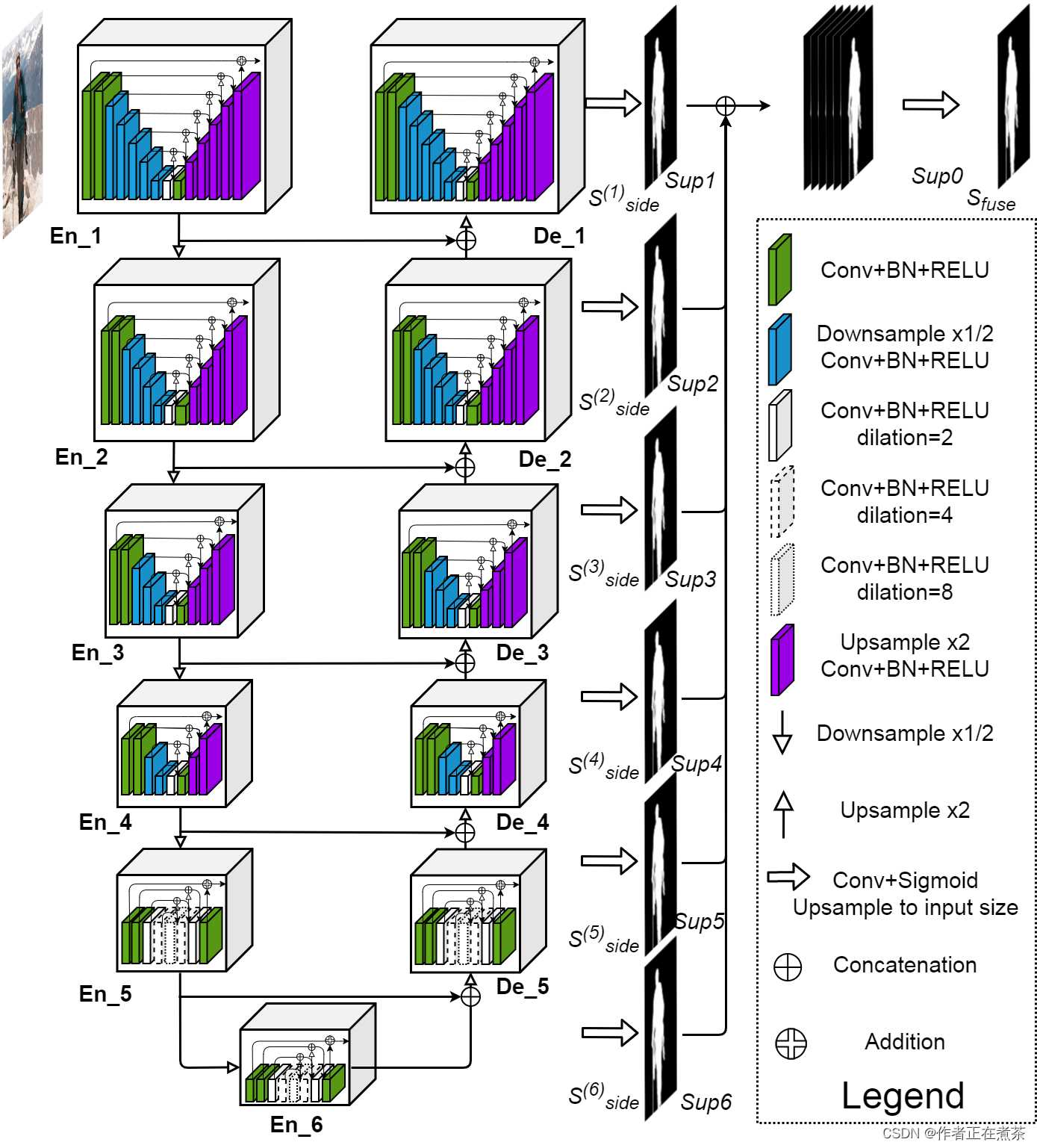
二、U2-Net 网络源代码
1、train.py
(1)parse_args 参数

【代码解析】对 parse_args 参数设置的具体讲解(结合上图):
- data-path 指向 DUTS 数据集的根目录
- device 默认值设置为 cuda,若是有 GPU 则默认使用第一块 GPU 进行训练,否则默认使用 CPU 进行训练
- batch-size 默认值设置为 16
- weight-decay 是指权重衰减,是设置优化器时的超参数
- epochs 默认值设置为 360,也就是进行 360 轮训练
- eval-interval 默认值设置为 10,也就是每训练 10 轮进行一次验证
- lr 是指初始学习率,默认值设置为 0.001
- print-freq 用于设置打印输出的频率,默认值设置为 50
- resume 是指在训练中由于某些原因导致训练中断,将 default 参数设置为最近一次保存的权重,从而能够接着往后进行训练
- start-epoch 是指默认从第几个 epoch 开始训练,默认值设置为 0
- amp 表示是否去使用混合精度训练,使用混合精度训练能够加速训练过程,并且对显存的占用也更少
(2)SODPresetTrain 类
SODPresetTrain 类对应了训练集的预处理以及数据增强的部分。

【代码解析】对 SODPresetTrain 类代码的具体讲解(结合上图):
在初始化 __init__ 方法中,传入了基础尺寸 base_size、裁剪后的尺寸 crop_size、水平翻转的概率 hflip_prob、图像每个通道的均值 mean、图像每个通道的标准差 std 等参数。在初始化 __init__ 方法中,定义了一个 transforms 变量,并使用 torchvision.transforms.Compose 函数,将多个图像变换操作 组合 在一起,这些变换操作包括:
- T.ToTensor() 可将 PIL 图像或数组转换为张量(Tensor)形式
- T.Resize(base_size, resize_mask=True) 将图像缩放到 base_size 尺寸,因为 resize_mask 为 True ,对 target 目标也进行相应缩放
- T.RandomCrop(crop_size) 将图像和 target 目标进行随机裁剪,裁剪成 crop_size 尺寸
- T.RandomHorizontalFlip(hflip_prob) 将图像和 target 目标进行水平方向上的随机翻转,从而增加数据的多样性
- T.Normalize(mean=mean, std=std) 使用给定的 mean 均值和 std 标准差对图像进行归一化
在 __call__ 方法中,将输入的图像和目标都传递给之前定义的 transforms 变量,实现对图像和目标的数据预处理,最终返回其结果。
(3)SODPresetEval 类
SODPresetEval 类对应了验证集的预处理以及数据增强的部分。

【代码解析】对 SODPresetEval 类代码的具体讲解(结合上图):
在初始化 __init__ 方法中,传入了基础尺寸 base_size、图像每个通道的均值 mean、图像每个通道的标准差 std 等参数。在初始化 __init__ 方法中,定义了一个 transforms 变量,并使用 torchvision.transforms.Compose 函数,将多个图像变换操作 组合 在一起,这些变换操作包括:
- T.ToTensor() 可将 PIL 图像或数组转换为张量(Tensor)形式
- T.Resize(base_size, resize_mask=False) 将图像缩放到 base_size 尺寸,由于 resize_mask 为 False,不对 target 目标也进行相应缩放
- T.Normalize(mean=mean, std=std) 使用给定的 mean 均值和 std 标准差对图像进行归一化
在 __call__ 方法中,将输入的图像和目标都传递给之前定义的 transforms 变量,实现对图像和目标的数据预处理,最终返回其结果。
(4)main 函数

【代码解析1】对 main 主函数代码的具体讲解(结合上图):
- 检查我们所使用的机器中是否有可用的 GPU 设备,若有则按照传入的 device 去利用对应的 GPU 设备,否则默认使用 CPU
- 根据时间戳去生成 results{}.txt 文件,后续会将训练结果保存到这个文件中
- 用 DUTSDataset 去实例化 train_dataset 训练集和 val_dataset 验证集,这个 DUTSDataset 就是自定义数据集读取的部分
- 确定数据集加载器中使用的 num_workers 工作线程数量,它取决于计算机的 CPU 核心数、批次大小以及最大允许的工作线程数量
- 用 data.DataLoader 去创建 train_data_loader 训练数据加载器和 val_data_loader 验证数据加载器,用于按批次加载数据
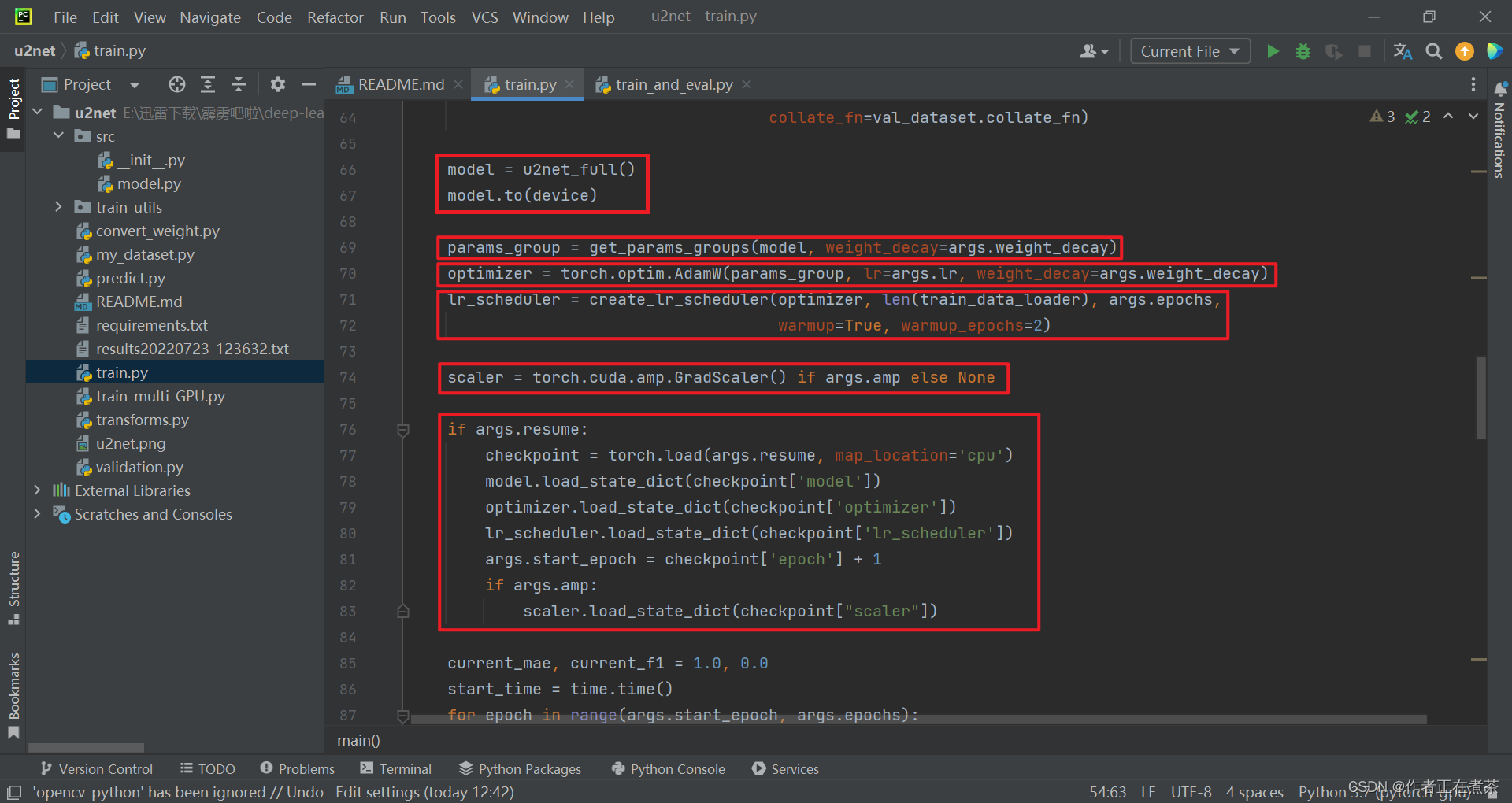
【代码解析2】对 main 主函数代码的具体讲解(结合上图):
- 用 u2net_full 创建模型对象,并将模型指定到对应的训练设备上
- 根据指定的权重衰减系数,将模型参数进行分组,并返回 params_group 参数组列表
- 创建优化器 optimizer 对象,这里我们采用的是 AdamW 优化器
- 创建学习率变化策略 lr_scheduler 对象,先进行 warm up 热身训练,再以 cosine 的形式进行衰减
- 根据 args.amp 的值判断是否启用混合精度训练,若是则用 torch.cuda.amp.GradScaler 创建梯度缩放器对象,否则为 None
- 根据 args.resume 的值判断是否载入最近一次对应的权重、优化器、学习率变化策略等训练过程中需要使用到的信息

【代码解析3】对 main 主函数代码的具体讲解(结合上图):
初始化平均绝对误差指标 MAE 和 max F-measure 指标 F1 ,MAE 越趋于 0 代表模型的效果越好,而 F1 越趋于 1 代表模型的效果越好,区间都在 0 和 1 之间 。在训练过程中,每间隔一定的 epoch 进行一次验证,若当前的 MAE 比我们记录的小,且 F1 比我们记录的大,就代表我们当前所得到的模型权重比之前记录的好,因此我们可以保存最近一次权重。

【代码解析4】对 main 主函数代码的具体讲解(结合上图):
- 在训练的迭代过程中,根据传入的 args.start_epoch 和 args.epochs 进行迭代,每迭代一轮,就在训练集上训练一次
- 每进行一轮训练,就返回对应的平均损失 mean_loss 和当前的学习率 lr
- 判断当前的 epoch 是否为 args.eval_interval 的整数倍,或者是否是最后一轮,若是则对模型进行评估和保存

【代码解析5】对 main 主函数代码的具体讲解(结合上图):
若当前的 MAE 大于等于验证集的 MAE,并且当前的 F1 小于等于验证集的 F1,则保存模型参数到文件;此外还会保存最近 10 轮的权重。
(5)train.py 源代码
import os
import time
import datetime
from typing import Union, Listimport torch
from torch.utils import datafrom src import u2net_full
from train_utils import train_one_epoch, evaluate, get_params_groups, create_lr_scheduler
from my_dataset import DUTSDataset
import transforms as Tclass SODPresetTrain:def __init__(self, base_size: Union[int, List[int]], crop_size: int,hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):self.transforms = T.Compose([T.ToTensor(),T.Resize(base_size, resize_mask=True),T.RandomCrop(crop_size),T.RandomHorizontalFlip(hflip_prob),T.Normalize(mean=mean, std=std)])def __call__(self, img, target):return self.transforms(img, target)class SODPresetEval:def __init__(self, base_size: Union[int, List[int]], mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):self.transforms = T.Compose([T.ToTensor(),T.Resize(base_size, resize_mask=False),T.Normalize(mean=mean, std=std),])def __call__(self, img, target):return self.transforms(img, target)def main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")batch_size = args.batch_size# 用来保存训练以及验证过程中信息results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))train_dataset = DUTSDataset(args.data_path, train=True, transforms=SODPresetTrain([320, 320], crop_size=288))val_dataset = DUTSDataset(args.data_path, train=False, transforms=SODPresetEval([320, 320]))num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])train_data_loader = data.DataLoader(train_dataset,batch_size=batch_size,num_workers=num_workers,shuffle=True,pin_memory=True,collate_fn=train_dataset.collate_fn)val_data_loader = data.DataLoader(val_dataset,batch_size=1, # must be 1num_workers=num_workers,pin_memory=True,collate_fn=val_dataset.collate_fn)model = u2net_full()model.to(device)params_group = get_params_groups(model, weight_decay=args.weight_decay)optimizer = torch.optim.AdamW(params_group, lr=args.lr, weight_decay=args.weight_decay)lr_scheduler = create_lr_scheduler(optimizer, len(train_data_loader), args.epochs,warmup=True, warmup_epochs=2)scaler = torch.cuda.amp.GradScaler() if args.amp else Noneif args.resume:checkpoint = torch.load(args.resume, map_location='cpu')model.load_state_dict(checkpoint['model'])optimizer.load_state_dict(checkpoint['optimizer'])lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])args.start_epoch = checkpoint['epoch'] + 1if args.amp:scaler.load_state_dict(checkpoint["scaler"])current_mae, current_f1 = 1.0, 0.0start_time = time.time()for epoch in range(args.start_epoch, args.epochs):mean_loss, lr = train_one_epoch(model, optimizer, train_data_loader, device, epoch,lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)save_file = {"model": model.state_dict(),"optimizer": optimizer.state_dict(),"lr_scheduler": lr_scheduler.state_dict(),"epoch": epoch,"args": args}if args.amp:save_file["scaler"] = scaler.state_dict()if epoch % args.eval_interval == 0 or epoch == args.epochs - 1:# 每间隔eval_interval个epoch验证一次,减少验证频率节省训练时间mae_metric, f1_metric = evaluate(model, val_data_loader, device=device)mae_info, f1_info = mae_metric.compute(), f1_metric.compute()print(f"[epoch: {epoch}] val_MAE: {mae_info:.3f} val_maxF1: {f1_info:.3f}")# write into txtwith open(results_file, "a") as f:# 记录每个epoch对应的train_loss、lr以及验证集各指标write_info = f"[epoch: {epoch}] train_loss: {mean_loss:.4f} lr: {lr:.6f} " \f"MAE: {mae_info:.3f} maxF1: {f1_info:.3f} \n"f.write(write_info)# save_bestif current_mae >= mae_info and current_f1 <= f1_info:torch.save(save_file, "save_weights/model_best.pth")# only save latest 10 epoch weightsif os.path.exists(f"save_weights/model_{epoch-10}.pth"):os.remove(f"save_weights/model_{epoch-10}.pth")torch.save(save_file, f"save_weights/model_{epoch}.pth")total_time = time.time() - start_timetotal_time_str = str(datetime.timedelta(seconds=int(total_time)))print("training time {}".format(total_time_str))def parse_args():import argparseparser = argparse.ArgumentParser(description="pytorch u2net training")parser.add_argument("--data-path", default="./", help="DUTS root")parser.add_argument("--device", default="cuda", help="training device")parser.add_argument("-b", "--batch-size", default=16, type=int)parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,metavar='W', help='weight decay (default: 1e-4)',dest='weight_decay')parser.add_argument("--epochs", default=360, type=int, metavar="N",help="number of total epochs to train")parser.add_argument("--eval-interval", default=10, type=int, help="validation interval default 10 Epochs")parser.add_argument('--lr', default=0.001, type=float, help='initial learning rate')parser.add_argument('--print-freq', default=50, type=int, help='print frequency')parser.add_argument('--resume', default='', help='resume from checkpoint')parser.add_argument('--start-epoch', default=0, type=int, metavar='N',help='start epoch')# Mixed precision training parametersparser.add_argument("--amp", action='store_true',help="Use torch.cuda.amp for mixed precision training")args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()if not os.path.exists("./save_weights"):os.mkdir("./save_weights")main(args)
相关文章:
【霹雳吧啦】手把手带你入门语义分割の番外11:U2-Net 源码讲解(PyTorch)—— 代码的使用
目录 前言 Preparation 一、U2-Net 网络结构图 二、U2-Net 网络源代码 1、train.py (1)parse_args 参数 (2)SODPresetTrain 类 (3)SODPresetEval 类 (4)main 函数 &#x…...

威尔仕2023年的统计数据
威尔仕健身房更新了2023年的统计数据,大家可以猜一猜我是哪一个称号?虽然小伙伴们的健身时长各有不同,有时候在课程中我也会分享自己健身的案例,看似一个简单的增强环路,旁边会有很多的调节环路来限制增强环路的增长&a…...
Spring——Spring基于注解的IOC配置
基于注解的IOC配置 学习基于注解的IOC配置,大家脑海里首先得有一个认知,即注解配置和xml配置要实现的功能都是一样的,都是要降低程序间的耦合。只是配置的形式不一样。 1.创建工程 1.1 pom.xml <?xml version"1.0" encoding…...
springbean生命周期类)
spring常用注解(一)springbean生命周期类
一、PostConstruct: 被PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器调用一次,类似于servlet的inti()方法。被PostConstruct修饰的方法会在构造函数之后,init()方法之前运行。...
【软件测试】2024年准备中/高级测试岗技术面试...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、软件测试基础知…...
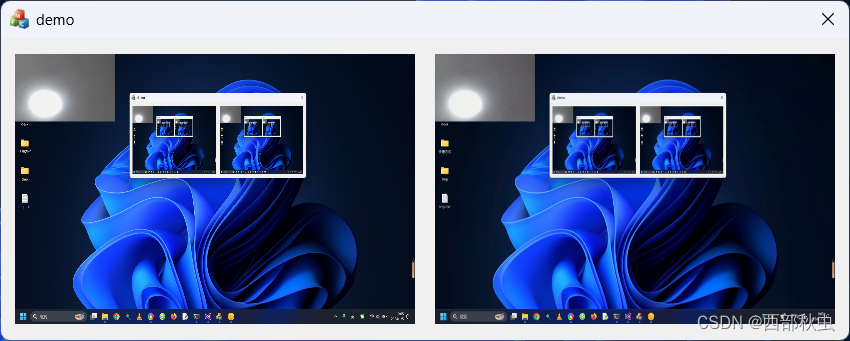
第11课 实现桌面与摄像头叠加
在上一节,我们实现了桌面捕获功能,并成功把桌面图像和麦克风声音发送给对方。在实际应用中,有时候会需要把桌面与摄像头图像叠加在一起发送,这节课我们就来看下如何实现这一功能。 1.备份与修改 备份demo10并修改demo10为demo11…...
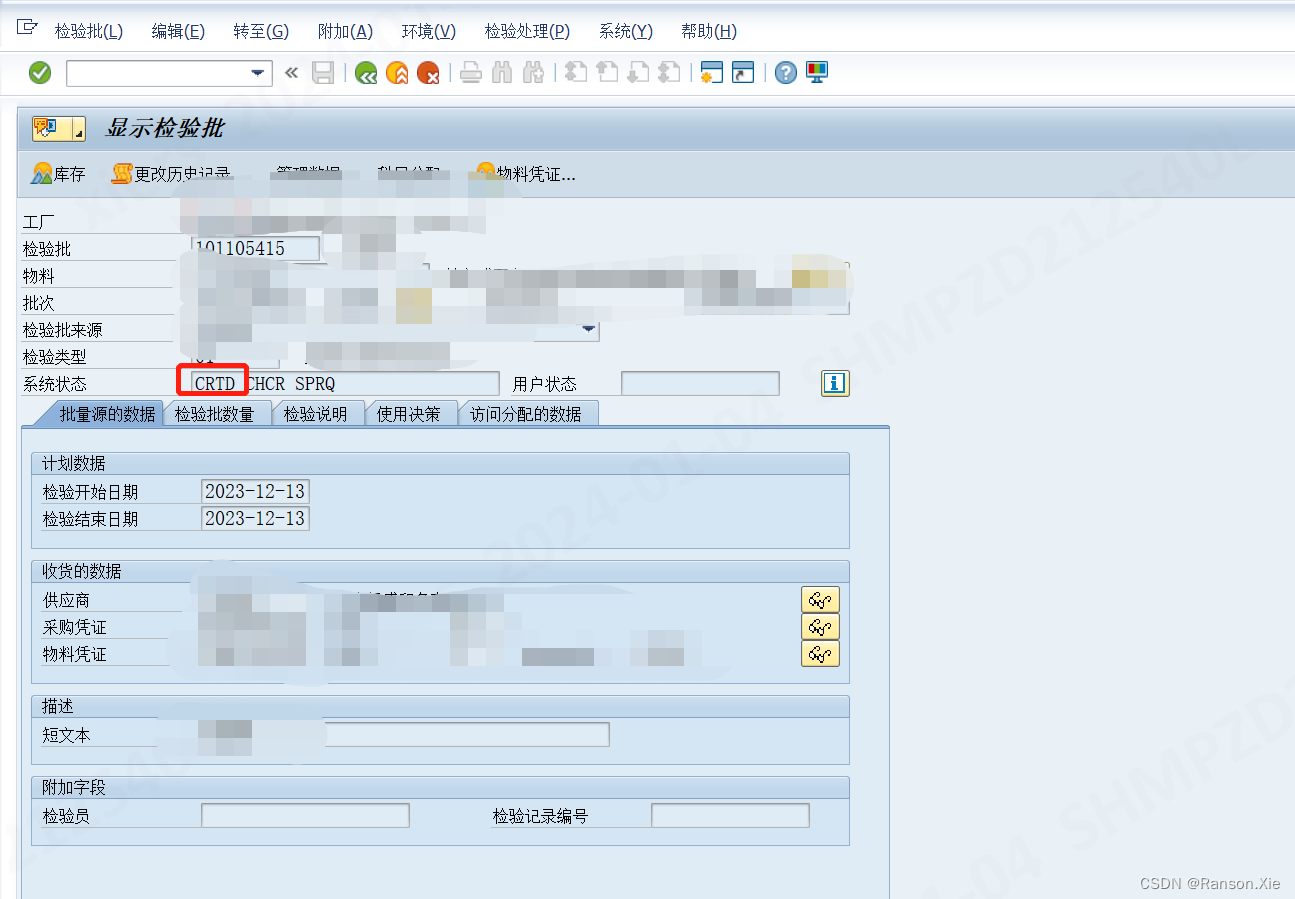
SAP 检验批状态修改(QA32质检放行报错:BS002 不允许 “访问使用决定“ (INL 101105415 ))
问题:在做QA32进行使用决策处理的时候发现这个报错: BS002 不允许 "访问使用决定" (INL 101105415 ) 原因:是因为这个检验批的状态已经变成Relase的状态了,但是决策还没有做 解决方案:将这个检验批的REL状态…...

华为交换机如何同时配置多个端口参数
知识改变命运,技术就是要分享,有问题随时联系,免费答疑,欢迎联系! 华为交换机如何批量配置端口 使用端口组功能可以实现一次配置多个端口,以减少重复配置工作。端口组分为如下两种方式: 永久端口组。如果用户需要多次…...
Mybatis之多表查询
目录 一、简介 1、使用嵌套查询: 2、使用多个 SQL 语句: 3、使用关联查询: 4、使用自定义映射查询: 二、业务场景 三、示例 1、一对一查询 2、一对多查询 一、简介 MyBatis 是一个优秀的持久层框架,它提供了强大的支持来执…...
部署node.js+express+mongodb(更新中)
1-Linux服务器部署MongoDB 1.升级 yum -y update 2.下载MongoDB安装包 3.上传安装包 上传目录 : /usr/local/ 2-配置MongoDB环境变量并启动 1.配置环境变量全局启动 vi ~/.bash_profile 使用i命令进入编辑模式 添加: export PATH/usr/local/mongodb/bin:$P…...

百度CTO王海峰:文心一言用户规模破1亿
“文心一言用户规模突破1亿。”12月28日,百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰在第十届WAVE SUMMIT深度学习开发者大会上宣布。会上,王海峰以《文心加飞桨,翩然赴星河》为题作了主旨演讲,分享了飞桨和文…...

简单最短路径算法
前言 图的最短路径算法主要包括: 有向无权图的单源最短路径 宽度优先搜索算法(bfs) 有向非负权图的单源最短路径 迪杰斯特拉算法(Dijkstra) 有向有权图的单源最短路径 贝尔曼福特算法(Bellman-Ford&#…...

答案解析——C语言—第3次作业—算术操作符与关系操作符
本次作业链接如下: C语言—第3次作业—算术操作符与关系操作符 1.在C语言中,表达式 7 / 2 的结果是多少? - A) 3.5 - B) 3 - C) 4 - D) 编译错误 答案:B) 3 解析: 在C语言中,当两个整数进行除法运算时&…...
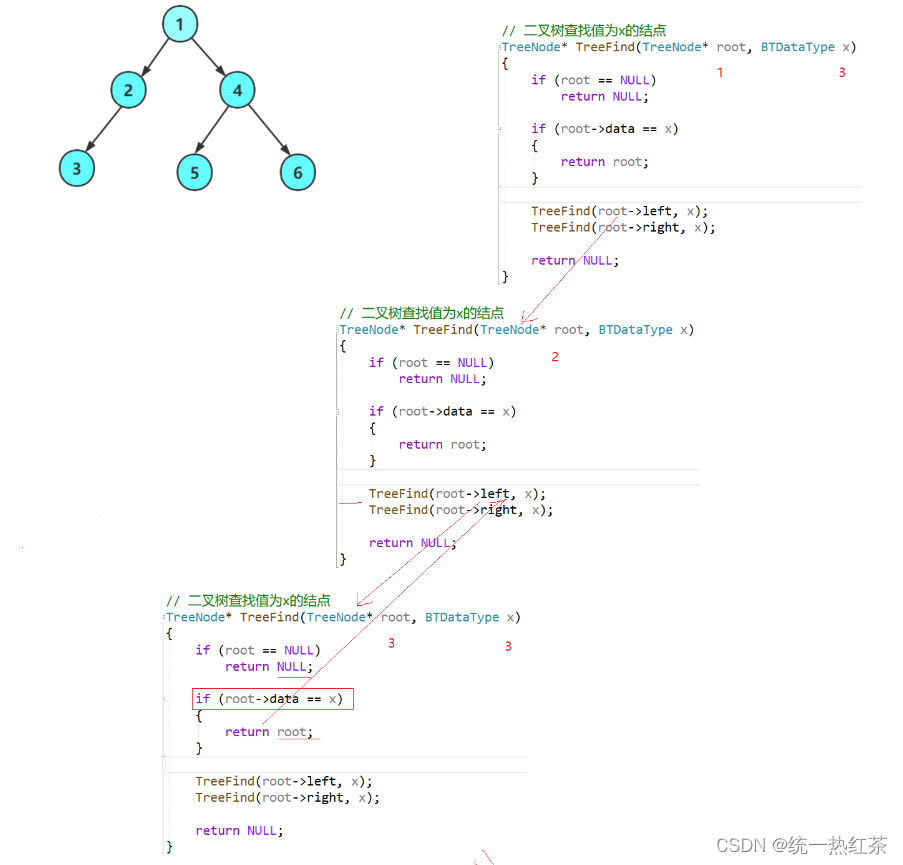
【数据结构】二叉树的链式实现
树是数据结构中非常重要的一种,在计算机的各方个面都有他的身影 此篇文章主要介绍二叉树的基本操作 目录 二叉树的定义:二叉树的创建:二叉树的遍历:前序遍历:中序遍历:后序遍历: 二叉树节点个数…...
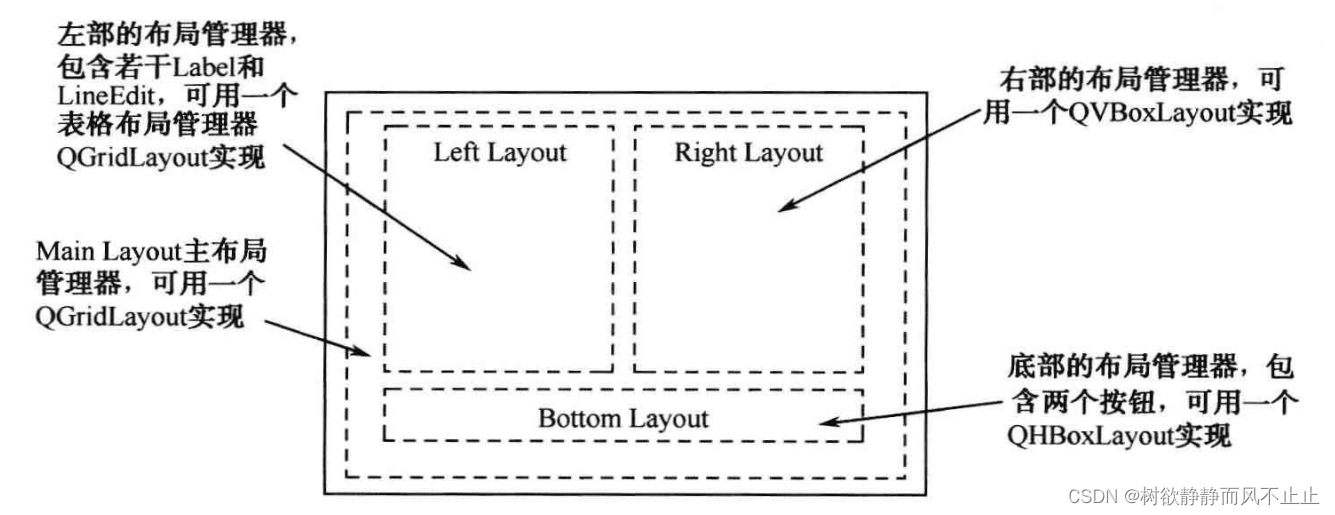
八、QLayout 用户基本资料修改(Qt5 GUI系列)
目录 一、设计需求 二、实现代码 三、代码解析 四、总结 一、设计需求 在很多应用程序中会有用户注册或用户编辑信息等界面。本文就设计一个用户信息编辑界面。要求包含用户名、姓名、性别、部门、年龄、头像、个人说明等信息。 二、实现代码 #ifndef DIALOG_H #define D…...

tomcat、java、maven
JDK|JRE Tomcat官网介绍的更清楚 Java 环境安装 安装 wget https://builds.openlogic.com/downloadJDK/openlogic-openjdk/8u392-b08/openlogic-openjdk-8u392-b08-linux-x64.tar.gz tar -xf openlogic-openjdk-8u392-b08-linux-x64.tar.gz mv openlogic-openjdk…...

IDEA好用插件
CodeGlance Pro 右侧代码小地图 Git Commit Template git提交信息模板 IDE Eval Reset 无限试用IDEA Maven Helper 图形化展示Maven项 One Dark theme 好看的主题 SequenceDiagram 展示方法调用链 Squaretest 生成单元测试 Translation 翻译 Lombok lombok插件…...
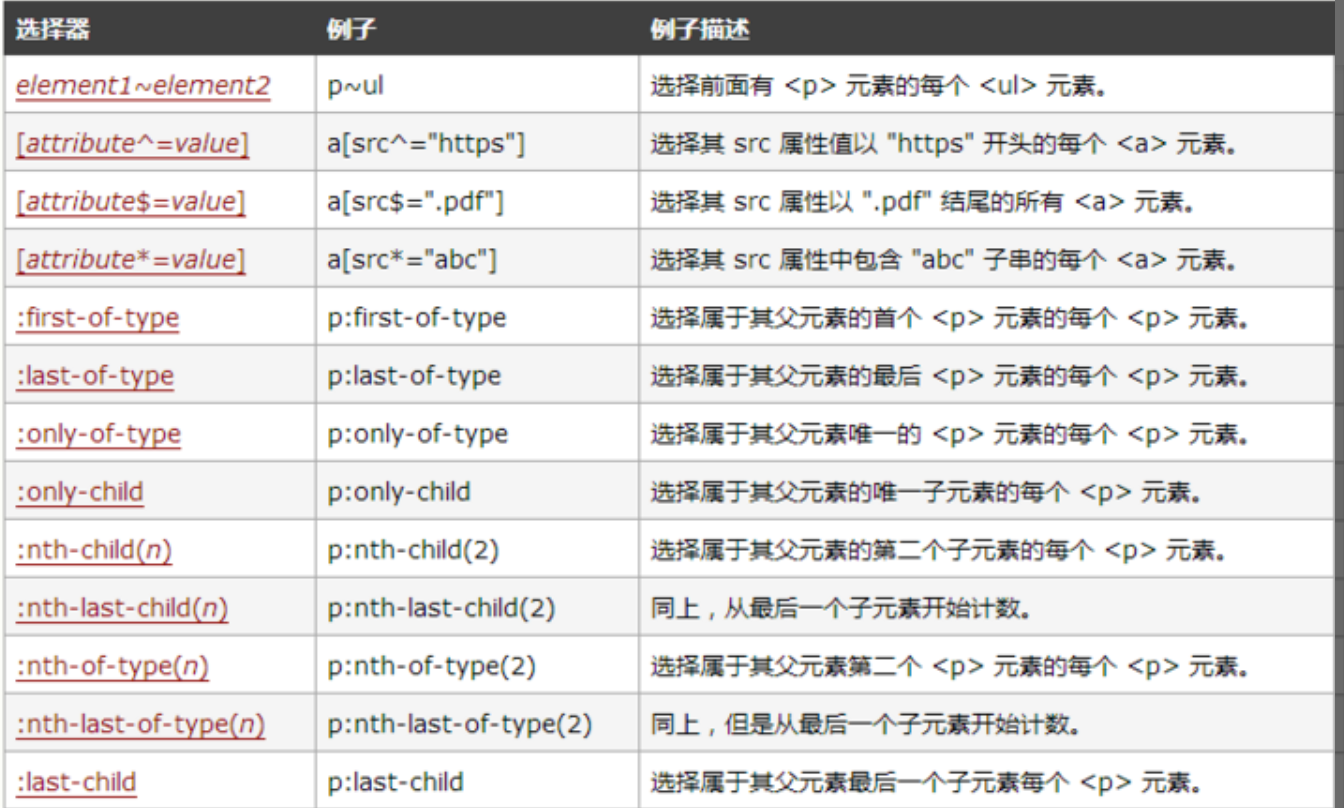
面试官:CSS3新增了哪些新特性?
面试官:CSS3新增了哪些新特性? 一、是什么 css,即层叠样式表(Cascading Style Sheets)的简称,是一种标记语言,由浏览器解释执行用来使页面变得更美观 css3是css的最新标准,是向后兼…...

Vite5 + Vue3 + Element Plus 前端框架搭建
为了开发一套高效使用的 Vite5 + Vue3 + Element Plus 前端框架,你可以按照以下步骤进行。话不多说,先上演示地址:Vue Shop Vite。 1, 安装开发环境 开发之前,确保你的电脑已经安装了 Node.js(建议使用最新稳定版 LTS),然后安装 Vite CLI。在命令行中运行以下命令: …...

STM32 内部 EEPROM 读写
STM32 的某些系列 MCU 自带 EEPROM。笔者使用的 STM32L151RET6 自带 16 KB 的 EEPROM,可以用来存储自定义的数据。在芯片选型时,自带 EEPROM 也可以作为一个考量点,省去了在外接 EEPROM 的烦恼。 下面简单介绍下 STM32 内部 EEPROM 的读写流…...

从零粉丝到行业KOL,ChatGPT驱动的LinkedIn内容矩阵搭建全链路,含17个已验证Prompt模板+3类避坑清单
更多请点击: https://intelliparadigm.com 第一章:从零粉丝到行业KOL的底层认知跃迁 成为技术领域有影响力的声音,从来不是靠日更三篇“速成教程”,而是源于对价值创造逻辑的重构。当多数人还在纠结“选什么平台”“起什么昵称”…...
)
3dmax动画期末作业全流程分享(附技术细节+避坑指南)
前言:期末将至,相信很多学习3dmax的小伙伴都在为动画期末作业发愁——从创意构思到建模、动画制作,再到渲染输出,每一步都可能遇到各种问题。本次就结合我的期末作业实践,详细分享从前期准备到成品交付的完整流程&…...

数字信号处理中的统计与概率基础解析
1. 数字信号处理中的统计与概率基础 在数字信号处理(DSP)领域,统计和概率理论构成了分析和处理信号的核心数学工具。信号在采集、传输和处理过程中不可避免地会受到各种干扰和噪声的影响,这些干扰可能来自测量系统本身,…...

十年后,编程还会是人类的工作吗?
一个正在被重写的职业剧本站在2026年的中点眺望2036年,没有人能准确预言未来。但作为软件测试从业者,我们或许是离“编程工作是否会被取代”这个答案最近的一群人。因为我们每天的工作,就是审视代码的边界、挖掘逻辑的漏洞、评估系统的风险。…...

Faust.js实战:用Next.js构建高性能Headless WordPress前端
1. 项目概述:当WordPress遇见现代前端如果你和我一样,在过去几年里深度参与过企业级WordPress项目,那你一定对那个经典的“两难困境”记忆犹新:一方面,WordPress的后台管理体验和内容生态无可匹敌,是内容团…...

从0到1掌握Ansible:让自动化运维不再是梦想
最近在公司推进自动化运维的时候,发现很多同事对Ansible还是一知半解,要么就是简单用用,要么就是直接放弃。其实Ansible真的没那么复杂,我用了这么多年,今天就把我的实战经验分享给大家。 说实话,刚开始接…...

云雾栖茶山,在云顶山读懂一片茶叶的蜕变旅程
位于福建省安溪县西坪镇的云顶山茶园,是一处融合了茶叶种植与传统制茶工艺的生态旅游区。该区域海拔约800米,常年云雾缭绕,土壤富含矿物质,为茶树生长提供了适宜的自然条件。景区以乌龙茶种植为核心,围绕“从叶片到茶杯…...

上午题_程序设计语言
编译程序和解释程序...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...

终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南
终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏截图分辨率太低而烦恼?是否需要在不同设备上测试UI布局却要反复重…...