LLM 中的长文本问题
近期,随着大模型技术的发展,长文本问题逐渐成为热门且关键的问题,不妨简单梳理一下近期出现的典型的长文本模型:
-
10 月上旬,Moonshot AI 的 Kimi Chat 问世,这是首个支持 20 万汉字输入的智能助手产品;
-
10 月下旬,百川智能发布 Baichuan2-192K 长窗口大模型,相当于一次处理约35 万个汉字;
-
11 月上旬,OpenAI 发布支持 128K 上下文窗口的 GPT-4 Turbo 模型;
-
11 月下旬,Anthropic 发布支持 200K 上下文窗口的 Claude 2.1 模型;
-
12 月上旬,零一万物开源了长文本模型 Yi-6B-200K和 Yi-34B-200K。
实际上,随着文本长度的提高,模型能够处理问题的边界也大大提高,因此研究并解决长文本问题就显得非常必要。本文将从长文本问题的本质出发,逐步分析和研究长文本实现的问题及解决办法。
一、长文本的核心问题与解决方向
1.1 文本长度与显存及计算量之关系
要研究清楚长文本的问题,首先应该搞清楚文本长度在模型中的地位与影响。那么我们便以 Decoder-base 的模型为例来进行分析
1.1.1 模型参数量
Decoder-base 的模型主要包括 3 个部分:embedding, decoder-layer, head。
其中最主要部分是decoder-layer,其由 lll 个层组成,每个层又分为两部分:self-attention 和 MLP。
self-attention的模型参数有、、的权重矩阵 、、及bias,输出矩阵 及bias,4个权重矩阵的形状为 ( 表示 hidden_size),4个bias的形状为 。则 self- attention 的参数量为 。
MLP由2个线性层组成,一般地,第一个线性层是先将维度从 映射到 ,第二个线性层再将维度从映射到。第一个线性层的权重矩阵 的形状为 ,偏置的形状为 。第二个线性层权重矩阵 的形状为 ,偏置形状为 。则 MLP 的参数量为 。
self-attention 和MLP各有一个layer normalization,包含了2个可训练模型参数:缩放参数γ和平移参数β,形状都是。2个layer normalization的参数量为 。
由此,每个Decoder层的参数量为。
此外,embedding和head 的参数量相同,与词表相关,为(如果是 Tied embedding,则二者共用同一个参数)。由于位置编码多样,且参数量小,故忽略此部分。
综上, 层模型的可训练模型参数量为 。当 较大时,可以忽略一次项,模型参数量近似为。
1.1.2 计算量估计
如果说参数量是模型的固有属性,那么计算量便是由模型和输入共同决定,下面分析这一过程。假设输入数据的形状为 ( 表示batch_size,表示sequence_length)。
先分析Decoder中self-attention的计算量,计算公式如下:
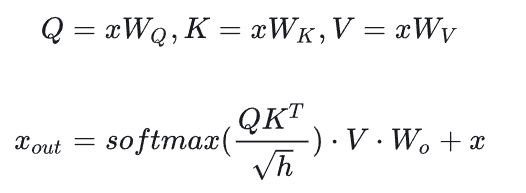
-
计算:矩阵乘法的输入和输出形状为。计算量为。
-
矩阵乘法的输入和输出形状为
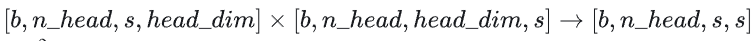
计算量为。
-
计算在上的加权,矩阵乘法的输入和输出形状为
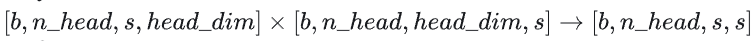
计算量为 。
-
attention后的线性映射,矩阵乘法的输入和输出形状为.计算量为。
接下来分析MLP块的计算,计算公式如下:
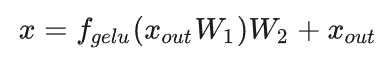
-
第一个线性层,矩阵乘法的输入和输出形状为 。计算量为 。
-
第二个线性层,矩阵乘法的输入和输出形状为 。计算量为。
将上述计算量相加,得到每个Decoder层的计算量大约为。
此外,另一个计算量的大头是logits的计算,将隐藏向量映射为词表大小。矩阵乘法的输入和输出形状为,计算量为。
因此,对于一个 lll 层的模型,输入数据形状为的情况下,一次前向计算的计算量为。
1.1.3 文本长度与计算量、参数量、显存的关系
忽略低次项,一次输入的tokens数为bs, 则计算量与参数量的关系为 在实际中通常 ,因此该项可近似认为约等于2。即在一次前向传递中,对于每个token,每个模型参数,需要进行2次浮点数运算(一次乘法法运算和一次加法运算)。考虑到后向传递的计算量是前向传递的2倍。因此一次训练迭代中,对于每个 token,每个模型参数,需要进行 次浮点数运算。
通过以上分析,我们可以得到结论:计算量主要和模型参数和 token 数相关,文本长度并不会显著增加计算量。那么这就引出另一个问题:文本长度与显存的关系。
除了模型参数、梯度、优化器状态外,占用显存的大头就是前向传递过程中计算得到的中间激活值。这里的激活(activations)指的是:前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。
先分析 Decoder layer 中 self-attention 的中间激活:
-
对于 ,需要保存它们共同的输入 ,这就是中间激活。输入 的形状为 ,元素个数为 ,占用显存大小为 。
-
对于 矩阵乘法,需要保存中间激活 ,两个张量的形状都是 ,占用显存大小合计为 。
-
对于 函数,需要保存函数的输入 ,占用显存大小为 ,这里的 表示注意力头数。
-
计算完 函数后,会进行dropout操作。需要保存一个mask矩阵,mask矩阵的形状与 相同,占用显存大小为 。
-
计算在 上的attention,即 ,需要保存 score ,大小为 ;以及 ,大小为 。二者占用显存大小合计为 。
-
计算输出映射以及一个dropout操作。输入映射需要保存其输入,大小为 ;dropout需要保存mask矩阵,大小为 。二者占用显存大小合计为 。
因此,将上述中间激活相加得到,self-attention的中间激活占用显存大小为 。接下来分析分析Decoder layer中MLP的中间激活:
-
第一个线性层需要保存其输入,占用显存大小为 。
-
激活函数需要保存其输入,占用显存大小为 。
-
第二个线性层需要保存其输入,占用显存大小为 。
-
最后有一个dropout操作,需要保存mask矩阵,占用显存大小为 。
对于MLP块,需要保存的中间激活值为 。
另外,self-attention块和MLP块分别对应了一个layer normalization。每个layer norm需要保存其输入,大小为 。2个layer norm需要保存的中间激活为 。
综上,每个层需要保存的中间激活占用显存大小为 。对于 层transformer模型,还有embedding层、最后的输出层。embedding层不需要中间激活。总的而言,当隐藏维度 比较大,层数 较深时,这部分的中间激活是很少的,可以忽略。因此,对于 层模型,中间激活占用的显存大小可以近似为 ,这个结果与文本长度关系密切。
下面以GPT3-175B为例,对比下文本长度对模型参数与中间激活的显存大小的影响。假设数据类型为 FP16 。
| 模型名 | 参数量 | 层数 | 隐藏维度 | 注意力头数 |
|---|---|---|---|---|
| GPT3 | 175B | 96 | 12288 | 96 |
GPT3的模型参数量为175B,占用的显存大小为 。GPT3 模型需要占用350GB的显存。
假设 GPT3 输入的 。对比不同的文本长度下占用的中间激活:
当 时,中间激活占用显存为
,大约是模型参数显存的0.79倍;
当 时,中间激活占用显存为
,大约是模型参数显存的2.68倍。
可以看到长度仅仅到 4K,显存占用就出现了剧烈增加,同时 GPU onchip 的 memory 就显得更加捉襟见肘(因此也就出现了 FlashAttention 这类算法)。因此如何解决长文本带来的巨量显存开销成为关键及核心问题。
1.2 长文本问题的解决思路
当前,为了实现更长长文本的支持,解决思路主要可以分为两个阶段:
-
阶段一:在预训练阶段尽可能支持更长的文本长度
为实现这一阶段目标,通常采用并行化 (parallelism) 方法将显存占用分摊到多个 device,或者改造 attention 结构,避免显存占用与文本长度成二次关系。 -
阶段二:在 SFT 或推理阶段尽可能外推到更大长度
为实现这一阶段目标,通常也是需要在两个方面进行考虑:-
对位置编码进行外推
-
优化 At
-
相关文章:
LLM 中的长文本问题
近期,随着大模型技术的发展,长文本问题逐渐成为热门且关键的问题,不妨简单梳理一下近期出现的典型的长文本模型: 10 月上旬,Moonshot AI 的 Kimi Chat 问世,这是首个支持 20 万汉字输入的智能助手产品; 10 月下旬,百川智能发布 Baichuan2-192K 长窗口大模型,相当于一次…...

深入了解Swagger注解:@ApiModel和@ApiModelProperty实用指南
在现代软件开发中,提供清晰全面的 API 文档 至关重要。ApiModel 和 ApiModelProperty 这样的代码注解在此方面表现出色,通过增强模型及其属性的元数据来丰富文档内容。它们的主要功能是为这些元素命名和描述,使生成的 API 文档更加明确。 Api…...

Linux学习第48天:Linux USB驱动试验:保持热情,保持节奏,持续学习是作为一个技术人员应有的基本素质和要求
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 最近更新的速度和频率大不如以前,主要原因还是自己有些懈怠了。学习是一个持续努力的过程,一旦中断,再想保持以往的状态可能要…...

数据库索引简析
文章目录 前言一、索引是什么二、索引的有什么用三、索引的分类四、索引的数据结构总结 前言 在我们使用数据库的过程中,往往会碰到一个叫做索引的东西,不管是表的设计,还是数据库性能的优化往往都会涉及到索引。那么他是个什么东西ÿ…...
leetcode贪心(单调递增的数字、监控二叉树)
738.单调递增的数字 给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。 (当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。ÿ…...

如何在win7同样支持Webview2 在 WPF 中使用本地 Webview2 ,如何不依赖系统 Runtime
项目运行环境: .Net Framework 4.5.2 Windows 7 x64 Service Pack 1 WebView2 Microsoft.WebView2.FixedVersionRuntime.120.0.2210.91.x64 考虑到很多老项目,本项目使用的是.Net Framework 4.5.2,.Net 更高版本的其实也是可以支持的。 …...

【docker】网络模式管理
目录 一、Docker网络实现原理 二、Docker的网络模式 1、host模式 1.1 host模式原理 1.2 host模式实操 2、Container模式 2.2 container模式实操 3、none模式 4、bridger模式 4.1 bridge模式的原理 4.2 bridge实操 5、overlay模式 6、自定义网络模式 6.1 为什么需要…...
LiveGBS国标GB/T28181流媒体平台功能-国标级联中作为下级平台对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话
LiveGBS国标级联中作为下级平台对接海康大华宇视华为政务公安内网等GB28181国标平台查看级联状态及会话 1、GB/T28181级联是什么2、搭建GB28181国标流媒体平台3、获取上级平台接入信息3.1、如何提供信息给上级3.2、上级国标平台如何添加下级域3.2、接入LiveGBS示例 4、配置国标…...

技术发展驱动编程语言走向
未来编程语言的走向可能会受到多种因素的影响,包括技术进步、市场需求、开发人员的偏好和生态系统的演变等。以下是一些可能的发展趋势: 简洁性和易用性 随着技术的进步,编程语言可能会变得越来越简洁和易于使用。一些语言可能会引入更高级的…...
tp5+workman(GatewayWorker) 安装及使用
一、安装thinkphp5 1、宝塔删除php禁用函数putenv、pcntl_signal_dispatch、pcntl_wai、pcntl_signal、pcntl_alarm、pcntl_fork,执行安装命令。 composer create-project topthink/think5.0.* tp5 --prefer-dist 2、配置好站点之后,浏览器打开访问成…...

vscode安装Prettier插件,对vue3项目进行格式化
之前vscode因为安装了Vue Language Features (Volar)插件,导致Prettier格式化失效,今天有空,又重新设置了一下 1. 插件要先安装上 2. 打开settings.json {"editor.defaultFormatter": "esbenp.prettier-vscode","…...

macOS跨进程通信: XPC 创建实例
一:简介 XPC 是 macOS 里苹果官方比较推荐和安全的的进程间通信机制。 集成流程简单,但是比较绕。 主要需要集成 XPC Server 这个模块,这个模块最终会被 apple 的根进程 launchd 管理和以独立进程的方法唤起和关闭, 我们主app 进…...

Ubuntu18.04 升级Ubuntu20.04
文章目录 背景升级方法遇到的问题 背景 因项目环境需要,欲将Ubuntu18.04升级至Ubuntu20.04,参考网上其他小伙伴的方法,也遇到了一个问题,特此记录一下,希望能帮助其他有同样问题的小伙伴。 升级方法 参考:…...
自动化测试怎么做?看完你就懂了。。。
前言 我想应该有很多测试人员应该有这样的疑虑,自动化测试要怎么去做,现在我把自己的一些学习经验分享给大家,希望对你们有帮助,有说的不好的地方,还请多多指教! 对于测试人员来说,不管进行功…...

小秋SLAM入门实战opencv所有文章汇总
opencv_core和 opencv_imgcodecs是 OpenCV(开源计算机视觉库)的两个主要模块 【如何使用cv::erode()函数对图像进行腐蚀操作】 头文件用途 用OpenCV创建一张类型为CV_8UC1的单通道随机灰度图像 用OpenCV创建一张灰度黑色图像并设置某一列为白色 OpenCV创…...

2023年终总结(脚踏实地,仰望星空)
回忆录 2023年,经历非常多的大事情,找工作、实习、研究生毕业、堂哥结婚、大姐买车、申博、读博、参加马拉松,有幸这一年全家人平平安安,在稳步前进。算是折腾的一年,杭州、赣州、武汉、澳门、珠海、遵义来回跑。完成…...

Transforer逐模块讲解
本文将按照transformer的结构图依次对各个模块进行讲解: 可以看一下模型的大致结构:主要有encode和decode两大部分组成,数据经过词embedding以及位置embedding得到encode的时输入数据 输入部分 embedding就是从原始数据中提取出单词或位置&…...

macOS进程间通信的常用技术汇总
macOS进程间通信的常用技术汇总 命令行传参。yyds管道(pipe), 匿名管道, c的技术,可以跨平台使用 只能在父子进程间通信,由于是单向的管道,只能单方面传输数据。 如果需要双向传输,需要建立双向的两条管道才行 匿名管…...

高德地图信息窗体设置
1. 添加默认信息窗体 //构建信息窗体中显示的内容var info [];info.push(<div style"height: 36px; line-height: 45px; padding: 0px 20px; white-space:nowrap;">位置:北京</div>);info.push(<div style"height: 36px; line-heig…...
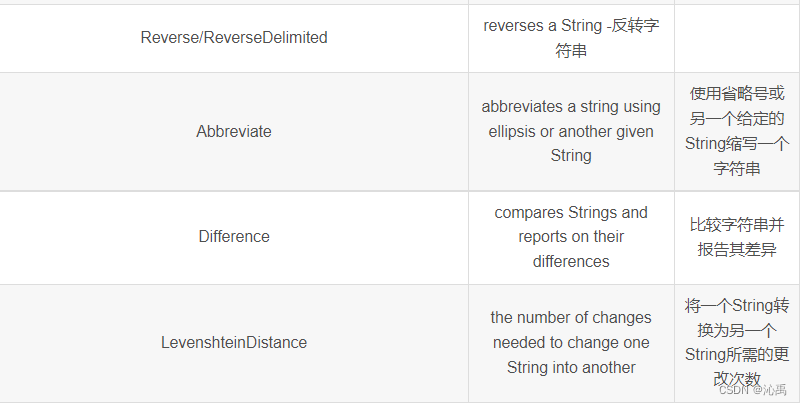
isEmpty 和 isBlank 的用法区别,居然一半的人答不上来.....
isEmpty 和 isBlank 的用法区别 isEmpty系列isBank系列 hi!我是沁禹~ 也许你两个都不知道,也许你除了isEmpty/isNotEmpty/isNotBlank/isBlank外,并不知道还有isAnyEmpty/isNoneEmpty/isAnyBlank/isNoneBlank的存在, come on ,让我们一起来探索org.apache…...

淘宝淘金币自动化脚本终极指南:每天节省20分钟,彻底解放双手
淘宝淘金币自动化脚本终极指南:每天节省20分钟,彻底解放双手 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/t…...

uniapp发开微信小程序处理手机物理按键逻辑
注意:wx.enableAlertBeforeUnload 需要微信小程序基础库 2.32.3 及以上版本如果版本不够,会发 fail 回调,在onLoad里面使用wx.enableAlertBeforeUnload开启物理返回键拦截在onUnload里面处理确认逻辑,wx.disableAlertBeforeUnload关闭物理返回键拦截监听…...

AI工具导航与实战指南:从分类体系到选型策略
1. 项目概述:AI-Infinity,一个前沿AI工具的探索者指南如果你和我一样,对AI领域层出不穷的新工具感到既兴奋又头疼,那么这个项目绝对值得你花时间深入了解。AI-Infinity,这个由开发者meetpateltech维护的GitHub仓库&…...

可视化监控大盘构建:Grafana搭配Prometheus的艺术
在软件测试领域,我们早已不满足于“功能正确”这一单一维度。性能表现、资源消耗、服务稳定性、异常预警……这些非功能质量属性正逐渐成为衡量系统成熟度的关键标尺。而要将这些隐性的、动态的指标转化为可感知、可决策的信息,一套高效、灵活的可视化监…...
搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值)
【LeetCode 手撕算法】(二分查找)搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值
复杂度为O(log n)且有序用二分查找35-搜索插入位置思路:二分查找,左右指针 求中间值注意:while的查询条件是>class Solution {public int searchInsert(int[] nums, int target) {int left0;int rightnums.length-1;while(left<right){…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...
)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程)
告别手搓测试平台:用Synopsys SVT APB VIP快速搭建你的SoC验证环境(附完整配置流程) 在SoC验证领域,APB总线作为AMBA协议家族中最基础的外设连接标准,几乎出现在每一个现代芯片设计中。然而,许多验证工程师…...

Matlab实战:基于EGM2008模型与球谐函数解析全球重力梯度场
1. 地球重力场模型与EGM2008简介 地球重力场是描述地球质量分布的重要物理场,它影响着卫星轨道、海平面变化甚至我们日常使用的导航系统。想象一下,如果把地球比作一个表面凹凸不平的土豆,重力场就是描述这个"土豆"各处引力大小的地…...
)
别再傻等进位了!手把手教你用Verilog实现4位超前进位加法器(附完整代码)
超前进位加法器的Verilog实战:从理论到硬件加速的完整实现 在数字电路设计中,加法器是最基础却又最关键的运算单元之一。传统行波进位加法器虽然结构简单,但在高位宽运算时,其级联进位方式导致的延迟问题会严重影响系统性能。想象…...

从零搭建生产级LLM API服务:架构设计、部署与性能调优实战
1. 项目概述与核心价值 最近在折腾大语言模型本地部署和API服务搭建的朋友,估计都绕不开一个词:文档。不是模型本身的论文,而是那些能把复杂技术栈串起来、让你从“能跑起来”到“能稳定用起来”的操作指南。我关注到 GitHub 上一个名为 var…...