【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具DataX 实现数据同步
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具Datax实现数据同步
1、准备工作:
- JDK(1.8 以上,推荐 1.8)
- Python(23 版本都可以)
- Apache Maven 3.x(Compile DataX)(手动打包使用,使用
tar包方式不需要安装)
| 主机名 | 操作系统 | IP 地址 | 软件包 |
| MySQL-1 | CentOS 7.4 | 192.168.1.1 | jdk-8u181-linux-x64.tar.gz datax.tar.gz |
| MySQL-2 | CentOS 7.4 | 192.168.1.2 |
2、安装 JDK:
下载地址:Java Archive Downloads - Java SE 8(需要创建 Oracle 账号)
[root@MySQL-1 ~]# ls anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz [root@MySQL-1 ~]# tar zxf jdk-8u181-linux-x64.tar.gz [root@DataX ~]# ls anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz [root@MySQL-1 ~]# mv jdk1.8.0_181 /usr/local/java [root@MySQL-1 ~]# cat <<END >> /etc/profile export JAVA_HOME=/usr/local/java export PATH=$PATH:"$JAVA_HOME/bin" END [root@MySQL-1 ~]# source /etc/profile [root@MySQL-1 ~]# java -version
- 因为
CentOS 7上自带Python 2.7的软件包,所以不需要进行安装。
3、Linux 上安装 DataX 软件
[root@MySQL-1 ~]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz [root@MySQL-1 ~]# tar zxf datax.tar.gz -C /usr/local/ [root@MySQL-1 ~]# rm -rf /usr/local/datax/plugin/*/._*
- 当未删除时,可能会输出:
[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 请检查您的配置文件.
验证:
[root@MySQL-1 ~]# cd /usr/local/datax/bin [root@MySQL-1 ~]# python datax.py ../job/job.json
输出:
2021-12-13 19:26:28.828 [job-0] INFO JobContainer - PerfTrace not enable! 2021-12-13 19:26:28.829 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.060s | All Task WaitReaderTime 0.068s | Percentage 100.00% 2021-12-13 19:26:28.829 [job-0] INFO JobContainer - 任务启动时刻 : 2021-12-13 19:26:18 任务结束时刻 : 2021-12-13 19:26:28 任务总计耗时 : 10s 任务平均流量 : 253.91KB/s 记录写入速度 : 10000rec/s 读出记录总数 : 100000 读写失败总数 : 0
4、DataX 基本使用
查看 streamreader \--> streamwriter 的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
输出:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [], "sliceRecordCount": ""}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "", "print": true}}}], "setting": {"speed": {"channel": ""}}}
}
根据模板编写 json 文件
[root@MySQL-1 ~]# cat <<END > test.json
{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [ # 同步的列名 (* 表示所有){"type":"string","value":"Hello."},{"type":"string","value":"河北彭于晏"},], "sliceRecordCount": "3" # 打印数量}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "utf-8", # 编码"print": true}}}], "setting": {"speed": {"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)}}}
}
输出:(要是复制我上面的话,需要把 # 带的内容去掉)

5、安装 MySQL 数据库
分别在两台主机上安装:
[root@MySQL-1 ~]# yum -y install mariadb mariadb-server mariadb-libs mariadb-devel
[root@MySQL-1 ~]# systemctl start mariadb # 安装 MariaDB 数据库
[root@MySQL-1 ~]# mysql_secure_installation # 初始化
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDBSERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!Enter current password for root (enter for none): # 直接回车
OK, successfully used password, moving on...
Set root password? [Y/n] y # 配置 root 密码
New password:
Re-enter new password:
Password updated successfully!
Reloading privilege tables..... Success!
Remove anonymous users? [Y/n] y # 移除匿名用户... skipping.
Disallow root login remotely? [Y/n] n # 允许 root 远程登录... skipping.
Remove test database and access to it? [Y/n] y # 移除测试数据库... skipping.
Reload privilege tables now? [Y/n] y # 重新加载表... Success!
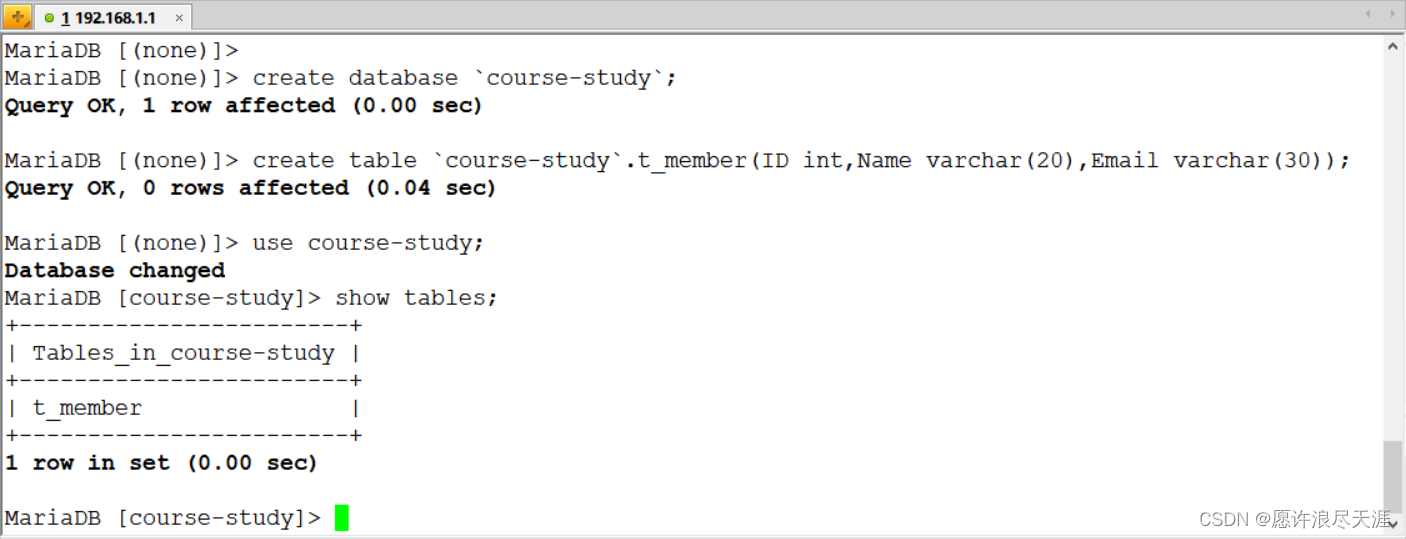
1)准备同步数据(要同步的两台主机都要有这个表)
MariaDB [(none)]> create database `course-study`;
Query OK, 1 row affected (0.00 sec)MariaDB [(none)]> create table `course-study`.t_member(ID int,Name varchar(20),Email varchar(30));
Query OK, 0 rows affected (0.00 sec)
因为是使用 DataX 程序进行同步的,所以需要在双方的数据库上开放权限:
grant all privileges on *.* to root@'%' identified by '123123';
flush privileges;
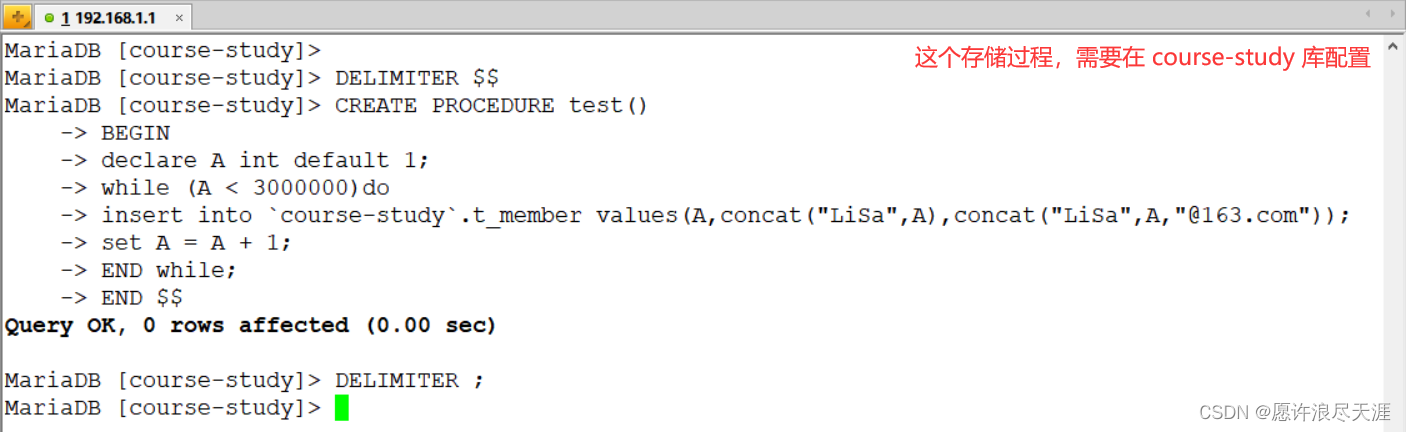
2)创建存储过程:
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
declare A int default 1;
while (A < 3000000)do
insert into `course-study`.t_member values(A,concat("LiSa",A),concat("LiSa",A,"@163.com"));
set A = A + 1;
END while;
END $$
DELIMITER ;
3)调用存储过程(在数据源配置,验证同步使用):
call test();
6、通过 DataX 实 MySQL 数据同步
1)生成 MySQL 到 MySQL 同步的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter
{"job": {"content": [{"reader": {"name": "mysqlreader", # 读取端"parameter": {"column": [], # 需要同步的列 (* 表示所有的列)"connection": [{"jdbcUrl": [], # 连接信息"table": [] # 连接表}], "password": "", # 连接用户"username": "", # 连接密码"where": "" # 描述筛选条件}}, "writer": {"name": "mysqlwriter", # 写入端"parameter": {"column": [], # 需要同步的列"connection": [{"jdbcUrl": "", # 连接信息"table": [] # 连接表}], "password": "", # 连接密码"preSql": [], # 同步前. 要做的事"session": [], "username": "", # 连接用户 "writeMode": "" # 操作类型}}}], "setting": {"speed": {"channel": "" # 指定并发数}}}
}
2)编写 json 文件:
[root@MySQL-1 ~]# vim install.json
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"username": "root","password": "123123","column": ["*"],"splitPk": "ID","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"], "table": ["t_member"]}]}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["*"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8","table": ["t_member"]}], "password": "123123","preSql": ["truncate t_member"], "session": ["set session sql_mode='ANSI'"], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "5"}}}
}
3)验证
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py install.json
输出:
2021-12-15 16:45:15.120 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-15 16:45:15.120 [job-0] INFO StandAloneJobContainerCommunicator - Total 2999999 records, 107666651 bytes | Speed 2.57MB/s, 74999 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 82.173s | All Task WaitReaderTime 75.722s | Percentage 100.00%
2021-12-15 16:45:15.124 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-15 16:44:32
任务结束时刻 : 2021-12-15 16:45:15
任务总计耗时 : 42s
任务平均流量 : 2.57MB/s
记录写入速度 : 74999rec/s
读出记录总数 : 2999999
读写失败总数 : 0
你们可以在目的数据库进行查看,是否同步完成。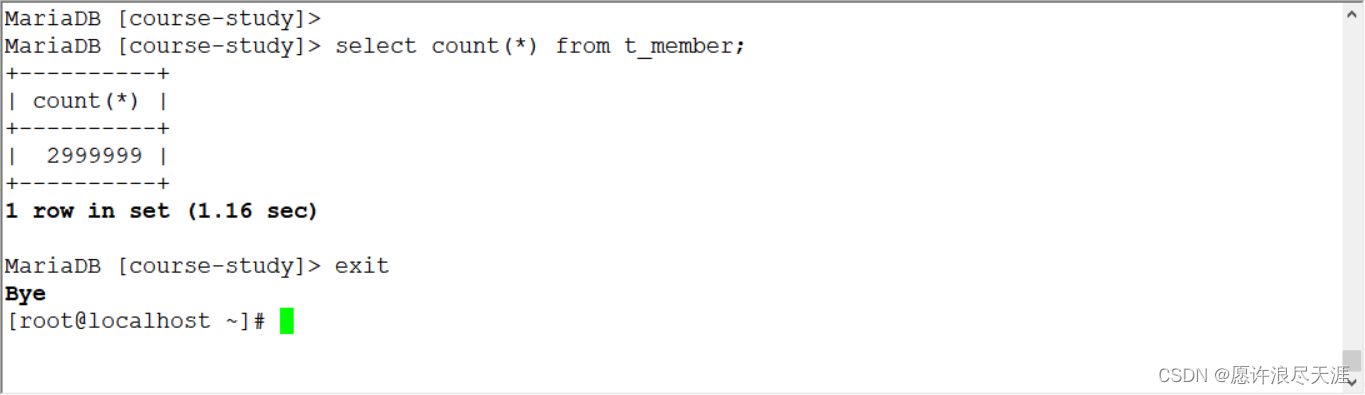
- 上面的方式相当于是完全同步,但是当数据量较大时,同步的时候被中断,是件很痛苦的事情;
- 所以在有些情况下,增量同步还是蛮重要的。
7、使用 DataX 进行增量同步
使用 DataX 进行全量同步和增量同步的唯一区别就是:增量同步需要使用 where 进行条件筛选。(即,同步筛选后的 SQL)
1)编写 json 文件:
[root@MySQL-1 ~]# vim where.json
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"username": "root","password": "123123","column": ["*"],"splitPk": "ID","where": "ID <= 1888","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"], "table": ["t_member"]}]}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["*"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8","table": ["t_member"]}], "password": "123123","preSql": ["truncate t_member"], "session": ["set session sql_mode='ANSI'"], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "5"}}}
}
- 需要注意的部分就是:
where(条件筛选) 和preSql(同步前,要做的事) 参数。
2)验证:
[root@MySQL-1 ~]# python /usr/local/data/bin/data.py where.json
输出:
2021-12-16 17:34:38.534 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-16 17:34:38.534 [job-0] INFO StandAloneJobContainerCommunicator - Total 1888 records, 49543 bytes | Speed 1.61KB/s, 62 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.002s | All Task WaitReaderTime 100.570s | Percentage 100.00%
2021-12-16 17:34:38.537 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-16 17:34:06
任务结束时刻 : 2021-12-16 17:34:38
任务总计耗时 : 32s
任务平均流量 : 1.61KB/s
记录写入速度 : 62rec/s
读出记录总数 : 1888
读写失败总数 : 0
目标数据库上查看: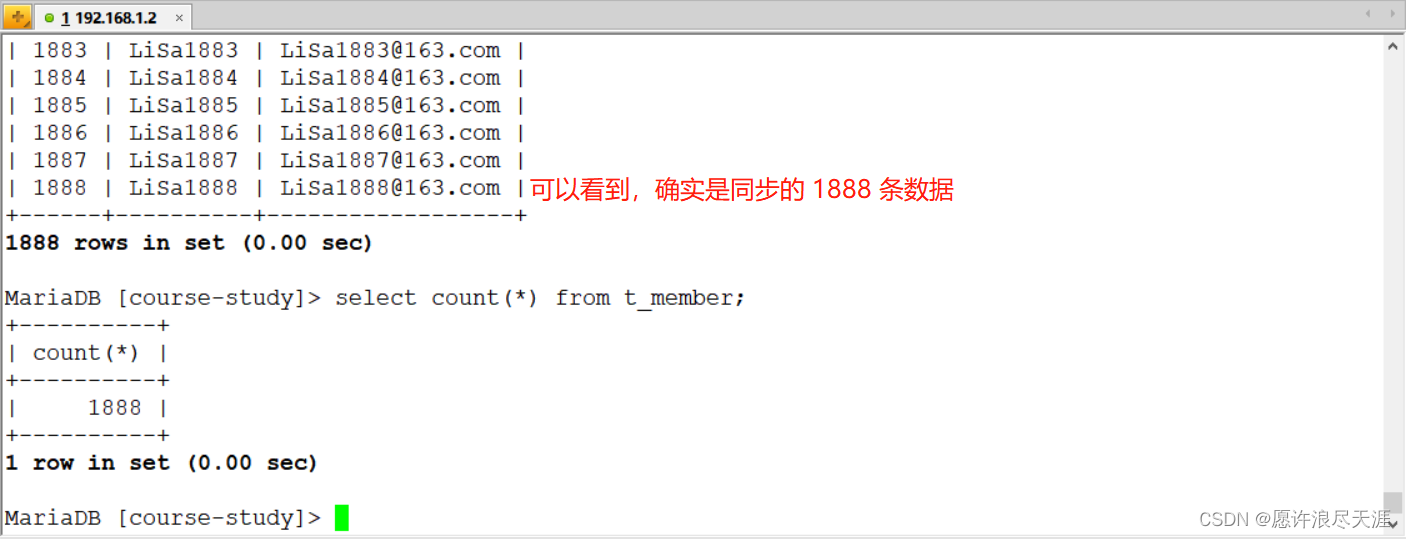
3)基于上面数据,再次进行增量同步:
主要是 where 配置:"where": "ID > 1888 AND ID <= 2888" # 通过条件筛选来进行增量同步
同时需要将我上面的 preSql 删除(因为我上面做的操作时 truncate 表)

相关文章:
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具DataX 实现数据同步
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图 【大数据进阶第三阶段之Datax学习笔记】使用…...

kotlin chunked 和 windowed
kotlin chunked的作用 将集合按照指定的数量分割成多个结合 val numbers listOf(0,1,2,3,4,5,6,7,8,9) //把集合按照一个结合3个元素分割 Log.d("chunked", numbers.chunked(3).toString()) // 打印结果 [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] kotlin windowed…...
C语言光速入门笔记
C语言是一门面向过程的编译型语言,它的运行速度极快,仅次于汇编语言。C语言是计算机产业的核心语言,操作系统、硬件驱动、关键组件、数据库等都离不开C语言;不学习C语言,就不能了解计算机底层。 目录 C语言介绍C语言特…...

Flutter+Go_Router+Fluent_Ui仿阿里网盘桌面软件开发跨平台实战-买就送仿小米app开发
Flutter是谷歌公司开发的一款开源、免费的UI框架,可以让我们快速的在Android和iOS上构建高质量App。它最大的特点就是跨平台、以及高性能。 目前 Flutter 已经支持 iOS、Android、Web、Windows、macOS、Linux 的跨平台开发。 Flutter官方介绍,目前Flutte…...
内联函数的作用
目的 主要为了提升程序运行速度。 分析 当程序调用一个函数时,程序暂停执行当前指令,跳到函数体处执行,在函数执行完后,返回原来的位置继续执行。如果该函数为内联函数,则不需跳,是因为该内联函数直接插…...
Simpy简介:python仿真模拟库-02/5
一、说明 关于python下的仿真库,本篇为第二部分,是更进一步的物理模型讲解,由于这部分内容强依赖于第一部分的符号介绍,因此,有以下建议: 此文为第二部分,若看第一部分。建议查看本系列的第一部…...

Kafka高级应用:如何配置处理MQ百万级消息队列?
在大数据时代,Apache Kafka作为一款高性能的分布式消息队列系统,广泛应用于处理大规模数据流。本文将深入探讨在Kafka环境中处理百万级消息队列的高级应用技巧。 本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经…...

LIN总线学习笔记(1)-总线传输规范
关注菲益科公众号—>对话窗口发送 “CANoe ”或“INCA”,即可获得canoe入门到精通电子书和INCA软件安装包(不带授权码)下载地址。 接触LIN是从最近负责项目中开始的。项目已经快要量产了,因为中间遇到的大大小小的问题…...

Qt界面篇:Qt停靠控件QDockWidget、树控件QTreeWidget及属性控件QtTreePropertyBrowser的使用
1、功能介绍 本篇主要使用Qt停靠控件QDockWidget、树控件QTreeWidget及Qt属性控件QtTreePropertyBrowser来搭建一个简单实用的主界面布局。效果如下所示。 2、控件使用详解 2.1 停靠控件QDockWidget QDockWidget可以停靠在 QMainWindow 内或作为桌面上的顶级窗口浮动。默认值…...
H266/VVC网络适配层概述
视频编码标准的分层结构 视频数据分层的必要性:网络类型的多样性、不同的应用场景对视频有不同的需求。 编码标准的分层结构:为了适应不同网络和应用需求,视频编码数据根据其内容特性被分成若干NAL单元(NAL Unit,NALU…...
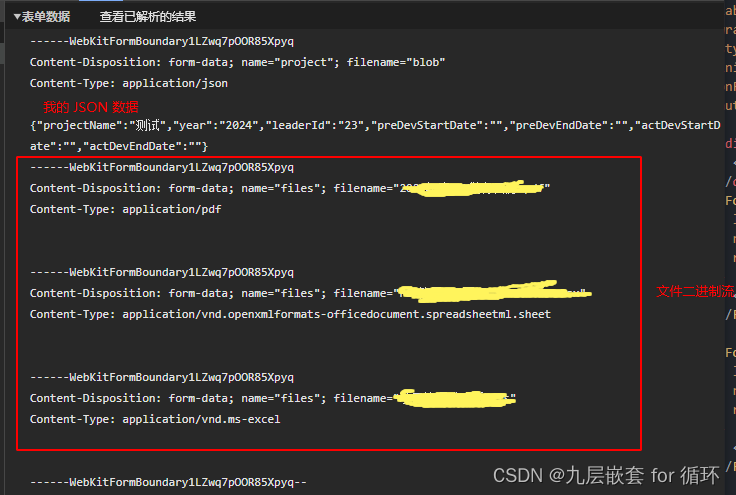
new FormData 同时发送表单 json 以及文件二进制流
需要新增时同时发送表单 json 以及对应的文件即可使用以下方法传参 let formDataParams new FormData(); 首先通过 new FormData() 创建你需要最后发送的表单 接着将你的对象 json 存储,注意使用 new Blob 创建大表单转换成 json 格式。以…...
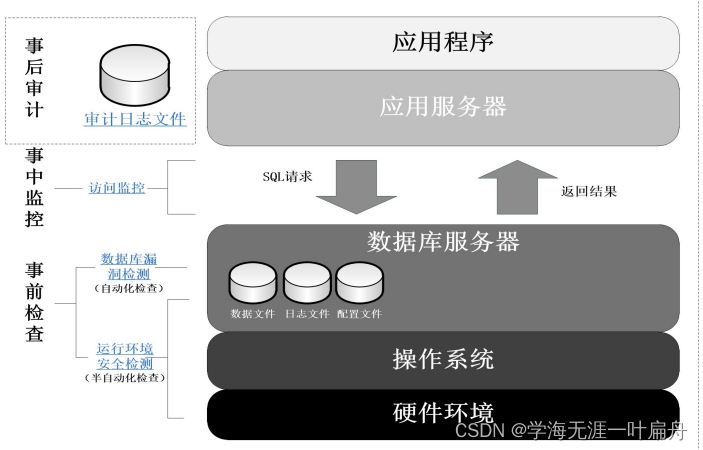
计算机环境安全
操作系统安全----比如windows,linux 安全标识--实体唯一性 windows---主体:账户,计算机,服务 安全标识符SID-Security Identifier 普通用户SID是1000,管理用SID是500 linux---主体:用户,用户组…...

Activiti7工作流引擎:多租户
一:多租户 表示每个租户之间数据隔离互不影响,互不可见。通常一个租户表示一个系统应用(类似于appid的作用)或者一家公司。 通过数据库级别进行隔离,每个租户对应一个数据库;通过表记录级别进行隔离&…...
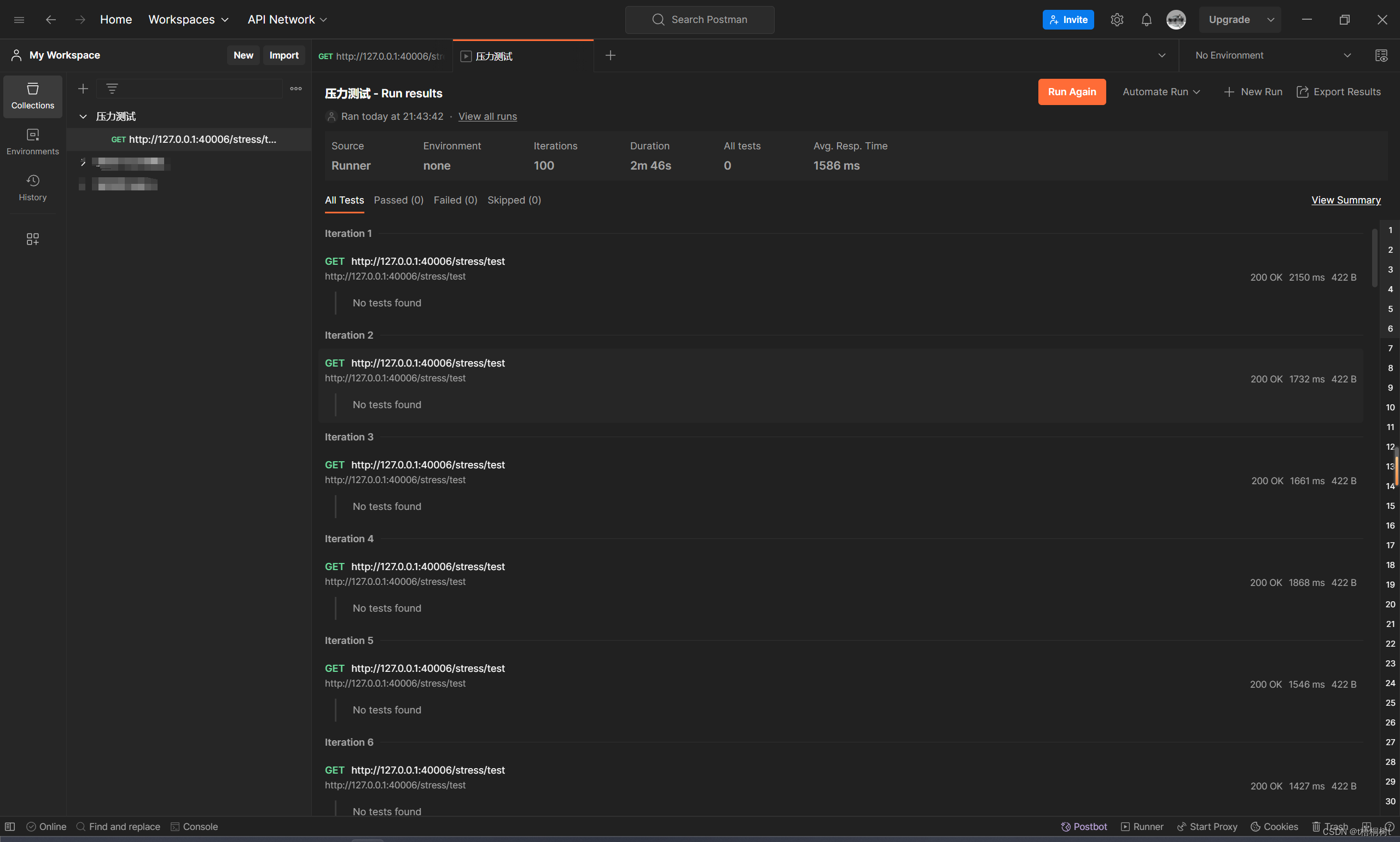
Postman实现压力测试
从事软件开发对于压力测试并不陌生,常见的一些压测软件有Apache JMeter LoadRunner Gatling Tsung 等,这些都是一些比较专业的测试软件,对于我的工作来说一般情况下用不到这么专业的测试,有时候需要对一些接口进行压力测试又不想再安装新软件,那么可以使用Postman来实现对…...
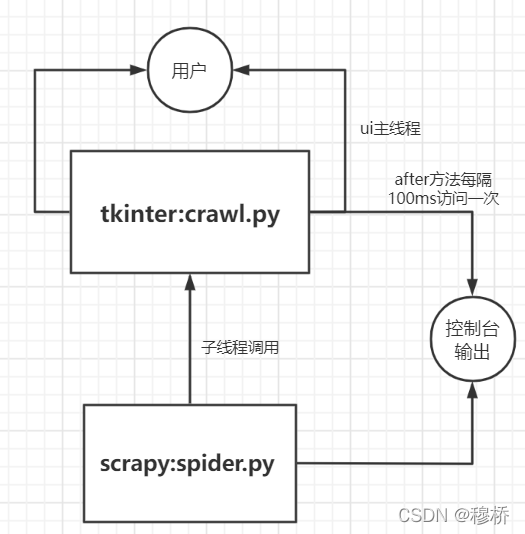
爬虫工具(tkinter+scrapy+pyinstaller)
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个and关系的关键字 ,则用|隔开处理:爬取访问6个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段࿰…...

MySQL常用sql语句记录
1,创建用户及赋权 -- 创建用户 CREATE USER usernamelocalhost IDENTIFIED BY password;-- 赋予所有权限 GRANT ALL PRIVILEGES ON database_name.* TO usernamelocalhost;-- 赋予特定表的某些权限 GRANT SELECT, INSERT ON table_name TO usernamelocalhost;-- 更…...

2024.1.4力扣每日一题——被列覆盖的最多行数
2024.1.4 题目来源我的题解方法一 回溯位运算优化 题目来源 力扣每日一题;题序:2397 我的题解 方法一 回溯位运算优化 这道题一看就会想到使用回溯法,但是采用回溯法后如何判断有多少行被覆盖,直接计算矩阵时间复杂度较高&…...
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)
本实践教程将教你如何使用 Elasticsearch 构建完整的搜索解决方案。 在本教程中你将学习: 如何对数据集执行全文关键字搜索(可选使用过滤器)如何使用机器学习模型生成、存储和搜索密集向量嵌入如何使用 ELSER 模型生成和搜索稀疏向量如何使用…...

第五讲_css元素显示模式
css元素显示模式 1. 元素的显示模式1.1 块元素1.2 行内元素1.3 行内块元素 2. 元素根据显示模式分类3. 修改元素的显示模式 1. 元素的显示模式 1.1 块元素 块元素的特性: 在页面中独占一行,从上到下排列。默认宽度,撑满父元素。默认高度&a…...

Shell脚本入门实战:探索自动化任务与实用场景
引言 Shell脚本作为一种强大的自动化工具,在现代操作系统中具有广泛的应用。无论是简单的文件操作,还是复杂的系统管理,Shell脚本都能提供高效、快速的解决方案。在本文中,我们将探索Shell脚本的基础知识,并通过实战场…...

从Kaggle竞赛到现实应用:聊聊ResNet18在驾驶安全监控中的潜力与局限
从Kaggle竞赛到现实应用:ResNet18在驾驶安全监控中的潜力与局限 当计算机视觉技术走出实验室,真正进入驾驶安全监控这样的关键场景时,我们需要思考的远不止模型在测试集上的准确率。ResNet18作为轻量级深度网络的代表,其在Kaggle竞…...

架构范式转移:DeepSeek-Coder-V2如何重构企业级代码智能的ROI模型
架构范式转移:DeepSeek-Coder-V2如何重构企业级代码智能的ROI模型 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Code…...

嵌入式开发中的编程规范实践与行业标准解析
1. 编程规范的本质与价值在嵌入式汽车电子领域干了十五年,我见过太多因为代码不规范导致的惨痛教训。有一次,某车企的ECU控制模块在零下30度环境突然死机,排查三周后发现是未初始化的指针在低温环境下产生了非预期行为——这种问题本可以通过…...

基于YOLOv11与Moondream VLM的本地化实时鸟类检测识别系统实践
1. 项目概述:打造一个本地化的实时鸟类观测站 如果你和我一样,喜欢在自家后院、阳台或者喂食器旁观察鸟类,但又不想一直守在窗边,或者希望记录下那些稍纵即逝的访客,那么这个项目可能就是为你准备的。我最近基于 YOLO…...

告别笨重模拟器:Windows系统上直接安装APK的终极方案
告别笨重模拟器:Windows系统上直接安装APK的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经为了在电脑上运行一个简单的手机应用而不得…...

Vim多光标编辑插件vim-visual-multi:提升批量文本处理效率
1. 项目概述:一个能改变你Vim多光标编辑体验的插件 如果你是一个Vim或Neovim的深度用户,并且对现代编辑器(比如VSCode、Sublime Text)里那种流畅的多光标编辑功能念念不忘,那么你肯定不止一次地搜索过“Vim multiple c…...

Pearcleaner:彻底清理Mac应用的终极免费开源解决方案
Pearcleaner:彻底清理Mac应用的终极免费开源解决方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 在Mac系统中卸载应用程序后,你是…...

构建自动化编译系统:Makefile递归遍历与智能目录生成实践
1. 为什么需要自动化编译系统 如果你曾经维护过一个包含几十个源文件的中大型C/C项目,肯定经历过这样的痛苦:每次新增一个源文件,都要手动修改Makefile;项目结构调整时,编译规则需要全部重写;不同模块之间的…...

3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南
3分钟掌握罗技鼠标宏:PUBG自动压枪脚本终极指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的枪械…...
)
手把手教你:在RT-Thread上用STM32驱动0.96寸OLED显示动态二维码(附完整源码)
基于RT-Thread的STM32动态二维码显示系统开发实战 在智能门锁、工业设备配网等物联网场景中,二维码作为信息载体正发挥着越来越重要的作用。本文将完整呈现如何在RT-Thread操作系统上,通过STM32驱动0.96寸OLED实现动态二维码显示功能。不同于简单的功能演…...