【信息学奥赛】1400:统计单词数
统计单词数也需要分割单词,如果使用字符数组来做的话,其实和1144:单词翻转类似,但是我一直只能通过四个样例,估计边界处理条件还是有点问题。
不过经过打印字符串长度之后发现了之前遇到的一个问题,即fgets在输入的时候会将结束的换行也算进长度。
下述是前面写出来的通过的1144:单词翻转对应的代码,一开始我一直以为最后一个单词的处理是end=len-1,但是一直出错,我还在想为什么会是len-2呢?其实是fgets读取的字符数组的最后一位是换行。如果不太理解,可以通过将空白符转换为显示化内容显示出来,比如,等。
1144:单词翻转的正确做法:
#include <iostream>
#include <cstring>
using namespace std;char s[505];int main() {fgets(s, 505, stdin);int len = strlen(s);int start = 0, end = 0;for (int i = 0; i < len; i++) {if (s[i] == ' ') {end = i - 1;for (int j = end; j >= start; j--) {cout << s[j];}if (i != len - 1) { // 如果不是最后一个单词cout << " ";}start = i + 1;}}// 处理最后一个单词end = len - 2;for (int j = end; j >= start; j--) {cout << s[j];}cout << endl; // 输出一个换行符,保证输出格式正确return 0;
}
发现上述问题后,再进行编写该题,但发现还是有点问题,我想的边界条件是最后一个单词是所述单词,其他边界条件还没想到。
由于是尝试使用字符数组写出来的,所以代码有点冗余。
1400:统计单词数的半残次品做法:
#include<iostream>
#include<cstring>
using namespace std;void transform(char *s);
void ismatch(char *p,char *s);char p[30];
char s[500];int ind=0; //下标
int num=0; //个数int main()
{scanf("%s",p);//cout<<strlen(p)<<endl;getchar(); //去掉空格fgets(s,500,stdin);s[strlen(s)-1]=' '; //将最后的空白符替换成空格//cout<<strlen(s)<<endl;transform(p);transform(s);// cout<<p<<endl<<s<<endl;ismatch(p,s);if(num==0)cout<<"-1"<<endl;elsecout<<num<<" "<<ind<<endl;return 0;
}//转换成小写
void transform(char *s)
{for(int i=0;i<strlen(s);i++){if(s[i]>='A'&&s[i]<='Z')s[i]+=32;}
}//s已经处理过
void ismatch(char *p,char *s)
{int len1=strlen(p),len2=strlen(s),start=0;//cout<<strlen(p)<<endl;//cout<<strlen(s)<<endl;bool flag=true,flagi=false;for(int i=0;i<len2;i++){if(s[i]==' '){if(len1==(i-start)) //长度相等{flag=true;for(int j=0,k=start;j<len1;j++,k++){if(p[j]!=s[k]){flag=false;break;}}if(flag){num++;if(!flagi){ind=start;flagi=true;}}}start=i+1;}}
}
后来反复看才知道,是题目没说清楚,文章长度范围是1<=len<=1000000,所以将上述s数组开大了一点,但是后面五个案例超时了。
1400:统计单词数的半残次品做法更正后的超时做法1:
#include<iostream>
#include<cstring>
using namespace std;void transform(char *s);
void ismatch(char *p,char *s);char p[30];
char s[1000010];int ind=0; //下标
int num=0; //个数int main()
{scanf("%s",p);//cout<<strlen(p)<<endl;getchar(); //去掉空格fgets(s,1000010,stdin);s[strlen(s)-1]=' '; //将最后的空白符替换成空格//cout<<strlen(s)<<endl;transform(p);transform(s);// cout<<p<<endl<<s<<endl;ismatch(p,s);if(num==0)cout<<"-1"<<endl;elsecout<<num<<" "<<ind<<endl;return 0;
}//转换成小写
void transform(char *s)
{for(int i=0;i<strlen(s);i++){if(s[i]>='A'&&s[i]<='Z')s[i]+=32;}
}//s已经处理过
void ismatch(char *p,char *s)
{int len1=strlen(p),len2=strlen(s),start=0;//cout<<strlen(p)<<endl;//cout<<strlen(s)<<endl;bool flag=true,flagi=false;for(int i=0;i<len2;i++){if(s[i]==' '){if(len1==(i-start)) //长度相等{flag=true;for(int j=0,k=start;j<len1;j++,k++){if(p[j]!=s[k]){flag=false;break;}}if(flag){num++;if(!flagi){ind=start;flagi=true;}}}start=i+1;}}
}
既然显示超时,那么算法思路应该是没问题的,主要是需要优化算法的时间复杂度和空间复杂度啦。
将上述更改为朴素匹配法,发现仍然超时,这是因为复杂度为O(len1*len2),其中len1是单词长度,len2是文章长度,这样很容易超时。
1400:统计单词数的半残次品做法更正后的超时做法2:
#include<iostream>
#include<cstring>
using namespace std;void transform(char *s);
void ismatch(char *p,char *s);char p[30];
char s[1000010];int ind=0; //下标
int num=0; //个数int main()
{scanf("%s",p);//cout<<strlen(p)<<endl;getchar(); //去掉空格fgets(s,1000010,stdin);s[strlen(s)-1]=' '; //将最后的空白符替换成空格//cout<<strlen(s)<<endl;transform(p);transform(s);// cout<<p<<endl<<s<<endl;ismatch(p,s);if(num==0)cout<<"-1"<<endl;elsecout<<num<<" "<<ind<<endl;return 0;
}//转换成小写
void transform(char *s)
{for(int i=0;i<strlen(s);i++){if(s[i]>='A'&&s[i]<='Z')s[i]+=32;}
}//s已经处理过
void ismatch(char *p,char *s)
{int len1=strlen(p),len2=strlen(s),start=0;//cout<<p<<endl;//cout<<strlen(p)<<endl;//cout<<s<<endl;//cout<<strlen(s)<<endl;for(int i=0;i<len2;i++) //i表示起始位置{int j; //在for外面int就不要再在for里面int了for(j=0;j<len1;j++) //j表示待匹配位置 {//cout<<"j:"<<j<<endl;//cout<<"s[i+j]:"<<s[i+j]<<endl;//cout<<"p[j]:"<<p[j]<<endl;if(s[i+j]!=p[j])break;if(i>0&&s[i-1]!=' ')break;}//cout<<"j:"<<j<<endl;if(j==len1&&s[i+j]==' '){num++;if(num==1)ind=i;}}
}
如果不是按照字符输入,而是按照单词输入,再判断单词和单词是否匹配,那么将会大大降低复杂度,一个单词则使用字符串存储,一篇文章则使用字符串数组存储。
字符串,最好使用string来处理,其中自带很多函数,下面是通过的字符串匹配的暴力算法,即朴素算法。
1400:统计单词数的正确做法:
#include<bits/stdc++.h>
using namespace std;string word,sen; //word表示单词 sen表示句子
int ans; //表示个数
int ind; //表示第一次初始的位置int main()
{getline(cin,word); //读取单词getline(cin,sen); //读取句子int len1=word.size();int len2=sen.size();for(int i=0;i<len2;i++) //遍历句子 表示起始位置{int j;for(j=0;j<len1;j++) //遍历单词 表示当前单词位置{if(tolower(sen[i+j])!=tolower(word[j])) //对应字符不相等break;if(i>0&&sen[i-1]!=' ') //当前不为第一个单词且当前前一个不为空格 则表示不为独立单词break;}if(j==len1&&sen[i+j]==' '||i+j==len2) //如果为单词尾且后面有空格 或者为文章尾部{ans++; //满足的个数if(ans==1) //第一次出现ind=i; //记录下标}}if(ans)cout<<ans<<" "<<ind<<endl;elsecout<<-1<<endl;return 0;
}
注意:使用字符数组需谨慎!尝试尝试字符串!或者字符串数组!
相关文章:

【信息学奥赛】1400:统计单词数
统计单词数也需要分割单词,如果使用字符数组来做的话,其实和1144:单词翻转类似,但是我一直只能通过四个样例,估计边界处理条件还是有点问题。 不过经过打印字符串长度之后发现了之前遇到的一个问题,即fget…...

# 技术详解: 利用CI同步文章以及多端发布
技术详解: 利用CI同步文章以及多端发布 技术详解: 利用CI同步文章以及多端发布 前言文章的同步实现的细节 思路文章元数据的定义和提取修改文章的优化本地图片资源上传CDN并替换本地link 终于到了 CI 的部分了最后来一些碎碎念 前言 前几天我更新了一篇简单技术总结之后&am…...

分形维数的计算方法汇总
以下是常用的时间序列分形维数计算方法及相应的参考文献:Hurst指数法Hurst指数法是最早用于计算分形维数的方法之一,其基本思想是通过计算时间序列的长程相关性来反映其分形特性。具体步骤是:(1) 对原始时间序列进行标准化处理。(2) 将序列分…...
)
微积分小课堂:积分(从微观趋势了解宏观变化)
文章目录 引言I. 预备知识: 积分效应1.1 闯黄灯1.2 公司利润(飞轮效应)1.3 飞轮效应II 积分2.1 积分的计算2.2 积分思想的本质引言 微分解决的问题是从宏观变化了解微观趋势;积分和微分刚好相反,是从微观去看宏观变化。 通过积分效应,提升我们的认识水平,同时能用一些工…...
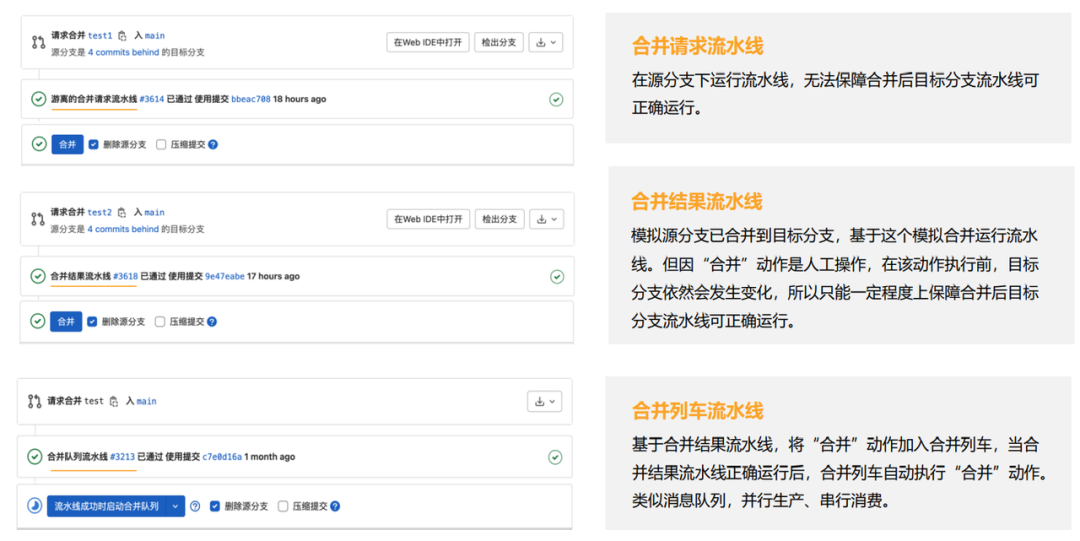
4道数学题,求解极狐GitLab CI 流水线|第4题:合并列车
本文来自: 武让 极狐GitLab 高级解决方案架构师 💡 极狐GitLab CI 依靠其一体化、轻量化、声明式、开箱即用的特性,在开发者群体中的使用率越来越高,在国内企业中仅次于 Jenkins ,排在第二位。 极狐GitLab 流水线有 4…...

代码规范简述
目录 命名规范 代码格式 OOP规约 集合规范 并发规范 SQL语句规范 SQL 建表规范 SQL 索引规范 SQL 查询规范 控制语句规范 Javadoc 规范 其他规范 命名规范 1、包名:使用小写字母,多个单词之间用"."分隔,例如ÿ…...

【Java集合框架】篇五:Map接口
1. Map及实现类特点 Map:存储key-value HashMap:线程不安全,效率高,key和value都可以为null,底层使用 数组单向链表红黑树 结构(jdk8)。 LinkedHashMap:是HashMap的子类࿰…...

Typroa安装教程
Markdown 是一种轻量级标记语言,创始人为约翰格鲁伯(John Gruber)。 它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的 XHTML(或者HTML)文档。这种语言吸收了很多在电子邮件中已有的纯文本标记…...
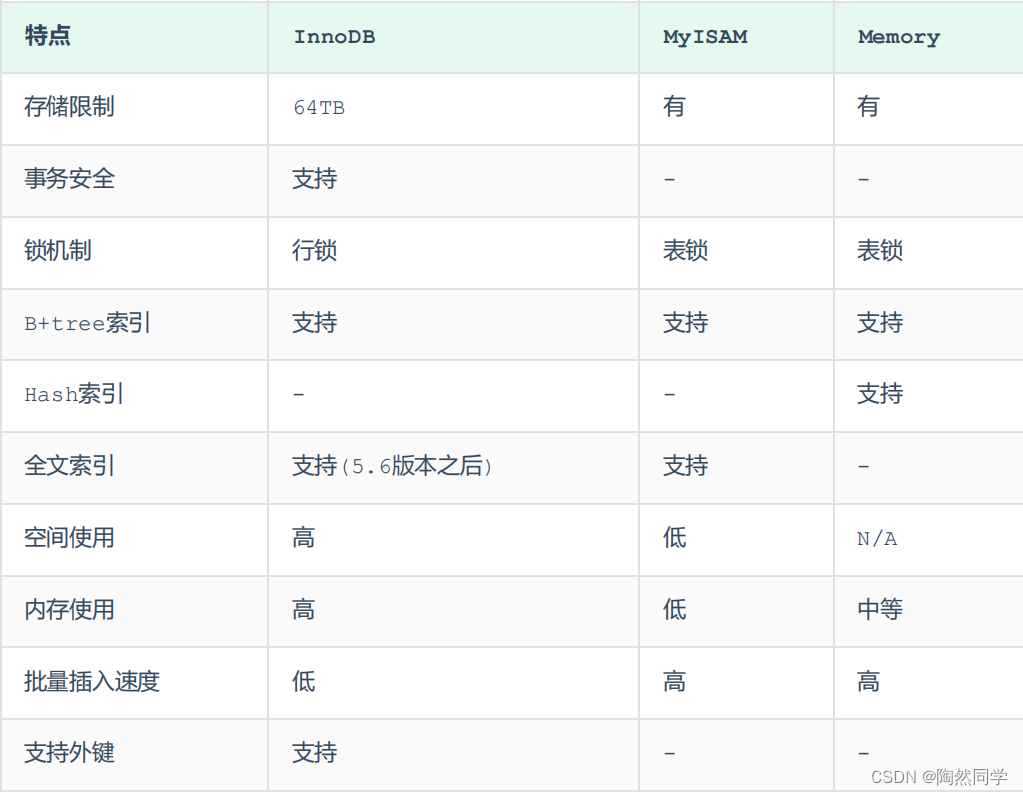
【MySQL】存储引擎
目录 1.MySQL体系结构 2.存储引擎介绍 3.存储引擎特点 4.存储引擎选择 1.MySQL体系结构 MySQL整体的逻辑结构可以分为4层,客户层、服务层、存储引擎层、数据层 客户层 客户层:进行相关的连接处理、权限控制、安全处理等操作 服务层 服务层负责与客户层进行连接处理、处…...
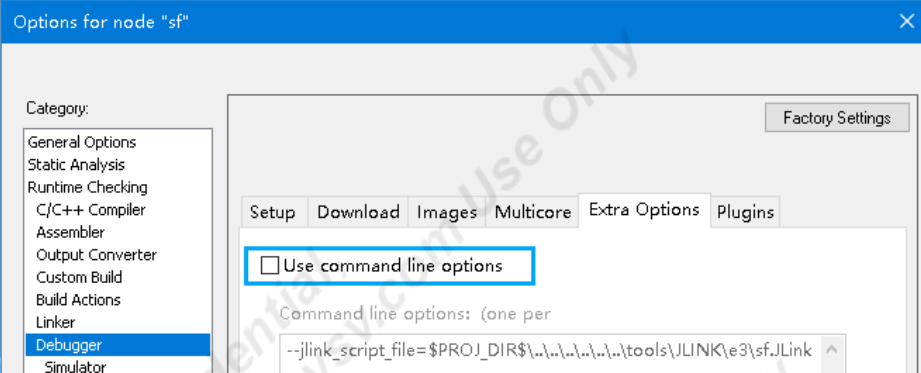
芯驰(E3-gateway)开发板环境搭建以及调试遇到问题的解决
1-Windows下环境配置 可以在Windows上使用命令行或者IAR IDE编译SSDK项目。Windows编译依赖的工具已经包含在 prebuilts/windows 目录中,包括编译器、Python和命令行工具。 1.1.1 CMD SSDK集成 msys 工具,可以在Windows命令行中完成SDK的配置、编译和…...
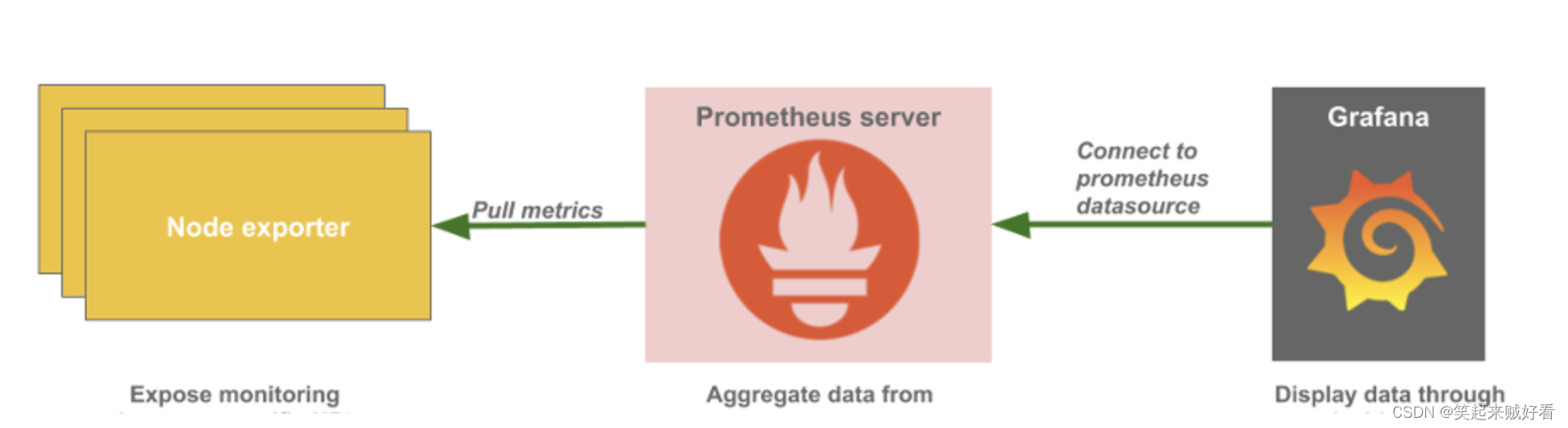
【大数据监控】Prometheus、Node_exporter、Graphite_exporter安装部署详细文档
目录Prometheus简介下载软件包安装部署创建用户创建Systemd服务修改配置文件prometheus.yml启动Prometheusnode exporter下载软件包安装部署添加用户创建systemd服务启动node_exportergraphite_exporter下载软件包安装部署创建systemd服务启动 graphite_exporterPrometheus 简介…...

《C++ Primer》 第十一章 关联容器
《C Primer》 第十一章 关联容器 11.1 使用关联容器 使用map: //统计每个单词在输入中出现的次数 map<string, size_t> word_count;//string到size_t的空map string word; while(cin>>word)word_count[word];//提取word的计数器并将其加1 for(const auto &w:…...

WebRTC标准与框架解读(1)
1、如果让我来设计webrtc框架我在分析源码的时候,都喜欢做这样一件事情:如果让我来设计它,我会怎么做?大家可以紧跟我的思路,分析一下WebRTC为什么如此设计。为了对整个框架有有一个全面的了解,我们首先要做…...
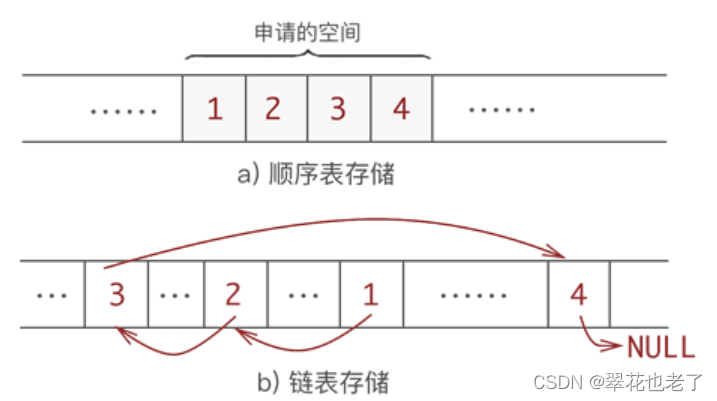
数据结构的一些基础概念
一 基本术语 数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。 数据元素:是组成数据的,有一定意义的基本单位,在计算机中通常作为整体处…...

【Python每日一练】总目录(不断更新中...)
Python 2023.03 20230303 1. 两数之和 ★ 2. 组合总和 ★★ 3. 相同的树 ★★ 20230302 1. 字符串统计 2. 合并两个有序链表 3. 下一个排列 20230301 1. 只出现一次的数字 2. 以特殊格式处理连续增加的数字 3. 最短回文串 Python 2023.02 20230228 1. 螺旋矩阵 …...
)
latex插入图片(自用)
加入宏包:\usepackage{graphicx} 使用 \includegraphics 命令进行插图。 \includegraphics[]{}: 第一参数[]:对图片做一些适当的调整(设定图片的高度和宽度或者按比例缩放) 第二参数{}:图片的名字…...

【微信小程序】-- 网络数据请求(十九)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

K8S 实用工具之一 - 如何合并多个 kubeconfig?
开篇 📜 引言: 磨刀不误砍柴工工欲善其事必先利其器 K8S 集群规模,有的公司倾向于少量大规模 K8S 集群,也有的公司会倾向于大量小规模的 K8S 集群。 如果是第二种情况,是否有一个简单的 kubectl 命令来获取一个 kubec…...
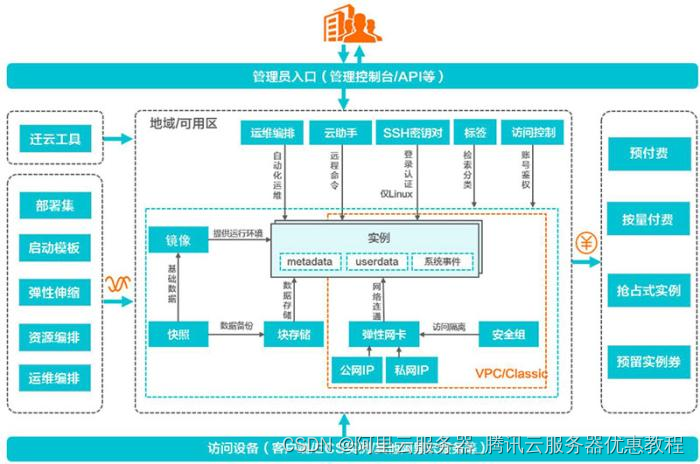
阿里云ECS服务器的6大功能组件
阿里的云服务在国内可以说是首屈一指的了,因此他们家的云服务器也是最受欢迎的。那么,你知道阿里云服务器ECS有哪些功能组件吗?不清楚不要紧,下面服务器吧小编带大家来看看。 在了解之前我们来看一张阿里云服务器ECS的产品组件架…...

外贸建站多少钱?不同预算对应的建站方案!
外贸建站多少钱? 答案是:3000左右。 作为一个外贸企业的经营者,我们深知一个优质的外贸网站对于企业的重要性。 然而,建立一个优质的外贸网站需要耗费大量的时间和资金,因此我们需要在预算有限的情况下,…...
)
别再复制粘贴了!手把手教你用Simscape Language从零创建自定义物理模块(附完整代码)
从零构建Simscape自定义物理模块:工程师的深度实践指南 在物理系统建模领域,预置的标准化组件库往往无法满足复杂工程场景的需求。当您面对一个特殊的齿轮传动机构、非线性的液压元件或是定制化的传感器模型时,掌握Simscape Language的自定义…...
)
网易技术岗校招通关秘籍:从需求画像到Offer收割(实战篇)
1. 网易技术岗校招需求画像解析 第一次参加大厂校招的同学,往往会被各种岗位JD绕晕。去年我带过一个浙大的学弟,他同时投了网易的Java和后端开发岗,结果发现笔试题目完全不同。后来才知道,网易不同业务线对"后端开发"的…...

3步开启Windows实时语音转文字:TMSpeech离线语音识别完全指南
3步开启Windows实时语音转文字:TMSpeech离线语音识别完全指南 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech TMSpeech是一款专为Windows系统设计的开源实时语音识别工具,能够将电脑系统声音…...

储能出海架构重构:摒弃传统x86工控机,基于ARM边缘节点的EMS策略下沉实战
摘要: 随着储能系统在全球范围的大规模部署,出海项目的硬件BOM成本压力与恶劣环境下的维护成本日益凸显。传统的“x86工控机下发控制 透传网关上传数据”的双体架构显得极度臃肿且易引发单点故障。本文从底层研发架构师视角出发,深度拆解符合…...

如何高效清理游戏平台残留文件:SteamCleaner一站式解决方案指南
如何高效清理游戏平台残留文件:SteamCleaner一站式解决方案指南 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://gitcode.c…...

如何高效配置智能游戏助手:绝区零一条龙完整使用攻略
如何高效配置智能游戏助手:绝区零一条龙完整使用攻略 【免费下载链接】ZenlessZoneZero-OneDragon 绝区零 一条龙 | 全自动 | 自动闪避 | 自动每日 | 自动空洞 | 支持手柄 项目地址: https://gitcode.com/gh_mirrors/ze/ZenlessZoneZero-OneDragon 还在为《绝…...

VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战
VideoDownloadHelper深度解析:破解主流视频平台下载限制的技术实战 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存…...

DeepRead Skills:为AI编程助手注入OCR与文档处理能力
1. 项目概述:为AI助手注入文档处理“超能力”如果你和我一样,日常开发中重度依赖Claude Code、Cursor这类AI编程助手,那你肯定遇到过这样的场景:想让它帮你写一段调用OCR API的代码,结果它要么给你一个过时的库示例&am…...

3篇6章3节:半眼图与全眼图,分布形态与不确定性表达的统一可视化方法
在现代数据科学与医学统计分析中,数据可视化的目标已从单纯展示数值变化,逐步转向同时刻画“分布结构”与“统计不确定性”。传统箱线图虽然能够提供中位数与四分位数范围,但其表达方式过于离散,难以反映数据的连续分布形态;小提琴图虽然引入核密度估计,能够展示分布形状…...

HTTP自适应流媒体技术解析:从HLS/DASH原理到实战部署
1. 流媒体技术演进:从“下载后播放”到“自适应缓冲”每天我们打开手机或电脑,点开一个视频,看到那个旋转的加载圈,心里总会咯噔一下。这个被称为“缓冲”的现象,早已成为数字生活的一部分。但你是否想过,为…...