大数据毕设分享 flink大数据淘宝用户行为数据实时分析与可视化
文章目录
- 0 前言
- 1、环境准备
- 1.1 flink 下载相关 jar 包
- 1.2 生成 kafka 数据
- 1.3 开发前的三个小 tip
- 2、flink-sql 客户端编写运行 sql
- 2.1 创建 kafka 数据源表
- 2.2 指标统计:每小时成交量
- 2.2.1 创建 es 结果表, 存放每小时的成交量
- 2.2.2 执行 sql ,统计每小时的成交量
- 2.3 指标统计:每10分钟累计独立用户数
- 2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
- 2.3.2 创建视图
- 2.3.3 执行 sql ,统计每10分钟的累计独立用户数
- 2.4 指标统计:商品类目销量排行
- 2.4.1 创建商品类目维表
- 2.4.1 创建 es 结果表,存放商品类目排行表
- 2.4.2 创建视图
- 2.4.3 执行 sql , 统计商品类目销量排行
- 3、最终效果与体验心得
- 3.1 最终效果
- 3.2 体验心得
- 3.2.1 执行
- 3.2.2 存储
- 4 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 flink大数据淘宝用户行为数据实时分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1、环境准备
1.1 flink 下载相关 jar 包
flink-sql 连接外部系统时,需要依赖特定的 jar 包,所以需要事先把这些 jar 包准备好。说明与下载入口
本项目使用到了以下的 jar 包 ,下载后直接放在了 flink/lib 里面。
需要注意的是 flink-sql 执行时,是转化为 flink-job 提交到集群执行的,所以 flink 集群的每一台机器都要添加以下的 jar 包。
| 外部 | 版本 | jar |
|---|---|---|
| kafka | 4.1 | flink-sql-connector-kafka_2.11-1.10.2.jar flink-json-1.10.2-sql-jar.jar |
| elasticsearch | 7.6 | flink-sql-connector-elasticsearch7_2.11-1.10.2.jar |
| mysql | 5.7 | flink-jdbc_2.11-1.10.2.jar mysql-connector-java-8.0.11.jar |
1.2 生成 kafka 数据
用户行为数据来源: 阿里云天池公开数据集
网盘:https://pan.baidu.com/s/1wDVQpRV7giIlLJJgRZAInQ 提取码:gja5
商品类目纬度数据来源: category.sql
数据生成器:datagen.py
有了数据文件之后,使用 python 读取文件数据,然后并发写入到 kafka。
修改生成器中的 kafka 地址配置,然后运行 以下命令,开始不断往 kafka 写数据
# 5000 并发
nohup python3 datagen.py 5000 &
1.3 开发前的三个小 tip
-
生成器往 kafka 写数据,会自动创建主题,无需事先创建
-
flink 往 elasticsearch 写数据,会自动创建索引,无需事先创建
-
Kibana 使用索引模式从 Elasticsearch 索引中检索数据,以实现诸如可视化等功能。
使用的逻辑为:创建索引模式 》Discover (发现) 查看索引数据 》visualize(可视化)创建可视化图表》dashboards(仪表板)创建大屏,即汇总多个可视化的图表
2、flink-sql 客户端编写运行 sql
# 进入 flink-sql 客户端, 需要指定刚刚下载的 jar 包目录
./bin/sql-client.sh embedded -l lib
2.1 创建 kafka 数据源表
-- 创建 kafka 表, 读取 kafka 数据
CREATE TABLE user_behavior (user_id BIGINT,item_id BIGINT,category_id BIGINT,behavior STRING,ts TIMESTAMP(3),proctime as PROCTIME(),WATERMARK FOR ts as ts - INTERVAL '5' SECOND
) WITH ('connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.startup-mode' = 'earliest-offset', 'connector.properties.zookeeper.connect' = '172.16.122.24:2181', 'connector.properties.bootstrap.servers' = '172.16.122.17:9092', 'format.type' = 'json'
);
SELECT * FROM user_behavior;
2.2 指标统计:每小时成交量
2.2.1 创建 es 结果表, 存放每小时的成交量
CREATE TABLE buy_cnt_per_hour (hour_of_day BIGINT,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'buy_cnt_per_hour','connector.document-type' = 'user_behavior','connector.bulk-flush.max-actions' = '1','update-mode' = 'append','format.type' = 'json'
);
2.2.2 执行 sql ,统计每小时的成交量
INSERT INTO buy_cnt_per_hour
SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*)
FROM user_behavior
WHERE behavior = 'buy'
GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
2.3 指标统计:每10分钟累计独立用户数
2.3.1 创建 es 结果表,存放每10分钟累计独立用户数
CREATE TABLE cumulative_uv (time_str STRING,uv BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'cumulative_uv','connector.document-type' = 'user_behavior', 'update-mode' = 'upsert','format.type' = 'json'
);
2.3.2 创建视图
CREATE VIEW uv_per_10min AS
SELECTMAX(SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0') OVER w AS time_str,COUNT(DISTINCT user_id) OVER w AS uv
FROM user_behavior
WINDOW w AS (ORDER BY proctime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW);
2.3.3 执行 sql ,统计每10分钟的累计独立用户数
INSERT INTO cumulative_uv
SELECT time_str, MAX(uv)
FROM uv_per_10min
GROUP BY time_str;
2.4 指标统计:商品类目销量排行
2.4.1 创建商品类目维表
先在 mysql 创建一张商品类目的维表,然后配置 flink 读取 mysql。
CREATE TABLE category_dim (sub_category_id BIGINT,parent_category_name STRING
) WITH ('connector.type' = 'jdbc','connector.url' = 'jdbc:mysql://172.16.122.25:3306/flink','connector.table' = 'category','connector.driver' = 'com.mysql.jdbc.Driver','connector.username' = 'root','connector.password' = 'root','connector.lookup.cache.max-rows' = '5000','connector.lookup.cache.ttl' = '10min'
);
2.4.1 创建 es 结果表,存放商品类目排行表
CREATE TABLE top_category (category_name STRING,buy_cnt BIGINT
) WITH ('connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://172.16.122.13:9200', 'connector.index' = 'top_category','connector.document-type' = 'user_behavior','update-mode' = 'upsert','format.type' = 'json'
);
2.4.2 创建视图
CREATE VIEW rich_user_behavior AS
SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name
FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C
ON U.category_id = C.sub_category_id;
2.4.3 执行 sql , 统计商品类目销量排行
INSERT INTO top_category
SELECT category_name, COUNT(*) buy_cnt
FROM rich_user_behavior
WHERE behavior = 'buy'
GROUP BY category_name;
3、最终效果与体验心得
3.1 最终效果
整个开发过程,只用到了 flink-sql ,无需写 java 或者其它代码,就完成了这样一个实时报表。
3.2 体验心得
3.2.1 执行
-
flink-sql 的 ddl 语句不会触发 flink-job , 同时创建的表、视图仅在会话级别有效。
-
对于连接表的 insert、select 等操作,则会触发相应的流 job, 并自动提交到 flink 集群,无限地运行下去,直到主动取消或者 job 报错。
-
flink-sql 客户端关闭后,对于已经提交到 flink 集群的 job 不会有任何影响。
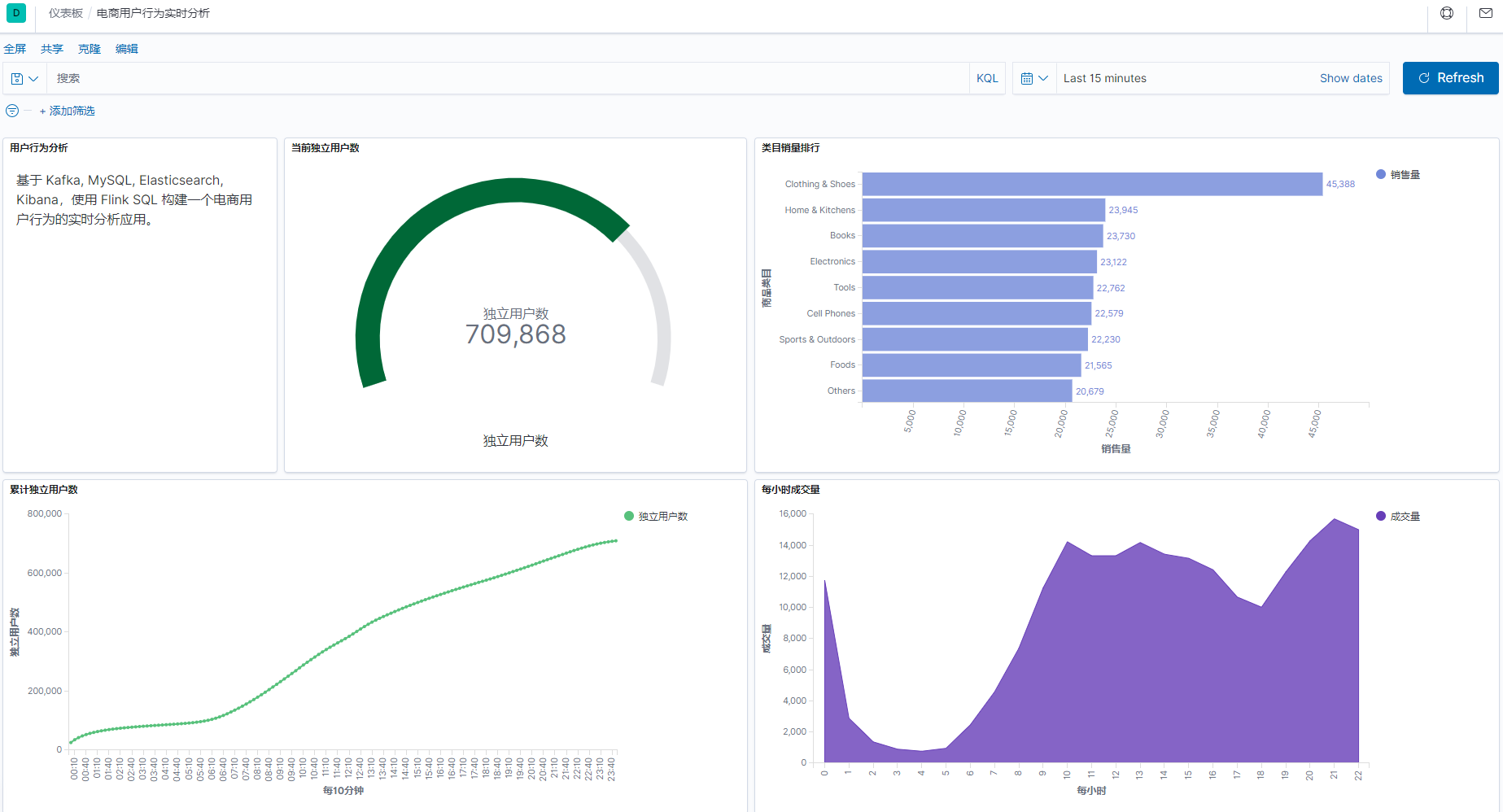
本次开发,执行了 3 个 insert , 因此打开 flink 集群面板,可以看到有 3 个无限的流 job 。即使 kafka 数据全部写入完毕,关闭 flink-sql 客户端,这个 3 个 job 都不会停止。
3.2.2 存储
-
flnik 本身不存储业务数据,只作为流批一体的引擎存在,所以主要的用法为读取外部系统的数据,处理后,再写到外部系统。
-
flink 本身的元数据,包括表、函数等,默认情况下只是存放在内存里面,所以仅会话级别有效。但是,似乎可以存储到 Hive Metastore 中,关于这一点就留到以后再实践。
4 最后
相关文章:
大数据毕设分享 flink大数据淘宝用户行为数据实时分析与可视化
文章目录 0 前言1、环境准备1.1 flink 下载相关 jar 包1.2 生成 kafka 数据1.3 开发前的三个小 tip 2、flink-sql 客户端编写运行 sql2.1 创建 kafka 数据源表2.2 指标统计:每小时成交量2.2.1 创建 es 结果表, 存放每小时的成交量2.2.2 执行 sql &#x…...

大语言模型训练数据集
大语言模型的数据集有很多,以下是一些常用的: - 中文维基百科:这是一个包含大量中文文本的数据集,可用于训练中文语言模型。 - 英文维基百科:这是一个包含大量英文文本的数据集,可用于训练英文语言模型。 …...
python的课后练习总结4(while循环)
for循环用于针对序列中的每个元素的一个代码块。 while循环是不断的运行,直到指定的条件不满足为止。 while 条件: 条件成立重复执行的代码1 条件成立重复执行的代码2 …….. i 1while i < 5:print(i)i i 11、使用wh…...
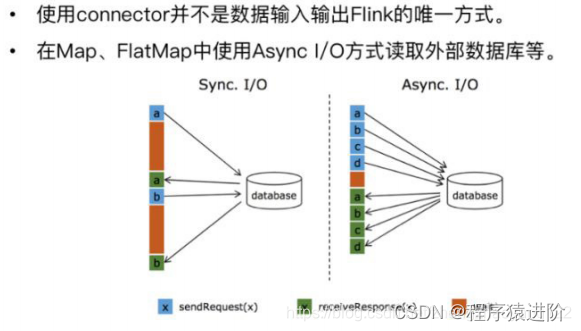
Flink Connector 开发
Flink Streaming Connector Flink是新一代流批统一的计算引擎,它需要从不同的第三方存储引擎中把数据读过来,进行处理,然后再写出到另外的存储引擎中。Connector的作用就相当于一个连接器,连接Flink计算引擎跟外界存储系统。Flin…...
Golang leetcode707 设计链表 (链表大成)
文章目录 设计链表 Leetcode707不使用头节点使用头节点 推荐** 设计链表 Leetcode707 题目要求我们通过实现几个方法来完成对链表的各个操作 由于在go语言中都为值传递,(注意这里与值类型、引用类型的而区别),所以即使我们直接在…...
Django和Vue项目运行过程中遇到的问题及解决办法
这是我从CSDN上边买来的一个系统的资源,准备在此基础上改成自己的系统,但是在运行项目这一步上都把自己难为了好几天,经过不断的摸索,终于完成了第一步!!! 如果大家也遇到同样的问题࿰…...

Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
Single-Image Crowd Counting via Multi-Column Convolutional Neural Network 论文背景人群密度方法过去的发展历史早期方法基于轨迹聚类的方法基于特征回归的方法基于图像的方法 Multi-column CNN用于人群计数基于密度图的人群计数通过几何自适应核生成密度图密度图估计的多列…...

el-cascader隐藏某一级的勾选框及vue报错Error in callback for watcher “options“的解决办法
今天用到饿了么的级联选择器时出现了这个报错Error in callback for watcher “options“: “TypeError: Cannot read propertie ‘level‘ of null,因为需求是在不同类型 el-cascader多选的时候默认是可以勾选所有级的选项的,如下图: 包含级联cascader的options、select的…...

2024美赛数学建模思路A题B题C题D题E题F题思路汇总 选题分析
文章目录 1 赛题思路2 美赛比赛日期和时间3 赛题类型4 美赛常见数模问题5 建模资料 1 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 2 美赛比赛日期和时间 比赛开始时间:北京时间2024年2月2日(周五ÿ…...

C++ 常用设计模式
一、工厂模式 from:C开发常用的设计模式及其实现详解 - 知乎 摘抄: 简单工厂、工厂、抽象工厂: 简单工厂需要工厂内部判断,而工厂模式不需要修改工厂类: 抽象工厂: 接上图: 未完待续.........

高性价比的高速吹风机/高速风筒解决方案,基于普冉单片机开发
高速吹风机是近些年非常火的一款产品,快速崛起并颠覆了传统吹风机,高速吹风机也成为了传统吹风机替代的一个大趋势。高速吹风机是利用高转速产生的大风量来快速吹干头发,由于其精巧的外观设计、超低的噪声、出色的干发效果,高速吹…...

toRefs的用法
文章目录 toRefs是什么toRefs的作用以及为什么要用它? toRefs是什么 toRefs 是 Vue 3 Composition API 中的一个函数,它用于将响应式对象转换为普通对象,其中对象的每个属性都是 ref 对象。这是因为在 Vue 3 中,reactive 创建的对…...
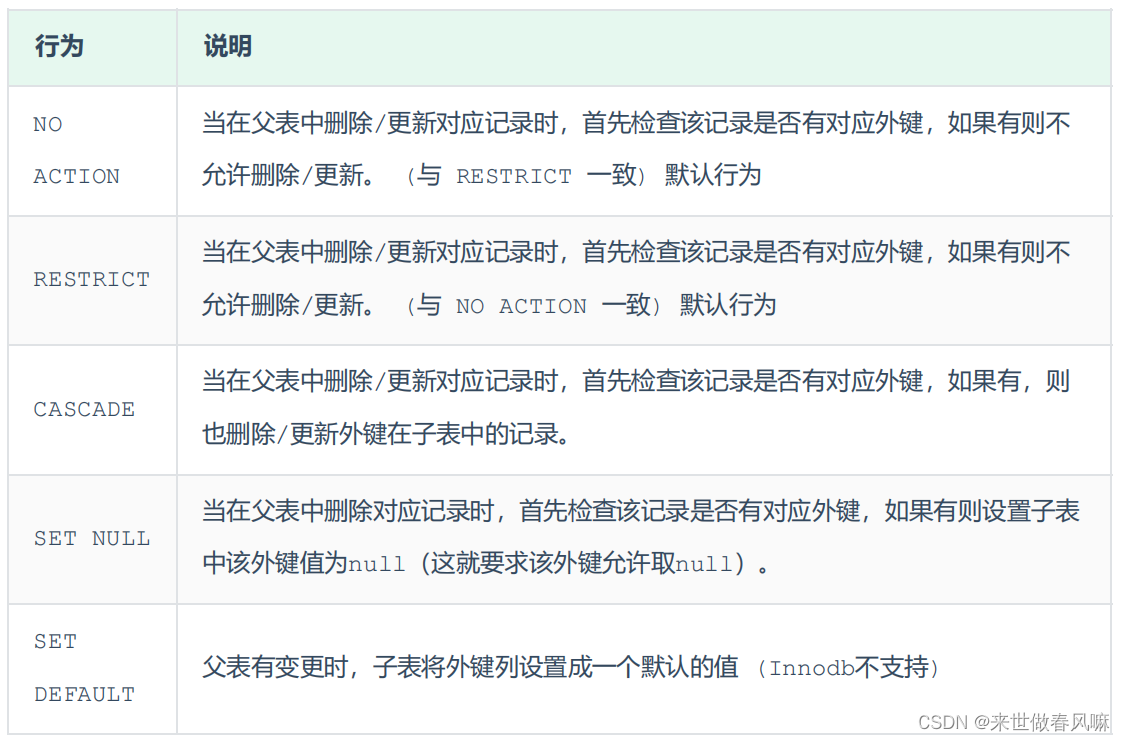
MySQL基础篇(三)约束
一、概述 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。 目的:保证数据库中数据的正确、有效性和完整性。 分类: 注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。 二…...
Java进阶 1-2 枚举
目录 常量特定方法 职责链模式的枚举实现 状态机模式的枚举实现 多路分发 1、使用枚举类型实现分发 2、使用常量特定方法实现分发 3、使用EnumMap实现分发 4、使用二维数组实现分发 本笔记参考自: 《On Java 中文版》 常量特定方法 在Java中,我们…...

一个人最大的内驱力是什么?
1、不因为孤独或外界压力而降低「生活标准“」的能力。 ”因为寂寞去约炮“、“因为家里催婚匆忙结婚“、”因为没谈过恋爱随便找个人交往。 “你的每一次选择都是在为自己想要的世界而投的票,往后余生是幸福还是悲剧,就是在这一次次 的将就与坚持死磕中…...

解决方法:公众号的API上传素材报错40005
公众号的API上传素材报错40005 Error uploading file : {"errcode":40005,"errmsg":"invalid file type hint: [YOkxGA0122w487] rid: 223442-323247e7bd5-5d75322d88"}上传错误原因分析: 之前成功的示例,文件名为"…...

音量控制软件sound control mac功能亮点
sound control mac可以帮助用户控制某个独立应用程序的音量,通过每应用音量,均衡器,平衡和音频路由独立控制每个应用的音频,还有整个系统的音量。 sound control mac功能亮点 每个应用程序的音量控制 独立控制应用的数量。 键盘音…...

Spring Boot 生产就绪中文文档-下
本文为官方文档直译版本。原文链接 由于篇幅较长,遂分两篇。上半部分中文文档 Spring Boot 生产就绪中文文档-下 度量标准入门受支持的监控系统AppOpticsAtlasDatadogDynatracev2 API自动配置手动配置 v1 API (旧版)与版本无关的设置 ElasticGangliaGraphiteHumioIn…...

DS|树结构及应用
题目一:DS树 -- 树的先根遍历(双亲转先序) 题目描述: 给出一棵树的双亲表示法结果,用一个二维数组表示,位置下标从0开始,如果双亲位置为-1则表示该结点为根结点 编写程序,输出该树…...
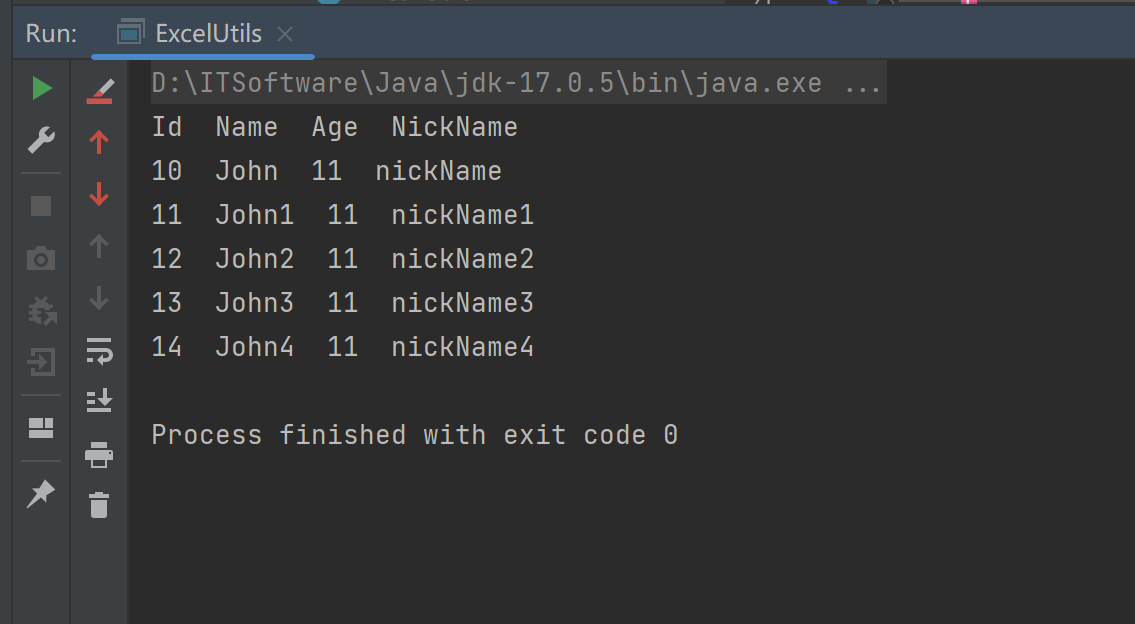
Java 读取超大excel文件
注意:此参考解决方案只是针对xlsx格式的excel文件! Maven <dependency><groupId>com.monitorjbl</groupId><artifactId>xlsx-streamer</artifactId><version>2.2.0</version> </dependency>读取方式1…...

【力扣100题】48.乘积最大子数组
题目描述 给你一个整数数组 nums,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。 测试用例的答案是一个 32 位整数。注意,一个只包含一个元素的数组的乘积就是这个…...

Codex 上下文提供详解与操作指南
1. 文档目标 这份文档解决的是一个非常实际的问题: 怎么给 Codex 足够完整的上下文什么信息是必须给的,什么信息是可选但高价值的怎样让 Codex 在一次任务里快速进入正确状态怎样避免“我已经说了很多,但结果还是不对”怎样把上下文提供方式变…...

Java开发者如何用Dify-Java-Client快速集成AI能力到Spring Boot项目
1. 项目概述:一个面向Java开发者的AI应用构建利器如果你正在用Java技术栈,同时又对当前火热的AI应用开发感兴趣,那么你很可能遇到过这样的困境:市面上主流的AI应用开发框架和客户端库,比如OpenAI的官方SDK、LangChain等…...

为内部工具集成AI能力时选择Taotoken作为统一接口层
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成AI能力时选择Taotoken作为统一接口层 当企业开发团队着手为多个内部系统,例如客户关系管理(…...

Cursor编辑器自动化实践:利用Sisyphus脚本解放重复开发任务
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫Fguedes90/cursor-sisyphus。乍一看这个标题,可能会有点摸不着头脑,但如果你是一个深度使用Cursor AI代码编辑器的开发者,或者对AI辅助编程的自动化流程感兴趣&…...

Delphi7 突破局限!借助Python扩展程序能力。
在桌面开发领域,Delphi7 凭借其简洁高效的可视化开发能力、稳定的运行性能,至今仍被许多开发者用于工业自动化、金融终端、桌面工具等项目开发。但不可否认的是,Delphi7 在网络数据抓取、AI交互、复杂数据处理等场景中存在天然局限࿰…...

AI智能体与Excalidraw集成:实现自然语言绘图与图形解析
1. 项目概述:当白板工具遇上AI智能体 最近在折腾AI智能体(Agent)开发时,发现一个很有意思的项目: Agents365-ai/excalidraw-skill 。乍一看,这像是一个给Excalidraw(一款开源的虚拟白板绘图工…...

告别枯燥表格!用Power BI的矩形树图,5分钟搞定你的销售利润可视化分析
商业数据可视化实战:用Power BI矩形树图5分钟呈现销售利润洞察 在每周的销售复盘会议上,你是否经常面对这样的困境:手头有一份密密麻麻的Excel表格,包含了各省市、各产品的销售利润数据,却难以快速向团队传达关键业务洞…...

Wonder3D完整教程:如何用单张图片快速生成3D模型
Wonder3D完整教程:如何用单张图片快速生成3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 想要将一张普通的图片变成立体的3D模型吗࿱…...

ChatGPT购物功能支持平台速查表,含响应延迟、支付闭环率、商品图识别准确率等5项硬指标实测数据
更多请点击: https://intelliparadigm.com 第一章:ChatGPT购物功能支持哪些平台 截至2024年,ChatGPT原生并不直接集成电商交易能力,但通过官方插件(Plugins)和第三方API集成,可在特定授权环境…...